1.?決策樹-分類
1.1?概念
????????1. 決策節點 通過條件判斷而進行分支選擇的節點。如:將某個樣本中的屬性值(特征值)與決策節點上的值進行比較,從而判斷它的流向。
????????2. 葉子節點 沒有子節點的節點,表示最終的決策結果。
????????3. 決策樹的深度 所有節點的最大層次數,決策樹具有一定的層次結構,根節點的層次數定為0,從下面開始每一層子節點層次數增加。
????????4. 決策樹優點:可視化 - 可解釋能力-對算力要求低。
????????5. 決策樹缺點:容易產生過擬合,所以不要把深度調整太大了。

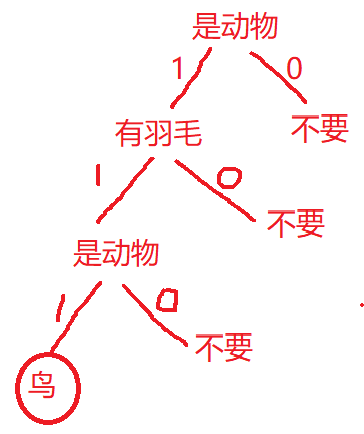
| 是動物 | 能飛 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
| 飛機 | 0 | 1 | 0 |
| 熊貓 | 1 | 0 | 0 |
?????????是否為動物:
| 是動物 | 能飛 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
| 熊貓 | 1 | 0 | 0 |
????????是否會飛:
| 是動物 | 能飛 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
????????是否有羽毛:
| 是動物 | 能飛 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
1.2?基于信息增益決策樹的建立
????????信息增益決策樹傾向于選擇取值較多的屬性,在有些情況下這類屬性可能不會提供太多有價值的信息,算法只能對描述屬性為離散型屬性的數據集構造決策樹。
????????根據以下信息構建一棵預測是否貸款的決策樹。我們可以看到有4個影響因素:職業,年齡,收入和學歷。
| 職業 | 年齡 | 收入 | 學歷 | 是否貸款 | |
| 1 | 工人 | 36 | 5500 | 高中 | 否 |
| 2 | 工人 | 42 | 2800 | 初中 | 是 |
| 3 | 白領 | 45 | 3300 | 小學 | 是 |
| 4 | 白領 | 25 | 10000 | 本科 | 是 |
| 5 | 白領 | 32 | 8000 | 碩士 | 否 |
| 6 | 白領 | 28 | 13000 | 博士 | 是 |
? ? ? ? (1)信息熵:信息熵描述的是不確定性。信息熵越大,不確定性越大。信息熵的值越小,則D的純度越高。
????????假設樣本集合D共有N類,第k類樣本所占比例為,則D的信息熵為:
![]()
? ? ? ? (2)信息增益:信息增益是一個統計量,用來描述一個屬性區分數據樣本的能力。信息增益越大,那么決策樹就會越簡潔。這里信息增益的程度用信息熵的變化程度來衡量, 信息增益公式:![]()
