
論文鏈接:https://arxiv.org/pdf/2509.01085
亮點直擊
BSA——一種可訓練的雙向動態稀疏注意力框架,該框架首次在視頻擴散訓練中對全注意力機制中的查詢(Query)及鍵值對(Key-Value)進行正交稀疏化處理以加速訓練過程。
為查詢塊和鍵值塊設計了不同的動態稀疏化策略,有效捕捉訓練過程中的注意力變化特性,實現超越固定模式的自適應標記選擇。
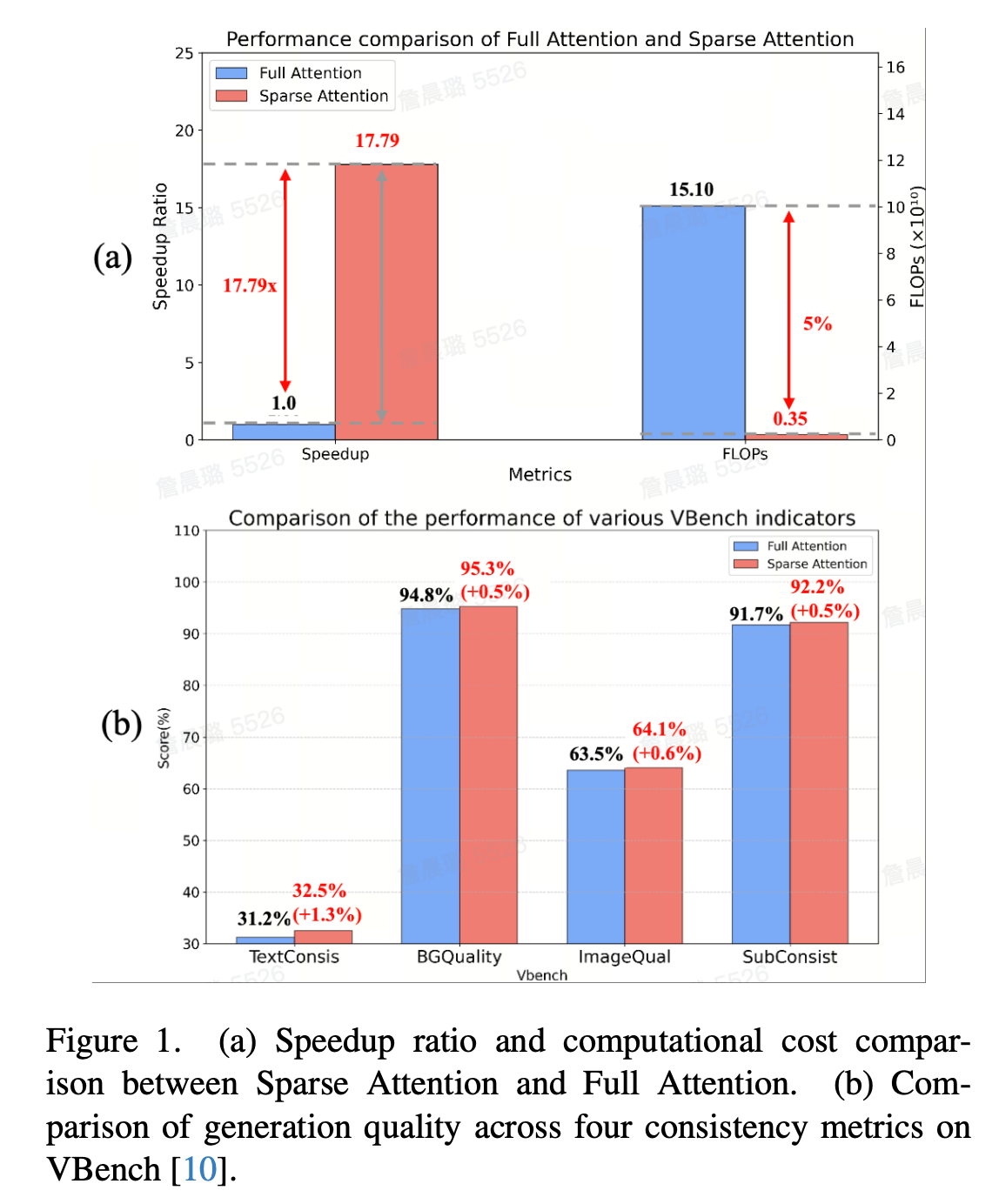
在Wan2.1-1.3B數據集表明:BSA可實現最高20倍的浮點運算量降低、17.7倍的訓練加速以及6倍的推理加速,同時保持或超越全注意力機制的生成質量。
結果
由于 DiT 模型采用Full Attention機制,計算量隨序列長度增加而呈二次方增長,計算復雜度為)(其中 L 為 token 序列長度)。這直接導致在訓練與推理過程中的計算成本急劇攀升,嚴重制約了 DiT 模型在高分辨率長視頻生成任務中的實用性與效率,因此亟待針對性的優化方案來解決這一核心限制。為了解決上述問題,提出了一種可訓練的雙向動態稀疏注意力加速框架,首次對3D Full Attention中的Query和Key-Value 對分別進行動態稀疏化計算,同時設計了不同的動態稀疏化策略來提升訓練、推理效率。
雙向Query-Key稀疏注意力:對于Query稀疏,通過對比token之間語義相似度來高效的選取Query內部關鍵的query token,動態優化query的稀疏性。對于Key-Value稀疏,只計算選取的關鍵KVBlock中的token。
動態稀疏注意力訓練策略:分別針對KV block和Query block的動態稀疏性均設計了不同的動態策略。對于KV block稀疏,對不同的Query動態選擇對應最關鍵的KV token,根據每一個訓練step輸入的block之間的注意力分數,動態選擇關鍵 token 直至累積分數達到目標閾值p。 對于Query動態稀疏策略,分別針對時間、空間動態稀疏來選擇不同的block稀疏度。
大量實驗表明,該方法顯著加速了視頻擴散模型在不同長序列上的端到端訓練速度,獲得了最大20倍的FLOPs減少和17.7倍的注意力訓練加速,同時獲得了與Full Attention相當甚至更好的生成質量,除此之外,也可以在不降低推理質量的情況下加速推理速度,在H100上將端到端的推理延遲從31s降低到5.2s ( 6.2x )。
問題與發現
解決的問題
