在之前的博客中,我們已經探討了進程創建、終止和等待的相關知識。今天,我們將繼續深入學習進程控制中的另一個重要概念——進程替換。
回顧之前的代碼示例,我們使用fork()創建子進程時,子進程會復制父進程的代碼和數據(寫入時觸發寫時拷貝機制),然后父子進程各自執行不同的代碼段。這種機制可能還不太直觀,在網絡編程部分我們會進一步體會其實際應用場景——父進程負責監聽客戶端請求,子進程則處理具體請求。這個內容我們將在后續博客中詳細討論。
今天我們重點介紹的是:在fork()創建子進程后,子進程通過調用exec函數來執行另一個程序。當exec函數被調用時,該進程的用戶空間代碼和數據會被新程序完全替換,并從新程序的啟動例程開始執行。這就是所謂的進程替換機制。
單進程版本
![]()
![]()
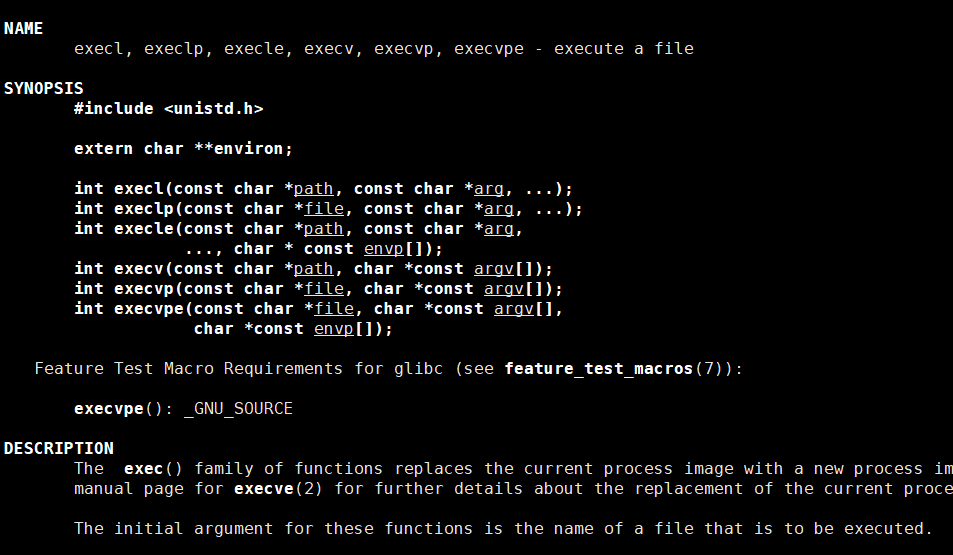
在這幾個系統調用接口中函數參數列表中的三個點(...)表示可變參數,允許函數接受不確定數量的參數。這種機制通常用于需要處理不同數量輸入的函數,我們可以類比scanf和printf理解一下?
現在我們就來使用一下這些函數,看看這些函數的功能以及使用規則。
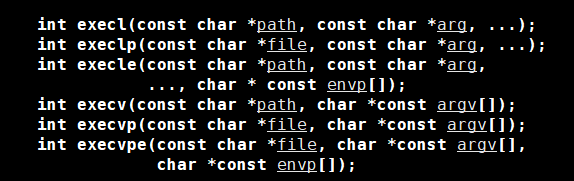
#include <unistd.h>int execl(const char *path, const char *arg0, ..., (char *) NULL);- path:要執行的可執行文件的路徑。
- arg0:程序的名稱(通常是?
argv[0])。 - ...:可變參數列表,表示程序的命令行參數,以?
NULL?結尾。
返回值
- 成功時,
execl?不會返回,因為原進程的代碼已被替換。 - 失敗時,返回?
-1,并設置?errno?以指示錯誤類型。
注意事項
execl?的參數列表必須以?NULL?結尾,否則可能導致未定義行為。- 如果?
path?不是有效的可執行文件路徑,execl?會失敗。 - 調用?
