基于多尺度結構引導擴散模型的圖像去模糊
摘要
擴散概率模型(Diffusion Probabilistic Models, DPMs)最近被用于圖像去模糊,其被表述為一個以模糊輸入為條件的圖像條件生成過程,將高斯噪聲映射到高質量圖像。當在成對的域內數據上訓練時,圖像條件DPMs(icDPMs)顯示出比基于回歸的方法更真實的結果。然而,當面對域外圖像時,它們在恢復圖像方面的魯棒性尚不清楚,因為它們沒有強加特定的退化模型或中間約束。為此,我們引入了一種簡單而有效的多尺度結構引導,作為一種隱式偏置(implicit bias),在中間層通知 icDPM 關于清晰圖像的粗粒度結構。這種引導公式顯著改善了去模糊結果,特別是在未見過的域上。該引導是從一個回歸網絡的潛在空間中提取的,該網絡經過訓練可以在多個較低分辨率下預測清晰目標,從而保留了最顯著的清晰結構。借助模糊輸入和多尺度引導,icDPM模型可以更好地理解模糊并恢復清晰圖像。我們在多個數據集上評估了僅在單個數據集上訓練的模型,并在未見數據上展示了更魯棒的去模糊結果和更少的偽影。我們的方法優于現有基線,在保持具有競爭力的失真度量的同時,實現了最先進的感知質量。
1 引言
圖像去模糊是一個本質上病態(ill-posed)的反問題,旨在根據模糊觀測估計一個(或多個)高質量圖像。深度網絡允許通過成對有監督學習進行端到端的圖像去模糊。雖然基于深度回歸的方法[88, 98, 105, 86, 6, 96, 7, 90, 85, 42, 66, 58]優化了諸如PSNR之類的失真度量,但它們通常會產生過度平滑的輸出,缺乏視覺保真度[40, 5, 14, 4]。因此,感知驅動的方法[44, 27]旨在產生清晰且視覺上令人愉悅的圖像,同時仍然忠實于清晰參考圖像,通常需要在失真性能上做出輕微妥協,即PSNR下降小于3dB [4, 61]允許顯著更好的視覺質量,同時仍然接近目標圖像。GANs[18]被用來改進去模糊感知[37, 38]。然而,GAN訓練存在不穩定性、模式崩潰(mode-collapse)和偽影[53],這可能會損害生成圖像的合理性。
基于深度回歸的方法是指:將去模糊問題視為圖像到圖像的轉換問題,深度模型將模糊圖像作為輸入,預測高質量的清晰圖像。使用像素級損失(如L1和L2損失)進行監督訓練,直接優化失真度量(如PSNR和SSIM)。比如正常的U-Net架構,端到端網絡監督學習。
基于感知驅動的方法是指:旨在產生清晰且視覺上令人愉悅的圖像,同時仍然忠實于清晰的參考圖像。比如基于生成模型的方法。
最近,DPMs[20]在各種成像反問題[74, 43, 90, 72, 13]中進一步提高了照片真實感,其被表述為一個圖像條件生成過程,其中DPM將退化估計作為輔助輸入。圖像條件DPMs(icDPMs)既不估計退化核,也不施加任何中間約束。這些模型使用標準的去噪損失[20]和成對訓練數據以監督方式進行訓練。在圖像恢復中,這種成對訓練數據集通常是通過在干凈的圖像組上應用已知的退化模型人為策劃的,這不可避免地引入了合成訓練數據集與真實世界模糊圖像之間的域差距(domain gap)。
成像反問題:反問題為已知輸出或觀測結果,推斷系統參數或原始輸入。已知模糊圖像,需要恢復出原始清晰圖像。成像反問題本質上是不適定問題,在圖像處理中,多個不同的清晰圖像可能產生相同的模糊觀測,因此反問題通常沒有唯一解。從論文和圖像處理領域來看,主要的成像反問題包括圖像去模糊、超分辨率、圖像去噪等。
域差距(domain gap)指的是合成訓練數據分布(ptrain)與真實世界數據分布(preal)之間的差異。
差距具體表現在以下幾個方面:數據生成方式的差異(合成訓練數據是已知的退化模型(如特定模糊核)人工生成的;真實世界模糊圖像具有更復雜的退化模式,往往無法用簡單的數學模型精確描述。)、 具體表現的差異、實證分析(Inception距離分析/表1/計算了GoPro(域內)和Realblur-J(域外)在不同尺度下的FID和KID值,顯示兩者之間存在顯著差異)。
域差距導致的主要問題是:模型在域外數據上魯棒性下降、產生視覺偽影、無法有效恢復真實世界的模糊圖像
魯棒性相當不明確指的是當icDPMs (image-conditioned Diffusion Probabilistic Models)面對與訓練數據分布不同的未見數據(out-of-domain data)時,其性能表現不穩定且難以預測。
中間恢復過程難以處理指的是icDPMs的去模糊過程缺乏明確的中間表示和約束。icDPMs將去模糊視為一個端到端的條件生成過程,沒有明確的中間步驟表示。
當面對未見數據時,icDPMs的魯棒性相當不明確,因為中間恢復過程是難以處理的。例如,當我們將合成訓練的icDPM應用于域外數據時,我們觀察到性能顯著下降,包括未能對輸入進行去模糊(圖1)和引入偽影(圖4 'icDPM’和圖7 ‘DvSR’)。我們通過實驗確定了現有去模糊icDPMs[72, 74, 90]中域敏感性與圖像條件之間的關系,其中觀察到的泛化能力差歸因于簡單的輸入級連接(input-level concatenation)以及去模糊過程中缺乏中間約束 。在合成訓練集上優化時,可能會發生過擬合或記憶[78],使得模型對輸入分布的偏移變得脆弱。目前,在模糊或損壞圖像上條件化DPM的研究尚不充分[68],我們假設更有效的圖像條件化對于icDPM至關重要,可以使模型在未見域上更具約束性和魯棒性。
域敏感性與圖像條件之間的關系指的是現有圖像條件擴散概率模型(icDPMs)對域外數據表現不佳的根本原因與其處理圖像條件的方式直接相關。
記憶:引用的[78]論文(“Diffusion art or digital forgery? investigating data replication in diffusion models”)指出,擴散模型可能不僅學習數據分布,還可能直接"復制"訓練數據中的特定樣本
輸入分布(Input Distribution):指訓練數據的統計特性,包括圖像內容、模糊類型、光照條件等。
分布偏移(Distribution Shift):指測試數據與訓練數據在統計特性上的系統性差異。也就是說輸入分布偏了一點就學不好了。

圖1:在 Realbur-J 數據集 [67]上的去模糊示例,模型僅在合成的GoPro數據[57]上訓練。比較了最近的基于回歸的方法[96,89](MPRNet,UFormer)、基于GAN的方法[38](DeblurGANV2)和圖像條件擴散概率方法(icDPM)。我們在icDPM公式上引入了一個引導模塊,提高了其在未見圖像上的魯棒性。


