LLM協作新突破:用多智能體強化學習實現高效協同——解析MAGRPO算法
論文:LLM Collaboration With Multi-Agent Reinforcement Learning
arXiv:2508.04652 (cross-list from cs.AI)
LLM Collaboration With Multi-Agent Reinforcement Learning
Shuo Liu, Zeyu Liang, Xueguang Lyu, Christopher Amato
Subjects: Artificial Intelligence (cs.AI); Software Engineering (cs.SE)
一段話總結:
本文將LLM協作建模為合作式多智能體強化學習(MARL) 問題,并形式化為Dec-POMDP,以解決現有LLM微調框架依賴個體獎勵導致協作困難的問題。為此,提出MAGRPO算法,通過集中式群體相對優勢進行聯合優化,同時保留去中心化執行以保證效率。實驗表明,在寫作(TLDR summarization、arXiv expansion)和編碼(HumanEval、CoopHumanEval)協作任務中,MAGRPO能使LLM agents通過有效協作生成高質量響應,且效率優于單agent和其他多agent基線方法。該研究為MARL方法應用于LLM協作開辟了道路,并指出了相關挑戰。
研究背景
想象一個場景:你讓兩個AI助手合作寫一篇科普文章,一個負責介紹背景,一個負責講解原理。結果呢?可能一個寫得太簡略,一個又過于冗長,風格完全不搭,甚至出現內容重復——這就是當前大型語言模型(LLM)協作時的常見問題。
近年來,LLM在各個領域大放異彩,但當需要多個LLM協同完成復雜任務(如聯合寫作、協作編碼)時,卻面臨諸多挑戰:
- 現有方法要么讓LLM在推理時通過提示詞互動(比如“你補充一下我的觀點”),但模型固定不變,很容易答非所問或傳播錯誤信息;
- 要么針對每個LLM單獨微調,設計復雜的個體獎勵(比如“這個LLM寫得好就加分”),但獎勵設計難度大,且多個LLM各自為戰,缺乏全局協作意識。
而在機器人、游戲等領域,多智能體系統(MAS)早已通過強化學習實現了高效協作(比如多個機器人協同搬運物體)。受此啟發,研究者們開始思考:能否將LLM協作也打造成一個“協作型團隊”,通過多智能體強化學習(MARL)讓它們學會協同工作?這正是本文要解決的核心問題。
主要作者及單位信息
- 作者:Shuo Liu, Zeyu Liang, Xueguang Lyu, Christopher Amato*
- 單位:Khoury College of Computer Sciences, Northeastern University(美國東北大學Khoury計算機學院)
創新點
本文的獨特之處在于跳出了“個體優化”的思維,為LLM協作提供了全新框架:
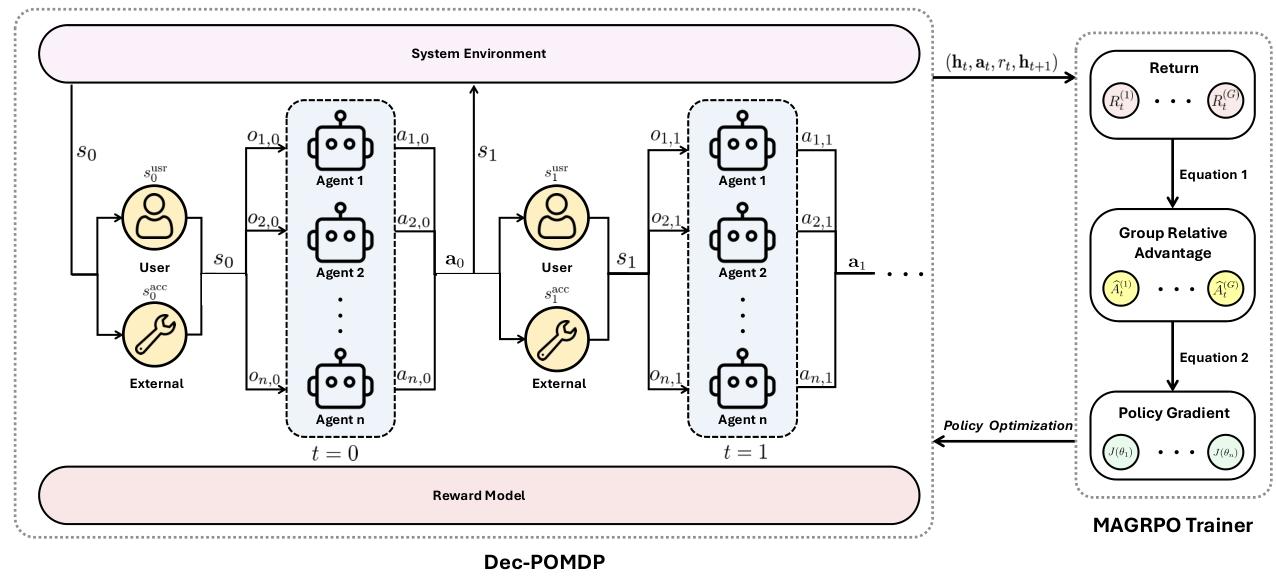
- 問題建模革新:首次將LLM協作明確建模為合作式多智能體強化學習問題,并通過Dec-POMDP(去中心化部分可觀測馬爾可夫決策過程) 形式化,讓協作目標更清晰。
