本文目錄:
- 一、案例介紹
- (一)關于人名分類
- (二)人名分類數據預覽
- 二、案例步驟
- (一)導入工具包
- (二)數據預處理
- 1. 獲取常用的字符數量
- 2. 國家名種類數和個數
- 3.讀數據到內存
- 4.構建數據源NameClassDataset
- 5.構建迭代器遍歷數據
- 三、構建RNN模型(選擇LSTM模型)
- (一)構建模型
- (二)模型測試
- 四、構建訓練函數并進行訓練
- (一)構建RNN訓練函數
- (二)LSTM模型訓練
- (三)模型訓練日志數據制圖
- (四)模型訓練結果分析
- 1.損失對比曲線分析
- 2 .訓練耗時分析
- 3. 訓練準確率分析
- 4.結論
- 五、模型預測
- 最后,附贈代碼完整版(包括傳統RNN、LSTM和GRU建模及預測)
前言:前面介紹了傳統RNN、LSTM、GRU,本篇文章分享綜合案例。
一、案例介紹
(一)關于人名分類
以一個人名為輸入, 使用模型幫助我們判斷它最有可能是來自哪一個國家的人名, 這在某些國際化公司的業務中具有重要意義, 在用戶注冊過程中, 會根據用戶填寫的名字直接給他分配可能的國家或地區選項, 以及該國家或地區的國旗, 限制手機號碼位數等等。
(二)人名分類數據預覽
數據存放路徑:$(home)/data/name_classfication.txt
數據格式說明 每一行第一個單詞為人名,第二個單詞為國家名。中間用制表符tab分割。
Huffmann German
Hummel German
Hummel German
Hutmacher German
Ingersleben German
Jaeger German
Jager German
Deng Chinese
Ding Chinese
Dong Chinese
Dou Chinese
Duan Chinese
Eng Chinese
Fan Chinese
Fei Chinese
Abaimov Russian
Abakeliya Russian
Abakovsky Russian
Abakshin Russian
Abakumoff Russian
Abakumov Russian
Abakumtsev Russian
Abakushin Russian
Abalakin Russian二、案例步驟
整個案例的實現可分為以下五個步驟:
第一步導入必備的工具包
第二步對data文件中的數據進行處理,滿足訓練要求
第三步構建RNN模型(選擇 LSTM)
第四步構建訓練函數并進行訓練
第五步構建預測函數并進行預測
(一)導入工具包
# 導入torch工具
import torch
# 導入nn準備構建模型
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 導入torch的數據源 數據迭代器工具包
from torch.utils.data import Dataset, DataLoader
# 用于獲得常見字母及字符規范化
import string
# 導入時間工具包
import time
# 引入制圖工具包
import matplotlib.pyplot as plt
# 從io中導入文件打開方法
from io import open(二)數據預處理
這里需要對data文件中的數據進行處理,滿足訓練要求。
1. 獲取常用的字符數量
# 獲取所有常用字符包括字母和常用標點
all_letters = string.ascii_letters + " .,;'"# 獲取常用字符數量
n_letters = len(all_letters)print("n_letter:", n_letters)運行結果:
n_letter: 572. 國家名種類數和個數
# 國家名 種類數
categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese','French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 國家名 個數
categorynum = len(categorys)
print('categorys--->', categorys)運行結果:
categorys---> ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese', 'French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
categorynum---> 183.讀數據到內存
# 思路分析
# 1 打開數據文件 open(filename, mode='r', encoding='utf-8')
# 2 按行讀文件、提取樣本x 樣本y line.strip().split('\t')
# 3 返回樣本x的列表、樣本y的列表 my_list_x, my_list_y
def read_data(filename):my_list_x, my_list_y= [], []# 打開文件with open(filename, mode='r', encoding='utf-8') as f:# 按照行讀數據for line in f.readlines():if len(line) <= 5:continue# 按照行提取樣本x 樣本y(x, y) = line.strip().split('\t')my_list_x.append(x)my_list_y.append(y)# 打印樣本的數量print('my_list_x->', len(my_list_x))print('my_list_y->', len(my_list_y))# 返回樣本x的列表、樣本y的列表return my_list_x, my_list_y4.構建數據源NameClassDataset
# 原始數據 -> 數據源NameClassDataset --> 數據迭代器DataLoader
# 構造數據源 NameClassDataset,把語料轉換成x y
# 1 init函數 設置樣本x和y self.my_list_x self.my_list_y 條目數self.sample_len
# 2 __len__(self)函數 獲取樣本條數
# 3 __getitem__(self, index)函數 獲取第幾條樣本數據
# 按索引 獲取數據樣本 x y
# 樣本x one-hot張量化 tensor_x[li][all_letters.find(letter)] = 1
# 樣本y 張量化 torch.tensor(categorys.index(y), dtype=torch.long)
# 返回tensor_x, tensor_y
class NameClassDataset(Dataset):def __init__(self, my_list_x, my_list_y):# 樣本xself.my_list_x = my_list_x# 樣本yself.my_list_y = my_list_y# 樣本條目數self.sample_len = len(my_list_x)# 獲取樣本條數def __len__(self):return self.sample_len# 獲取第幾條 樣本數據def __getitem__(self, index):# 對index異常值進行修正 [0, self.sample_len-1]index = min(max(index, 0), self.sample_len-1)# 按索引獲取 數據樣本 x yx = self.my_list_x[index]y = self.my_list_y[index]# 樣本x one-hot張量化tensor_x = torch.zeros(len(x), n_letters)# 遍歷人名 的 每個字母 做成one-hot編碼for li, letter in enumerate(x):# letter2indx 使用all_letters.find(letter)查找字母在all_letters表中的位置 給one-hot賦值tensor_x[li][all_letters.find(letter)] = 1# 樣本y 張量化tensor_y = torch.tensor(categorys.index(y), dtype=torch.long)# 返回結果return tensor_x, tensor_y分析
文本張量化,這里也就是人名張量化是通過one-hot編碼來完成。
# 將字符串(單詞粒度)轉化為張量表示,如:"ab" --->
# tensor([[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0.]],# [[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0.]]])5.構建迭代器遍歷數據
def dm_test_NameClassDataset():# 1 獲取數據myfilename = './data/name_classfication.txt'my_list_x, my_list_y = read_data(myfilename)print('my_list_x length', len(my_list_x))print('my_list_y length', len(my_list_y))# 2 實例化dataset對象nameclassdataset = NameClassDataset(my_list_x, my_list_y)# 3 實例化dataloadermydataloader = DataLoader(dataset=nameclassdataset, batch_size=1, shuffle=True)for i, (x, y) in enumerate (mydataloader):print('x.shape', x.shape, x)print('y.shape', y.shape, y)break運行結果:
my_list_x length 20074
my_list_y length 20074
x.shape torch.Size([1, 5, 57]) tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0.],[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0.],[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0.],[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0.]]])