受傳統盲去模糊算法的啟發(這些算法使用顯式的結構先驗(例如,包含圖像顯著性[62, 93])進行優化,我們通過中間層的多尺度結構引導增強了icDPM主干(UNet[70])。這些引導特征是通過一個回歸網絡獲得的,該網絡經過訓練可以從輸入中預測顯著的清晰特征。該引導與模糊圖像一起,為模型提供了關于圖像中特定退化的更具信息性的線索。因此,模型可以更準確地恢復清晰圖像并更有效地泛化。
圖像顯著性(Image Saliency) 是指圖像中對人類視覺系統特別突出、引人注意的部分,通常代表圖像中最重要的結構特征和信息。
我們的貢獻有三方面:
(1) 我們研究并分析了條件擴散模型在運動去模糊任務中的域泛化能力,并通過實驗發現了模型魯棒性與圖像條件化之間的關系;
(2) 我們提出了一種直觀但有效的引導模塊,將輸入圖像投影到多尺度結構表示中,然后將其作為輔助先驗融入擴散模型以提高魯棒性;
(3) 與現有基準相比,我們僅在單個數據集上訓練的模型通過產生更合理的去模糊和更少的偽影,在不同的測試集上顯示出更魯棒的結果,并通過最先進的感知質量和相當的失真度量進行了量化。
2 相關工作
單圖像去模糊
是從模糊觀測中恢復一個或多個高質量、清晰圖像的反過程。通常,經典的去模糊方法涉及變分優化[17, 36, 41, 54, 63, 93, 1, 26],對模糊核、圖像或兩者施加先驗假設,以緩解反問題的病態性。手工制作的結構先驗,如邊緣和形狀,已成功用于許多算法中,以引導去模糊過程在去除模糊的同時保留圖像中的重要特征[62, 63, 93]。我們的設計原則受到這些方法的啟發,涉及一種學習的引導作為隱式結構偏置。隨著深度學習的興起,去模糊可以被視為一個特定的圖像到圖像轉換問題,其中深度模型以模糊圖像作為輸入,并預測一個高質量對應物,通過恢復圖像與目標之間的逐像素損失進行監督[88, 98, 105, 86, 6, 96, 7, 90, 85, 42, 66, 58, 25]。已知逐像素損失(如L1L_{1}L1?和L2L_{2}L2?)由于其“回歸到均值”的性質會導致過度平滑的圖像[40, 5, 14]。為此,在逐像素約束之上添加了感知驅動的損失,包括感知損失[27, 101, 51, 50, 103, 14]和對抗損失[37, 38],以提高去模糊圖像的視覺保真度,同時失真分數有所下降[4, 61]。另外,最近的工作通過探索注意力機制[60, 95, 89, 94, 85, 86]、多尺度范式[57, 7]和多階段框架[97, 6, 96]來改進架構設計。
擴散概率模型(DPM)
[77, 20, 79, 15]、基于分數的模型(Score-based models)[81, 82, 83]及其最近的探索性泛化[2, 24, 12]在廣泛的應用中取得了顯著成果[10],從圖像和視頻合成[73, 64, 69, 21, 31, 22]到解決一般成像反問題[11, 28, 33, 30, 39, 8]。DPMs的特點是訓練穩定[20, 15, 29]、模式覆蓋多樣[80, 34]和高感知質量[73, 15, 64]。DPM公式涉及一個固定的前向過程(逐漸向圖像添加高斯噪聲)和一個可學習的反向過程(去噪并恢復清晰圖像),采用馬爾可夫鏈結構操作。條件DPMs旨在通過附加輸入(類別[15]、文本[73, 64]、源圖像)執行圖像合成。
圖像條件DPMs(icDPMs)
已成功地重新用于圖像恢復任務,如超分辨率[74, 43]、去模糊[90]、JPEG恢復[72, 32]。這是通過在輸入級連接損壞的觀測來實現的。它們不需要特定任務的損失或架構設計,并因高樣本感知質量而被采用。ControlNet[100]進一步實現了對預訓練文本到圖像擴散模型的特定任務圖像條件化。InDI[13]提出了一種替代且更直觀的擴散過程,其中低質量輸入通過小步驟直接恢復為高質量圖像。然而,DPMs對域中未見偏移的泛化能力,以及它們對低質量/損壞圖像的條件化仍然未被探索。
對未見域的泛化
如上所述,用于去模糊的深度恢復模型依賴于合成的成對訓練數據。然而,任何訓練良好的深度恢復模型在域外數據上都可能無法產生可比的結果(圖1)。為了解決這個問題,研究人員追求兩個主要方向來改進模型泛化:增強訓練數據的代表性和真實性,或提高模型的域泛化能力。我們的方法側重于后者,但它與前者并不互斥,可以結合使用以進一步改善結果。為了解決數據限制,先前的工作側重于獲取或組合更具代表性的訓練數據[56, 67, 66, 104],和/或使用生成方法[99, 91]生成真實的退化圖像。其他先前的工作側重于顯式的域適應(domain adaptation),利用遷移學習技術來減少域差距。這些方法包括非配對圖像翻譯[23, 65]和域適應[87, 75, 47, 58],通常涉及對抗式公式和兩個指定域之間的聯合訓練。然而,當引入新數據集時,這些方法可能需要重新訓練。相比之下,我們的方法不涉及特定域之間的顯式適應。相反,我們專注于引入更有效的圖像條件化機制,自然地使模型對分布偏移更具魯棒性。
3 方法
3.1 概述
我們假設可以訪問一個包含樣本 (x,y)~ptrain(x,y)(\bm{x},\bm{y})\sim p_{\text{train}}(\bm{x},\bm{y})(x,y)~ptrain?(x,y) 的成對數據集,其中 x\bm{x}x 代表高質量清晰圖像,而 y\bm{y}y 是相應的低質量模糊觀測(在圖2中表示)。這種成對數據集通常是通過采用特定的退化模型從高質量圖像模擬退化圖像來生成的合成數據集。
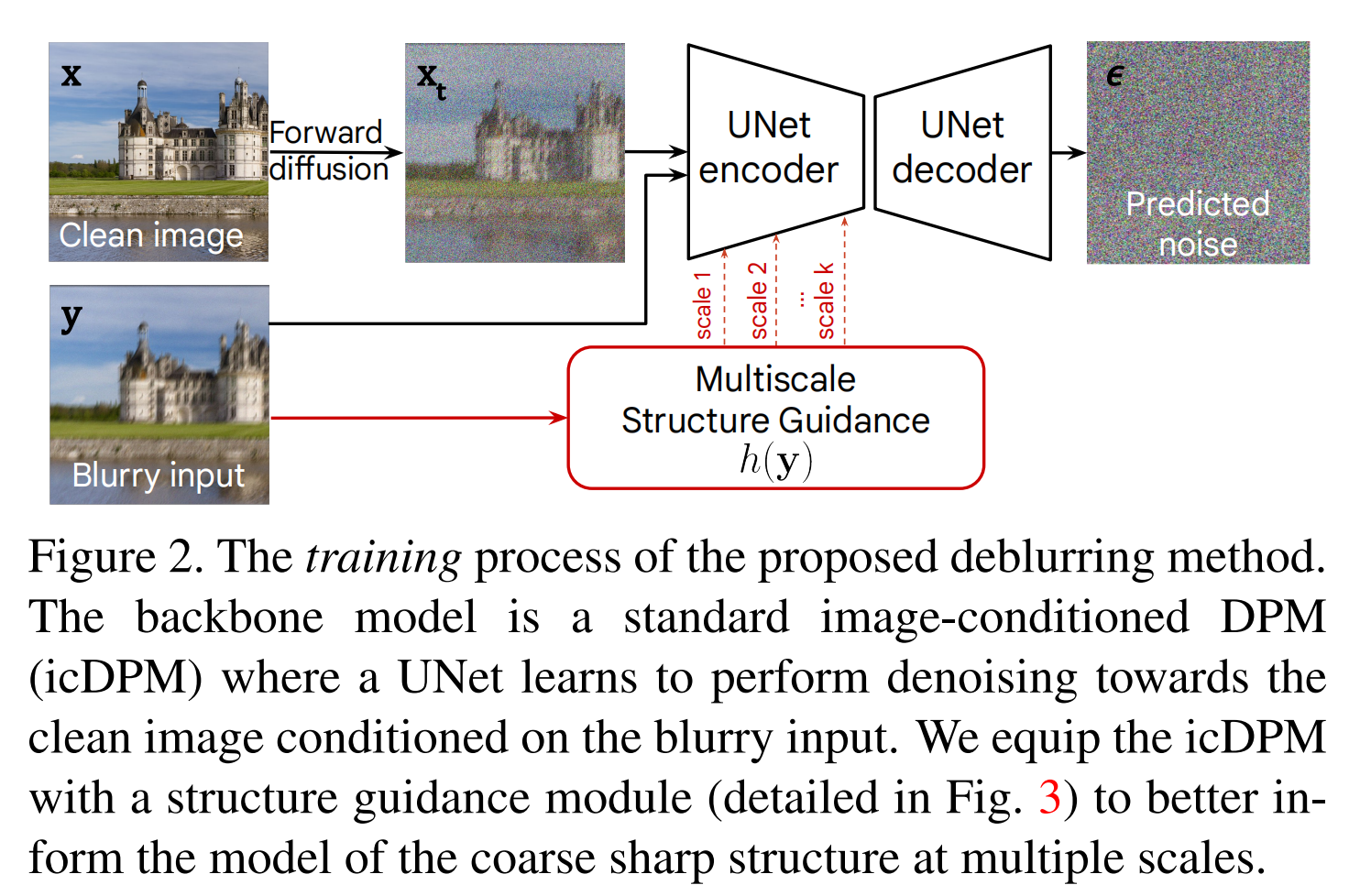
圖2:所提出的去模糊方法的訓練過程。主干模型是一個標準的圖像條件DPM(icDPM),其中UNet學習在模糊輸入條件下對清晰圖像進行去噪。我們為icDPM配備了一個結構引導模塊(詳見圖3),以在多尺度上更好地告知模型粗粒度清晰結構。
x\bm{x}x 是高質量清晰圖像
y\bm{y}y 是低質量人工合成模糊數據
y^\hat{\bm{y}}y^? 是低質量觀測真實模糊數據
目標是從低質量觀測 y^~preal(y^)\hat{\bm{y}}\sim p_{\text{real}}(\hat{\bm{y}})y^?~preal?(y^?) 重建一個或多個干凈、清晰的圖像 x\bm{x}x。通常,訓練集分布 ptrainp_{\text{train}}ptrain? 與未見圖像 prealp_{\text{real}}preal? 的分布不同。因此,至關重要的是模型不僅在 ptrainp_{\text{train}}ptrain? 上表現良好,而且能夠泛化到 prealp_{\text{real}}preal?。
