參考:AdaCoT: Rethinking Cross-Lingual Factual Reasoning throughAdaptive Chain-of-Thought
????????AdaCoT(Adaptive Chain-of-Thought,自適應思維鏈)是一項提升大型語言模型(LLMs)跨語言事實推理能力的新框架。這篇論文深入探討了LLMs在多語言環境下表現不一的問題,尤其是在資源匱乏語言上的表現不佳,并提出了解決方案。????????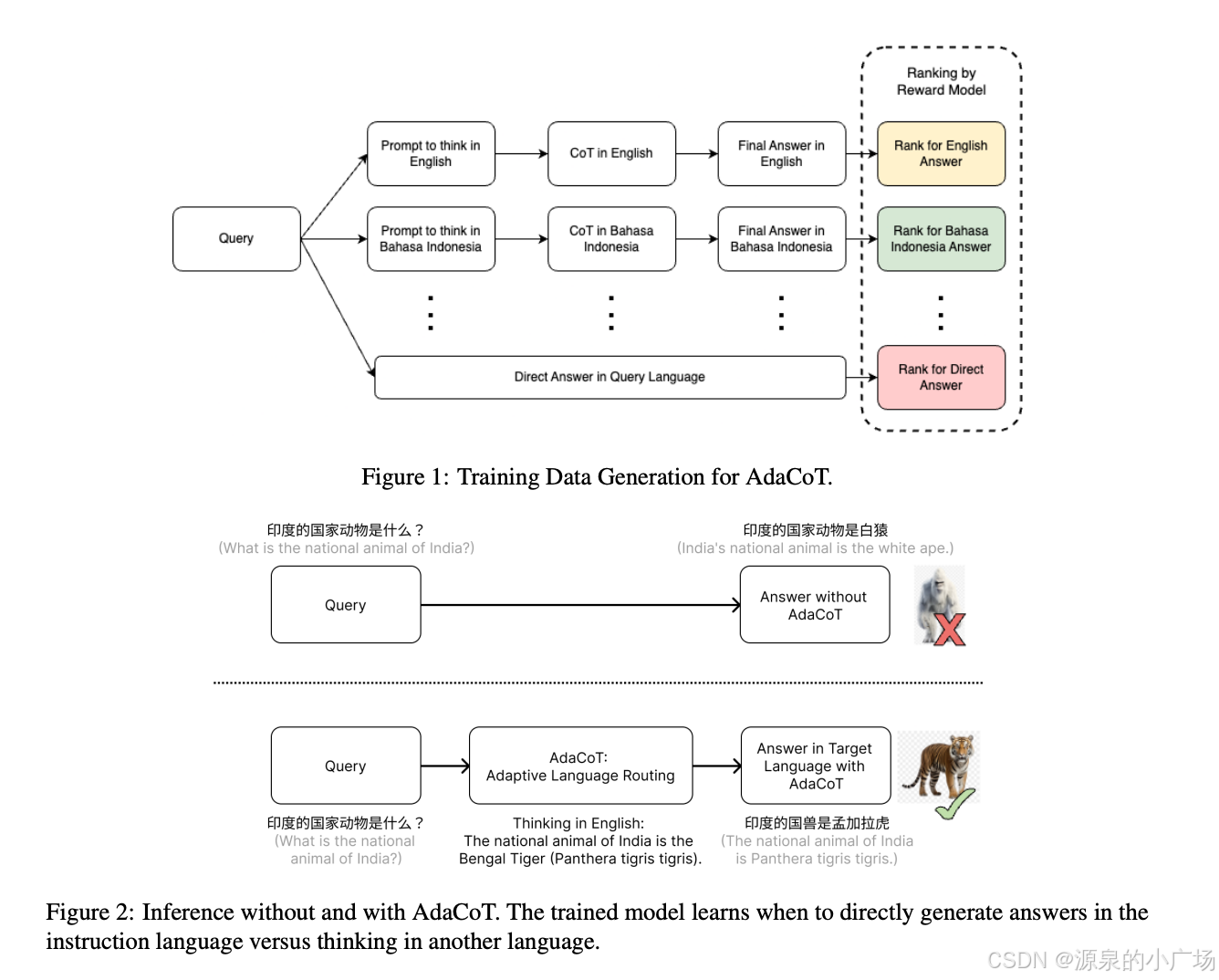
1. 論文背景與AdaCoT旨在解決的問題
????????大型語言模型在多語言預訓練方面展現出強大的能力,但由于訓練數據分布不均,其性能在不同語言間存在顯著差異,尤其偏向英語等主流語言。這導致LLMs在處理跨語言事實知識時面臨挑戰,特別是在資源匱乏語言中。傳統的翻譯方法或簡單的跨語言微調往往無法捕捉細微的推理過程或導致信息失真。AdaCoT正是為了解決這些問題而提出的。
2. AdaCoT核心思想
????????AdaCoT的核心思想是通過在生成目標語言響應之前,動態地將思維過程路由到中間的“思維語言”中,從而增強多語言事實推理能力。它認識到不同語言在特定推理任務上可能具有優勢,例如,某些語言可能擅長邏輯連接,而另一些則可能在數學詞匯方面表現出色。
3. 算法原理
AdaCoT框架基于兩個關鍵原則:
動態路由優化(Dynamic Routing Optimization): 根據任務特性和歷史表現,學習選擇最有效的中間“思維語言”。這意味著模型會根據具體查詢內容和知識分布,自適應地決定是直接在目標語言中生成答案,還是先在某種輔助語言中進行思考。
跨語言知識整合(Cross-Lingual Knowledge Integration): 綜合來自多種語言視角的見解,以生成更穩健的最終輸出。通過這種方式,AdaCoT能夠利用不同語言的優勢,同時保持文化和語言的細微差別。
4. 方法論
AdaCoT通過一種雙路徑機制來實現其自適應路由:
- 跨語言思維鏈(Cross-Lingual Chain-of-Thought, CoT): 利用輔助語言中的思維鏈推理步驟來提升最終輸出質量。
- 直接生成(Direct Generation): 對于模型在目標語言中表現良好或使用中間語言可能降低性能(例如,詩歌創作)的情況,直接在目標語言中生成響應,繞過中間語言以提高效率。
訓練階段的算法流程:
候選響應生成(Candidate Response Generation):
????????給定一個目標語言(l)的輸入查詢(P_l),AdaCoT首先利用LLM將其翻譯成多種主要語言,包括原始語言以及英語、中文和印尼語等輔助語言。
????????然后,采用兩種策略生成多樣化的候選響應:
????????跨語言思維鏈(Cross-Lingual CoT):???
1. 將原始查詢P_l翻譯成輔助語言P_t。
2. 基礎LLM根據P_t在輔助語言(t)中生成中間推理過程(I_t)。
3. 教師模型(例如GPT-4o)利用原始查詢P_l和中間推理I_t,在目標語言(l)中生成最終響應(R_l)。這里的目標是R_l既要保持I_t的語義含義,又要遵循P_l的原始指令。
?????????????
????????直接生成(Direct Generation): 基礎LLM直接在目標語言(l)中從P_l生成響應,不使用任何輔助語言。
候選響應排序(Candidate Response Ranking):???????
1.使用一個強大的LLM(例如GPT-4o)作為評估器,對不同語言路徑(或直接生成)產生的多樣化響應進行評分。
2. 評分基于四個指標:事實不準確性、響應幻覺、重復性以及對指令的遵循程度,采用0-10的李克特量表。
3. 選擇得分最高的路徑作為最優路徑。
AdaCoT微調(AdaCoT Fine-Tuning):???????
1. 利用評估得分(S_t)來指導最優推理動作的選擇,最大化選擇得分最高路徑的可能性。
2. 僅對得分大于等于9(高質量輸出)的實例進行微調,這使得模型能夠從高質量的推理策略中學習。
3. 通過這種方式,模型學會根據輸入查詢動態預測正確的推理路徑和最終響應。
5. 實驗結果
????????AdaCoT在多個基準數據集(如Multilingual TruthfulQA、CrossAlpaca-Eval 2.0、Cross-MMLU和Cross-LogiQA)上進行了全面評估。實驗結果表明,AdaCoT在事實推理質量和跨語言一致性方面取得了顯著提升,尤其是在資源匱乏語言設置中表現出強大的性能增益。自適應路由機制也被證明對高資源語言同樣有效。
優勢與局限性優勢:
????????彌合性能差距: 有效彌合了高資源語言和低資源語言之間的性能差距。
????????保留文化和語言細微差別: 在提升性能的同時,保持了文化和語言的細微差別。
????????無需額外預訓練: 不需要對大型多語言語料庫進行額外的預訓練,提高了計算效率。
????????利用語言優勢: 能夠利用不同語言在特定推理任務上的優勢。
局限性:
????????思維語言數量有限: 目前框架依賴于有限的思維語言集合,這限制了其在更廣泛語言環境中的泛化能力。
????????計算效率: 動態路由機制雖然創新,但可能導致推理延遲增加,帶來計算效率問題。
????????高質量訓練數據需求: AdaCoT需要多樣化、高質量的訓練指令,這在某些領域或資源匱乏語言中可能難以獲取。





 :使用 Milvus 實現高效圖片查重功能)
的自述)












