一、污點與容忍
1. 給節點添加污點
1)命令格式
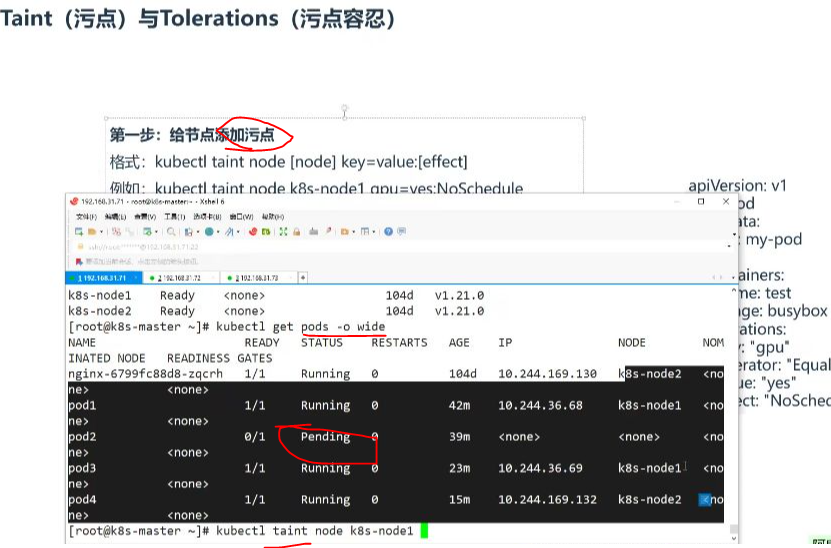
- 基本語法:kubectl taint node [node] key=value:[effect]
- 示例:kubectl taint node k8s-node1 gpu=yes:NoSchedule
- 操作說明:與打標簽命令類似,將"label"替換為"taint"即可
2)value鍵值配置
- 鍵值規范:污點以鍵值對形式配置,如gpu=nvidia
- 實際應用:通常用于標記特殊節點,如GPU節點可標記為gpu=nvidia
3)effect動作

- NoSchedule:Pod一定不會被調度到該節點(最常用)
- PreferNoSchedule:盡量不調度,非必須配置容忍
- NoExecute:不僅不調度,還會驅逐節點上已有Pod
4)污點效果
- 強制隔離:當節點設置NoSchedule后,未配置容忍的Pod絕對不會被調度到該節點
- master節點:K8s默認給master節點打上node-role.kubernetes.io/master:NoSchedule污點
5)資源不夠的情況
- 資源不足表現:即使集群資源不足,未配置容忍的Pod也不會被調度到有污點的節點
- 實際現象:Pod會保持Pending狀態,如示例中的pod2和pod5
6)配置污點容忍

