一、故障起因
起因是用戶反饋系統很卡,我登錄普羅米修斯一看,發現docker部署得集群下的一個java應用服務器cpu爆了,直接沖到了1000%以上了,接著就是各種接口超時報警等,趕緊打開對應的服務器查看進程情況,這會使用jstack和top命令定位哪個線程占用的cpu比較大,定位代碼問題。
二、常見的cpu100%以上異常的情況
程序中存在內存泄漏或者內存溢出,導致 JVM 不斷進行垃圾回收;
代碼中調用的某些資源造成的死鎖或者是代碼的死循環導致的cpu超頻計算,或者長時間占用cpu的操作,像一些遞歸的使用、循環操作等等,或者一些特別復雜的正則匹配引起;
程序中存在大量的 IO 操作;
程序中存在大量的數據庫操作,導致數據庫連接池的耗盡和數據庫負載過高。
三、排查方法
排查cpu過高的java導出日志,交給開發排查問題
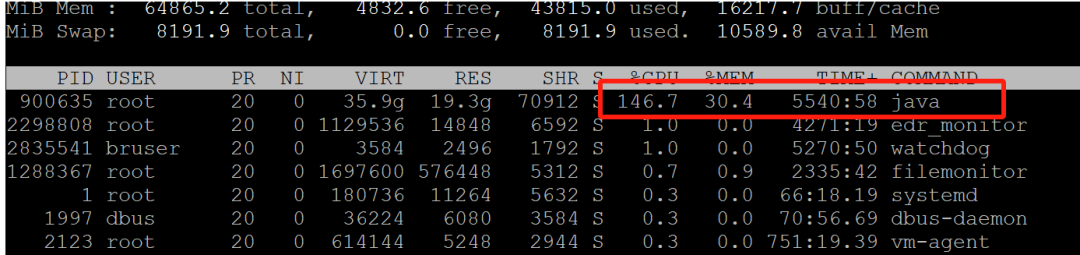
1.top查看cpu使用率比較高的線程
top打印
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
900635 root 20 0 36.1g 19.4g 70976 S 153.0 30.7 5619:07 java

模型的保存與加載)





![[數據庫原理]事務](http://pic.xiahunao.cn/[數據庫原理]事務)


)








