目錄
一.?業務處理模塊的任務
二. 網絡通信接口設計
2.1.文件上傳
2.2.展示頁面獲取
2.3.文件下載
三.業務處理類設計
3.1.業務處理類的代碼框架編寫?
3.2.文件上傳代碼編寫
3.3.展示頁面的獲取代碼編寫
3.4.文件下載代碼編寫——下載篇
3.4.文件下載代碼編寫——斷點續傳篇
四.服務端功能聯調
一.?業務處理模塊的任務
云備份項目中,業務處理模塊是針對客戶端的業務請求進行處理,并最終給與響應。
而整個過程中包含以下要實現的功能:
- 借助網絡通信模塊httplib庫搭建http服務器與客戶端進行網絡通信
- 針對收到的請求進行對應的業務處理并進行響應(文件上傳,列表查看,文件下載(包含斷點續傳))
仔細一看,就像是將網絡通信模塊和業務處理模塊進行了合并
因為我們可以借助httplib庫快速完成完成http服務器的搭建,所以干脆就和業務處理模塊合并到一起
服務端業務管理模塊的基本任務就是下面這些
一. 搭建網絡通信服務器:借助httplib庫完成;
二. 業務處理請求:
- 文件上傳請求:客戶端上傳需要備份的文件——服務端響應上傳文件成功;
- 文件列表請求:客戶端瀏覽器請求一個備份文件的展示頁面——服務端響應該頁面;
- 文件下載請求:客戶端通過展示頁面,點擊下載文件——服務端響應客戶端要下載的文件數據。
二. 網絡通信接口設計
什么叫網絡通信接口設計?
業務處理模塊要對客戶端的請求進行處理,那么我們就需要提前定義好客戶端與服務端的通信,明確客戶端發送什么樣的請求,服務端處理后應該給與什么樣的響應,而這就是網絡通信接口的設計.
我們的客戶端請求就是只有文件上傳,展示頁面,文件下載這3種
2.1.文件上傳
我們看個文件上傳的例子,我們從客戶端上傳一個a.txt,它的內容就是hello world,我們在服務端收到的http請求報文就是下面這樣子的
POST /upload HTTP/1.1
Content-Type:multipart/form-data;boundary= ----WebKitFormBoundary+16字節隨機字符....此處省略------WebKitFormBoundary
Content-Disposition:form-data;name="file";filename="a.txt";
Content-Type:text/plainhello world
------WebKitFormBoundary--
我們怎么獲取正文內容——hello world呢?我們是不是看到了3個------WebKitFormBoundary啊?
我們就根據這個來分割報文,就能獲得正文。
但事實上,這個活不用我們來干,httplib庫會幫我們干好,這里只是為了幫助大家理解而已。
所以最重要的部分其實就是下面這句
POST /upload HTTP/1.1當服務器收到一個POST方法的/upload請求,則我們認為這是一個文件上傳請求,我們就應該解析請求,獲得文件數據,將數據寫進文件里面,這個文件就備份成功了。
成功之后,我們還需要進行響應,這個很簡單,往客戶端返回下面這個即可(先別想太多,目前就只考慮成功的情況)
HTTP/1.1 200 OK
Content-Length: 0
2.2.展示頁面獲取
客戶端往服務端發生下面這種請求時
GET /list HTTP/1.1
Content-Length: 0
我們只關心請求方法GET和資源路徑/list。
這個時候服務器就應該返回一個html界面,來展示已經上傳的文件。
這個時候,我們服務器返回的響應報文就應該類似于是下面這樣子的
HTTP/1.1 200 OK
Content-Length:
Content-Type: text/html
...
<html>這里是html界面
</html>
我知道大家可能不太了解html,不了解也沒有關心,我們完全可以去別人的官網上面看看,它們是怎么實現的,然后隨便復制一些下來就行,我這里就簡單的copy了一些,就是為了讓大家簡單的看看一下我們大概的html的界面
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><title>Page of Download</title></head><body><h1>Download</h1><table><tr><td><a href="/download/a.txt"> a.txt </a></td><td align="right"> 1994-07-08 03:00 </td><td align="right"> 27K </td></tr></table></body>
</html>
我們可以把這個放到記事本里面去,