DPMs 鑒于DPM在高質量圖像恢復[74, 90]方面的卓越性能,我們考慮使用通用DPM進行我們的公式化。接下來,我們簡要描述DPM的訓練和采樣,以為我們的工作提供背景。
使用通用DPM進行我們的公式化的含義:作者采用通用的擴散概率模型 (general-purpose DPM) 作為他們方法的基礎數學框架和實現架構。他們選擇通用DPM是因為它在高質量圖像恢復任務中表現優異
無條件 DPMs 旨在通過迭代地對來自高斯分布的樣本進行去噪并將其轉換為來自目標數據分布的樣本來從數據分布 p(x)p(\bm{x})p(x) 中采樣 。為了訓練這樣的模型,涉及一個前向擴散過程和一個反向過程。如圖 2 所示,在擴散步驟 ttt 時,目標圖像 x\bm{x}x 的噪聲版本 xt\bm{x}_{t}xt? 通過以下公式生成。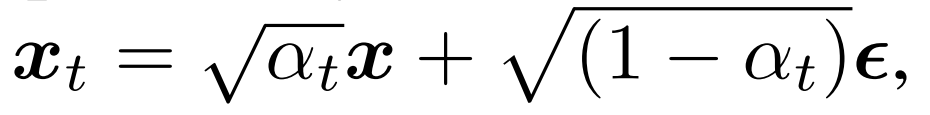 其中,?~N(0,Id)\epsilon\sim\mathcal{N}(0,\bm{I}_{d})?~N(0,Id?),其中 ?\epsilon? 從標準高斯分布 N(0,Id)\mathcal{N}(0,\bm{I}_{d})N(0,Id?) 采樣,αt\alpha_{t}αt? 控制每一步 ttt 添加的噪聲量。在反向過程中,一個圖像到圖像的網絡(即UNet)Gθ(xt,t)\mathcal{G}_{\theta}(\bm{x}_{t},t)Gθ?(xt?,t) 由參數 θ\thetaθ 參數化,學習從部分噪聲輸入 xt\bm{x}_{t}xt? 中估計清晰圖像。在實踐中,對模型進行重新參數化以預測噪聲而不是清晰圖像可以獲得更好的樣本質量[20]。訓練完成后,它通過從純高斯噪聲 xT~N(0,Id)\bm{x}_{T}\sim\mathcal{N}(0,\bm{I}_{d})xT?~N(0,Id?) 開始迭代運行 TTT 步來采樣清晰圖像。
其中,?~N(0,Id)\epsilon\sim\mathcal{N}(0,\bm{I}_{d})?~N(0,Id?),其中 ?\epsilon? 從標準高斯分布 N(0,Id)\mathcal{N}(0,\bm{I}_{d})N(0,Id?) 采樣,αt\alpha_{t}αt? 控制每一步 ttt 添加的噪聲量。在反向過程中,一個圖像到圖像的網絡(即UNet)Gθ(xt,t)\mathcal{G}_{\theta}(\bm{x}_{t},t)Gθ?(xt?,t) 由參數 θ\thetaθ 參數化,學習從部分噪聲輸入 xt\bm{x}_{t}xt? 中估計清晰圖像。在實踐中,對模型進行重新參數化以預測噪聲而不是清晰圖像可以獲得更好的樣本質量[20]。訓練完成后,它通過從純高斯噪聲 xT~N(0,Id)\bm{x}_{T}\sim\mathcal{N}(0,\bm{I}_{d})xT?~N(0,Id?) 開始迭代運行 TTT 步來采樣清晰圖像。
圖像條件DPMs 進一步注入輸入圖像 y\bm{y}y,以生成與低質量觀測配對的高質量樣本。這涉及從條件分布 p(x∣y)p(\bm{x}|\bm{y})p(x∣y)(后驗)中生成樣本。使用條件DPM Gθ([xt,y],t)\mathcal{G}_{\theta}([\bm{x}_{t},\bm{y}],t)Gθ?([xt?,y],t),其中圖像條件化通常通過 y\bm{y}y 和 xt\bm{x}_{t}xt? 在輸入級連接來實現[74, 90, 72]。然而,我們發現這種公式對輸入圖像的域偏移敏感,并導致泛化能力差(圖1中的’DPM’)。此外,在許多情況下它會引入視覺偽影(圖7中的’DvSR’)。
我們推測這是由于簡單的圖像條件化(輸入級連接),在中間過程中缺乏約束。因此,我們將多尺度結構引導 h(y)h(\bm{y})h(y) 集成到icDPM主干的潛在空間中,以通知模型關于顯著的圖像特征,例如對重建高質量圖像至關重要的顯著粗粒度結構,同時解耦不相關信息,如模糊核的痕跡和顏色信息。為了獲得具有上述特征的引導,我們提出了一個輔助回歸網絡,并利用其學習到的特征作為引導的實現,如下文第3.2節所述。
3.2 多尺度結構引導
圖 3 顯示了我們提出的引導 h(?)h(\cdot)h(?) 的細節。配備這種多尺度引導的 DPM 能更好地感知輸入底層的顯著結構,因此它學習更好地從目標條件分布preal(x∣y)p_{\text{real}}(\bm{x}|\bm{y})preal?(x∣y)中采樣。此外,當輸入域改變時,h(y)h(\bm{y})h(y)的分布不會顯著改變,因此即使在應用于未見域時,它也能可靠地提供輔助結構引導。
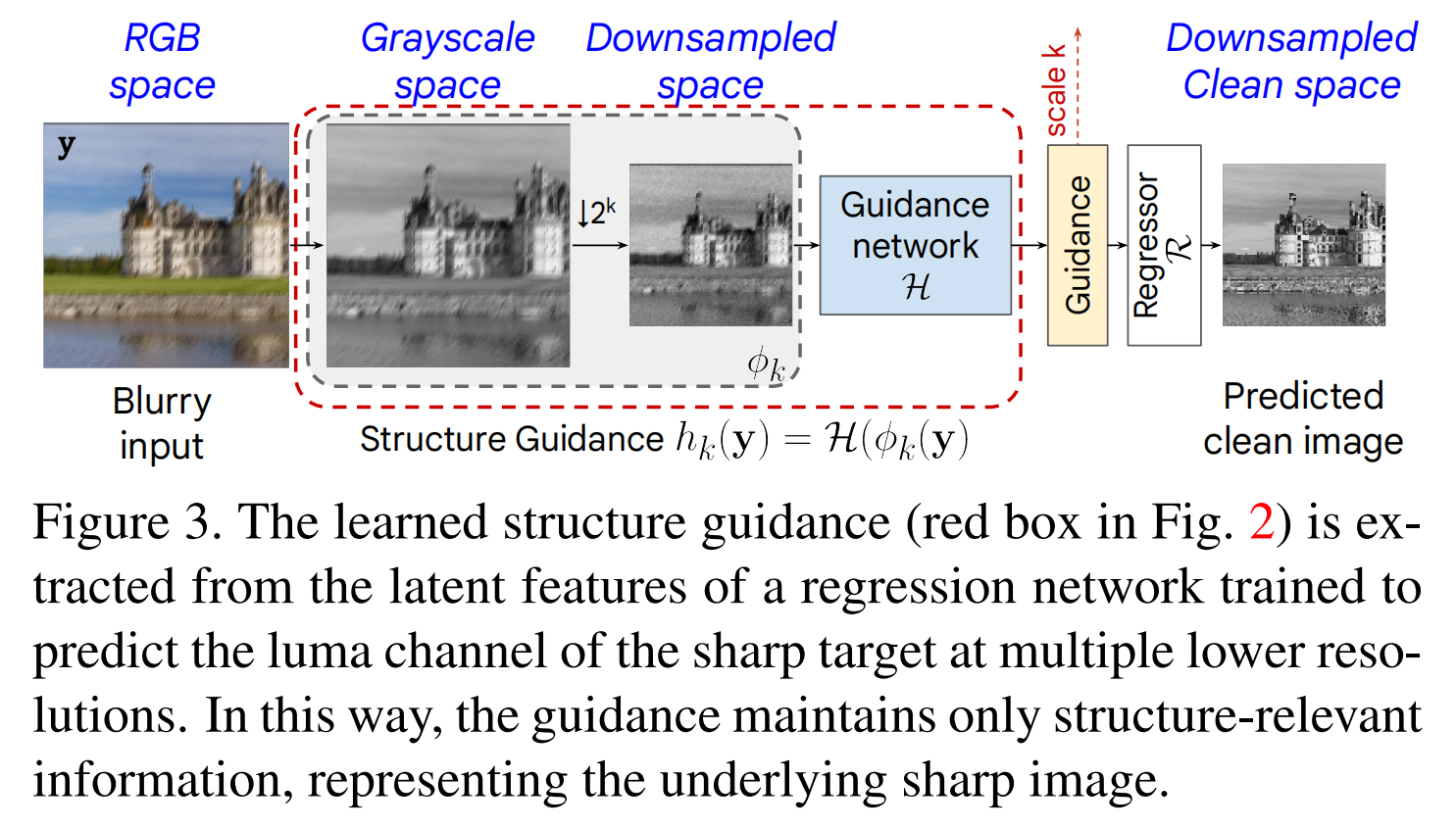
圖3:學習的結構引導(圖2中的紅框)是從一個回歸網絡的潛在特征中提取的,該網絡經過訓練可以在多個較低分辨率下預測清晰目標的亮度(luma)通道。這樣,引導僅保留與結構相關的信息,代表底層的清晰圖像。
為達此目的,我們將引導模塊構建為hk(?)=H(?k(?))h_{k}(\cdot)=\mathcal{H}(\phi_{k}(\cdot))hk?(?)=H(?k?(?))。在尺度kkk上,它由一個圖像轉換函數?k(?)\phi_{k}(\cdot)?k?(?)和一個回歸驅動的引導網絡H\mathcal{H}H組成。具體來說,?k(?)\phi_{k}(\cdot)?k?(?)轉換輸入圖像y\bm{y}y以抑制與粗粒度清晰圖像結構無關的信息(例如,顏色和特定域退化的信息)。這確保了H\mathcal{H}H在一個對輸入域不太敏感的空間上操作。我們首先將y\bm{y}y轉換為灰度空間yˉ\bar{\bm{y}}yˉ?,然后,yˉ\bar{\bm{y}}yˉ?被下采樣2k2^{k}2k倍,其中k=1,2,3k=1,2,3k=1,2,3。這移除了精細細節(包括一定程度的模糊痕跡),同時在多個較低分辨率下保留了粗粒度結構。受[91]啟發,我們還添加少量高斯噪聲以掩蓋其他特定域的退化/特征,并使輸出對輸入域偏移不太敏感。在最近的擴散模型中,添加噪聲已成為常見做法[71, 73],因為它增強了處理域外數據時的魯棒性。因此,
