一、多線程
1.基本概念
(1)程序(Program):
為了完成特定的任務,用某種計算機語言編寫的一組指令的集合,即指一段靜態的代碼(源代碼經編譯之后形成的二進制格式的文件),靜態對象。
(2)進程(Process):
程序的一次執行的過程,或正在執行的程序,是一個動態的過程,有它自身的產生,存在和消亡過程(生命周期)。
進程作為資源分配的單位,系統在運行的時候會為每個進程分配不同的內存區域。
(3)線程(Thread):
進程可以進一步劃分為線程,線程是程序內部一條執行路徑,如果一個進程同時并行的執行了多個線程,就是支持多線程的。線程作為調用和執行的單位,每個線程擁有獨立的運行棧和程序計數器(PC),進程也可以是多進程的程序,但是多進程之間的切換會有很大的開銷,線程相對于進程來說切換的開銷要小很多。所以,很多時候我們不去設計多進程的程序反而設計成多線程的程序。一個進程中的多個線程可以共享相同的內存單元,它們從同一個堆中分配對象,也可以訪問相同的變量和對象,這使得線程之間通訊更簡便,高效,但是多個線程共享資源的時候可能會有線程安全問題。
(4)單核 CPU 和多核 CPU 的理解
① 單核 CPU:其實是一個假的多線程,這時候多個線程輪流使用 CPU,我們將這個使用 CPU 的過程稱為“時間片”,當輪流使用 CPU 切換的速度極其快的時候,就像是有多個任務在并行執行。
② 如果是多核 CPU 的話,那么可以做到真正的并行,即不同的線程享受不同的 CPU 內核(現在的服務器都是多核的)
③ 并行和并發
a.并行:多個 CPU 同時執行多個任務,例如多個人同時做不同的事情
b.并發:一個 CPU(利用時間片)同時執行多個任務,比如:多個人同時做同一件事情。
(5)使用多線程的優點:
① 提高響應的速度,比如圖形界面,可以增強用戶的體驗度(異步模式)。
② 提高計算機系統的 CPU 的利用率。
③ 改善程序結構,將即長又復雜的進程代碼分割成多個線程代碼(不能過多),獨立運行,利于理解和修改。
(6)什么時候應該使用多線程
① 程序需要同時執行兩個或多個任務時
② 程序需要實現一些需要等待的任務時,例如輸入,文件讀寫(比較耗時的操作)
③ 網絡操作,搜索操作等
④ 需要在后臺運行的程序
(7)創建線程的方式,有兩種:
① 通過繼承 java.lang.Thread 類來完成
② 通過實現 Runnable 接口來完成? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
步驟:
a. 定義類繼承 Thread 類,并重寫 run() 方法,其中 run() 方法就是線程的執行體,注意:run() 方法是由虛擬機自動調用的線程執行體方法,不是程序員自己調用的,如果程序員自己去調用 run() 方法,那么線程就失去意義了,run() 是在當前線程獲得 CPU “時間片”的時候由 JVM 自動調用。
示例:
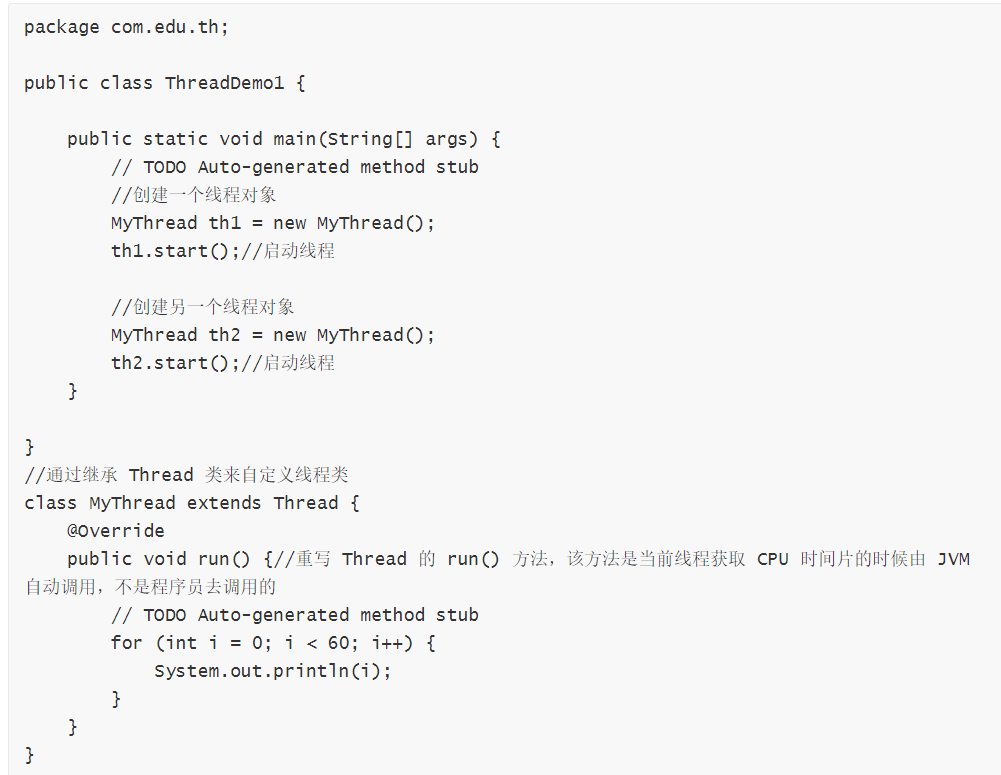

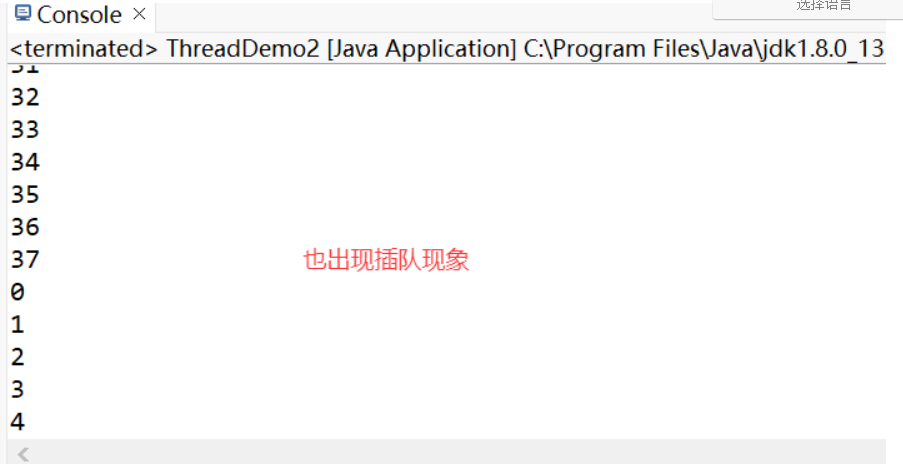
從結果可知,其中一個線程打印到30的時候,它的 CPU 的“時間片”結束了,另一個線程獲取到了 CPU 時間片然后打印,這里出現了插隊的現象。
2)Thread類的構造器
public Thread():創建一個新的Thread對象
public Thread(String name):創建一個線程并指定名稱
public Thread(Runnable target):通過傳遞一個 Runnable 的實現類對象來創建一個線程對象
public Thread(Runnable target, String name):通過一個Runnable接口的實現類對象來創建一個線程對象,并且指定線程名稱。
示例:

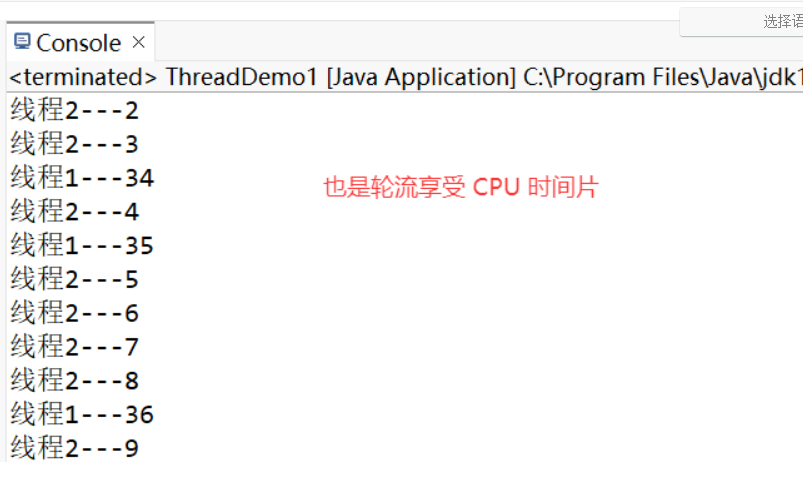
注意:Thread 的 start() 調用一次之后就不能再調用,否則會拋出 IllegalThreadStateException 異常:
3)通過實現 Runnable 接口創建線程
由于 Java 是單繼承,如果繼承 Thread 來創建線程,那么這個線程類就不能再繼承其他類,但如果是實現Runnable 接口來創建線程,那么線程類還可以繼承其他類
步驟:
a. 定義一個實現 Runnable 接口的類,并覆蓋 run() 方法,run() 方法就是線程的執行體
b. 將 Runnable 接口的實現類對象傳遞給 Thread 類的構造器,創建線程對象
c. 通過線程對象的 start() 方法啟動線程
示例:

?
void start():啟動線程,注意,如果已經調用了start(),再次調用start()方法會拋 IllegalThreadStateException。
public void run():線程被調用時執行的方法
String getName():獲取線程的名稱
void setName(String name):設置線程的名稱
static Thread currentThread():返回當前線程的實例,在 Thread 類中就是指 this。
static void yield():線程讓步,暫停當前正在執行的線程,把執行機會讓給優先級相同或較高的線程,若線程隊列中沒有同優先級的線程,則忽略該方法。
join():當某個線程執行流程中調用其他線程的 join 方法時,調用線程(當前線程)將被阻塞,直到 join() 方法加入的其他線程執行完為止。
示例:
package com.edu.th;
public class ThreadDemo3 {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
//每個 main 方法就是一個main 主線程,在 main 方法中創建的其他線程就是子線程
Thread thread = Thread.currentThread();//獲取當前線程
System.out.println(thread);
SumThread st = new SumThread();
st.start();//啟動子線程,完成計算
//如果不加上st.join(),那么主線程main 執行完了可能子線程都還沒執行,得到的結果就不正確
try {
st.join();//調用子線程的 join 方法,那么主線程 main 就會在這里阻塞,直到子線程 st 執行完,主線程才能繼續往下執行
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(st.getSum());
}
}
class SumThread extends Thread {
int sum = 0;
@Override
public void run() {
// TODO Auto-generated method stub
for (int i = 1; i <= 100; i++) {
sum += i;
}
}
public int getSum() {
return sum;
}
}

static void sleep(long millis):休眠多少毫秒,讓當前活動的線程在指定時間段內放棄使用CPU,使其他線程有機會獲得CPU來執行,時間到后重新到線程隊列中排隊等待執行。

stop():強制結束線程,不推薦使用
boolean isAlive():判斷線程是否活躍(run)
(8)多線程的內存圖解
多線程執行時,到底在內存中是如何運行的呢?
多線程執行時,在棧內存中,其實每一個執行線程都有一片自己所屬的棧內存空間。進行方法的壓棧和彈棧。
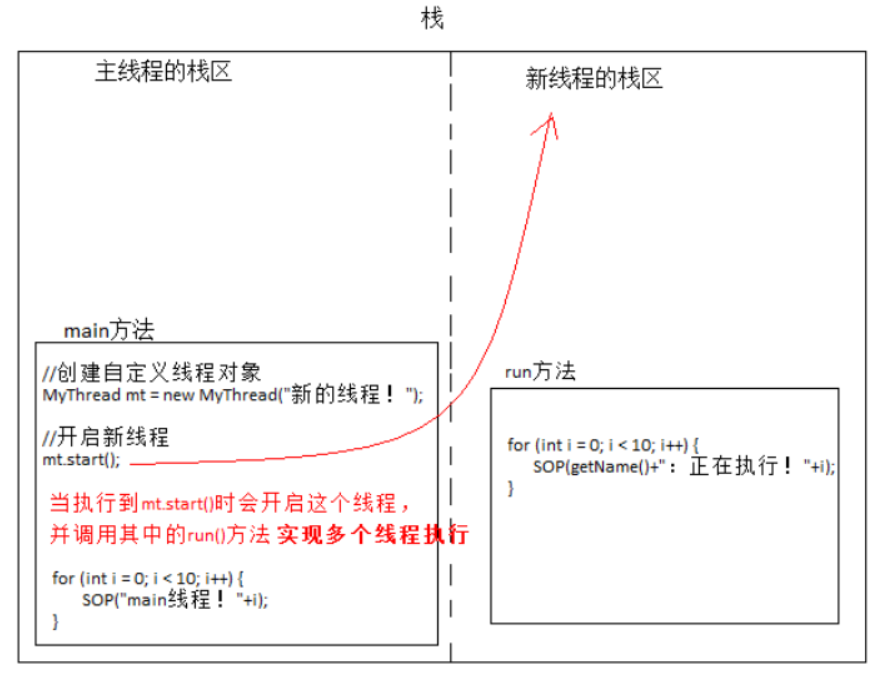
當執行線程的任務結束了,線程自動在棧內存中釋放了。但是當所有的執行線程都結束了,那么進程就結束了。
(9)線程調度策略:
① 時間片方式:一個 CPU 讓不同的線程輪流享受 CPU ,然后急速的切換。
② 搶占式:高優先級的線程搶占 CPU,有可能低優先級的線程最后才能享受 CPU,高優先級并不意味著這種就一直享受 CPU,只能說高優先級的線程獲得 CPU 的幾率比低優先級的高。
(10)Java 多線程的調度方法:
① 同優先級的線程組成先進先出隊列(FIFO),即先到先服務,使用時間片策略。
② 對于高優先級的線程,使用搶占式策略。
(11)線程的優先級:
① MAX_PRIORITY:10
② MIN_PRIORITY:1
③ NORM_PRIORITY:5
涉及到優先級的方法有:
getPriority():獲取線程優先級
setPriority(int priority):設置線程優先級
示例:

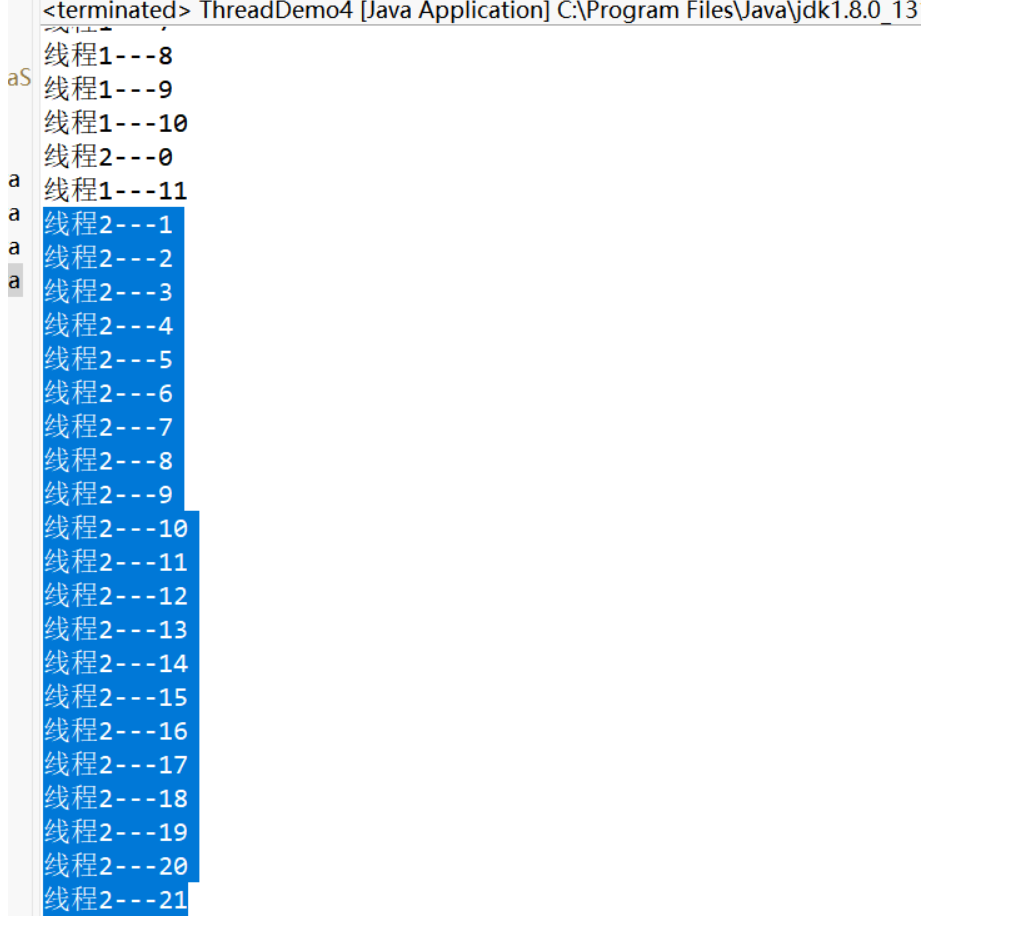
線程2獲得 CPU 的幾率要高一些。
(12)線程的分類
① 主要分為兩類:用戶線程和守護線程,這兩種線程幾乎是一致的,唯一的區別是判斷 JVM 何時離開。
② 守護線程是用來服務用戶線程,通過在 start() 方法之前調用 setDaemon(true) 來將用戶線程設置為守護線程。
③ 典型的 Java 垃圾回收器就是一個守護線程。
④ 如果 JVM 中所有的線程都是守護線程,當前 JVM 退出。

