資料來源:火山引擎-開發者社區
DiT 模型與推理挑戰
近年來,擴散模型(Diffusion Models)在生成式人工智能領域取得了突破性進展,尤其是在圖像和視頻生成方面表現卓越。基于 Transformer 的擴散模型(DiT, Diffusion Transformer)因其強大的建模能力和高質量輸出,成為學術界和工業界的研究熱點。DiT 模型通過逐步去噪的過程,從隨機噪聲生成逼真的圖像或視頻幀,結合 Transformer 架構的全局建模能力,能夠捕捉復雜的語義特征和視覺細節,廣泛應用于文本到圖像、文本到視頻、視頻編輯等場景。
然而,DiT 模型在推理過程中面臨諸多挑戰,主要體現在計算效率、顯存占用、模型架構復雜性及多模態融合等方面。這些痛點限制了 DiT 模型在實際場景中的部署和應用,尤其是在對實時性和資源效率有要求的生成任務中。
計算量大
- 序列長度激增:當 DiT 模型在處理高分辨率圖像或長視頻時,輸入序列的長度會顯著增長,導致自注意力(Self-Attention)機制的計算量呈平方級膨脹。
- 擴散步驟多:擴散模型需要多步迭代去噪(比如50步),每一步都需要執行完整的前向計算,累積的計算開銷巨大。
模型多樣
- 架構多樣性:不同 DiT 模型的算子設計和連接方式上差異顯著,例如注意力機制、卷積層或歸一化層的組合方式各異,這增加了并行策略適配的復雜性。此外,不同階段的算子對硬件設備的計算和顯存特性要求不同,存在極大差異,導致同構推理性價比低下。例如,DiT 核心的 Transformer 模塊屬于計算密集型,高度依賴算力;而VAE(變分自編碼器,Variational Auto-Encoder)則對顯存容量和訪存帶寬要求極高。