?k(y)=d↓k(yˉ)+n,n~N(0,σ2I).\phi_{k}(\bm{y})=d_{\downarrow k}(\bar{\bm{y}})+\bm{n},\quad\bm{n}\sim\mathcal{N}(0,\sigma^{2}\bm{I}).?k?(y)=d↓k?(yˉ?)+n,n~N(0,σ2I). (1)
然后,引導網絡Hφ\mathcal{H}_{\varphi}Hφ?通過將?k(y)\phi_{k}(\bm{y})?k?(y)映射到表示/潛在空間來提取引導特征:hk(y)=Hφ(?k(y))h_{k}(\bm{y})=\mathcal{H}_{\varphi}(\phi_{k}(\bm{y}))hk?(y)=Hφ?(?k?(y))。為確保它獲得顯著的結構特征并進一步濾除不重要信息,我們在hk(y)h_{k}(\bm{y})hk?(y)之上應用回歸任務Rφ\mathcal{R}_{\varphi}Rφ?,并將輸出約束得更接近其清晰目標?k(x)\phi_{k}(\bm{x})?k?(x)。這樣,在尺度kkk上的引導hk(y)h_{k}(\bm{y})hk?(y)被強制保留與清晰圖像相關的信息,并抑制其他特定于輸入的信號(例如,模糊痕跡)。
最后,我們將多尺度引導{hk(y)}\{h_{k}(\bm{y})\}{hk?(y)}整合到原始擴散UNet中,方法是將提取的表示作為額外的偏置(bias)添加到擴散編碼器(圖2)相應尺度的特征圖上。為補償深度的差異,在每個對應尺度,我們應用一個卷積層,其具有與擴散編碼器中相同數量的特征。詳細圖示見附錄。
3.3 訓練損失
我們的模型通過用于優化引導網絡的多尺度回歸損失和icDPM中的去噪損失進行端到端訓練。回歸損失是每個尺度kkk上的均方誤差,定義為:
Lguidancek=E(x,y)~ptrain∥Rφ(Hφ(?k(y)))??k(x)∥2,\mathcal{L}_{\text{guidance}}^{k}=\mathbb{E}_{(\bm{x},\bm{y})\sim p_{\text{train}}}\|\mathcal{R}_{\varphi}(\mathcal{H}_{\varphi}(\phi_{k}(\bm{y})))-\phi_{k}(\bm{x})\|_{2},Lguidancek?=E(x,y)~ptrain??∥Rφ?(Hφ?(?k?(y)))??k?(x)∥2?, (2)
其中Hφ\mathcal{H}_{\varphi}Hφ?是引導特征提取器,R\mathcal{R}R實例化為一個單一卷積層,將引導特征投影到面向清晰圖像的最終輸出(如圖3所示)。總回歸損失是不同尺度損失的平均值:Lguidance=∑kLguidancek\mathcal{L}_{\text{guidance}}=\sum_{k}\mathcal{L}_{\text{guidance}}^{k}Lguidance?=∑k?Lguidancek?。注意,我們在引導網絡中不使用任何額外的下采樣/上采樣操作,因此空間維度在每個尺度上保持不變。我們通過實驗觀察到,通過集成三個不同的尺度k=1,2,3k=1,2,3k=1,2,3可以獲得最佳性能,細節在第4.6節討論。
通過聚合來自輸入圖像y\bm{y}y和多尺度引導{hk(y)}\{h_{k}(\bm{y})\}{hk?(y)}的信息,我們的icDPM G\mathcal{G}G通過最小化去噪損失進行訓練,
LDPM=E(x,y)~ptrainEt~Unif(0,1)E?~N(0,I)\mathcal{L}_{\text{DPM}} =\mathbb{E}_{(\bm{x},\bm{y})\sim p_{\text{train}}}\mathbb{E}_{t\sim\text{Unif}(0,1)}\mathbb{E}_{\bm{\epsilon}\sim\mathcal{N}(0,\bm{I})}LDPM?=E(x,y)~ptrain??Et~Unif(0,1)?E?~N(0,I)? (3)
∥Gθ(xt,y,{Hφ(?k(y))},αt)??∥1.\|\mathcal{G}_{\theta}(\bm{x}_{t},\bm{y},\{\mathcal{H}_{\varphi}(\phi_{k}(\bm{y}))\},\alpha_{t})-\bm{\epsilon}\|_{1}.∥Gθ?(xt?,y,{Hφ?(?k?(y))},αt?)??∥1?.
由參數θ\thetaθ參數化的去噪模型預測噪聲?\bm{\epsilon}?,給定噪聲損壞xt\bm{x}_{t}xt?、模糊輸入y\bm{y}y、噪聲調度器αt\alpha_{t}αt?以及提出的多尺度引導{Hφ(?k(y))}\{\mathcal{H}_{\varphi}(\phi_{k}(\bm{y}))\}{Hφ?(?k?(y))}。總訓練損失L=Lguidance+LDPM\mathcal{L}=\mathcal{L}_{\text{guidance}}+\mathcal{L}_{DPM}L=Lguidance?+LDPM?,用于以端到端的方式優化引導網絡H\mathcal{H}H、回歸層R\mathcal{R}R和icDPM G\mathcal{G}G。在推理過程中,模型從高斯噪聲開始,并在每個去噪步驟中以模糊輸入和多尺度引導為條件,迭代地恢復清晰圖像。
4 實驗
設置與度量
如上所述,我們特別關注DPMs對未見模糊數據的模型泛化能力。因此,我們在模型僅使用合成成對數據集進行訓練,并在幾個未見測試集(這些圖像可能呈現與域內數據不同的內容和失真)上進行評估的場景下設置實驗。作為基準,我們使用廣泛采用的運動去模糊數據集GoPro[57]作為我們的訓練數據,并假設Realblur-J[67]、REDS[56]和HIDE[76]代表未見測試集。
在GoPro[76]中,提供了3214對模糊/干凈訓練樣本用于訓練,并保留1111張圖像用于評估。Realblur-J[67]是一個最近的真實數據集,主要包含具有運動模糊的低光場景,提供了980張測試圖像。我們認為它與GoPro存在最大的域差距。REDS[56]提供了一個互補的視頻去模糊數據集,包含更真實的
===== Page 5 =====
運動模糊。我們遵循[56, 6]并提取300張驗證圖像用于運動去模糊測試。HIDE[76]是最常用于測試從GoPro訓練獲得的模型泛化能力的數據集,包含2025張測試圖像。
實現細節