- 配置位置:在Pod的spec中添加tolerations字段
- 關鍵字段:
- key:需要匹配的污點鍵名
- operator:匹配操作符(Equal/Exists)
- value:需要匹配的污點值
- effect:需要匹配的污點效果
7)查看污點
- 查看命令:kubectl describe node [node] | grep Taint
- 輸出示例:
8)創建嘗試分配
- 實驗現象:當所有節點都有污點且Pod未配置容忍時,Pod會保持Pending狀態
- 錯誤提示:0/3 nodes available: 1 node(s) had taint {...}, that the pod didn't tolerate
9)配置污點容忍并分配
- 正確配置:必須確保tolerations中的key、value、effect與節點污點完全匹配
- 驗證方法:通過kubectl get pods -o wide查看Pod最終調度到的節點
2. 污點容忍
- operator類型:
- Equal:要求value嚴格匹配(最常用)
- Exists:只需key存在即可,不檢查value
- 特殊值處理:
- 空key+Exists:匹配所有污點
- 空effect:匹配所有effect效果
3. 相關知識點
- 刪除污點:kubectl taint node [node] key:[effect]-
- 實用技巧:可通過K8s官方文檔搜索"tolerations"獲取配置示例模板
- 常見錯誤:value拼寫錯誤會導致容忍失效(如將"nvidia"誤寫為"nvdia")
二、pod的配置問題
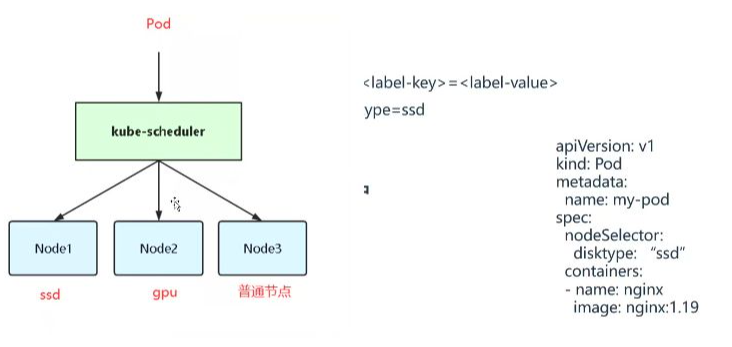
- nodeSelector使用:通過disktype: "ssd"標簽選擇特定節點,但不會100%保證調度到目標節點
- 污點容忍特性:配置容忍后僅表示可以調度到帶污點的節點,并非強制調度
- 調度可能性:當存在普通節點時,Pod仍可能調度到其他非目標節點
三、大師節點配置容忍性泡的示例
1. 污點與污點容忍的概念

