項目場景:
提示:這里簡述項目相關背景:定時爬取外網的某個頁面,并將需要的部分翻譯為中文存入excel
接下了的,沒學過的最好看一下
基本爬蟲的學習
【爬蟲】requests 結合 BeautifulSoup抓取網頁數據_requests beautifulsoup 在界面中選取要抓取的元素-CSDN博客
問題描述 一:
提示:這里描述項目中遇到的問題:
以基本爬蟲的學習的例子為例,換到你自己想要的url?運行不了?
?原因分析 一:
程序使用一段時間后會遇到HTTP Error 403: Forbidden錯誤。 因為在短時間內直接使用Get獲取大量數據,會被服務器認為在對它進行攻擊,所以拒絕我們的請求,自動把電腦IP封了。?
?解決方案?一:
我就不細講了,看懂別人的就行:
python 爬蟲禁止訪問解決方法(403)_爬蟲加了請求頭還是403錯誤-CSDN博客
? 我的是這樣的
import random
import timeimport requests
from bs4 import BeautifulSoupurl = "https://pubmed.ncbi.nlm.nih.gov/"# List of user-agent strings
my_headers = ["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14","Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11','Opera/9.25 (Windows NT 5.1; U; en)','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)','Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)','Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12','Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7","Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0"
]try:with requests.Session() as session:t = 0.1time.sleep(t)# 隨機從列表中選擇IP、Header#proxy = random.choice(proxy_list)header = random.choice(my_headers)headers = {"User-Agent": header}response = session.get(url, headers=headers)response.raise_for_status() # Raises HTTPError for bad responsesprint(f"Response status using {header}: {response.status_code}")#print(response.content) # 打印網頁內容# 使用BeautifulSoup解析HTML內容soup = BeautifulSoup(response.content, 'html.parser')# Extract information from each 'li' element within 'items-list'paper_items = soup.select('ul.items-list li.full-docsum')for item in paper_items:paper_link = item.find('a')['href'] # Extract href attribute from <a> tagpaper_title = item.find('a').text.strip() # Extract text from <a> tagprint(f"論文標題: {paper_title}")print(f"鏈接: {url}{paper_link}")print()# for header in my_headers:# headers = {"User-Agent": header}# response = session.get(url, headers=headers)# response.raise_for_status() # Raises HTTPError for bad responses# print(f"Response status using {header}: {response.status_code}")except requests.exceptions.HTTPError as errh:print(f"HTTP error occurred: {errh}")
except requests.exceptions.RequestException as err:print(f"Request error occurred: {err}")
問題描述 二:
使用python自帶的translate 超多問題,又慢又多個單詞組成的翻譯不準確,且不到10次就崩了,
?解決方案? 二:
東西給家人們找好了,就學吧
【筆記】Python3|(一)用 Python 翻譯文本的教程、代碼與測試結果(第三方庫 translate 和 騰訊 API 篇)_python調用有道翻譯-CSDN博客
python實現調用騰訊云翻譯API_騰訊翻譯api怎么獲取-CSDN博客
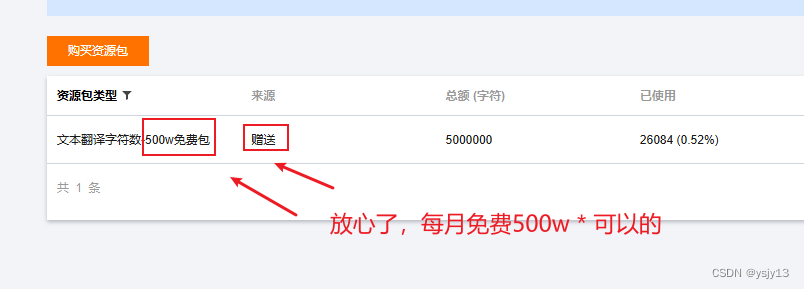
怎么存入ecxel? 可以讓 Al (gpt)幫你寫
?上面實現 完整代碼
寫自己的騰訊云?SecretId 和 SecretKey 還有 url???