y.shape torch.Size([1]) tensor([15])三、構建RNN模型(選擇LSTM模型)
(一)構建模型
# LSTM類 實現思路分析:
# 1 init函數 準備三個層 self.rnn self.linear self.softmax=nn.LogSoftmax(dim=-1)
# def __init__(self, input_size, hidden_size, output_size, num_layers=1)# 2 forward(input, hidden)函數
# 讓數據經過三個層 返回softmax結果和hn
# 形狀變化 [seqlen,1,57],[1,1,128]) -> [seqlen,1,128],[1,1,128]# 3 初始化隱藏層輸入數據 inithidden()
# 形狀[self.num_layers, 1, self.hidden_size]
class LSTM(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super(LSTM, self).__init__()# 1 init函數 準備三個層 self.rnn self.linear self.softmax=nn.LogSoftmax(dim=-1)self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_sizeself.num_layers = num_layers# 定義rnn層self.rnn = nn.LSTM(self.input_size, self.hidden_size, self.num_layers)# 定義linear層self.linear = nn.Linear(self.hidden_size, self.output_size)# 定義softmax層self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden, c):# 讓數據經過三個層 返回softmax結果和 hn c# 數據形狀 [6,57] -> [6,1,52]input = input.unsqueeze(1)# 把數據送給模型 提取事物特征# 數據形狀 [seqlen,1,57],[1,1,128], [1,1,128]) -> [seqlen,1,18],[1,1,128],[1,1,128]rr, (hn, cn) = self.rnn(input, (hidden, c))# 數據形狀 [seqlen,1,128] - [1, 128]tmprr = rr[-1]tmprr = self.linear(tmprr)return self.softmax(tmprr), hn, cndef inithidden(self):# 初始化隱藏層輸入數據 inithidden()hidden = c = torch.zeros(self.num_layers, 1, self.hidden_size)return hidden, c(二)模型測試
def dm_test_rnn_lstm_gru():# one-hot編碼特征57(n_letters),也是RNN的輸入尺寸input_size = 57# 定義隱層的最后一維尺寸大小n_hidden = 128# 輸出尺寸為語言類別總數n_categories # 1個字符預測成18個類別output_size = 18# 1 獲取數據myfilename = './data/name_classfication.txt'my_list_x, my_list_y = read_data(myfilename)print('categorys--->', categorys)# 2 實例化dataset對象nameclassdataset = NameClassDataset(my_list_x, my_list_y)# 3 實例化dataloadermydataloader = DataLoader(dataset=nameclassdataset, batch_size=1, shuffle=True)my_lstm = LSTM(n_letters, n_hidden, categorynum)print('lstm 模型', my_lstm)for i, (x, y) in enumerate (mydataloader):# print('x.shape', x.shape, x)# print('y.shape', y.shape, y)hidden, c = my_lstm.inithidden()output, hidden, c = my_lstm(x[0], hidden, c)print("lstm output.shape--->:", output.shape, output)if (i == 0):break
運行結果:
lstm 模型 LSTM((rnn): LSTM(57, 128)(linear): Linear(in_features=128, out_features=18, bias=True)(softmax): LogSoftmax(dim=-1)
)
lstm output.shape--->: torch.Size([1, 18]) tensor([[-2.9283, -3.0017, -2.8902, -2.8179, -2.8484, -2.8152, -2.9654, -2.8846,-2.8642, -2.8602, -2.8860, -2.9505, -2.8806, -2.9436, -2.8388, -2.9312,-2.9241, -2.8211]], grad_fn=<LogSoftmaxBackward0>)四、構建訓練函數并進行訓練
(一)構建RNN訓練函數
# 思路分析
# 從文件獲取數據、實例化數據源對象nameclassdataset 數據迭代器對象mydataloader
# 實例化模型對象my_rnn 損失函數對象mycrossentropyloss=nn.NLLLoss() 優化器對象myadam
# 定義模型訓練的參數
# starttime total_iter_num total_loss total_loss_list total_acc_num total_acc_list
# 外層for循環 控制輪數 for epoch_idx in range(epochs)
# 內層for循環 控制迭代次數 for i, (x, y) in enumerate(mydataloader)# 給模型喂數據 # 計算損失 # 梯度清零 # 反向傳播 # 梯度更新# 計算輔助信息 # 累加總損失和準確數 每100次訓練計算一個總體平均損失 總體平均準確率 每2000次訓練 打印日志# 其他 # 預測對錯 i_predit_tag = (1 if torch.argmax(output).item() == y.item() else 0)# 模型保存# torch.save(my_rnn.state_dict(), './my_rnn_model_%d.bin' % (epoch_idx + 1))
# 返回 平均損失列表total_loss_list, 時間total_time, 平均準確total_acc_list(二)LSTM模型訓練
def my_train_lstm():# 獲取數據myfilename = './data/name_classfication.txt'my_list_x, my_list_y = read_data(myfilename)# 實例化dataset對象nameclassdataset = NameClassDataset(my_list_x, my_list_y)# 實例化 模型input_size = 57n_hidden = 128output_size = 18my_lstm = LSTM(input_size, n_hidden, output_size)print('my_lstm模型--->', my_lstm)# 實例化 損失函數 adam優化器mycrossentropyloss = nn.NLLLoss()myadam = optim.Adam(my_lstm.parameters(), lr=mylr)# 定義模型訓練參數starttime = time.time()total_iter_num = 0 # 已訓練的樣本數total_loss = 0.0 # 已訓練的損失和total_loss_list = [] # 每100個樣本求一次平均損失 形成損失列表total_acc_num = 0 # 已訓練樣本預測準確總數total_acc_list = [] # 每100個樣本求一次平均準確率 形成平均準確率列表# 外層for循環 控制輪數for epoch_idx in range(epochs):# 實例化dataloadermydataloader = DataLoader(dataset=nameclassdataset, batch_size=1, shuffle=True)# 內層for循環 控制迭代次數for i, (x, y) in enumerate(mydataloader):# 給模型喂數據hidden, c = my_lstm.inithidden()output, hidden, c = my_lstm(x[0], hidden, c)# 計算損失myloss = mycrossentropyloss(output, y)# 梯度清零myadam.zero_grad()# 反向傳播myloss.backward()# 梯度更新myadam.step()# 計算總損失total_iter_num = total_iter_num + 1total_loss = total_loss + myloss.item()# 計算總準確率i_predit_tag = (1 if torch.argmax(output).item() == y.item() else 0)total_acc_num = total_acc_num + i_predit_tag# 每100次訓練 求一次平均損失 平均準確率if (total_iter_num % 100 == 0):tmploss = total_loss/total_iter_numtotal_loss_list.append(tmploss)tmpacc = total_acc_num/total_iter_numtotal_acc_list.append(tmpacc)# 每2000次訓練 打印日志if (total_iter_num % 2000 == 0):tmploss = total_loss / total_iter_numprint('輪次:%d, 損失:%.6f, 時間:%d,準確率:%.3f' %(epoch_idx+1, tmploss, time.time() - starttime, tmpacc))# 每個輪次保存模型torch.save(my_lstm.state_dict(), './my_lstm_model_%d.bin' % (epoch_idx + 1))# 計算總時間total_time = int(time.time() - starttime)return total_loss_list, total_time, total_acc_list(三)模型訓練日志數據制圖
def dm_test_train_rnn_lstm_gru():total_loss_list_rnn, total_time_rnn, total_acc_list_rnn = my_train_rnn()total_loss_list_lstm, total_time_lstm, total_acc_list_lstm = my_train_lstm()total_loss_list_gru, total_time_gru, total_acc_list_gru = my_train_gru()# 繪制損失對比曲線# 創建畫布0plt.figure(0)# # 繪制損失對比曲線plt.plot(total_loss_list_rnn, label="RNN")plt.plot(total_loss_list_lstm, color="red", label="LSTM")plt.plot(total_loss_list_gru, color="orange", label="GRU")plt.legend(loc='upper left')plt.savefig('./img/RNN_LSTM_GRU_loss2.png')plt.show()# 繪制柱狀圖# 創建畫布1plt.figure(1)x_data = ["RNN", "LSTM", "GRU"]y_data = [total_time_rnn, total_time_lstm, total_time_gru]# 繪制訓練耗時對比柱狀圖plt.bar(range(len(x_data)), y_data, tick_label=x_data)plt.savefig('./img/RNN_LSTM_GRU_period2.png')plt.show()# 繪制準確率對比曲線plt.figure(2)plt.plot(total_acc_list_rnn, label="RNN")plt.plot(total_acc_list_lstm, color="red", label="LSTM")plt.plot(total_acc_list_gru, color="orange", label="GRU")plt.legend(loc='upper left')plt.savefig('./img/RNN_LSTM_GRU_acc2.png')plt.show()模型訓練日志輸出:
輪次:3, 損失:0.805885, 時間:118,準確率:0.759
輪次:3, 損失:0.794148, 時間:123,準確率:0.762
輪次:3, 損失:0.783356, 時間:128,準確率:0.765
輪次:3, 損失:0.774931, 時間:133,準確率:0.767
輪次:3, 損失:0.765427, 時間:137,準確率:0.769
輪次:3, 損失:0.757254, 時間:142,準確率:0.771
輪次:3, 損失:0.750375, 時間:147,準確率:0.773
輪次:3, 損失:0.743092, 時間:152,準確率:0.775
輪次:4, 損失:0.732983, 時間:157,準確率:0.778
輪次:4, 損失:0.723816, 時間:162,準確率:0.780
輪次:4, 損失:0.716507, 時間:167,準確率:0.782
輪次:4, 損失:0.708377, 時間:172,準確率:0.785
輪次:4, 損失:0.700820, 時間:177,準確率:0.787
輪次:4, 損失:0.694714, 時間:182,準確率:0.788
輪次:4, 損失:0.688386, 時間:187,準確率:0.790
輪次:4, 損失:0.683056, 時間:191,準確率:0.791
輪次:4, 損失:0.677051, 時間:196,準確率:0.793
輪次:4, 損失:0.671668, 時間:201,準確率:0.794(四)模型訓練結果分析
1.損失對比曲線分析
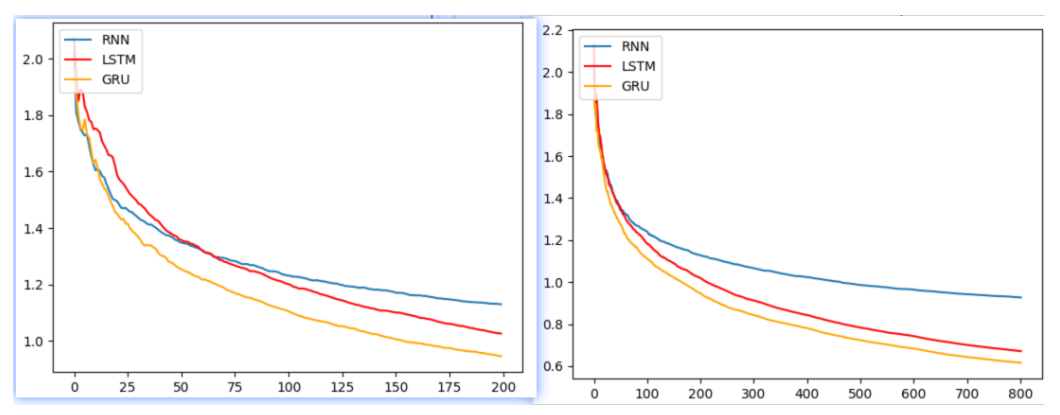
左圖:1個輪次損失對比曲線,右圖4個輪次損失對比曲線
模型訓練的損失降低快慢代表模型收斂程度。由圖可知, 傳統RNN的模型第一個輪次開始收斂情況最好,然后是GRU, 最后是LSTM, 這是因為RNN模型簡單參數少,見效快。隨著訓練數據的增加,GRU效果最好、LSTM效果次之、RNN效果排最后。
所以在以后的模型選用時, 要通過對任務的分析以及實驗對比, 選擇最適合的模型。
2 .訓練耗時分析
