NeRF和3DGS
- 一、傳統三維表征方法
- 1.1 顯示表征
- 1.2 隱式表征
- 二、NeRF(Nerual Radiance Field)
- 2.1 NeRF場景表示
- 2.2 NeRF訓練流程
- 2.3 NeRF體渲染
- 2.4 NeRF位置編碼
- 2.5 NeRF體素分層采樣(Volume Hierarchical Sampling)
- 2.6 NeRF網絡結構
- 2.7 NeRF總結
- 2.8 NeRF相關研究
- 三、3DGS
- 3.1 3DGS"顯示"三維特征
- 3.2 3DGS原理介紹
- 3.3 3DGS前向渲染
- 3.3.1 坐標系變換
- 3.3.2 顏色渲染(alpha-blending)
- 3.3.3 按圖像塊Tile并行化渲染
- 3.4 3DGS優化訓練過程
- 3.5 3DGS相關研究
- 3.6 3DGS相關研究點
一、傳統三維表征方法
1.1 顯示表征

補充:
- 多邊形網格:明確的拓撲關系,便于可視化,內存占用低;非結構化網格生成難度高;
- 體素:難以支撐高精度、大規模場景重建;
- 點云:易獲取(可直接通過激光雷達深度相機采集),無需復雜預處理;缺乏拓撲關系,難以直接表征孔洞遮擋等表面連續性關系;噪聲,數據缺失;存儲計算效率低。

1.2 隱式表征
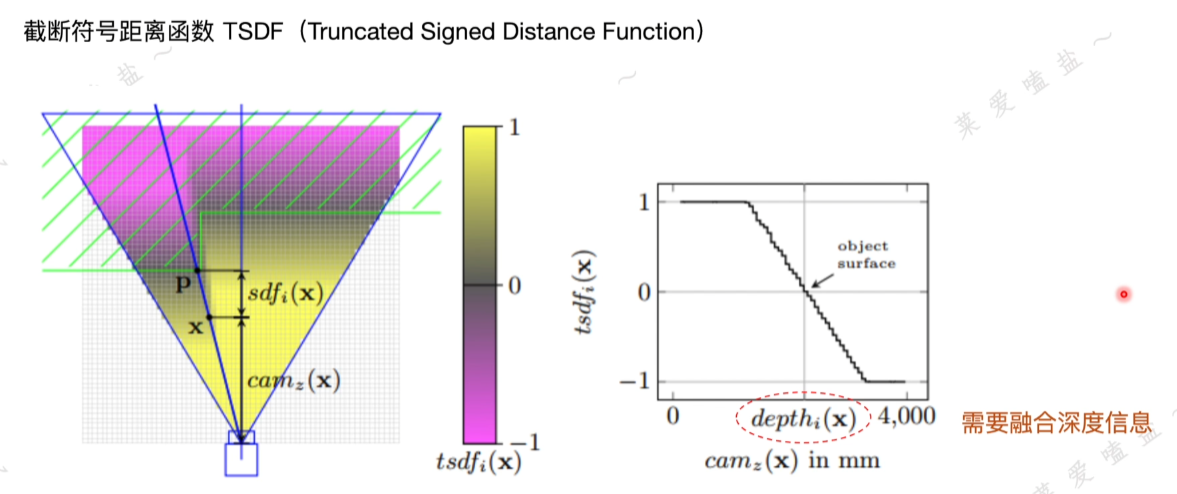
藍色三角形:相機的視場范圍
綠色:物體截面;
二、NeRF(Nerual Radiance Field)
2.1 NeRF場景表示
思想:將場景表達為與空間信息相關的可優化的函數,并通過優化方法擬合該函數。
