文章目錄
- 一、前言
- 二、undo 日志(回滾日志)
- 1. 事務 id
- 2. undo 日志格式
- 2.1 INSERT 對應的 undo 日志
- 2.2 DELETE 對應的 undo 日志
- 2.3 UPDATE 對應的 undo 日志
- 2.3.1 不更新主鍵
- 2.3.2 更新主鍵
- 2.3 增刪改操作對二級索引的影響
- 2.4 roll_pointer
- 3. FIL_PAGE_UNDO_LOG 頁面
- 4. Undo 頁面鏈表
- 5. Undo 日志具體寫入過程
- 6. 重用 Undo 頁面
- 7. 回滾段
- 7.1 概念
- 7.2 從回滾段申請 Undo 頁面鏈表
- 7.3 多個回滾段
- 7.4 回滾段的分類
- 7.5 roll_pointer 的組成
- 7.6 事務分配 Undo 頁面鏈表的過程
- 7.7 undo 日志在崩潰恢復時的作用
- 四、總結
- 五、參考內容
一、前言
最近在讀《MySQL 是怎樣運行的》、《MySQL技術內幕 InnoDB存儲引擎 》,后續會隨機將書中部分內容記錄下來作為學習筆記,部分內容經過個人刪改,因此可能存在錯誤,如想詳細了解相關內容強烈推薦閱讀相關書籍。
二、undo 日志(回滾日志)
redo 日志記錄了事務的行為,可以很好的通過其對頁進行 “重做”。但是事務有時候還需要回滾操作,這是就需要undo 日志,undo 日志保證了事務的原子性。
在對 DB 進行修改時, InnoDB不僅會產生 redo 還會產生一定量的 undo, 如果事務需要進行回滾,則可以利用這些undo 信息回滾。與 redo 存放在重做日志文件中不同的是, undo 存放在數據庫內部的一個特殊段(segment)中,稱為 undo 段,undo 段位于共享表空間中。
undo 日志并非是將數據庫物理地恢復到執行語句或事務之前的樣子:undo 日志是邏輯日志,因此只是將數據庫邏輯地恢復到原來的樣子,所有的修改都被邏輯地取消了,但是數據結構和頁本身在回滾之后可能并不相同。因為在系統中可能存在多個事務并發操作,數據庫的任務就是協調數據記錄的并發訪問。比如一個事務修改當前頁中某幾條記錄,同時還有別的事務在對當前頁進行修改,所以不能將一個頁回滾到事務開始的樣子,不然會影響其他事務工作。
1. 事務 id
一個事務可以是只讀事務,也可以是讀寫事務,如果一個事務在執行過程中對某個表執行了增刪改操作,那么 InnoDB 會為其分配一個事務id。
事務id 就是一個遞增的數字, 其分配策略如下:
- 服務器會在內存中維護一個全局變量,每當需要為某個事務分配事務id時,就會把該變量的值當做事務id分配給該事物,并且把該變量自增1
- 當這個變量的值是 256 的倍數時,就會將該變量的值刷新到系統表空間頁號為5 的頁面中一個名為 Max Trx ID 的屬性中,該屬性占用 8 字節的存儲空間
- 當系統下一次啟動時會將 Max Trx ID 屬性加載到內存中,將該值加上 256 之后賦值給前面提到的全局變量。
事務id對事務的分配方式如下:
- 對于只讀事務,只有在他第一次對某個用戶創建的臨時表增刪改操作時會為這個事務分配一個事務id,否則不分配事務id,默認為0。
- 對于讀寫事務來說,只有在他第一次對某個表(包括用戶創建的臨時表)執行增刪改操作時,才會為這個事務分配一個事務id,否則不分配事務id,默認為0。
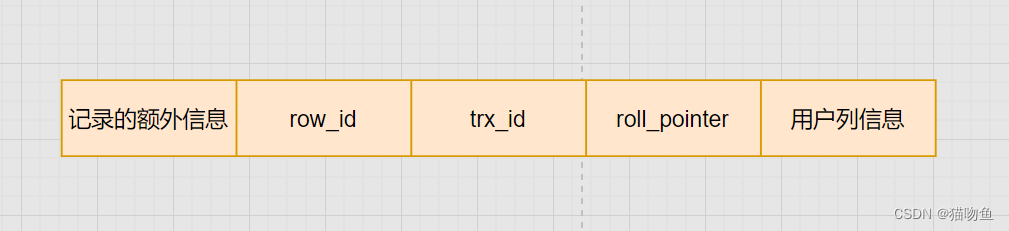
在 【MySQL02】【 InnoDB 記錄存儲結構】提到過 InnoDB 記錄行格式中聚簇索引會存在 row_id、trx_id、roll_pointer 三個隱藏列,而 trx_id 中保存的就是對當前記錄進行修改的所在事務的事務id。如下圖:
2. undo 日志格式
一個事務執行過程中可能會對應多條語句,就會需要記錄多條對應的 undo 日志。這些日志會從 0 開始編號,根據生成順序可以稱為 第 0號 undo 日志,第 1 號 undo 日志等,這個編號也稱為 undo no。
undo 日志會被記錄到類型為 FIL_PAGE_UNDO_LOG 的頁面中,這些頁面可以從系統表空間分配,也可以從 undo 表空間(專門存放 undo 日志的表空間)分配。
2.1 INSERT 對應的 undo 日志
在進行 INSERT 操作時, undo 日志只需要記錄新插入的記錄的主鍵值即可,如果需要回滾則通過主鍵值將插入記錄刪除即可。
INSERT 對應的 undo 日志格式為 TRX_UNDO_INSERT_REC,結構如下:
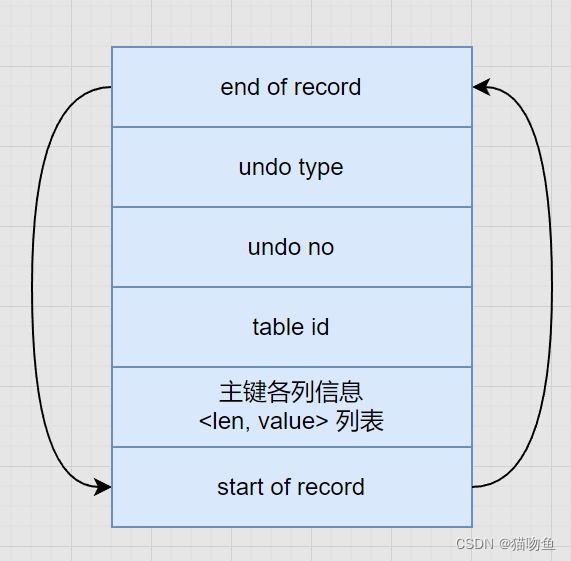
其中各個字段的解釋如下:
| 字段 | 解釋 |
|---|---|
| end of record | 本條 undo 日志結束,下一條開始時在頁面中的地址 |
| undo type | 本條undo 日志的類型,即 TRX_UNDO_INSERT_REC |
| undo no | 本條undo日志對應的編號 |
| table id | 本條 undo 日志對應的記錄所在表的table_id |
| 主鍵各列信息 | 主鍵字段每個列占用的存儲空間大小和真實值 |
| start of record | 上一條 undo 日志結束,本條開始時在頁面中的地址 |
這里注意兩點:
- undo 在一個事務是從 0 開始遞增的,只要事務沒提交,每生成一條 undo 日志,那么該條日志的 undo 就增1。
- 如果記錄中的主鍵只包含一列,那么在 TRX_UNDO_INSERT_REC 類型的日志中,只需要把該列占用的存儲空間大小和真實值記錄下來。如果記錄中的主鍵包含多個列(聯合主鍵),那么每個列占用的存儲空間大小和對應的真實值都需要記錄下來。(len 代表列占用的存儲空間大小;value 代表列的真實值)
當進行插入操作時,實際上需要向聚餐索引和所有二級索引都插入一條記錄,不過在記錄 undo 日志時,只需要針對聚簇索引記錄來記錄一條 undo 日志就好,聚簇索引記錄和二級索引記錄是一一對應的,在回滾 INSERT 操作時,只需要根據這條記錄的主鍵信息進行刪除操作,在刪除時會將聚簇索引和所有對應的二級索引都刪除。
2.2 DELETE 對應的 undo 日志
在【MySQL02】【 InnoDB 記錄存儲結構】中提到過,插入到頁面的記錄會根據記錄頭信息中的 next_record 屬性組成一個單向鏈表,暫且成為正常記錄鏈表。而被刪除的記錄也會通過next_record 屬性組成一個鏈表,不過這個鏈表中的記錄占用的存儲空間可以被重新利用,所以也稱這個鏈表為垃圾鏈表。而每個數據頁的 Page Header 部分中有一個名為 PAGE_FREE 的屬性指向被刪除記錄組成的垃圾鏈表中的頭節點。數據頁結構如下圖:
記錄的刪除需要經歷兩個階段:
- delete mark 階段 : 將記錄的 deleted_flag 標志位置為 1,同時修改記錄的 trx_id、roll_pointer 的值。在刪除語句所在的事務提交之前,被刪除的記錄一直都處于這種中間狀態。
- purge 階段:當刪除該語句所在的事務提交之后,會有專門的線程來將記錄真正的刪除掉,這里所謂真正的刪除就是將該記錄從正常鏈表中移除,并且加到垃圾鏈表中(這里是加入到鏈表的頭節點,并修改 PAGE_FREE 指向新刪除的記錄),除此之外還會修改一些頁面屬性。
在 purge 階段執行結束后,記錄就可以確定被刪除了,空間也可以重復利用了。
如何重復利用垃圾鏈表的空間?