execl?后,原進程的所有代碼(包括?execl?之后的代碼)都不會執行。
#include <iostream>
#include <unistd.h>int main()
{printf("before : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());return 0;
}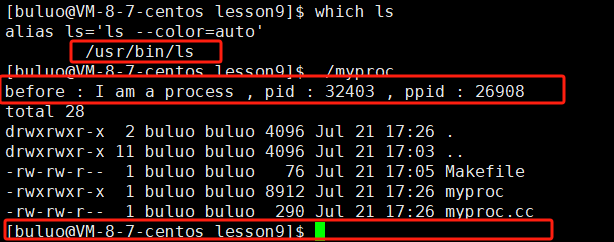
可以看到當我們將我們寫的程序運行之后,系統中自帶的命令ls被調用了,并且我們程序中的第二條printf語句并沒有被執行,看到了這個現象,相信大家對進程替換有了一個初步的雛形,現在我們在來談一談進程替換的原理。
進程替換的原理
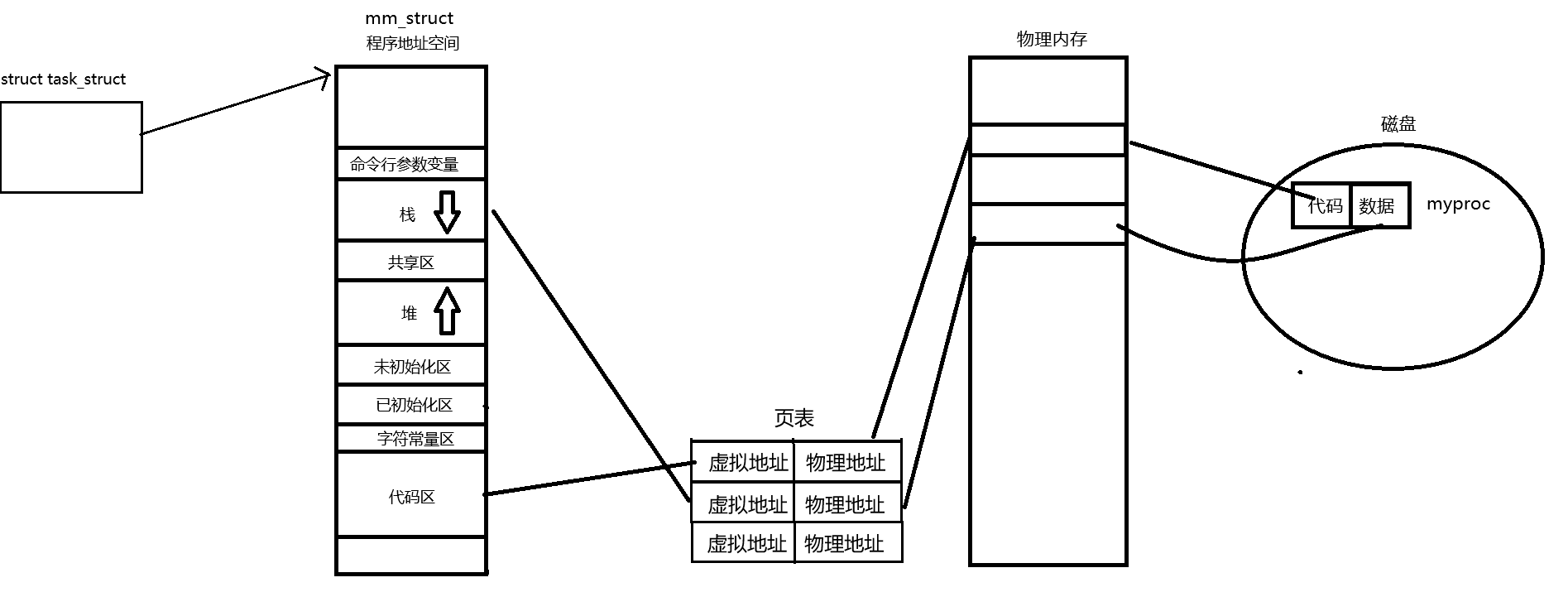
當我們啟動一個程序時,操作系統首先會為其創建一個新的進程。內核會分配一個 task_struct來保存進程的基本信息,同時創建一個 mm_struct 結構來描述該進程的虛擬內存空間。隨后,系統會將程序的代碼段、數據段等通過頁表映射加載到內存中,實現從虛擬地址到物理地址的轉換。?
