
摘要
近年來,不完全多視圖聚類(IMVC)受到廣泛關注。然而,現有研究仍然存在以下幾個不足之處:1) 部分方法忽略了樣本對在全局結構分布中的關聯性;2) 許多方法計算成本較高,因此無法應用于大規模不完全數據的聚類任務;3) 部分方法未對二分圖結構進行優化。
為了解決上述問題,提出了一種新穎的 IMVC 錨圖網絡(Anchor Graph Network),該方法包括一個生成模型和一個相似性度量網絡。具體而言,該方法利用生成模型構建二分圖,從而挖掘樣本對的潛在全局結構分布。隨后,使用圖卷積網絡(GCN)結合構建的二分圖來學習結構化嵌入。值得注意的是,引入二分圖可以顯著降低計算復雜度,使我們的模型能夠處理大規模數據。
與以往基于二分圖的方法不同,方法利用二分圖來引導 GCN 的學習過程。此外,還在方法中引入了一種創新的自適應學習策略,以構建穩健的二分圖。大量實驗表明,與當前最先進的方法相比,我們的方法在性能上具有可比性或更優的表現。
引言
現實世界中廣泛存在多視圖數據,其中同一樣本可以通過不同的模態和視角進行描述。多視圖數據的無監督聚類是機器學習領域的重要研究內容,其目標是利用視圖間的互補信息和視圖內的樣本關聯性,將樣本劃分到不同的簇中。
在數據采集過程中,由于傳感器損壞或人為疏忽,可能導致某些視圖缺失,從而形成不完全多視圖數據。現有的多視圖聚類方法通常假設所有視圖都是完整的,因此無法直接應用于不完全數據。與傳統的多視圖聚類相比,不完全多視圖聚類(IMVC)更具挑戰性,因為缺失的數據會導致視圖間互補性和一致性的信息丟失。為了解決這一挑戰,近年來提出了越來越多的 IMVC 方法。
根據數學建模方式,現有的 IMVC 方法可分為兩大類:傳統方法和深度學習方法。傳統 IMVC 方法又可進一步分為四類:核學習方法、矩陣分解方法、圖學習方法和張量方法。
-
核學習方法 關注從不完整的核函數中獲取一致的表示;
-
矩陣分解方法 旨在將不同視圖映射到一個共享空間;
-
圖學習方法 通過探索樣本之間的關系,獲得一致的相似性結構或共識表示;
-
張量方法 則將所有視圖的圖結構堆疊為張量,并利用張量約束來優化模型,以捕獲所有視圖之間的高階連接。
這些方法的共同目標是獲取所有視圖一致同意的聚類結果。然而,大多數傳統方法難以充分挖掘高階信息,并且計算復雜度較高,難以應用于大規模數據。
考慮到深度神經網絡強大的特征提取能力,近年來提出了一系列基于深度學習的 IMVC 方法。例如,Wen 等人利用編碼器來獲得多視圖之間的一致低維表示,而 Huang 等人則利用高斯混合模型來獲取樣本的概率分布信息。盡管這些方法在實驗中表現良好,但它們通常需要構建全局相似性矩陣,導致計算復雜度隨著樣本數呈二次增長,因此難以應用于大規模數據。
