一、深度Q網絡(Deep Q-Network,DQN)介紹
1、背景與動機
深度Q網絡(DQN)是深度強化學習領域的里程碑算法,由DeepMind于2013年提出。它首次在 Atari 2600 游戲上實現了超越人類的表現,解決了傳統Q學習在高維狀態空間中的應用難題。DQN在機器人路徑規劃領域展現出巨大潛力,能夠幫助機器人在復雜環境中找到最優路徑。
傳統Q學習在狀態空間維度較高時面臨以下挑戰:
- Q表無法存儲高維狀態的所有可能情況
- 特征提取需要手動設計,泛化能力差
- 更新過程容易導致Q值估計不穩定
DQN通過引入深度神經網絡作為Q函數的近似器,并采用經驗回放和目標網絡等技術,有效解決了上述問題。
2、核心思想
DQN的核心思想是使用深度神經網絡來近似Q函數,即:
Q ? ( s , a ) ≈ Q ( s , a ; θ ) Q^*(s, a) \approx Q(s, a; \theta) Q?(s,a)≈Q(s,a;θ)
其中, s s s 表示狀態, a a a 表示動作, θ \theta θ 表示神經網絡的參數。
目標是找到一組參數 θ ? \theta^* θ?,使得網絡輸出的Q值與實際的Q值盡可能接近。通過不斷與環境交互收集數據,使用梯度下降法優化網絡參數。
3、算法流程
DQN的算法流程可以概括為以下步驟:
-
初始化:
- 初始化Q網絡參數 θ \theta θ
- 初始化目標網絡參數 θ ? \theta^- θ? 并與Q網絡參數同步
- 初始化經驗回放緩沖區 D D D
-
與環境交互:
- 在當前狀態 s s s 下,根據 ? \epsilon ?-貪婪策略選擇動作 a a a
- 執行動作 a a a,觀察獎勵 r r r 和下一個狀態 s ′ s' s′
- 將經驗 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 存入經驗回放緩沖區 D D D
-
采樣與更新:
- 從經驗回放中隨機采樣一批數據 { ( s i , a i , r i , s i ′ ) } \{(s_i, a_i, r_i, s_i')\} {(si?,ai?,ri?,si′?)}
- 計算目標Q值:
y i = { r i if? s i ′ is?terminal r i + γ max ? a ′ Q ( s i ′ , a ′ ; θ ? ) otherwise y_i = \begin{cases} r_i & \text{if } s_i' \text{ is terminal} \\ r_i + \gamma \max_{a'} Q(s_i', a'; \theta^-) & \text{otherwise} \end{cases} yi?={ri?ri?+γmaxa′?Q(si′?,a′;θ?)?if?si′??is?terminalotherwise?
其中, γ \gamma γ 是折扣因子( 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1) - 計算當前Q值: Q ( s i , a i ; θ ) Q(s_i, a_i; \theta) Q(si?,ai?;θ)
- 計算損失函數:
L ( θ ) = 1 N ∑ i = 1 N ( y i ? Q ( s i , a i ; θ ) ) 2 L(\theta) = \frac{1}{N} \sum_{i=1}^{N} (y_i - Q(s_i, a_i; \theta))^2 L(θ)=N1?i=1∑N?(yi??Q(si?,ai?;θ))2 - 使用梯度下降法更新Q網絡參數 θ \theta θ
-
同步目標網絡:
- 每隔一定步數(如C步),將Q網絡參數 θ \theta θ 同步到目標網絡 θ ? \theta^- θ?
-
重復:
- 重復上述過程直到收斂
4、關鍵技術
1. 經驗回放(Experience Replay)
經驗回放通過存儲代理與環境交互的經驗,并隨機采樣小批量數據進行更新,解決了以下問題:
- 數據相關性:傳統Q學習使用相關數據更新,容易導致估計偏差
- 數據利用效率:每個經驗只使用一次,數據利用率低
經驗回放的數學表達為:
D = { e 1 , e 2 , … , e N } , e i = ( s i , a i , r i , s i ′ ) D = \{e_1, e_2, \dots, e_N\}, \quad e_i = (s_i, a_i, r_i, s_i') D={e1?,e2?,…,eN?},ei?=(si?,ai?,ri?,si′?)