Page Header 存在一個名為 PAGE GARBAGE 的屬性,記錄這當前頁面中可重用存儲空間占用的總字節數,每當有已刪除記錄加入到垃圾鏈表后,都會將 PAGE GARBAGE 屬性的值加上已刪除記錄占用的存儲空間的大小。PAGE_FREE 指向垃圾鏈表的頭節點,之后每當插入新的記錄時,會首先判斷垃圾鏈表中的頭節點代表的已刪除的記錄所占用的空間是否足夠容納這條新插入的記錄。如果無法容納就直接向頁申請新的空間來存儲這條記錄(并不會遍歷所有的垃圾鏈表,而是直接用頭節點判斷)。如果可以容納就直接重用這條已刪除記錄的存儲空間,并讓 PAGE_FREE 指向垃圾鏈表的下一條記錄。碎片空間的重組
這就會存在一個問題:如果新插入的記錄無法完全占用已刪除記錄的存儲空間,就意味著頭節點對應的記錄所占用的存儲空間中有一部分空間未使用到,形成了碎片空間。而這些未被使用的碎片空間占用的存儲空間的大小會被統計到 PAGE_GARBAGE 屬性中,當頁空間快滿時如果在插入一條新紀錄,此時頁并不能分配足夠的空間時就會判斷PAGE_GARBAGE 的空間和剩余可利用的空間相加之后是否可以容納這條記錄,如果可以 InnoDB 會嘗試重新組織頁內的記錄。重新組織的過程是先開辟出一個臨時頁將頁面內的記錄依次插入一遍,然后再把臨時頁面的內容復制到本頁面,這樣就可以把那些碎片空間都解放出來。
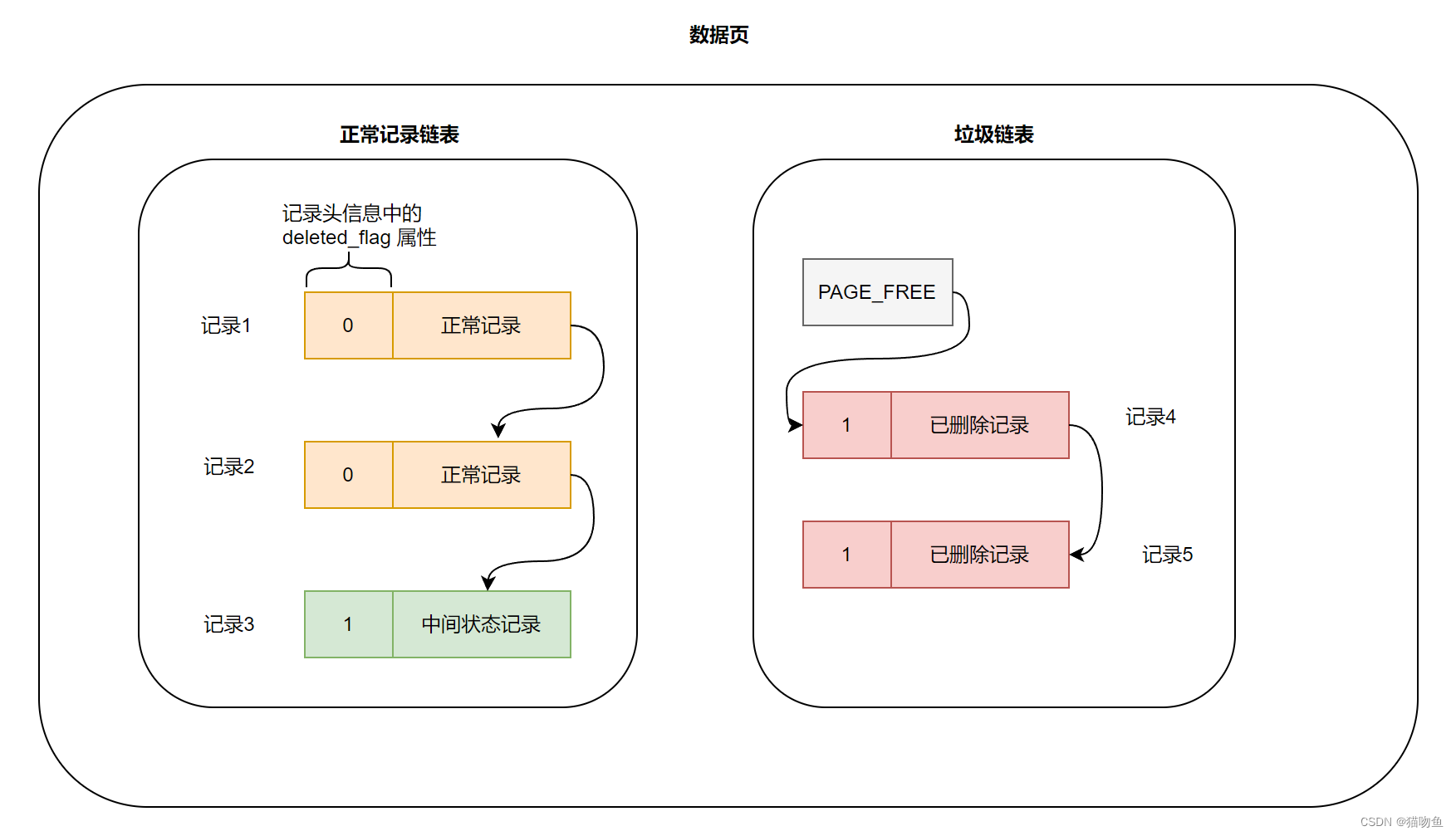
以下圖為例:其中 記錄1,2,3 是未刪除數據,因此在正常數據鏈表中,而 記錄 4,5 是已經打上刪除標記的"已刪除"記錄,在垃圾鏈表中,上面提到數據頁的 Page Header 部分中的 PAGE_FREE 屬性指向垃圾鏈表的節點的頭指針。
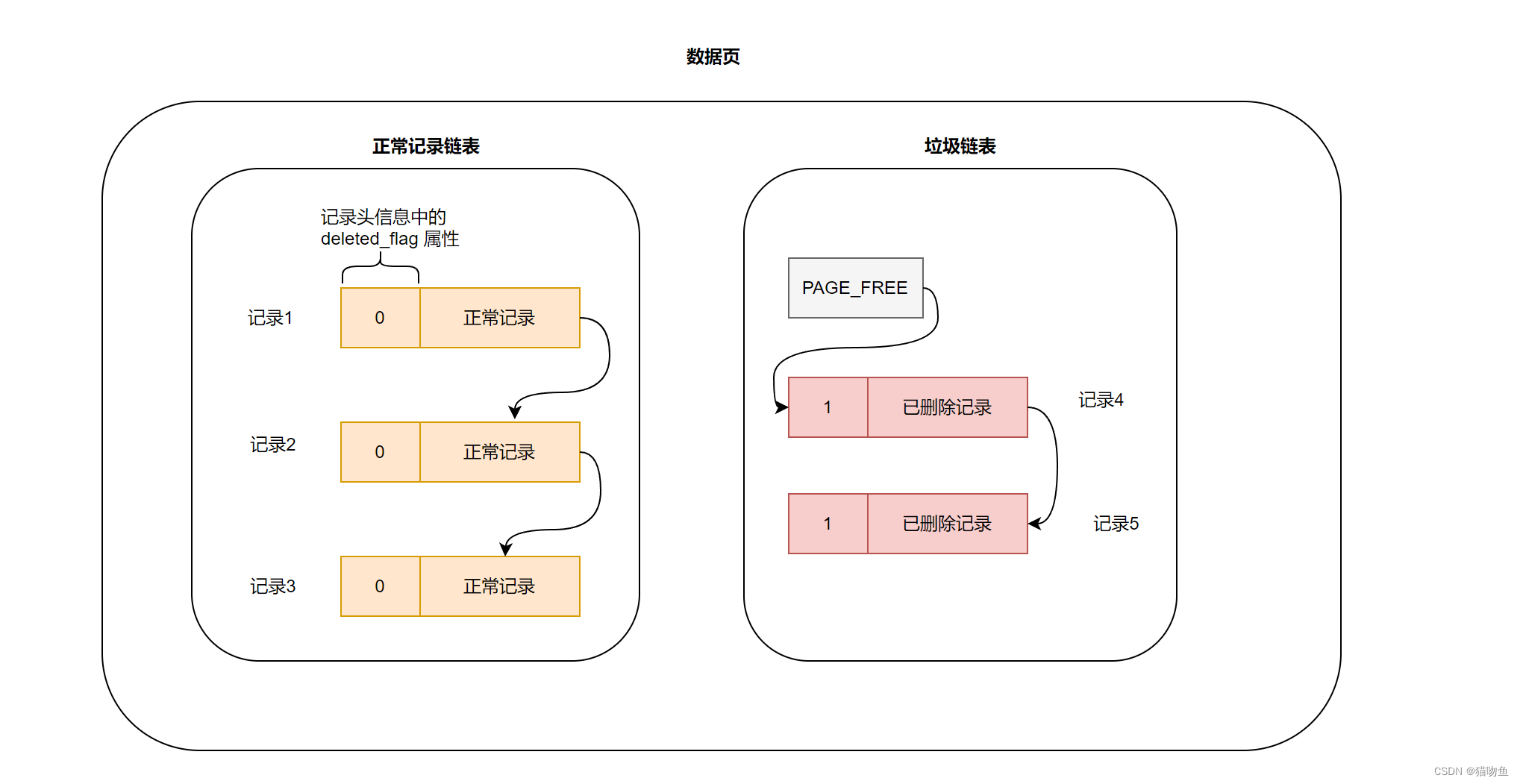
我們假設某個事務需要刪除記錄3 會經歷如下階段:
- delete mark 階段 :此階段會將記錄3 的 delete_flag 置為 1 但是并不會將記錄3 移動到 垃圾鏈表中。此時記錄3既不是正常記錄,也不是已刪除記錄,而是處于一個中間狀態,如下圖:
- purge 階段 :該階段將 記錄3 從正常記錄鏈表中移除并添加到垃圾鏈表中,需要注意這里是將記錄3 添加到垃圾鏈表表頭。
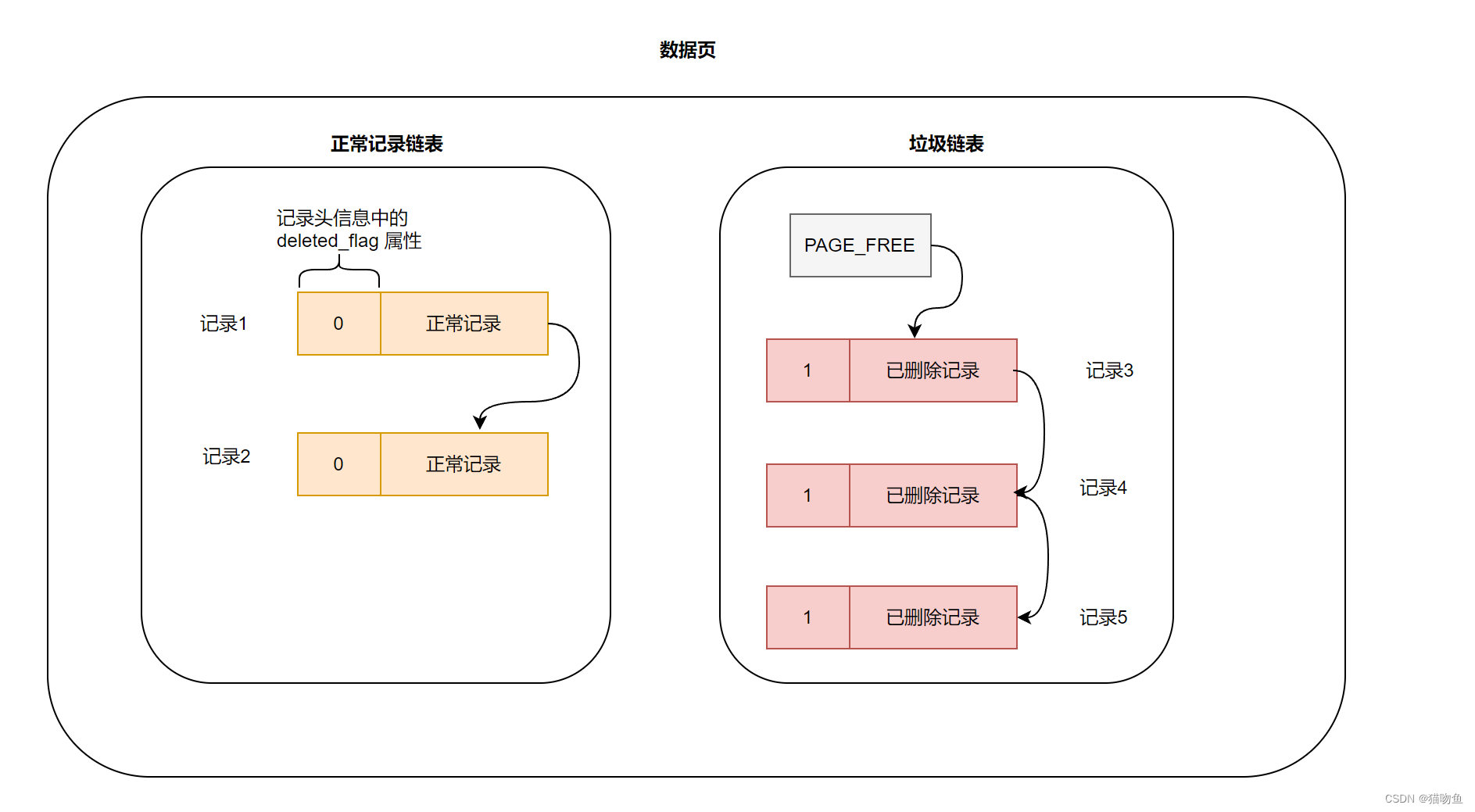
綜上可以得知一個事務在刪除一條記錄時,只需要經歷 delete mark 階段,而一旦事務提交就不需要再回滾這個事務了。
2.3 UPDATE 對應的 undo 日志
InnoDB 對 UPDATE 操作分為更新逐漸和不更新兩種情況,不同的情況有不同的處理方式。
2.3.1 不更新主鍵
不更新主鍵還可以劃分為更新的列占用的存儲空間發生變化和不發生變化兩種情況。
-
就地更新(in-place update): 在更新的時候,對于每個被更新的列來說,如果更新的列更新前后所占用的存儲空間一樣大,則可以進行就地更新,也就是在原紀錄的基礎上修改對應列的值。
-
先刪除舊記錄再插入新記錄 :在不滿足就地更新的條件時,就需要先刪除舊記錄后再更具更新后的列的值創建一條新的記錄并插入到頁面中。需要注意這里所說的刪除不是 delete mark 操作,而是真正刪除,即把這條記錄從正常記錄鏈表移除并加入到垃圾鏈表中,并修改頁面中相應的統計信息(如 PAGE_FREE、PAGE_GARBAGE 等)。并且這里執行真正刪除操作的線程是用戶線程,而并非專門進行 purge 操作的線程。在真正刪除之后就會根據各個列更新后的值創建一條新的記錄并將這條記錄插入頁面中。