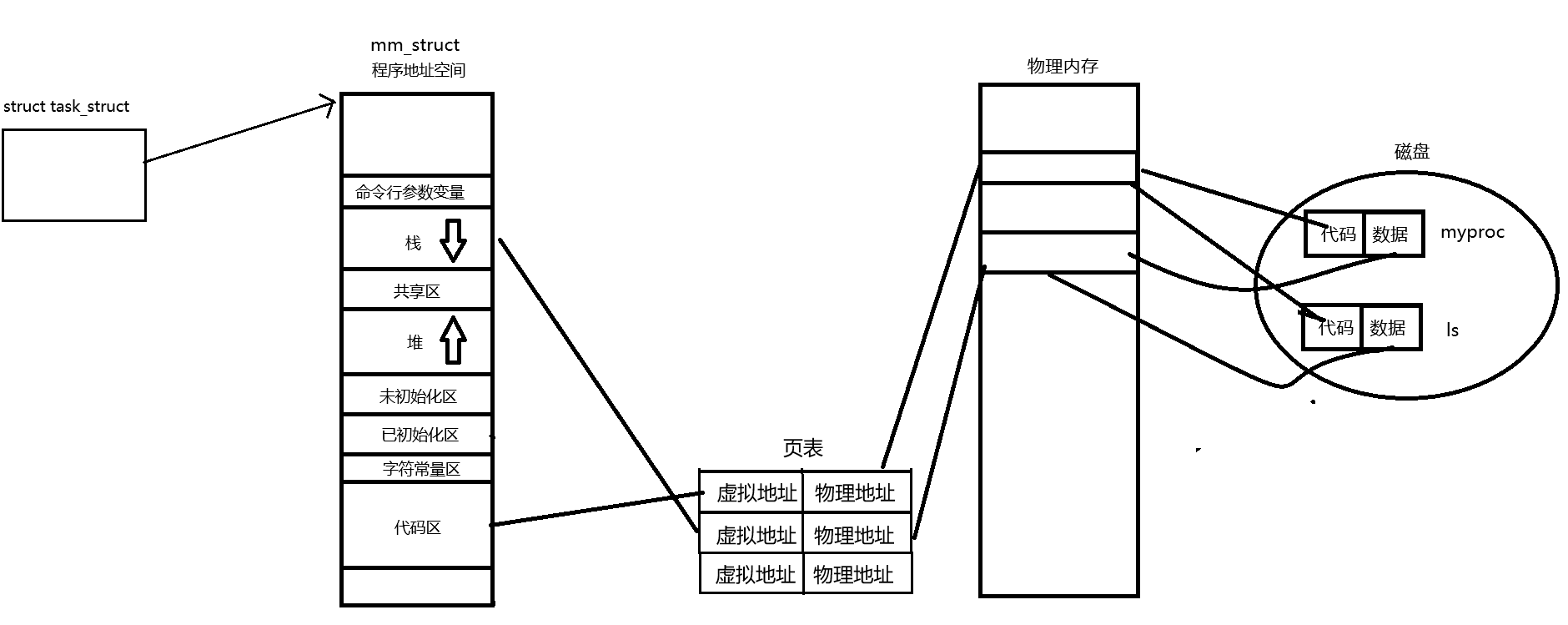
而當我們執行exec*系列的函數時,我們的進程就非常簡單粗暴的將自己的代碼和數據全部替換為ls的代碼和數據,然后通過頁表重新映射,這樣就替換成功,然后從新程序的入口地址重新開始執行,所以從始至終,我們并沒有創建新的進程,而是將原來的進程的代碼和數據進行了修改,這就是進程替換的原理。接下來讓我們看看多進程版本的程序替換。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}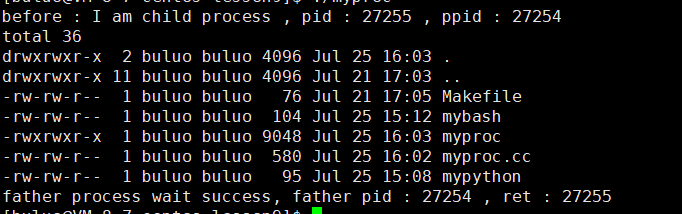
通過執行這段代碼,我們可以明顯看到,我們創建了一個子進程,然后讓子進程進行程序替換,然后父進程等待并回收子進程,通過現象我們目前可以看到這些,但是我相信大家可能會有這樣的疑問,我們之前單進程進行程序替換的時候我知道,他直接就將代碼和數據替換了,但是現在,我們將子進程的代碼和數據替換之后,會不會對父進程的代碼和數據有影響呢?
答案是當然不會了,因為進程是具有獨立性的,雖然子進程是父進程創建的,但是子進程的改變是不會影響父進程的,因為我們有寫時拷貝技術,所以父進程是不會受到影響的。
那么還有人會說,有寫時拷貝技術沒有錯,但是父子進程在寫入的時候,不是數據發生寫時拷貝,而代碼不是不可被寫入嗎,那么怎么替換呢?沒有錯,代碼是不可寫入的,但是我們這里使用的是操作系統的接口呀,作為用戶你是沒有能力對代碼進行寫入的,但是一旦我們使用了操作系統的接口,那么一旦發生程序替換,我們的操作系統也會對代碼進行寫時拷貝,所以這就好比原則上我們不可以,但是現在原則就在這里。開個玩笑,所以操作系統是可以讓代碼也進行寫時拷貝,從而進行進程替換。?