我們的框架在TensorFlow 2.0中實現,并在32個TPU v3核心上訓練。我們僅使用回歸損失進行預熱啟動訓練,并在前60k次迭代中將去噪損失的權重線性增加到1。訓練期間使用Adam優化器[35](β1=0.5,β2=0.999\beta_{1}=0.5,\beta_{2}=0.999β1?=0.5,β2?=0.999),在128×128128\times 128128×128隨機裁剪上的批次大小為256。我們在前20k次迭代中使用線性增加的學習率,然后使用恒定學習率1×10?41\times 10^{-4}1×10?4。我們為icDPM使用全卷積UNet架構[90],以確保模型可用于任意圖像分辨率。在推理過程中,我們遵循[90]并在不同參數下執行一系列采樣。更多細節包含在附錄中。
引導的有效性
我們首先通過與基線設置(即標準圖像條件DPM,縮寫為’icDPM’)進行定性比較來驗證所提出的引導模塊的有效性,我們將在此基線之上引入引導模塊(縮寫為’icDPM w/ Guide’)。引導和KID(Kernel Inception Distance)在引導網絡輸出上進行比較,并與下采樣灰度輸入進行比較。這表明引入學習的引導可以提供更多與域無關的信息,并有利于模型在未見域上的泛化。在圖4中,我們在一個域外輸入上展示了不同尺度的多尺度回歸輸出。結果符合我們的預期,因為每個尺度的灰度預測逐步接近清晰圖像。此外,我們在此示例中注意到icDPM存在明顯的采樣偽影,這些偽影通過提出的引導被有效消除。
**引導與模型容量。**由于引導網絡引入了更多參數,我們調查其性能提升是否僅僅源于更大的模型。我們聯合分析了不同模型大小(帶或不帶引導網絡)的情況,結果呈現在表2中。我們將GoPro測試集上的結果稱為“域內”(‘In-domain’),將Realblur-J數據集上的結果稱為“域外”(‘Out-of-domain’),使用的是僅在GoPro上訓練的單一模型。我們保持構建塊的數量不變,僅通過改變卷積濾波器數量來調整網絡大小。‘-S’和’-L’分別表示較小和較大的模型。我們從不同網絡大小下不帶所提出引導網絡的圖像條件DPM(icDPM)開始。在表2行(a)和(b)中,我們觀察到通過增加UNet容量,域內去模糊性能在感知和失真質量方面都有顯著改善。然而,域外測試結果隨著網絡增大而變得更差,表明訓練過程中可能存在過擬合。通過視覺檢查,我們還發現較大的DPM在面對未見數據時容易產生偽影,如圖1、4和8所示。通過引入引導網絡,我們觀察到域內和域外性能都有提升。為了分離引入引導模塊的效果,我們還比較了icDPM和帶有引導的icDPM在參數量相近的情況下的性能(從(e)到(d),我們通過使用較小的引導模塊減少了模型參數)。我們觀察到(d) icDPM-L w/ Guide-S與(e) icDPM-L w/ Guide-L在域內和域外性能上結果相當,并且兩者都優于icDPM-L。
我們還在圖5中展示了一個失真-感知圖,其中樣本是通過不同的采樣參數(即步數和噪聲標準差)獲得的。與[90]類似,我們發現感知質量和失真度量之間存在普遍的權衡。此外,我們觀察到在所有采樣參數下,所有帶引導的模型始終優于基線DPMs。我們在附錄中提供了其他數據集的額外結果,并觀察到與基線icDPM相比使用引導模塊的類似效果和益處。
去模糊結果
我們將我們的去模糊結果與最先進的方法進行比較,大致分為失真驅動模型[6, 96, 7]、感知驅動的基于GAN的方法[37, 38]以及最近的基于擴散的方法[90]。在這項工作中,我們特別強調評估(1)在未見數據上的泛化能力,以及(2)輸出的感知質量,愿意在平均失真分數上做出輕微下降以換取失真和感知之間更好的權衡[4]。對于基準測試,我們主要考慮結果的感知質量,通過生成模型的標準度量進行量化,包括LPIPS[102]、NIQE[55]、FID(Frechet Inception Distance)[19]和KID(Kernel Inception Distance)[3]。為了完整性,我們還給出了失真度量,包括PSNR和SSIM。然而,我們注意到它們與人類感知的相關性較低[59],并且最大化PSNR/SSIM會導致視覺感知的妥協[4]。我們的方法基于生成模型并執行隨機后驗采樣。訓練數據集中提供的參考圖像只是其他可能恢復結果中的一種(由于反問題的病態性)。因此,類似于[4, 61],我們的結果在像素級平均失真上有所妥協,同時仍然忠實于目標。我們為每個指標突出顯示最佳和次佳值。KID值乘以1000以便閱讀。
我們首先在表4中展示域內GoPro性能。我們的模型在感知度量上全面達到了最先進的水平,同時通過對多個樣本取平均(‘Ours-SA’)保持了具有競爭力的失真度量。此外,我們關注在Realblur-J(表5)、REDS(表7)和HIDE(表6)上的域泛化和域外結果。我們在未見過的Realblur-J數據集上實現了顯著更好的感知質量
表3:在GoPro[57]、HIDE[76]、Realblur-J[67]、REDS[56]數據集上的平均去模糊結果(使用僅在GoPro[57]上訓練的模型),表明模型在各種未見數據上的魯棒性。
| Perceptual | Distortion | ||||
|---|---|---|---|---|---|
| LPIPS ↓ | NIQE ↓ | FID ↓ | KID ↓ | PSNR ↑ | |
| DeblurGAN-v2 [38] | 0.149 | 3.42 | 14.57 | 5.28 | 28.09 |
| MPRNet [96] | 0.140 | 3.70 | 20.22 | 8.49 | 29.78 |
| UFormer [89] | 0.133 | 3.65 | 18.99 | 8.13 | 30.06 |
| Restormer [94] | 0.139 | 3.69 | 19.90 | 8.36 | 30.00 |
| Ours-SA | 0.124 | 3.64 | 14.36 | 6.79 | 29.98 |
| Ours | 0.104 | 2.94 | 8.41 | 2.39 | 28.81 |
表2:所提出的引導在圖像條件DPM(icDPM)上的有效性,在不同網絡大小下(‘-S’和’-L’分別指小型和大型網絡)。我們展示了域內(在GoPro上訓練,在GoPro上測試)和域外(在GoPro上訓練,在Realblur-J上測試)的結果。基于(a)-(b),我們觀察到更大的icDPM提升了域內性能,但不一定帶來更好的域外結果。使用引導?-(d),我們觀察到域內和域外性能的一致改善。