如果新創建的記錄占用的存儲空間不超過舊記錄占用的空間,就可以直接重用加入到垃圾鏈表中的舊記錄所占用的存儲空間,否則就要在頁面中新申請一塊空間供新紀錄使用。如果本頁面內已經沒有可用的空間,就需要進行頁分裂操作,然后再插入新記錄。
2.3.2 更新主鍵
在聚簇索引中,記錄按照主鍵大小值排序成一個單向鏈表,如果更新了某條記錄的主鍵值就意味著這條記錄在聚簇索引中的位置即將發生改變。(如果主鍵從1 變更為 100000,由于中間數據量很多,物理層面可能跨了好幾個頁面),這種情況 InnoDB 在聚簇索引中分了兩步進行處理。
- 將舊記錄進行 delete mark 操作。
- 根據更新后的各列的值創建一條新記錄,并將其插入到聚簇索引中:由于更新后的記錄主鍵值發生了改變,所以需要重新從聚簇索引中定位這條記錄所在的位置,然后將其插進去。
針對這種情況,會產生兩條 undo 日志,在進行 delete mark 進行操作時,記錄一條 undo 日志;之后重新插入時還會一條 undo 日志,也就是說每對一條記錄的主鍵值進行改動都會記錄 2條 undo 日志。
2.3 增刪改操作對二級索引的影響
上面說的都是增刪改對聚簇索引記錄所做的影響。對于二級索引記錄來說, INSERT 和 DELETE 操作與在聚簇索引中執行時產生的影響差不多,但 UPDATE 稍有不同。
當更新語句更新的列并不涉及二級索引,則無需對二級索引做任何操作;如果更新語句的更新列涉及二級索引,則會進行下面兩個操作:
- 對舊的二級索引記錄執行 delete mark 操作
- 根據更新后的值創建一條新的二級索引記錄,然后在二級索引對應的 B+Tree 中重新定位到他的位置并插進去。
每修改一條二級索引也會影響這條二級索引所在的頁面的 Page Header 部分中一個名為 PAGE_MAX_TRX_ID 的屬性,這個屬性代表修改當前頁的最大的事務id。
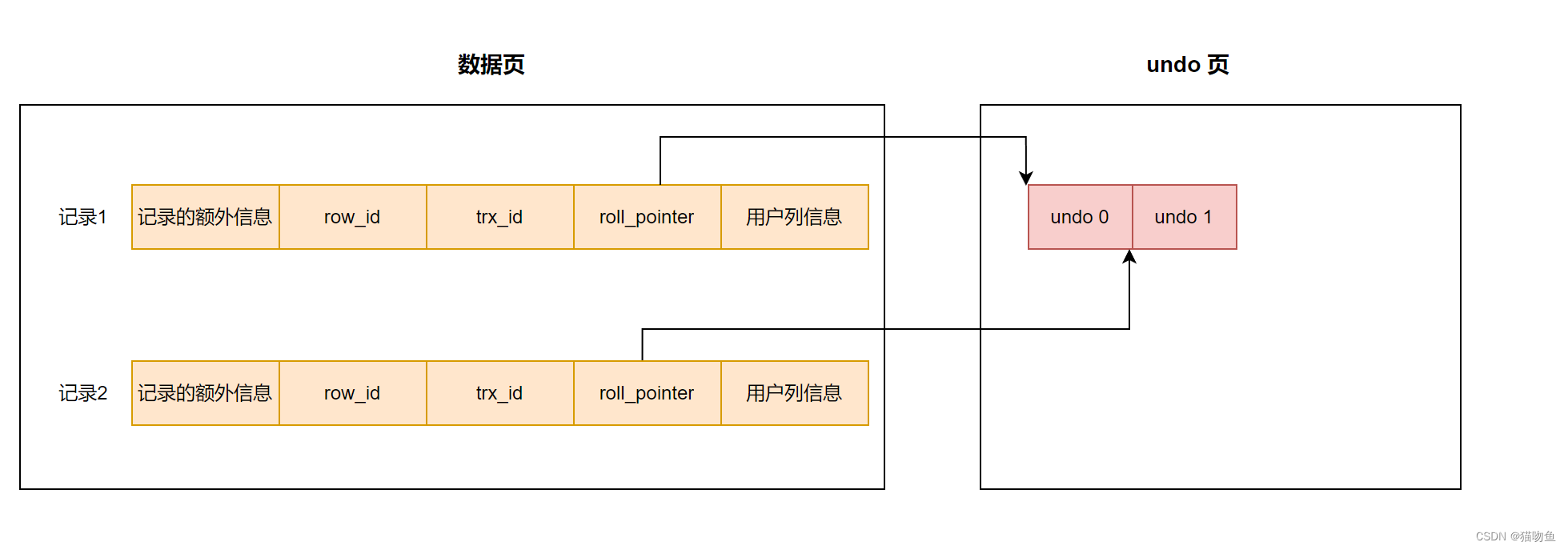
2.4 roll_pointer
roll_point 本質上就是指向記錄對應的undo 日志的指針,如下圖:當向表中依次插入了記錄1 和 記錄2 兩條記錄,此時記錄行的 roll_pointer 就會指向對應 undo 頁的 undo 日志。
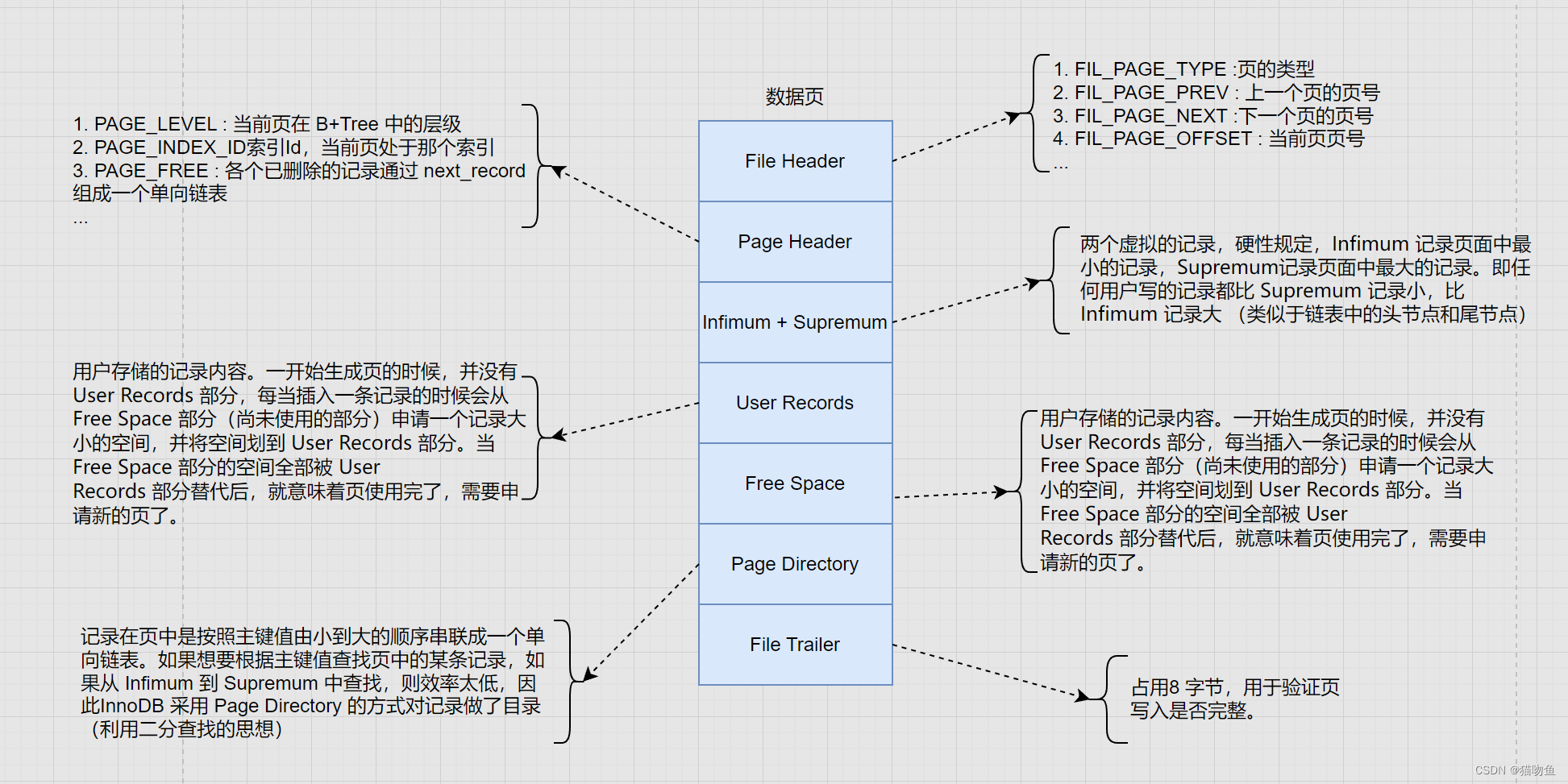
3. FIL_PAGE_UNDO_LOG 頁面
表空間實際是由許多頁面構成的,頁面默認為16KB,這些頁面有不同的類型,其中有一種名為 FIL_PAGE_UNDO_LOG 類型的頁面是專門用來存儲 undo 日志的。這種頁面的通用格式如下:
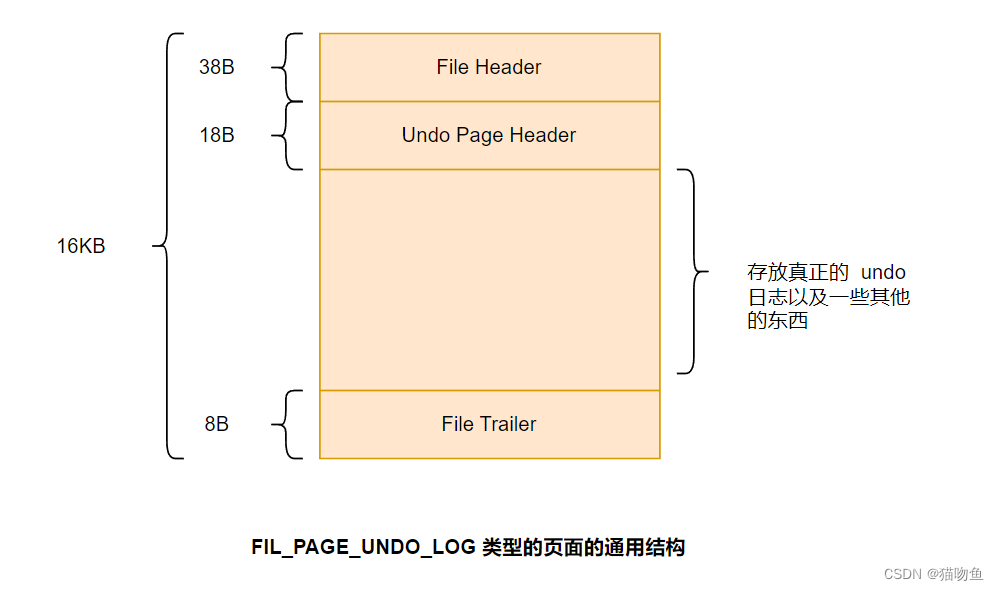
圖中 File Header 和 File Trailer 是各種頁面的通用結構,在【MySQL02】【 InnoDB 記錄存儲結構】有過詳細介紹,這里不再贅述。Undo Page Header 部分是 FIL_PAGE_UNDO_LOG 頁面(下簡稱 Undo 頁面)獨有的,結構如下:
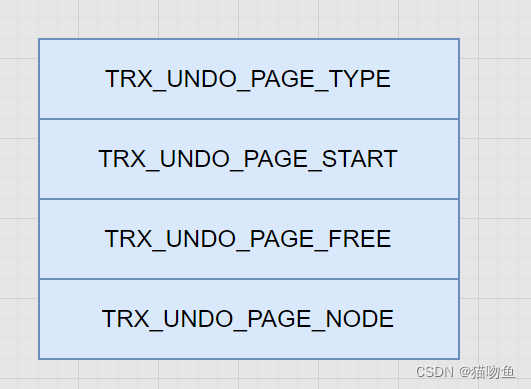
其中各個屬性的解釋如下:
| 屬性 | 解釋 |
|---|---|
| TRX_UNDO_PAGE_TYPE | 當前頁面準備存儲的 undo 日志類型。簡單來說可以分為 TRX_UNDO_INSERT(一般由 INSERT 語句產生,當 UPDATE 語句中有更新主鍵的情況時也會產生該類型的日志,稱為 insert undo 日志)和 TRX_UNDO_UPDATE (除了 TRX_UNDO_INSERT 類型之外的其他類型都屬于該類型,稱為 update undo 日志) |