現在我們在來補充一下幾個小問題:
????????為什么當我們執行exec*系列函數之后的代碼就不執行了呢?這就是因為在調用exec*函數之前,我們的代碼還是正常執行,當我們執行exec*函數之后,進程的代碼數據就被替換了,所以原來的代碼和數據就找不到了,因此之后的代碼就不會被執行了,這就好比你和你女朋友在熱戀的時候,曾經許下了海誓山盟的承諾,說我將來要給你什么什么樣的生活等等,但是不到幾個月,你小子就執行了exec*函數(變心了),那么這些承諾你也就不遵守了,就好比那句話,愛的承諾只有在相愛的時候才有意義,差不多就是這個意思。
? ? ? ? 當我們程序替換了之后,我們是如何找到程序的入口地址的呢?雖然執行exec*函數之后進程的代碼和數據都被替換了,但是CPU是如何找到這個新的程序的入口地址的呢?這個問題的答案就是其實在Linux中形成的可執行程序是有格式的,叫做ELF,其中就有可執行程序的表頭,可執行程序的入口地址就在表中,所以我們就可以通過這個表頭文件找到新程序的入口地址,這樣我們就可以執行新的程序了。
好了,了解了這么多進程替換的原理,現在我們就來驗證一下各個程序替換的接口,讓我們直觀感受一下。
多進程版本-驗證各個程序替換的接口
![]()
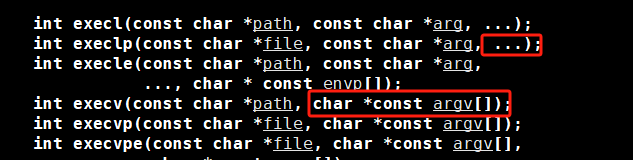
首先我們得所有得程序替換的接口都是exec開頭的,而這個execl,l就代表list,意思就是我們在傳參的時候,我們的參數從第二個開始是一個一個的將其傳遞給這個函數,就向列表一樣,就和我們在命令行進行傳參是一樣的效果。而我們的第一個參數就是這個程序的地址,因為我們要執行一個程序,總得找到這個程序在哪,不然連位置到找不到,這還怎么執行。所以,在所有的exec*系列的函數的第一個參數都是執行程序的地址。而我們后面所填的參數目的就是在找到這個程序之后,如何執行這個程序,執行這個程序時,要涵蓋哪些選項。反正就是在命令行怎么寫,在這個函數中就怎么寫。
現在我們再來看看第二個接口函數execlp,我們可以看待這個函數帶了p,而這個p就是path,就是我們之前博客中提到的PATH環境變量,那么該函數就會在執行時會自己默認去PATH路徑中查找該程序,所以我們只需要指明文件名就可以了。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execlp("ls", "ls", "-a", "-l", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}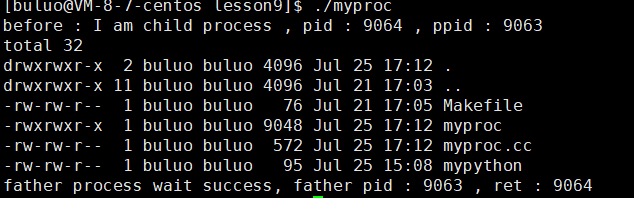
可以看到我們不需要指明路徑,程序也可以正確執行。
現在我們再來看看execv這個接口函數,這個v就相當于vector,沒有帶p所以要帶全路徑,而我們的第二個參數我們可以看到并不是可變參數列表了,而成為了字符指針數組,說白了就是將我們命令行中的參數放入到字符指針數組中,然后將這個字符指針數組作為參數交給這個函數即可。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{char *const myargv[] = {"ls","-a","-l",NULL};pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execv("/usr/bin/ls", myargv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}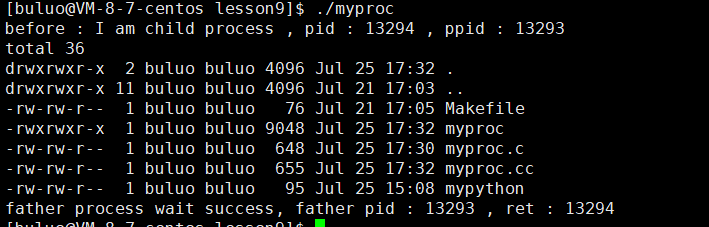
所以我們在執行ls時,會將我們自己寫的字符指針數組傳遞給ls程序的main函數?,這樣ls命令就可以執行了。
下面我們再來看看execvp函數,通過上面的講解,相信大家就明白這個函數該如何調用了,這里就不過多介紹,execvp第一個參數直接寫文件名就可以,操作系統會在PATH環境變量中尋找該函數的路徑,第二個則是字符指針數組,將我們需要的參數填入其中就可以了。
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execvp("ls", myargv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}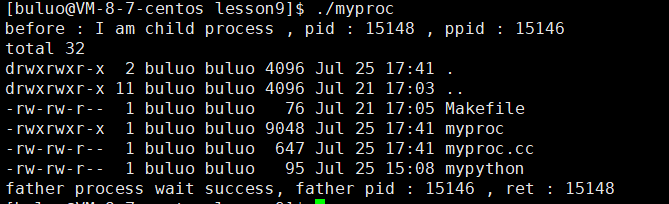
看了這么多函數的調用,我相信大家現在就有一個問題就是怎么都執行的系統的命令,我要執行一個我自己寫的程序該怎么操作。現在,我們就來替換為我們自己寫的程序來看看。?
