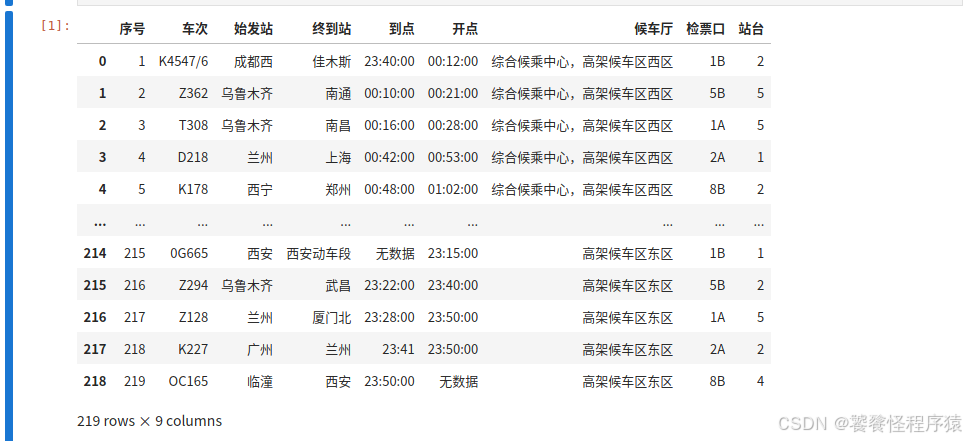
Step1、讀取數據
import pandas as pd
import requests
import re
import json
from tqdm import tqdm# 讀取數據
data = pd.read_excel('data/info_table.xlsx')
data = data.fillna('無數據')
data
Step2、注冊硅基流動
https://cloud.siliconflow.cn
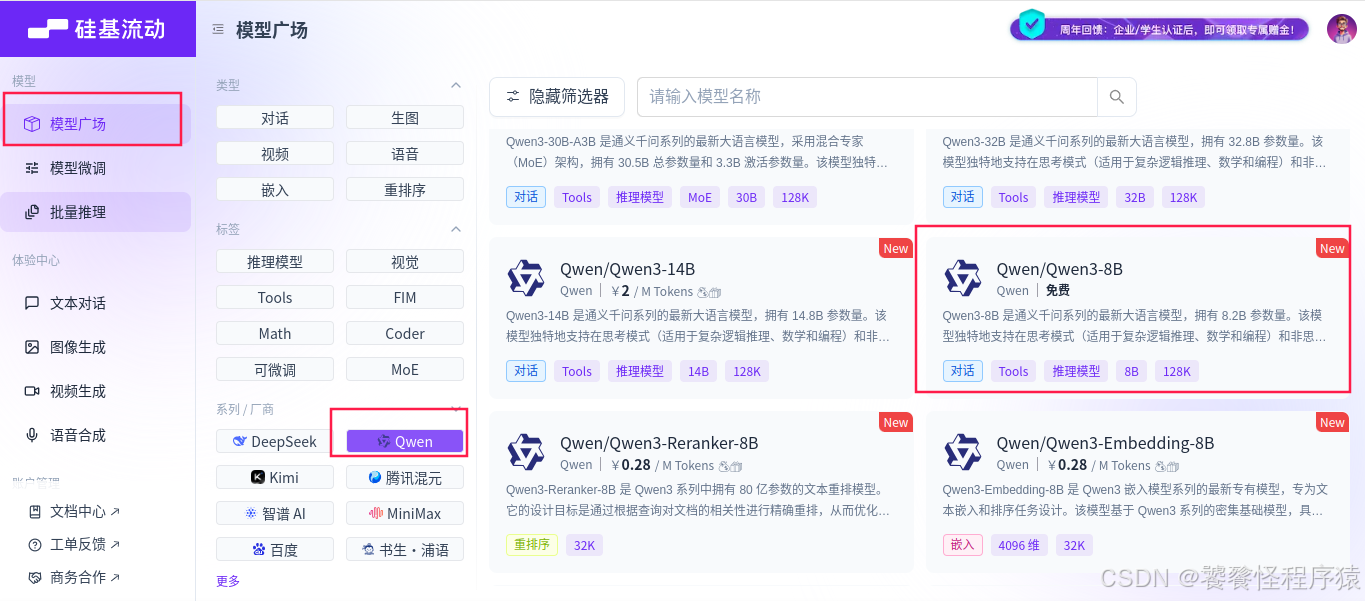
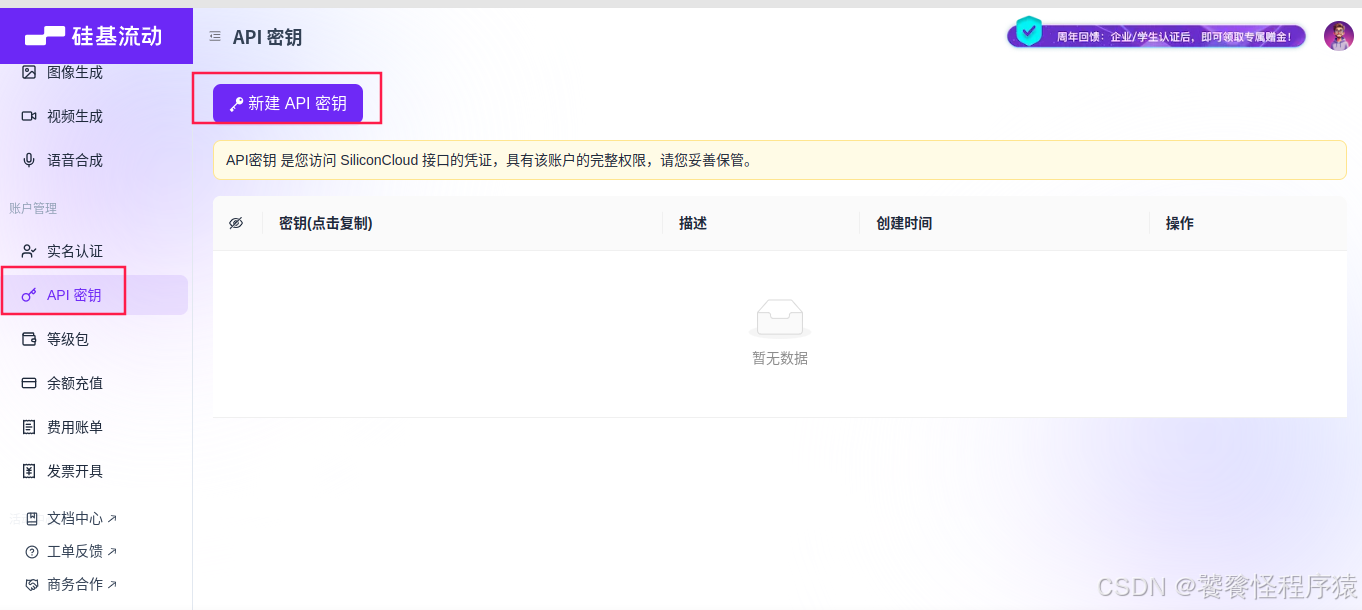
Qwen/Qwen3-8B 模型可以免費使用,接下來申請 API KEY:
Step3、封裝LLM API請求
把 key 復制下來,替代 baseline 中的代碼:
def call_llm(content: str):"""調用大模型Args:content: 模型對話文本Returns:list: 問答對列表"""# 調用大模型(硅基流動免費模型,推薦學習者自己申請)url = "https://api.siliconflow.cn/v1/chat/completions"payload = {"model": "Qwen/Qwen3-8B","messages": [{"role": "user","content": content # 最終提示詞,"/no_think"是關閉了qwen3的思考}]}headers = {"Authorization": "Bearer sk-***","Content-Type": "application/json"}resp = requests.request("POST", url, json=payload, headers=headers).json()# 使用正則提取大模型返回的jsoncontent = resp['choices'][0]['message']['content'].split('</think>')[-1]pattern = re.compile(r'^```json\s*([\s\S]*?)```$', re.IGNORECASE) # 匹配 ```json 開頭和 ```結尾之間的內容(忽略大小寫)match = pattern.match(content.strip()) # 去除首尾空白后匹配if match:json_str = match.group(1).strip() # 提取JSON字符串并去除首尾空白data = json.loads(json_str)return dataelse:return contentreturn response['choices'][0]['message']['content']
該方法用于調用 qwen3 模型并返回 JSON 數據。
Step4、構建問題列表