| TRX_UNDO_PAGE_START | 表示當前頁面從什么位置開始存儲 undo 日志,或者說第一條 undo 日志在本頁面中的起始偏移量 |
| TRX_UNDO_PAGE_FREE | 表示當前頁面中存儲的最后一條 undo 日志結束時的偏移量,或者說從這個位置開始,可以往后繼續寫入新的 undo 日志。當一條undo 日志沒寫時TRX_UNDO_PAGE_FREE 等于 TRX_UNDO_PAGE_START |
| TRX_UNDO_PAGE_NODE | 代表一個鏈表節點結構,下面會將。 |
4. Undo 頁面鏈表
一個事務中可能包含多個語句,一個語句可能修改多條記錄,一條記錄的修改可能會產生多條 undo 日志記錄,因此一個事務執行過程中可能產生很多 undo 日志,這些日志可能一個頁面中放不下,需要放到多個頁面中,這些頁面就通過上面介紹的 TRX_UNDO_PAGE_NODE屬性連成了鏈表,如下圖:
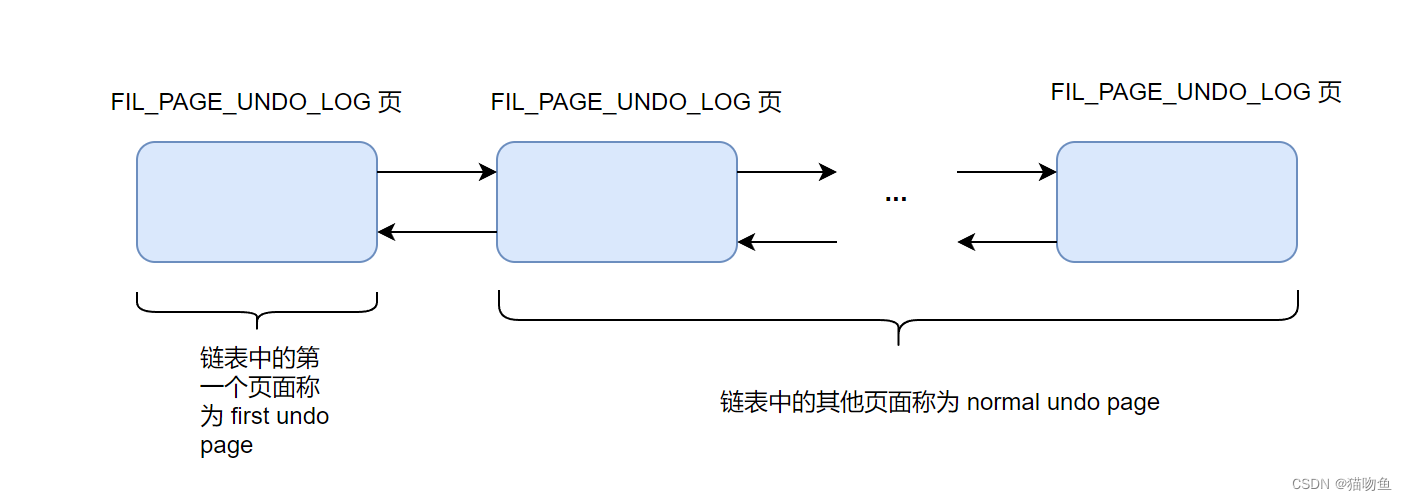
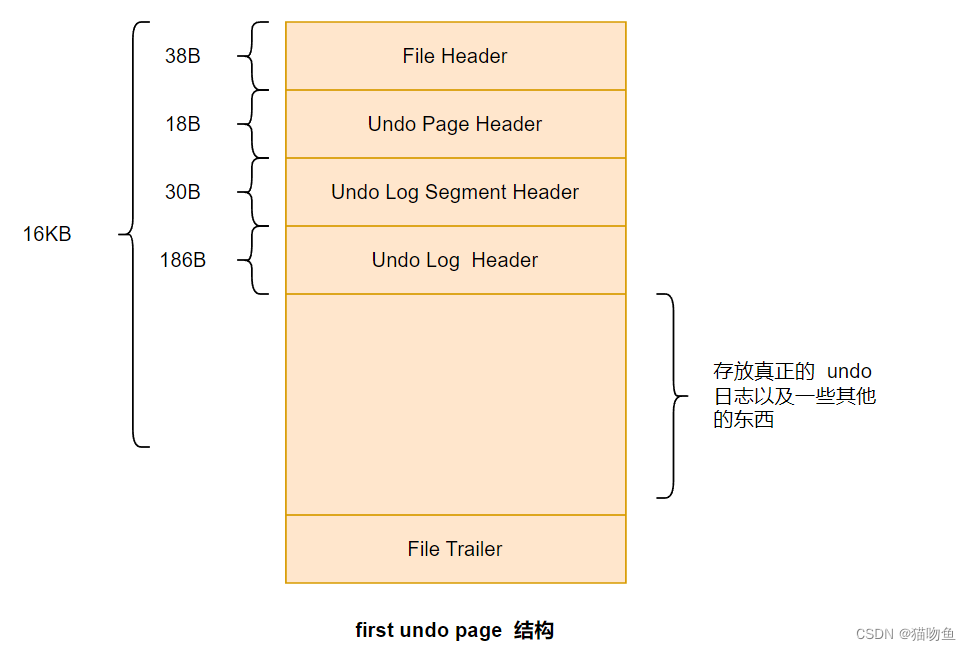
first undo page 中除了包含 Undo Page Header 之外,還會包含其他一些管理信息,結構如下:
在一個事務執行過程中,可能會混合著增刪改的操作,也就會產生多種類型的 undo 日志,但是同一個Undo 頁面要么只存儲 TRX_UNDO_INSERT大類的 undo 日志,要么只存儲 TRX_UNDO_UPDATE 大類的 undo 日志,不能混著存儲,所以在一個事務執行過程中就可能需要兩個 Undo 頁面鏈表,一個稱為 insert undo 鏈表,一個稱為 update undo 鏈表,如下:
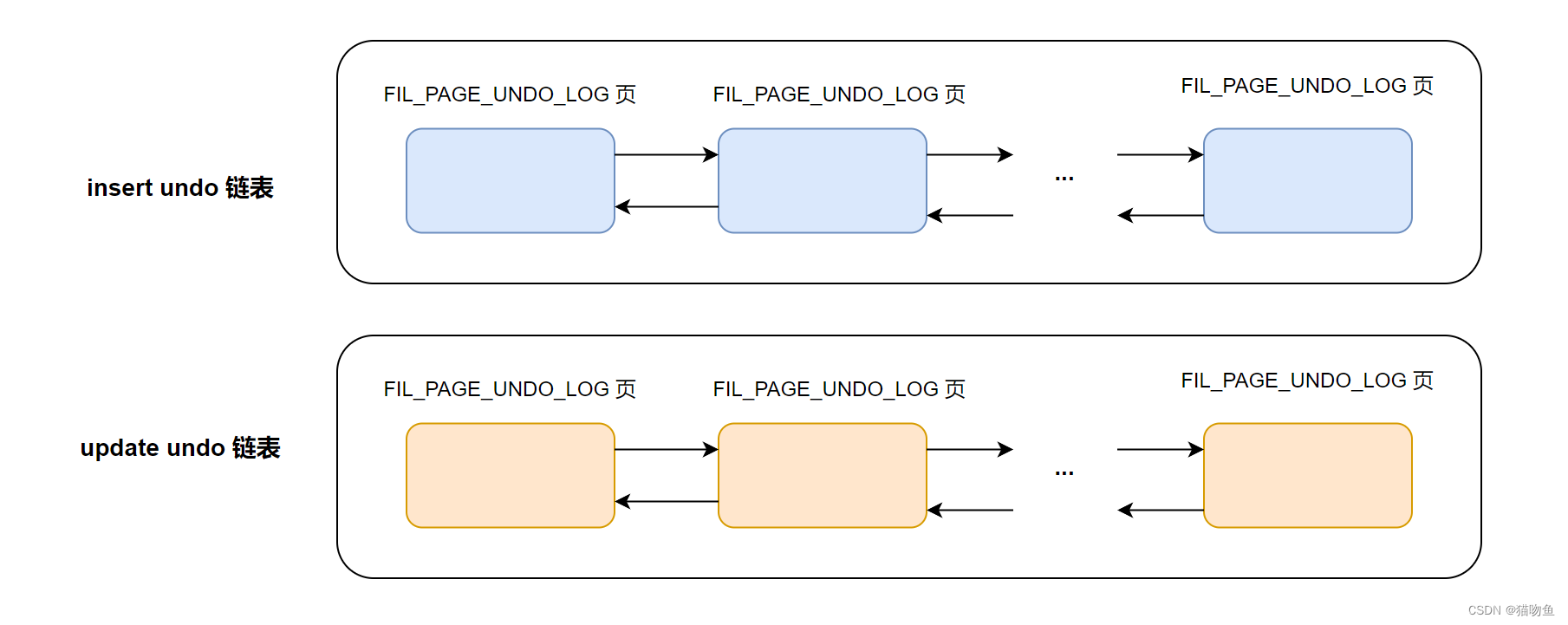
同時InnoDB 規定,對普通表和臨時表的記錄改動時產生的 undo 日志要分別記錄,所以在一個事務中最多有4個 以 undo 頁面為節點組成的鏈表(這四個鏈表并不是在事務開始時就會分配的,而是需要使用的時候才會分配。)。如下圖:
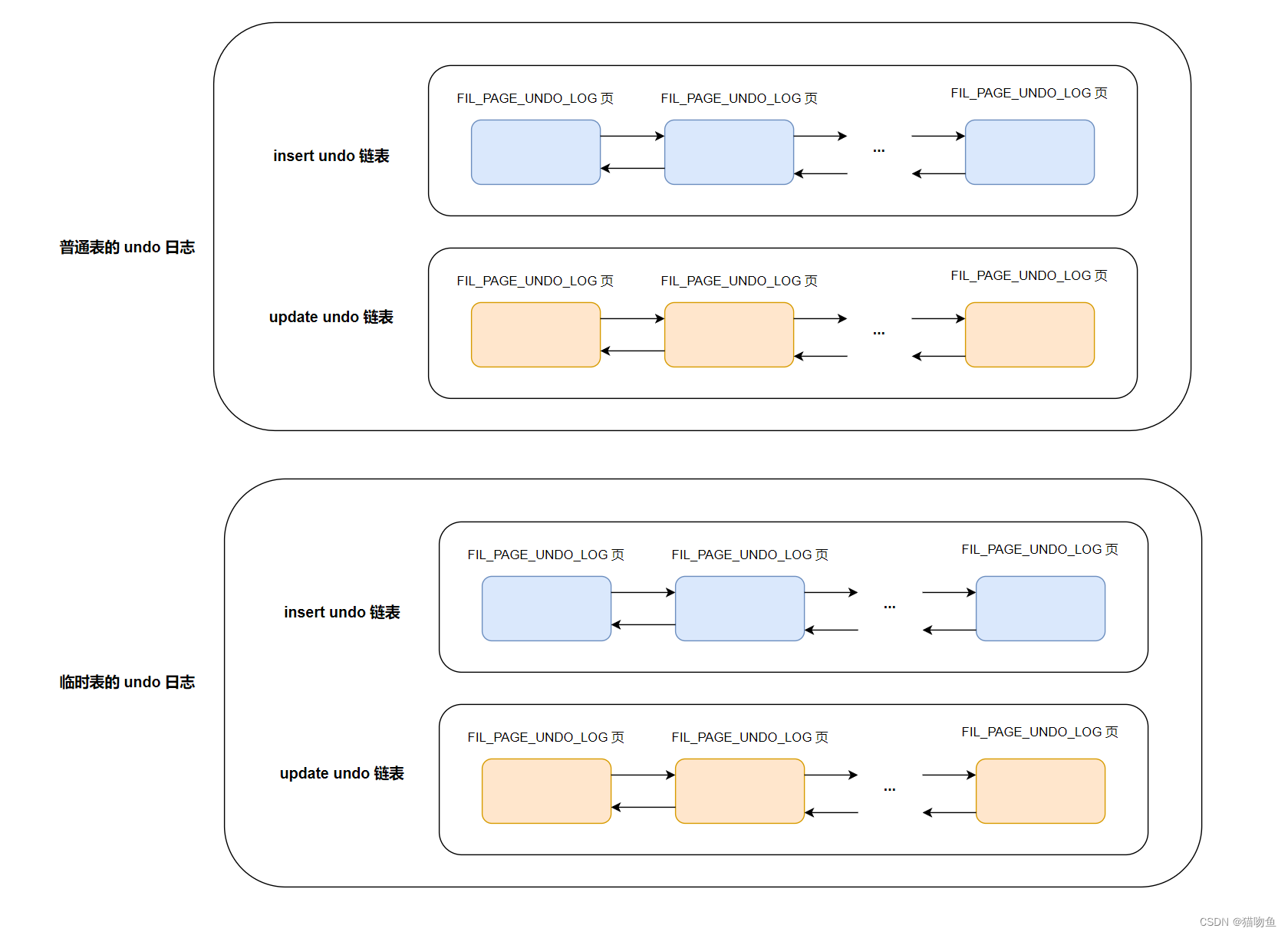
注意:
- 為了盡可能提高 undo 日志的寫入效率,不同事務執行過程中產生的 undo 日志需要寫入不同的 Undo 頁面鏈表。如果有更多的事務就會產生更多的 Undo 頁面鏈表。
- InnoDB 規定,每個 Undo 頁面鏈表都對應著一個段,稱為 Undo Log Segment。也即是說鏈表中的頁面都是從這個段中申請的,所以在 Undo 鏈表的第一個頁面(first undo page)中設計了一個 Undo Log Segment Header 部分,這個部分主要包含了該鏈表對應的段的 Segment Header 信息,以及其他一些關于這個段的信息。
5. Undo 日志具體寫入過程
一個事務在向 Undo 頁面中寫入 undo 日志時,是一條接一條相鄰寫入的。寫完一個 Undo 頁面后,再從段中申請一個新頁面,然后把這個頁面插入到 Undo 頁面鏈表中,繼續往這個新的頁面中寫 undo 日志。
對于沒有被重用的 Undo 頁面鏈表來說,鏈表的第一個頁面(first undo page)在真正寫入 undo 日志前,會填充 Undo Page Header、Undo Log Segment Header、Undo Log Header 三部分,之后才會正式寫入日志。對于其他頁面(normal undo page)來說,在真正寫入undo 日志前,只會填充 Undo Page Heade。鏈表基節點存放到 first undo page 的 Undo Log Segment Header 部分,鏈表節點信息存放到每個 Undo 頁面的 Undo Page Header 部分,如下圖:
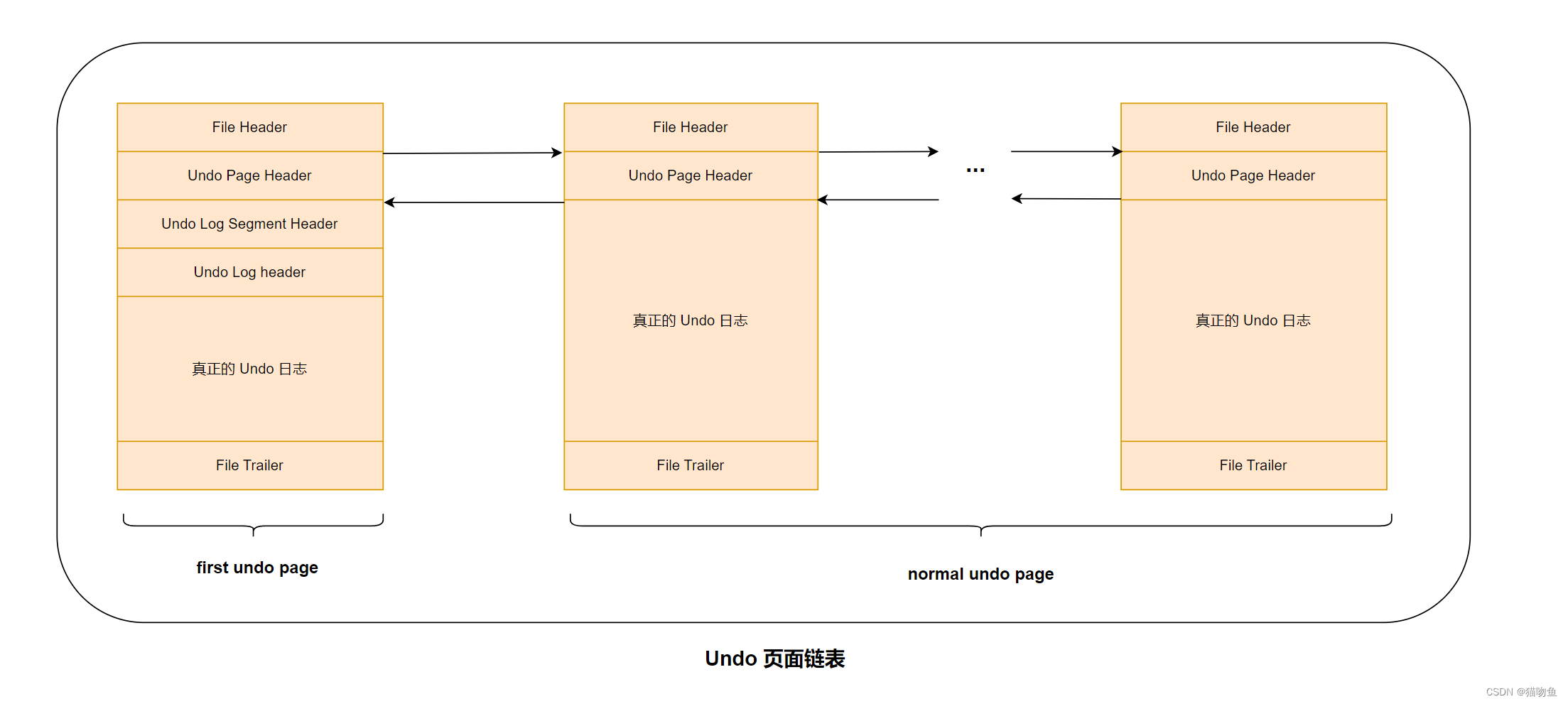
6. 重用 Undo 頁面
上文提到 InnoDB 規定會為每個事務單獨分配對應的 Undo 頁面鏈表,即一個 Undo 頁面鏈表只存儲一個事務執行過程中產生的一組 undo 日志,這就可能造成空間浪費。如大部分事務在執行過程中可能只修改了一條或幾條記錄,針對某個 Undo 頁面鏈表只產生了少了 undo 日志,這些少量 的 undo 日志只會占用很少的存儲空間,但是因為每開啟一個事物就新創建一個 Undo 頁面鏈表(即使這個鏈表中只有一個頁面)來存儲這些少量的 undo 日志,因此會造成鏈表中的頁面的空間浪費。
因此 InnoDB規定 在事務提交后的某些情況下可以重用該事務的 Undo 頁面鏈表。重用 Undo 頁面需要滿足如下條件:
- 該鏈表中只包含一個 Undo 頁面
- 該 Undo 頁面已經使用的空間小于整個頁面空間的 3/4
Undo 頁面鏈表被分為 insert undo 鏈表和 update undo 鏈表兩種,這兩種鏈表在重用時策略也是不同的,如下:
- insert undo 鏈表:這種類型的undo日志在事務提交后就沒用了,可以被清除掉,因此在某個事務提交后,在重用這個事務的 insert undo 鏈表時,可以直接把之前事務寫入的一組 undo 日志覆蓋掉,從頭開始寫入新事物的一組 undo 日志。
- update undo 鏈表:在一個事務提交后,它的 update undo 鏈表中的 undo 日志不能立即刪除(需要用于 MVCC)。這樣之后的事務想重用 update undo 鏈表時就不能覆蓋之前事務寫入的 undo 日志,這樣就相當于在同一個 Undo 頁面寫入了多組 undo 日志。
7. 回滾段
7.1 概念
一個事務在執行過程中最多可以分配 4 個 Undo 頁面鏈,而在同一時刻的不同事務擁有的 Undo 頁面鏈表是不同的,系統在同一時刻可以存在多個 Undo 頁面鏈表。為了更好的管理這些鏈表,InnoDB 提出了名為 Rollback Segment Header 的頁面,這個頁面中可以存放各個 Undo 頁面鏈表的 first undo page 的頁號,這些頁號稱為 undo slot。
InnoDB 規定,每個 Rollback Segment Header 頁面都對應著一個段,這個段稱為回滾段(Rollbakc Segment),與其他段不同,回滾段中其實只有一個頁面。
Rollback Segment Header 的結構如下:
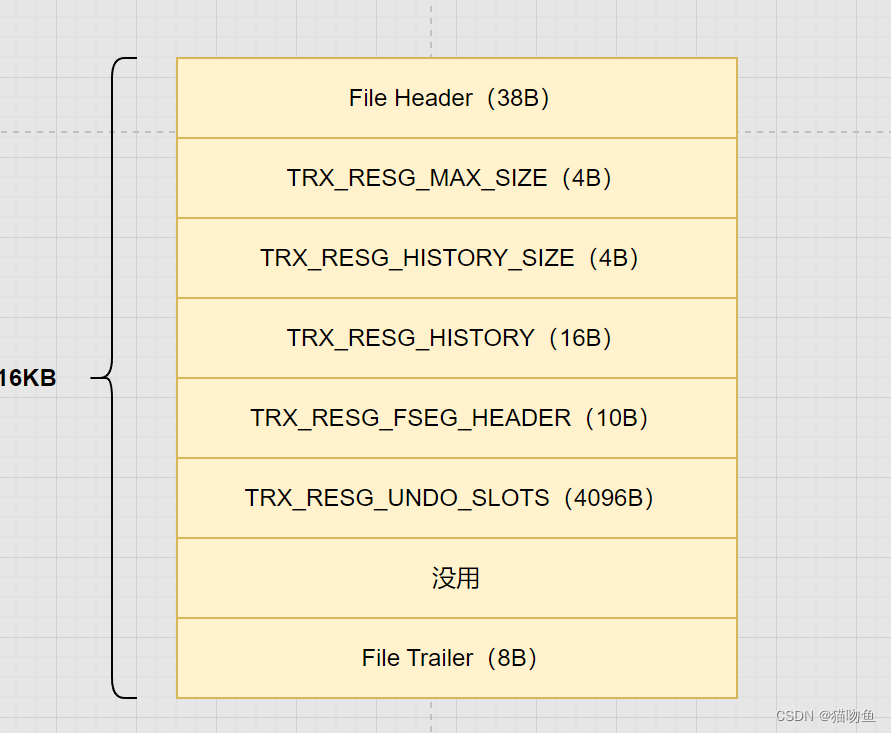
其中各個字段的含義如下:
| 字段名 | 解釋 |
|---|---|
| TRX_RESG_MAX_SIZE | 這個回滾段中管理的所有 Undo 頁面鏈表中的 Undo 頁面數量之和的最大值。即在這個回滾段中,所有 Undo 頁面鏈表中的 Undo 頁面數量之和是不能超過該值,該屬性默認無限制。 |
| TRX_RESG_HISTORY_SIZE | History 鏈表所占用的頁面數量 |
| TRX_RESG_HISTORY | History 鏈表的基節點 |