實時性需求
- 視頻生成的實時性瓶頸:基于DiT的視頻生成模型(如?Sora)需要保證多幀間的連貫性,這就要求處理時空一致性。然而,這一需求使得單卡推理在面對高質量視頻時,無法滿足實時生成的要求。推理過程中的延遲,使得高清視頻的生成體驗較差,用戶往往需要忍受長時間的等待,影響了使用體驗。
火山引擎 veFuser 推理框架解決方案
為應對 DiT 模型推理的挑戰,字節跳動依托自身強大的技術研發實力,精心構建了基于擴散模型的圖像與視頻生成推理服務框架 VeFuser,旨在提供低延遲、低成本的高質量圖片與視頻生成體驗。
圖片生成:低端硬件上的高效推理
veFuser 針對硬件資源的優化極為出色,即使在配備 24GB 顯存的低端 GPU 上,也能高效運行當前主流的圖像生成模型,如 FLUX.1-dev(12B) 和 HiDream-I1-Full(17B)。與開源實現相比,veFuser 將推理時間縮減了 83%,極大提升了生成效率。在 FLUX.1-dev 模型上,出圖時間只需 3 秒;在 HiDream-I1-Full 模型上,出圖時間只需 13 秒。這一性能突破不僅顯著提升了用戶體驗,還通過降低對高端硬件的依賴,減少了部署和運營成本,提供了更具性價比的生成式 AI 解決方案。
視頻生成:實時體驗的先鋒
在視頻生成任務中,veFuser 展現了無與倫比的實時性能。針對某 14B 開源視頻生成模型,veFuser 在 32 卡集群上可實現 16 秒延遲生成 5 秒 480p 視頻的極致體驗。若擴展至百卡集群,veFuser 甚至能實現 5 秒生成 5 秒視頻的實時生成效果,接近實時渲染的行業前沿水準。這種低延遲特性為短視頻、直播、虛擬現實等高實時性場景提供了強大支持。
