引言
看到一則報道[1],重組后的Meta實驗室在9月1號發布了一篇關于提升RAG解碼效率的論文,提出的思路有點啟發作用,于是把原文下載下來仔細看下。
論文標題:REFRAG: Rethinking RAG based Decoding
論文地址:https://arxiv.org/pdf/2509.01092
1. 動機
通過將外部知識檢索結果與用戶問題拼接后輸入模型,檢索增強生成(RAG)已成為提升模型回答質量的重要途徑。
然而,這種機制的代價極其高昂:拼接的上下文通常包含數千甚至上萬 Token,其中只有少數段落與問題密切相關,其余則是冗余信息。對于解碼器而言,這意味著需要維護線性增長的 KV Cache,同時在預填充階段進行近似二次復雜度的注意力計算,導致**首 Token 延遲(TTFT)**大幅增加,吞吐量下降。
現有的長上下文優化方法大多從稀疏注意力或高效緩存角度出發,但這些方案往往面向一般長文本任務,而未能利用 RAG 特有的“塊對塊低相關性”結構性特征。于是,REFRAG 的提出正是為了填補這一空白,它將 RAG 的解碼過程重新設計為一個壓縮、感知與擴展的動態過程,從而顯著降低延遲與計算成本。
2. 框架
REFRAG 的核心思路是將檢索得到的長上下文從 Token 級別提升到 Chunk 級別表示。
具檢索文檔會被切分為固定大小的塊,每個塊通過輕量級編碼器(如 RoBERTa)生成一個壓縮后的向量表示,再通過投影層映射到解碼器可理解的 Token 空間。
這樣,原本需要處理數千 Token 的解碼器輸入被壓縮為幾百個 Chunk Embedding,輸入規模大幅縮短,注意力計算也隨之減少。
并且,REFRAG 并未犧牲自回歸生成的特性,Chunk Embedding 可以插入在任意位置,與原始 Token 并存,從而保持方法的普適性。
為了避免“一刀切”壓縮帶來的信息損失,REFRAG 還引入了一個輕量的強化學習策略,動態決定哪些 Chunk 必須保留原文 Token,哪些可以以壓縮表示替代。這一機制使得模型能夠在有限算力預算下,把計算資源分配到最關鍵的上下文部分。
整體流程如下圖所示。

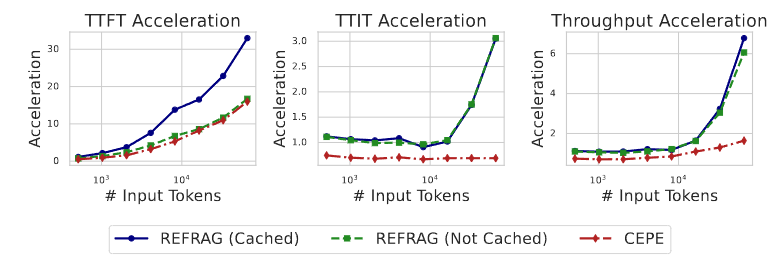
下圖展示了REFRAG和其它方法在以下三個指標上的加速效果:
- TTFT (Time to First Token): 首詞元生成延遲,指的是模型接收到輸入指令后,生成并輸出第一個詞元(token,可以理解為一個單詞或一個漢字)所花費的時間。這個指標衡量的是模型的“反應速度”。
- TTIT (Time to Iterative Token): 迭代詞元生成時間,指的是在生成第一個詞元之后,生成每一個后續詞元所花費的時間。這個指標衡量的是模型生成連續文本的“輸出速度”。
- Throughput: 吞吐量,指的是單位時間內(通常是每秒)模型能夠生成的總詞元數量。這個指標是衡量模型整體處理效率和性能的關鍵指標,綜合了啟動延遲和生成速度。
3. 具體方法
在 REFRAG 的方法論中,核心挑戰是:如何讓解碼器能夠“理解”由編碼器生成的塊級壓縮表示,并在必要時動態選擇哪些塊需要恢復為原始 Token,從而保證生成質量。
為此,作者提出了一套 分階段訓練流程,具體流程如下:
3.1 編碼器與解碼器對齊:持續預訓練(CPT)
REFRAG 的關鍵創新在于用 Chunk Embedding 替代原始 Token 嵌入。然而,解碼器原本是習慣接收逐 Token 的序列表示,如果直接將壓縮后的向量送入解碼器,模型很難理解其中的語義。因此,需要一個 對齊過程。
具體做法是設計 下段預測(Next Paragraph Prediction)
任務:給定輸入 Token 的前半部分 x1:sx_{1:s}x1:s?,由編碼器生成 Chunk Embedding,輔助解碼器預測接下來的 Token xs+1:s+ox_{s+1:s+o}xs+1:s+o?。
通過這種方式,解碼器逐漸學會利用壓縮表示來完成預測,形成對 Chunk Embedding 的依賴關系。這一步訓練被稱為 持續預訓練(CPT),是連接編碼器和解碼器的橋梁。
3.2 重建任務:減少信息損失
僅僅通過下段預測進行對齊仍然不足,因為 Chunk Embedding 本身會丟失部分細節。為此,作者在 CPT 前額外引入了一個 重建任務(Reconstruction Task):
- 輸入:原始上下文 Token 塊 x1:sx_{1:s}x1:s?