訓練耗時對比圖:
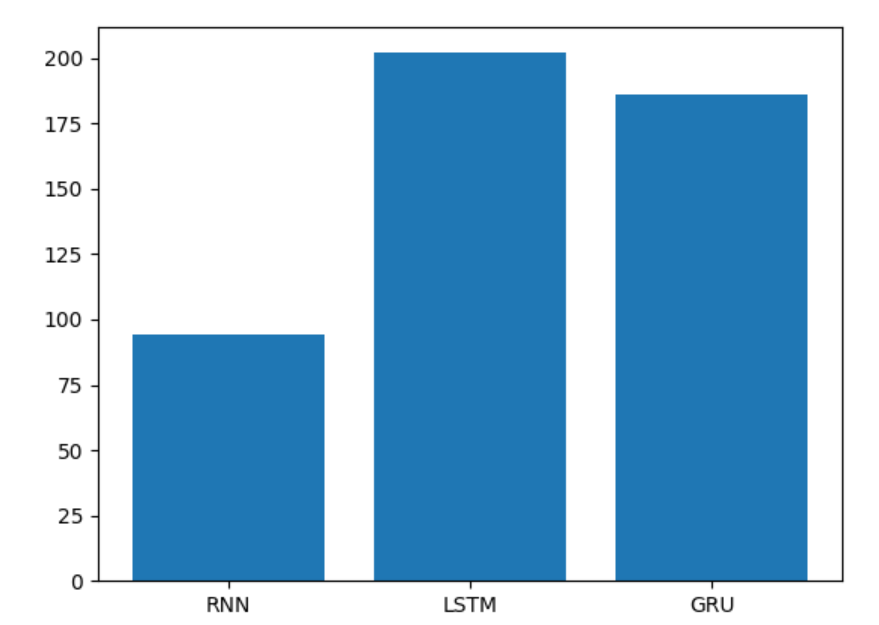
模型訓練的耗時長短代表模型的計算復雜度,由圖可知, 也正如我們之前的理論分析,傳統RNN復雜度最低, 耗時幾乎只是后兩者的一半, 然后是GRU,最后是復雜度最高的LSTM。
3. 訓練準確率分析
訓練準確率對比圖:
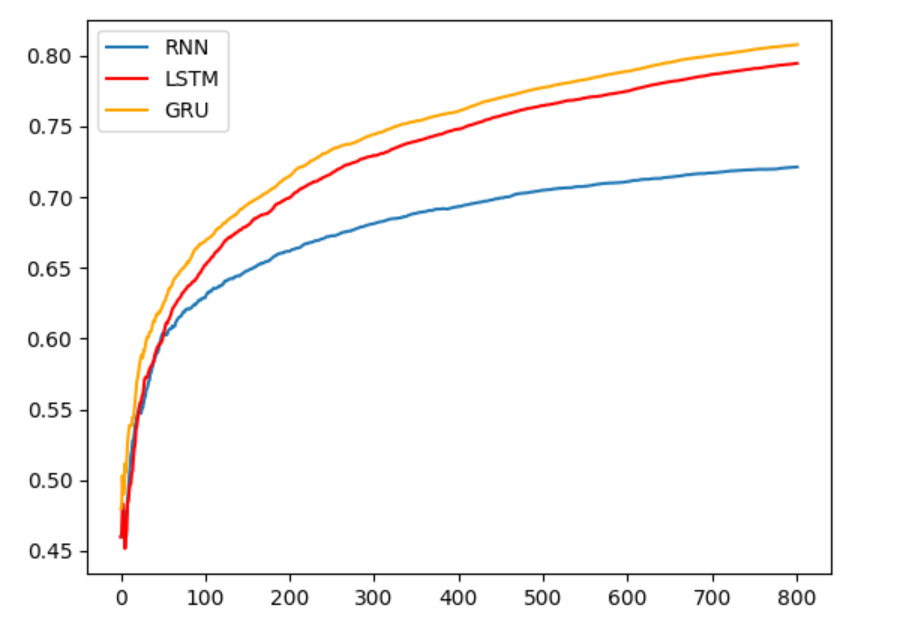
由圖可知, GRU效果最好、LSTM效果次之、RNN效果排最后。
4.結論
模型選用一般應通過實驗對比,并非越復雜或越先進的模型表現越好,而是需要結合自己的特定任務,從對數據的分析和實驗結果中獲得最佳答案。
五、模型預測
def my_predict_lstm(x):n_letters = 57n_hidden = 128n_categories = 18# 輸入文本, 張量化one-hotx_tensor = lineToTensor(x)# 實例化模型 加載已訓練模型參數my_lstm = LSTM(n_letters, n_hidden, n_categories)my_lstm.load_state_dict(torch.load(my_path_lstm))with torch.no_grad():# 模型預測hidden, c = my_lstm.inithidden()output, hidden, c = my_lstm(x_tensor, hidden, c)# 從預測結果中取出前3名# 3表示取前3名, 1表示要排序的維度, True表示是否返回最大或是最下的元素topv, topi = output.topk(3, 1, True)print('rnn =>', x)for i in range(3):value = topv[0][i]category_idx = topi[0][i]category = categorys[category_idx]print('\t value:%d category:%s' % (value, category))print('\t value:%d category:%s' % (value, category))運行結果:
rnn => zhangvalue:0 category:Chinesevalue:-1 category:Russianvalue:-1 category:German
本案例也可以構建傳統rnn模型或者gru模型進行目標完成,具體大家可自行嘗試。
最后,附贈代碼完整版(包括傳統RNN、LSTM和GRU建模及預測)
# -*-coding:utf-8-*-
# 導入torch工具
import torch
# 導入nn準備構建模型
import torch.nn as nn
#導入優化器optim
import torch.optim as optim
# 導入torch的數據源 數據迭代器工具包
from torch.utils.data import Dataset, DataLoader
# 用于獲得常見字母及字符規范化
import string
# 導入時間工具包
import time
# 引入制圖工具包
import matplotlib.pyplot as plt
from tqdm import tqdm
import json# 1.todo: 獲取常用的字符數量
# 此次將人名變成向量的過程:將人名中的每個字母(字符)進行one-hot張量表示,然后拼接代表整個人名的向量表示
# 因為人名的組成大部分都是由大小寫英文字母以及某些特殊的字符組成,這里一個展示是57個,其實就是one-hot編碼的維度all_letters = string.ascii_letters+" .,;'"
print(f'all_letters--》{all_letters}')
print(f'{all_letters.find("A")}')
n_letters = len(all_letters)
print('字符的總個數', n_letters)# 2 todo: 獲取國家的類別個數
# 國家名 種類數
categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese','French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 國家名 個數
categorynum = len(categorys)
print('categorys--->', categorynum)# 3 todo. 讀取數據到內存中
def read_data(filename):# 定義兩個空列表,分別存儲人名和國家名my_list_x, my_list_y = [], []# 讀取數據with open(filename, 'r', encoding='utf-8') as fr:for line in fr.readlines():# 數據清洗if len(line) <= 5:continuex, y = line.strip().split('\t')my_list_x.append(x)my_list_y.append(y)return my_list_x, my_list_y# 4 todo. 構建dataset類
class NameClassDataset(Dataset):def __init__(self, my_list_x, my_list_y):# 如果繼承的父類沒有__init__方法,那么此時可以省略掉super().__init__(),當然要是寫上也不會報錯# super().__init__()# 獲取樣本xself.my_list_x = my_list_x# 獲取樣本x對應的標簽yself.my_list_y = my_list_y# 獲取樣本的長度self.sample_len = len(my_list_x)def __len__(self):return self.sample_lendef __getitem__(self, item):# item代表就是索引index = min(max(item, 0), self.sample_len-1)# 根據索引取出對應的x和yx = self.my_list_x[index]# print(f'x---->{x}')y = self.my_list_y[index]# print(f'y---》{y}')# 初始化全零的一個張量tensor_x = torch.zeros(len(x), n_letters)# 遍歷人名的每個字母變成one-hot編碼for idx, letter in enumerate(x):tensor_x[idx][all_letters.find(letter)] = 1# print(f'tensor_x--》{tensor_x}')tensor_y = torch.tensor(categorys.index(y), dtype=torch.long)return tensor_x, tensor_y# 5 todo. 實例化Dataloader
def get_dataloader():my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')nameClass_dataset = NameClassDataset(my_list_x, my_list_y)# 實例化Dataloadertrain_dataloader = DataLoader(dataset=nameClass_dataset,batch_size=1,shuffle=True)# for tensor_x, tensor_y in train_dataloader:# print(f'tensor_x--》{tensor_x.shape}')# print(f'tensor_y--》{tensor_y.shape}')# breakreturn train_dataloader# 6 todo. 定義RNN模型
class NameRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super().__init__()# input_size-->輸入x單詞的詞嵌入維度self.input_size = input_size# hidden_size-->RNN輸出的隱藏層維度self.hidden_size = hidden_size# output_size-->國家類別的總個數self.output_size = output_size# num_layers:幾層隱藏層self.num_layers = num_layers# 實例化RNN對象# batch_first=False,默認self.rnn = nn.RNN(input_size, hidden_size, num_layers)# 定義輸出層self.out = nn.Linear(hidden_size, output_size)# 定義logsoftmax層self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input_x, hidden):# input_x按照講義,輸入的時候,是個二維的【seq_len, input_size】-->[6, 57]# hidden:初始化隱藏層的值:[1, 1, 128]# 升維度,在dim=1的維度進行升維:input_x-->[6, 1, 57]input_x = input_x.unsqueeze(dim=1)# 將input_x和hidden送入rnn:rnn_output-->shape--[6,1,128];hn-->[1, 1, 128]rnn_output, hn = self.rnn(input_x, hidden)# 將上述rnn的結果經過輸出層;rnn_output[-1]獲取最后一個單詞的詞向量代表整個句子的語意# temp_vec-->[1, 128]temp_vec = rnn_output[-1]# 將temp_vec送入輸出層:result-->[1, 18]result = self.out(temp_vec)return self.softmax(result), hndef inithidden(self):return torch.zeros(self.num_layers, 1, self.hidden_size)# 7 todo. 定義LSTM模型
class NameLSTM(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super().__init__()# input_size-->輸入x單詞的詞嵌入維度self.input_size = input_size# hidden_size-->RNN輸出的隱藏層維度self.hidden_size = hidden_size# output_size-->國家類別的總個數self.output_size = output_size# num_layers:幾層隱藏層self.num_layers = num_layers# 實例化LSTM對象self.lstm = nn.LSTM(input_size, hidden_size, num_layers)# 定義輸出層self.out = nn.Linear(hidden_size, output_size)# 定義logsoftmax層self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input_x, h0, c0):# input_x-shape-->[seq_len, embed_dim]-->[6, 57]# h0,c0-->shape-->[num_layers, batch_size, hidden_size]-->[1, 1, 128]# 1.先對input_x升維度;shape-->[6, 1, 57]input_x = input_x.unsqueeze(dim=1)# 2.將input_x, h0,c0送入lstm模型# lstm_output-->shape=-->[6, 1, 128]lstm_output, (hn, cn) = self.lstm(input_x, (h0, c0))# 3.取出lstm輸出結果中最后一個單詞對應的隱藏層輸出結果送入輸出層# temp_vec-->shape-->[1, 128]temp_vec = lstm_output[-1]# 送入輸出層result->shape-->[1, 18]result = self.out(temp_vec)return self.softmax(result), hn, cndef inithidden(self):h0 = torch.zeros(self.num_layers, 1, self.hidden_size)c0 = torch.zeros(self.num_layers, 1, self.hidden_size)return h0, c0# 8 todo. 定義GRU模型
class NameGRU(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super().__init__()# input_size-->輸入x單詞的詞嵌入維度self.input_size = input_size# hidden_size-->RNN輸出的隱藏層維度self.hidden_size = hidden_size# output_size-->國家類別的總個數self.output_size = output_size# num_layers:幾層隱藏層self.num_layers = num_layers# 實例化GRU對象# batch_first=False,默認self.gru = nn.GRU(input_size, hidden_size, num_layers)# 定義輸出層self.out = nn.Linear(hidden_size, output_size)# 定義logsoftmax層self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input_x, hidden):# input_x按照講義,輸入的時候,是個二維的【seq_len, input_size】-->[6, 57]# hidden:初始化隱藏層的值:[1, 1, 128]# 升維度,在dim=1的維度進行升維:input_x-->[6, 1, 57]input_x = input_x.unsqueeze(dim=1)# 將input_x和hidden送入rnn:rnn_output-->shape--[6,1,128];hn-->[1, 1, 128]rnn_output, hn = self.gru(input_x, hidden)# 將上述gru的結果經過輸出層;rnn_output[-1]獲取最后一個單詞的詞向量代表整個句子的語意# temp_vec-->[1, 128]temp_vec = rnn_output[-1]# 將temp_vec送入輸出層:result-->[1, 18]result = self.out(temp_vec)return self.softmax(result), hndef inithidden(self):return torch.zeros(self.num_layers, 1, self.hidden_size)my_lr = 1e-3
epochs = 1# 9 todo: 定義RNN模型的訓練函數