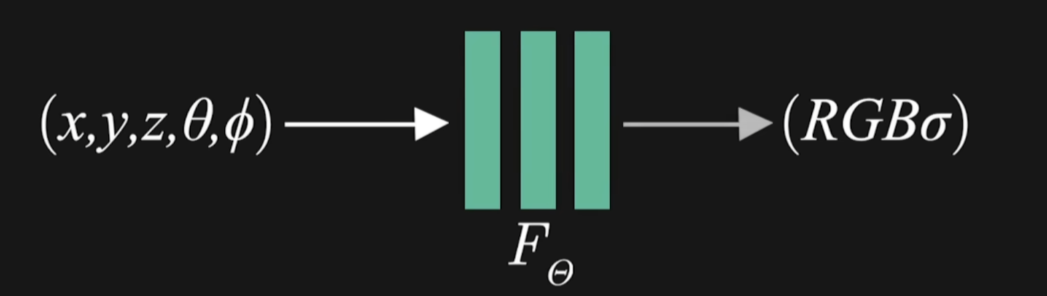
函數輸入:采樣點位置+觀測方向,五維向量;
函數參數化為一個全連接的深度神經網絡,將輸入信息處理后輸出相應空間位置的體素密度以及依賴觀測方向的RGB顏色;
再利用提渲染技術將顏色俺體素密度沿相機光纖進行積分渲染相應像素的顏色,此渲染過程可微,像素顏色真值已知;所以可通過最小化所有相機射線渲染顏色與真實像素的誤差來優化此全連接網絡,即場景的表示。
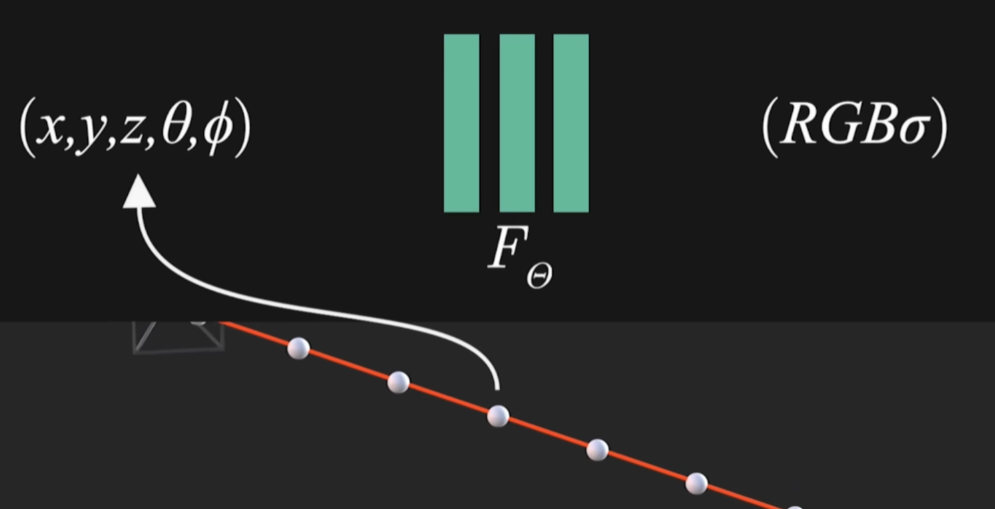
2.2 NeRF訓練流程
觀測角度也做自變量原因:不同角度的光影有區別變化。
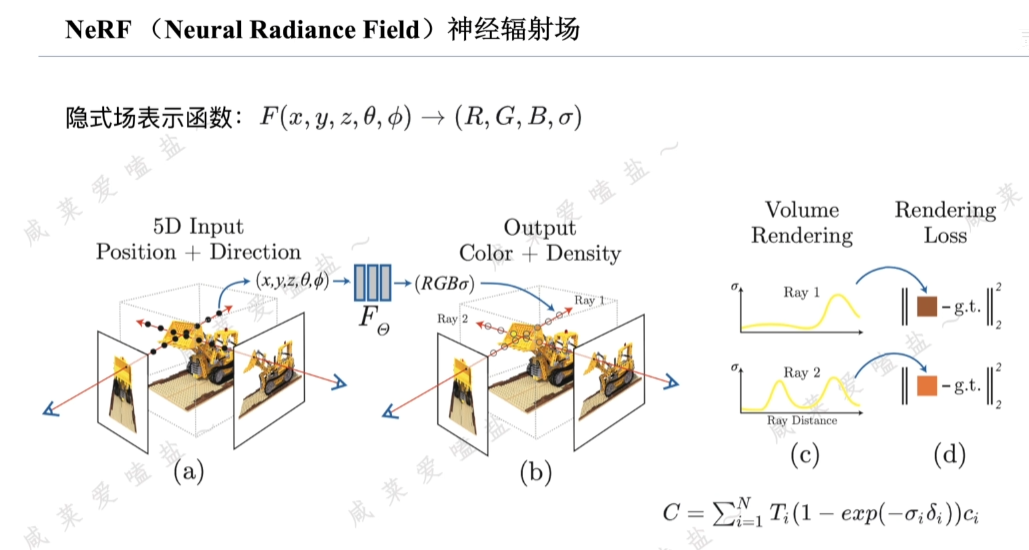
1)光線采樣
對于每張訓練圖像中的每個像素根據相機位姿生成一條從相機中心穿過該像素的光纖,隨后沿光線在近處遠處截斷平面之間均勻或分層采樣多個3D點。
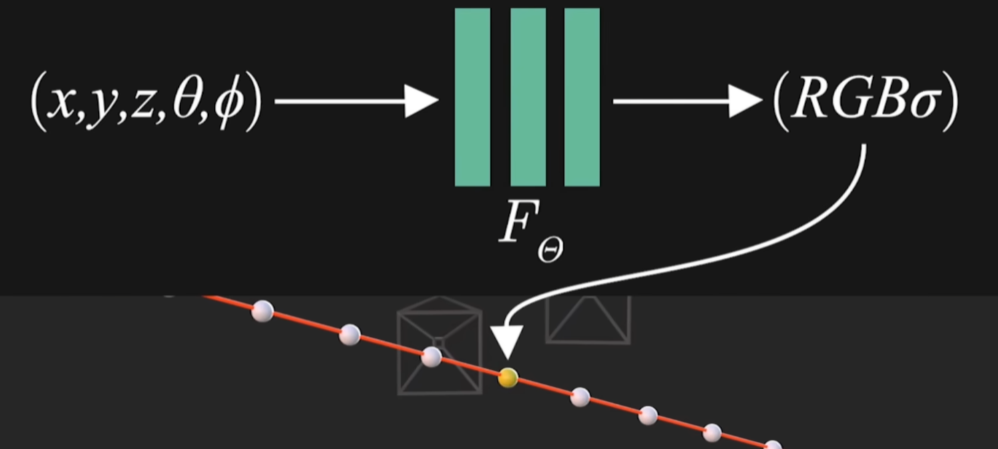
2)神經網絡預測
將每個采樣點的3D坐標以及觀測方向輸入多層感知機MLP,輸出該位置的集合不透明度和從觀測方向看到的顏色。
3)體渲染
沿光線積分3D點的密度和顏色合成2D像素顏色(此過程可微,公式中僅包含+、-、exp三種可微運算,為后續可優化提供條件)。
4)損失計算與優化
計算渲染像素顏色與真實像素之間的均方誤差,并通過梯度下降的方法更新MLP參數逐步最小化損失函數。
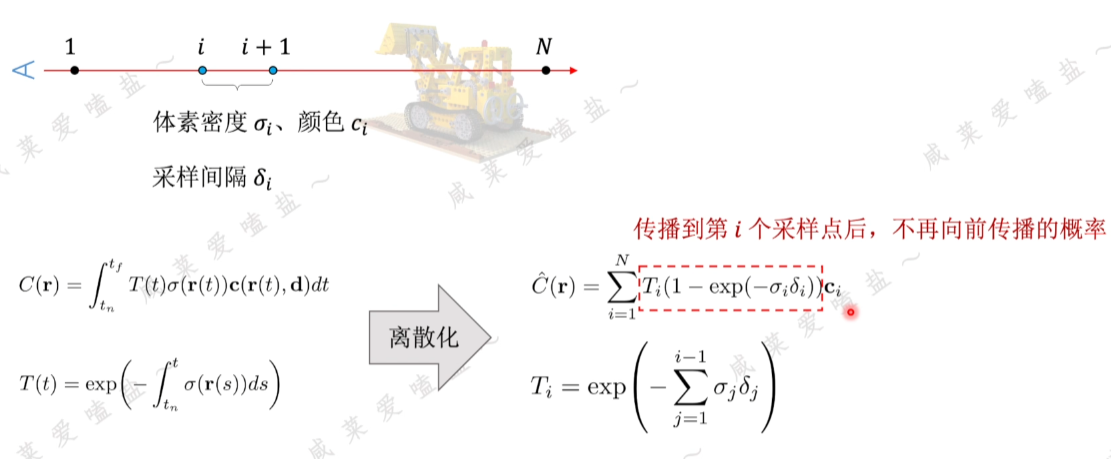
2.3 NeRF體渲染
NeRF體渲染(Volunme Rendering)公式理解