視頻 DiT 在訓練全分辨率、長序列數據時,大部分計算資源都耗費在注意力上,它可以消耗高達95 %的處理時間,且訓練后的 DiT 在推理階段仍速度緩慢,這使得注意力計算成為視頻 DiT 縮放的首要瓶頸。為了改善這一狀況,近期很多工作提出了多種稀疏注意力機制。它們的核心思路是讓每個查詢Query僅與KV鍵值對的部分子集進行交互,以此來降低計算的復雜程度。它們只關注KV鍵值對中的部分冗余子集,卻忽略了Query查詢序列中同樣存在大量的冗余信息,這會導致大量的重復計算。除此之外,絕大多數稀疏注意力機制大多被設計成無需訓練的形式。這些未經過訓練的方法通過直接截取部分KV子集來進行注意力計算,在實際訓練中往往只能得出欠佳的結果。
關鍵發現
發現
為了設計高效的注意力訓練框架,對當前Full Attention的訓練延遲進行了特異性分析,并揭示了以下兩個關鍵發現:
(1)Full Attention中的查詢Query和Key-Value序列均具有較大稀疏性而導致過多的計算浪費。
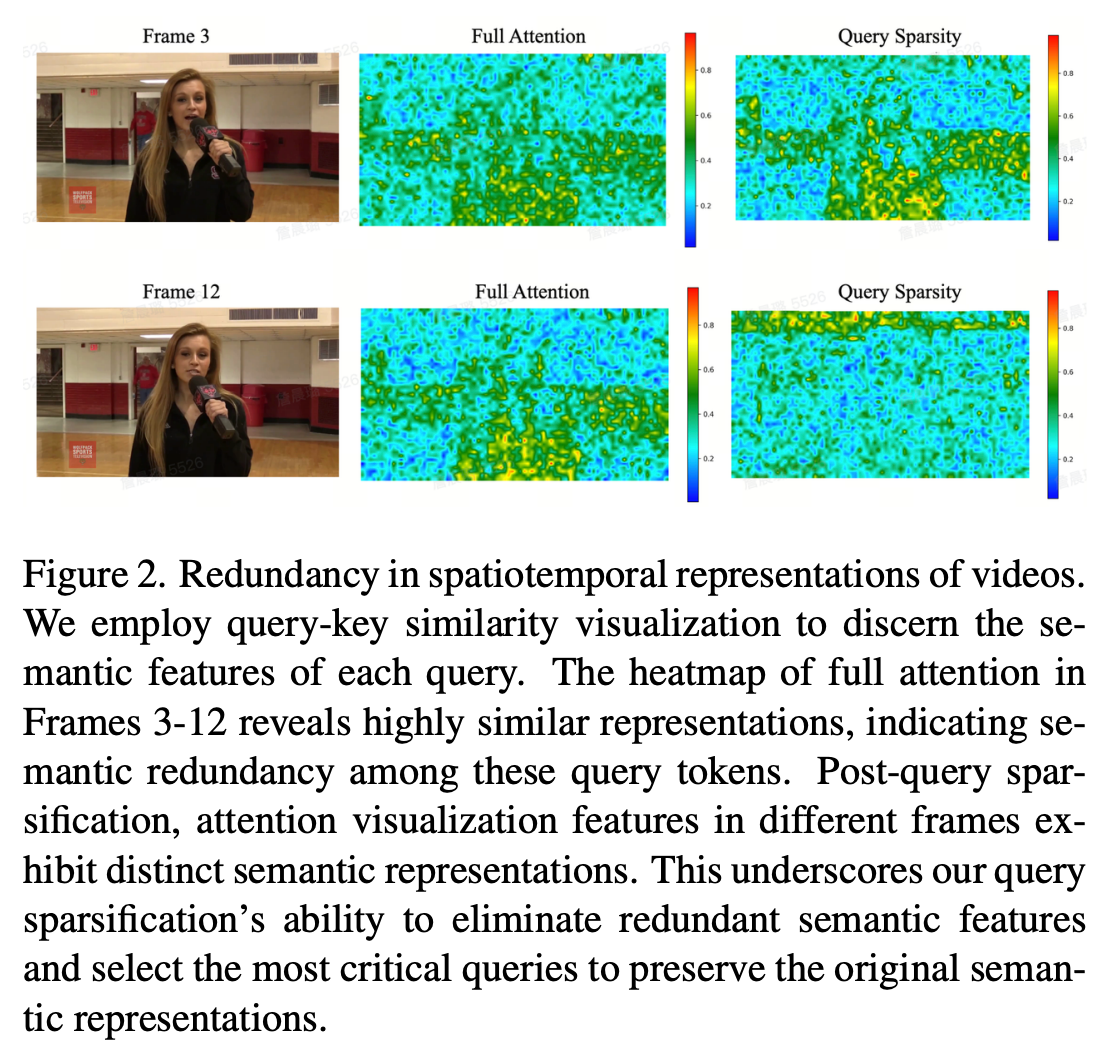
對于查詢Query來說,視頻幀之間及幀內 token 存在大量重復語義(如靜態背景、連續動作的相似幀)導致 token 數龐大。如圖2所示,Frame3和Frame12中的Full Attention中的query熱力圖呈現高度相似的表法,說明這些token提供相同的語義特征,對所有Query的序列token進行注意力查詢計算會導致嚴重的計算浪費。
對于KV鍵值對來說,token序列計算得到的注意力分數具有長尾效應,只有部分關鍵KV子集于每個查詢Query具有強相關性,這一小部分計算顯著影響最終的輸出。因此,只需要計算小部分關鍵令牌就可以在不影響生成質量的情況下顯著降低的計算成本。
(2)DiT中的注意力計算呈現動態稀疏性。動態稀疏性分別體現在Query和KV的時間、空間動態稀疏性。
空間動態稀疏:不同的 Query 所對應的關鍵 KV 對子集本應是動態變化的,如果采用固定的稀疏化策略,則無法適應時空的動態稀疏,過選會造成計算冗余,漏選則會產生精度損失,因此需要設計動態稀疏策略來適配DiT中本身的動態稀疏性。
時間動態稀疏:隨著訓練training step 的推進,稀疏度是隨時間變化的,前期注意力會獲取主要的全局信息,而后期注意力查詢則只關注于更高語義層次的局部特征,稀疏度隨著訓練逐漸增大。