def train_rnn():# 1.讀取txt文檔數據my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')# 2.實例化Dataset對象name_dataset = NameClassDataset(my_list_x, my_list_y)# 3.實例化自定義的RNN模型對象input_size = n_letters # 57hidden_size = 128output_size = categorynum # 18name_rnn = NameRNN(input_size, hidden_size, output_size)# 4.實例化損失函數對象以及優化器對象rnn_nllloss = nn.NLLLoss()rnn_adam = optim.Adam(name_rnn.parameters(), lr=my_lr)# 5.定義訓練日志的參數start_time = time.time()total_iter_num = 0 # 已經訓練的樣本的總數total_loss = 0.0 # 已經訓練的樣本的總損失total_loss_list = [] # 每隔100個樣本我們計算一下平均損失,并保存total_acc_num = 0 # 已經訓練的樣本中預測正確的個數total_acc_list = []# 每隔100個樣本我們計算一下平均準確率,并保存# 6. 開始外部迭代for epoch_idx in range(epochs):# 6.1 實例化Dataloader的對象train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)# 6.2 開始遍歷迭代器,內部迭代for idx, (tensor_x, tensor_y) in enumerate(tqdm(train_dataloader)):# 6.3 準備模型需要的數據tensor_x0 = tensor_x[0] # [seq_length, input_size]h0 = name_rnn.inithidden()# print(f'tensor_y--》{tensor_y}')# 6.4 將數據送入模型得到預測結果output-->shape-->[1, 18]output, hn = name_rnn(tensor_x0, h0)# print(f'output--》{output}')# 6.5 計算損失my_loss = rnn_nllloss(output, tensor_y)# print(f'my_loss--》{my_loss}')# 6.6 梯度清零rnn_adam.zero_grad()# 6.7 反向傳播my_loss.backward()# 6.8 梯度更新rnn_adam.step()# 6.9 統計已經訓練的樣本的總個數total_iter_num = total_iter_num + 1# 6.10 統計已經訓練的樣本總損失total_loss = total_loss + my_loss.item()# 6.11 統計已經訓練的樣本中預測正確的樣本總個數# torch.argmax(output)取出預測結果中最大概率值對應的索引predict_id = 1 if torch.argmax(output).item() == tensor_y.item() else 0total_acc_num = total_acc_num + predict_id# 6.12 每間隔100步,保存平均損失已經平均準確率if (total_iter_num % 100) == 0:# 計算平均損失并保存avg_loss = total_loss / total_iter_numtotal_loss_list.append(avg_loss)# 計算平均準確率并保存avg_acc = total_acc_num / total_iter_numtotal_acc_list.append(avg_acc)# 6.13 每間隔2000步,打印日志if (total_iter_num % 2000) == 0:temp_avg_loss = total_loss / total_iter_numtemp_avg_acc = total_acc_num / total_iter_numprint('輪次:%d, 損失:%.6f, 時間:%d,準確率:%.3f' %(epoch_idx+1, temp_avg_loss, time.time() - start_time, temp_avg_acc))# 7保存模型torch.save(name_rnn.state_dict(), './save_model/szAI_%d.bin'%(epoch_idx+1))total_time = time.time() - start_timernn_dict = {"total_loss_list": total_loss_list,"total_time": total_time,"total_acc_list": total_acc_list}with open('name_classify_rnn.json', 'w', encoding='utf-8') as fw:fw.write(json.dumps(rnn_dict))
def train_lstm():my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')# 2.實例化Dataset對象name_dataset = NameClassDataset(my_list_x, my_list_y)# 3.實例化自定義的RNN模型對象input_size = n_letters # 57hidden_size = 128output_size = categorynum # 18name_lstm = NameLSTM(input_size, hidden_size, output_size)# 4.實例化損失函數對象以及優化器對象rnn_nllloss = nn.NLLLoss()rnn_adam = optim.Adam(name_lstm.parameters(), lr=my_lr)# 5.定義訓練日志的參數start_time = time.time()total_iter_num = 0 # 已經訓練的樣本的總數total_loss = 0.0 # 已經訓練的樣本的總損失total_loss_list = [] # 每隔100個樣本我們計算一下平均損失,并保存total_acc_num = 0 # 已經訓練的樣本中預測正確的個數total_acc_list = [] # 每隔100個樣本我們計算一下平均準確率,并保存# 6. 開始外部迭代for epoch_idx in range(epochs):# 6.1 實例化Dataloader的對象train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)# 6.2 開始遍歷迭代器,內部迭代for idx, (tensor_x, tensor_y) in enumerate(tqdm(train_dataloader)):# 6.3 準備模型需要的數據tensor_x0 = tensor_x[0] # [seq_length, input_size]h0,c = name_lstm.inithidden()# print(f'tensor_y--》{tensor_y}')# 6.4 將數據送入模型得到預測結果output-->shape-->[1, 18]output, hn,cn = name_lstm(tensor_x0, h0,c)# print(f'output--》{output}')# 6.5 計算損失my_loss = rnn_nllloss(output, tensor_y)# print(f'my_loss--》{my_loss}')# 6.6 梯度清零rnn_adam.zero_grad()# 6.7 反向傳播my_loss.backward()# 6.8 梯度更新rnn_adam.step()# 6.9 