def create_question_list(row: dict):"""根據一行數創建問題列表Args:row: 一行數據的字典形式Returns:list: 問題列表"""question_list = []# ----------- 添加問題列表數據 begin ----------- ## 檢票口question_list.append(f'{row["車次"]}號車次應該從哪個檢票口檢票?')# 站臺question_list.append(f'{row["車次"]}號車次應該從哪個站臺上車?')# 目的地question_list.append(f'{row["車次"]}次列車的終到站是哪里?')# ----------- 添加問題列表數據 end ----------- #return question_list
使用訓練集數據構建問題列表。
Step5、執行模型蒸餾
# 簡單問題的prompt
prompt = '''你是列車的乘務員,請你基于給定的列車班次信息回答用戶的問題。
# 列車班次信息
{}# 用戶問題列表
{}'''
output_format = '''# 輸出格式
按json格式輸出,且只需要輸出一個json即可
```json
[{"q": "用戶問題","a": "問題答案"
},
...
]
```'''train_data_list = []
error_data_list = []
# 提取列
cols = data.columns
# 遍歷數據(baseline先10條數據)
i = 1
for idx, row in tqdm(data.iterrows(), desc='遍歷生成答案', total=len(data)):try:# 組裝數據row = dict(row)row['到點'] = str(row['到點'])row['開點'] = str(row['開點'])# 創建問題對question_list = create_question_list(row)# 大模型生成答案llm_result = call_llm(prompt.format(row, question_list) + output_format)# 總結結果train_data_list += llm_resultexcept:error_data_list.append(row)continue
Step6、蒸餾數據集保存
# 轉換訓練集
data_list = []
for data in tqdm(train_data_list, total=len(train_data_list)):if isinstance(data, str):continuedata_list.append({'instruction': data['q'], 'output': data['a']})json.dump(data_list, open('single_row.json', 'w', encoding='utf-8'), ensure_ascii=False)
data_list[:2]
此時single_row.json就可以用于模型微調。

參考資料
- https://www.datawhale.cn/activity/351/learn/198/4422
- https://docs.siliconflow.cn/cn/api-reference/chat-completions/chat-completions



Day10)


——聯合體)
![[python][flask]Flask-Login 使用詳解](http://pic.xiahunao.cn/[python][flask]Flask-Login 使用詳解)


)

)




)