- 算法創新:提出MAGRPO(Multi-Agent Group Relative Policy Optimization)算法,結合“集中式訓練、去中心化執行”模式——訓練時用全局信息優化協作策略,執行時每個LLM獨立決策,兼顧效率與協作性。
- 獎勵設計簡化:摒棄復雜的個體獎勵,采用聯合獎勵(比如“兩篇摘要是否結構合理、風格一致”),讓LLM自然學會分工協作,無需手動設計角色規則。
研究方法和思路
核心思路:把LLM協作變成“團隊游戲”
-
問題形式化:用Dec-POMDP定義協作規則
- 每個LLM是一個“智能體”,接收自然語言提示(觀測),生成文本或代碼(動作)。
- 環境根據所有LLM的聯合輸出更新狀態(比如任務進度、用戶反饋)。
- 系統根據聯合輸出的質量給出聯合獎勵(比如寫作任務中獎勵“結構合理+風格一致”,編碼任務中獎勵“代碼可運行+功能互補”)。
- 目標是讓所有LLM共同優化策略,最大化累計獎勵(即“團隊總分”)。
-
MAGRPO算法:讓LLM學會“團隊配合”
- 步驟1:多輪交互:每個回合中,LLM們根據各自的歷史(之前的提示和輸出)同步生成響應。
- 步驟2:群體采樣:為了穩定訓練,每個LLM生成多個候選響應(比如每個生成3個版本),形成“響應群體”。
- 步驟3:計算獎勵:系統根據聯合響應的質量(如結構、一致性、正確性)給出聯合獎勵。
- 步驟4:優化策略:通過“群體相對優勢”(對比不同響應的獎勵差異)更新每個LLM的策略,讓它們逐漸學會“哪些輸出能讓團隊得分更高”。
- 特點:訓練時用全局信息(所有LLM的輸出和獎勵)優化,執行時每個LLM僅根據自己的觀測獨立決策,既保證協作又不犧牲效率。
實驗方法:在寫作和編碼任務中“實戰測試”
-
寫作協作任務
- TLDR摘要生成:2個LLM分工,一個寫精簡摘要,一個寫詳細摘要,要求結構合理、風格一致。
- arXiv論文擴展:2個LLM從論文摘要擴展引言,一個寫背景,一個寫方法,要求內容連貫。
- 對比基線:單LLM、并行生成(無協作)、順序生成(單向參考)、一輪討論(雙向參考)。
-
編碼協作任務
- HumanEval/CoopHumanEval:2個LLM分工寫Python函數,一個寫輔助函數,一個寫主函數,要求代碼可運行、功能互補。
- 對比基線:單LLM、樸素拼接(無協作)、順序生成(主函數參考輔助函數)、一輪討論(互相參考)。
-
評估指標
- 寫作:結構(長度比)、風格一致性(詞匯相似度)、邏輯連貫性(過渡詞使用)。
- 編碼:結構完整性(函數定義正確)、語法正確性、測試通過率、協作質量(主函數是否有效調用輔助函數)。
主要貢獻
- 理論層面:為LLM協作提供了堅實的數學框架(Dec-POMDP),證明了用MARL解決協作問題的可行性。
- 方法層面:MAGRPO算法無需復雜的個體獎勵設計,僅通過聯合獎勵就能讓LLM自主學會分工協作,降低了工程落地難度。
- 實踐層面:實驗表明,MAGRPO在寫作和編碼任務中全面超越現有方法:
- 寫作任務:速度是單LLM的3倍,結構合理性和風格一致性得分超95%(基線最高71.5%)。
- 編碼任務:多輪MAGRPO的測試通過率達74.6%,協作質量達86.2%(單LLM分別為63.4%和無協作指標)。
- 領域價值:打開了MARL與LLM結合的新方向,為未來更復雜的多LLM協作(如大型軟件開發、多步驟決策)奠定了基礎。
思維導圖:

詳細總結:
1. 研究背景與動機
- LLM與MAS的潛力:LLM在多領域表現優異,但協作能力未被充分優化;MAS在協作任務(如游戲、機器人)中已展現潛力,可用于提升LLM協作。
- 現有方法的局限:
- 提示級交互(如辯論、角色分配):依賴固定模型,易產生沖突信息,提示設計困難。
- 個體獎勵微調:需為每個agent設計復雜獎勵,且缺乏收斂保證。
2. 核心方法
- 問題形式化:將LLM協作定義為Dec-POMDP,包含狀態(全局狀態含可訪問部分和用戶狀態)、觀測(自然語言提示)、動作(自然語言響應)、聯合獎勵(基于可訪問狀態和聯合動作)等要素。
- MAGRPO算法:
- 核心思路:借鑒GRPO和MAPPO,通過群體蒙特卡洛樣本估計期望回報,計算群體相對優勢以穩定訓練。
- 流程:每個episode中,agents同步生成響應,基于聯合獎勵更新歷史,最終通過隨機梯度下降優化策略。
3. 實驗設計與結果
| 任務類型 | 數據集/任務 | 評估指標 | 關鍵結果(MAGRPO vs 基線) |
|---|---|---|---|
| 寫作協作 | TLDR summarization | 結構(長度比)、風格一致性(Jaccard相似度)、邏輯連貫性(過渡詞) | 速度是單模型3倍,結構和連貫性得分更高(98.7% vs 單模型6.6%) |
| 寫作協作 | arXiv expansion | 同上 | 總回報顯著高于并行生成、順序生成等基線(93.1% vs 并行59.6%) |
| 編碼協作 | HumanEval | 結構完整性、語法正確性、測試通過率、協作質量 | 多輪MAGRPO測試通過率74.6%,協作質量86.2%,優于單模型(63.4%)和樸素拼接(40.1%) |
| 編碼協作 | CoopHumanEval | 同上 | 單輪/多輪MAGRPO總回報(83.7%/88.1%)高于所有基線,且方差更低 |
4. 貢獻與局限
- 貢獻:
- 將LLM協作建模為合作式MARL問題;
- 提出MAGRPO算法優化協作;
- 驗證其在寫作和編碼任務中的有效性;
- 分析現有方法局限和開放挑戰。
- 局限與未來方向:
- 局限:使用同質agent、數據集和模型規模有限、獎勵模型簡單;
- 未來:探索異質agent協作、擴大項目規模、設計更精細的獎勵模型。
關鍵問題:
-
MAGRPO算法與現有多agent LLM協作方法的核心區別是什么?
現有方法多依賴提示級交互(無微調)或個體/角色條件獎勵微調,存在協作低效、獎勵設計復雜、缺乏收斂保證等問題;而MAGRPO將LLM協作建模為合作式MARL問題,通過集中式群體相對優勢進行聯合優化,同時保留去中心化執行,無需復雜個體獎勵設計,且有更好的協作效果和收斂性。 -
在寫作協作實驗中,評估LLM生成內容質量的具體指標有哪些?
包括三類指標:(1)結構:兩段摘要的長度比和獨特詞比;(2)風格一致性:基于獨特詞(或n-grams)的歸一化Jaccard相似度;(3)邏輯連貫性:過渡詞使用的類別數量(獎勵隨類別數對數增長)。總獎勵為這些指標的加權和。 -
該研究指出的LLM協作領域開放挑戰有哪些?
主要包括:(1)LLM基于自然語言的表示形式對MARL建模的挑戰(如動作/觀測空間大);(2)訓練范式選擇(CTDE vs DTE)的權衡;(3)獎勵模型的設計需更精細以對齊人類偏好;(4)需探索異質agent協作及更大規模項目中的協作模式。
總結
本文通過將LLM協作建模為合作式多智能體強化學習問題,提出了MAGRPO算法,成功解決了現有方法中“協作低效”和“獎勵設計復雜”的痛點。實驗證明,經過MAGRPO訓練的LLM團隊,在寫作和編碼任務中能生成更高質量的結果,且效率顯著提升。
解決的主要問題
- 現有LLM協作依賴提示詞或個體獎勵,協作性差、設計復雜。
- LLM在多輪交互中難以保持風格一致、功能互補。
主要成果
- 提出MAGRPO算法,實現LLM的高效協同訓練。
- 在寫作和編碼任務中驗證了方法的優越性,為MARL在LLM領域的應用提供了范例。




)
把“可配置查詢”裝進 Mustache)
)


)

:I2C 總線上可以接多少個設備?如何保證數據的準確性?)

如何開發有監督神經網絡系統?)




)