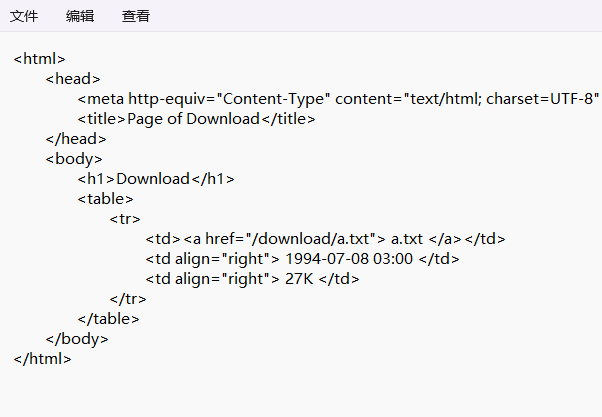
然后修改文件后綴名為html即可

然后我們打開就是下面這樣子
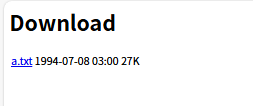
我們點擊a.txt就能實現下載,我們后面的html界面就基于上面這個界面改就OK了,不要把大量時間放到前端設計上。
2.3.文件下載
當客戶端發來下面這種請求報文,就是想要下載文件了
GET /download/a.txt http/1.1
Content-Length: 0
我們是需要關注GET和/download兩個東西的
我們服務端如何去響應呢?
大概是下面這樣子
HTTP/1.1 200 OK
Content-Length: 文件長度正文就是文件數據
至于斷點續傳,我們要等到我們基本功能都設計完成了之后,我們再來講?
三.業務處理類設計
我們這里是需要借助httplib庫的,如果說大家對httplib庫還是不太了解的,可以去:【云備份】httplib庫-CSDN博客
3.1.業務處理類的代碼框架編寫?
我們創建一個service.hpp來編寫我們的業務處理的代碼
然后,我們先把我們的這個業務處理類的框架寫出來
service.hpp
#ifndef __MY_SERVICE__
#define __MY_SERVICE__#include "data.hpp" //我們上傳文件,需要把數據放進去,需要數據管理模塊
#include"httplib.h"extern cloud::DataManager *_data;//全局的數據管理模塊
namespace cloud
{class Service{public:Service()//初始化{//我們那些東西都是從配置文件里面獲取的,這些東西配置文件都有Config* config = Config::GetInstance();_server_port = config->GetServerPort();_server_ip = config->GetSeverIp();_download_prefix = config->GetDownloadPrefix();}bool RunModule() // 主邏輯執行函數——搭建服務器{//這個就是httplib庫的使用了_server.Post("/upload", Upload);//文件上傳——對于POST方法和/upload的請求_server.Get("/listshow", ListShow);//文件列表請求//注意一件事情,當我們在瀏覽器輸入12.34.56.78:9090,瀏覽器默認會在后面加一個/,也就是12.34.56.78:9090/_server.Get("/", ListShow);//文件列表請求_server.Get("/download/(.*)", Download);//文件下載——(.*)是正則表達式,可以匹配任意一個字符串,不會的去網上搜索一下_server.listen(_server_ip.c_str(), _server_port);//一定要監聽服務器的端口return true; }private:// 文件上傳請求處理函數static void Upload(const httplib::Request &req, httplib::Response &rsp);// 展示頁面請求處理函數static void ListShow(const httplib::Request &req, httplib::Response &rsp);// 文件下載請求處理函數static void Download(const httplib::Request &req, httplib::Response &rsp);private:int _server_port; // 服務器端口std::string _server_ip; // 服務器IPstd::string _download_prefix; // 文件下載請求前綴httplib::Server _server; // Server類對象用于搭建服務器};}
#endif這里使用了正則表達式,大家可以去網上搜索一下即可
結構解析
()
表示一個捕獲組(capture group),用于提取匹配的內容。例如,匹配到的文本可以被后續代碼引用(如?$1?或?\1)。
.
匹配任意單個字符(默認不包括換行符?\n,除非開啟單行模式)。
*
表示前面的元素(此處是.)可以出現?0 次或多次(貪婪匹配,盡可能多匹配)。整體行為
(.*)?會匹配任意長度的字符串(包括空字符串),并將其捕獲到第一個分組中。如果用于全局匹配(如?
/g?標志),它會從當前位置匹配到行尾(或符合后續模式的位置)。
3.2.文件上傳代碼編寫
#ifndef __MY_SERVICE__
#define __MY_SERVICE__#include "data.hpp" //我們上傳文件,需要把數據放進去,需要數據管理模塊
#include "httplib.h"extern cloud::DataManager *_data;//全局的數據管理模塊
namespace cloud
{class Service{public:Service()//初始化{//我們那些東西都是從配置文件里面獲取的,這些東西配置文件都有Config* config = Config::GetInstance();_server_port = config->GetServerPort();_server_ip = config->GetSeverIp();_download_prefix = config->GetDownloadPrefix();}bool RunModule() // 主邏輯執行函數——搭建服務器{//這個就是httplib庫的使用了//對于12.34.56.78:9090/upload,我們就上傳文件_server.Post("/upload", Upload);//文件上傳——對于POST方法和/upload的請求//對于12.34.56.78:9090/listshow,我們就返回一個html界面_server.Get("/listshow", ListShow);//文件列表請求//注意一件事情,當我們在瀏覽器輸入12.34.56.78:9090,瀏覽器默認會在后面加一個/,也就是12.34.56.78:9090/_server.Get("/", ListShow);//文件列表請求_server.Get("/download/(.*)", Download);//文件下載——(.*)是正則表達式,可以匹配任意一個字符串,不會的去網上搜索一下_server.listen(_server_ip.c_str(), _server_port);//一定要監聽服務器的端口return true; }private:// 文件上傳請求處理函數static void Upload(const httplib::Request &req, httplib::Response &rsp){//只有請求方法是POST,url是/upload時,才能進行文件上傳//不過要注意的是,客戶端發來的http請求報文里面的正文內容并不全是數據,但是全部數據都在正文里面//這個實現很復雜,所以我們借助httplib庫auto ret=req.has_file("file");//用于檢查HTTP請求中是否包含名為 "file" 的文件上傳字段。//req.has_file("file") 中的 "file" 參數是客戶端上傳文件時使用的字段名稱(即 HTML 表單中 <input type="file"> 的 name` 屬性),并非固定死的。if(ret==false)//沒有{rsp.status=400;return;}//如果有,我們就獲取這個文件即可const auto& file = req.get_file_value("file");std::string back_dir = Config::GetInstance()->GetBackDir();//獲取配置文件里面的上傳路徑std::string realpath = back_dir + FileUtil(file.filename).FileName();//上傳路徑+文件的名稱FileUtil fu(realpath);//文件管理類fu.SetContent(file.content); // 將數據寫入文件中BackupInfo info;//數據管理模塊info.NewBackupInfo(realpath); // 組織備份的文件信息_data->Insert(info); // 向全局的數據管理模塊添加備份的文件信息return;}// 展示頁面請求處理函數static void ListShow(const httplib::Request &req, httplib::Response &rsp){}// 文件下載請求處理函數static void Download(const httplib::Request &req, httplib::Response &rsp){}private:int _server_port; // 服務器端口std::string _server_ip; // 服務器IPstd::string _download_prefix; // 文件下載請求前綴httplib::Server _server; // Server類對象用于搭建服務器};}
#endif首先我們需要將我們當前目錄下的packdir和backdir目錄里面的文件清理干凈,然后還有刪除cloud.dat,此外,我們還需要將httplib.h拷貝到當前目錄來
cp cpp-httplib/httplib.h .接著我們編寫測試函數
#include "util.hpp"
#include "conf.hpp"
#include "data.hpp"
#include"hot.hpp"
#include"service.hpp"cloud::DataManager *_data;//全局的數據管理模塊
void Servicetest()
{cloud::Service svr;svr.RunModule();
}
int main(int argc, char *argv[])
{Servicetest();
}
編譯即可
接著我們可以叫deepseek來生成一個html界面
<!DOCTYPE html>
<html>
<head><title>文件上傳</title>
</head>
<body><form action="http://117.72.80.239:9090/upload" method="post" enctype="multipart/form-data"><input type="file" name="file"><input type="submit" value="上傳"></form>
</body>
</html>這里的主機名和端口號一定要填寫我們服務器的ip和那個端口號
然后我們創建一個html界面即可