包含兩個部分:(1)射線上顏色的積累;(2)射線上各采樣點的累計不透明度
- 累計透射率

穿過推土機密度場和輻射場的一條射線從tn出發射向無窮遠tf處,該射線傳播到多遠處會停止?

- 顏色累計


o:坐標原點;d:描述射線方向的單位向量
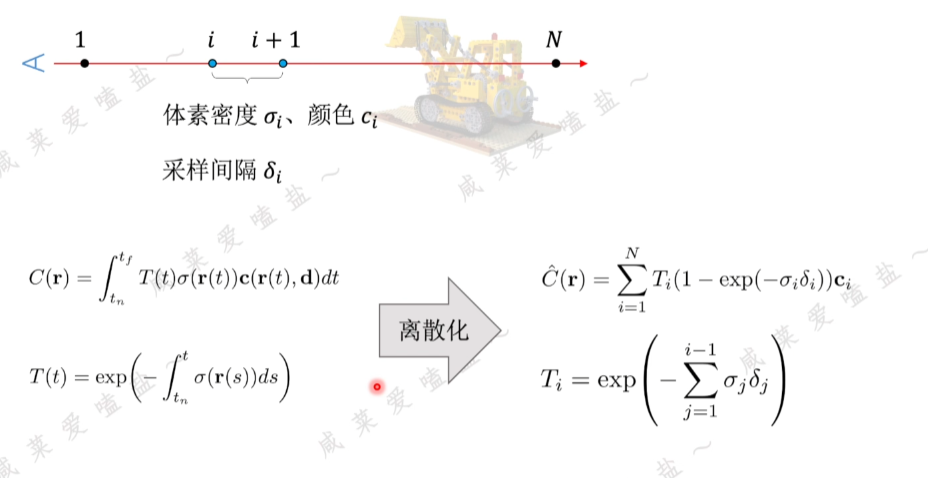
核心思路:假設在兩個采樣點之間的密度顏色都是均勻且固定的,采樣間隔相距越小最終累計顏色越精確。
2.4 NeRF位置編碼
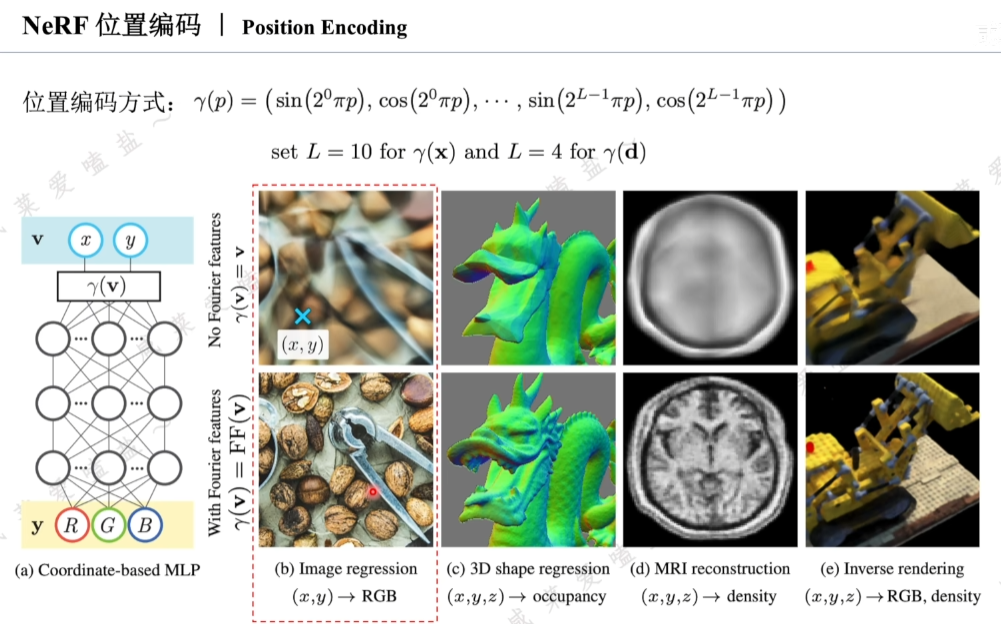
類似vision transformer,像素坐標(x,y)輸入網絡之前,利用三角函數對其進行類似傅里葉變換操作。
與VIT不同之處在于,VIT進行位置編碼是使網絡能夠注意到圖像塊之間的相對位置信息。NeRF是為了帶訓練優化的場函數mlp可以更好地擬合高頻信息,更具體講,神經網絡對于相近的輸入有著相近的輸出,現實中,觀測位置的小變化也會引起觀測結果的細節存在巨大改變。神經網絡可能會以一種偏向于平均的方式進行擬合,反映到渲染結果會形成模糊笑果。引入位置編碼將位置與視角方向映射到高維且高頻空間后,再作為神經網絡輸入,此時微小的輸入變化也會引起編碼結果的巨大變化,間接提高了神經網絡的輸出對于輸入微小變化的敏感度。
2.5 NeRF體素分層采樣(Volume Hierarchical Sampling)
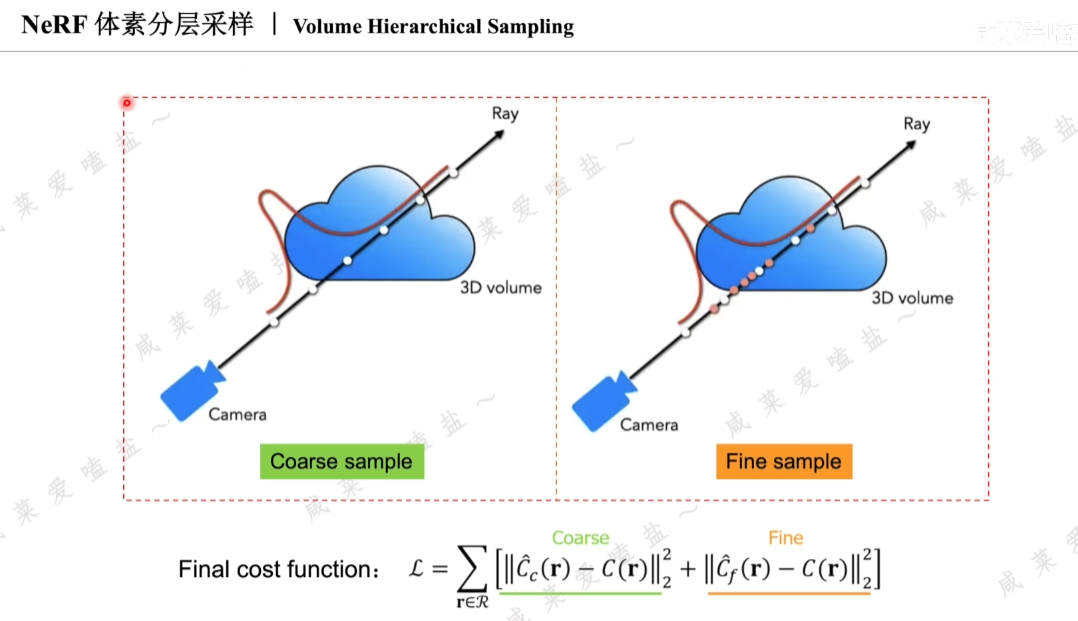
普通情況下密度場中存在大片空白區域,若采用均勻采樣,極有可能導致在信息密集的區域采樣不足,而在無信息的空白區域過度采樣,極大浪費資源(網絡訓練過程中會對空區域進行過度擬合)。
故采用多層級采樣。
首先大尺度采樣,判斷密度場的密度集中區域;
再對密度集中區域進行精細采樣。
最終采樣結果包含兩個部分:粗采樣和精采樣。
2.6 NeRF網絡結構
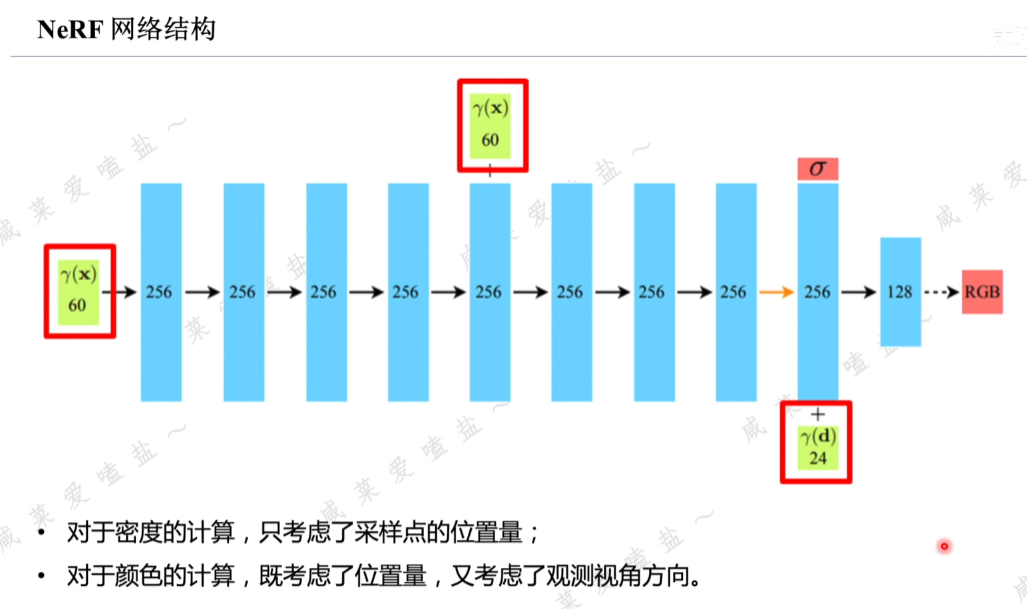
全連接+Relu激活層。
位置編碼后的位置量→5層網絡編碼→再次將位置信息接入到第5層的激活層之后(避免多層編碼后網絡對于原始位置信息的遺忘)→3層全連接,輸出256維的特征向量,解碼該向量可計算出采樣點的體素密度;此處對于密度的計算只考慮采樣點的未知量,對顏色的計算需要考慮未知量和觀測視角方向;即在第9層會將前8層編碼的特征向量與經過位置編碼的視角方向進行串聯→隨后經過128維的全連接層→最后輸出網絡預測的在相應空間位置與觀測視角相關的采樣點顏色。
其中位置編碼后的坐標由原來的三維升維到60維,視角方向編碼由2維升到24維。
2.7 NeRF總結