每次更新時,從 D D D 中隨機采樣小批量數據 B ? D B \subseteq D B?D。
2. 目標網絡(Target Network)
目標網絡通過維持一個固定的網絡來計算目標Q值,避免了Q值估計的不穩定。目標網絡的參數 θ ? \theta^- θ? 每隔一定步數與Q網絡參數 θ \theta θ 同步:
θ ? ← θ every?C?steps \theta^- \leftarrow \theta \quad \text{every C steps} θ?←θevery?C?steps
3. ? \epsilon ?-貪婪策略
? \epsilon ?-貪婪策略在探索與利用之間取得平衡:
a = { random?action with?probability? ? arg ? max ? a Q ( s , a ; θ ) with?probability? 1 ? ? a = \begin{cases} \text{random action} & \text{with probability } \epsilon \\ \arg\max_a Q(s, a; \theta) & \text{with probability } 1-\epsilon \end{cases} a={random?actionargmaxa?Q(s,a;θ)?with?probability??with?probability?1???
其中, ? \epsilon ? 隨時間逐漸衰減,從初始值(如1.0)逐漸降低到較小值(如0.1)。
5、數學推導
1. Q學習更新公式
Q學習的目標是找到最優策略下的Q值:
Q ? ( s , a ) = E r [ r + γ max ? a ′ Q ? ( s ′ , a ′ ) ] Q^*(s, a) = \mathbb{E}_r[r + \gamma \max_{a'} Q^*(s', a')] Q?(s,a)=Er?[r+γa′max?Q?(s′,a′)]
其中, E r \mathbb{E}_r Er? 表示對獎勵分布的期望。
2. 損失函數
DQN使用均方誤差(MSE)作為損失函數:
L ( θ ) = E s , a , r , s ′ [ ( y ? Q ( s , a ; θ ) ) 2 ] L(\theta) = \mathbb{E}_{s,a,r,s'} \left[ (y - Q(s, a; \theta))^2 \right] L(θ)=Es,a,r,s′?[(y?Q(s,a;θ))2]
其中, y = r + γ max ? a ′ Q ( s ′ , a ′ ; θ ? ) y = r + \gamma \max_{a'} Q(s', a'; \theta^-) y=r+γmaxa′?Q(s′,a′;θ?) 是目標Q值。
3. 梯度更新
使用梯度下降法更新參數 θ \theta θ:
θ ← θ + α ? θ L ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta L(\theta) θ←θ+α?θ?L(θ)
其中, α \alpha α 是學習率, ? θ L ( θ ) \nabla_\theta L(\theta) ?θ?L(θ) 是損失函數對參數的梯度。
6、與傳統Q學習的對比