我們再創建一個www.txt,里面只寫了一句話yunbeifen,等會我們就把這個文件上傳到我們的服務器里面去
確保服務器防火墻和安全組的9090端口都開放了。

然后我們打開我們創建的那個html文件,點擊上傳,這一步是最關鍵的。

點擊上傳之后,會顯示出下面這個界面
我們回我們的服務器上看一下


很好,我們成功了
3.3.展示頁面的獲取代碼編寫
這個的過程其實也挺簡單的
- 1.獲取所有文件的備份信息——>都存放在cloud.dat里面
- 2.根據所有備份信息,組織html文件數據
cloud.dat
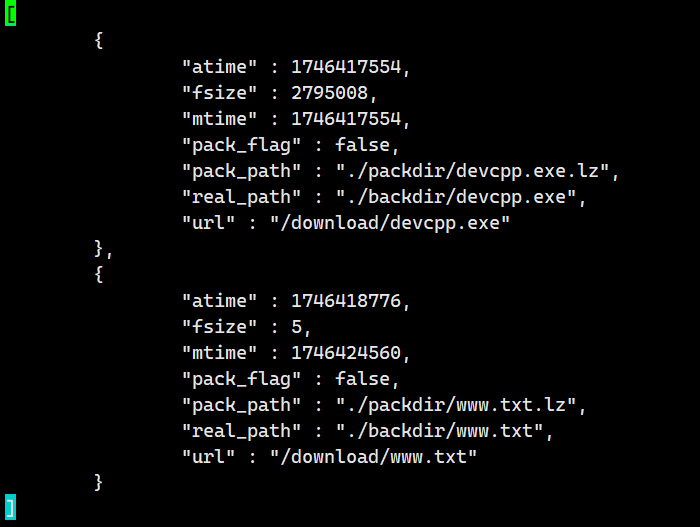
注意:我上傳了兩次www.txt。
此外我們的html界面應該是和下面類似的
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><title>Download</title></head><body><h1>Download</h1><table><tr><td><a href="/download/a.txt"> a.txt </a></td><td align="right"> 1994-07-08 03:00 </td><td align="right"> 27K </td></tr></table></body>
</html>
實際上我們可以把它寫成一行,展示的效果是一樣的
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><title>Page of Download</title></head><body><h1>Download</h1><table><tr><td><a href="/download/a.txt"> a.txt </a></td><td align="right"> 1994-07-08 03:00 </td><td align="right"> 27K </td></tr></table></body></html>那我們的代碼就很好寫了?
注意:下面這行應該交給httlib庫來寫,而不能直接寫進我們的html文件里面
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />所以我們真正寫進我們的html文件里面的是
<html><head><title>Download</title></head><body><h1>Download</h1><table><tr><td><a href="/download/a.txt"> a.txt </a></td><td align="right"> 1994-07-08 03:00 </td><td align="right"> 27K </td></tr></table></body>
</html>
好,我們的代碼如下
service.hpp?
//傳入time_t,傳出stringstatic std::string TimetoStr(time_t t){std::string tmp = std::ctime(&t);return tmp;}// 展示頁面請求處理函數static void ListShow(const httplib::Request &req, httplib::Response &rsp) {// 1.獲取所有文件的備份信息std::vector<BackupInfo> array;_data->GetAll(&array);//通過全局數據// 2.根據所有備份信息,組織html文件數據std::stringstream ss;ss << "<html><head><title>Download</title></head>";ss << "<body><h1>Download</h1><table>";for(auto &a : array){ss << "<tr>";std::string filename = FileUtil(a.real_path).FileName();ss << "<td><a href='" << a.url << "'>" << filename << "</a></td>";ss << "<td align='right'>" << TimetoStr(a.mtime) << "</td>";ss << "<td align='right'>" << a.fsize / 1024 << "k</td>";}ss << "</table></body></html>";rsp.body = ss.str();rsp.set_header("Content-Type", "text/html");rsp.status = 200;}現在我們來測試一下
cloud.cc
#include "util.hpp"
#include "conf.hpp"
#include "data.hpp"
#include"hot.hpp"
#include"service.hpp"cloud::DataManager *_data;//全局的數據管理模塊
void Servicetest()
{cloud::Service svr;svr.RunModule();
}
int main(int argc, char *argv[])
{Servicetest();
}
我們編譯運行