統計已經訓練的樣本的總個數total_iter_num = total_iter_num + 1# 6.10 統計已經訓練的樣本總損失total_loss = total_loss + my_loss.item()# 6.11 統計已經訓練的樣本中預測正確的樣本總個數# torch.argmax(output)取出預測結果中最大概率值對應的索引predict_id = 1 if torch.argmax(output).item() == tensor_y.item() else 0total_acc_num = total_acc_num + predict_id# 6.12 每間隔100步,保存平均損失已經平均準確率if (total_iter_num % 100) == 0:# 計算平均損失并保存avg_loss = total_loss / total_iter_numtotal_loss_list.append(avg_loss)# 計算平均準確率并保存avg_acc = total_acc_num / total_iter_numtotal_acc_list.append(avg_acc)# 6.13 每間隔2000步,打印日志if (total_iter_num % 2000) == 0:temp_avg_loss = total_loss / total_iter_numtemp_avg_acc = total_acc_num / total_iter_numprint('輪次:%d, 損失:%.6f, 時間:%d,準確率:%.3f' % (epoch_idx + 1, temp_avg_loss, time.time() - start_time, temp_avg_acc))# 7保存模型torch.save(name_lstm.state_dict(), './save_model/_%d.bin' % (epoch_idx + 1))total_time=time.time()-start_time# 9. 將損失列表和準確率列表以及時間保存到字典并存儲到文件里lstm_dict = {"total_loss_list": total_loss_list,"total_time": total_time,"total_acc_list": total_acc_list}with open('name_classify_lstm.json', 'w', encoding='utf-8') as fw:fw.write(json.dumps(lstm_dict))
def train_gru():# 1.讀取txt文檔數據my_list_x, my_list_y = read_data(filename='./data/name_classfication.txt')# 2.實例化Dataset對象name_dataset = NameClassDataset(my_list_x, my_list_y)# 3.實例化自定義的RNN模型對象input_size = n_letters # 57hidden_size = 128output_size = categorynum # 18name_gru = NameGRU(input_size, hidden_size, output_size)# 4.實例化損失函數對象以及優化器對象rnn_nllloss = nn.NLLLoss()rnn_adam = optim.Adam(name_gru.parameters(), lr=my_lr)# 5.定義訓練日志的參數start_time = time.time()total_iter_num = 0 # 已經訓練的樣本的總數total_loss = 0.0 # 已經訓練的樣本的總損失total_loss_list = [] # 每隔100個樣本我們計算一下平均損失,并保存total_acc_num = 0 # 已經訓練的樣本中預測正確的個數total_acc_list = []# 每隔100個樣本我們計算一下平均準確率,并保存# 6. 開始外部迭代for epoch_idx in range(epochs):# 6.1 實例化Dataloader的對象train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)# 6.2 開始遍歷迭代器,內部迭代for idx, (tensor_x, tensor_y) in enumerate(tqdm(train_dataloader)):# 6.3 準備模型需要的數據tensor_x0 = tensor_x[0] # [seq_length, input_size]h0 = name_gru.inithidden()# print(f'tensor_y--》{tensor_y}')# 6.4 將數據送入模型得到預測結果output-->shape-->[1, 18]output, hn = name_gru(tensor_x0, h0)# print(f'output--》{output}')# 6.5 計算損失my_loss = rnn_nllloss(output, tensor_y)# print(f'my_loss--》{my_loss}')# 6.6 梯度清零rnn_adam.zero_grad()# 6.7 反向傳播my_loss.backward()# 6.8 梯度更新rnn_adam.step()# 6.9 統計已經訓練的樣本的總個數total_iter_num = total_iter_num + 1# 6.10 統計已經訓練的樣本總損失total_loss = total_loss + my_loss.item()# 6.11 統計已經訓練的樣本中預測正確的樣本總個數# torch.argmax(output)取出預測結果中最大概率值對應的索引predict_id = 1 if torch.argmax(output).item() == tensor_y.item() else 0total_acc_num = total_acc_num + predict_id# 6.12 每間隔100步,保存平均損失已經平均準確率if (total_iter_num % 100) == 0:# 計算平均損失并保存avg_loss = total_loss / total_iter_numtotal_loss_list.append(avg_loss)# 計算平均準確率并保存avg_acc = total_acc_num / total_iter_numtotal_acc_list.append(avg_acc)# 6.13 每間隔2000步,打印日志if (total_iter_num % 2000) == 0:temp_avg_loss = total_loss / total_iter_numtemp_avg_acc = total_acc_num / total_iter_numprint('輪次:%d, 損失:%.6f, 時間:%d,準確率:%.3f' %(epoch_idx+1, temp_avg_loss, time.time() - start_time, temp_avg_acc))# 7保存模型torch.save(name_gru.state_dict(), './save_model/gru_%d.bin'%(epoch_idx+1))total_time = time.time() - start_timegru_dict = {"total_loss_list": total_loss_list,"total_time": total_time,"total_acc_list": total_acc_list}with open('name_classify_gru.json', 'w', encoding='utf-8') as fw:fw.write(json.dumps(gru_dict))