| TRX_RESG_FSEG_HEADER | 這個回滾段對應的 10字節大小的 Segment Header 結構,通過他可以找當前回滾段對應的 INODE Entry |
| TRX_RESG_UNDO_SLOTS | 各個 Undo 頁面鏈表的 first undo page 的頁號集合,也就是undo slot 集合 |
7.2 從回滾段申請 Undo 頁面鏈表
在初始情況下,由于未向任何事物分配任何 Undo 頁面鏈表,所以對于一個 Rollback Segment Header 頁面來說,他的各個 undo slot 都被設置為一個特殊的值:FIL_NULL,這表示該 undo slot 不指向任何頁面。
隨著時間的流逝,開始有事務需要分配 Undo 頁面鏈表了,于是從回滾段的第一個 undo slot 開始尋找:
- 如果 undo slot 的值是 FIL_NULL,那么就在表空間中新創建一個段(Undo Log Segment),然后從段中申請一個頁面作為 Undo 頁面鏈表的 first undo page,最后把該 undo slot 的值設置為剛剛申請的這個頁面的地址,這也就意味著這個 undo slot 被分配給了這個事務。
- 如果不是為 FIL_NULL,則說明該 undo slot 已經指向了一個 undo 鏈表,也就是說這個 undo slot 已經被其他事務占用了,這就需要跳到下一個 undo slot 重復上述判斷邏輯。
如果一個 Rollback Segment Header 頁面中包含的 1024 個 undo slot 的值都不為 FIL_NULL,則新事物無法再獲得新的 Undo 頁面鏈表,就會停止執行事務并向用戶報錯:
Too many active concurrent transactions
當一個事務提交時,其占用的 undo slot 有兩種可能:
-
如果該 undo slot 符合被重用的條件,則該 undo slot 就處于被緩存的狀態。InnoDB規定,該 Undo 頁面鏈表的 TRX_UNDO_STATE 屬性會被設置為 TRX_UNDO_CACHED。
被緩存的 undo slot 都會被加入到一個鏈表中,不同的 Undo 頁面鏈表(insert undo 鏈表和 update undo 鏈表)對應的 undo slot 會被加入到不同的鏈表中。
一個回滾段對應著上述兩個 cached 鏈表,如果有新事物要分配 undo slot 都先從對應的 cached 鏈表中招,如果沒有被緩存的 undo slot,才會到回滾段的 Rollback Segment Header 頁面中尋找。 -
如果該 undo slot 不符合被重用的條件,那么根據該 undo slot 對應的 Undo 頁面鏈表類型的不同也會有不同的處理。
- 如果是 insert undo 鏈表,則該 Undo 頁面鏈表的 TRX_UNDO_STATE 屬性會被設置為 TRX_UNDO_TO_FREE 。之后該 Undo 頁面鏈表對應的段會被釋放掉,然后把該 undo slot 的值設置為 FIL_NULL。
- 如果是 update undo 鏈表,則該 Undo 頁面鏈表的 TRX_UNDO_STATE 屬性會被設置為 TRX_UNDO_TO_PURGE,并將該 undo slot 的值設置為 FIL_NULL,然后將本次事務寫入的一組 undo 日志放到 History 鏈表中(這里并不會將 Undo頁面鏈表對應的段釋放掉,因為MVCC 還需要使用)
7.3 多個回滾段
由于一個回滾段最多只支持1024個事務并發,這顯然是不夠的,所以 InnoDB 設置了128個回滾段,如下:
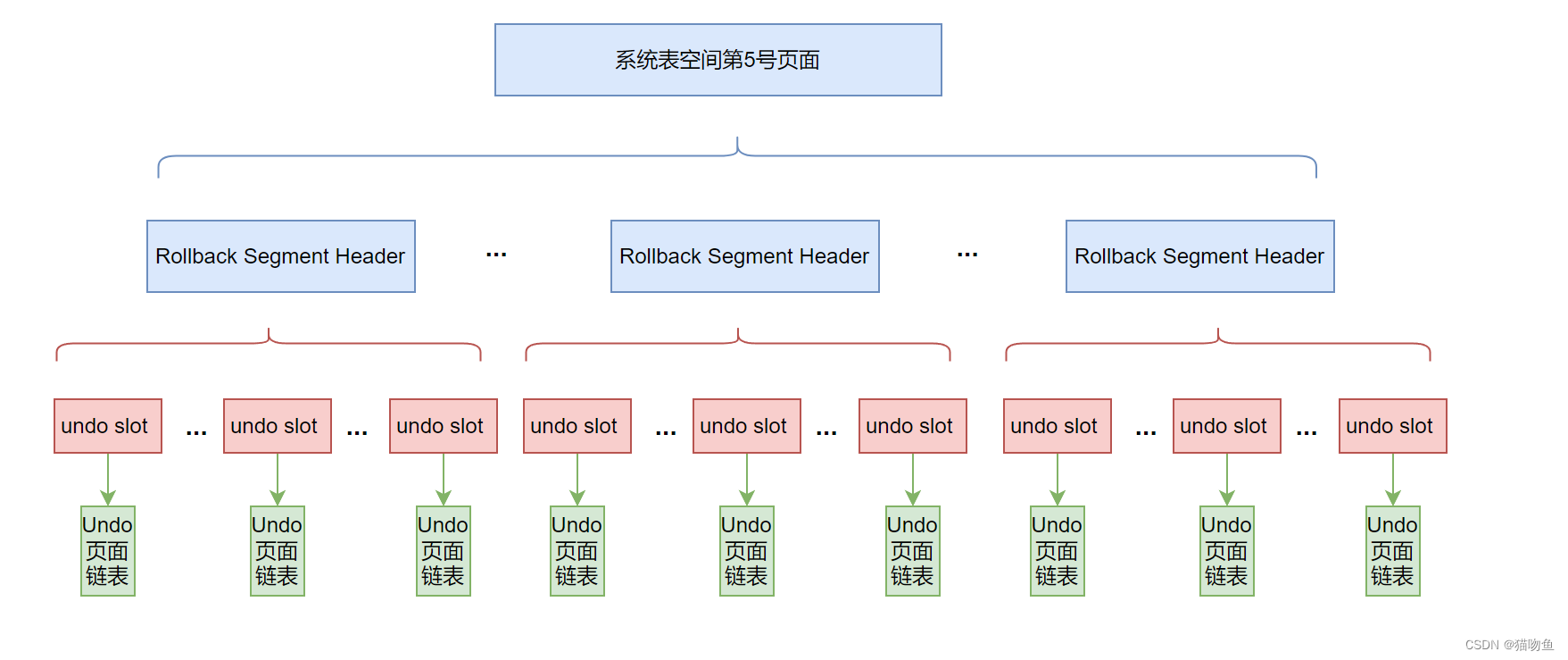
7.4 回滾段的分類
對128個回滾段從0開始編號,即最開始的回滾段稱為 0 號回滾段,最后的回滾段稱為 127 號回滾段,這128個回滾段可以分為兩大類:
-
第 0號,第33~127號回滾段屬于一類:其中第 0 號回滾段必須在系統表空間中,第 33~127號回滾段既可以在系統表空間也可以在自己配置的 undo 表空間中。
如果一個事務在執行過程中對普通表的記錄進行了改動,需要分配 Undo 頁面鏈表,則必須從這一類段中分配相應的 undo slot。
-
第1~32號回滾段屬于一類,這些回滾段必須在臨時表空間(對應數據目錄中的 ibtmp1 文件)中。
如果一個事務在執行過程中對臨時表的記錄進行了改動,需要分配 Undo 頁面鏈表,則必須從這一類段中分配相應的 undo slot。
如果一個事務在執行過程中既對普通表記錄進行改動,又對臨時表的記錄進行改動,則就需要為這個記錄分配兩個回滾段。
之所以分為兩種回滾段,是因為臨時表的修改產生的undo 日志只需要在系統運行過程中有效即可,如果系統崩潰,則重啟后也不需要恢復這些 undo 日志所在的頁面,所以在針對臨時表寫的 undo 頁面時并不需要記錄相應的 redo 日志,而對于普通表的修改不僅要記錄其 undo 日志,還要記錄 redo 日志。
回滾段的數量和存儲位置都可以通過配置來指定,本文不再贅述。
7.5 roll_pointer 的組成
roll_pointer 的結構如下:

各個屬性的意義如下:
| 屬性 | 解釋 |
|---|---|
| is_insert | 表示該指針指向的 undo 日志是否是 TRX_UNDO_INSERT 大類的 undo 日志 |
| rseg_id | 表示該指針指向的 undo 日志的回滾段編號,即0~127 回滾段編號 |
| page number | 表示該指針指向的 undo 日志所在的頁面的頁號 |
| offset | 表示該指針指向的 undo 日志在頁面中的偏移量 |
roll_pointer 基于上述內容便可以定位到一條 undo 日志。
7.6 事務分配 Undo 頁面鏈表的過程
-
事務在執行過程中對普通表的記錄進行首次改動之前,會首先到系統表空間的第五號頁面分配(輪詢方式分配)一個回滾段(就是獲取一個 Rollback Segment Header 頁面的地址)。一旦某個回滾段被分配給了這個事務,之后該事務再對普通表的記錄進行改動時就不會重新分配了。
-
在分配到回滾段后,首先判斷回滾段的兩個 cache 鏈表有沒有已經緩存的 undo slot。如果有緩存的 undo slot 就將緩存的 undo slot 分配給當前事務。
-
如果沒有緩存的 undo slot ,則需要從 Rollback Segment Header 中找到一個可用的 undo slot 分配給該事物。分配的邏輯上面已經提到:
從 Rollback Segment Header 的第0 個 undo slot 開始判斷:
- 如果 undo slot 的值是 FIL_NULL,那么就在表空間中新創建一個段(Undo Log Segment),然后從段中申請一個頁面作為 Undo 頁面鏈表的 first undo page,最后把該 undo slot 的值設置為剛剛申請的這個頁面的地址,這也就意味著這個 undo slot 被分配給了這個事務。
- 如果不是為 FIL_NULL,則說明該 undo slot 已經指向了一個 undo 鏈表,也就是說這個 undo slot 已經被其他事務占用了,這就需要跳到下一個 undo slot 重復上述判斷邏輯。