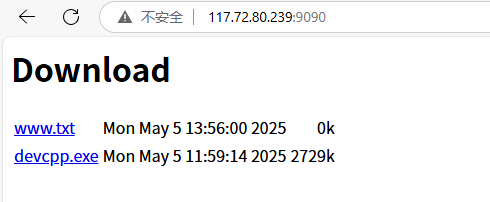
我們現在就看到了我們之前上傳的文件
現在我們再次上傳一個文件看看

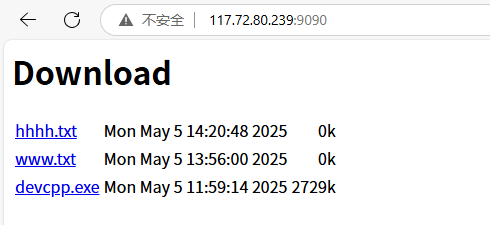
是不是挺順利的啊?
3.4.文件下載代碼編寫——下載篇
首先我們這里不搞斷點續傳,先把下載的基本功能搞定了再說
這里需要對上面我們設計的文件下載過程的內容進行補充:
- Etag字段
HTTP的Etag字段是標識文件的唯一標識
其中客戶端第一次下載文件的時候,服務器自動生成能唯一標識文件的Etag首部字段,然后將這個Etag字段加入到HTTP響應信息返還給客戶端。
第二次下載的時候客戶端就會把Etag首部字段發給服務器,而服務器則根據這個Etag判斷這個資源有沒有被修改過(即Etag值不同),如果沒有被修改過,直接使用原先緩存的數據,不用重新下載。
事實上,這個Etag是什么東西,HTTP協議并沒有說明,只需要服務端和客戶端都認識即可。
為了方便,我們將Etag設置為“文件名-文件大小-最后一次的修改時間”,這樣子也能保證能標識唯一一個文件。
而Etag不僅僅是緩存用的到,還有就是后面的斷點續傳的實現也能用到。
斷點續傳也需要保證文件沒有被修改過。事實上我們可以看看《圖解HTTP》上是怎么描述這個字段的
我們看看《圖解HTTP》是怎么描述這個字段的。
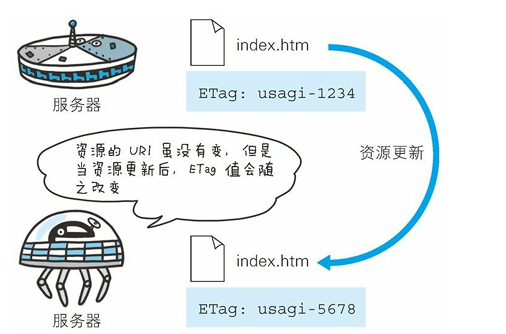
ETag: "82e22293907ce725faf67773957acd12"首部字段 ETag 能告知客戶端實體標識。
它是一種可將資源以字符串 形式做唯一性標識的方式。
服務器會為每份資源分配對應的 ETag 值。?
另外,當資源更新時,ETag 值也需要更新。
生成 ETag 值時,并沒有 統一的算法規則,而僅僅是由服務器來分配。
資源被緩存時,就會被分配唯一性標識。
例如,當使用中文版的瀏覽 器訪問 http://www.google.com/ 時,就會返回中文版對應的資源,而 使用英文版的瀏覽器訪問時,則會返回英文版對應的資源。
兩者的 URI 是相同的,所以僅憑 URI 指定緩存的資源是相當困難的。
若在下 載過程中出現連接中斷、再連接的情況,都會依照 ETag 值來指定資 源。
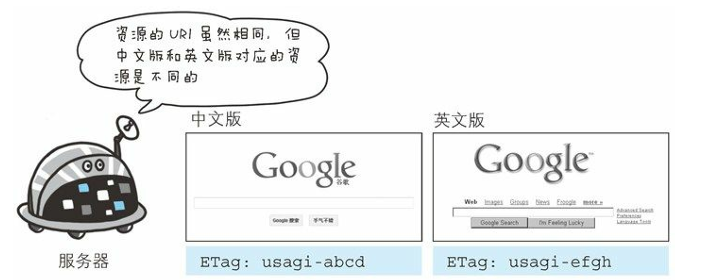
資源被緩存時,就會被分配唯一性標識。
例如,當使用中文版的瀏覽 器訪問 http://www.google.com/ 時,就會返回中文版對應的資源,而 使用英文版的瀏覽器訪問時,則會返回英文版對應的資源。
兩者的 URI 是相同的,所以僅憑 URI 指定緩存的資源是相當困難的。
若在下 載過程中出現連接中斷、再連接的情況,都會依照 ETag 值來指定資 源。
- Accept-Ranges字段
這個用于告訴客戶端,我服務器支持斷點續傳,并且數據單位以字節為單位。
也就是說,我們的服務端返回的HTTP響應報文應該是下面這樣子的
HTTP/1.1 200 OK
Content-Length: 100000
ETag: "一個能夠唯一標識文件的數據"
Accept-Ranges: bytes
文件數據
我們看看《圖解HTTP》是怎么描述的
?
圖:當不能處理范圍請求時,Accept-Ranges: none
Accept-Ranges: bytes首部字段 Accept-Ranges 是用來告知客戶端服務器是否能處理范圍請 求,以指定獲取服務器端某個部分的資源。
可指定的字段值有兩種,可處理范圍請求時指定其為 bytes,反之則 指定其為 none。
我們寫出的代碼如下:
service.hpp
// 生成Etag字段:filename-size-mtimestatic std::string GetETag(const BackupInfo &info){// etag: filename-fsize-mtimeFileUtil fu(info.real_path);std::string etag = fu.FileName();etag += '-';etag += std::to_string(info.fsize);etag += '-';etag += std::to_string(info.mtime);return etag;}// 文件下載請求處理函數static void Download(const httplib::Request &req, httplib::Response &rsp){// 1.獲取客戶端請求的路徑資源,如果被壓縮,要先解壓縮// 2.根據資源路徑,獲取文件備份信息BackupInfo info;_data->GetOneByURL(req.path, &info);// 3.判斷文件是否被壓縮,如果被壓縮,要先解壓縮if (info.pack_flag == true){FileUtil fu(info.pack_path);fu.UnCompress(info.real_path); // 將文件解壓到備份目錄下// 4.刪除壓縮包,修改備份信息(已經沒有被壓縮)fu.Remove();info.pack_flag = false;_data->Updata(info);}FileUtil fu(info.real_path);fu.GetContent(&rsp.body);//讀取文件,把文件內容放到rsp.body里面去// 5.設置相應頭部字段:Etag, Accept-Ranges: bytesrsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", GetETag(info));rsp.status = 200;}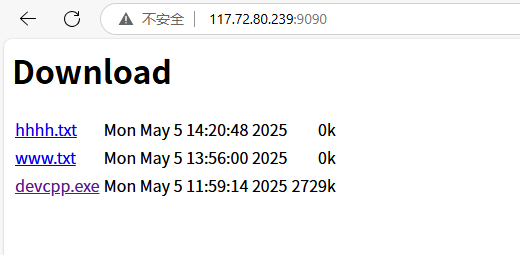
我們隨機點擊那個藍色的,可是我們點進去,它卻不是給我們下載,而是直接給我們看這個文件里面有什么
這個時候我就需要講講這個Content-Type字段的重要性了
- Content-Type
Content-Type: text/html; charset=UTF-8首部字段 Content-Type 說明了實體主體內對象的媒體類型,字段值用 type/subtype 形式賦值
Content-Type決定了瀏覽器怎么處理這個數據。我們并沒有設置Content-Type,所以我們就需要去設置一下,我們在原代碼上面加上這一句
rsp.set_header("Content-Type", "application/octet-stream");"application/octet-stream"?是一種通用的MIME類型,表示二進制數據流。
現在我們編譯運行