- Taints作用:避免Pod調度到特定Node,保障master節點安全性和專注性
- Tolerations作用:允許Pod調度到持有Taints的Node,但不是強制調度
- 應用場景:
- 專用節點分組管理
- 特殊硬件節點(SSD/GPU)
- 基于Taint的驅逐
2. 污點容忍的配置方法
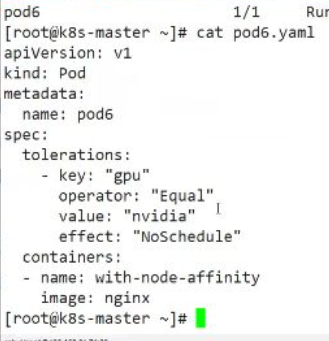
- 基本配置:
- effect取值:
- NoSchedule:不調度
- NoExecute:不執行
- PreferNoSchedule:盡量不調度
3. 污點容忍的省略情況
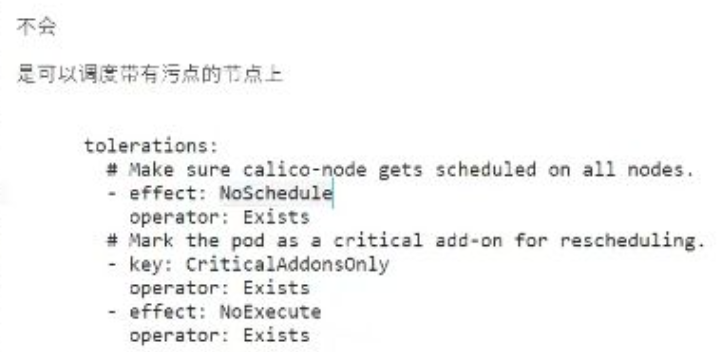
- value省略:可以只保留key不指定value,如master節點的node-role.kubernetes.io/master
- key省略:通過operator: Exists可容忍所有帶指定effect的污點
- 范圍影響:省略value/key會擴大容忍范圍,適配更多環境
4. 靜態泡與污點容忍的關系
- 靜態Pod特性:不受調度器管理,由kubelet直接管理
- master節點運行:k8s組件采用靜態Pod方式啟動,不受污點限制
- 兩種例外情況:
- 靜態Pod(如etcd/kube-apiserver)
- 配置了污點容忍的Pod(如calico)
5. 配置污點容忍的示例
- 全節點部署需求:為保證集群通信,calico需要在所有節點運行
- 通用容忍配置:
- 設計目的:適配不同k8s環境,確保網絡組件必運行
6. 污點容忍的范圍與實際應用
- 范圍控制:
- 指定key+value:精確匹配特定污點
- 僅指定effect:容忍所有帶該effect的污點
- 使用Exists操作符:不校驗key/value,僅看effect
- 實際建議:生產環境應明確指定key/value,避免過度容忍
四、部署配置容忍泡的示例
- 驗證方法:創建5副本Deployment測試全節點調度
- 配置要點:
- 預期結果:Pod可調度到所有帶NoSchedule污點的節點
- 與靜態Pod區別:非靜態Pod必須顯式配置容忍才能在污點節點運行
五、查看分布情況
1. Pod調度情況
- Pending狀態分析:多個Pod處于Pending狀態,原因是節點存在污點{gpu:nvidia2}和{gpu:nvidia},而Pod未配置相應容忍
- 節點污點檢查:通過kubectl describe node可查看節點污點信息,顯示master節點有NoSchedule污點
- 運行狀態示例:
- nginx-6799fc88d8-zqcrh:1/1 Running
- pod2:0/1 Pending 74m
- web-54c699bb5c-*系列:多個處于ContainerCreating狀態
2. Pod擴容嘗試
- 擴容策略:從5個副本擴容到10個副本進行測試
- 調度效果:部分Pod仍無法調度,顯示"1 node(s) had taint {gpu:nvidia2}"等錯誤
- 關鍵現象:5個副本時未分配成功,擴容后部分Pod開始運行在node1和node2節點
3. 污點容忍配置
- 基礎容忍配置:
- 特殊容忍配置:
- CriticalAddonsOnly:關鍵組件專用容忍
- NoExecute:用于驅逐場景的容忍
- 配置原則:
- 不指定key時容忍所有NoSchedule污點
- 需要精確匹配時應指定key/value對
4. Pod分布驗證
- 成功調度案例:
- web-54c699bb5c-9w81z:運行在k8s-node1(10.244.36.71)
- web-54c699bb5c-htdgn:運行在k8s-node1(10.244.36.73)
- 節點分布規律:Pod均勻分布在node1和node2節點,master節點未參與調度
5. 污點去除操作
- 去除命令:kubectl taint node <node-name> <taint-key>-
- 關鍵操作:去除master節點的NoSchedule污點后,Pod可調度到master節點
- 驗證方法:通過kubectl describe node | grep Taint確認污點已去除
6. 污點與容忍總結
- 精確匹配配置:
- 實踐經驗:
- 明確指定key/value的配置更可靠
- calico等系統組件使用Exists操作符容忍所有污點
- 生產環境建議為關鍵組件配置專用容忍
- 常見問題:
- 效果(effect)必須匹配:NoSchedule/NoExecute
- master節點默認有NoSchedule污點
- 多個污點需要分別配置容忍
六、配置容忍并查看分布情況
1. Pod容忍配置
- 配置方法:在Pod的spec中通過tolerations字段配置容忍,允許Pod被調度到帶有特定污點的節點上
- 關鍵參數:
- key:污點的鍵名
- operator:比較運算符(Equal/Exists)
- value:污點的值(當operator為Equal時需指定)
- effect:污點效果(NoSchedule/PreferNoSchedule/NoExecute)
2. 節點直接指定