| Guidance network | Diffusion network | #Params | In-Domain | Out-of-domain | |||
|---|---|---|---|---|---|---|---|
| best LPIPS ↓ | best PSNR ↑ | best LPIPS ↓ | best PSNR ↑ | ||||
| (a) icDPM-S | - | ch=32 | 6M | 0.077 | 30.555 | 0.150 | 28.209 |
| (b) icDPM-L | - | ch=64 | 27M | 0.058 | 32.105 | 0.156 | 27.996 |
| ? icDPM-S w/ Guide-S | ch=32 | ch=32 | 10M | 0.068 | 31.298 | 0.145 | 28.286 |
| (d) icDPM-L w/ Guide-S | ch=32 | ch=64 | 30M | 0.058 | 32.220 | 0.128 | 28.742 |
| (e) icDPM-L w/ Guide-L | ch=64 | ch=64 | 52M | 0.057 | 32.254 | 0.123 | 28.711 |
圖5:作為表2補充的感知-失真圖,在不同采樣參數下。在不同網絡容量下(‘-S’和’-L’分別指小型和大型),與icDPM相比,引導機制始終允許獲得更好的感知質量和更低的失真。其他數據集的圖在補充材料中,我們觀察到類似的趨勢。
===== Page 6 =====
和REDS,以及在HIDE上具有競爭力的結果。此外,我們通過比較它們在所有四個測試集上的平均性能(總結在表3中)來分析性能最佳的單一數據集訓練模型的魯棒性。我們的方法顯著提高了感知分數,同時保持了高度競爭力的失真分數,與最佳PSNR相差<0.08 dB,與平均樣本(‘Ours-SA’)的最佳SSIM相差<0.001。
視覺去模糊示例在圖6(GoPro[57]和HIDE[76])、圖7(RealblurJ[67])和圖8(REDS[56])中分別提供。在GoPro(域內)測試示例上,我們發現所有方法都能產生合理的無偽影去模糊結果,而我們的方法生成更清晰、視覺上更真實的結果。在三個域外數據集上,基線方法的性能開始下降。例如,基于GAN的模型[38]和先前的基于擴散的模型[90]傾向于在域外數據上產生偽影,而最先進的基于回歸的模型[89]產生過度平滑的結果。我們的公式在不同數據集上表現得更一致更好,顯著減少了未見數據上的偽影,具有高感知真實感。更多放大的視覺示例在附錄中。
感知研究
我們進一步進行了一項用戶研究,讓人類受試者驗證在未見數據上去模糊性能的感知質量,所有模型均在GoPro上訓練
圖6:在GoPro[57](前兩行)和HIDE[76](后兩行)測試集上的去模糊結果,來自MIMO UNet+ [7], DvSR [90], UFormer [89]和Ours。所有模型僅在GoPro[57]訓練集上訓練。我們的方法生成感知上更清晰的圖像,并在應用于未見圖像(HIDE)時減少偽影。放大結果見附錄。
圖7:Realblur-J[67]上的測試示例,所有模型僅在GoPro數據集[57]上訓練。建議電子版查看。我們通過實驗發現DeblurGANv2[38]和DvSR[90]容易產生偽影,而基于回歸的UFormer[89]產生過度平滑的圖像。我們的方法減輕了偽影,并在未見數據上(即使域差距很大)產生高保真的去模糊結果。
===== Page 7 =====
并在Relblur-J上測試。我們要求Amazon Mechanical Turk評分者從給定的對中選擇質量最好的圖像。我們使用了30對唯一的512×512512\times 512512×512大小的圖像,平均了來自25位評分者的750個評分。在表8中,每個值代表評分者更喜歡行模型而不是列模型的次數比例。可以看出,我們的方法優于現有解決方案。此外,值得指出的是,我們的方法帶引導機制和不帶引導機制(表示為icDPM)的偏好存在顯著差距。
額外的建模選擇
**引導網絡。**我們對引導網絡的建模選擇進行了額外的消融研究,包括回歸目標(RGB vs 灰度)、采用的尺度數量(單一尺度 vs 多尺度)以及融入引導的機制(輸入級 vs 潛在空間)。為公平比較,訓練期間在不同配置下使用相同的擴散UNet,推理期間使用相同的采樣參數。表9 (a) 表示我們不帶任何引導的基線icDPM。我們首先比較了在輸入級融入引導和在潛在空間融入引導的差異(表9 (b) 和 ?)。在(b)中,我們將回歸輸出上采樣到原始輸入大小,并將結果連接到擴散UNet的輸入。在?中,我們將回歸輸出之前的特征圖通過上述加法操作融入UNet的潛在空間。結果表明潛在空間引導優于輸入級連接。無論是(b)還是?都優于(a),顯示了引入引導的整體益處。
我們在行(d)與?的比較中也觀察到使用多尺度引導比單尺度引導有適度改進。在行(e)中,我們將回歸目標從彩色空間簡化為灰度空間,這進一步改善了結果。
**引導操作。**我們對將引導注入icDPM主干的操作進行了消融研究。我們測試了三種不同的可能引導操作,包括加法(我們的最終選擇)、連接(concatenation)和自適應組歸一化(adaptive group normalization)。表10顯示了在GoPro上的去模糊PSNR,其中加法實現了最佳性能。根據經驗,我們觀察到在我們的用例中自適應歸一化傾向于引入偽影。與連接相比,加法更節省內存,并確保引導不能被簡單地忽略。
**引導特征的訓練目標。**由于我們的目標是通過集成多尺度結構引導來增強icDPM主干的魯棒條件化機制,我們引入了回歸損失來聯合訓練引導模塊和icDPM。我們假設該損失對于確保導出的引導表示保留突出的結構特征同時濾除無關信息至關重要。為了驗證我們的假設,我們在沒有回歸損失的情況下訓練了模型,我們觀察到GoPro測試集上的PSNR從31.19下降到30.56。這表明回歸損失對于有效約束引導的學習至關重要,移除該損失可能使模型等效于只是一個更大的UNet架構。
定性地,我們檢查了圖9中描繪的學習到的通道級引導特征圖。正如預期的那樣,這些特征圖與邊緣和整體結構高度相關,它們為icDPM提供了關于其清晰重建的粗粒度結構的輔助信息,并最終有益于模型的魯棒性。
5 討論
我們提出了一種用于icDPM的學習多尺度結構引導機制,它作為一種隱式偏置,增強了其去模糊的魯棒性。我們承認存在局限性,需要進一步研究。