def draw_picture():with (open('name_classify_gru.json','r') as fg,open('name_classify_rnn.json','r') as fr,open('name_classify_lstm.json','r') as fl):fr=json.loads(fr.read())fg=json.loads(fg.read())fl=json.loads(fl.read())plt.figure(0)plt.plot(fr['total_loss_list'],label='rnn')plt.plot(fl['total_loss_list'],label='lstm')plt.plot(fg['total_loss_list'],label='gru')plt.legend(loc='upper left')plt.show()plt.figure(1)x_list=["RNN", "LSTM", "GRU"]plt.bar(range(len(x_list)),y=[fr['total_time'],fl['total_time'],fg['total_time']],tick_label=x_list)plt.show()plt.figure(2)plt.plot(fr['total_acc_list'], label='rnn')plt.plot(fl['total_acc_list'], label='lstm')plt.plot(fg['total_acc_list'], label='gru')plt.legend(loc='upper left')plt.show()
def str_to_vec(x):len_letter=len(x)tensor_x = torch.zeros(len_letter, n_letters)for idx,letter in enumerate(x):tensor_x[idx][all_letters.find(letter)]=1return tensor_x
#模型預測
def my_predict_rnn(x):n_letters = 57n_hidden = 128n_categories = 18# 輸入文本, 張量化one-hotx_tensor = str_to_vec(x)# 實例化模型 加載已訓練模型參數my_rnn = NameRNN(n_letters, n_hidden, n_categories)my_rnn.load_state_dict(torch.load( './save_model/szAI_1.bin'))with torch.no_grad():# 模型預測output, hidden = my_rnn(x_tensor, my_rnn.inithidden())# 從預測結果中取出前3名# 3表示取前3名, 1表示要排序的維度, True表示是否返回最大或是最下的元素topv, topi = output.topk(3, 1, True)print('rnn =>', x)for i in range(3):value = topv[0][i]category_idx = topi[0][i]category = categorys[category_idx]print('\t value:%d category:%s' %(value, category))
def my_predict_lstm(x):n_letters = 57n_hidden = 128n_categories = 18# 輸入文本, 張量化one-hotx_tensor = str_to_vec(x)# 實例化模型 加載已訓練模型參數my_rnn = NameLSTM(n_letters, n_hidden, n_categories)my_rnn.load_state_dict(torch.load( './save_model/_1.bin'))with torch.no_grad():# 模型預測hidden, c=my_rnn.inithidden()output, hidden ,c= my_rnn(x_tensor,hidden,c )# 從預測結果中取出前3名# 3表示取前3名, 1表示要排序的維度, True表示是否返回最大或是最下的元素topv, topi = output.topk(3, 1, True)print(topi,topv) #一個是值,一個是索引print('lstm =>', x)for i in range(3):value = topv[0][i]category_idx = topi[0][i]category = categorys[category_idx]print('\t value:%d category:%s' %(value, category))
def my_predict_gru(x):n_letters = 57n_hidden = 128n_categories = 18# 輸入文本, 張量化one-hotx_tensor = str_to_vec(x)# 實例化模型 加載已訓練模型參數my_rnn = NameGRU(n_letters, n_hidden, n_categories)my_rnn.load_state_dict(torch.load( './save_model/gru_1.bin'))with torch.no_grad():# 模型預測hidden=my_rnn.inithidden()output, hidden= my_rnn(x_tensor,hidden)# 從預測結果中取出前3名# 3表示取前3名, 1表示要排序的維度, True表示是否返回最大或是最下的元素topv, topi = output.topk(3, 1, True)print(topi,topv) #一個是值,一個是索引print('lstm =>', x)for i in range(3):value = topv[0][i]category_idx = topi[0][i]category = categorys[category_idx]print('\t value:%d category:%s' %(value, category))if __name__ == '__main__':# train_dataloader = get_dataloader()# # name_lstm= NameLSTM(input_size=n_letters, hidden_size=128, output_size=categorynum)# name_gru= NameGRU(input_size=n_letters, hidden_size=128, output_size=categorynum)# print(name_gru)# for tensor_x, tensor_y in train_dataloader:# h0 = name_gru.inithidden()# x0 = tensor_x[0]# output, hn= name_gru(x0, h0)# print(f'output--》{output.shape}')# print(f'output--》{output}')# print(f'hn--》{hn.shape}')# break# train_rnn()# train_lstm()# train_gru()# draw_picture()# tensor_x=str_to_vec('zhang')# print(tensor_x)my_predict_rnn('zhang')my_predict_lstm('zhang')my_predict_gru('zhang')my_predict_rnn('Benesch')my_predict_lstm('Benesch')my_predict_gru('Benesch')今日分享結束。




-實現四層負載均衡)




:sqlmap快速上手)




)


)