所有線程設置為守護線程后,程序運行起來馬上就退出。
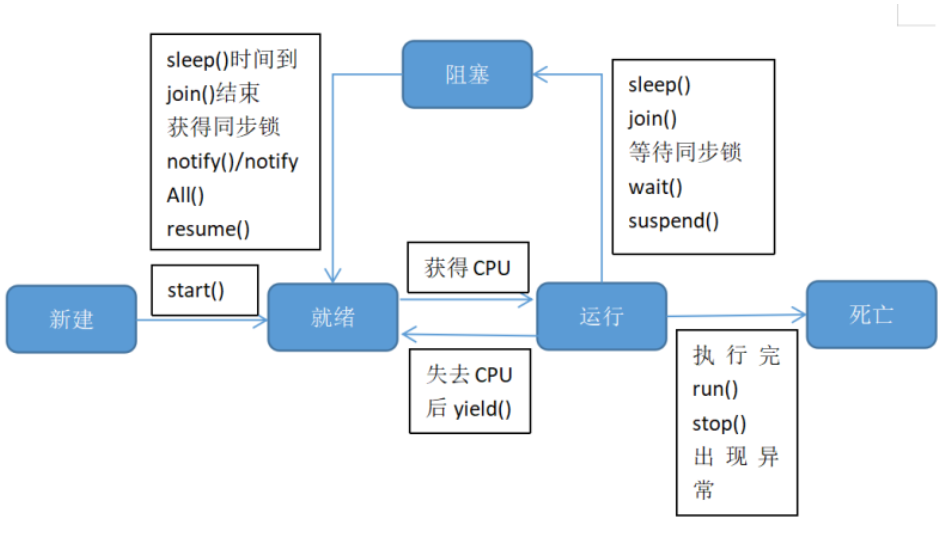
(13)線程的生命周期
一個完整的線程的生命周期會經歷如下 5 個階段:
1)新建:
當一個 Thread 類或其子類的對象被聲明并創建,新生的對象處于線程新建狀態。
2)就緒:
處于新建狀態的線程被 start() 后,將進入線程隊列等待 CPU 時間片,此時它已經具備了運行的條件,只是沒有分配到 CPU 資源
3)運行:
當就緒的線程被調度并獲得 CPU 資源的時候,便進入運行狀態,此時會執行 run() 方法。
4)阻塞:
當某種特殊情況下,被認為掛起或執行輸入輸出操作時,讓出 CPU 并臨時終止自己的運行,進入阻塞狀態。
5)死亡:
線程完成了 run() 方法中所有的操作或被強制性的終止或發生異常
2.線程同步
(1)舉例:比如家里面有3000塊錢,你取了2000,同時你媳婦也取了2000。
(2)線程同步問題:
① 多個線程的執行的不確定性引起執行結果的不穩定。
② 多個線程操作同一個共享數據時,會造成操作的不完整,會破壞數據。
示例:售票系統
package com.edu.th;
public class SellTicketsDemo {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket th1 = new Ticket("用戶1");//現在這三個線程對象共享 count 靜態成員變量
Ticket th2 = new Ticket("用戶2");
Ticket th3 = new Ticket("用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket extends Thread {
private static int count = 100;//飛機票的總數,是靜態成員,被所有 Ticket 實例所有共享
public Ticket(String name) {
// TODO Auto-generated constructor stub
super(name);
}
@Override
public void run() {
// TODO Auto-generated method stub
while(count > 0) {
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
}
}
}
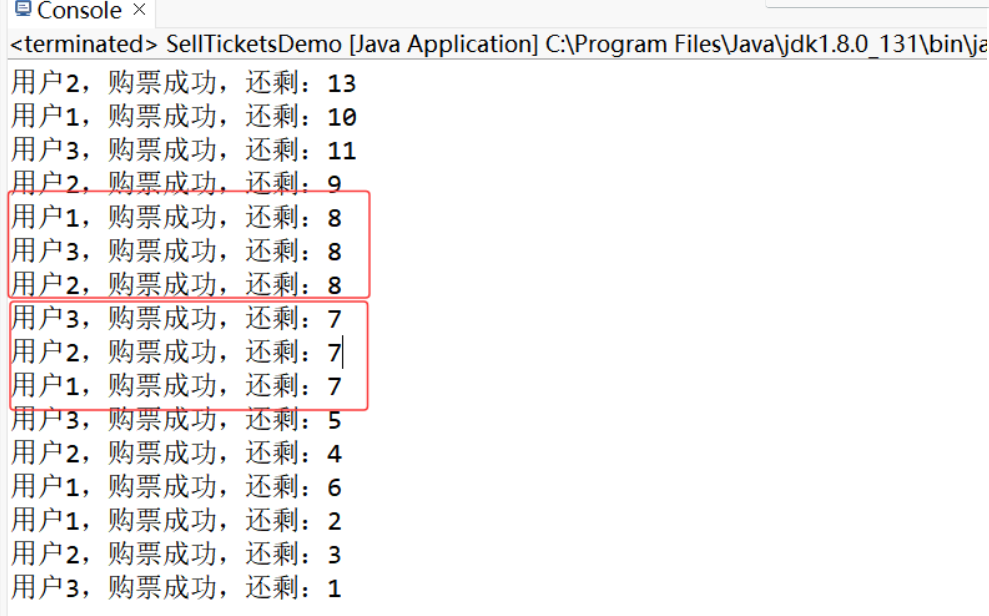
發現上面的例子中的數據是混亂的,其原因是因為有三個線程同時操作共享的 count 資源,由于各個線程的調度的不確定性,可能一個線程還沒修改完 count 值的時候,其他線程就進來修改,造成數據混亂。
第二種實現方式:
package com.edu.th;
public class SellTicketsDemo2 {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket2 tk = new Ticket2();
/**
* 此時雖然 Ticket2 的 count 是實例變量,但是 Ticket2 的實例只有一個,并且三個線程使用的是同一個 Ticket2 實例,
* 所以 Ticket2 的實例變量 count 也是被下面三個線程共享的
*/
Thread th1 = new Thread(tk, "用戶1");
Thread th2 = new Thread(tk, "用戶2");
Thread th3 = new Thread(tk, "用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket2 implements Runnable {
private int count = 100;//飛機票的總數,實例變量
@Override
public void run() {
// TODO Auto-generated method stub
while(count > 0) {
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
}
}
}
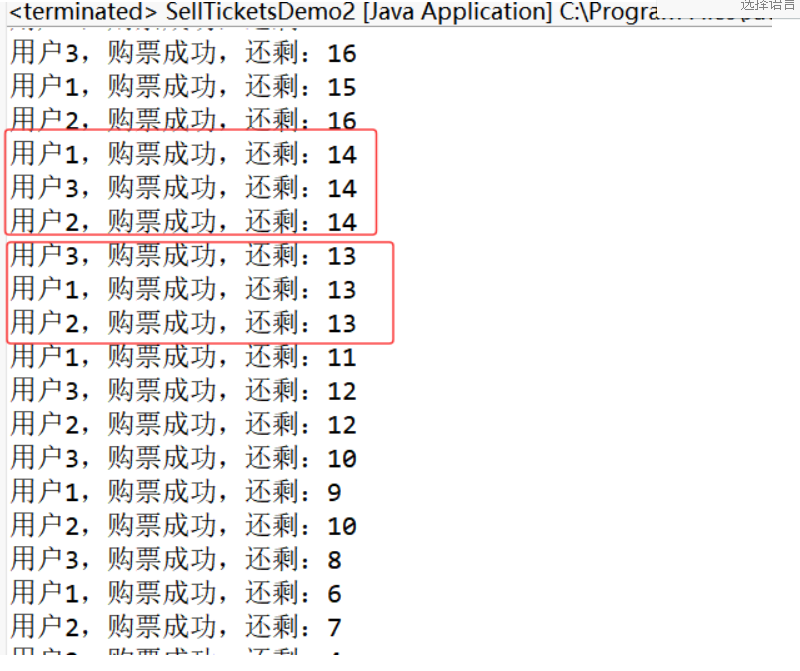
數據也是混亂的。
解決方案:對多線程來操作共享數據的時候,只讓一個線程執行,在執行的過程中,不讓其他線程進來,而是等待當前線程修改完共享數據之后,才讓其他線程進來,這就是我們要講的加鎖的機制。
(3)Java中解決線程安全問題的解決方案:線程同步,有兩種方式
1) 同步代碼塊