為了解決這一問題,一些 IMVC 方法引入了錨點(anchor)的概念。例如,基于錨點的稀疏子空間 IMVC 方法通過對共識圖施加稀疏約束來進行優化,而 Zhao 等人提出了無約束錨點圖卷積網絡(GCN)框架,以解決高視圖缺失率情況下的錨點選擇問題。
盡管這些方法取得了一定的進展,但仍然存在以下不足:
-
許多 IMVC 方法僅考慮相鄰樣本之間的關系,忽略了全局結構信息的保持;
-
許多 IMVC 方法計算復雜度高,難以應用于大規模數據聚類任務;
-
部分方法過度關注樣本嵌入的學習,而忽略了對二分圖結構的優化。
本文貢獻
針對上述問題,本文提出了一種新穎的錨點圖網絡 AGIMVC(Anchor Graph Network for IMVC),該方法主要包含一個生成模型和一個基于 GCN 的相似性度量網絡。
-
生成模型 用于構建二分圖,以有效捕獲大規模數據的全局結構分布;
-
相似性度量網絡 通過將二分圖轉換為新的圖結構,以計算拉普拉斯矩陣,從而在 GCN 訓練過程中利用二分圖指導學習,捕獲跨視圖的高階關系和潛在分布;
-
自適應學習策略 可動態更新錨點,以構建更加穩健的二分圖結構;
-
加權融合層 用于減少缺失視圖對模型的負面影響。
實驗結果表明,AGIMVC 在多個數據集上取得了遠超現有方法的性能。
模型
A. 問題陳述
不完整多視角聚類(IMVC)的目標是利用所有視角中的已有信息來推測缺失視角的信息,并最終將樣本分為 c?個簇。
B. AGIMVC
如圖 2 所示,AGIMVC 主要包含五個部分:生成模型、相似度度量網絡模塊、重建層、錨點更新模塊以及融合層。
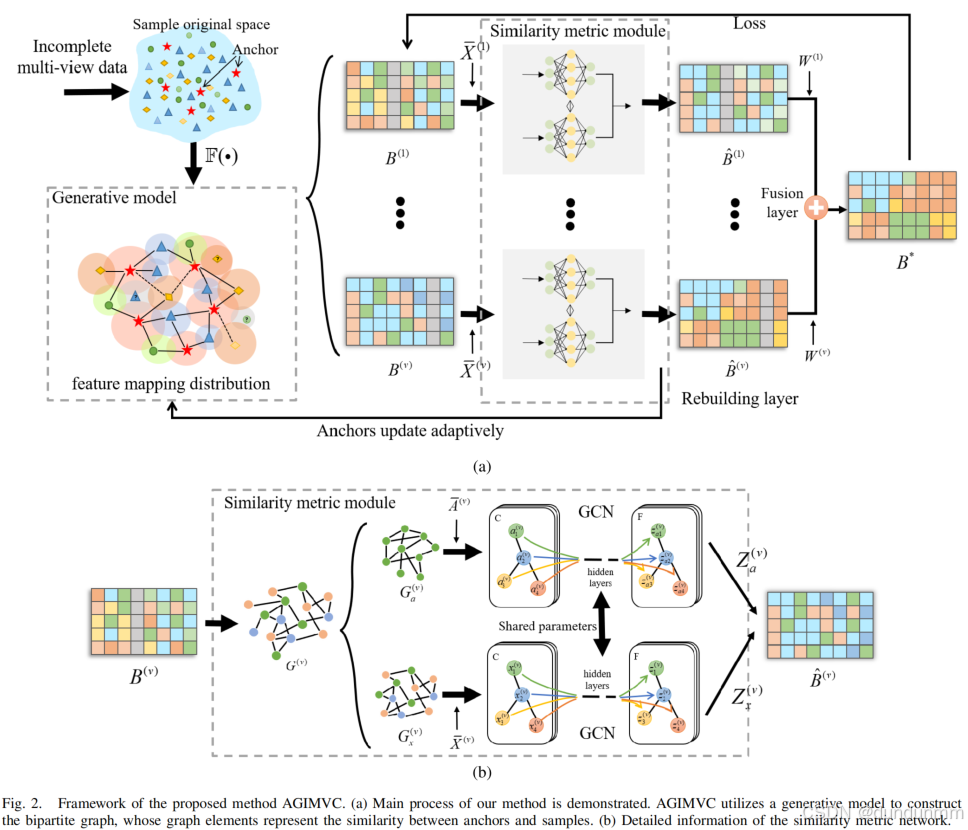
1) 生成模型
生成模型假設每個節點具有一個潛在分布,該分布反映了該節點與其他節點的連接性。基于生成模型的方法在獲取潛在空間分布方面表現較優,并且通常具有較快的收斂速度 [45]。因此,我們利用生成模型構建二分圖,從而高效地獲取全局結構信息。
與其他測度不同,Wasserstein 距離可以衡量兩個分布之間的距離,即使它們的重疊部分很少甚至沒有 [46]。因此,我們在方法中引入 Wasserstein 距離。
![]()
在相似性學習中,一個公認的假設是:如果兩個樣本相似,它們的分布在特征空間中也應當接近 [47]。為了保持錨點和樣本之間的相似關系,我們采用如下的距離度量準則:
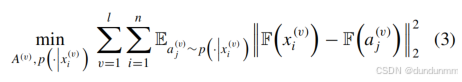
其中,F(?)表示樣本的理想特征映射分布,aj(v) 是第 v?視角中的第 j?個錨點。
實際上,某些樣本不應該與部分錨點具有相似性,即某些樣本應當僅與其中心錨點連接。因此,構造的圖應當是稀疏的,即僅將最相關的 k?個樣本連接到錨點。在本研究中,為了避免模型崩潰,我們嘗試通過增量 δ 動態增加 k,并構造如下的二分圖 [48]:

2) 相似度度量網絡模塊
近年來,圖卷積網絡(GCN)因其在利用圖結構信息方面的優異表現而備受關注,能夠生成更好的節點嵌入 [49]。在本方法中,相似度度量網絡包含兩個共享權重的 GCN 模塊,分別用于捕捉樣本和錨點的高階結構信息。
為了通過 GCN 獲取一個有信息量的二分圖,受馬爾科夫過程 [50] 啟發,我們將每個視角的二分圖 B(v) 轉化為新圖 G(v):
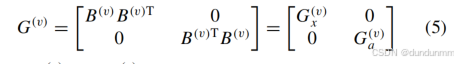
其中,Gx(v)和 Ga(v)分別表示樣本和錨點的高階相似性圖。
然后,這些圖分別輸入到 GCN,以獲得低維結構嵌入。 u 層網絡下的非線性嵌入表達式為:
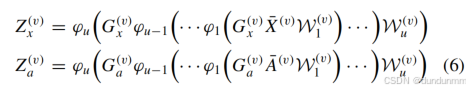
其中,Zx(v)和 Za(v) 分別表示網絡學習獲得的特征映射分布。
3) 重建層
在此層中,我們基于新的特征映射分布重建二分圖,而非恢復原始特征分布。AGIMVC 計算新的分布,使用歐式距離構建新的二分圖:
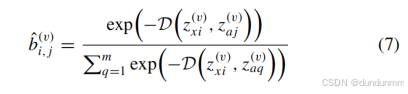
4) 錨點更新模塊(Anchors Update Module):
在深度學習中,并非所有原始特征都適用于構建錨點與樣本之間的親和圖。為了增強重要錨點的特征分布并描繪高階結構,我們的方法引入了一種創新的自適應學習策略。具體而言,在公式 (3) 的基礎上,我們采用以下公式更新錨點:

自適應錨點更新模塊的詳細過程包括兩個步驟:首先通過公式 (8) 更新錨點分布,然后利用公式 (4) 重新更新二部圖 B(v)。最終,更新后的 B(v)將用于網絡訓練。
5) 融合層(Fusion Layer):
為了解決多視圖學習中的不完整性問題,我們引入了一個加權融合層,以減少缺失視圖對網絡訓練的負面影響:

通過公式 (9),所有二部圖被融合為一個通用圖。最終的二部圖 B?包含了跨視圖的高階潛在相關性以及缺失視圖的結構信息。
6) 目標損失(Objective Loss):
不同于其他采用復雜損失函數的模型,AGIMVC 采用以下簡潔的交叉熵損失進行模型訓練:
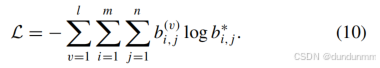
AGIMVC 的相似度度量網絡模塊通過最小化 L進行訓練。

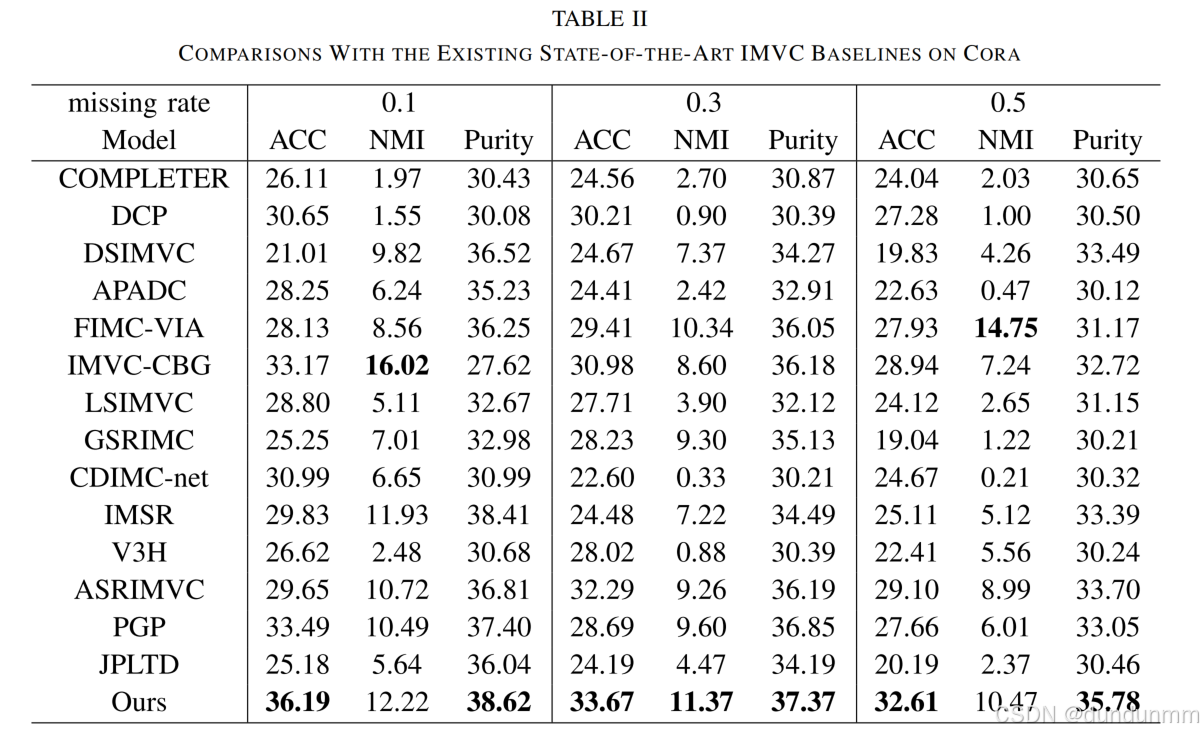
實驗
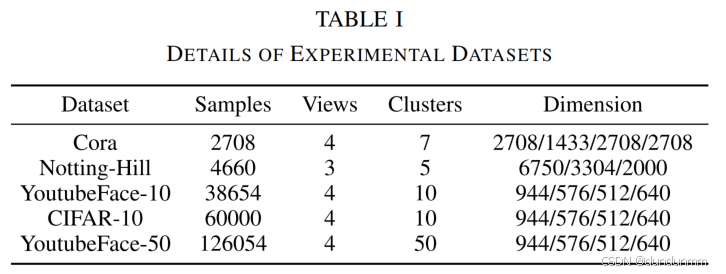
不完全多視圖聚類很符合真實數據情況



圖形管線)
》50+MOD整合包)







求解移動機器人路徑規劃,MATLAB代碼)




)