雖然我們專注于在無需訪問大規模真實訓練數據的情況下改進模型對未見數據的泛化能力,但我們認識到訓練數據的質量和真實性最終限制了模型的能力。在我們的設置中,我們僅限于使用GoPro訓練數據集進行基準測試,該數據集沒有充分覆蓋所有真實場景,例如光線條件差的飽和區域。幾乎所有方法在去模糊此類圖像上都失敗了,示例見附錄。我們相信我們的方法可以進一步受益于大規模多樣化的訓練數據集。此外,我們工作的范圍特別針對在icDPM背景下提高去模糊的魯棒性,其中去模糊任務被表述為條件生成問題,類似的想法可以在不同的背景下探索,例如使回歸模型更魯棒。然而,由于引導模塊也使用回歸目標進行訓練,將其附加到回歸模型可能會導致參數量增加的單一模型。這種公式以及其他擴展(例如將引導插入其他最先進的回歸主干如transformers)需要進一步研究。
致謝 合著者Guido Gerig感謝紐約電信先進技術中心(CATT)的支持。
表10:引導操作的消融研究。
| Operation | PSNR |
|---|---|
| Addition | 31.139 |
| Concatenate | 30.248 |
| Adaptive norm | 29.676 |
圖9:在Realb1ur-J[67]的測試圖像上的域外去模糊結果(左),以及在尺度k=1k=1k=1(原始輸入的1/2大小)上的12個(共64個)選定的通道級引導特征圖(右)。
===== Page 8 =====
表5:使用GoPro訓練模型在Realblur-J[67]上的結果。
| Perceptual | Distortion | ||||
|---|---|---|---|---|---|
| LPIPS ↓ | NIQE ↓ | FID ↓ | KID ↓ | PSNR ↑ | |
| UNet [70] | 0.175 | 3.911 | 22.24 | 8.07 | 28.06 |
| DeblurGAN [37] | - | - | - | - | 27.97 |
| DeblurGAN-v2 [38] | 0.139 | 3.870 | 14.40 | 4.64 | 28.70 |
| MPRNet [96] | 0.153 | 3.967 | 20.25 | 7.57 | 28.70 |
| DvSR [90] | 0.153 | 3.277 | 18.73 | 6.00 | 28.02 |
| DvSR-SA [90] | 0.156 | 3.783 | 20.09 | 7.43 | 28.46 |
| Restormer [94] | 0.149 | 3.916 | 19.55 | 7.12 | 28.96 |
| UFormer-B [89] | 0.140 | 3.857 | 18.56 | 7.02 | 29.06 |
| Ours-SA | 0.139 | 3.809 | 16.84 | 6.25 | 28.81 |
| Ours | 0.123 | 2.976 | 12.95 | 3.58 | 28.56 |
表4:GoPro[57]數據集上的圖像去模糊結果。
| Perceptual | Distortion | ||||
|---|---|---|---|---|---|
| LPIPS ↓ | NIQE ↓ | FID ↓ | KID ↓ | PSNR ↑ | |
| HINet [6] | 0.088 | 4.01 | 17.91 | 8.15 | 32.77 |
| MPRNet [96] | 0.089 | 4.09 | 20.18 | 9.10 | 32.66 |
| MIMO-UNet+ [7] | 0.091 | 4.03 | 18.05 | 8.17 | 32.44 |
| SAPHNet [84] | 0.101 | 3.99 | 19.06 | 8.48 | 31.89 |
| SimpleNet [44] | 0.108 | - | - | - | 31.52 |
| DeblurGANv2 [38] | 0.117 | 3.68 | 13.40 | 4.41 | 29.08 |
| DvSR [90] | 0.059 | 3.39 | 4.04 | 0.98 | 31.66 |
| DvSR-SA [90] | 0.078 | 4.07 | 17.46 | 8.03 | 33.23 |
| UFormer [89] | 0.087 | 4.08 | 19.66 | 9.09 | 32.97 |
| Restormer [94] | 0.084 | 4.12 | 19.33 | 8.75 | 32.92 |
| Ours-SA | 0.078 | 4.10 | 8.69 | 7.06 | 33.20 |
| Ours | 0.057 | 3.27 | 3.50 | 0.77 | 31.19 |
表7:使用GoPro訓練模型在REDS[56]上的結果。
| Perceptual | Distortion | ||||
|---|---|---|---|---|---|
| LPIPS ↓ | NIQE ↓ | FID ↓ | KID ↓ | PSNR ↑ | |
| HINet [6] | 0.195 | 3.223 | 21.48 | 7.91 | 26.72 |
| DeblurGAN-v2 [38] | 0.181 | 3.172 | 14.98 | 5.12 | 27.08 |
| MPRNet [96] | 0.204 | 3.282 | 23.90 | 8.94 | 26.80 |
| Restormer [94] | 0.213 | 3.326 | 24.86 | 9.30 | 26.91 |
| UFormer-B [89] | 0.192 | 3.272 | 21.48 | 7.91 | 27.31 |
| Ours-SA | 0.178 | 3.248 | 17.27 | 6.21 | 26.95 |
| Ours | 0.147 | 2.610 | 11.91 | 3.51 | 26.36 |
表6:使用GoPro[57]訓練模型在HIDE[76]上的結果。
| Perceptual | Distortion | ||||
|---|---|---|---|---|---|
| LPIPS ↓ | NIQE ↓ | FID ↓ | KID ↓ | PSNR ↑ | |