? ? ? ? (3 )信息增益決策樹建立步驟:第一步,計算根節點的信息熵上表根據是否貸款把樣本分成2類樣本,"是"占4/6=2/3, "否"占2/6=1/3,所以![]() ;第二步,計算屬性的信息增益:
;第二步,計算屬性的信息增益:
????????<1> "職業"屬性的信息增益![]() ,在職業中,工人占1/3, ?工人中,是否代款各占1/2, ?所以有
,在職業中,工人占1/3, ?工人中,是否代款各占1/2, ?所以有![]() ,在職業中,白領占2/3, ?白領中,是貸款占3/4, 不貸款占1/4, 所以有
,在職業中,白領占2/3, ?白領中,是貸款占3/4, 不貸款占1/4, 所以有![]() ,所以有
,所以有![]() ,最后得到職業屬性的信息增益為:
,最后得到職業屬性的信息增益為:![]() 。
。
????????<2>" 年齡"屬性的信息增益(以35歲為界)
![]()
????????<3> "收入"屬性的信息增益(以10000為界,大于等于10000為一類)
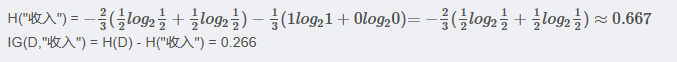
????????<4> "學歷"屬性的信息增益(以高中為界, 大于等于高中的為一類)
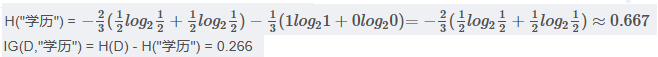
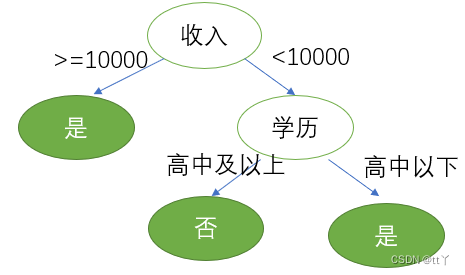
????????第三步,劃分屬性,對比屬性信息增益發現,"收入"和"學歷"相等,并且是最高的,所以我們就可以選擇"學歷"或"收入"作為第一個決策樹的節點, 接下來我們繼續重復1,2的做法繼續尋找合適的屬性節點。
1.3?基于基尼指數決策樹的建立(了解)
????????基尼指數(Gini Index)是決策樹算法中用于評估數據集純度的一種度量,基尼指數衡量的是數據集的不純度,或者說分類的不確定性。在構建決策樹時,基尼指數被用來決定如何對數據集進行最優劃分,以減少不純度。
????????基尼指數的計算:對于一個二分類問題,如果一個節點包含的樣本屬于正類的概率是 (p),則屬于負類的概率是 (1-p)。那么,這個節點的基尼指數 (Gini(p)) 定義為:
????????????????????????????????????????
????????對于多分類問題,如果一個節點包含的樣本屬于第 k 類的概率是 p_k,則節點的基尼指數定義為:
?????????????????????????????????????????????????????????????
????????基尼指數的意義:1. 當一個節點的所有樣本都屬于同一類別時,基尼指數為 0,表示純度最高。2. 當一個節點的樣本均勻分布在所有類別時,基尼指數最大,表示純度最低。