回到下面這個界面,隨便點擊一個藍色的
?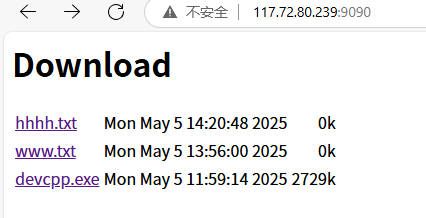
點擊之后,立馬下載了
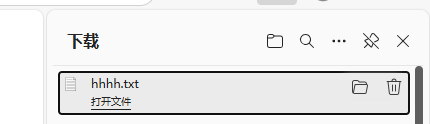
打開一看
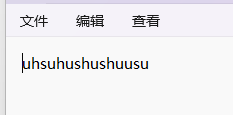
那我們怎么判斷這個hhhh.txt文件和我們之前上傳的文件是一樣的呢?
我們借助md5這個工具就行,我們打開powershell
Get-FileHash -Path "文件路徑" -Algorithm MD5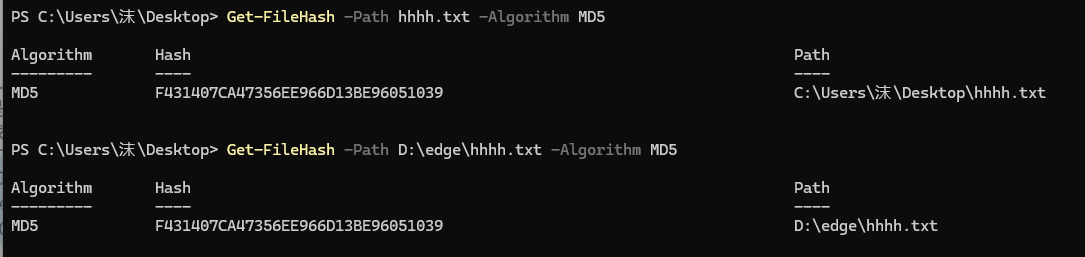
?我們發現就是一模一樣的。
3.4.文件下載代碼編寫——斷點續傳篇
先來理解一下這個斷點續傳的原理是什么
在文件下載過程中,因為某種異常而中斷,如果再次進行從頭下載,那么效率比較低下,因為需要將之前已經傳輸給的數據再次傳輸一遍。
因此斷點續傳就是從上次下載斷開的位置,重新下載即可,之前已經傳輸過的數據將不再進行重新傳輸
實現思想:
客戶端在下載文件的時候,需要每次接收到數據寫入文件后記錄自己當前下載的數據量,當異常下載中斷時,下次斷點續傳的時候,只需將要重新下載的數據區間(下載起始位置,下載結束位置)告訴服務器,這個時候服務器只需要回傳客戶端需要的區間數據即可。
需要考慮的一個問題:
如果上次下載文件之后,這個文件在服務器上被修改了,那這個時候不能斷點續傳,必須重新下載整個文件
主要關鍵點就是
- 客戶端能告訴服務器,文件下載區間范圍
- 服務器能夠檢測上一次下載這個文件后,這個文件是否被修改過
那HTTP是怎么實現斷點續傳的呢?
首先HTTP有一個Accept-Ranges字段,這個用于告訴客戶端,我服務器支持斷點續傳,并且數據單位以字節為單位。
其次服務器會發給客戶端一個Etag值,客戶端會保存起來。
接著斷點續傳的時候,客戶端會把上次下載時服務端發來的Etag值發回給這個服務端,這個時候服務端就會根據這個Etag值來判斷這個要下載的文件在上次下載之后有沒有被修改過。
此外在斷點續傳的時候,客戶端發給服務器的HTTP請求報文里面還會包含下面兩個首部字段
If-Range字段和?Range字段
- If-Range字段
這個字段是客戶端發給服務器的,不是服務器發給客戶端的!!!
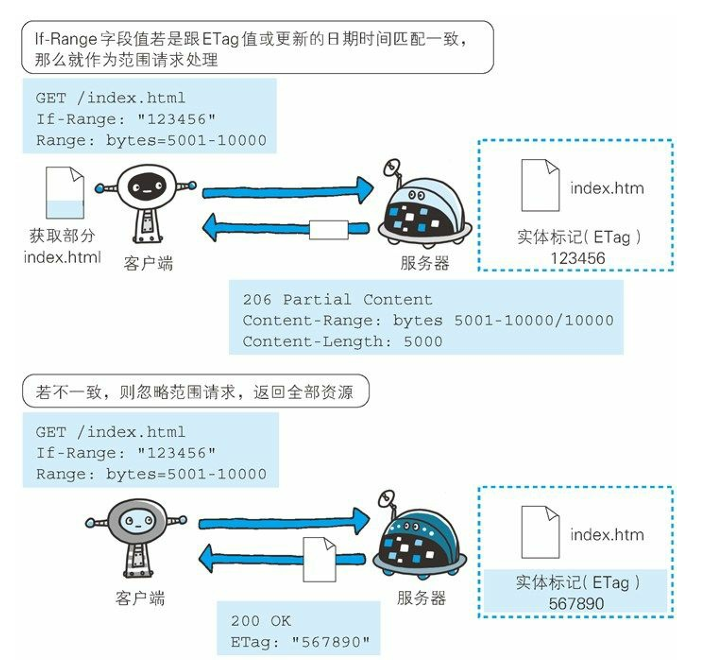
?首部字段 If-Range 屬于附帶條件之一。
它告知服務器若指定的 If Range 字段值(ETag 值或者時間)和請求資源的 ETag 值或時間相一 致時,則作為范圍請求處理。
反之,則返回全體資源。?