| 特性 | 傳統Q學習 | DQN |
|---|---|---|
| 狀態表示 | 離散狀態或手工特征 | 深度神經網絡自動提取特征 |
| 數據利用 | 每個數據只使用一次 | 經驗回放多次利用數據 |
| 穩定性 | Q值估計容易發散 | 目標網絡提高穩定性 |
| 適用場景 | 低維狀態空間 | 高維狀態空間(如圖像) |
7、局限性
- 樣本效率低:需要大量交互數據
- 超參數敏感:對 ? \epsilon ?、學習率、折扣因子等敏感
- 獎勵稀疏問題:在獎勵稀疏環境中表現不佳
- 計算資源需求高:需要強大的計算設備支持
二、構建CNN-LSTM深度神經網絡作為Q函數的近似器
輸入是10*10大小含有障礙物的地圖,輸出是機器人8個方向的動作Q值,用于指導機器人選擇最優動作。
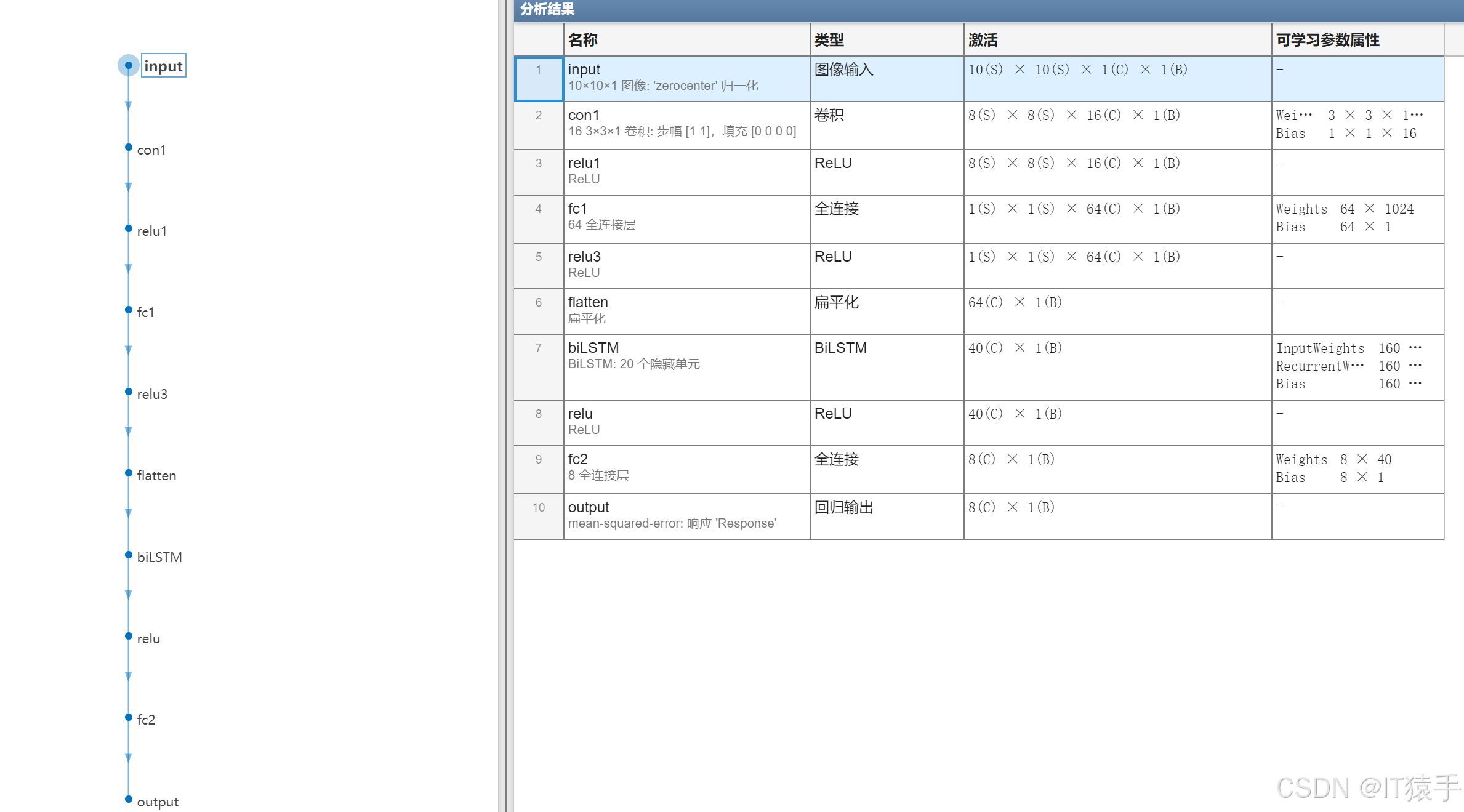
所搭建的深度神經網絡包含卷積層、激活層、全連接層、扁平化層和LSTM層。以下是每一層的詳細說明:
1. 輸入層 (input)
- 輸入尺寸: (10 \times 10 \times 1)
- 歸一化: 使用 “zero-centered” 歸一化方法
- 描述: 接收 (10 \times 10) 的單通道圖像作為輸入。
2. 卷積層 (con1)
- 卷積核尺寸: (3 \times 3)
- 卷積核數量: 16
- 步幅: ([1, 1])
- 填充: ([0, 0, 0, 0])
- 輸出尺寸: (8 \times 8 \times 16)
- 描述: 使用 16 個 (3 \times 3) 的卷積核對輸入圖像進行卷積操作,提取特征。
3. ReLU 激活層 (relu1)
- 輸入/輸出尺寸: (8 \times 8 \times 16)
- 描述: 對卷積層的輸出應用 ReLU 激活函數,引入非線性。
4. 全連接層 (fc1)
- 輸入尺寸: (8 \times 8 \times 16 = 1024)
- 輸出尺寸: (64)
- 權重矩陣: (64 \times 1024)
- 偏置向量: (64 \times 1)
- 描述: 將卷積層的輸出展平后,通過全連接層映射到 64 維特征空間。
5. ReLU 激活層 (relu3)
- 輸入/輸出尺寸: (64)
- 描述: 對全連接層的輸出應用 ReLU 激活函數。
6. 扁平化層 (flatten)
- 輸入尺寸: (1 \times 1 \times 64)
- 輸出尺寸: (64 \times 1)
- 描述: 將三維張量展平為一維向量。
7. LSTM層 (Lstm)
- 隱藏單元數量: 20
- 輸入尺寸: (64 \times 1)
- 輸出尺寸: (20 \times 1)
- 權重矩陣:
- 輸入權重: (80 \times \dots)
- 循環權重: (80 \times \dots)
- 偏置向量: (80 \times \dots)
- 描述: 使用 LSTM處理序列數據,捕捉時間序列中的依賴關系。
8. ReLU 激活層 (relu)
- 輸入/輸出尺寸: (20 \times 1)
- 描述: 對 LSTM層的輸出應用 ReLU 激活函數。
9. 全連接層 (fc2)
- 輸入尺寸: (20)
- 輸出尺寸: (8)
- 權重矩陣: (8 \times 20)