veFuser 核心優勢
降低計算復雜度與延遲
- 高性能算子:針對 Attention 算子進行了高度優化,實現細粒度的通信計算重疊。在 D、A、L、H 不同架構的 GPU 上,針對擴散模型常用的算子進行了深度調優,對計算密集算子進行無損的量化和稀疏化。
- 稀疏 Attention:打破傳統自注意力機制對序列中所有元素進行全局計算的模式。在處理高分辨率圖像或長視頻的長輸入序列時,它基于對數據特征的深入分析,運用特定的算法篩選出與當前計算任務最相關的關鍵信息。
攻克模型架構異構性難題
- 分布式架構:擴散模型的工作流往往包含多個獨立的角色(如 Text Encoder、VAE 、LLM 等),各個階段對顯存、計算、帶寬等不同資源的瓶頸不同。針對這一特點,我們為不同角色選擇最適合的并行方法和資源配置,并將工作流看成一張 DAG。將耦合的一個工作流中的不同角色(如Encoder、VAE、DiT等),拆分為獨立的微服務,并通過統一調度異步執行沒有依賴的角色,比如 image encoder 和 text encoder。
- 異構部署:同時結合各個階段對顯存、計算、帶寬等不同資源瓶頸,利用異構硬件的不同特性,優化部署成本。
- 靈活可擴展:支持自定義 pipeline 和服務組件,支持不同類型的模型推理的低成本接入。
突破實時性與擴展性限制
- 內存優化:veFuser 根據模型結構優化中間結果內存排布,消除算子激增導致的臨時內存開銷。在僅 24GB 顯存的 GPU 上,veFuser 可流暢運行 720p 視頻生成任務。