myproc.cc
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
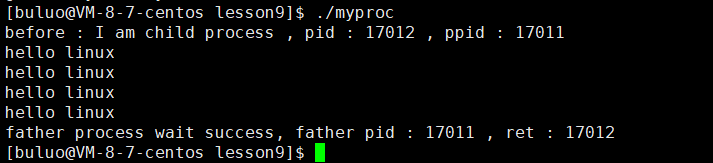
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("./mytest", "mytest", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}mytest.cc?
#include<iostream>int main()
{std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl;std::cout<<"hello linux"<<std::endl; return 0;
}?
![]() ?
?
可以看到通過上面的代碼我們將我們自己寫的程序執行起來了,但是細心的同學可能發現了,你的execl中第一個寫的路徑時當前路徑我知道,但是第二個參數為什么是這樣寫呢,你又沒有將當前路徑加到PATH環境變量中去,你執行的時候不應該是"./mytest"么,你是不是在胡扯呢?我相信同學看到都會有這樣的疑問,但是我想說的是你說的很對,確實我們在命令行執行時需要加"./mytest",但是我們為什么要加"./mytest"呢?那是因為我們如果不加,我們就找不到我們程序所在位置,所以我們需要加,但是這里為什么不加呢?這時因為我們在調用execl函數時,他的第一個參數已經告訴了我們的操作系統這個函數在哪里,所以我們在這里可以不加,當然了,我們加上也是可以了,沒有什么影響。
那么現在我們已經可以替換為我們自己寫的程序了,我們可以再調用其他解釋性語言,或者一些腳本語言呢?讓我們來試一試。
用其他語言編寫的程序進行替換
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/bash", "bash", "test.sh", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}
#! /usr/bin/bashfunction myfun()
{cnt=1while [ $cnt -le 10 ]doecho "hello $cnt"let cnt++done
}myfun?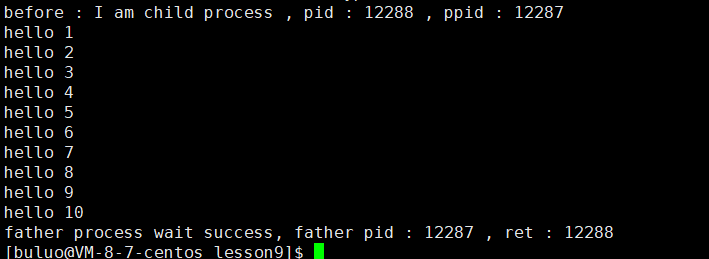
?
if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("/usr/bin/python3", "python", "test.py", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}
#! /usr/bin/python3def func():for i in range(0,10):print("hello " + str(i))func()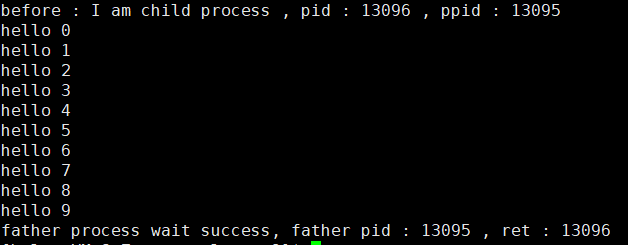 ?
?
所以我們的進程替換不僅僅可以調用系統命令,還可以調用我們自己寫的程序,還可以進行跨語言的調用,這歸根結底還是因為所有的語言都是一個工具而已,在執行的時候,本質都是進程!只要是進程,我們就可以通過操作系統提供的接口被我們操作,所以只要我們的程序是在操作系統時使用,再高級的語言執行起來都是一個進程。?
了解了這么多,我們再來看看最后兩個接口函數execle和execvpe,這兩個函數接口中都有e,那么這個e代表什么呢?這個e就是我們的env(environment)環境變量,我們看看我們如何將父進程的設置的環境變量交給替換進程呢?我們先來看看不傳之前能不能接收到環境變量?
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execl("./mytest", "mytest", "-a", "-b", "-c", NULL);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}?