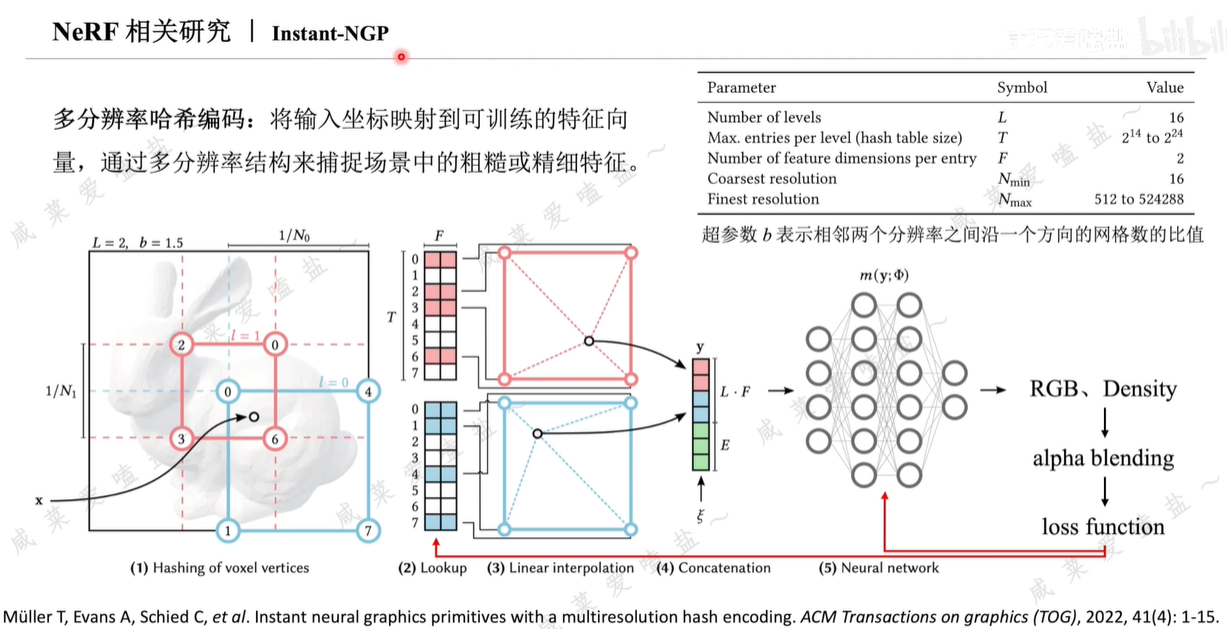
2.8 NeRF相關研究
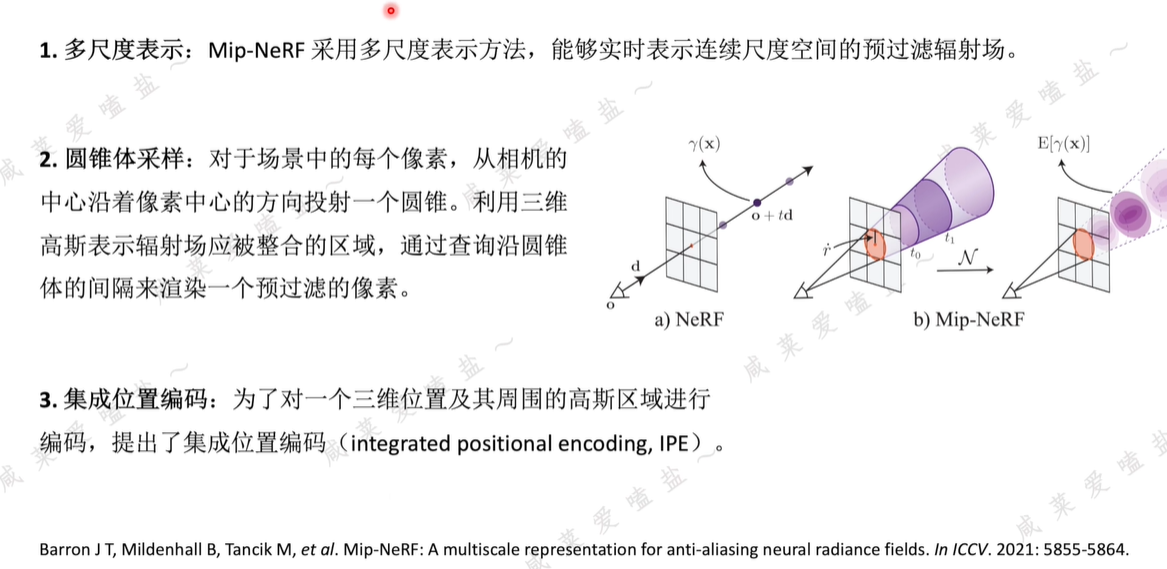
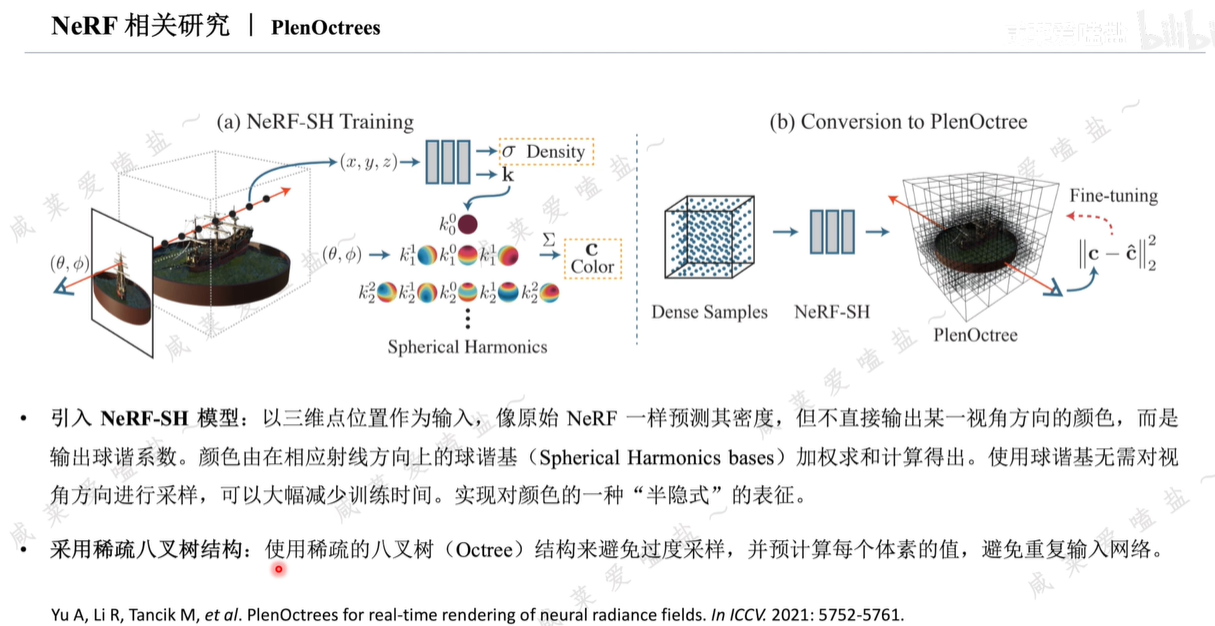
Nvidia提出,NeRF研究工作者集大成之作。
三、3DGS
3.1 3DGS"顯示"三維特征

- 1、各向異色的3DGS經過訓練后仍然保留了原始的三維幾何信息,NeRF不具備,因為NeRF的渲染是通過對神經輻射場中的采樣點經過MLP解碼實現,其實際上是將三維點的位置信息隱藏在了訓練好的MLP中,不利于直觀理解。
3DGS重建場景放大可看到很多半透明橢球疊加,可從細節上擬合細節處紋理,進而展現逼真渲染效果。

