TorchRec中的分片
文章目錄
- TorchRec中的分片
- 前言
- 一、Planner
- 二、EmbeddingTable 的分片
- TorchRec 中所有可用的分片類型列表
- 三、使用 TorchRec 分片模塊進行分布式訓練
- TorchRec 在三個主要階段處理此問題
- 四、DistributedModelParallel(分布式模型并行)
- 總結
前言
- 我們來了解TorchRec架構中是如何分片的
一、Planner
-
TorchRec planner 幫助確定模型的最佳分片配置。
-
它評估嵌入表分片的多種可能性,并優化性能。
-
planner 執行以下操作:
- 評估硬件的內存約束。
- 根據內存獲取(例如嵌入查找)估算計算需求。
- 解決特定于數據??的因素。
- 考慮其他硬件細節,例如帶寬,以生成最佳分片計劃。
二、EmbeddingTable 的分片
- TorchRec sharder 為各種用例提供了多種分片策略,我們概述了一些分片策略及其工作原理,以及它們的優點和局限性。通常,我們建議使用 TorchRec planner 為您生成分片計劃,因為它將為模型中的每個嵌入表找到最佳分片策略。
- 每個分片策略都確定如何進行表拆分、是否應拆分表以及如何拆分、是否保留某些表的一個或幾個副本等等。分片結果中的每個表片段,無論是一個嵌入表還是其中的一部分,都稱為分片。
- 可視化 TorchRec 中提供的不同分片方案下表分片的放置
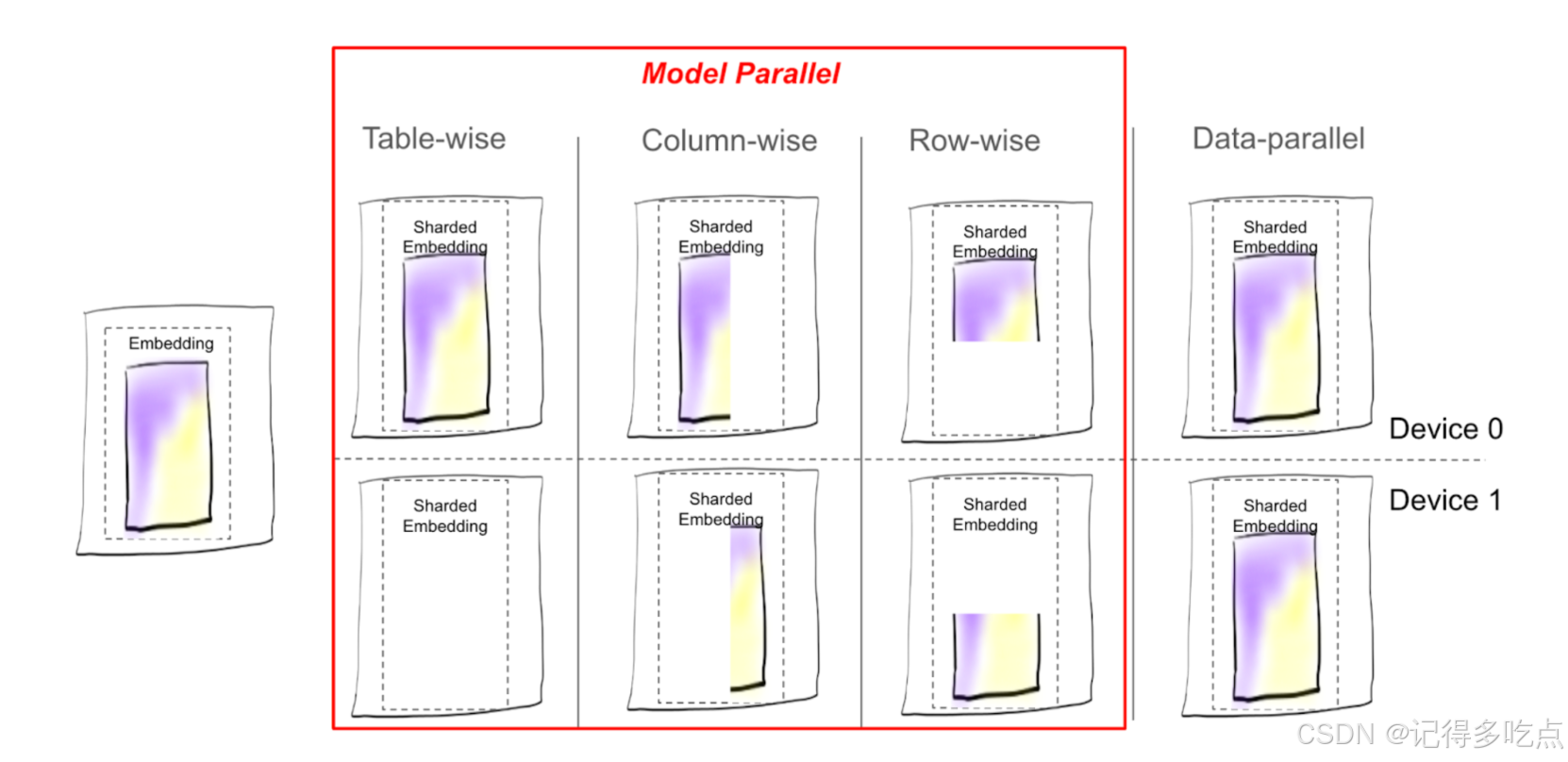
TorchRec 中所有可用的分片類型列表
- 表式 (TW):顧名思義,嵌入表作為一個整體保留并放置在一個 rank 上。
- 列式 (CW):表沿 emb_dim 維度拆分,例如,emb_dim=256 拆分為 4 個分片:[64, 64, 64, 64]。
- 行式 (RW):表沿 hash_size 維度拆分,通常在所有 rank 之間均勻拆分。
- 表式-行式 (TWRW):表放置在一個主機上,在該主機上的 rank 之間進行行式拆分。
- 網格分片 (GS):表是 CW 分片的,每個 CW 分片都以 TWRW 方式放置在主機上。
- 數據并行 (DP):每個 rank 保留表的副本。
分片后,模塊將轉換為它們自身的分片版本,在 TorchRec 中稱為 ShardedEmbeddingCollection 和 ShardedEmbeddingBagCollection。這些模塊處理輸入數據的通信、嵌入查找和梯度。
三、使用 TorchRec 分片模塊進行分布式訓練