#include <iostream>int main(int argc, char *argv[], char *env[])
{std::cout << "這是命令行參數!" << std::endl;std::cout << "begin!!!!!!!!!!!!" << std::endl;for (int i = 0; i < argc; i++){std::cout << i << " : " << argv[i] << std::endl;}std::cout << "這是環境變量!" << std::endl;for (int i = 0; env[i]; i++){std::cout << i << " : " << env[i] << std::endl;}std::cout << "end!!!!!!!!!!!!!!" << std::endl;return 0;
}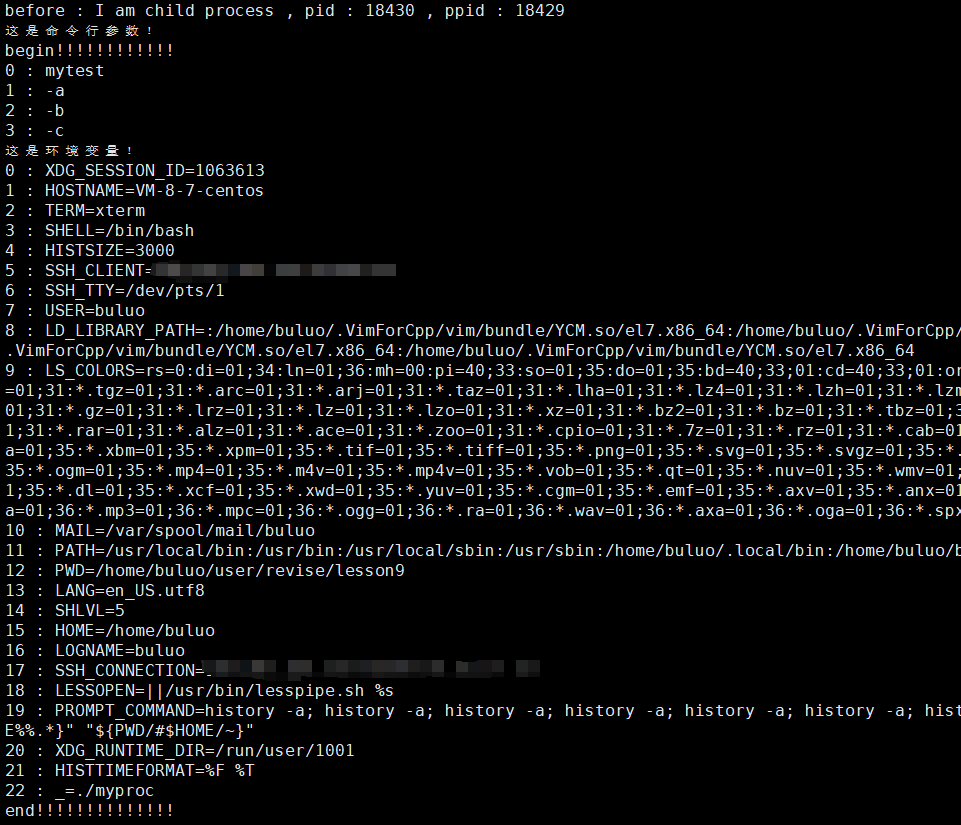
我們可以看到我們使用的是execl接口,并沒有傳入環境變量,但是替換的進程依舊拿到了,這是為什么呢?環境變量又是什么時候給進程的?
環境變量也是數據,在我們的程序地址空間中的棧區上方就是我們的環境變量,所以在創建子進程的時候,環境變量就已經被子進程繼承下去了!所以我們不傳也可以拿到環境變量的信息。那么這兩個接口的功能是干什么的呢?我都能拿到環境變量了,還要你們干什么。
其實這兩個接口函數的功能就是為了新增一些環境變量或者將這個環境變量徹底全部替換
我們來看看如何新增環境變量,我們可以通過接口函數putenv就可以實現,現在我們進行實現一下看看。
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>int main()
{extern char **environ;putenv("buluo=66666");pid_t id = fork();if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execle("./mytest", "mytest", "-a", "-b", "-c", NULL, environ);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}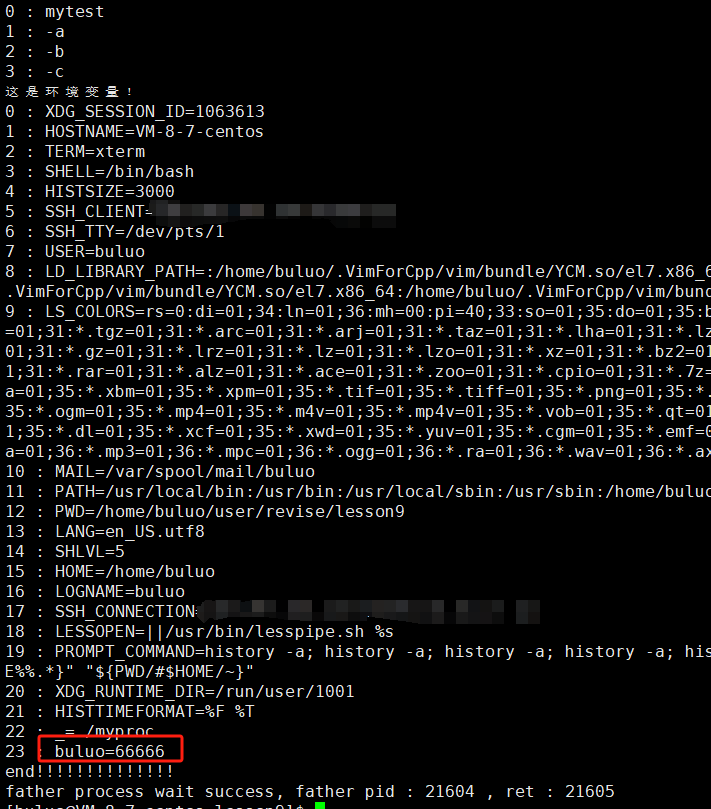