- 偏置向量: (8 \times 1)
- 描述: 將 LSTM層的輸出映射到 8 維輸出空間。
10. 輸出層 (output)
- 輸出尺寸: (8 \times 1)
- 損失函數: 均方誤差(mean-squared-error)
- 響應: “Response”
- 描述: 輸出層用于回歸任務,預測 8 維的連續值。
三、DQN求解機器人路徑規劃
3.1 環境設置
- 狀態空間:機器人當前的位置或狀態,以及與目標位置的關系。
- 動作空間:機器人可以采取的所有可能動作,如移動到相鄰位置。
- 獎勵函數:定義機器人在執行動作后獲得的即時獎勵。例如,到達目標點給予高獎勵,碰撞給予負獎勵,距離目標點越近獎勵越高。
3.2 網絡設計
DQN網絡輸入是10×10大小的地圖狀態,輸出是機器人8個方向的動作Q值。網絡結構如下:
- 輸入層:接收10×10的地圖作為輸入。
- 隱藏層:可以包含卷積層、LSTM等,用于提取地圖特征。
- 輸出層:輸出8個方向動作的Q值。
3.3 訓練過程
- 初始化:初始化經驗池,隨機初始化Q網絡的參數,并初始化目標網絡,其參數與Q網絡相同。
- 獲取初始狀態:機器人從環境中獲取初始狀態。
- 選擇動作:根據當前狀態和ε-貪心策略選擇動作。
- 執行動作并觀察:機器人執行動作并觀察新的狀態和獲得的獎勵。
- 存儲經驗:將經驗(狀態、動作、獎勵、新狀態)存儲在經驗池中。
- 樣本抽取與學習:從經驗池中隨機抽取樣本,并使用這些樣本來更新Q網絡。
- 目標網絡更新:定期將Q網絡的參數復制到目標網絡。
3.4 路徑規劃
在訓練完成后,使用訓練好的DQN網絡來規劃路徑。機器人根據當前狀態和Q值函數選擇最優動作,逐步接近目標位置。
四、部分MATLAB代碼及結果
%% 畫圖
analyzeNetwork(dqn_net)figure
plot(curve,'r-',LineWidth=2);
saveas(gca,'11.jpg')figure
imagesc(~map)
hold on
plot(state_mark(:,2),state_mark(:,1),'c-',LineWidth=2);
colormap('gray')
scatter(start_state_pos(2) ,start_state_pos(1),'MarkerEdgeColor',[0 0 1],'MarkerFaceColor',[0 0 1], 'LineWidth',1);%start point
scatter(target_state_pos(2),target_state_pos(1),'MarkerEdgeColor',[0 1 0],'MarkerFaceColor',[0 1 0], 'LineWidth',1);%goal point
text(start_state_pos(2),start_state_pos(1),'起點','Color','red','FontSize',10);%顯示start字符
text(target_state_pos(2),target_state_pos(1),'終點','Color','red','FontSize',10);%顯示goal字符
title('基于DQN的機器人路徑規劃')
saveas(gca,'12.jpg')





)


)


)








