“Giga”一詞源于“gigantic”,互聯網上具有海量音頻資源,但語音質量良莠不齊,高質量音頻文本對數據十分稀缺且標注成本高昂,特別是在小語種領域。GigaSpeech 是一個非常成功的英文開源數據集,以 YouTube 和 Podcast 為音頻來源,提供了上萬小時的高質量文本標注語音數據集,獲得了廣泛關注和應用。針對多語言領域仍存在的語音識別性能較差、可用高質量標注數據缺乏等問題,我們提出了利用 in-the-wild 無標注音頻,構建高質量大規模語音識別數據集的新范式,制作出面向真實場景的大規模、多領域、多語言的語音識別數據集 GigaSpeech 2。基于Gigaspeech 2 數據集訓練的語音識別模型在三個東南亞語種(泰語、印尼語、越南語)上達到了媲美商業語音識別服務的性能。我們懷揣著技術應當普惠大眾的理念,致力于開源高質量語音識別數據集和模型,促進多語言文化溝通。

1. 概述
上海交通大學跨媒體語言智能實驗室(X-LANCE)、SpeechColab、香港中文大學、清華大學語音與音頻技術實驗室(SATLab)、鵬城實驗室、海天瑞聲(Dataocean AI)、思必馳(AISpeech)、Birch AI、Seasalt AI 共同合作開發了 GigaSpeech 2。GigaSpeech 2 是一個持續擴展的、多領域多語言的大規模語音識別語料庫,旨在促進低資源語言語音識別領域的發展和研究。GigaSpeech 2 raw 擁有 30000 小時的自動轉錄音頻,涵蓋泰語、印尼語、越南語。經過多輪精煉和迭代,GigaSpeech 2 refined 擁有 10000 小時泰語、6000 小時印尼語、6000 小時越南語。我們也開源了基于 GigaSpeech 2 數據訓練的多語種語音識別模型,模型性能達到了商業語音識別服務水平。
2. 數據集構建
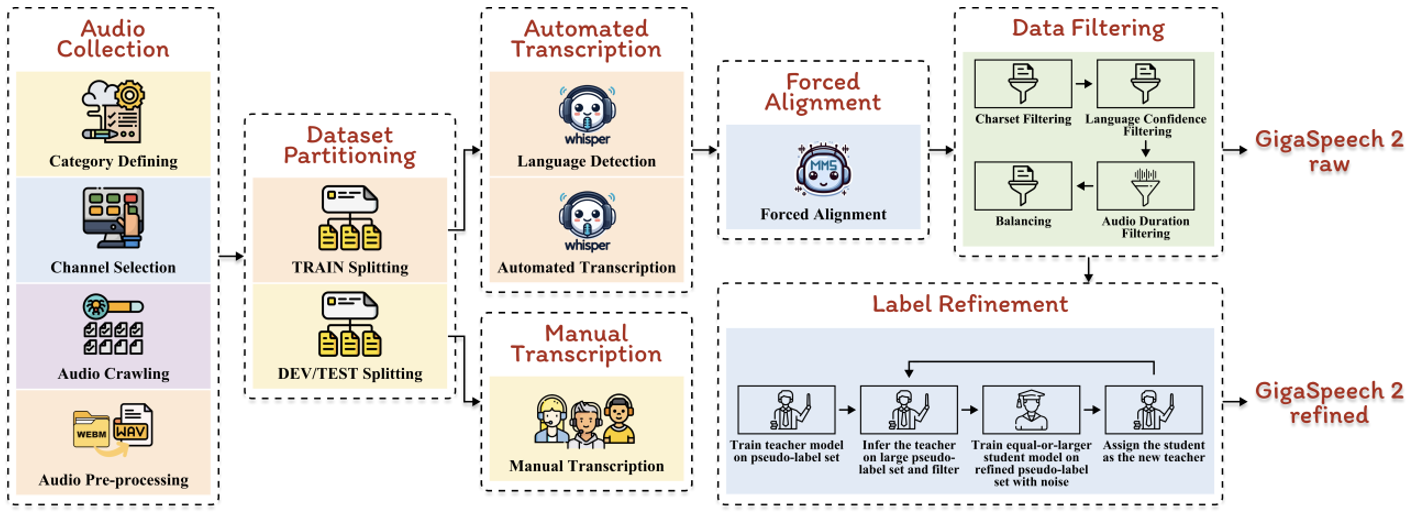
GigaSpeech 2 的制作流程也已同步開源,這是一個自動化構建大規模語音識別數據集的流程,面向互聯網上的海量無標注音頻,自動化地爬取數據、轉錄、對齊、精煉。