- 2、NeRF是依賴黑盒式神經網絡構建依賴關系。
3.2 3DGS原理介紹

- 將3DGS重建場景投射到不同視角的相機平面,顏色形狀均都是不同的。其中形狀的各向異性,是由于它本身是一個三維橢球而非正球體;顏色的各向異性則是通過球諧函數實現。
- 可實現快速的拋雪球渲染與反向傳播。拋雪球計算機圖形學中經典概念,把三維點視作雪球朝相機平面進行潑灑,雪球在平面擴散開,當有很多大大小小不同形狀、顏色各異的雪球進行潑灑和疊加時便形成期望渲染的圖像。這種方法無需像NeRF一樣進行光線采樣。這是3DGS比NeRF更快的主要原因之一。另外,這樣的拋濺過程顯示可微,因此3DGS源碼無論在前向渲染還是梯度反向傳播階段均利用cuda手動計算而非深度學習中常用的pytorch自動求梯度的方式。
- 根據反向傳播計算出的梯度,自適應調整3DGS的數量。若空間某一處的3DGS太大,無法擬合高紋理區域的細節,則像細胞一樣分裂成兩個或多個。
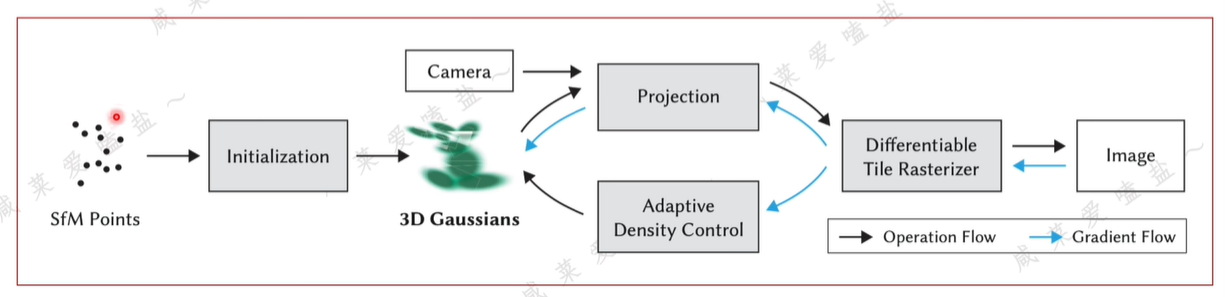
- 首先從一組圖像中恢復出場景的系數點云和相機位姿,這一過程通常是通過colmap實現。
- 利用點云初始化3DGS,即賦予其初始的顏色、尺寸、不透明度等屬性。
- 利用相機內外參將3DGS投影到相機平面
- 利用可微的光柵化方法渲染得到一張圖像。有了圖像后即可與相應的真值圖像進行比對,計算損失函數。并沿藍色箭頭反傳梯度。
- 梯度兩個作用。其一,用來更新3DGS的屬性值,即上方藍色箭頭傳播方向;其二,用來指導自適應密度控制,通過對梯度進行一定的閾值判斷來決定各個3DGS到底是分裂克隆還是刪除。
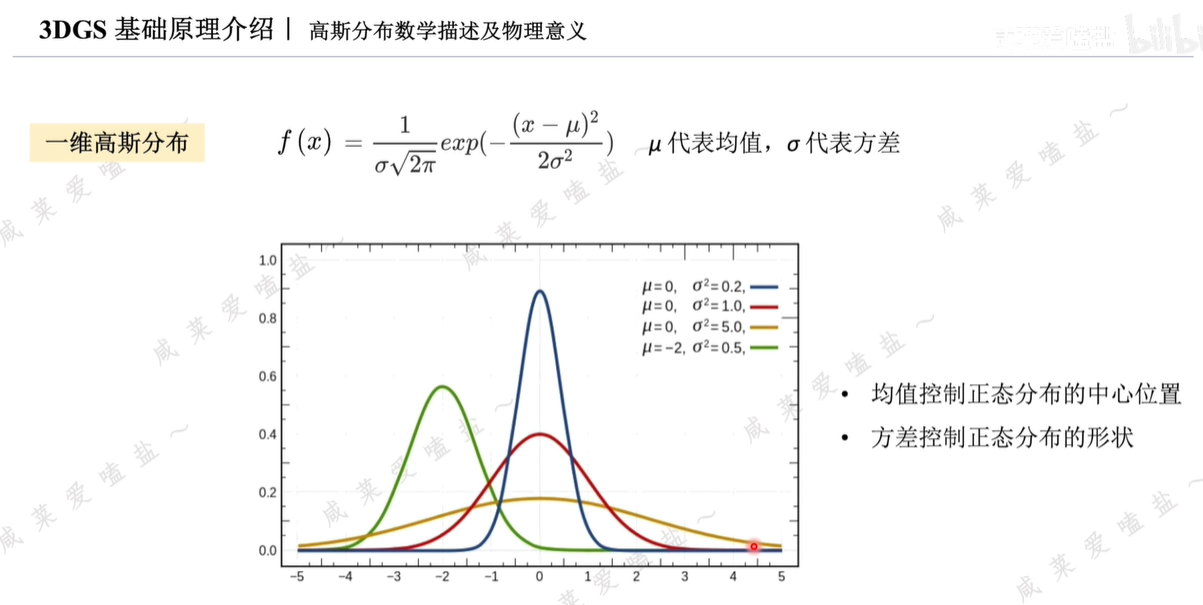
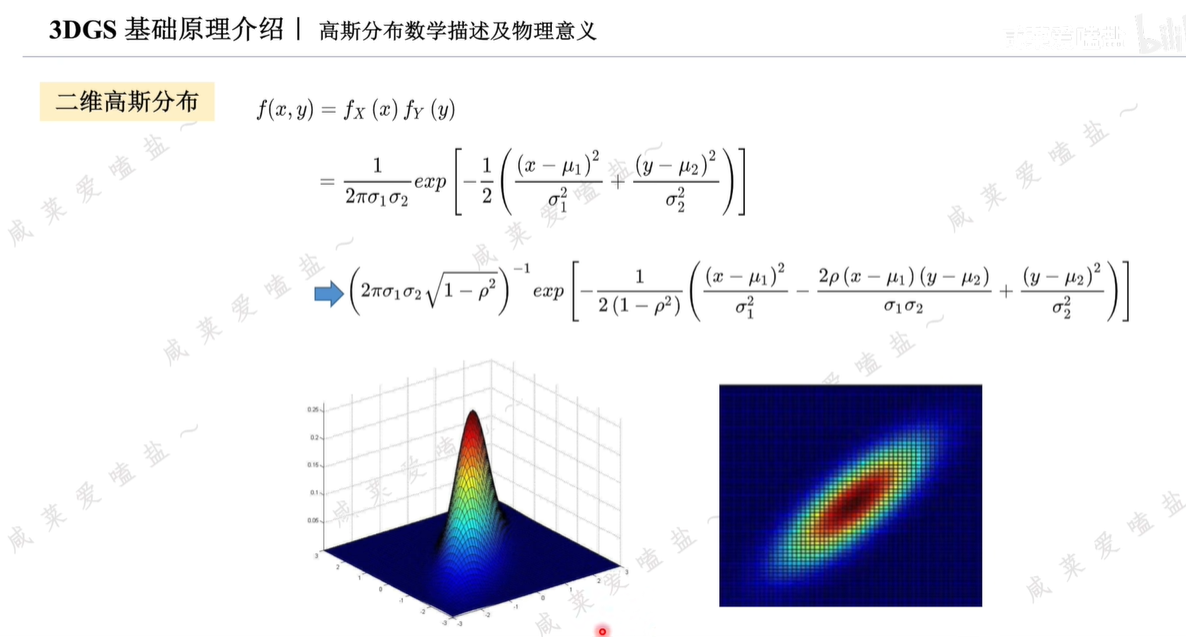
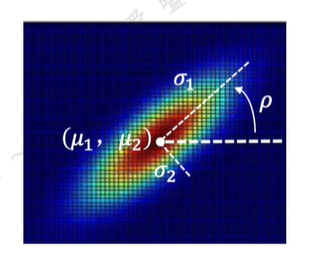
二維高斯分布大體呈現橢圓形狀,離橢圓中心越遠的地方數值越小。
均值和方差依舊用來控制概率分布的中心位置與形狀;增加的相關系數ρ控制該分布的旋轉角度。
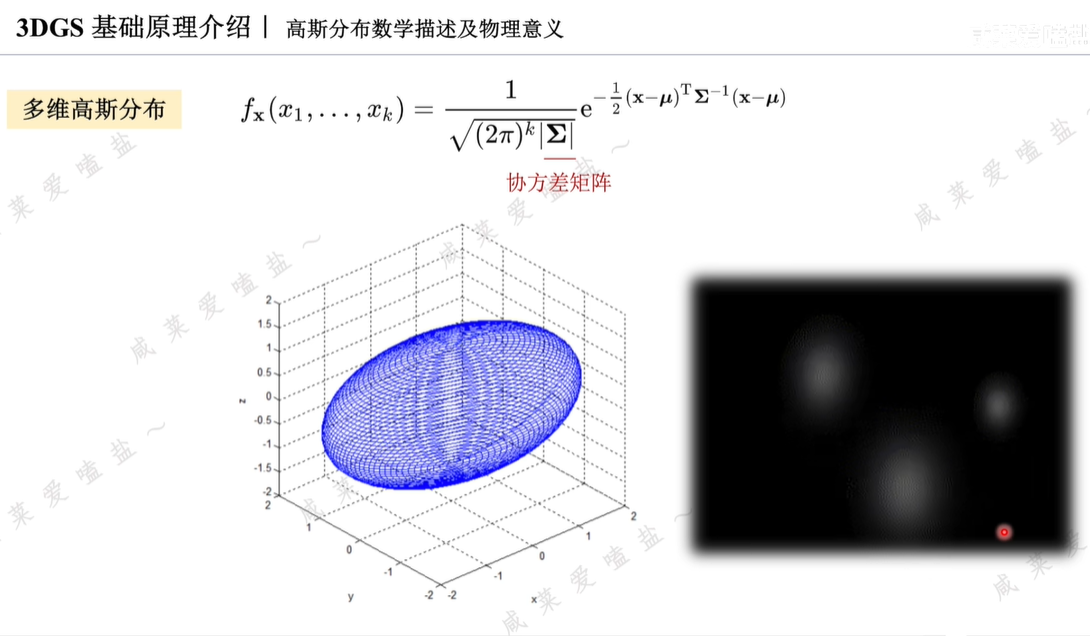
三維高斯分布類似一個橢球,橢球在三維空間中的位置由均值決定,形狀和姿態由協方差矩陣決定。
考慮到標準三維高斯分布的形狀是正球體,而任意圓球都可以通過仿射變換變為橢球,所以實際上協方差矩陣就是從標準高斯分布到任意高斯分布的仿射變換,因此可將協方差矩陣進一步拆解為尺度矩陣與旋轉矩陣的組合形式。

R為旋轉矩陣,一個行列式唯一的正交矩陣;
S為尺度矩陣,一個三維的對角矩陣,對角線的元素對應橢球三個主軸的縮放尺度。
此處協方差矩陣的拆解還有另一個好處,高斯分布要求協方差矩陣式半正定的,但隨著訓練優化的不斷進行,直接對協方差矩陣做梯度下降時無法保證這一特性,而將其進行拆解為縮放和旋轉矩陣即有效保證協方差矩陣的半正定性。
更詳細數學推導可見博文:場景重建——3DGS重建和閉環仿真相關概念綜述。
除了位置和形狀,3DGS還具備顏色和不透明度(此處和NeRF一致)。
- 顏色