- 高效并行框架:集成多種并行框架,包括混合流水線并行(PipeFusion)、序列并行(USP 并行)和 CFG 并行,顯著提升多卡擴展性。
- 通信效率提升:通過 veTurbo rpc (支持在 vpc 上實現虛擬 RDMA 傳輸通信協議)實現多角色的通信,同時針對 tensor 數據優化傳輸性能。
多 Lora 動態切換
Lora(Low Rank Adaptation)是內容生成任務中一個常用的插件能力,能夠很好地控制生成內容的風格模式。然而,頻繁地切換Lora往往會帶來較高的開銷。因此,veFuser 針對這一通用能力,實現了多?LoRA?動態切換功能,基于用戶請求實現近乎無感的風格切換體驗。
精度無損
通過嚴格的 GSB(Good - Same - Bad) 評測,veFuser 確保速度提升不會犧牲輸出質量。無論是圖像還是視頻生成,veFuser 始終保持與傳統框架相當或更優的生成效果,實現速度與品質的完美平衡。
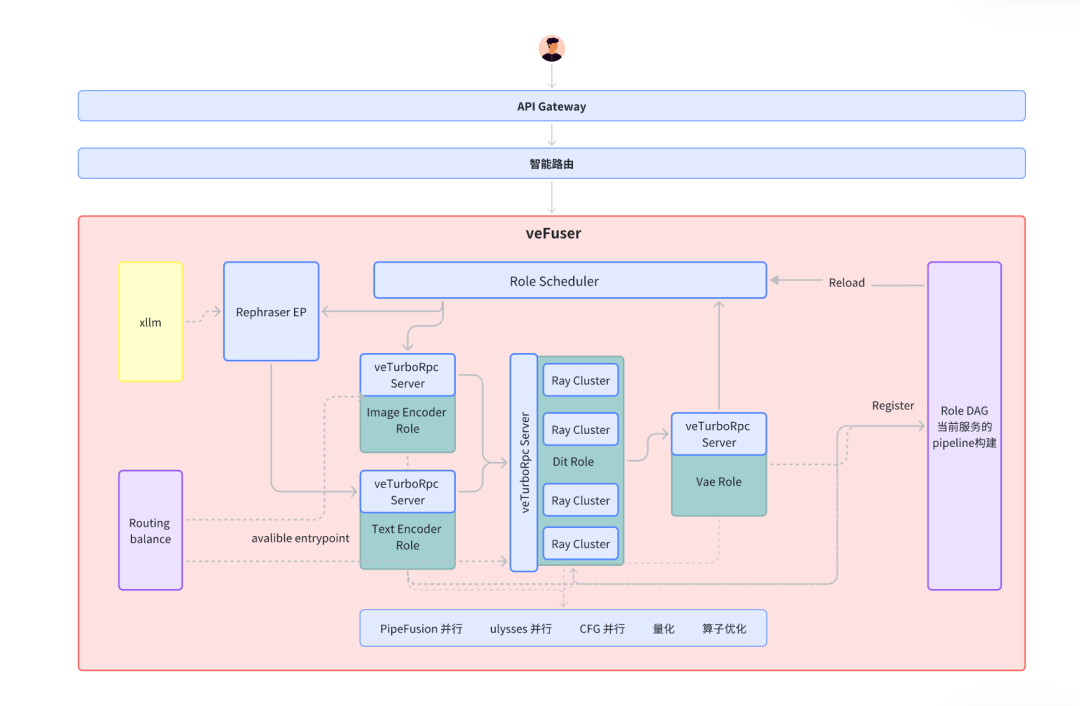
圖1 veFuser 產品架構
veFuser 性能優勢
某 14B 開源模型 視頻生成任務-單機性能(Dit 單機 8 卡)
D卡
I2V (Image to Video,圖生視頻)性能相較于業內 SOTA 水平延時降低 50% 左右,480P 每 infer-steps 平均 1.8 秒,720P 每infer-steps 平均 5 秒。
T2V (Text to Video,文生視頻)性能相較于業內 SOTA 水平延時降低 60% 左右,480P 每 infer-steps 平均 1.5 秒,720P 每 infer-steps 平均 4 秒。