2) 同步方法

說明:synchronized 鎖是什么
a. 任意對象都可以作為同步鎖,所以對象都自動包含有單一的鎖
b. 同步方法的鎖:靜態方法使用“類型.class”加鎖,非靜態方法使用“對象”加鎖
注意:必須確保使用同一個資源的多個線程共用一把鎖,否則加鎖將沒有任何作用
示例:
package com.edu.th;
public class SellTicketsDemo2 {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket2 tk = new Ticket2();
/**
* 此時雖然 Ticket2 的 count 是實例變量,但是 Ticket2 的實例只有一個,并且三個線程使用的是同一個 Ticket2 實例,
* 所以 Ticket2 的實例變量 count 也是被下面三個線程共享的
*/
Thread th1 = new Thread(tk, "用戶1");
Thread th2 = new Thread(tk, "用戶2");
Thread th3 = new Thread(tk, "用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket2 implements Runnable {
private int count = 100;//飛機票的總數,實例變量
@Override
public void run() {
/**
* 通過 synchronized(this) 同步代碼塊加鎖之后,如果一個線程進入到該同步代碼塊操作,此時就對代碼塊加鎖,其他線程
* 試圖進入該代碼塊就會被阻塞在外部等待,直到該線程執行完所有操作走出同步代碼塊釋放鎖之后,其他線程才能進入同步代碼塊
* 進行加鎖,以此類推......,這樣就沒有線程安全問題了,稱為線程同步。
*/
//由于三個線程用的都是同一個 tk 對象,而 this 指的就是 tk 對象,所以 this 放在這里作為鎖的話,那么三個線程就是共用同一把鎖,這樣加鎖沒有問題
synchronized (this) {
// TODO Auto-generated method stub
while (count > 0) {
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
}
}
}
}
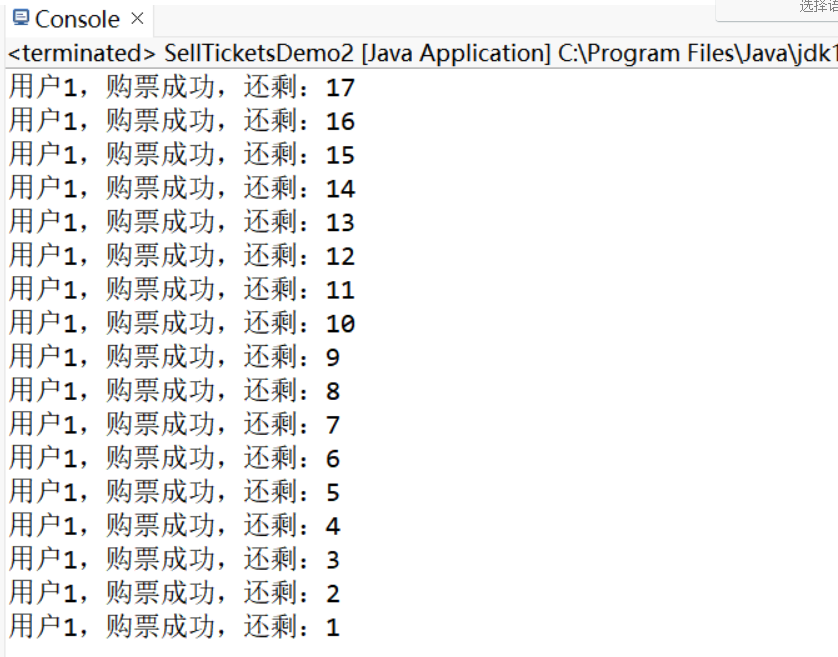
此時數據沒有換亂,換句話說,線程同步了。
但是此時只有線程1執行了所有代碼,其他線程出現了“餓死”的情況,主要是因為這把鎖是不公平鎖。
示例2:如果多個線程使用的不是同一把鎖,相當于沒有加鎖,還是會有線程同步的問題
package com.edu.th;
public class SellTicketsDemo {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket th1 = new Ticket("用戶1");//現在這三個線程對象共享 count 靜態成員變量
Ticket th2 = new Ticket("用戶2");
Ticket th3 = new Ticket("用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket extends Thread {
private static int count = 100;//飛機票的總數,是靜態成員,被所有 Ticket 實例所有共享
public Ticket(String name) {
// TODO Auto-generated constructor stub
super(name);
}
@Override
public void run() {
synchronized (this) {//由于上面產生了三個不同的 Ticket 對象,這里的 this 就表示有三把不同的鎖,相當于沒有加鎖
// TODO Auto-generated method stub
while (count > 0) {
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
}
}
}
}
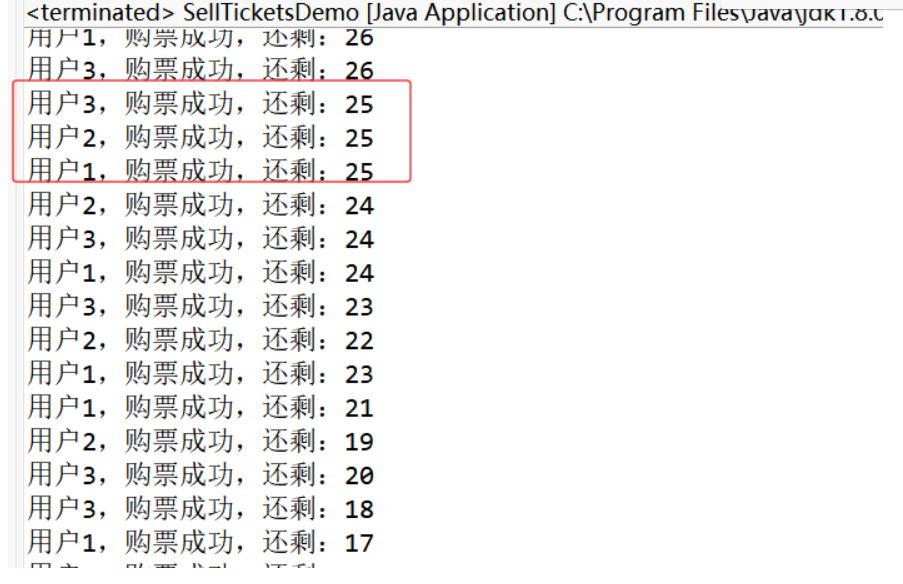
數據還是出現了混亂,線程沒有同步
要解決上面的問題,必須使用“一把鎖”的方案:
package com.edu.th;
public class SellTicketsDemo {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket th1 = new Ticket("用戶1");//現在這三個線程對象共享 count 靜態成員變量
Ticket th2 = new Ticket("用戶2");
Ticket th3 = new Ticket("用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket extends Thread {
private static int count = 100;//飛機票的總數,是靜態成員,被所有 Ticket 實例所有共享
//創建一個靜態的對象 lock 作為鎖,靜態成員被所有實例共享,那么上面三個線程看到的 lock 鎖就是同一把鎖了
private static Object lock = new Object();
public Ticket(String name) {
// TODO Auto-generated constructor stub
super(name);
}
@Override
public void run() {
synchronized (lock) {//上面三個線程共用同一把鎖 lock
// TODO Auto-generated method stub
while (count > 0) {
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
}
}
}
}
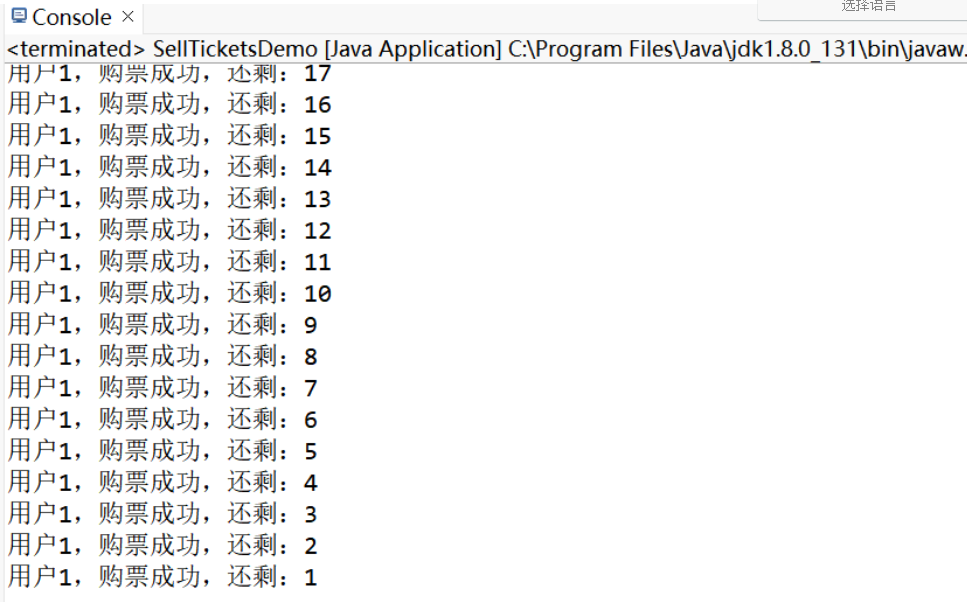
加鎖成功,線程同步了。
3) 同步的范圍
a. 如何找到代碼中是否存在線程安全問題
a) 明確哪些代碼是多線程運行代碼
b) 明確多線程是否有共享數據
c) 明確多線程運行代碼中是否有多條語句操作共享數據
b. 解決線程安全問題
a) 對于多條操作共享數據的語句,只讓一個線程執行,在執行的過程中,其他線程不能參與進來。
b) 在設計同步代碼塊的時候需要注意:
i. 同步代碼塊范圍太小:沒有鎖住所有安全問題的代碼。
ii. 同步代碼塊范圍太大:沒有發揮多線程的優勢。
4) 釋放鎖的時間
a. 當線程執行完同步方法或同步代碼塊時。
b. 當線程的同步方法或同步代碼塊遇到了 break,return 等語句時終止了該代碼時。
c. 當線程的同步方法或同步代碼塊遇到了未處理的 Error 或異常時。
d. 當線程的同步方法或同步代碼塊中執行了線程對象的 wait() 方法,當前線程暫停,并釋放鎖。
5) 不會釋放鎖的操作
a. 線程執行到同步方法或同步代碼塊時,調用 Thread.sleep() 或 Thread.yield() 方法暫停當前線程。
b. 線程執行到同步方法或同步代碼塊時,程序調用了 suspend 掛起線程也不釋放鎖。
注意:應該避免使用 suspend() 和 resume() 方法
(4)針對懶漢式單例設計模式存在線程安全問題的解決方法:

(5)線程死鎖
1) 死鎖:
不同的線程分別占用了對方需要同步的資源不放,都在等待對方放棄自己需要同步的資源,就會形成死鎖。
2) 死鎖的示例:
package com.edu.th;
public class DeadLockDemo {
private static Object o1 = new Object();//第一把鎖
private static Object o2 = new Object();//第二把鎖
public static void main(String[] args) {
// TODO Auto-generated method stub
//匿名對象
new Thread(new Runnable() {//匿名內部類
@Override
public void run() {
// TODO Auto-generated method stub
//形成一個同步代碼塊的嵌套,從而制造死鎖
synchronized (o1) {//第一個同步塊,使用 o1 加鎖
try {
Thread.sleep(200);//休眠200毫秒,模擬線程運行鎖消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
synchronized (o2) {//嵌套加上 o2 鎖
try {
Thread.sleep(200);//休眠200毫秒,模擬線程運行鎖消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("線程1執行完畢");
}
}
}
},"線程1").start();
//匿名對象
new Thread(new Runnable() {//匿名內部類
@Override
public void run() {
// TODO Auto-generated method stub
//形成一個同步代碼塊的嵌套,從而制造死鎖
synchronized (o2) {//第一個同步塊,使用 o2 加鎖
try {
Thread.sleep(200);//休眠200毫秒,模擬線程運行鎖消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
synchronized (o1) {//嵌套加上 o1 鎖
try {
Thread.sleep(200);//休眠200毫秒,模擬線程運行鎖消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("線程1執行完畢");
}
}
}
},"線程2").start();
}
}