球諧函數,一組定義在球面上的特殊函數。在計算機圖形學領域,通常用它來表示近似的光照或顏色的分布。
階數l為0時,止嘔一個球諧基且為常數,也就是說無論輸入的方式是什么永遠返回一個固定顏色;當階數升高時,對應球諧系數變多,且數值依賴于輸入的視角方向,這就意味著可以用它來實現各向異性的顏色表示。
在3DGS源代碼中,初始球諧函數階數設為0,隨著訓練優化過程的進行,逐步增加到3,初始設為0是由于在訓練初始階段相較于3DGS的顏色,其位置信息更能影響渲染質量。因此為了提高訓練效率,在初始階段會將球諧函數階數設為0。最終增長到階數3后不會再繼續增長,因為一般情況下,三階的球諧函數已可以擬合絕大多數場景的各向異性的顏色細節。
3階情況下,各個球諧基的具體公式:
一共16個球諧基,每一組球諧基對應RGB3原色中的一個,為了形成最終的顏色,需要訓練的球諧系數16*3=48個。
3DGS模型需要優化的屬性值。

在優化過程中,算法會根據反傳回來的梯度,也就是損失函數相對于以上各個屬性的偏導數不斷更新迭代這些變量。
3.3 3DGS前向渲染
3.3.1 坐標系變換
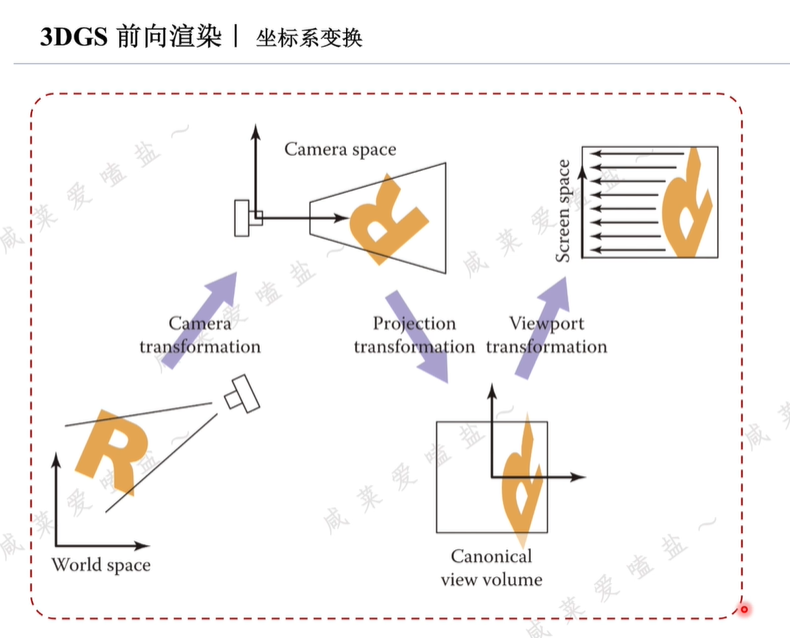
傳統圖形學渲染管線中,坐標系變換用于將世界坐標系中的3D位置信息映射到圖像空間,這個流程主要由三部分組成:
-
相機變換,剛體變換,一般通過旋轉矩陣與位移向量將物體從世界坐標系轉換至相機坐標系。
-
投影變換,相機空間中的點映射到xyz三個坐標范圍都在-1~1之間的立方體中,該立方體被視為規范化視圖體積,即NDC標準化坐標。
在針孔攝像模型假設前提下,所以實際上存在一個如下上方視椎體,在該視椎體里,發射的光線并不是平行的,在原始NeFR中不存在次問題,因為NeRF本來就是從每條不同方向的光線上進行采樣,再通過查詢的方式來確認相應坐標的采樣點的屬性等。
但在3DGS中,每次都計算不同方向的射線和哪些高斯橢球有接觸是比較麻煩的,所以希望能在一個對于不同光線都是平行的空間里完成這一步驟,如此,便不需要每次都計算光線和高斯是否接觸。
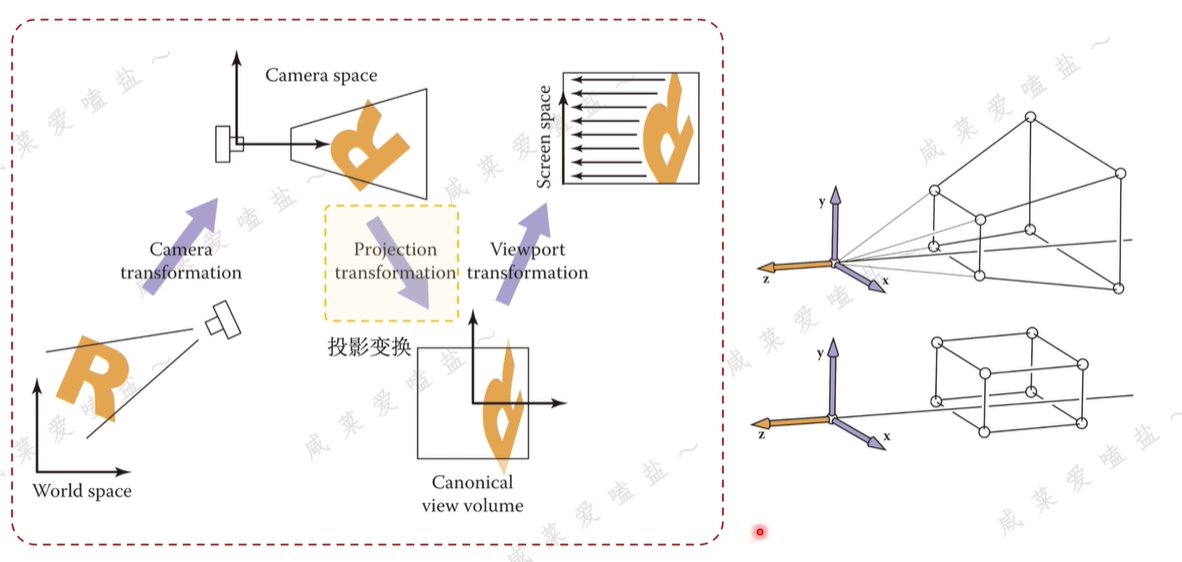
-
視角變換,viewpoint transformation。用來將NDC標準立方體沿Z軸壓扁,并將得到的22正方形映射到WH的屏幕空間。
與傳統SLAM不同在于,傳統視覺SLAM在做完世界坐標系to相機坐標系的轉化后會利用內參矩陣直接將三維點投影到相機的歸一化平面。
橢球投影到平面