這樣,我們替換進程后也可以拿到父進程中新增的環境變量。
自定義環境變量
int main()
{extern char **environ;putenv("buluo=66666");pid_t id = fork();char *const myenv[]={"MYVAL=66666","TEST=380",NULL};if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execle("./mytest", "mytest", "-a", "-b", "-c", NULL, myenv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}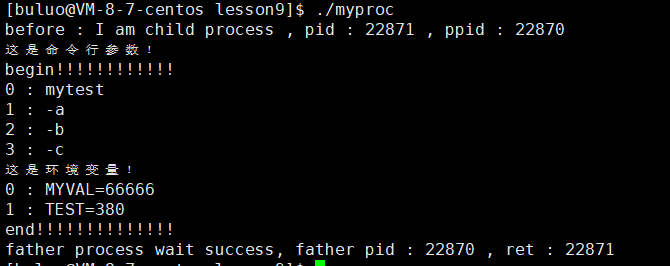 ?
?
這樣就可以自定義環境變量了。?
?而最后一個函數execve也就是類似的功能,我們也用代碼模擬一下即可
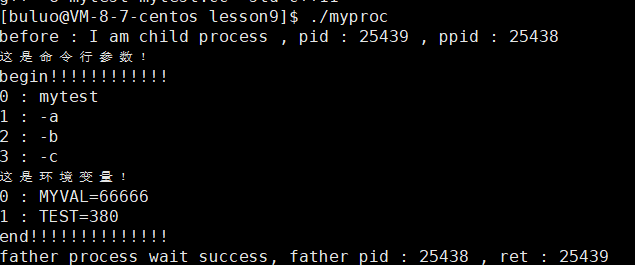
int main()
{extern char **environ;putenv("buluo=66666");pid_t id = fork();char *const myargv[] = {"mytest", "-a", "-b", "-c", NULL};char *const myenv[] = {"MYVAL=66666","TEST=380",NULL};if (id == 0){printf("before : I am child process , pid : %d , ppid : %d \n", getpid(), getppid());execve("./mytest", myargv, myenv);printf("after : I am a process , pid : %d , ppid : %d \n", getpid(), getppid());exit(1);}pid_t ret = waitpid(id, NULL, 0);if (ret > 0){printf("father process wait success, father pid : %d , ret : %d \n", getpid(), ret);}return 0;
}
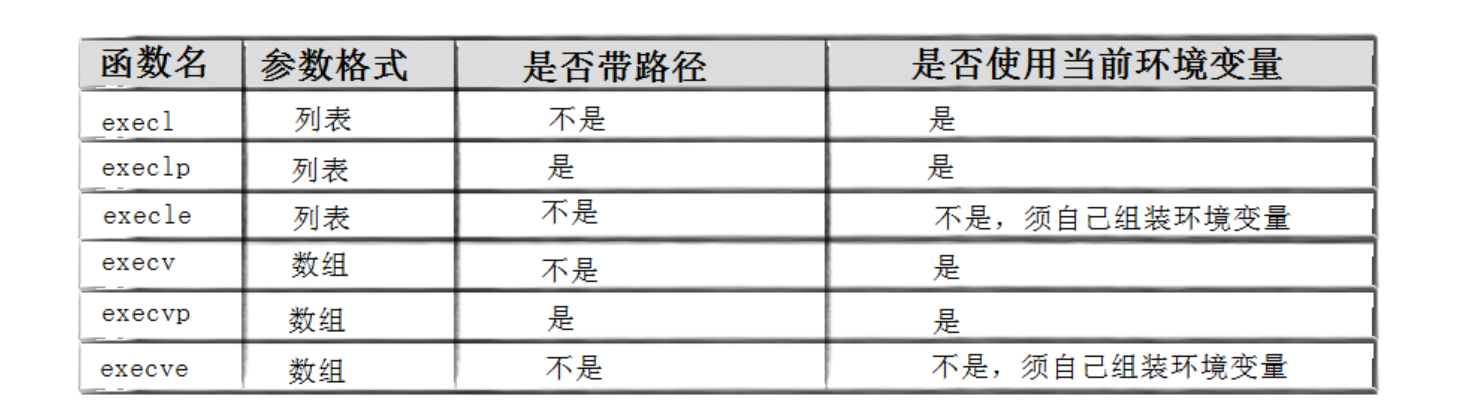
命名理解?