- nodeName使用:通過spec.nodeName字段可直接指定Pod運行的節點,繞過調度器
- 應用場景:適用于需要精確控制Pod運行位置的場景
- 注意事項:直接指定節點會失去調度器的自動容錯和負載均衡能力
七、k配置問題
1. 配置必要性分析
- 配置爭議:在容忍配置中,key參數是否必須存在存在不同理解
- 實踐經驗:
- 通常建議明確指定key值(如"gpu")
- 但實際使用中發現并非絕對必要
- 待研究點:需要進一步研究key參數在不同場景下的深層含義和最佳實踐
八、nodeName
1. nodeName意義
- 強制調度機制:通過nodeName字段可直接指定Pod運行的目標節點,完全繞過kube-scheduler調度器
- 特殊應用場景:主要用于測試環境,當需要精確控制Pod部署位置時使用
- 與調度器關系:不參與調度器的節點篩選流程,直接跳過所有調度策略(如節點親和性、污點容忍等)
2. 應用案例
- 配置方法:
- 實際效果驗證:
- 案例中創建pod7并指定到k8s-node1后,Pod立即進入Running狀態(00:44:37驗證)
- 對比普通Pending狀態的Pod(如pod2/pod5),證明nodeName確實繞過調度器限制
- 使用注意事項:
- 生產環境慎用:可能導致Pod無法調度(當目標節點不可用時)
- 測試環境優勢:比nodeSelector更快速直接,無需預先配置節點標簽
- 典型測試場景:驗證特定節點上的硬件/軟件兼容性時使用
- 與常規調度區別:
- 常規調度:經過節點篩選(nodeSelector/nodeAffinity)→ 打分 → 綁定流程
- nodeName調度:直接綁定指定節點,相當于"走后門"機制(00:45:17講解)
九、DaemonSet
1. DaemonSet功能
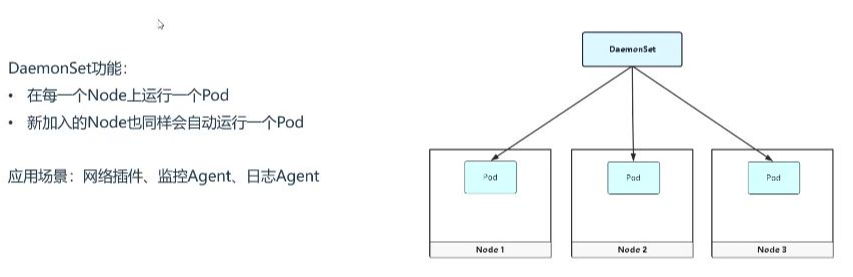
- 節點全覆蓋:確保在集群每個節點(包括新加入節點)上都運行一個Pod副本
- 自動擴展:新節點加入集群時會自動創建Pod,無需人工干預
- 運維特性:適用于需要以守護進程方式在每個節點運行的場景
2. DaemonSet應用場景
- 網絡插件:如Calico網絡組件,需要在所有節點部署網絡代理
- 監控Agent:采集節點級監控指標(如CPU/內存使用率)
- 日志Agent:收集節點上所有Pod的日志(如Filebeat)
- 運維工具:主要用于基礎設施層而非業務應用層
3. DaemonSet示例
- 與Deployment區別:
- 不需要設置replicas副本數
- 不支持strategy更新策略字段
- 資源類型需改為DaemonSet
- 污點處理:
- 默認不調度到有污點的節點
- 可通過tolerations配置容忍特定污點
- 實驗時建議先刪除節點污點:kubectl taint node <node-name> <taint-key>-
4. 部署日志采集程序