????????決策樹中的應用:在構建決策樹時,我們希望每個內部節點的子節點能更純,即基尼指數更小。因此,選擇分割特征和分割點的目標是使子節點的平均基尼指數最小化。具體來說,對于一個特征,我們計算其所有可能的分割點對應的子節點的加權平均基尼指數,然后選擇最小化這個值的分割點。這個過程會在所有特征中重復,直到找到最佳的分割特征和分割點。
????????例如,考慮一個數據集 (D),其中包含 (N) 個樣本,特征 (A) 將數據集分割為 |D_1|和 |D_2| ,則特征 (A) 的基尼指數為:
????????????????????????????????????????????????????????????????????
其中 |D_1|和 |D_2| 分別是子集 D_1 和 D_2 中的樣本數量。
????????通過這樣的方式,決策樹算法逐步構建一棵樹,每一層的節點都盡可能地減少基尼指數,最終達到對數據集的有效分類。
????????案例:
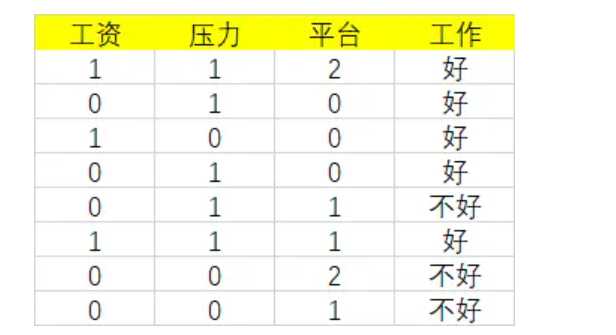
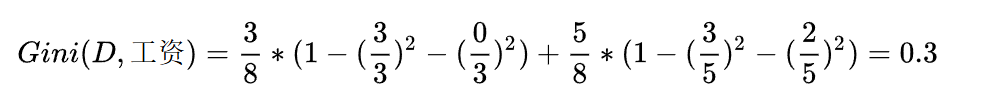
????????首先工資有兩個取值,分別是0和1。當工資=1時,有3個樣本。所以:
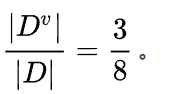
????????同時,在這三個樣本中,工作都是好。所以:
![]()
????????就有了加號左邊的式子:
![]()
????????同理,當工資=0時,有5個樣本,在這五個樣本中,工作有3個是不好,2個是好。就有了加號右邊的式子:
![]()
????????同理,可得壓力的基尼指數如下:
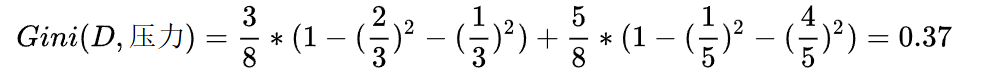
????????平臺的基尼指數如下:
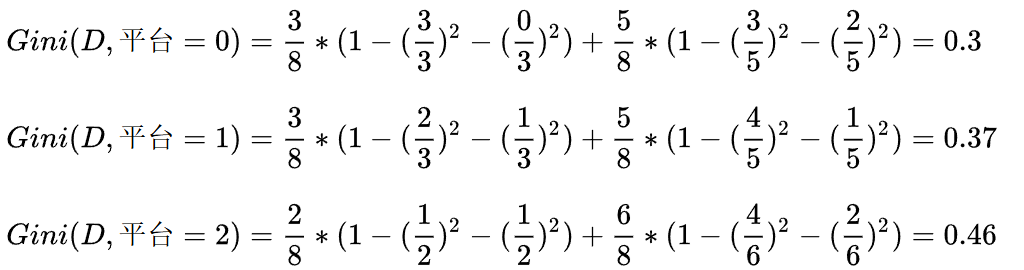
????????在計算時,工資和平臺的計算方式有明顯的不同。因為工資只有兩個取值0和1,而平臺有三個取值0,1,2。所以在計算時,需要將平臺的每一個取值都單獨進行計算。比如:當平臺=0時,將數據集分為兩部分,第一部分是平臺=0,第二部分是平臺!=0(分母是5的原因)。根據基尼指數最小準則, 我們優先選擇工資或者平臺=0作為D的第一特征。
????????我們選擇工資作為第一特征,那么當工資=1時,工作=好,無需繼續劃分。當工資=0時,需要繼續劃分。
????????當工資=0時,繼續計算基尼指數:
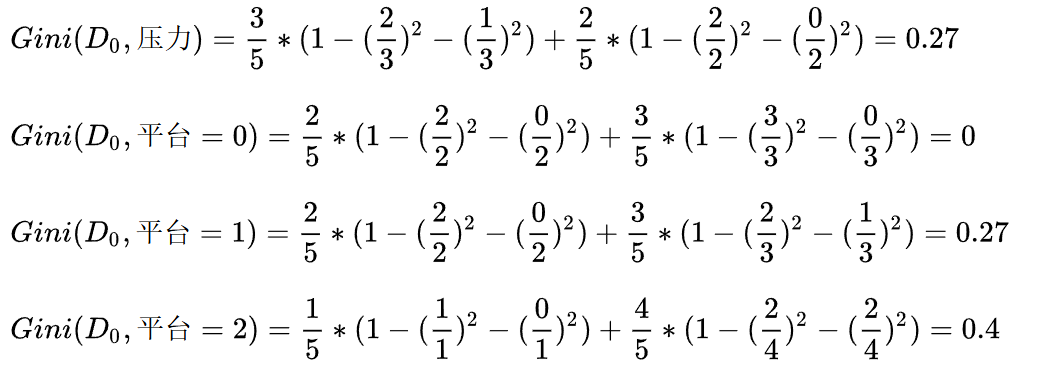
????????當平臺=0時,基尼指數=0,可以優先選擇。同時,當平臺=0時,工作都是好,無需繼續劃分,當平臺=1,2時,工作都是不好,也無需繼續劃分。直接把1,2放到樹的一個結點就可以。
1.4 API介紹??
class sklearn.tree.DecisionTreeClassifier(....)
