引言
Streamlit 在開發大模型AI測試工具方面具有顯著的重要性,尤其是在簡化開發流程、增強交互性以及促進快速迭代等方面。以下是幾個關鍵點,說明了 Streamlit 對于構建大模型AI測試工具的重要性:
1. 快速原型設計和迭代
對于大模型AI測試工具的開發而言,快速構建原型并進行迭代至關重要。Streamlit 允許開發者通過簡單的Python腳本快速創建Web應用程序,無需深入掌握前端技術(如HTML、CSS、JavaScript)。這種能力使得團隊能夠迅速將想法轉化為可交互的界面,加速了從概念驗證到實際應用的過程。
2. 強大的數據可視化支持
在評估大模型的表現時,數據可視化是不可或缺的一環。Streamlit 提供了豐富的內置函數用于生成圖表和圖形,包括折線圖、柱狀圖、散點圖等,并且可以輕松地與更高級的數據可視化庫(如 Altair 或 Plotly)集成。這有助于直觀展示模型性能指標、誤差分布、特征重要性等內容,從而幫助研究人員更好地理解和優化模型。
3. 簡化的用戶交互設計
Streamlit 使得添加用戶輸入控件變得極為簡單,例如滑塊、下拉菜單、復選框等。這對于調整超參數、選擇不同的模型版本或配置測試場景非常有用。它允許非技術人員也能夠方便地使用這些工具,提高了協作效率。
4. 實時反饋機制
Streamlit 應用程序能夠實時響應用戶的輸入變化,這意味著任何對變量的修改都會立即反映在界面上。這一特性特別適合于調試復雜的機器學習模型,因為它可以讓開發者即時看到參數調整后的效果,從而更快地找到最優解。
5. 易于分享和部署
一旦開發完成,Streamlit 應用可以通過命令行一鍵部署到云端服務(如Heroku、AWS等),也可以直接運行在本地服務器上供團隊內部訪問。此外,由于其基于Python的特性,結合Docker容器化技術,可以確保環境的一致性和穩定性,便于跨平臺分享和部署。
6. 社區支持與擴展性
作為一個開源項目,Streamlit 擁有一個活躍的社區,提供了大量的教程、案例研究和第三方插件,可以幫助開發者解決遇到的各種問題。同時,它還支持與其他流行的Python庫(如Pandas、NumPy、Scikit-learn等)無縫集成,為構建復雜的大模型AI測試工具提供了強大的后端支持。
綜上所述,Streamlit 憑借其易用性、靈活性及強大的功能,在開發大模型AI測試工具中扮演著至關重要的角色。無論是對于初學者還是經驗豐富的開發者來說,都是一個值得考慮的選擇。它可以極大地提高工作效率,降低技術門檻,使更多的人能夠參與到AI模型的測試與優化工作中來。本文將詳細介紹如何使用Streamlit來創建一個實用的自動化測試報告生成器,并提供完整的代碼示例,適合初學者學習。
一、環境搭建與依賴安裝
安裝必要的庫
在開始之前,請確保你已經安裝了Python(建議版本3.7及以上)。接下來,我們需要安裝幾個關鍵的庫:
- Streamlit:用于構建Web界面。
- Pandas:用于數據處理。
- Openpyxl:用于讀取Excel文件。
可以通過以下命令安裝這些庫:
pip install streamlit pandas openpyxl
二、代碼分段解讀
1. 加載數據函數
首先定義一個函數來加載上傳的Excel文件。這里我們使用@st.cache_data裝飾器來緩存數據,提高性能。
import streamlit as st
import pandas as pd# 加載數據函數
@st.cache_data # 使用緩存提高性能
def load_data(file_path):return pd.read_excel(file_path, engine='openpyxl')
2. 主頁面設置
接下來設置主頁面的標題和描述,讓用戶了解該應用的目的。
# 主頁面設置
st.title("自動化測試報告生成器")
st.write("""
這是一個基于Streamlit的應用程序,用于分析和展示自動化測試的結果。
""")
3. 上傳Excel文件
提供一個文件上傳組件,允許用戶選擇并上傳Excel文件。
# 上傳Excel文件
uploaded_file = st.file_uploader("選擇一個Excel文件", type=["xlsx"])
if uploaded_file is not None:data = load_data(uploaded_file)
4. 數據驗證
檢查上傳的Excel文件是否包含所有必需的列,如“Test Name”、“Status”和“Execution Time”。