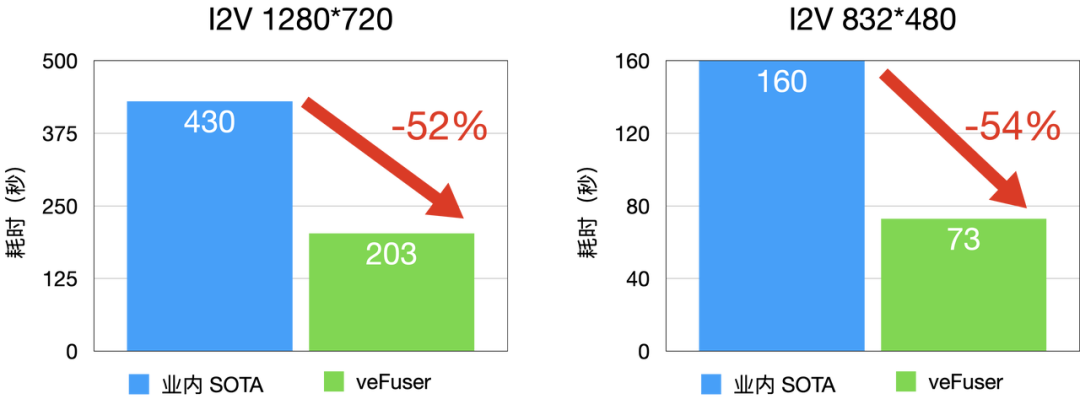
圖2 I2V 延時分布(D卡)
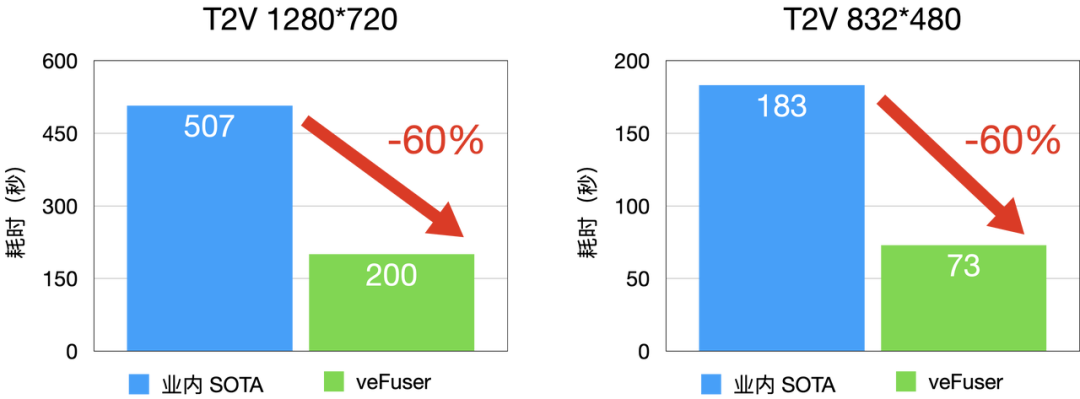
圖3 T2V 延時分布(D卡)
A800
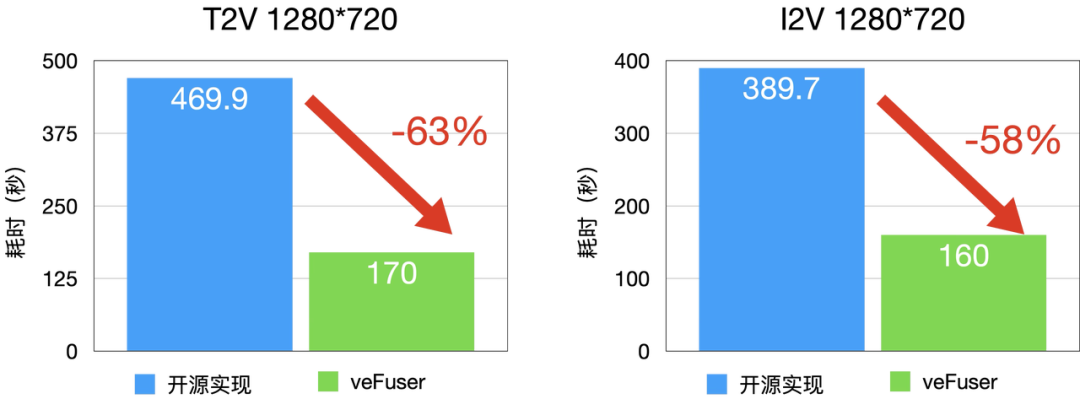
圖4 I2V 和 T2V 延時分布(A800)
H20
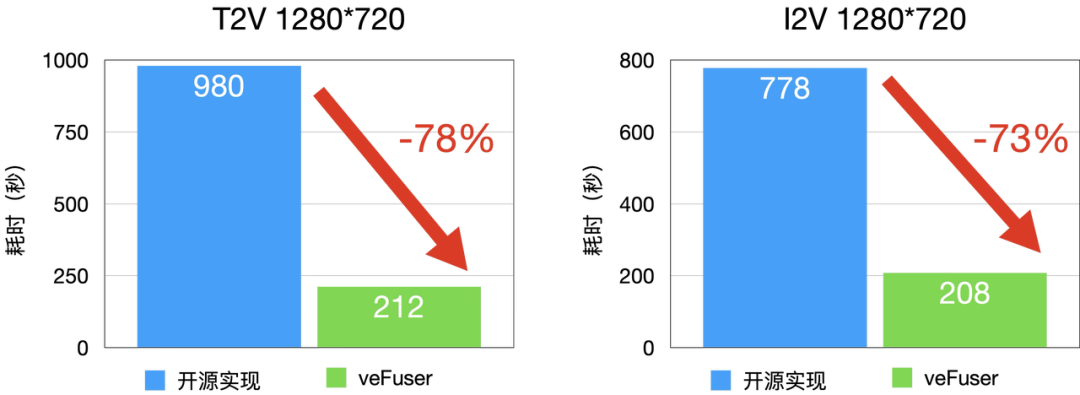
圖5 I2V 和 T2V 延時分布(H20)
L20
- veFuser 詳細延時分布:
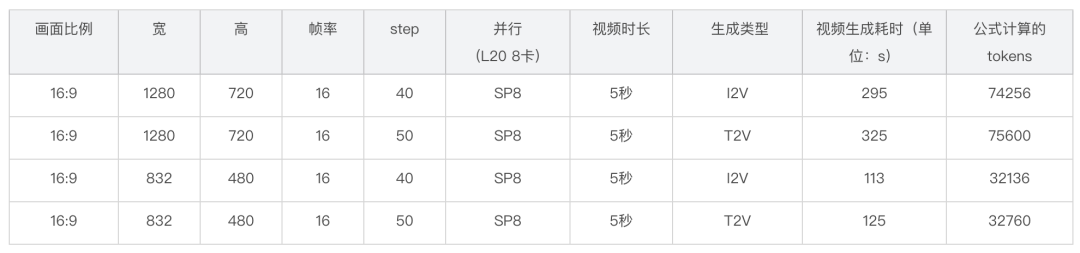
某 14B 開源模型 視頻生成任務-多機擴展性能
多機延遲 - D 卡
借助 veFuser 對 CFG 并行的支持,即便 D 卡不具備 RDMA 網絡,也能夠達成近乎 TCO 無損的 16 卡并行效果,為計算任務提供高效且穩定的運行環境。
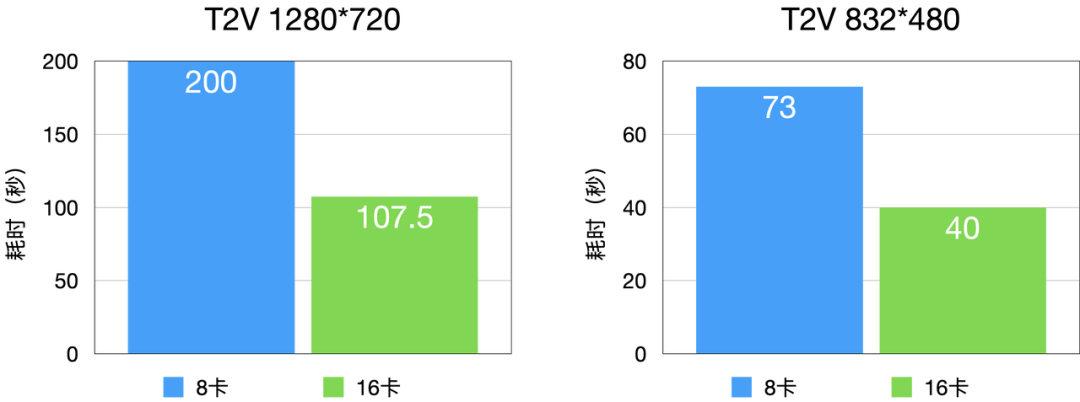
圖6 T2V 延時分布(D卡)
多機延遲 - A100
- 與 D 卡相比,A100 具有 RDMA,這一優勢使得計算集群的并行規模能夠從 16 卡進一步拓展至 32 卡,顯著提升了大規模并行計算的性能與效率。
- 通過多機部署,可以實現極低的延遲,比如 480P-5秒-T2V 在 A100 上最低耗時可以到 16 秒(32卡并行),vefuser 在 RDMA 互聯硬件上具有非常好的擴展性。