參數:
criterion "gini" "entropy” 默認為="gini" 當criterion取值為"gini"時采用 基尼不純度(Gini impurity)算法構造決策樹,當criterion取值為"entropy”時采用信息增益( information gain)算法構造決策樹.
max_depth int, 默認為=None 樹的最大深度# 可視化決策樹
function sklearn.tree.export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
參數:estimator決策樹預估器out_file生成的文檔feature_names節點特征屬性名
功能:把生成的文檔打開,復制出內容粘貼到"http://webgraphviz.com/"中,點擊"generate Graph"會生成一個樹型的決策樹圖? ? ? ? 示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, export_graphviz# 1)獲取數據集
iris = load_iris()# 2)劃分數據集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)#3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)決策樹預估器
estimator = DecisionTreeClassifier(criterion="entropy")estimator.fit(x_train, y_train)# 5)模型評估,計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)# 6)預測
index=estimator.predict([[2,2,3,1]])
print("預測:\n",index,iris.target_names,iris.target_names[index])# 可視化決策樹
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)????????把文件"iris_tree.dot"內容粘貼到"Webgraphviz"點擊"generate Graph"決策樹圖:
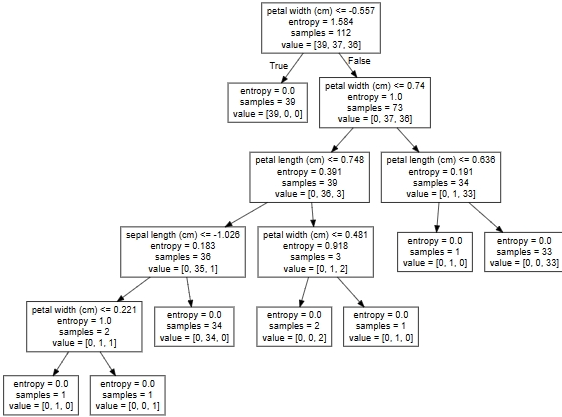
? ? ? ? 示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
# 1、獲取數據
titanic = pd.read_csv("src/titanic/titanic.csv")
titanic.head()
# 篩選特征值和目標值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]#2、數據處理
# 1)缺失值處理, 因為其中age有缺失值。
x["age"].fillna(x["age"].mean(), inplace=True)# 2) 轉換成字典, 因為其中數據必須為數字才能進行決策樹,所在先轉成字典,后面又字典特征抽取,這樣之后的數據就會是數字了, 鳶尾花的數據本來就全部是數字,所以不需要這一步。
"""
x.to_dict(orient="records") 這個方法通常用于 Pandas DataFrame 對象,用來將 DataFrame 轉換為一個列表,其中列表的每一個元素是一個字典,對應于 DataFrame 中的一行記錄。字典的鍵是 DataFrame 的列名,值則是該行中對應的列值。