- 有許多可用的分片策略,我們如何確定使用哪一個?
- 每種分片方案都有相關的成本,這與模型大小和 GPU 數量相結合,決定了哪種分片策略最適合模型。
- 在沒有分片的情況下,每個 GPU 保留嵌入表的副本 (DP),主要成本是計算,其中每個 GPU 在前向傳遞中查找其內存中的嵌入向量,并在后向傳遞中更新梯度。
- 使用分片時,會增加通信成本:
- 每個 GPU 都需要向其他 GPU 請求嵌入向量查找,并通信計算出的梯度。這通常被稱為 all2all 通信。
- 在 TorchRec 中,對于給定 GPU 上的輸入數據,我們確定數據每個部分的嵌入分片所在的位置,并將其發送到目標 GPU。
- 然后,目標 GPU 將嵌入向量返回給原始 GPU。在后向傳遞中,梯度被發送回目標 GPU,并且分片會通過優化器進行相應的更新。
- 如上所述,分片需要我們通信輸入數據和嵌入查找。
TorchRec 在三個主要階段處理此問題
我們將此稱為分片嵌入模塊前向傳遞,該傳遞用于 TorchRec 模型的訓練和推理
-
特征 All to All / 輸入分布 (input_dist)
- 將輸入數據(以 KeyedJaggedTensor 的形式)通信到包含相關嵌入表分片的適當設備
-
嵌入查找
- 使用特征 all to all 交換后形成的新輸入數據查找嵌入
-
嵌入 All to All/輸出分布 (output_dist)
- 將嵌入查找數據通信回請求它的適當設備(根據設備接收到的輸入數據)
-
后向傳遞執行相同的操作,但順序相反。
四、DistributedModelParallel(分布式模型并行)
- 以上所有內容最終匯集成 TorchRec 用于分片和集成計劃的主要入口點。
- 在高層次上,DistributedModelParallel 執行以下操作:
- 通過設置進程組和分配設備類型來初始化環境。
- 如果沒有提供 sharder,則使用默認的 sharder,默認 sharder 包括 EmbeddingBagCollectionSharder。
- 接收提供的分片計劃,如果未提供,則生成一個。
- 創建模塊的分片版本,并用它們替換原始模塊,例如,將 EmbeddingCollection 轉換為 ShardedEmbeddingCollection。
- 默認情況下,使用 DistributedDataParallel 包裝 DistributedModelParallel,使模塊既是模型并行又是數據并行。
總結
- 對TorchRec中的分塊策略進行了解。

詳解)

)
)

)


簡要示例說明)


)