為了解決上述挑戰,提出了一種可訓練的雙向動態稀疏注意力(BSA,Bidirectional Sparse Attention for Faster Video Diffusion Training)加速框架,首次對3D Full Attention中的Query和Key-Value 對分別進行動態稀疏化,同時設計了不同的動態稀疏化策略來提升訓練、推理效率。
方法
1. Sparse Attention 回顧
現代視頻擴散 Transformer(DiT)使用 3D Full Attention來捕捉整個視頻體積內的依賴關系,在Full Attention中,Q、K、V中的所有序列令牌都參與交互和計算。而Sparse Attention通過從KV對中選擇關鍵子集和來減少總體計算量,旨在提高效率。注意力輸出O計算如下:
2. 方法架構
2.1 整體框架
主圖
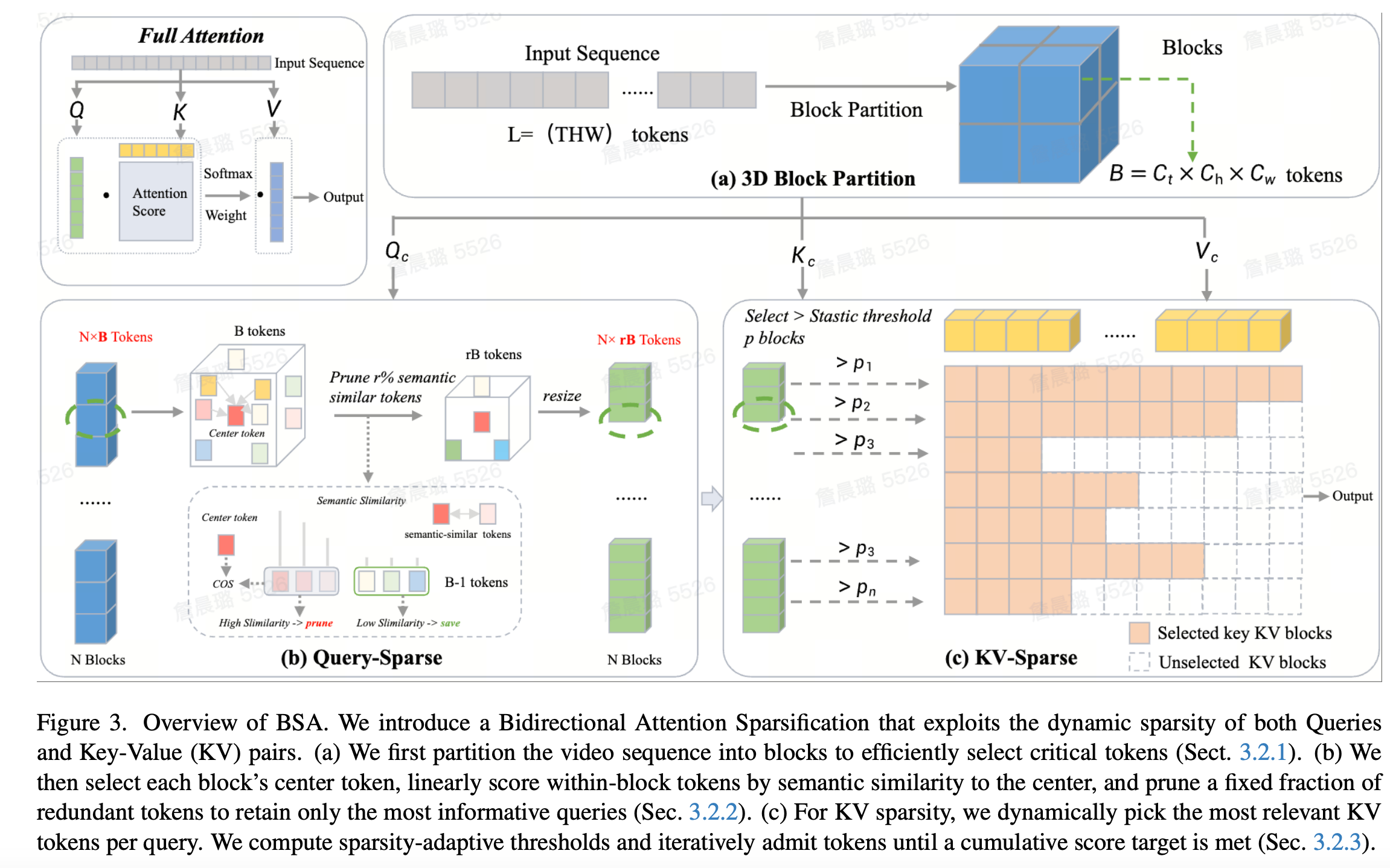
如圖3 所示,方法框架主要分成三部分: (a)為注意力序列立方體劃分,將視頻 latent 劃分為時空立方體(Block),通過均值池化生成塊級表示來有效地篩選關鍵信息。 (b)提出的Query-Sparse方法,分別基于Query的語義冗余特征來高效的選取最優query token,并根據時間空間動態稀疏性設計動態稀疏策略。 (c)提出的動態KV-sparse方法,對不同的Q選擇對應最關鍵的KV token,動態選擇關鍵 token 直至累積分數達到目標閾值p,無需預設固定稀疏模式,適應不同輸入內容的稀疏需求。
2.2 立方體劃分
給定一個形狀為()的視頻,為了可以高效地以較低的計算成本來選擇關鍵token子集,采用將多個token組合成一個較大的立方體block的形式來進行初步的選擇。對于輸入查詢 、鍵、值 ,將視頻 latent()劃分為大小為的立方體,每個立方體對應 GPU 上的一個塊(block),塊大小。然后對每個立方體的 tokens 進行均值池化,得到塊級查詢 、鍵、值 。視頻中的每個立方體映射為GPU SM上的單個瓦片來協同設計稀疏注意力算法及其核心實現。
3. Query-Sparse
視頻數據本身具有多幀的時間相關性和每幀幀內的空間相關性,因此存在時空信息冗余。實驗測試顯示在視頻擴散模型中,約 4% 的空間鄰近 token 貢獻了 80% 的注意力分數,可以去除冗余token的情況下實現無損性能。因此考慮到每個query查詢序列中也會存在很大的信息冗余(如靜態背景、連續動作的相似幀),主要的語義(如物體類別、動作趨勢)由少量關鍵 token 主導,丟棄相似語義的冗余 token 不會破壞整體語義結構。