第一個線程獲取到 o1 鎖之后企圖去獲取 o2 鎖,第二個線程獲取到 o2 鎖之后企圖去獲取 o1 鎖,此時線程1占著o1 鎖,那么線程2 等待,同時線程2占著 o2 鎖,那么線程1等待,就會陷入相互等待對方釋放鎖,從而形成死鎖。
3) 死鎖的解決方案
a. 有專門的算法,原則
b. 盡量較少同步資源的定義
c. 避免同步塊的嵌套
3.Lock 鎖(屬于J.U.C(java.util.concurrent),適合高并發)
(1)從 JDK5.0 開始,Java 提供了 Lock 對象來作為同步鎖。
(2)Lock 對象是控制多個線程對共享資源進行訪問的工具,鎖提供了對共享資源的獨占訪問,每次只能有一個線程對 Lock 對象加鎖,線程開始訪問共享資源之前應該先獲得鎖。
(3)ReentrantLock 類實現了 Lock 接口,它用于 synchronized 相同的并發性和內存語義,在線程安全中,可以顯式的加鎖和釋放鎖。
(4)ReentrantLock 類包含兩個構造函數,默認構造函數 public ReentrantLock() 會創建不公平鎖,帶參的構造函數 public ReentrantLock(boolean fair) 傳入 true 表示創建公平鎖,傳入 false 表示創建不公平鎖。
示例:
package com.edu.th;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class SellTicketsDemo3 {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket3 tk = new Ticket3();
/**
* 此時雖然 Ticket2 的 count 是實例變量,但是 Ticket2 的實例只有一個,并且三個線程使用的是同一個 Ticket2 實例,
* 所以 Ticket2 的實例變量 count 也是被下面三個線程共享的
*/
Thread th1 = new Thread(tk, "用戶1");
Thread th2 = new Thread(tk, "用戶2");
Thread th3 = new Thread(tk, "用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket3 implements Runnable {
private int count = 100;//飛機票的總數,實例變量
private Lock lock = new ReentrantLock(true);//創建一個 ReentrantLock 鎖對象,是公平鎖
@Override
public void run() {
// TODO Auto-generated method stub
/**
* 加鎖之后(lock.lock()),如果一個線程進入到該同步塊中操作,那么其他線程會被阻塞在外部等待,直到該線程做完所有操作釋放
* 鎖(lock.unlock())之后,其他線程才能進來,這樣就沒有線程安全問題了,稱為線程同步。
*/
while (true) {
lock.lock();//加鎖
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
if(count > 0)
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
else
break;
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {//Lock 鎖的釋放一般都是放在 finally 語句塊中,表示鎖在任何情況下都必須釋放
lock.unlock();//釋放鎖
}
}
}
}
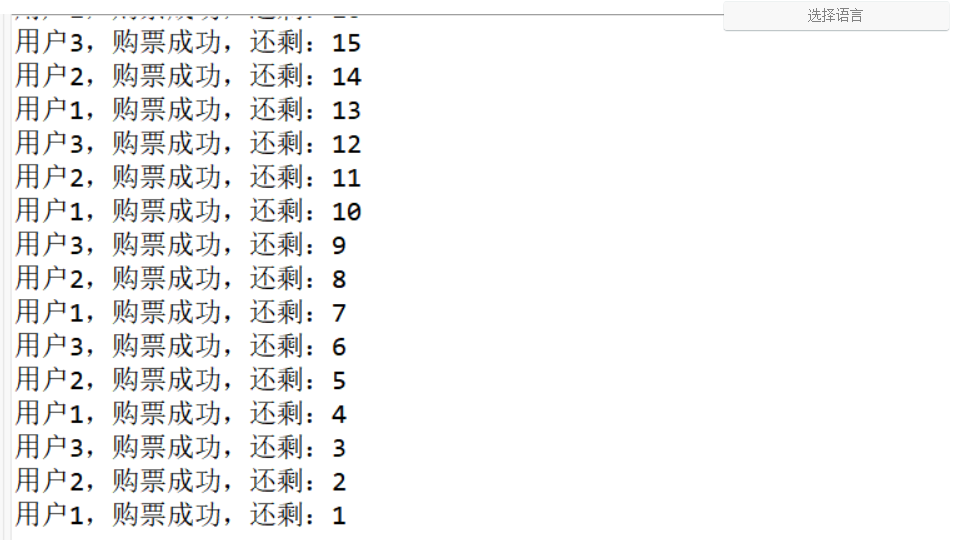
打印的數據沒有問題,所以線程是安全的,同時三個線程輪流打印,不存在線程“餓死”的情況,因為我們加的鎖是公平鎖。
現在我們來看加不公平鎖的情況:
package com.edu.th;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class SellTicketsDemo3 {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Ticket3 tk = new Ticket3();
/**
* 此時雖然 Ticket2 的 count 是實例變量,但是 Ticket2 的實例只有一個,并且三個線程使用的是同一個 Ticket2 實例,
* 所以 Ticket2 的實例變量 count 也是被下面三個線程共享的
*/
Thread th1 = new Thread(tk, "用戶1");
Thread th2 = new Thread(tk, "用戶2");
Thread th3 = new Thread(tk, "用戶3");
th1.start();
th2.start();
th3.start();
}
}
class Ticket3 implements Runnable {
private int count = 100;//飛機票的總數,實例變量
private Lock lock = new ReentrantLock();//創建一個 ReentrantLock 鎖對象,是不公平鎖
@Override
public void run() {
// TODO Auto-generated method stub
/**
* 加鎖之后(lock.lock()),如果一個線程進入到該同步塊中操作,那么其他線程會被阻塞在外部等待,直到該線程做完所有操作釋放
* 鎖(lock.unlock())之后,其他線程才能進來,這樣就沒有線程安全問題了,稱為線程同步。
*/
while (true) {
lock.lock();//加鎖
try {
Thread.sleep(100);//休眠 100 毫秒,模擬售票消耗的時間
if(count > 0)
System.out.println(Thread.currentThread().getName() + ",購票成功,還剩:" + count--);
else
break;
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {//Lock 鎖的釋放一般都是放在 finally 語句塊中,表示鎖在任何情況下都必須釋放
lock.unlock();//釋放鎖
}
}
}
}
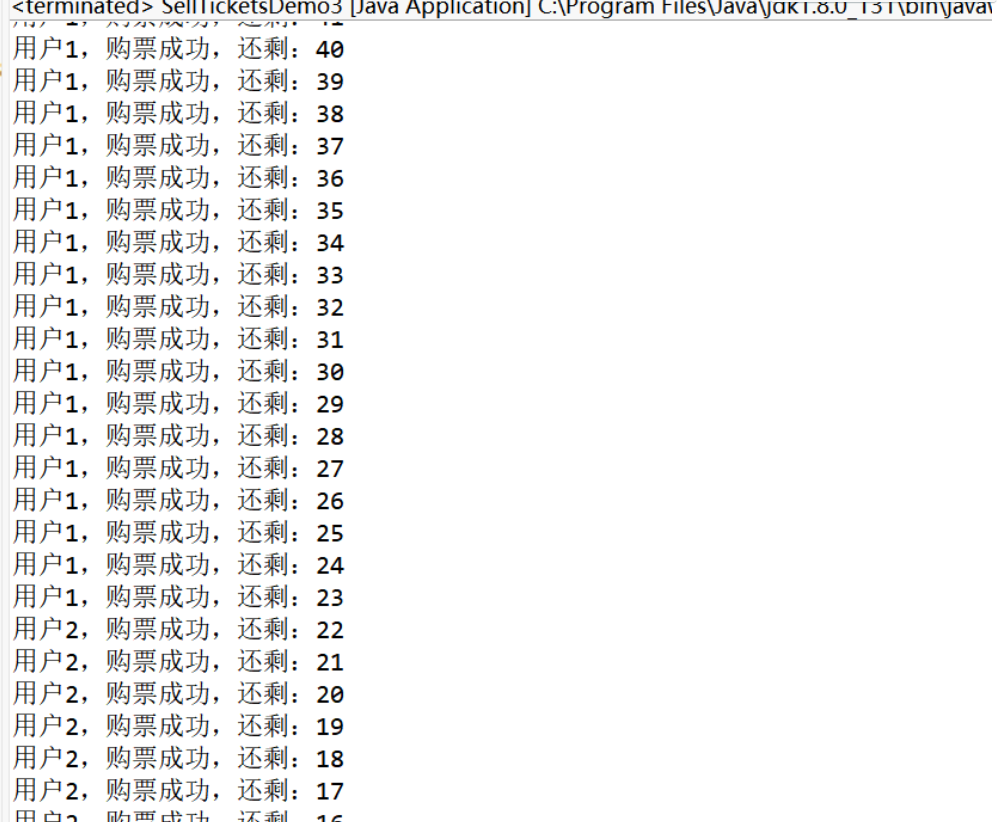
“用戶1”線程獲得了大部分的執行機會,”用戶2”線程獲得了少部分的執行機會,”用戶3”線程被“餓死”了,所以不公平鎖可能存在線程“餓死”的情況。
(5)對比 synchronized 和 Lock
① Lock 是顯式鎖,需要手動加鎖和釋放鎖,synchronized 是隱式鎖,出了作用域就自動釋放鎖。
② Lock 只有代碼塊鎖,而 synchronized 有代碼塊鎖和方法鎖。
③ 使用 Lock 鎖,JVM 將花費比較少的時間來調度線程,性能更好,并且具有很好的擴展性。
4.線程通訊
(1)線程通訊牽涉到的 API:Object 類關于線程通訊的 API
wait():使當前線程掛起并放棄 CPU,同步資源并等待,并且會釋放鎖,使別的線程可以訪問并修改共享資源,當前線程需要排隊等待其他線程調用 notify() 或 notifyAll() 喚醒之后再獲得鎖繼續執行。
notify():喚醒正在排隊等候同步資源的線程中優先級最高的線程,結束等待,繼續執行
notifyAll():喚醒所有正在排隊等候同步資源的所有線程,結束等待,繼續執行
注意:這三個方法只能在 synchronized 方法或代碼塊中才能使用,否則會拋出異常
示例:線程通訊,兩個線程交替打印 i++
package com.edu.th;
public class ThreadCommunicateDemo {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
CommThread ct = new CommThread();
//兩個線程共享同一個 ct 對象
new Thread(ct, "線程1").start();
new Thread(ct, "線程2").start();
}
}
class CommThread implements Runnable{
int i = 0;
@Override
public void run() {
// TODO Auto-generated method stub
while(true) {
/**
* 線程1進入同步代碼塊中喚醒線程2,并將 i+1 輸出,然后 wait() 釋放鎖并等待線程2喚醒它,線程2被
* 線程1喚醒之后就可以獲得鎖進入同步代碼塊,然后喚醒線程1,并將 i+1 輸出,然后wait()釋放鎖并陷入阻塞狀態等待線程1喚醒,
* 這樣就能實現兩個線程交替打印i++的操作(是公平的)
*/
synchronized (this) {
notify();//如果當前線程進入同步代碼塊,就去喚醒其他線程來進入同步代碼塊
if(i <= 100) {
System.out.println(Thread.currentThread().getName() + "---" + i++);
}else {
break;
}
try {
wait();//當前線程執行 i++ 執行,陷入等待,等待其他線程喚醒
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}