假設你有一個如下所示的 DataFrame x:A B C
0 1 4 7
1 2 5 8
2 3 6 9
執行 x.to_dict(orient="records"),你會得到這樣的輸出:
[{'A': 1, 'B': 4, 'C': 7},{'A': 2, 'B': 5, 'C': 8},{'A': 3, 'B': 6, 'C': 9}
]
"""
x = x.to_dict(orient="records")
# 3)、數據集劃分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train) #稀疏矩陣
x_test = transfer.transform(x_test)# 3)決策樹預估器
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=8)
estimator.fit(x_train, y_train)# 4)模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)# 6)預測
x_test = transfer.transform([{'pclass': '1rd', 'age': 22.0, 'sex': 'female'}])
index=estimator.predict(x_test)
print("預測1:\n",index)#[1] 頭等艙的就可以活下來
x_test = transfer.transform([{'pclass': '3rd', 'age': 22.0, 'sex': 'female'}])
index=estimator.predict(x_test)
print("預測2:\n",index)#[0] 3等艙的活不下來# 可視化決策樹
export_graphviz(estimator, out_file="titanic_tree.dot", feature_names=transfer.get_feature_names_out())2.?集成學習方法之隨機森林
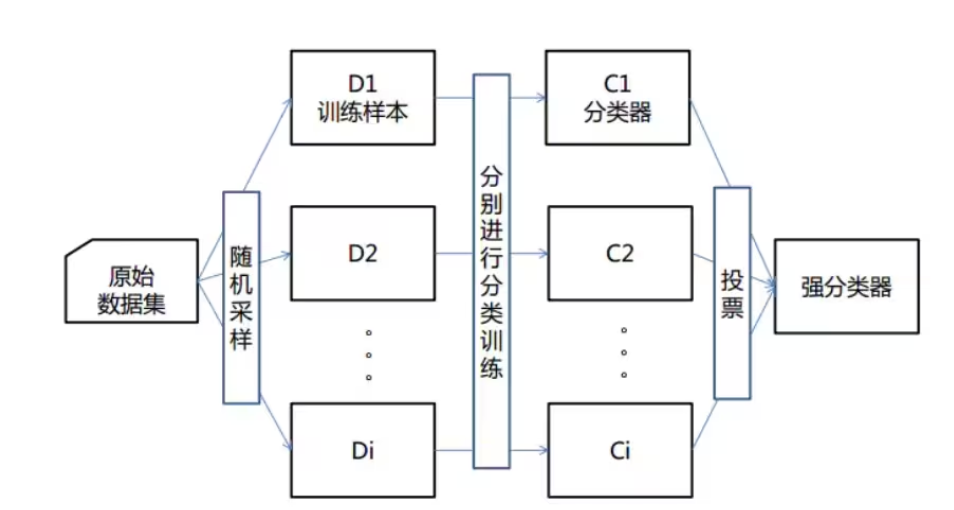
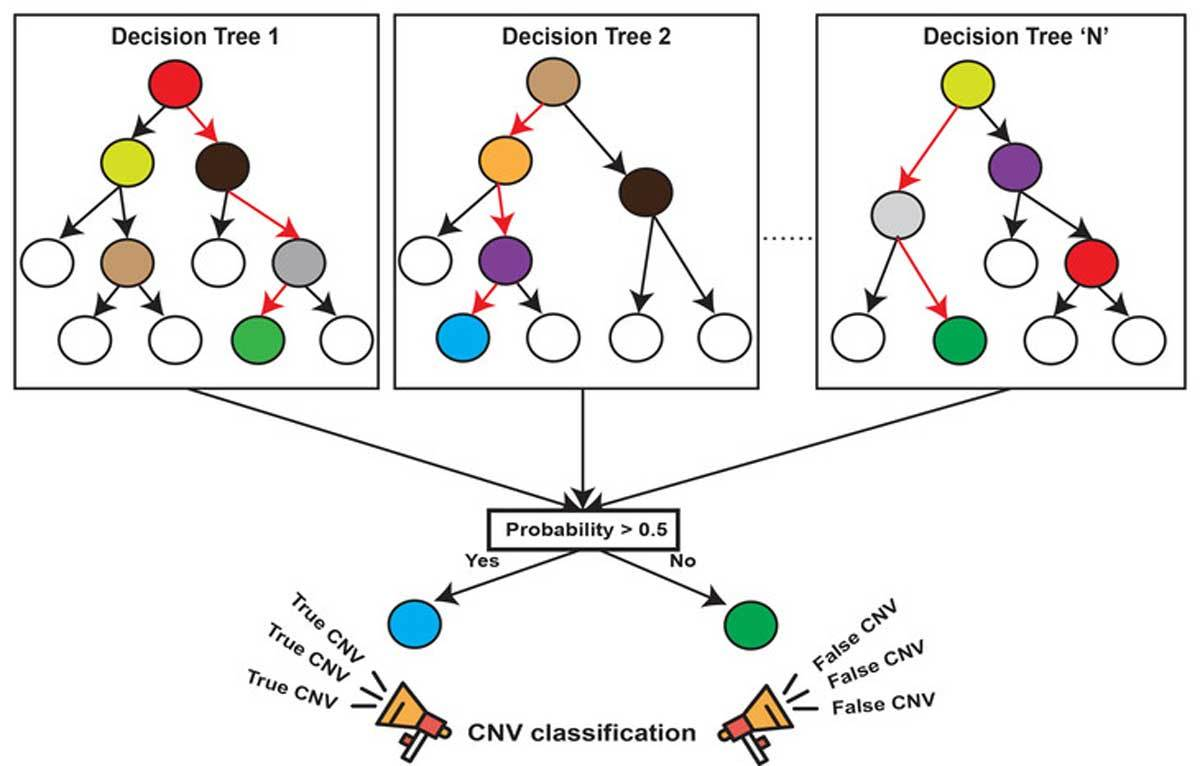
????????機器學習中有一種大類叫集成學習(Ensemble Learning),集成學習的基本思想就是將多個分類器組合,從而實現一個預測效果更好的集成分類器。集成算法可以說從一方面驗證了中國的一句老話:三個臭皮匠,賽過諸葛亮。集成算法大致可以分為:Bagging,Boosting 和 Stacking 三大類型。
(1)每次有放回地從訓練集中取出 n 個訓練樣本,組成新的訓練集;
(2)利用新的訓練集,訓練得到M個子模型;
(3)對于分類問題,采用投票的方法,得票最多子模型的分類類別為最終的類別;
????????隨機森林就屬于集成學習,是通過構建一個包含多個決策樹(通常稱為基學習器或弱學習器)的森林,每棵樹都在不同的數據子集和特征子集上進行訓練,最終通過投票或平均預測結果來產生更準確和穩健的預測。這種方法不僅提高了預測精度,也降低了過擬合風險,并且能夠處理高維度和大規模數據集。
2.1?算法原理
-
隨機: 特征隨機,訓練集隨機
-
樣本:對于一個總體訓練集T,T中共有N個樣本,每次有放回地隨機選擇n個樣本。用這n個樣本來訓練一個決策樹。
-
特征:假設訓練集的特征個數為d,每次僅選擇k(k<d)個來構建決策樹。