基于此發現,提出了基于特征冗余的query token稀疏化方法。詳細地說,對于查詢Query設查詢分成 個塊 ,塊 的token集合為 ,對應中心token為。 發現基于分塊后的同一block內的 token(如空間鄰近的像素塊)通常包含很多語義高度相似的特征,中心 token 在時間空間維度上可作為該區域的語義代表,可以計算塊內其他token與中心語義代表token之間的特征相似度,使用余弦相似度或點積衡量中心 token 與周圍 token 的語義相似性,避免平均池化的 “一刀切” 信息損失,對于每個block之內的token進行局部時空窗口內計算相似性,然后對每個block內保留部分不冗余的tokens,這些token便可以貢獻關鍵的注意力分數,而去除的冗余token由于所代表的特征信息與其他token重復,因此即便去除了也可以實現無損性能,不會破壞語義結構。對每個塊分別按剪枝率 保留部分token,最后將所有block內的保留下來的關鍵token進行拼接,構成新的無冗余的查詢Query ,具體生成方式如下所示:
其中, 表示在塊b 內根據從大到小排序后的排名,是塊b中的 token 數量,是保留比例。
4. KV-Sparse
基于立方體劃分后的塊級表示,可以讓每個查詢Query僅與KV鍵值對的部分子集進行交互,以此來大量降低計算的復雜程度。但是如何確定每個查詢Query對應的關鍵KV鍵值對子集是一個非常重要的問題。在實驗中發現,稀疏性在注意力塊之間和同一塊內之間存在顯著差異,并且對于每一個query查詢對應的關鍵kv對也是動態變化的,不應該采用固定的top-k選擇方式來統一固定對每個query進行關鍵kv的選擇。
因此提出了基于統計閾值的動態KV-Sparse稀疏方法,分別針對每個Query選取動態的關鍵KV對,并通過輸入注意力分數的統計特性來計算得到動態的稀疏閾值來選取關鍵KV對,無需預設固定稀疏模式,適應不同輸入內容的稀疏需求。
首先先對每個立方體的 tokens 進行均值池化,得到塊級查詢 、鍵、值 ,然后進行塊選擇Key Block Select ,計算塊間注意力得分 ,通過動態統計閾值 選擇關鍵塊(保留高注意力值的塊)。然后再將稀疏化的每個查詢Query block 分別與選取到的關鍵KV對僅在關鍵塊內進行 token 級注意力計算。動態稀疏分別體現在兩方面:
獲取基于統計的動態閾值p。對于每一次計算得到的塊間注意力得分 ,可以通過計算query與KV對每次得到的注意力得分 中所有分數的均值和標準差,計算出一個可以選出k個關鍵樣本的動態閾值p,也就是說根據輸入注意力分數的統計特征去選出根據統計分布的關鍵KV對,而不是人為的截取對應關鍵kV對。
通過動態閾值選取不同Query的關鍵KV對。針對選取的關鍵block(假設K個),針對每一個query block分別和KV做計算,并且分別根據超過統計的動態閾值來進行動態索引選擇:對每個query block i,選擇最小索引集,確保所選注意力分數之和不低于閾值。
最終的稀疏注意力:設稀疏化后的查詢矩陣為,(其中為稀疏化后的查詢 token 數量),篩選出的關鍵鍵矩陣為 、關鍵值矩陣為 。其中對應所有 query block 選出的關鍵 KV 對鍵集合;對應相應的值集合;稀疏掩碼矩陣為 ,稀疏掩碼矩陣,保證只計算選中選中的 query 與 KV 交互對應的注意力。稀疏注意力輸出可以表示為:
其中,為稀疏化后的注意力分數矩陣(維度 , 為關鍵 KV token 數量),是縮放因子,為最終的稀疏注意力輸出,維度和輸入保持一致。
實驗
基于Wan2.1-1.3B模型架構進行T2V任務的模型訓練,重新初始化進行training from scatch,所有的模型訓練均訓練至完全收斂,以保證公平比較。
Loss比較
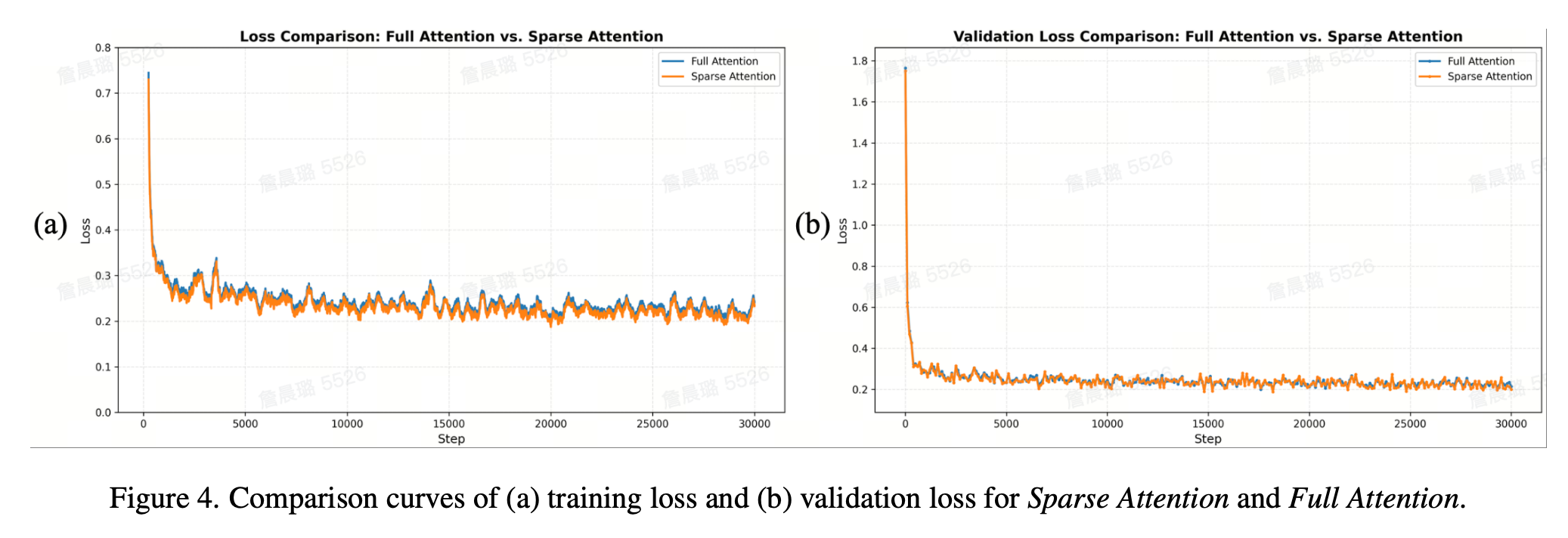
如圖4所示,Sparse Attention與Full Attention基線的預訓練損失曲線相重合,均表現出穩定且平滑的下降趨勢,并且大部分優于Full Attention 模型。
loss
Efficiency和Quality比較
如表1 所示,在2個不同的分辨率上對Sparse Attention 和Full Attention 進行from strach訓練,分別為61 × 448 × 832,23K令牌)的原始分辨率,和擴展的更長token長度( 157x768x1280 , 153K令牌)。進行Sparse Attention和Full Attention在效率和生成質量上的對比。
在原始序列長度(23k tokens)下,Sparse Attention比Full Attention的獲得了12.85倍的加速比,并且實現了93%的稀疏度,FLOPs為Full Attention的7%。除此之外,在加速的同時,BSA體現出了強大的生成質量,它在Vbench的4個一致性測量指標上優于Full Attention,尤其是在背景一致性上。這說明了Sparse Attention 可以在較短序列長度上也可以實現較大的加速訓練,同時也可以達到更好的生成效果。