上面的例子是“線程1”和“線程2”交替執行,是公平的,如果我們將 notify() 和 wait() 取出,那么就會變成不公平的,參考之前的 synchronized 代碼。
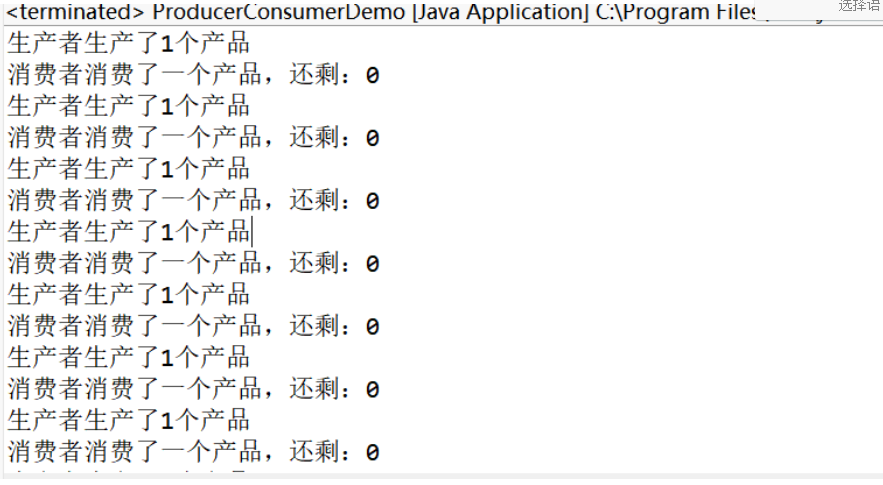
示例2:經典的生產者和消費者線程:生產者生產產品由消費者消費,沒有產品時,消費者等待(wait()),當消費者消費完產品時,通知生產者生產產品(notify()),當產品數量達到一定數量時,生產者等待(wait()),等待消費者去消費,當生產者把產品生產好之后,通知消費者消費(notify())。
package com.edu.th;
public class ProducerConsumerDemo {
?? ?public static void main(String[] args) {
// TODO Auto-generated method stub
Clert clert = new Clert();
//兩個線程共享同一個 clert 對象
new Producer(clert).start();//啟動生產者線程
new Consumer(clert).start();//啟動消費者線程
}
}
//店員類
class Clert{
private int product = 0;//初始化產品數量為 0
//消費產品,是一個同步方法,由消費者來調用
public synchronized void getProduct() {
if(product == 0) {//沒貨了,消費者等待
try {
wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {//否則表示生產者已經生產了產品,可以消費
System.out.println("消費者消費了一個產品,還剩:" + --product);
try {
Thread.sleep(300);//休眠模擬消費者消費產品所消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//消費者消費了產品之后通知生產者可以繼續生產產品了
notify();
}
}
//生產產品,同步方法,由生產者來調用
public synchronized void setProduct() {
if(product != 0) {//產品不為0,表示有貨,則生產者等待,等待消費者消費
try {
wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}else {//否則表示沒貨了,生產者繼續生產產品
System.out.println("生產者生產了" + ++product + "個產品");
try {
Thread.sleep(300);//模擬生產者生產產品所消耗的時間
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//有產品了,通知消費者可以消費了
notify();
}
}
}
//生產者線程
class Producer extends Thread {
private Clert clert;
?? ?public Producer(Clert clert) {
this.clert = clert;
}
@Override
public void run() {
// TODO Auto-generated method stub
while(true) {
clert.setProduct();//生產者不斷的生產產品
}
}
}
//消費者線程
class Consumer extends Thread {
private Clert clert;
?? ?public Consumer(Clert clert) {
this.clert = clert;
}
@Override
public void run() {
// TODO Auto-generated method stub
while(true) {
clert.getProduct();//消費者不斷地消費產品
}
}
}
5.JDK5.0 新增的創建線程的方式
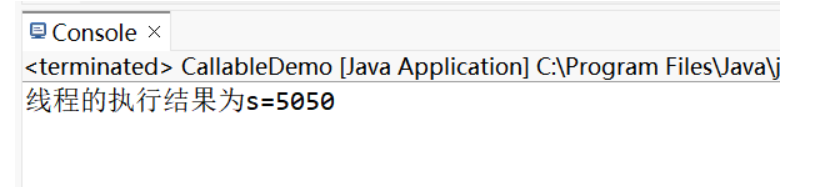
(1)實現 Callable 接口:相對于實現 Runnable 接口而言,Callable 更強大(屬于J.U.C(java.util.concurrent),適合高并發)
① 相對于 run() ,其可以有返回值
② 方法可以拋出異常
③ 執行泛型返回值
④ 需要借助 FutureTask 類,比如獲取返回值
示例:使用 Callable 不用去 join() 線程去阻塞就能直接獲得值

(2)使用線程池
如果經常創建和銷毀線程,將特別消耗資源,如果是在高并發的情況下,對性能的影響是特別大的,我們可以考慮一次性創建多個線程,將這些線程放在線程池中,要使用的時候從線程池取出使用,使用完歸還給線程池,這樣可以避免頻繁的創建和銷毀線程,實現重復利用,效率比較高。
1)線程池的優點:
a. 提高了響應的速度(減少了創建線程和銷毀線程的時間)
b. 減低資源消耗(每次從線程池中取出,不用重新創建)
c. 便于管理:corePoolSize:核心池大小,maximumPoolSize:線程池最大大小,keepAliveTime:線程保持多少時間后終止...
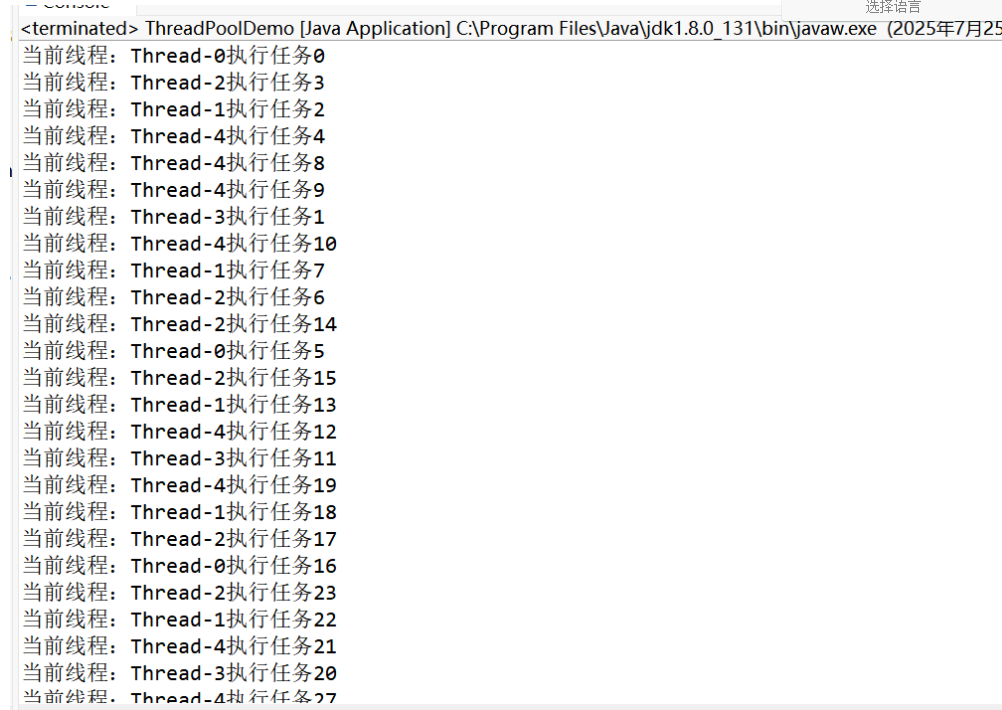
2)自定義線程池
a. 要實現一個線程池,我們首先要分析其應該具備哪些功能:
a) 創建一個阻塞隊列,用于存放要執行的任務
b) 提供 submit 方法,用于添加新的任務
c) 提供構造方法,指定應該創建多少個線程
d) 在構造方法中,創建好這些線程
b. 代碼實現:
package com.edu.th;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ThreadPoolDemo {
?? ?public static void main(String[] args) throws InterruptedException {
// TODO Auto-generated method stub
//創建線程池對象
MyThreadPoolExecutor executor = new MyThreadPoolExecutor(5);//創建包含5個線程的線程池
for (int i = 0; i < 100; i++) {
int n = i;
executor.submit(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println("當前線程:" + Thread.currentThread().getName() + "執行任務" + n);
}
});
}
}
}
class MyThreadPoolExecutor {
//用于存放線程任務的隊列,是一個阻塞隊列且線程安全
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<Runnable>(100);//最多100個任務
public MyThreadPoolExecutor(int n) {//創建 n 個線程
for (int i = 0; i < n; i++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
while(true) {
try {
Runnable r = queue.take();//從隊列中取出一個任務來運行
r.run();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
});
t.start();
}
}
//添加任務
public void submit(Runnable r) throws InterruptedException {
queue.put(r);//將任務添加到隊列
}
}
3)創建線程池的 API(屬于J.U.C(java.util.concurrent),適合高并發)
a. ExecutorService 和 Executors
a) ExecutorService:真正的線程池接口,包含如下接口方法:
void execute(Runnable runnable):執行任務,沒有返回值,一般用于執行 Runnable 接口實現類的實例
<T> Future <T> submit(Callable<T> task):執行任務,有返回值
b) Executors 工具類:創建各種線程池
Executors.newCachedThreadPool():創建一個可根據需要創建新線程的線程池
Executors.newFixedThreadPool(int n):創建 n 個固定數量線程的線程池
Executors.newSingleThreadPool():創建單一線程的線程池
Executors.newSechduledThreadPool():創建一個線程池,可以安排在給定延遲時間后執行或周期性的執行
示例:
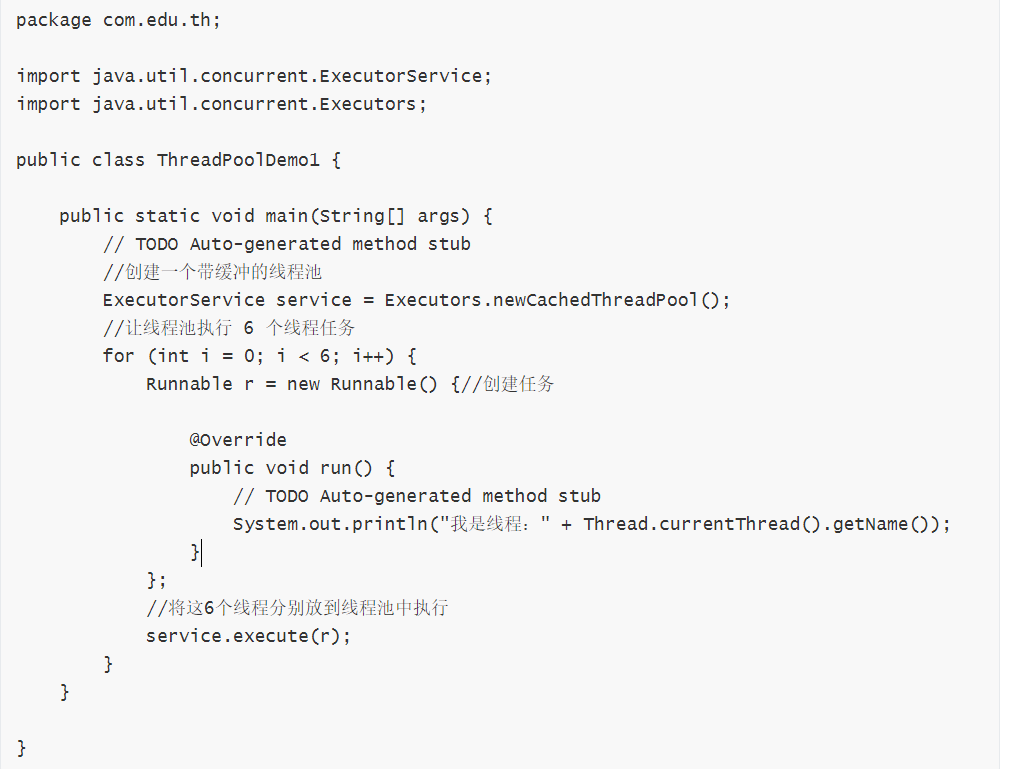
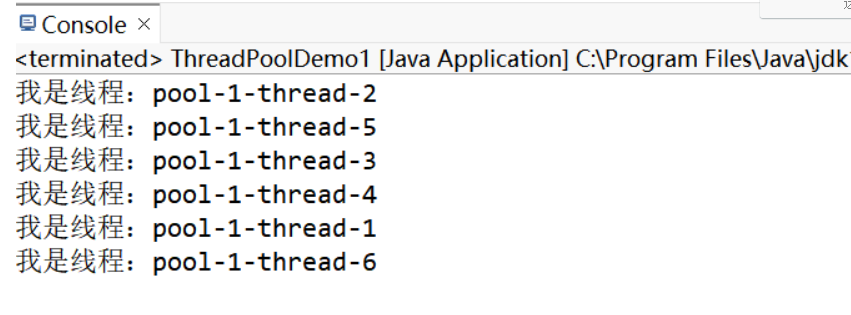
示例2:利用線程池創建線程,要求延遲 2 秒后執行