# 確認必要列存在required_columns = ['Test Name', 'Status', 'Execution Time']missing_columns = [col for col in required_columns if col not in data.columns]if missing_columns:st.error(f"缺少必需的列: {', '.join(missing_columns)}")
5. 顯示原始數據選項
提供一個選項讓用戶查看上傳文件中的原始數據。
else:# 顯示原始數據選項if st.checkbox('顯示原始數據'):st.subheader('原始數據')st.write(data)
6. 篩選條件
允許用戶根據測試狀態(通過/失敗)進行篩選。
# 篩選條件st.sidebar.header("篩選條件")status_filter = st.sidebar.multiselect("選擇測試狀態",options=['Pass', 'Fail'],default=['Pass', 'Fail'])
7. 應用篩選條件
根據用戶選擇的狀態過濾數據。
# 應用篩選條件filtered_data = data[data['Status'].isin(status_filter)]
8. 顯示概覽信息
計算并展示總測試數、通過測試數、失敗測試數及通過率等概覽信息。
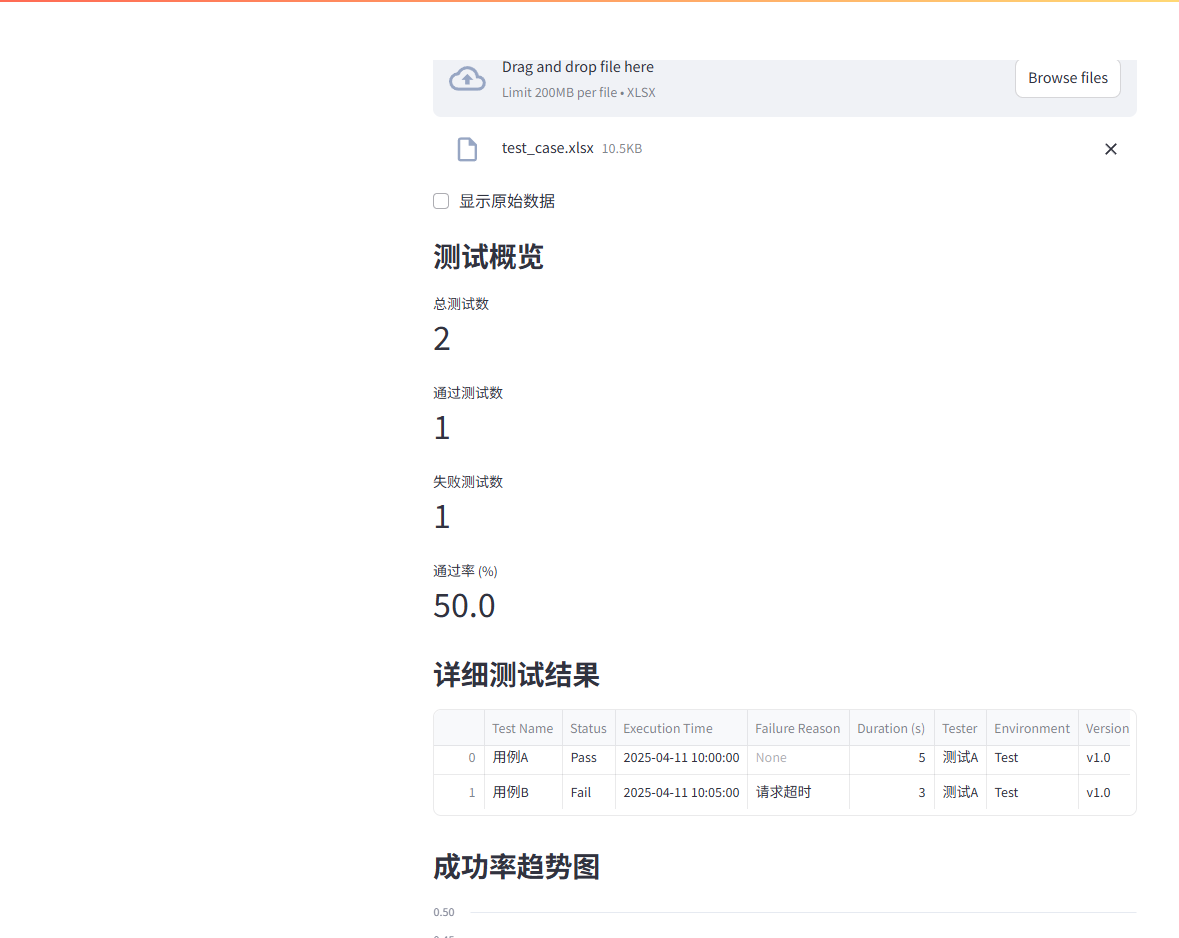
# 顯示概覽信息total_tests = len(filtered_data)passed_tests = (filtered_data['Status'] == 'Pass').sum()failure_tests = total_tests - passed_testspass_rate = round((passed_tests / total_tests) * 100, 2)st.subheader("測試概覽")st.metric(label="總測試數", value=total_tests)st.metric(label="通過測試數", value=passed_tests)st.metric(label="失敗測試數", value=failure_tests)st.metric(label="通過率 (%)", value=pass_rate)
9. 顯示詳細測試結果
以表格形式展示經過篩選后的測試結果。
# 顯示詳細測試結果st.subheader("詳細測試結果")st.dataframe(filtered_data)
10. 成功率趨勢圖
繪制每日的成功率趨勢圖,幫助分析測試結果的變化趨勢。
# 成功率趨勢圖success_rate_over_time = filtered_data.groupby(pd.Grouper(key='Execution Time', freq='D'))['Status'].apply(lambda x: (x == 'Pass').mean()).reset_index()st.subheader("成功率趨勢圖")st.line_chart(success_rate_over_time.set_index('Execution Time'))
11. 更多圖表示例
提供額外的圖表選項,如失敗原因條形圖(如果存在相關數據)。
# 更多圖表示例st.subheader("更多圖表示例")chart_type = st.selectbox("選擇圖表類型", ["失敗原因條形圖"])if chart_type == "失敗原因條形圖" and 'Failure Reason' in filtered_data.columns:failure_reasons = filtered_data[filtered_data['Status'] == 'Fail']['Failure Reason'].dropna().value_counts()st.bar_chart(failure_reasons)
else:st.write("請上傳一個Excel文件以開始分析。")
windows環境下在cmd啟動服務:

效果展示:
excel文檔格式:

上傳excel文檔后展示的效果如下圖所示:
結論
通過上述步驟,我們構建了一個基于Streamlit的自動化測試報告生成器。這個應用程序不僅展示了如何利用Streamlit的強大功能來簡化測試數據的可視化和分析過程,還為測試工程師提供了一個實際操作的例子。希望這篇教程能幫助你快速入門Streamlit,并應用于實際工作中,提升測試工作的效率和質量。如果你有任何問題或建議,請隨時留言交流!源碼及excel文檔已上傳云盤,感興趣的寶子們一起學習一下吧~










詳解)

)
)

)


簡要示例說明)