在更長的序列長度(153k tokens)下,Sparse Attention在加速比和生成質量的優勢上更加明顯。具體來說,BSA與Full Attention模型訓練相比,獲得了17.79倍的加速比,稀疏度可以達到95%,FLOPs計算也可以達到Full Attention的5%。并且它在生成質量上相對于Full Attention的提升幅度也更大,尤其是文本一致性和背景一致性。這種改進主要是源于對于更長的序列長度,那么模型訓練時Attention計算的占比也更多,由此可以達到的稀疏度和加速比都會隨之增大。

Training on Longer Sequences 在不同序列長度上的對比
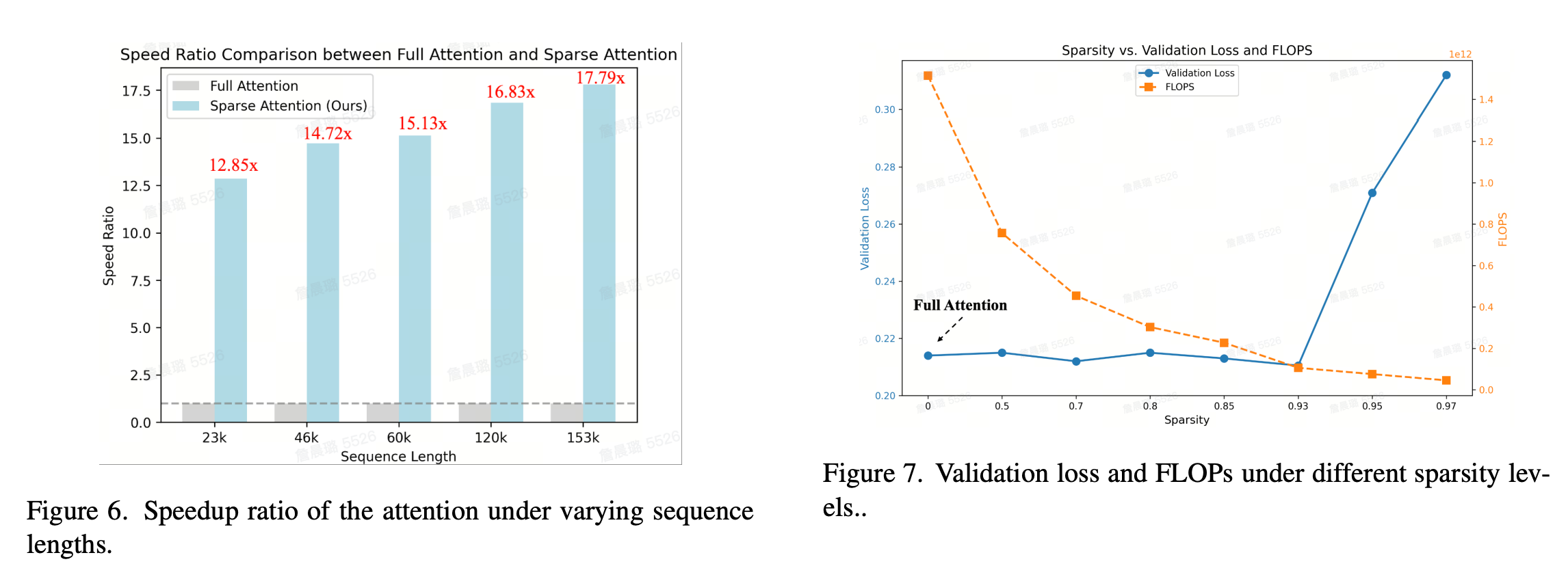
為了評估BSA在不同序列長度上的訓練加速效果,分別在5種不同序列長度上進行訓練加速比測試。所有的模型訓練設置均保持一致來保證訓練的公平性,結果如圖6所示。詳細地說,分別測試了23k、44k、59k、117k、153k序列長度,加速比隨著序列長度的增加逐漸增大。當序列長度為最小的23k的時候,加速比也可以達到12.85x,當序列長度增加為其2倍的44k的時候,加速比可以增加至14.72x。對于當前測試的最長的序列長度153k時,最大加速比可以達到17.79倍,由此說明對于更長的序列長度,Sparse Attention可以更有效地縮短模型訓練的時間。
speed
Sparse Adaptation 稀疏度討論
為了探究稀疏度與訓練Loss和計算量之間的關系,還測試了不同稀疏度下的驗證損失Validation Loss和計算量FLOPs的實驗,如圖7所示。模型的稀疏度與Query-sparse中的保留token比例r和KV-sparse中的動態閾值p(動態閾值通過每一次計算得到的注意力分數來選取的k個關鍵值得到)相關,并且也存在trade-off的權衡。當sparsity為0時,代表的是Full Attention的訓練結果。從圖7中可以發現,當Sparse Attention的稀疏度在0-0.93時,validation loss與Full Attention的Validation loss幾乎沒有區別,并且FLOPs隨著稀疏度的增加而下降。但是當Sparse Attention的稀疏度超過0.95,雖然計算量FLOPs仍在減少,但是validation loss卻變得很大,這說明在這個稀疏度下無法實現無損的生成質量。而當稀疏度為0.93附近時,是一個最優的結果,即既可以實現無損甚至更好的生成效果,還可以減少13x的計算量FLOPs。