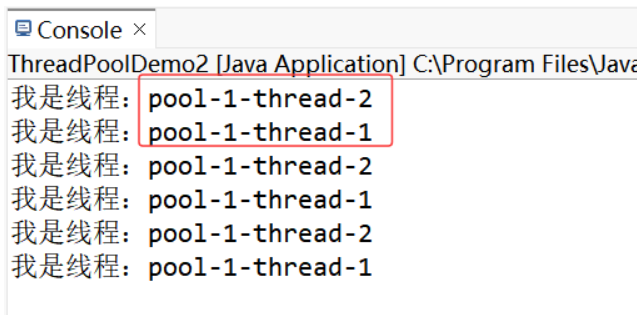
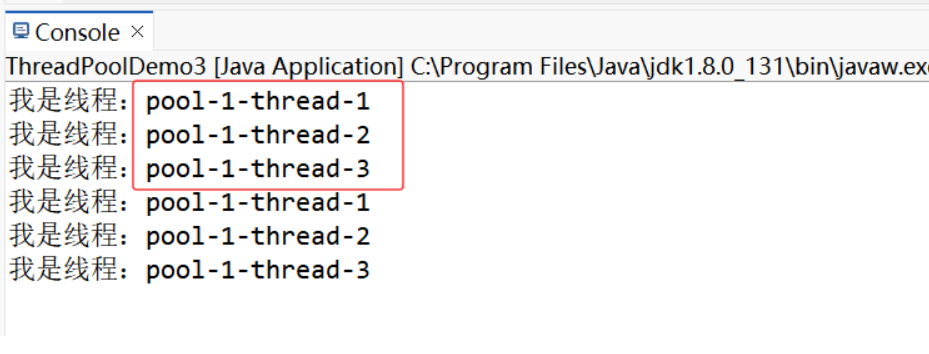
示例3:Callable 在線程池中使用

6.并發容器:ConcurrentHashMap
ConcurrentHashMap 是 Java 中一種線程安全的哈希表實現,屬于 Java 并發包 J.U.C(java.util.concurrent)的一部分。它被設計用于在多線程環境中高效地進行并發讀寫操作。以下是對 ConcurrentHashMap 的詳細介紹:
(1)基本概念
線程安全:ConcurrentHashMap 在多個線程同時讀取和寫入數據時,能夠保持數據的一致性和完整性。
高效性:與其他同步容器(如 Hashtable 或 Collections.synchronizedMap(map))相比,ConcurrentHashMap 具有更高的并發性能。
(2)工作原理
ConcurrentHashMap 采用了分段鎖(Segmented Locking)的策略,將數據分成多個段(或桶),每個段都有獨立的鎖。這樣,在不同段的數據上可以并發地執行讀寫操作,從而提高性能。
分段鎖:ConcurrentHashMap 默認將其結構分為 16 個段,每個段可以獨立鎖定。這樣,多個線程可以同時訪問不同的段而不互相阻塞。
非阻塞讀取:對于讀取操作,ConcurrentHashMap 使用了一種非阻塞的方式,通常不需要加鎖,從而提高了并發性能。
(3)主要方法
put(K key, V value):插入或更新指定的鍵值對。
get(Object key):根據鍵獲取對應的值。
remove(Object key):移除指定的鍵及其對應的值。
containsKey(Object key):檢查是否包含指定的鍵。
keySet()、values()、entrySet():獲取鍵、值及鍵值對的集合。
(4)使用示例
package com.edu.th;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapDemo {
?public static void main(String[] args) {
? // TODO Auto-generated method stub
? ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>();
? //插入數據
? map.put("A", 1);
? map.put("B", 2);
? //讀取數據
? Integer value = map.get("A");
? System.out.println(value);
? //移除數據
? map.remove("B");
? //檢查鍵
? boolean exists = map.containsKey("B");
? System.out.println("Key B是否存在:" + exists);
?}
(5)優勢與局限
優勢:
高并發性能:適用于讀多寫少的場景,能夠在多線程環境中提供良好的性能。
不阻塞的讀操作:讀取操作幾乎沒有鎖的開銷。
局限:
不支持 null 鍵或值:在 ConcurrentHashMap 中,不能插入 null 鍵或 null 值。
可能導致的遍歷性能下降:在高并發的情況下,遍歷操作可能會受到影響,因為可能會有其他線程同時對數據進行修改。
(6)總結
ConcurrentHashMap 是處理并發場景中常用的數據結構,適合在多線程應用中使用。理解其工作原理和使用方法能夠幫助開發者有效管理共享數據,減少數據競爭和提高程序的性能。
除了 ConcurrentHashMap 之外,在J.U.C 中還有比如 CopyOnWriteArrayList (線程安全的 List,適合高并發),BlockingQueue 的實現類,例如 ArrayBlockingQueue(線程安全的隊列,適合高并發)。





![信息學奧賽一本通 1593:【例 2】牧場的安排 | 洛谷 P1879 [USACO06NOV] Corn Fields G](http://pic.xiahunao.cn/信息學奧賽一本通 1593:【例 2】牧場的安排 | 洛谷 P1879 [USACO06NOV] Corn Fields G)



)
圖片向量化存儲-Milvus 單機版部署)

正則表達式)