-
-
森林: 多個決策樹分類器構成的分類器, 因為隨機,所以可以生成多個決策樹
-
處理具有高維特征的輸入樣本,而且不需要降維
-
使用平均或者投票來提高預測精度和控制過擬合
2.2 API 介紹
class sklearn.ensemble.RandomForestClassifier參數:
n_estimators int, default=100
森林中樹木的數量。(決策樹個數)criterion {“gini”, “entropy”}, default=”gini” 決策樹屬性劃分算法選擇當criterion取值為“gini”時采用 基尼不純度(Gini impurity)算法構造決策樹,當criterion取值為 “entropy” 時采用信息增益( information gain)算法構造決策樹.max_depth int, default=None 樹的最大深度。 ? ? ? ? 示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 1、獲取數據
titanic = pd.read_csv("src/titanic/titanic.csv")
titanic.head()
# 篩選特征值和目標值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]#2、數據處理
# 1)缺失值處理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2) 轉換成字典
x = x.to_dict(orient="records")
# 3)、數據集劃分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)'''
#3 預估: 不加網格搜索與交叉驗證的代碼
estimator = RandomForestClassifier(n_estimators=120, max_depth=5)
# 訓練
estimator.fit(x_train, y_train)
'''#3 預估: 加網格搜索與交叉驗證的代碼
estimator = RandomForestClassifier()
# 參數準備 n_estimators樹的數量, max_depth樹的最大深度
param_dict = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5,8,15,25,30]}
# 加入網格搜索與交叉驗證, cv=3表示3次交叉驗證
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 訓練
estimator.fit(x_train, y_train)# 5)模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)'''
加網格搜索與交叉驗證的代碼
print("最佳參數:\n", estimator.best_params_)
print("最佳結果:\n", estimator.best_score_)
print("最佳估計器:\n", estimator.best_estimator_)
print("交叉驗證結果:\n", estimator.cv_results_)
'''
#估計運行花1min-第十三章 拷貝控制)
)

:源碼解析:數據處理模塊)
(Day 1))

)










_47)
 去除無效的干擾!巧妙轉化)