Qualitative Results 定性實驗結果
如圖5所示,展示了4個分別在不同序列長度上的生成視頻不同幀下的T2V生成結果,分別包括不同幀數下較低分辨率(448??832)和高分辨率(782??1280)。如圖中4個不同的例子展示所示,所提出的Sparse Attention生成的視頻與Full attention相比可以達到無損的效果。

vis
Comparison with Other Sparse Attentions 與其他SparseAttention方法對比
sota
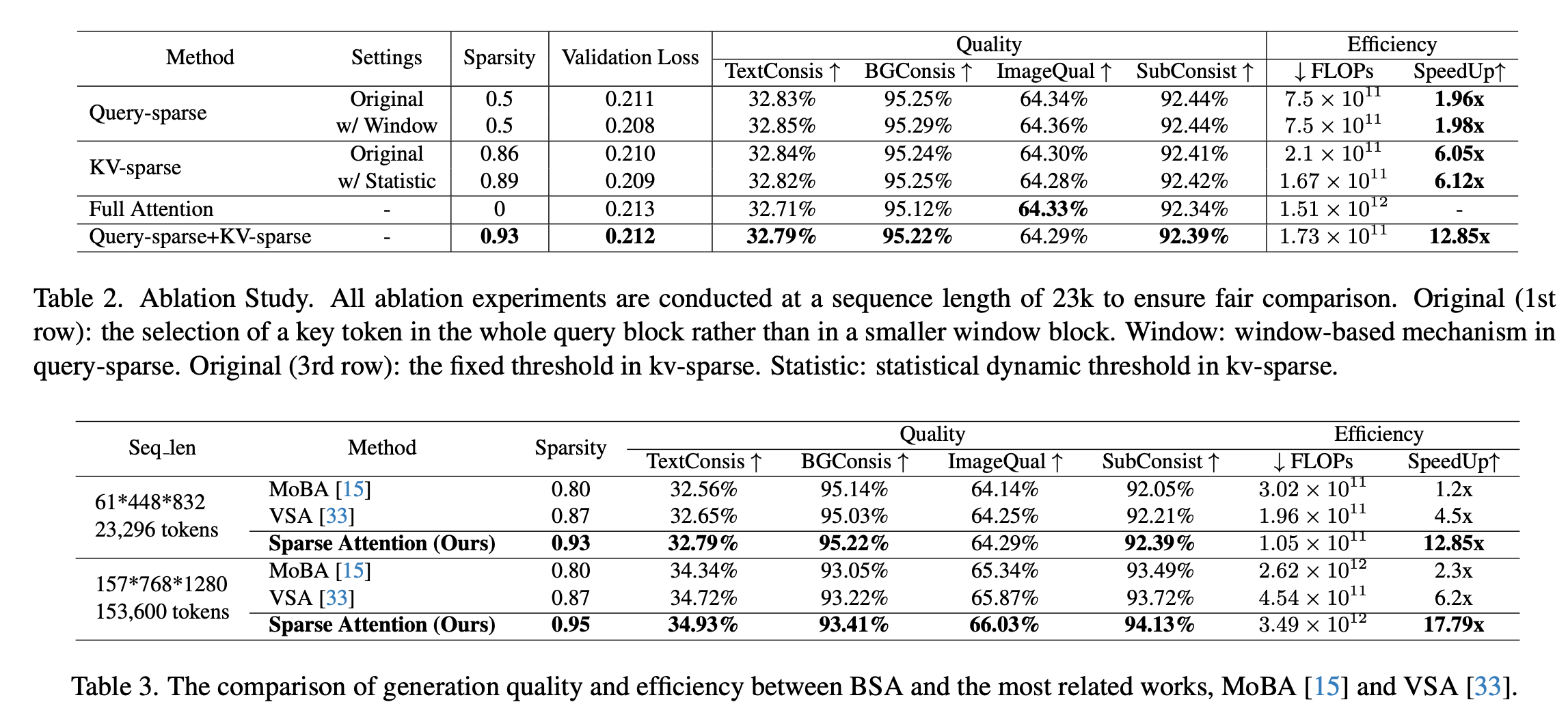
如表2所示,與最相關的基于訓練的稀疏注意方法(如MoBA和VSA)進行了詳細的比較。BSA在加速比方面比MoBA和VSA都有明顯的優勢,對于23k序列長度,可以達到12.85x的attention加速,但是目前training-based最優的VSA僅可以實現4.5x的attention加速比。并且與這些稀疏注意力方法相比,也提供了更好的生成質量。
Ablation Study
為了探究Query-sparse和KV-sparse對加速效果和生成質量的影響,分別對其進行了詳盡的消融實驗,如表3所示。采取Full Attention為基線在表2的第5行,總體的方法展示在最后一行,并且分別在第1-4行來計算Query-sparse及其window窗口、KV-sparse及其統計動態閾值對加速效果和生成質量的影響。
Query-Sparse
Original Query-sparse:在沒有進行KV-sparse的基礎上,通過表2的第1行可以發現,當保持prune rate為0.5時,可以達到無損的驗證結果,在effciency方面,并且可以實現1.96x的加速比,減少50%的計算量。除此之外,在Vbench上的測試結果也都優于Full Attention。
Query-sparse with window size selection:還測試了采用window size來根據多個center token來選取有效token的方法。這說明了with window block selection可以更好地選取包含有效語義的tokens,而不會被冗余token干擾。
KV-Sparse