- 以 A800 T2V 為例子進行說明,Dit 部分進行并行擴展:
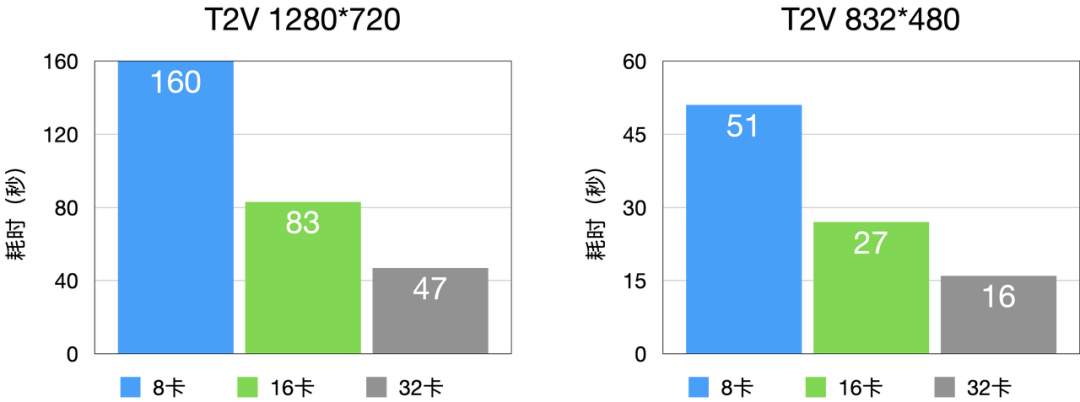
圖7 T2V 延時分布(A100)
多機擴展加速比
如圖8所示,從 8 卡到 32 卡可以實現近乎線性的加速比,在極大減少延遲的前提下,TCO 基本不變。
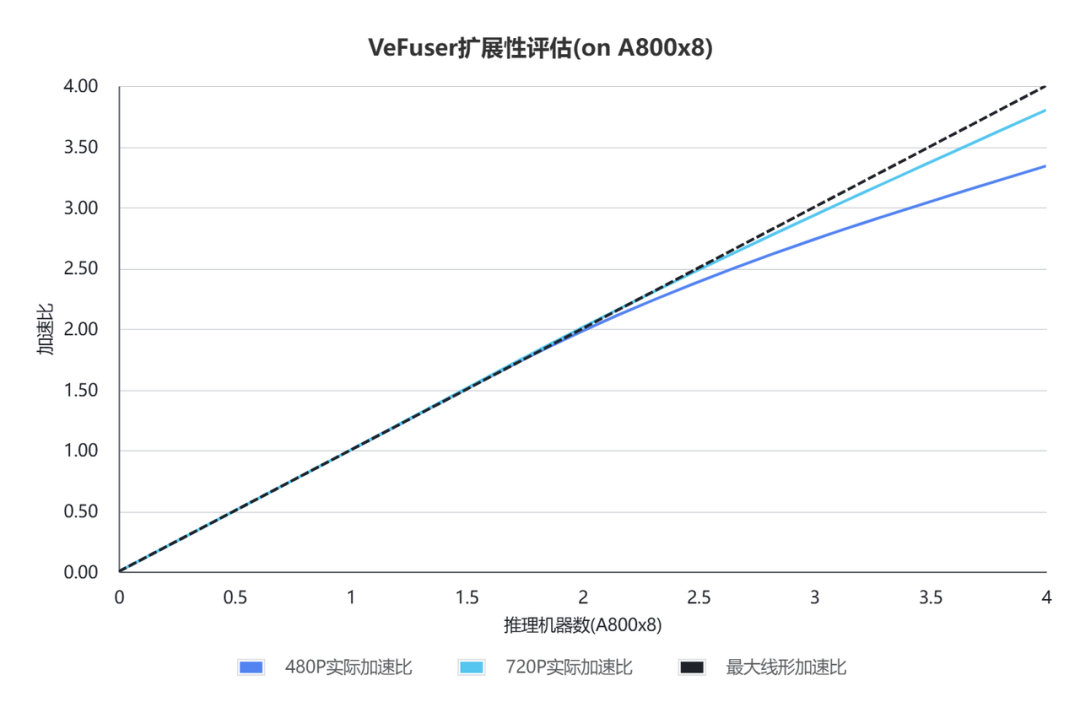
圖8 VeFuser 擴展性評估(on A800x8)
按照當前的理論拓展性,當推理卡數增加到 128 張 A800 后,實際生圖速度(藍線)與實時生圖所需速度(黑線)重合,如圖9所示。表示在這個設置下,理論上可以實現視頻生成時間小于等于視頻的時間,達到實時生視頻的效果。
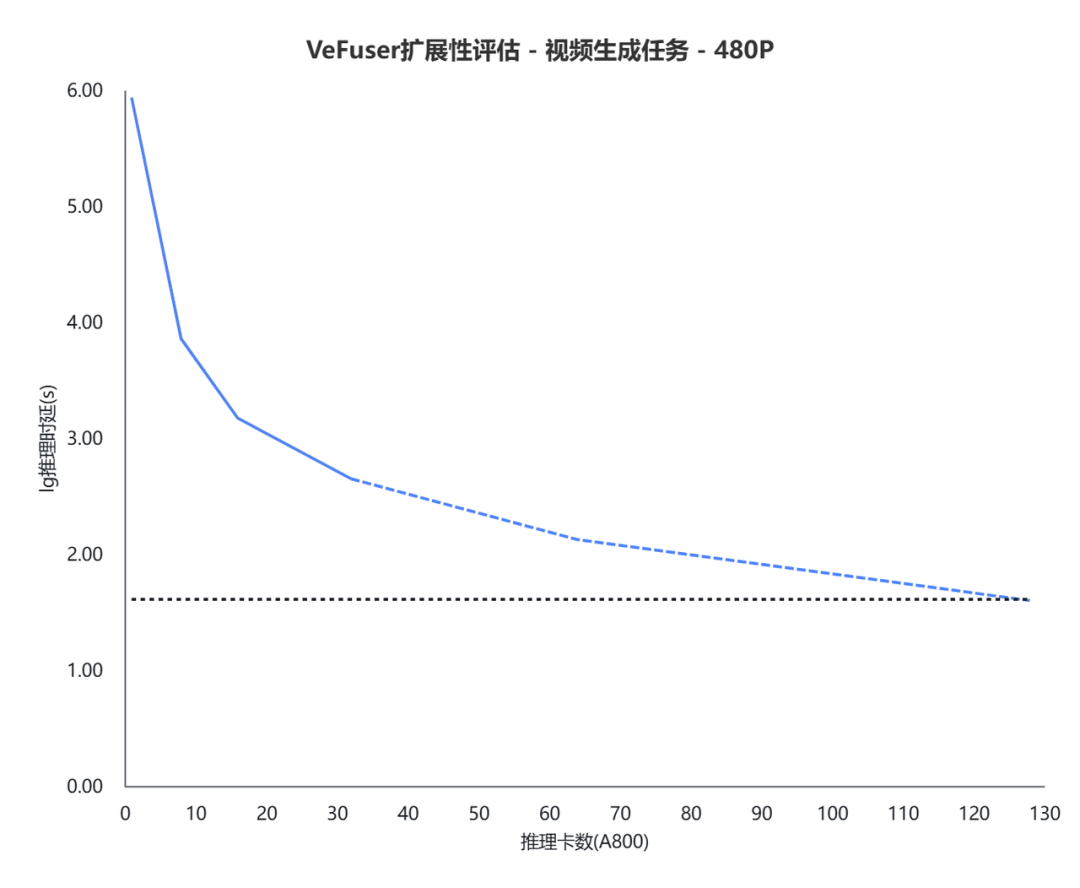
圖9 VeFuser 擴展性評估 - 視頻生成任務 - 480P(on A800)
FLUX.1 & HiDream 文生圖任務-單機性能
- 對于 FLUX.1-dev 模型:
- 在 D 卡上性能相較于開源實現單卡延時降低 83% 左右,1024px 下生成單圖的時間僅需 2.87s。
- 在 L20 上性能相較于開源實現單卡延時降低 76% 左右,1024px 下生成單圖的時間僅需 6.22s。
- 對于 HiDream-I1-Full 模型:
- 在 D 卡上性能相較于開源實現單卡延時降低 54% 左右,四卡延時降低 83% 左右,1024px 下生成單圖的時間僅 12.49s。