Σ:3DGS的三維協方差矩陣。
Σ’:投影到2D屏幕后的二維協方差矩陣。
W:從世界坐標系到相機坐標系的轉換矩陣,即相機變化。
J:投影變換的一階導數,即雅克比矩陣。
大致思路:三維橢球體經過仿射變換后投影到二維平面,呈現的不一定是橢圓,而是如圖右側呈現出局部被扭曲的形狀,而為了后續方便計算,希望投影結果仍然是一個橢圓形,也就是繼續用二維協方差矩陣表示。
所以需要采取一定的近似方法,便引入了對投影變換的局部反射近似。其本質是對該過程進行一個一階泰勒展開。
通過以上過程,即可獲知將3D高斯潑濺到屏幕所產生的2D高斯位置信息。
3.3.2 顏色渲染(alpha-blending)
在計算顏色之前,需要首先計算潑濺的2DGS在屏幕上會影響哪些像素,而被影響的像素應該呈現怎樣的透明度呢?
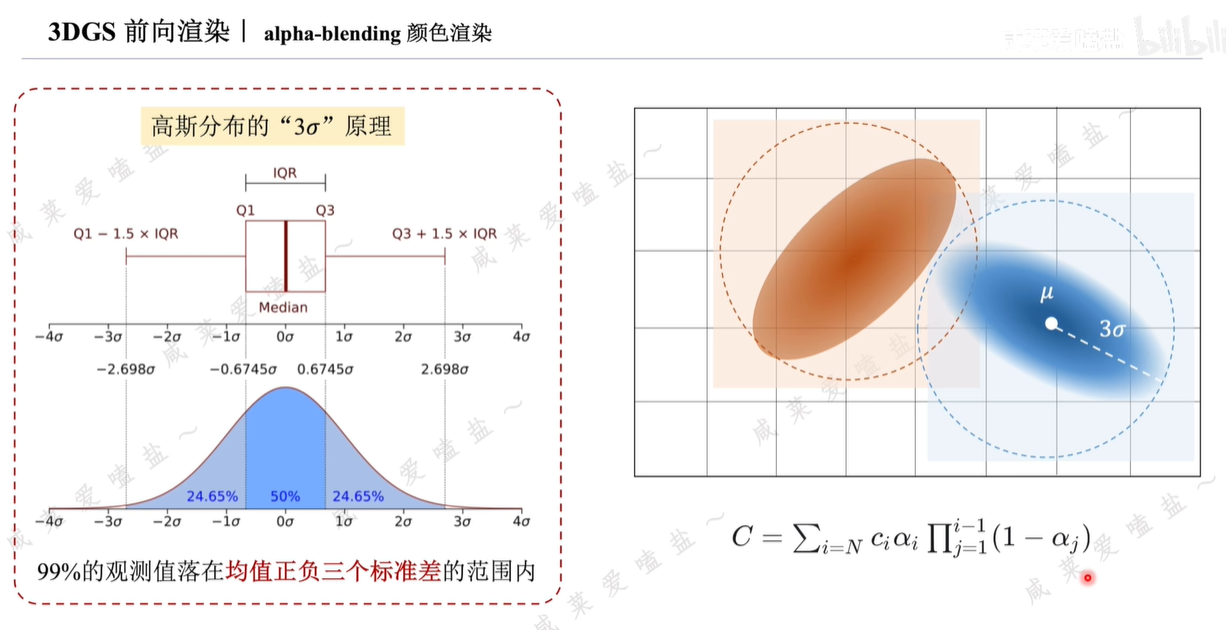
論文中利用高斯分布的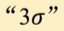 原理,即服從正態分布的隨機變量有99%或幾乎所有的觀測值都會落在均值正負3三個標準差的范圍范圍內。
原理,即服從正態分布的隨機變量有99%或幾乎所有的觀測值都會落在均值正負3三個標準差的范圍范圍內。
具體來說,首先以均值為中心,取2D高斯的長軸,即較大的標準差,它的三倍為半徑做圓,以此劃定高斯分布對周邊的影響范圍。距離2DGS中心越遠的像素其透明度也應該越低。
隨后通過alpha-blending渲染,給定任意像素位置,可通過前面講的投影變換計算出像素與所有影響到它的3DGS的距離,即這些高斯的深度。目的是形成一個經過排序的高斯列表。便可以利用alpha-blending的方式來計算該像素的顏色。
N高斯點顏色的加權和就是該像素最終的顏色C。α是最終的不透明度,它是通過3DGS的不透明度和2D高斯的概率分布密度決定,對應物理含義為高斯點在概率密度越低的地方越不可見。
逐像素渲染較慢。
3.3.3 按圖像塊Tile并行化渲染
為了實現快速光柵化而做的并行化操作。