-
找到可用的 undo slot 后,如果該 undo slot 是從 cached 鏈表獲取的,那么其對應的 Undo Log Segment 就已經分配了,否則需要重新分配一個 Undo Log Segment,然后從該 Undo Log Segment 中申請一個頁面作為 Undo 頁面鏈表的 first undo page,并把該頁的頁號填入獲取的 undo slot 中。
-
然后事務就可以把 undo 日志寫入到上面申請的Undo 頁面鏈表了。
7.7 undo 日志在崩潰恢復時的作用
當服務器崩潰后恢復時,首先需要按照 redo 日志將各個頁面的數據恢復到崩潰之前的狀態,這樣可以保證已提交事務的持久性,但這樣有一個問題即:未提交事務寫的 redo 日志可能也已經刷盤,那么這些未提交的事務在修改過的頁面在 MySQL 重啟時可能也被恢復了。因此為了保證事務的原子性,需要將未提交事務的 redo 日志回滾掉。
在 【MySQL04】【 redo 日志】 中有過介紹為什么不在事務提交時將臟頁刷新,主要因為下面的問題
- 刷新一個完整的頁面太浪費了,有時候僅僅修改了頁面的一個字節也需要將整個頁刷新到磁盤。
- 隨機IO刷新效率太低。一個事務可能包含很多語句,即使一個語句也可能修改很多頁面,并且這些頁面可能并不相鄰,在將這些頁面刷新到磁盤的時候需進行很對隨機IO。
因為上述問題,InnoDB 并不是在事務提交時將所有頁刷新到磁盤,而是將修改的內容記錄下來,在合適的時機刷新到磁盤中。
InnoDB 通過系統表空間第5號頁面定位到 128 個回滾段的位置,在每個回滾段的 1024 個 undo slot 中找到那些值不為 FIL_NULL 的 undo slot ,每一個 undo slot 對應一個 Undo 頁面鏈表。然后從 Undo 頁面鏈表第一個頁面的 Undo Segment Header 中找到 TRX_UNDO_STATE 屬性,該屬性標識當前 Undo 頁面鏈表所處的狀態,如果該屬性的值為 TRX_UNDO_ACTIVE ,則意味著有一個活躍的事務在向這個 Undo 頁面鏈表中寫入 undo 日志。然后再在 Undo Segment Header 中找到 TRX_UNDO_LAST_LOG 屬性,通過該屬性可以找到本 Undo 頁面鏈表最后一個 Undo Log Header 的位置,從該 Undo Log Header 中可以找到對應事務的事務id以及一些其他信息,則該事物id對應的事務就是未提交的事務,通過 undo 日志中記錄的信息將該事物對頁面所做的更改全部回滾掉,這樣就保證了事務的原子性。
四、總結
一個事務最多有四個 Undo 頁面鏈表, 一個 Undo 頁面鏈表至少有一個 Undo頁面,一般來說一個 Undo 頁面鏈表在不重用的情況下只能被一個事務使用。
InnoDB中存在多個回滾段,一個回滾段默認支持 1024個事務并發,因此最多存在 1024個 Rollback Segment Header ,而 每個 Rollback Segment Header 都存在多個 undo slot,每個 undo slot 中保存的是 undo 頁面鏈表的 first undo page,根據 first undo page 就可以找到完整的 undo 頁面鏈表。
五、參考內容
書籍:《MySQL是怎樣運行的——從根兒上理解MySQL》、《MySQL技術內幕 InnoDB存儲引擎 》
如有侵擾,聯系刪除。 內容僅用于自我記錄學習使用。如有錯誤,歡迎指正






)







服務(二))