- 在 L20 上性能相較于開源實現單卡延時降低 57% 左右,四卡延時降低 86% 左右,1024px 下生成單圖的時間僅 13.17s。
D卡
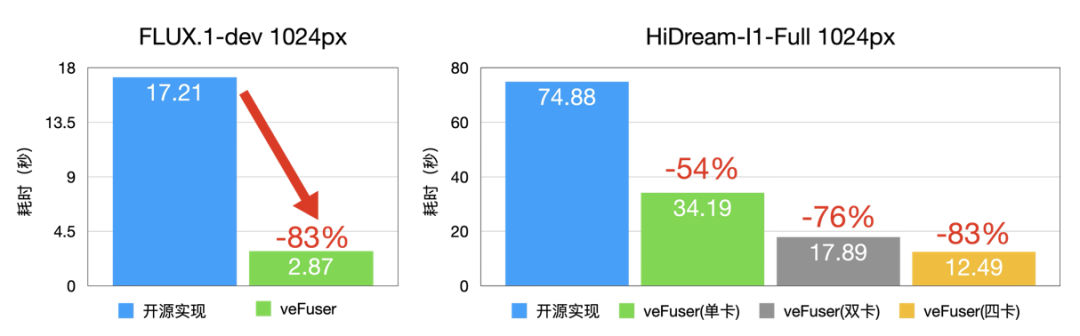
圖10 模型生圖速度(D卡)
L20
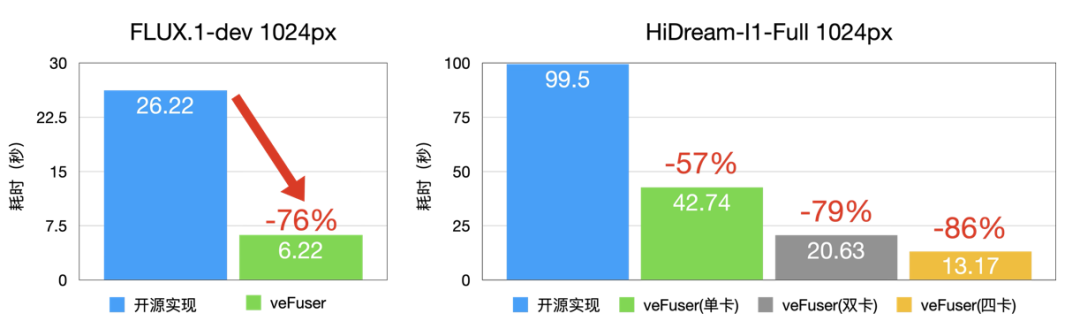
圖11 模型生圖速度(L20)
veFuser 生成效果:速度與質量兼得
火山引擎 veFuser 推理框架在加速 DiT 模型推理的同時,始終以高質量生成效果為核心目標,為用戶提供高效且高質量的圖像和視頻生成體驗。以下分別展示了使用開源模型原版與通過 veFuser 生成的視頻和圖像示例,在生成速度更快的情況下,veFuser 所生成的效果與原版一致。
- Prompt:在客廳里,一只毛茸茸的、眼睛明亮的小狗正在追逐一個玩具

圖12 開源實現生成視頻 VS veFuser生成視頻
- Prompt: A steaming plate of fettuccine Alfredo

圖13 開源實現生成圖片 VS veFuser生成圖片
總結與展望:veFuser 的持續創新與生態拓展
隨著生成式人工智能領域的高速發展,新模型,新架構層出不窮。更多元的模型選擇,更豐富的社區插件生態也共同推動了整個行業的蓬勃發展。在未來,veFuser 仍會持續迭代,在通用性,易用性,高效性等各個方面持續提升。
靈活兼容,快速迭代:持續適配新模型
針對未來 DiT 系列模型的多樣化創新,veFuser 將持續構造更加通用化的模型服務框架以及模型推理框架,抽象模型結構,實現對各種不同模型結構的“即插即用”支持,避免過多重復的開發成本。