為了降低為每個像素計算有序列表的計算成本,3DGS將精度從像素級別轉移到塊級別。如上圖圖(b)所示,3D高斯最初將圖像劃為多個不重疊的圖像塊,這些圖像塊在論文中成為Tile。每個塊包含16*16像素。
3DGS進一步確定哪些圖像塊與這些投影的高斯,也就是2D橢圓相交。考慮到一個投影的高斯可能覆蓋多個塊,一種合理的方式是復制高斯,為每個副本分配一個標識符即塊的ID。
復制后如圖(c)所示,3D高斯會將各自的塊ID與每個高斯視圖變換得到的深度值結合,得到一個未排序的字節列表,其中高位代表塊ID,低位表示深度。如此,排序后的列表就可直接用于渲染,如圖(c)和圖(d)所示。
每個塊和像素的渲染都是獨立進行的,因此這一過程非常適合并行計算,這樣做的另一個好處是每個塊的像素都可以訪問一個公共的共享內存,并保持一個統一的讀取系列,從而提高渲染的并行執行效率。
至此已可以利用3DGS渲染出建模后的三維世界的圖片,再計算其與真實圖片的差異,也就是loss function,見下節。
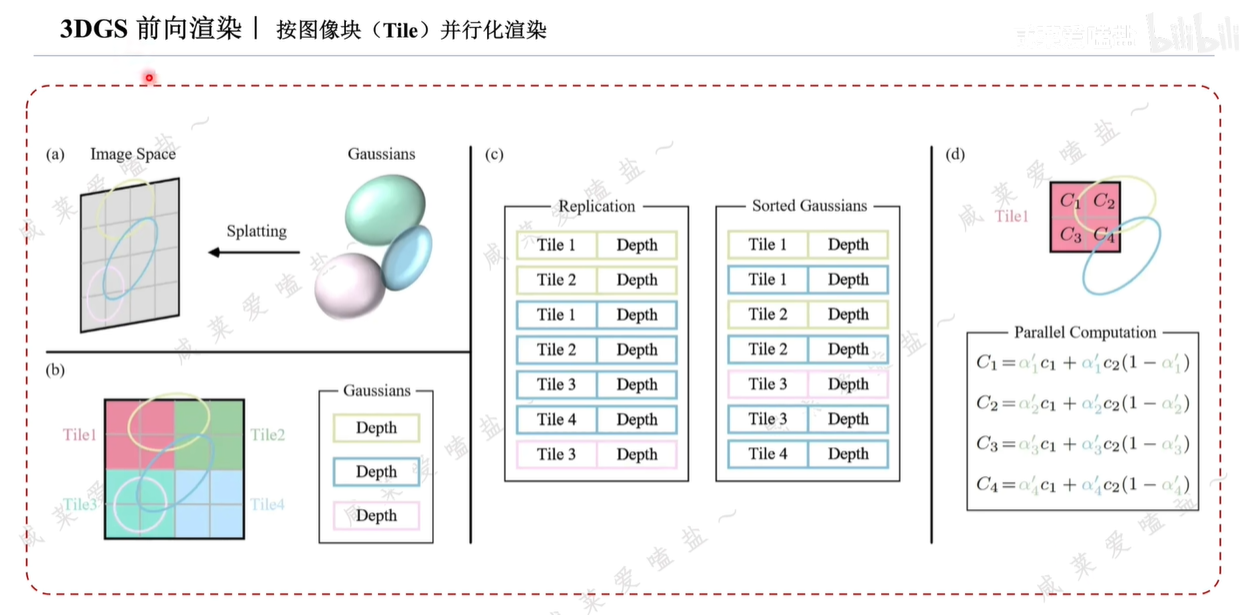
3.4 3DGS優化訓練過程
反向傳播梯度:更新優化3D高斯的均值、協方差矩陣、不透明度和球諧函數并指導3D高斯群體的自適應密度的控制策略。
D-SSIM:基于結構相似性的損失函數,同時考慮深度信息,可以衡量兩個圖片在結構亮度對比度上的相似性。
自適應密度控制策略包括三種:
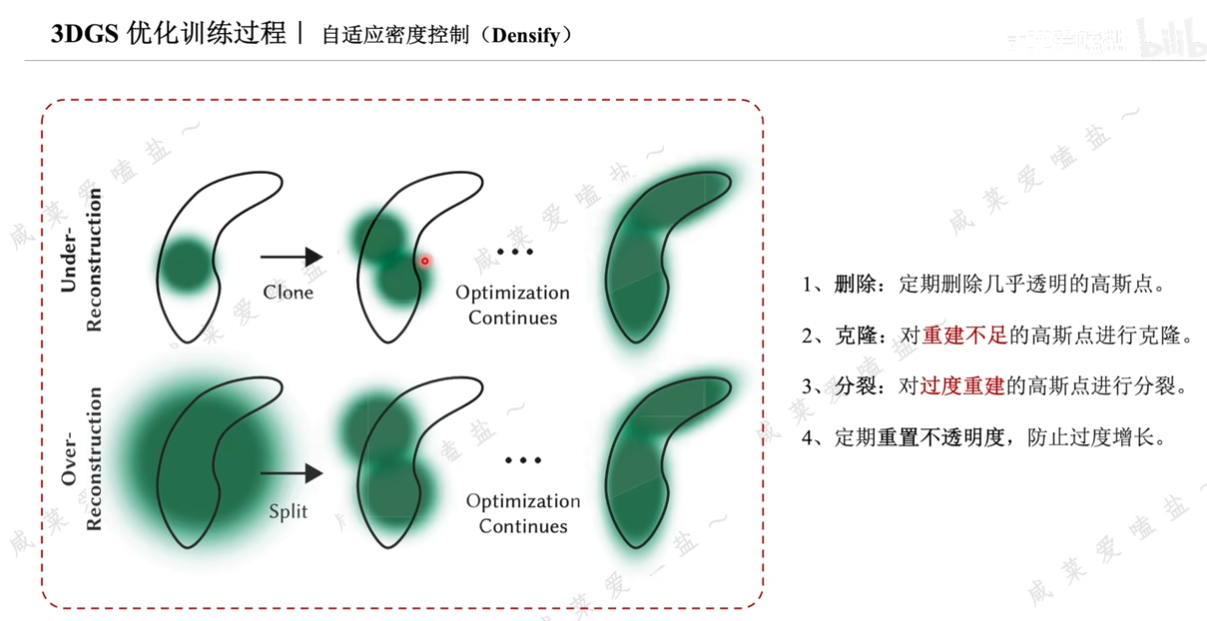
- 每100次迭代會刪除幾乎透明的高斯點,不透明度α小于一定閾值的3D高斯;克隆一個相同大小的副本,并沿著位置梯度方向進行擺放;分裂可能會導致密度不合理的增加,所以采用4,每迭代3000次,重置不透明度。
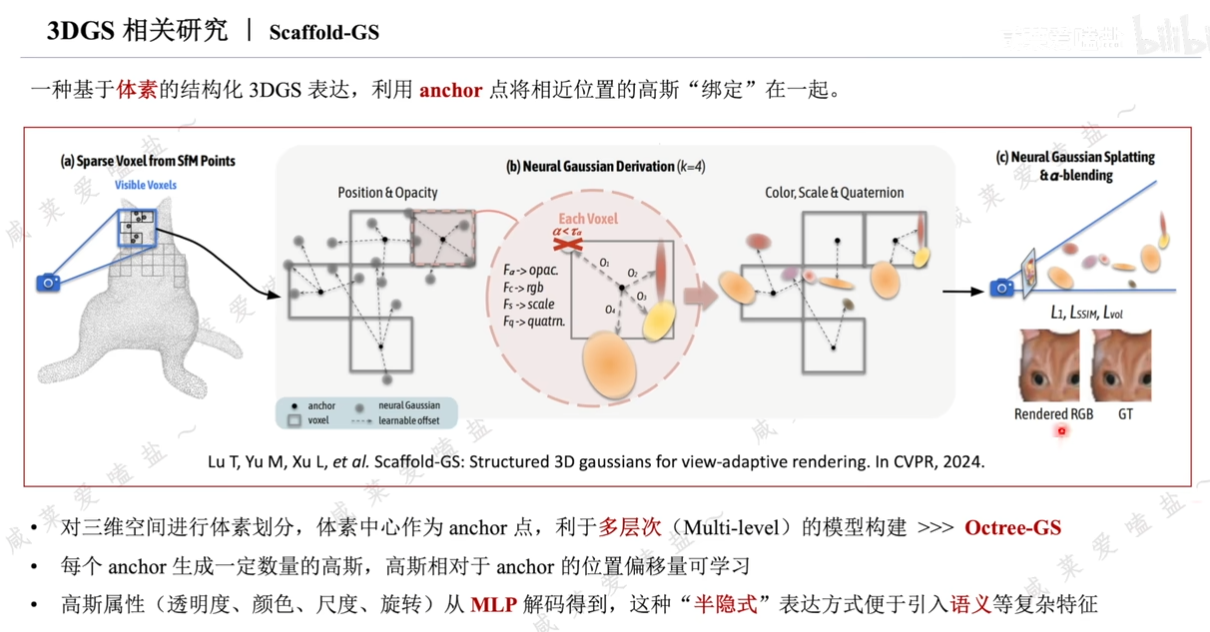
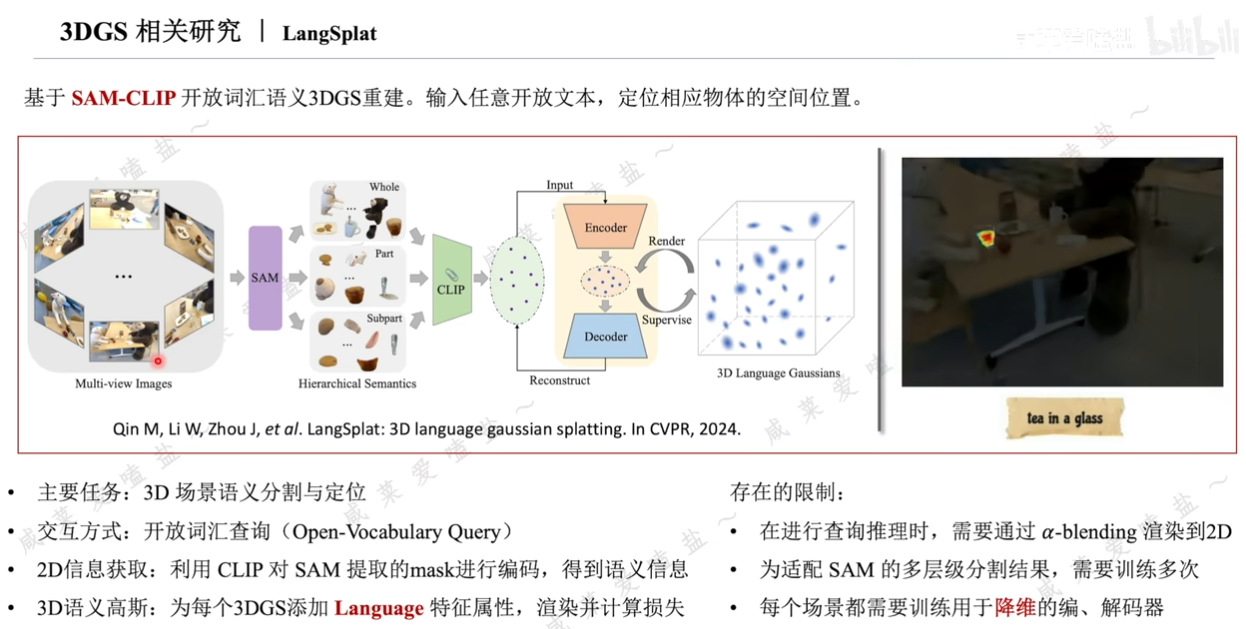
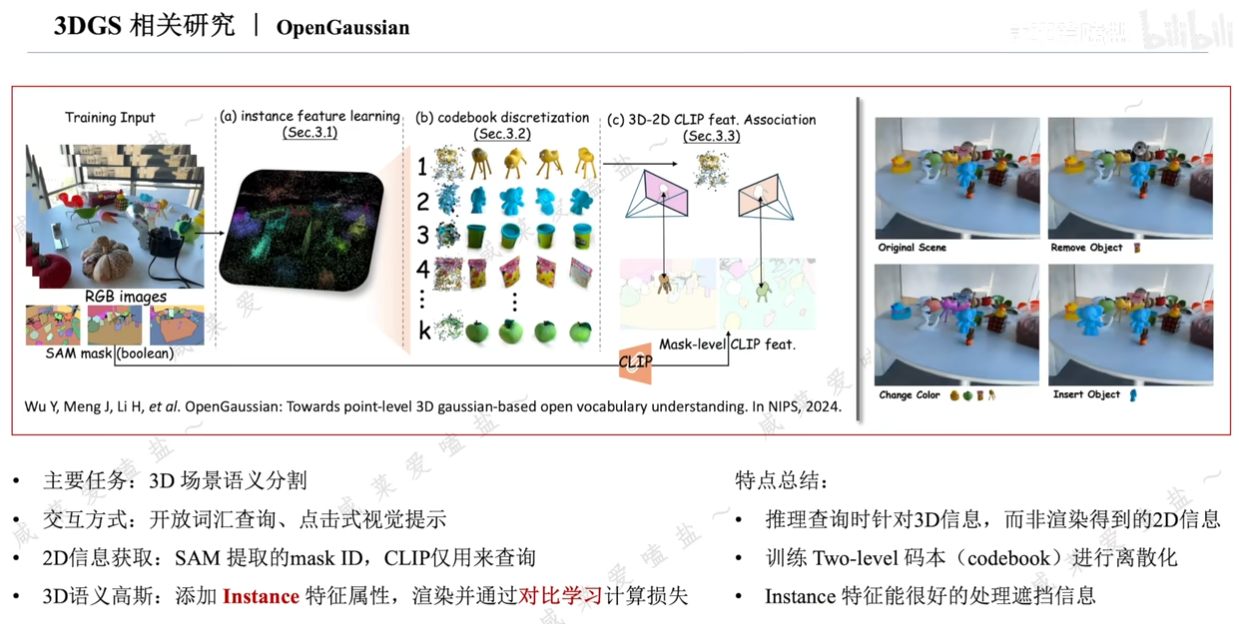
3.5 3DGS相關研究

3.6 3DGS相關研究點
up主講得很好:3DGS原理

)










-實現四層負載均衡)




:sqlmap快速上手)