- 編碼器:壓縮為向量表示
- 解碼器:嘗試從壓縮向量重建原始 Token 序列
在該任務中,解碼器參數被凍結,只訓練編碼器和投影層。這相當于讓編碼器學會“盡可能無損地壓縮”,而投影層學會“把向量翻譯回 Token 空間”。經過這一階段,編碼器與投影層能生成較為保真的壓縮表示,解碼器也能正確解讀,從而為后續 CPT 奠定基礎。
3.3 課程學習:緩解訓練難度
當塊大小 kkk 增大時,壓縮任務變得極其困難,因為需要用一個定長向量表示 VkV^kVk 種 Token 組合(VVV 是詞表大小)。直接訓練模型去重建大塊信息容易陷入困境。為解決這個優化難題,REFRAG 引入 課程學習策略:
- 從 單塊重建 開始(例如只壓縮 x1:kx_{1:k}x1:k? 并重建它)。
- 隨著訓練進行,逐步增加塊數(重建 2k,3k,...2k, 3k, ...2k,3k,... 的序列)。
- 在數據采樣上,先以簡單任務為主,逐步增加復雜任務的比例。
這種漸進式訓練讓模型逐步掌握壓縮表示的規律,而不會在一開始就陷入高維空間的難題。
3.4 選擇性壓縮:強化學習策略
盡管壓縮能帶來效率提升,但并非所有上下文塊都適合壓縮。例如,一個包含關鍵定義或數值的段落,如果被過度壓縮,可能嚴重影響模型輸出的正確性。因此,REFRAG 引入了一個 強化學習(RL)策略網絡,用來在推理時動態決定:
- 哪些塊保留原始 Token(高保真但開銷大);
- 哪些塊替換為 Chunk Embedding(低開銷但近似)。
訓練方式如下:
- 獎勵信號:使用預測困惑度(Perplexity)作為負獎勵,即如果某塊被壓縮后困惑度急劇上升,說明信息損失過大,應保留原文。
- 策略機制:RL 策略在序列層面逐步做決策,以保證解碼器的自回歸特性不被破壞。
- 輸出形式:生成一個壓縮掩碼(mask),指導哪些塊用向量替代,哪些保留 Token。
與啟發式規則(如“壓縮低困惑度塊”)相比,RL 策略在不同任務和不同上下文規模下都能取得更優的平衡,證明了其靈活性和魯棒性。
3.5 微調階段(SFT)
完成 CPT 和 RL 策略學習后,REFRAG 還需要進一步在具體下游任務(如問答、對話、摘要)上進行 監督微調(SFT)。這一階段的目標是讓模型在實際應用中學會如何最優地結合壓縮塊與原始塊,從而兼顧速度和準確性。
4. 實驗
4.1 實驗設置與基線
作者主要在 LLaMA-2-7B 模型上進行實驗,并將其與幾種典型的長上下文優化方法作對比,包括:
- LLaMA-Full Context:原始 LLaMA 模型,完整上下文輸入。
- LLaMA-32K:擴展上下文窗口到 32K Token 的版本。
- LLaMA-No Context:不輸入上下文,只依賴提示。
- LLaMA256:只保留最近 256 Token 上下文。