Original KV-sparse:在沒有Query-sparse的基礎上,基于閾值的KV-sparse可以實現0.86的稀疏度和6.05x倍的訓練加速,還節省了將近8.6倍的計算量。除此之外,總體生成效果與Full Attention相比還是可以達到無損的結果。
KV-sparse with stastic dynamic threshold:還測試了加上動態統計閾值的KV-sparse。從表2中的結果可以驗證,這種基于統計信息的動態閾值可以在相同validation loss的基礎上實現更高的稀疏度,并且在生成質量相當的情況下實現更高的訓練加速比和更少的計算量FLOPs。
Query-Sparse + KV-Sparse
如表2的最后一行顯示,結合了Query-Sparse 和KV-Sparse的方法在相當的validation loss和生成質量的情況下實現了最大的稀疏度0.93和最大的加速比12.85倍。這得益于Query-Sparse 和KV-Sparse是可以正交實現的,兩者達到的稀疏效果可以進行疊加,達到最優的加速效果,并且不會損害生成質量,驗證了稀疏注意力的有效性。并且需要強調的是,稀疏方法所增加的計算量很小,幾乎可以忽略不計,這也顯示了Sparse Attention方法的高效性。
結論
視頻擴散Transformer(DiT)模型在生成質量方面表現優異,但在生成高分辨率長視頻時遇到了主要的計算瓶頸。Full Attention的二次復雜度會增加訓練/推理成本。 為了克服這一限制,提出了一個雙向稀疏注意(BSA)框架,用于更快的視頻DiT訓練,這是第一個提出雙向Query-KV動態稀疏化的框架,從而提高了訓練和推理效率。完全關注效率低下源于兩個關鍵挑戰:由于查詢和鍵值對固有的稀疏性而導致的過度計算,以及由于固定的稀疏模式無法利用DiT的動態關注而導致的冗余計算 。BSA通過兩個關鍵組件來解決這些問題,查詢稀疏性通過語義相似度和動態時空訓練策略選擇信息量最大的查詢令牌來優化,而KV稀疏性通過計算統計動態閾值并僅保留關鍵KV塊進行計算來實現。 大量實驗表明,BSA顯著加速了長序列的DiT訓練,將FLOPs降低了20倍,實現了17.79倍的注意力訓練速度,同時保持甚至超過了完Full Attention的生成質量。
參考文獻
[1] Bidirectional Sparse Attention for Faster Video Diffusion Training





附源碼)


:Java Stream 求兩個List的元素交集)




)