其中 從頁面要獲取的html源代碼 放到Al (gtp)? 讓他幫你修改代碼就行? ?不要直接用我的??
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.tmt.v20180321 import tmt_client, modelsSecretId = "xxxxxxxxxxxxxxxxxxxxxxxxxx"
SecretKey = "xxxxxxxxxxxxxxxxxxxxxxxxx"import random
import time
import pandas as pd
from requests.exceptions import RequestException
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbookurl = "https://pubmed.ncbi.nlm.nih.gov/"
my_headers = ["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14","Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11','Opera/9.25 (Windows NT 5.1; U; en)','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)','Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)','Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12','Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7","Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0"
]class Translator:def __init__(self, from_lang, to_lang):self.from_lang = from_langself.to_lang = to_langdef translate(self, text):try:cred = credential.Credential(SecretId, SecretKey)httpProfile = HttpProfile()httpProfile.endpoint = "tmt.tencentcloudapi.com"clientProfile = ClientProfile()clientProfile.httpProfile = httpProfileclient = tmt_client.TmtClient(cred, "ap-beijing", clientProfile)req = models.TextTranslateRequest()req.SourceText = textreq.Source = self.from_langreq.Target = self.to_langreq.ProjectId = 0resp = client.TextTranslate(req)return resp.TargetTextexcept TencentCloudSDKException as err:return errdef fetch_and_translate_papers(url, headers):try:with requests.Session() as session:t = 0.1time.sleep(t)translator = Translator(from_lang="en", to_lang="zh")header = random.choice(headers)headers = {"User-Agent": header}response = session.get(url, headers=headers)response.raise_for_status()print(f"Response status using {header}: {response.status_code}")soup = BeautifulSoup(response.content, 'html.parser')# Prepare data