這一流程包含利用 Whisper 進行初步轉錄,使用 TorchAudio 進行強制對齊,經過多維度過濾制作出 GigaSpeech 2 raw。隨后,采用改進的 Noisy Student Training (NST) 方法,通過反復迭代精煉偽標簽,持續提高標注質量,最終制作出 GigaSpeech 2 refined。
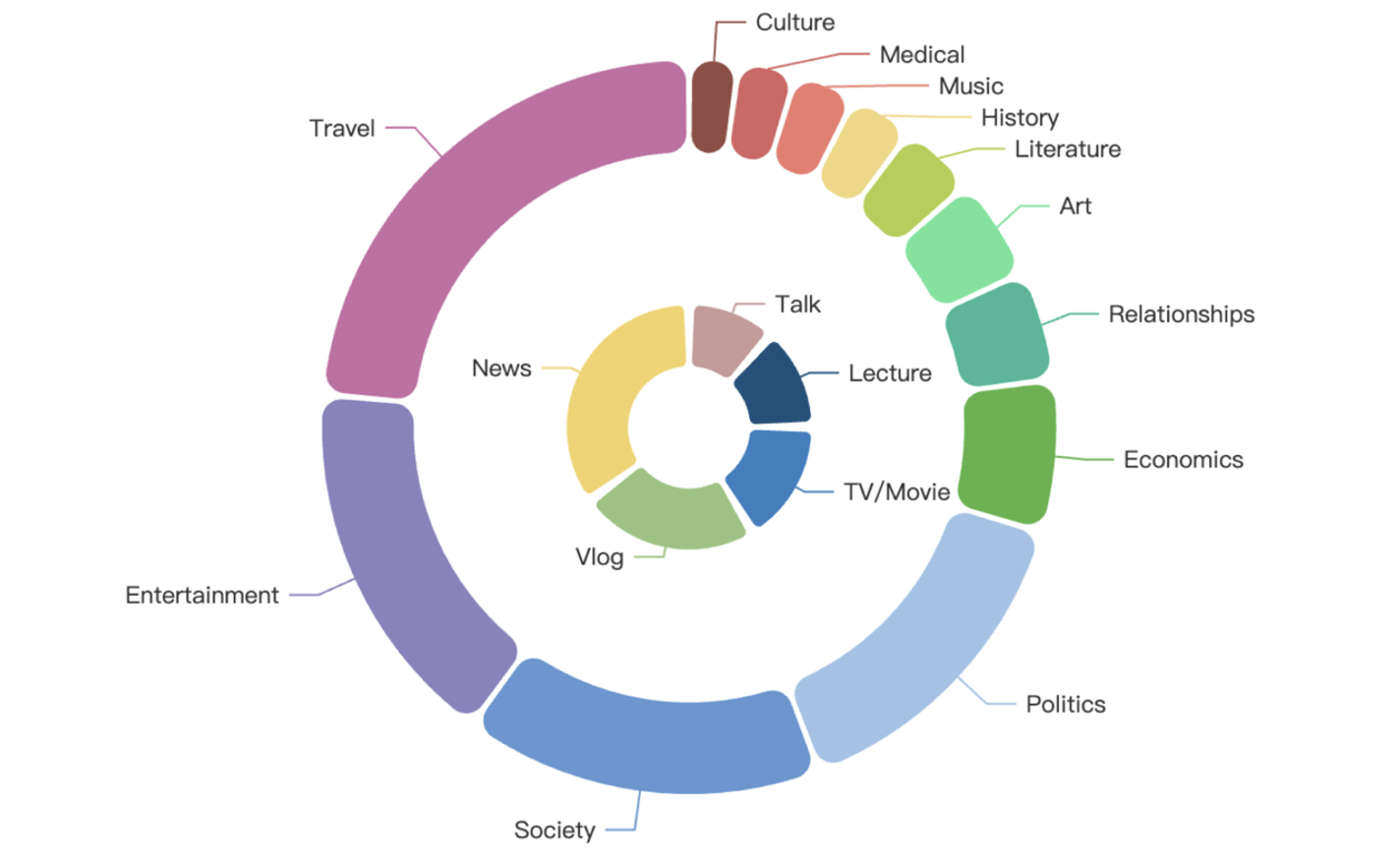
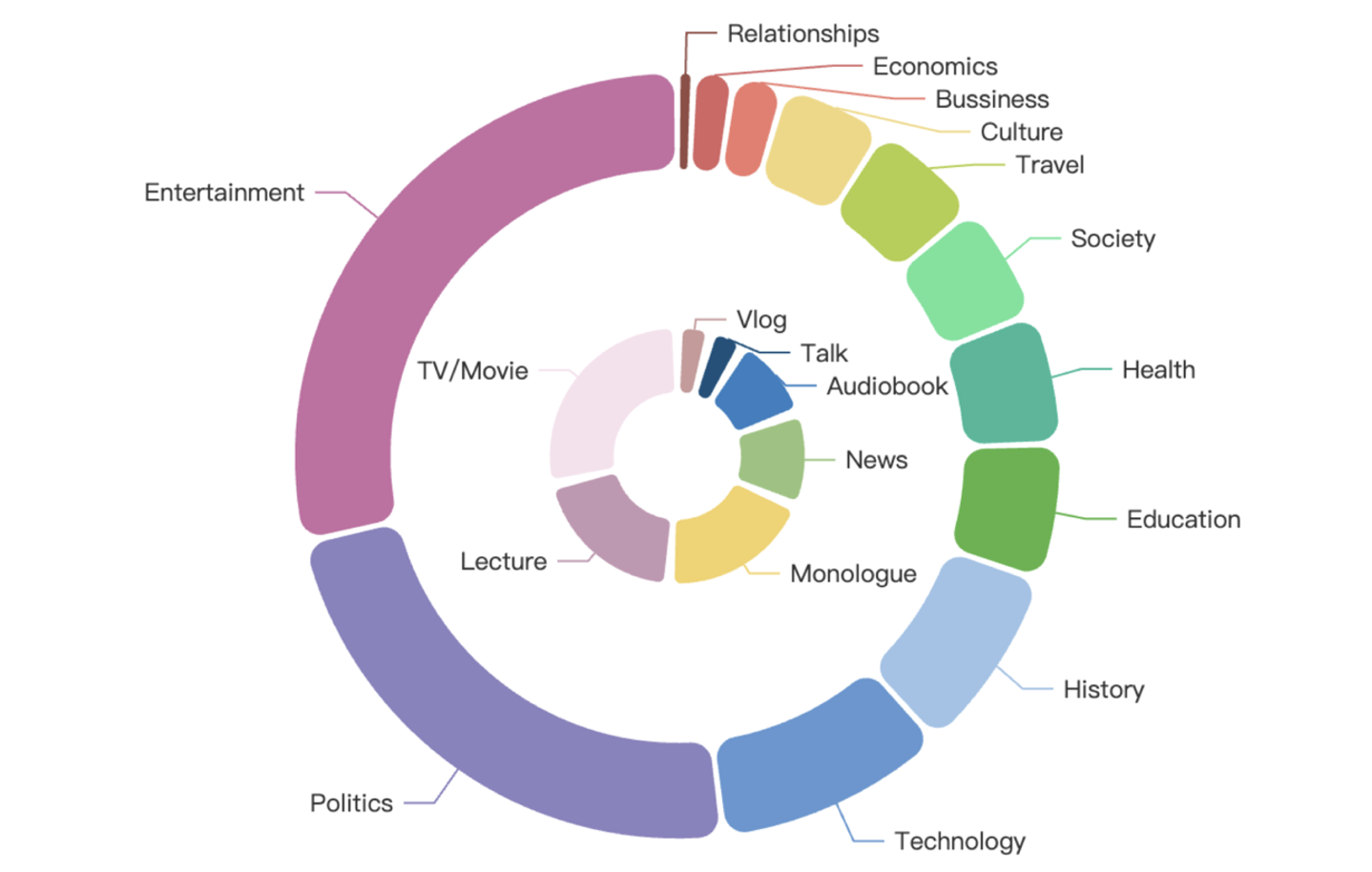
GigaSpeech 2 在主題上涵蓋了多樣化話題領域,包括農業、藝術、商業、氣候、文化、經濟、教育、娛樂、健康、歷史、文學、音樂、政治、兩性關系、購物、社會、體育、科技和旅行。同時,在內容形式上涵蓋了多種類型,包含聲書、解說、講座、獨白、電影電視劇、新聞、訪談、視頻博客。
3. 訓練集詳情
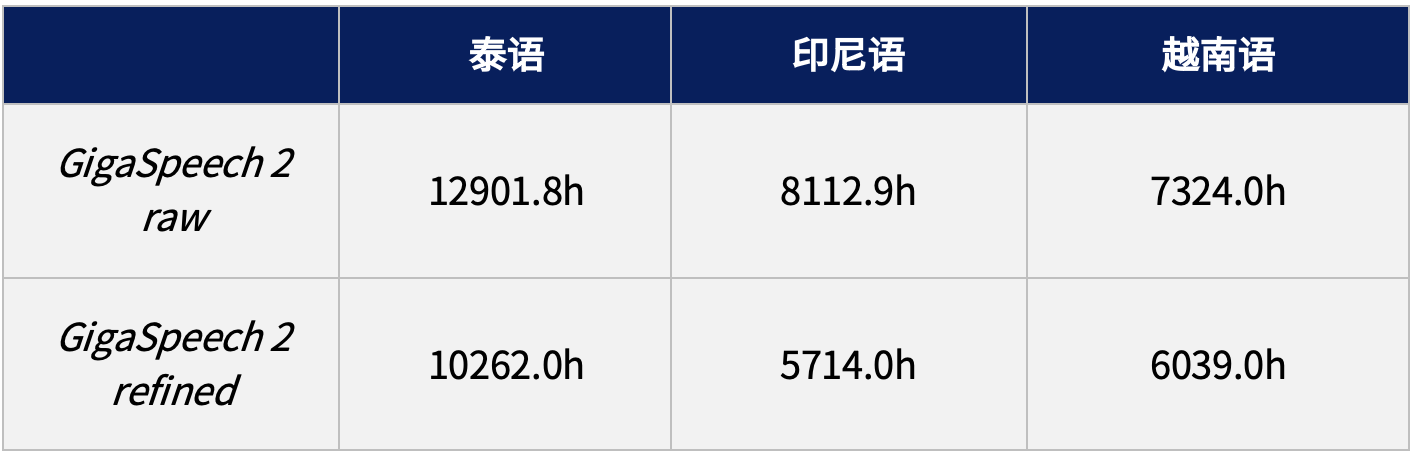
GigaSpeech 2 提供了兩個版本的數據集,分別為 raw 和 refined 版本,適用于有監督訓練任務。訓練集時長詳情如下表所示:
4. 開發集和測試集詳情
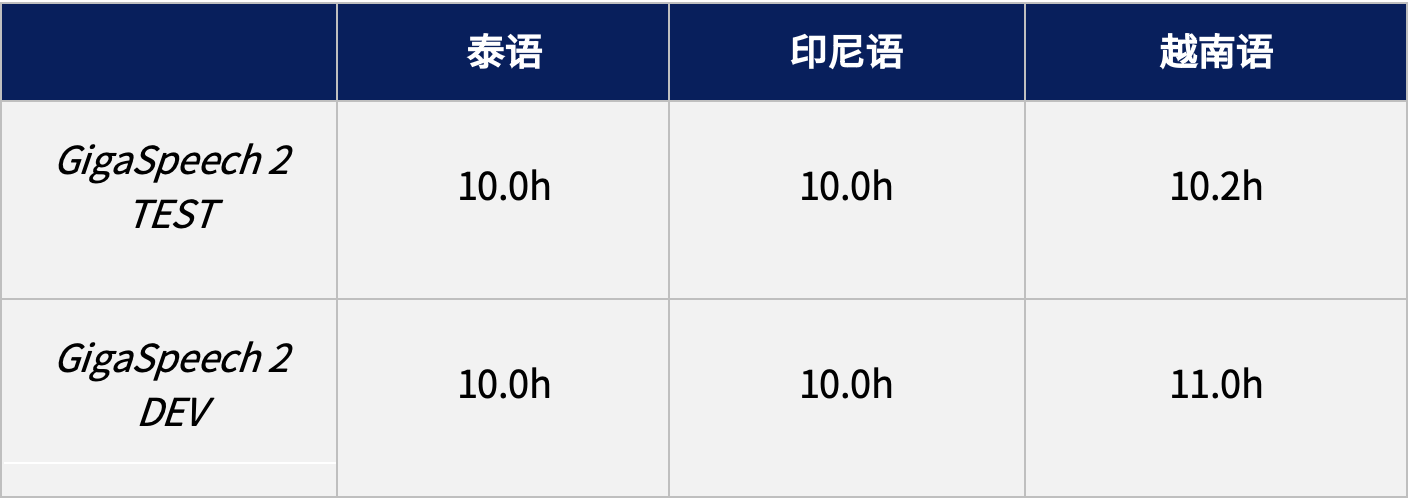
GigaSpeech 2 開發集和測試集由海天瑞聲的專業人員對語音數據人工標注得到,時長詳情如下表所示:
主題和內容分布詳情如下圖所示,外圈表示主題領域,內圈表示內容形式:
 泰語
泰語
 印尼語
印尼語
 越南語
越南語
5. 實驗結果
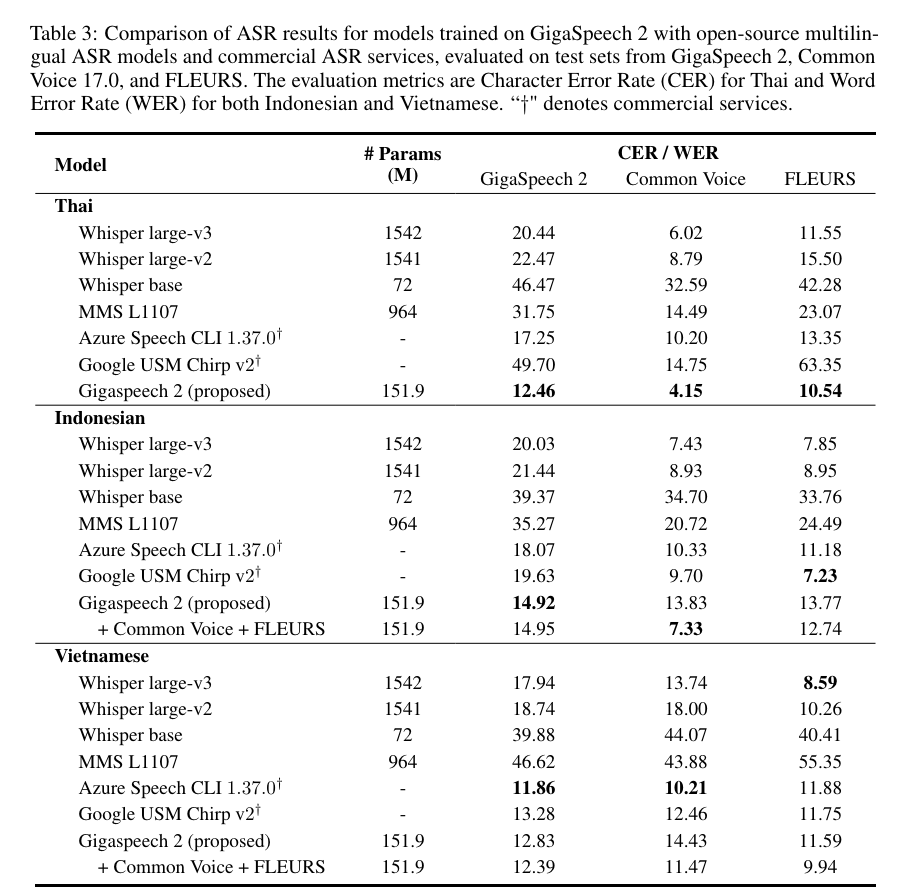
我們將使用 GigaSpeech 2 數據集訓練的語音識別模型與業界領先的 OpenAI Whisper (large-v3、large-v2、base)、Meta MMS L1107、Azure Speech CLI 1.37.0 和 Google USM Chirp v2 模型在泰語、印尼語和越南語上進行比較。性能評估基于 GigaSpeech 2、Common Voice 17.0 以及 FLEURS 三個測試集,通過字符錯誤率(CER)或單詞錯誤率(WER)指標進行評估。結果表明:
1)在泰語上,我們的模型展現出卓越的性能,全面超越了所有競爭對手,包括微軟和谷歌商用接口。值得一提的是,我們的模型在達到這一顯著成果的同時,參數量僅為 Whisper large-v3 的十分之一。
2)在印尼語和越南語上,我們的系統與現有的基線模型相比表現出具有競爭力的性能。
6. 排行榜
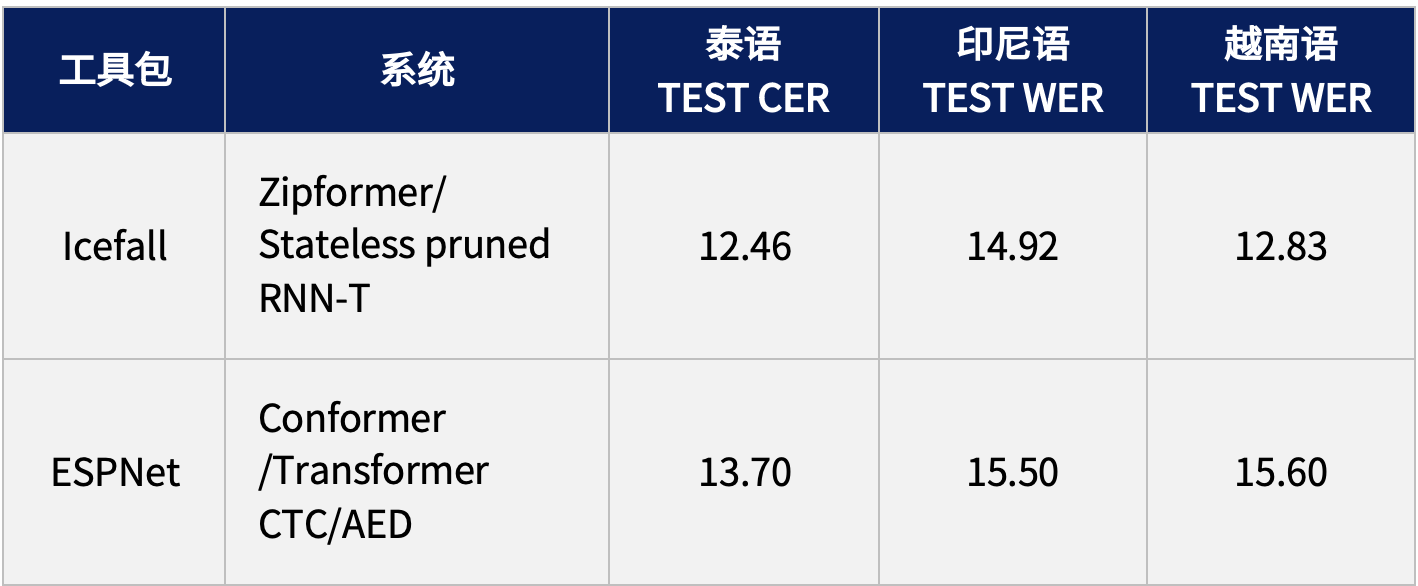
為了便于使用和跟蹤最新的技術發展,GigaSpeech 2 基于主流的語音識別框架提供了基線的訓練腳本,并開放了排行榜,目前提供的系統包括 Icefall 和 ESPNet,后續還將繼續更新與完善。
7. 資源鏈接
GigaSpeech 2 數據集已開放,歡迎大家下載:
https://huggingface.co/datasets/speechcolab/gigaspeech2
大規模語音識別數據集自動化構建流程發布于:
GitHub - SpeechColab/GigaSpeech2: An evolving, large-scale and multi-domain ASR corpus for low-resource languages with automated crawling, transcription and refinement
預印版論文發布于:
https://arxiv.org/pdf/2406.11546
8. 進一步合作
我們是一群試圖讓語音技術更易于使用的志愿者,歡迎各種形式的合作與貢獻。目前我們正在探索以下方向,如果您對某些方向感興趣,并且認為自己能夠提供幫助,請聯系 gigaspeech@speechcolab.org。
-
不同預訓練模型的推理架構
-
增加多樣化的數據來源
-
對語音算法/服務進行基準測試
-
構建和發布預訓練模型
-
支持更多語言
-
支持更多任務
-
制作新數據集
![[數據庫原理]關系范式總結(自用)](http://pic.xiahunao.cn/[數據庫原理]關系范式總結(自用))













)

報名答題題庫(持續更新中,僅供學習分享使用))