- ?Range
Range: bytes=5001-10000對于只需獲取部分資源的范圍請求,包含首部字段 Range 即可告知服 務器資源的指定范圍。
上面的示例表示請求獲取從第 5001 字節至第 10000 字節的資源。
接收到附帶 Range 首部字段請求的服務器,會在處理請求之后返回狀 態碼為 206 Partial Content 的響應。
無法處理該范圍請求時,則會返 回狀態碼 200 OK 的響應及全部資源。
也就是說,客戶端發來的HTTP請求一般就會包含下面這些字段
GET /download/a.txt http/1.1
Content-Length:0
If-Range:“文件唯一標識"
Range:bytes=89-999對于斷點續傳,除了客戶端發來的HTTP報文的首部字段有點不同,我們服務端的HTTP響應也是有一點不同的
我們HTTP響應需要添加Content-Range字段
- Content-Range
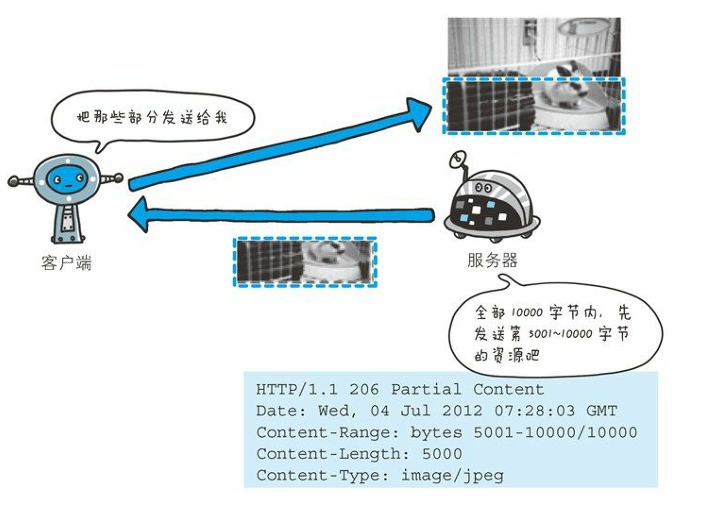
針對范圍請求,返回響應時使用的首部字段 Content-Range,能告知客 戶端作為響應返回的實體的哪個部分符合范圍請求。
字段值以字節為 單位,表示當前發送部分及整個實體大小。
Content-Range: bytes 5001-10000/10000- bytes 5001-10000:表示當前響應中返回的數據是資源的 第 5001 字節到第 10000 字節(閉區間)。
- /10000:表示資源的總大小為 10000 字節。
?除此之外,如果斷點續傳成功之后,我們的服務器需要返回206狀態碼
- 206狀態碼
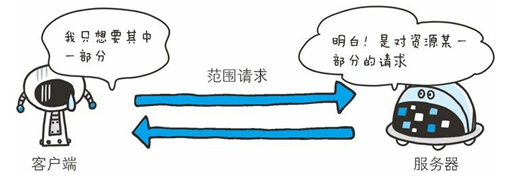
該狀態碼表示客戶端進行了范圍請求,而服務器成功執行了這部分的 GET 請求。
響應報文中包含由 Content-Range 指定范圍的實體內容。
也就是說我們的服務端的HTTP響應報文應該包含下面這些字段
HTTP/1.1 206 Partial content
Content-Length:
content-Range:bytes 89-999/100000
Content-Type:application/octet-stream
ETag:"inode-size-mtime一個能夠唯一標識文件的數據
Accept-Ranges:bytes好了,我們現在就來實現我們的斷點續傳
// 生成Etag字段:filename-size-mtimestatic std::string GetETag(const BackupInfo &info){// etag: filename-fsize-mtimeFileUtil fu(info.real_path);std::string etag = fu.FileName();etag += '-';etag += std::to_string(info.fsize);etag += '-';etag += std::to_string(info.mtime);return etag;}// 文件下載請求處理函數static void Download(const httplib::Request &req, httplib::Response &rsp){// 1.獲取客戶端請求的路徑資源,如果被壓縮,要先解壓縮// 2.根據資源路徑,獲取文件備份信息BackupInfo info;_data->GetOneByURL(req.path, &info);// 3.判斷文件是否被壓縮,如果被壓縮,要先解壓縮if(info.pack_flag == true){FileUtil fu(info.pack_path);fu.UnCompress(info.real_path); // 將文件解壓到備份目錄下// 4.刪除壓縮包,修改備份信息(已經沒有被壓縮)fu.Remove();info.pack_flag = false;_data->Updata(info);}//現在需要來判斷有沒有斷點續傳這個需要bool retrans = false;//這個表示我們需不需要斷點續傳std::string old_etag;if(req.has_header("If-Range"))//如果客戶端發來的報文里面有If-Range這個頭部字段,表示客戶端在請求斷點續傳{old_etag = req.get_header_value("If-Range");//獲取If-Range的值——Etag值// 有If-Range字段且這個字段的值與請求文件的最新Etag一致則符合斷點續傳,//不一致則表示在上一次下載之后這個文件沒有被修改過,可以進行斷點續傳if(old_etag == GetETag(info)){retrans = true;}}// 如果沒有If-Range字段則是正常下載,或者如果有這個字段,但是// 它的值與當前文件的etag不一致,則必須重新返回全部數據// 5.讀取文件數據,放入rsp.body中FileUtil fu(info.real_path);if(retrans == false)//客戶端沒有斷點續傳的需求或者在上一次下載之后這個文件被修改過,那不進行斷點續傳{fu.GetContent(&rsp.body);// 6.設置相應頭部字段:Etag, Accept-Ranges: bytesrsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", GetETag(info));rsp.set_header("Content-Type", "application/octet-stream");rsp.status = 200;}else//斷點續傳{// httplib庫內部實現了對于區間請求也就是斷點續傳請求的處理// 只需要我們用戶將文件所有數據讀取到rsp.body中,它內部會自動根據請求區間// 從body中取出指定區間數據進行響應// 也就是說,我們不需要寫std::string range = req.get_header_value("Range"); bytes=starts-endfu.GetContent(&rsp.body);rsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", GetETag(info));// rsq.set_header("Content-Range", "bytes start-end/fsize");//這個httplib庫實現了,我們就不寫了rsp.status = 206;}}我們編譯運行一下
?
我們打開我們上傳的那個界面:

我們上傳一個比較大的文件,然后在客戶端下載文件過程中,我們關閉服務器
注意文件名字不要有中文,要不然就會出現下面這個
?
上面那些亂碼的文件都是我的實驗品,請忽略