- REPLUG:優化檢索器的方法。
- CEPE:基于 KV Cache 的壓縮擴展方法。
- REFRAG8 / REFRAG16 / REFRAG32:分別對應壓縮率為 8、16、32 的 REFRAG 模型。
訓練數據采用 SlimPajama 子集(包括 Books、ArXiv 等文檔),用于持續預訓練;驗證與測試數據包括 PG19(長篇小說)、ProofPile(數學推理)等,用于檢驗長文本理解和生成能力。
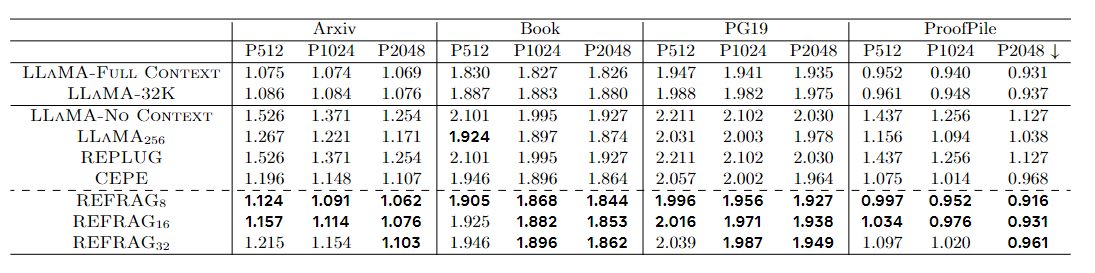
這張表的評價指標是困惑度(Perplexity),是衡量語言模型預測下一個 token 的不確定性:
- PPL 越小,說明模型越“不困惑”,模型能更準確地預測下一個 token,說明語言理解/生成能力更強。
- PPL 越大,說明模型越“困惑”,模型給正確詞分配的概率很低,相當于“沒猜對”,性能差。
4.2 推理效率與加速效果
REFRAG 的最大亮點在于顯著降低了 首 Token 延遲(TTFT)。
- 在 壓縮率 32 的設定下,REFRAG 在 LLaMA-2-7B 上實現了 30.85× 的 TTFT 加速,吞吐率也提升了數量級。
- 相比之下,CEPE 的加速倍數僅為 3.75×,說明 REFRAG 在利用結構性稀疏性方面更高效。
- 更重要的是,這種大幅提速并未導致困惑度顯著上升,說明壓縮表示并未破壞模型的語義理解能力。
此外,REFRAG 的推理開銷主要集中在預填充階段,一旦完成壓縮處理,后續 Token 的生成速度與原始 LLaMA 基本一致,這保證了系統在實際應用中的低延遲體驗。
4.3 消融實驗
作者進一步進行了消融實驗,以驗證各個組件的貢獻:
- 無重建任務:困惑度顯著上升,說明重建訓練對于壓縮表示的保真性至關重要。
- 無課程學習:模型難以收斂,訓練過程不穩定。
- 無強化學習策略:準確率下降,說明啟發式壓縮無法適應不同任務和上下文復雜度。
總結
本文提出方法優勢在于它是非侵入式的,即沒有對下游的語言模型進行改造,理論可適配現有的語言模型,
然而,這項工作實際上只在7B參數級規模的模型上進行實驗,更大參數量的語言模型的效果未可知。
并且,此方法需要訓練過程是比較多的,按照文章給出的實驗環境,在8個節點上進行訓練(每個節點8張H100),總共64張H100,也只有meta這樣的實驗室有這種實驗資源。
最后,本文暫未開源,一些方法細節尚未可知。
總之,整體是一個不錯的想法,在提升模型響應速度和提升上下文窗口長度上,是一個新的思路。
參考
[1] Meta超級智能實驗室首篇論文:重新定義RAG: https://www.qbitai.com/2025/09/329342.html







附源碼)


:Java Stream 求兩個List的元素交集)




)