生態開放,功能拓展:支持更加豐富的插件生態
除了目前的 LoRA 支持外,veFuser 將結合社區需求,持續支持各類文生圖/文生視頻插件生態,允許用戶自定義各種不同的插件模式,以實現生成效果的精準控制。
更極致的性能實現:推理速度,顯存開銷全面突破
通過低精度量化/模型蒸餾等方式,進一步減少推理過程的顯存開銷。同時充分結合不同算力卡型的硬件架構,定制化實現更高性能的推理算子,以實現更加極致的推理速度。
快速使用 veFuser
針對不同類型用戶對視頻生成的使用需求,火山引擎提供了兩種便捷的接入方式:火山引擎機器學習平臺(veMLP)和 火山方舟,分別適用于具備模型訓練能力的專業用戶和追求開箱即用體驗的開發者。
veMLP:靈活定制,高效部署
體驗鏈接:機器學習平臺-火山引擎
對于有定制化訓練和推理需求的用戶,可以在 veMLP 上免費使用 veFuser。用戶可以在平臺中選擇快速入門鏡像,結合主流的開源模型進行快速部署,也可以將自己訓練好的模型與推理框架集成,通過 veFuser 實現高效推理。
火山方舟:開箱即用,輕松生成高質量視頻
體驗鏈接:賬號登錄-火山引擎
如果用戶更傾向于開箱即用的體驗,火山方舟提供了基于 veFuser 推理加速的視頻生成開源模型以及字節跳動自主研發的 Seedance 模型,可以直接登錄方舟平臺在模型廣場中體驗。同時,Seedance 模型還支持 API 接口調用,便于快速集成到業務系統中,適合短視頻生成、內容創作、營銷工具等場景的快速接入和規模化應用。
求解DF1-DF14,提供完整MATLAB代碼)




)




)




的用法)

-Hive數據分析2)