- l(list) : 表示參數采用列表
- v(vector) : 參數用數組
- p(path) : 有p自動搜索環境變量PATH
- e(env) : 表示自己維護環境變量
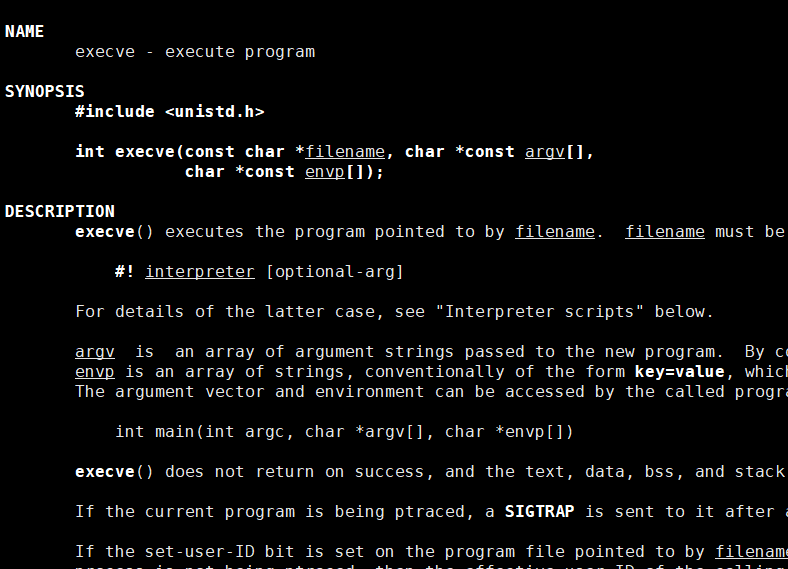
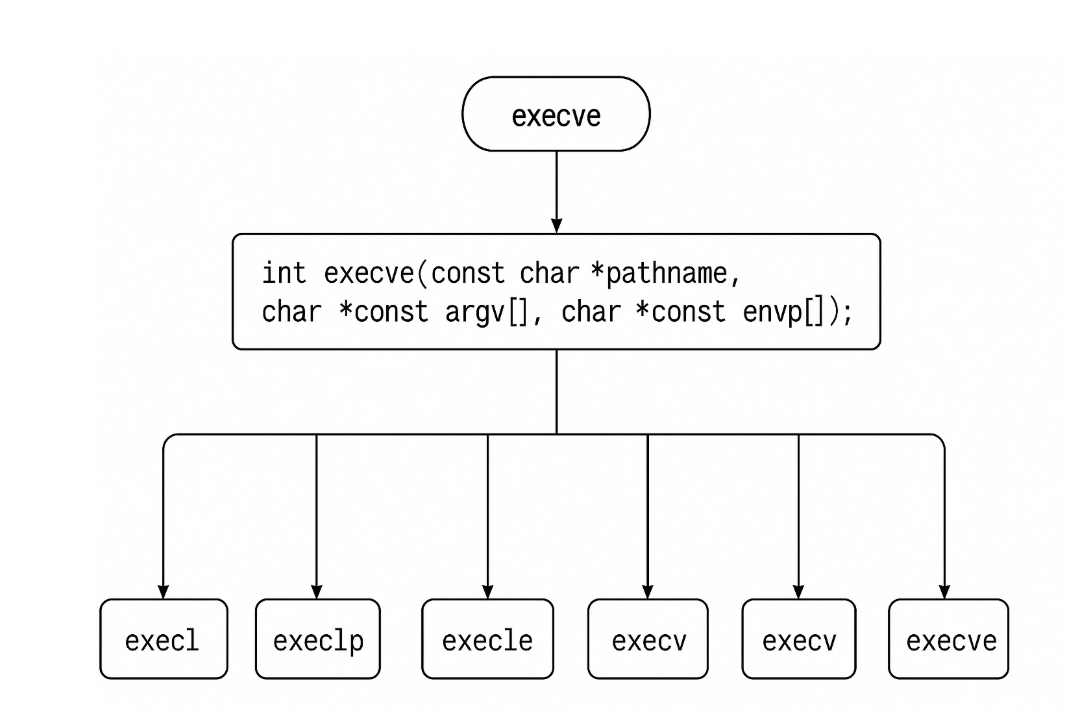
事實上,只有execve是真正的系統調用,其它六個函數最終都調用 execve?
 ?
?
這就是進程替換,希望對大家理解進程的控制有一定的幫助!!!!!!
?



)

)









---層序遍歷二叉樹)
)

對北半球光伏數據進行時間序列預測)