to store in DataFramedata = []paper_items = soup.select('ul.items-list li.full-docsum')for item in paper_items:paper_link = item.find('a')['href'] # Extract href attribute from <a> tagpaper_title = item.find('a').text.strip() # Extract text from <a> tagchinese_paper_title = translator.translate(paper_title)print(f"Paper Title: {paper_title}")print(f"論文標題: {chinese_paper_title}")print(f"鏈接: {url}{paper_link}")print()data.append({'Paper Title': paper_title,'論文標題': chinese_paper_title,'鏈接': f"{url}{paper_link}",})# Create a DataFramedf = pd.DataFrame(data)# Save to Excelfile_name = 'pubmed.xlsx'df.to_excel(file_name, index=False, engine='openpyxl')print(f"Data saved to {file_name}")except RequestException as e:print(f"Error fetching {url}: {e}")# Call the function
fetch_and_translate_papers(url, my_headers)
讓 al 修改的是這段
paper_items = soup.select('ul.items-list li.full-docsum')for item in paper_items:paper_link = item.find('a')['href'] # Extract href attribute from <a> tagpaper_title = item.find('a').text.strip() # Extract text from <a> tagchinese_paper_title = translator.translate(paper_title)print(f"Paper Title: {paper_title}")print(f"論文標題: {chinese_paper_title}")print(f"鏈接: {url}{paper_link}")print()data.append({'Paper Title': paper_title,'論文標題': chinese_paper_title,'鏈接': f"{url}{paper_link}",})從頁面要獲取的html源代碼? 這個也要教嗎 懶了呀
就是你要爬的頁面 在頁面鼠標 右鍵源代碼
?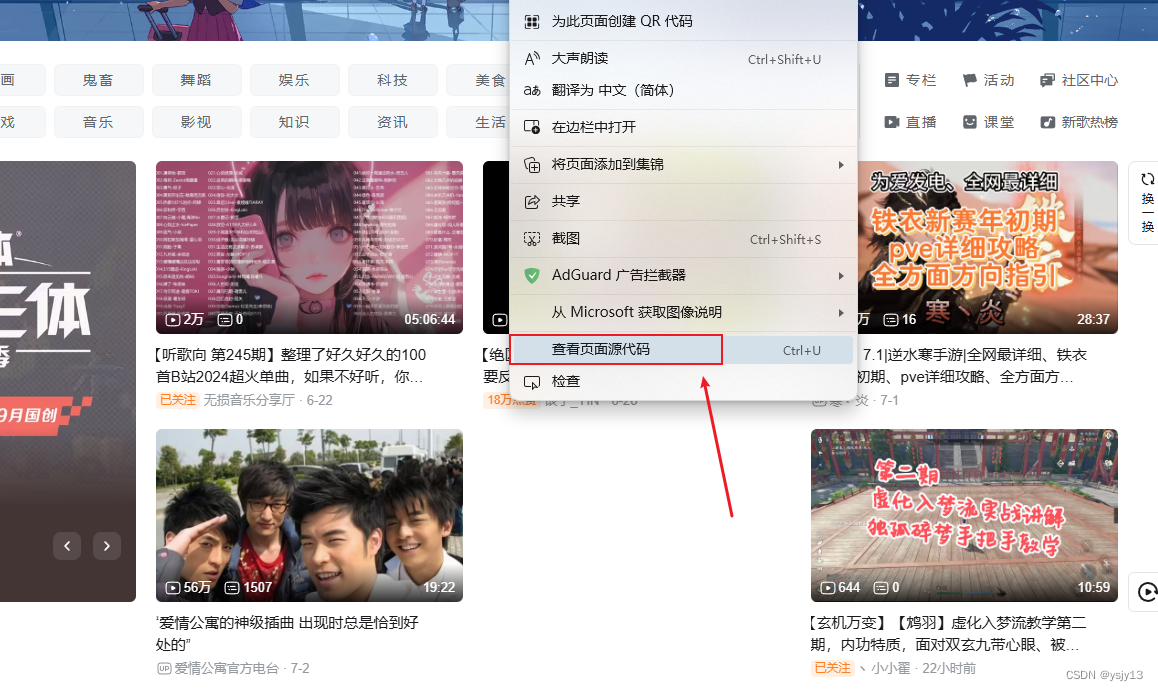
?把你要爬的 html源代碼 放al 讓他辦你改
問題描述 三:
怎么在自己的電腦定時執行 這個代碼泥
解決方案 三:
東西也給家人們找好了,學吧,人懶不想總結太多了
?【Python】使用Windows任務計劃程序定時運行Python腳本!-CSDN博客
?之后 要進行修改時間的可以看這個
?win10下設置定時任務,間隔每/分鐘 - Acezhang - 博客園 (cnblogs.com)
?到最后有一點 小問題 :
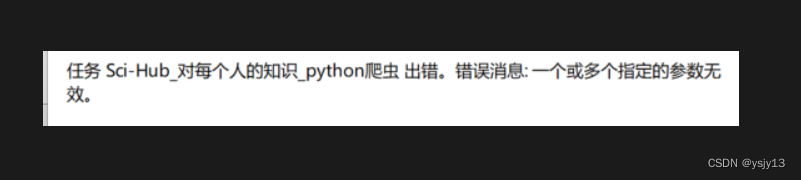
原因應該就是上面圖片的沒填? 問題不大。?windows解決任務計劃程序出錯一個或多個指定的參數無效_計劃任務一個或多個指定的參數無效-CSDN博客
?其中 管理員的單詞懂吧選那個
人麻了? 要定時還是有很多問題的
你的bat(腳本) 要運得了才可以? 點擊bat 如果閃退 就是不成功??
家人們 內容有點多 更多是自己去看別人的內容,我用了一天半完成的 不急慢慢來?
??居然沒有打賞功能 可憐我寫了半天?

)







服務(二))






--定點數的舍入模式(6)向0取整fix)