| HINet [6] | 0.088 | 4.01 | 17.91 | 8.15 | 32.77 |
| MPRNet [96] | 0.089 | 4.09 | 20.18 | 9.10 | 32.66 |
| MIMO-UNet+ [7] | 0.091 | 4.03 | 18.05 | 8.17 | 32.44 |
| SAPHNet [84] | 0.101 | 3.99 | 19.06 | 8.48 | 31.89 |
| SimpleNet [44] | 0.108 | - | - | - | 31.52 |
| DeblurGANv2 [38] | 0.117 | 3.68 | 13.40 | 4.41 | 29.08 |
| DvSR [90] | 0.059 | 3.39 | 4.04 | 0.98 | 31.66 |
| DvSR-SA [90] | 0.078 | 4.07 | 17.46 | 8.03 | 33.23 |
| UFormer [89] | 0.087 | 4.08 | 19.66 | 9.09 | 32.97 |
| Restormer [94] | 0.084 | 4.12 | 19.33 | 8.75 | 32.92 |
| Ours-SA | 0.078 | 4.10 | 8.69 | 7.06 | 33.20 |
| Ours | 0.057 | 3.27 | 3.50 | 0.77 | 31.19 |
表8:在Realblur-J[67]數據集上使用GoPro[57]訓練模型的人類受試者感知研究。每個值代表評分者更喜歡行模型而不是列模型的次數比例。
| DGANv2 | UFormer | DvSR | icDPM | Ours-SA | Ours | |
|---|---|---|---|---|---|---|
| DGANv2 | - | 0.28 | 0.43 | 0.56 | 0.26 | 0.17 |
| UFormer | 0.72 | - | 0.53 | 0.58 | 0.44 | 0.35 |
| DvSR | 0.57 | 0.47 | - | 0.61 | 0.32 | 0.29 |
| icDPM | 0.44 | 0.45 | 0.39 | - | 0.28 | 0.23 |
| Ours-SA | 0.74 | 0.56 | 0.68 | 0.72 | - | 0.38 |
| Ours | 0.83 | 0.65 | 0.71 | 0.79 | 0.62 | - |
圖8:REDS[56]去模糊示例,來自HINet [6], DeblurGAN-v2 [38], 不帶引導的icDPM和Ours(帶引導的icDPM)。當僅在GoPro[57]上訓練時,我們的方法更好地從輸入圖像中去除模糊痕跡,同時在應用于未見數據時消除偽影。
附錄部分(A-C)主要為圖表、詳細實現細節、額外消融實驗和失敗案例分析,翻譯核心內容如下:
- A. 附加結果: 包含更多失真-感知圖(圖10)和大量視覺對比示例(圖13-32),展示了在GoPro(域內)、HIDE、REDS、Realblur-J(域外)數據集上不同方法的去模糊效果,以及模型在低光/強光等困難場景下的失敗案例(圖29-32)。
- B. 附加消融:
- 輸入連接 (表11): 實驗表明移除輸入級連接會嚴重損害性能(PSNR和LPIPS下降),因此最終模型保留了輸入連接。
- 跨域對齊 (圖11): 嘗試在引導特征上使用對抗損失進行域適應(對齊GoPro和Realblur-J的特征分布)反而降低了性能,推測可能是GAN訓練不穩定或公式不理想所致。
- C. 附加實現細節:
- 架構 (圖12): 詳細展示了擴散網絡(基于[90]的全卷積UNet)和引導網絡的結構,以及如何將引導特征注入UNet編碼器的殘差塊(Guided Block)。
- 推理 (表12): 描述了采樣參數的網格搜索(擴散步數T和最大噪聲方差1-αT)。
- 計算成本 (表13): 報告了不同模型配置在720x1280x3輸入下的FLOPs(單擴散步)。
- 基準結果: 說明了如何獲得對比方法的結果(使用作者提供的代碼和預訓練模型)。
參考文獻列表 (Pages 10-14)
[1] Jeremy Anger, Mauricio Delbracio, and Gabriele Facciolo. Efficient blind deblurring under high noise levels. In 2019 11th International Symposium on Image and Signal Processing and Analysis (ISPA), pages 123-128. IEEE, 2019.
[2] Arpit Bansal, Eitan Borgnia, Hong-Min Chu, Jie S Li, Hamid Kazemi, Furong Huang, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Cold diffusion: Inverting arbitrary image transforms without noise. arXiv preprint arXiv:2208.09392, 2022.
… (參考文獻列表過長,此處省略,保留原文格式)
結論 (Page 26, 29 - 文本層標識,無實質結論文本)
圖19: HIDE[76]去模糊示例,來自MPRNet [96], MIMO UNet+ [7], SAPHNet [84], Restormer [94], UFormer [89], DvSR [90]和Ours。
圖22: GoPro [57]去模糊示例,來自MPRNet [96], MIMO UNet+ [7], SAPHNet [84], Restormer [94], UFormer [89], DySR [90]和Ours。
圖24: GoPro [57]去模糊示例,來自MPRNet [96], MIMO UNet+ [7], SAPHNet [84], Restormer [94], UFormer [89], DvSR [90]和Ours。
(附錄中的圖25-28為Realblur-J結果,圖29-32為失敗案例)


:使用云平臺最小外部依賴方案)







服務器/多客戶端模型)


——設備樹(上))
)



)