我們點擊第一個即可,點完之后立馬關閉服務器

接著我們立馬關閉服務器
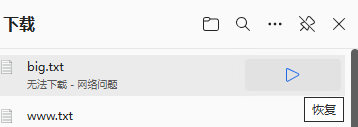
我們點擊恢復,我們發現是從上次下載的位置繼續下載的
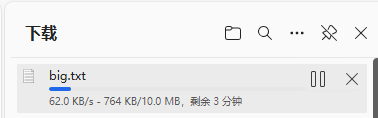
這就是我們的斷點續傳。
接著我們看看這兩個文件是不是一樣的啊
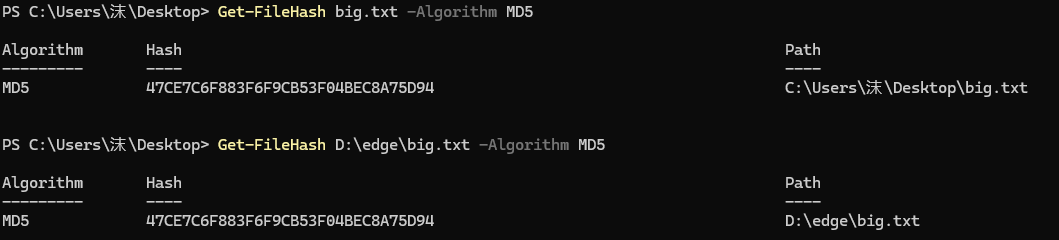
是一樣的啊!!!
?好了啊,在這里,我們就把源碼給你們
service.hpp
#ifndef __MY_SERVICE__
#define __MY_SERVICE__#include "data.hpp" //我們上傳文件,需要把數據放進去,需要數據管理模塊
#include "httplib.h"extern cloud::DataManager *_data; // 全局的數據管理模塊
namespace cloud
{class Service{public:Service() // 初始化{// 我們那些東西都是從配置文件里面獲取的,這些東西配置文件都有Config *config = Config::GetInstance();_server_port = config->GetServerPort();_server_ip = config->GetSeverIp();_download_prefix = config->GetDownloadPrefix();}bool RunModule() // 主邏輯執行函數——搭建服務器{// 這個就是httplib庫的使用了// 對于12.34.56.78:9090/upload,我們就上傳文件_server.Post("/upload", Upload); // 文件上傳——對于POST方法和/upload的請求// 對于12.34.56.78:9090/listshow,我們就返回一個html界面_server.Get("/listshow", ListShow); // 文件列表請求// 注意一件事情,當我們在瀏覽器輸入12.34.56.78:9090,瀏覽器默認會在后面加一個/,也就是12.34.56.78:9090/_server.Get("/", ListShow); // 文件列表請求_server.Get("/download/(.*)", Download); // 文件下載——(.*)是正則表達式,可以匹配任意一個字符串,不會的去網上搜索一下_server.listen(_server_ip.c_str(), _server_port); // 一定要監聽服務器的端口// 檢查服務器是否成功啟動if (!_server.listen(_server_ip.c_str(), _server_port)){std::cerr << "服務器啟動失敗!" << std::endl;return false;}return true;}private:// 文件上傳請求處理函數static void Upload(const httplib::Request &req, httplib::Response &rsp){// 只有請求方法是POST,url是/upload時,才能進行文件上傳// 不過要注意的是,客戶端發來的http請求報文里面的正文內容并不全是數據,但是全部數據都在正文里面// 這個實現很復雜,所以我們借助httplib庫auto ret = req.has_file("file"); // 用于檢查HTTP請求中是否包含名為 "file" 的文件上傳字段。// req.has_file("file") 中的 "file" 參數是客戶端上傳文件時使用的字段名稱(即 HTML 表單中 <input type="file"> 的 name` 屬性),并非固定死的。if (ret == false) // 沒有{rsp.status = 400;return;}// 如果有,我們就獲取這個文件即可const auto &file = req.get_file_value("file");std::string back_dir = Config::GetInstance()->GetBackDir(); // 獲取配置文件里面的上傳路徑std::string realpath = back_dir + FileUtil(file.filename).FileName(); // 上傳路徑+文件的名稱FileUtil fu(realpath); // 文件管理類fu.SetContent(file.content); // 將數據寫入文件中BackupInfo info; // 數據管理模塊info.NewBackupInfo(realpath); // 組織備份的文件信息_data->Insert(info); // 向全局的數據管理模塊添加備份的文件信息return;}// 傳入time_t,傳出stringstatic std::string TimetoStr(time_t t){std::string tmp = std::ctime(&t);return tmp;}// 展示頁面請求處理函數static void ListShow(const httplib::Request &req, httplib::Response &rsp){// 1.獲取所有文件的備份信息std::vector<BackupInfo> array;_data->GetAll(&array); // 通過全局數據// 2.根據所有備份信息,組織html文件數據std::stringstream ss;ss << "<html><head><title>Download</title></head>";ss << "<body><h1>Download</h1><table>";for (auto &a : array){ss << "<tr>";std::string filename = FileUtil(a.real_path).FileName();ss << "<td><a href='" << a.url << "'>" << filename << "</a></td>";ss << "<td align='right'>" << TimetoStr(a.mtime) << "</td>";ss << "<td align='right'>" << a.fsize / 1024 << "k</td>";}ss << "</table></body></html>";rsp.body = ss.str();rsp.set_header("Content-Type", "text/html");rsp.status = 200;}// 生成Etag字段:filename-size-mtimestatic std::string GetETag(const BackupInfo &info){// etag: filename-fsize-mtimeFileUtil fu(info.real_path);std::string etag = fu.FileName();etag += '-';etag += std::to_string(info.fsize);etag += '-';etag += std::to_string(info.mtime);return etag;}// 文件下載請求處理函數static void Download(const httplib::Request &req, httplib::Response &rsp){// 1.