- YAML關鍵配置:
- 部署驗證:
- 使用kubectl get pods -o wide查看Pod分布
- 通過kubectl describe ds <name>檢查調度狀態
- 節點增加時會自動創建新Pod(約30秒內完成)
十、調度失敗原因分析
- 查看方法:
- 查看調度結果:kubectl get pod <NAME> -o wide
- 查看失敗原因:kubectl describe pod <NAME>
- 常見原因:
- 資源不足:節點CPU/內存無法滿足pod的request配置
- 污點問題:節點配置了污點但pod沒有相應容忍
- 標簽不匹配:節點沒有pod要求的標簽
- 磁盤不足:雖然少見但也會導致調度失敗(需注意錯誤信息)
十一、DaemonSet控制器
1. DaemonSet控制器概述
- 工作特點:自動在符合條件的節點上創建pod
- 驗證案例:刪除節點污點后,DaemonSet會自動拉起pod
2. DaemonSet創建問題
- 命令行限制:不支持kubectl create直接創建
- 替代方案:通常使用YAML文件進行部署
3. DaemonSet不常用原因
- 使用場景:主要用于節點級守護進程,不是常規工作負載
4. node selector與污點區別
- 功能差異:
- node selector:節點必須具有指定標簽
- 污點:節點排斥非特定pod
- 優先級關系:兩者功能不同,不存在優先級比較
- 調度disable:使節點完全不調度新pod,不同于污點的選擇性排斥
5. toleration與taint匹配
- 特殊配置:
- 當toleration的key為空且operator為"Exists"時
- 表示能容忍任意taint(除非指定了effect限制)
6. dry-run選項區別
- client模式:僅在客戶端驗證配置
- server模式:提交到API server進行驗證
- 應用場景:測試資源配置時使用不同驗證級別
十二、答疑
1. 權重的作用與理解
- 調度加分機制:權重相當于調度系統中的加分值,類似于比賽評委的特殊加分權限
- 實際應用場景:以中國好聲音為例,特定評委可通過加分提高選手獲勝概率
- 技術實現原理:在Kubernetes調度器打分環節會計算該值,影響節點分配優先級
- 學習建議:初學者只需理解其加分功能,深入理解需研究整個調度打分流程
2. 關于fact分配到master的疑問
- 現象描述:測試發現pod無法分配到master節點,與預期行為不符
- 排查過程:講師重現測試環境,創建10個pod均未分配到master
- 可能原因:環境配置存在隱藏影響因素,需進一步驗證
- 臨時結論:初步排除理解錯誤,轉向環境因素排查
3. 驗證測試環境是否影響分配
- 配置驗證:確認使用了正確的effect和operator配置組合
- 測試建議:建議學員嘗試相同配置驗證分配行為
- 最新發現:經過反復測試后確認配置理論上應生效
- 環境變量:強調環境差異可能導致不同表現,需實際驗證
4. 數字與優先級的關系
- 數值規律:數字越大表示優先級越高,對應調度分數越高
- 評分類比:類似評委打分(1-100分范圍),高分增加勝出概率
- 權重機制:高權重值會顯著提升節點被選中的可能性
- 使用建議:合理設置權重值范圍,避免極端數值影響調度平衡
5. 練習與驗證
- 練習內容:
- 驗證master節點分配問題
- 測試不同權重值對調度的影響
- 嘗試各種tolerations配置組合
- 驗證方法:通過kubectl create命令部署測試用例
- 注意事項:記錄完整測試過程,注意環境差異因素
- 交流機制:鼓勵學員在群內分享驗證結果和異常情況
十三、知識小結
知識點 | 核心內容 | 關鍵配置/參數 | 典型應用場景 |
污點(Taint) | 節點排斥機制,阻止Pod默認調度 | kubectl taint nodes <node-name> key=value:NoSchedule | Master節點保護、專用節點隔離 |
污點容忍(Toleration) | 允許Pod調度到帶污點的節點 | tolerations: - key: "key" operator: "Equal" value: "value" effect: "NoSchedule" | 系統組件部署(如Calico)、特殊硬件利用 |
NodeSelector | 基礎節點選擇器 | nodeSelector: disktype: ssd | 簡單環境區分 |
NodeAffinity | 高級節點親和性規則 | preferredDuringSchedulingIgnoredDuringExecution/requiredDuringSchedulingIgnoredDuringExecution | 復雜調度策略 |
DaemonSet | 每個節點運行一個Pod的控制器 | 無replicas字段,自動識別集群節點數 | 網絡插件、監控代理、日志收集器 |
調度失敗分析 | 常見原因排查 | 1. 資源不足 2. 污點未容忍 3. 標簽不匹配 | 集群運維排錯 |
Master節點調度 | 默認帶node-role.kubernetes.io/master:NoSchedule污點 | 需配置容忍或靜態Pod方式運行 | Kubernetes控制平面組件部署 |
NodeName直配 | 繞過調度器直接指定節點 | spec.nodeName: node1 | 測試環境專用 |


:sqlmap快速上手)




)


)


)
)




)