獲取客戶端請求的路徑資源,如果被壓縮,要先解壓縮// 2.根據資源路徑,獲取文件備份信息BackupInfo info;_data->GetOneByURL(req.path, &info);// 3.判斷文件是否被壓縮,如果被壓縮,要先解壓縮if(info.pack_flag == true){FileUtil fu(info.pack_path);fu.UnCompress(info.real_path); // 將文件解壓到備份目錄下// 4.刪除壓縮包,修改備份信息(已經沒有被壓縮)fu.Remove();info.pack_flag = false;_data->Updata(info);}//現在需要來判斷有沒有斷點續傳這個需要bool retrans = false;//這個表示我們需不需要斷點續傳std::string old_etag;if(req.has_header("If-Range"))//如果客戶端發來的報文里面有If-Range這個頭部字段,表示客戶端在請求斷點續傳{old_etag = req.get_header_value("If-Range");//獲取If-Range的值——Etag值// 有If-Range字段且這個字段的值與請求文件的最新Etag一致則符合斷點續傳,//不一致則表示在上一次下載之后這個文件沒有被修改過,可以進行斷點續傳if(old_etag == GetETag(info)){retrans = true;}}// 如果沒有If-Range字段則是正常下載,或者如果有這個字段,但是// 它的值與當前文件的etag不一致,則必須重新返回全部數據// 5.讀取文件數據,放入rsp.body中FileUtil fu(info.real_path);if(retrans == false)//客戶端沒有斷點續傳的需求或者在上一次下載之后這個文件被修改過,那不進行斷點續傳{fu.GetContent(&rsp.body);// 6.設置相應頭部字段:Etag, Accept-Ranges: bytesrsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", GetETag(info));rsp.set_header("Content-Type", "application/octet-stream");rsp.status = 200;}else//斷點續傳{// httplib庫內部實現了對于區間請求也就是斷點續傳請求的處理// 只需要我們用戶將文件所有數據讀取到rsp.body中,它內部會自動根據請求區間// 從body中取出指定區間數據進行響應// 也就是說,我們不需要寫std::string range = req.get_header_value("Range"); bytes=starts-endfu.GetContent(&rsp.body);rsp.set_header("Accept-Ranges", "bytes");rsp.set_header("ETag", GetETag(info));// rsq.set_header("Content-Range", "bytes start-end/fsize");//這個httplib庫實現了,我們就不寫了rsp.status = 206;}}private:int _server_port; // 服務器端口std::string _server_ip; // 服務器IPstd::string _download_prefix; // 文件下載請求前綴httplib::Server _server; // Server類對象用于搭建服務器};}
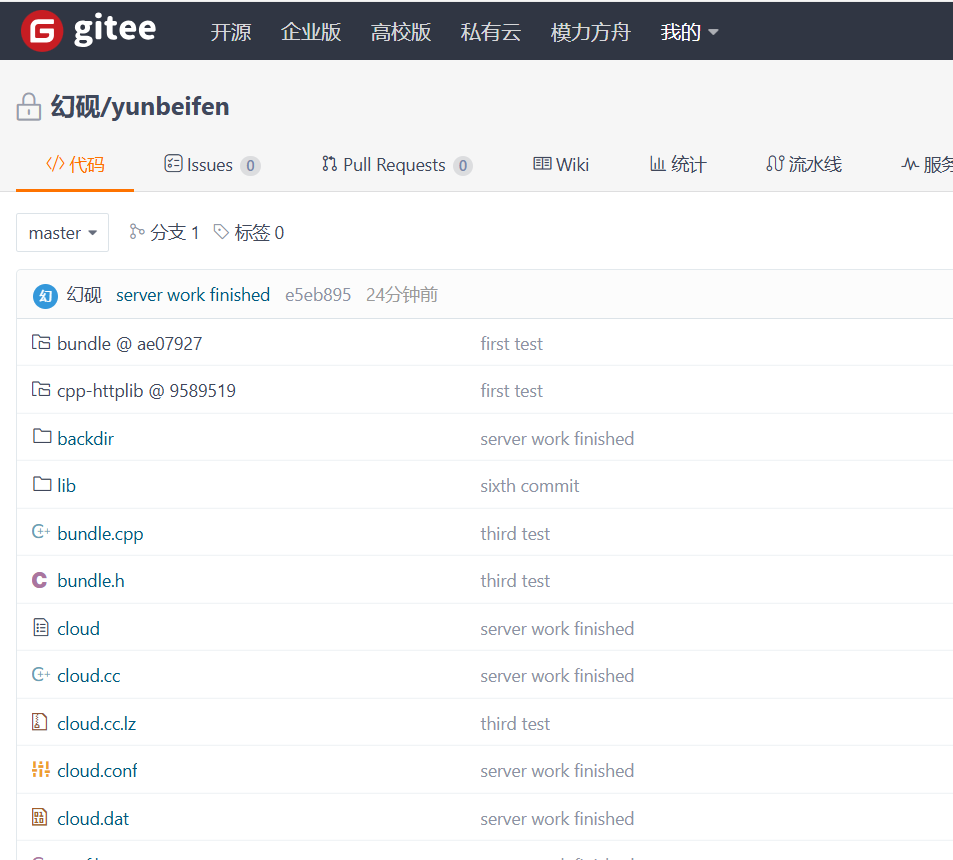
#endif我們git一下
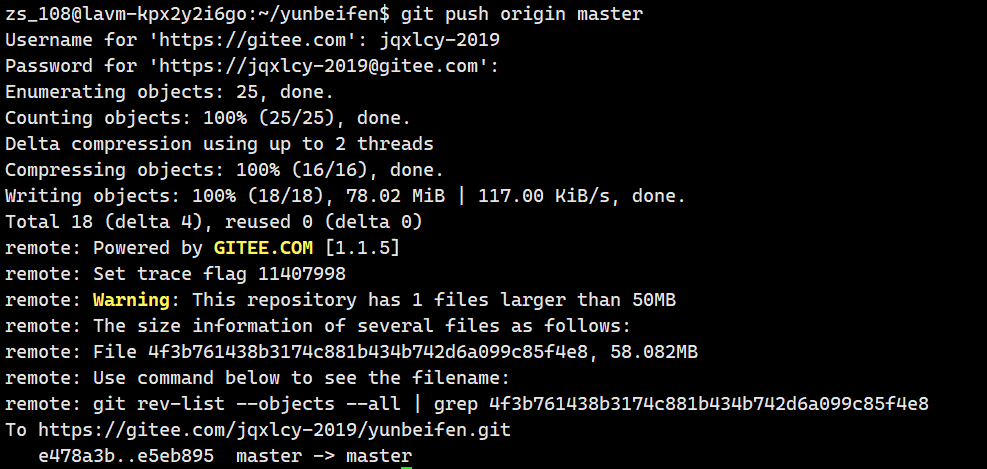
?
四.服務端功能聯調
?到這里我們的服務端就算是寫完了。我們得讓這個服務器運行起來
我們這個熱點管理模塊是一個死循環,我們的業務處理模塊也是一個死循環
兩個死循環,那我們只能使用多線程了
cloud.cc
#include "util.hpp"
#include "conf.hpp"
#include "data.hpp"
#include"hot.hpp"
#include"service.hpp"
#include<thread>cloud::DataManager *_data;//全局的數據管理模塊
void Servicetest()
{cloud::Service svr;svr.RunModule();
}
void HotTest()
{_data=new cloud::DataManager();cloud::HotManager hot;hot.RunModule();}
int main(int argc, char *argv[])
{_data=new cloud::DataManager();//C++多線程模塊std::thread thread_hot_manager(HotTest);std::thread thread_service(Servicetest);//等待線程退出thread_hot_manager.join();thread_service.join();Servicetest();}
?
我們打開這個網站
我們上傳一個文件上去

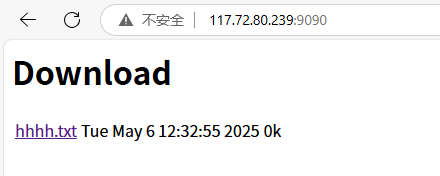
這個時候我們等待30s,這個是我們的熱點管理時間

等待30s后,我們發現下面這個情況

這個時候展示界面是沒有變化的
這個時候我們點擊下載,發現是下面這種情況
這個時候我們再等30s,發現是下面這個

這個就很完美了




)


——Mistral-7B實現流式傳輸音頻:魔力8號球)







)



