文章目錄
- 前言
- 一、到底什么是指令集?
- 二、為什么現代CPU需要指令集?
- 三、開發完指令集究竟有什么缺點?
- 四、寄存器讀寫怎么驗證?
- 總結
前言
其實很早以前就想對這個話題展開來聊聊,但是對體系結構的理解也僅僅限于《量化體系結構》這一書,對底層實現也僅僅局限于做過RISC-V RV32I基本指令子集的CPU設計。此外實踐深度遠遠不足以支撐我站在系統的角度考慮問題!因此怕講了出現太多錯誤,被技術老炮們炮轟。
現在之所以敢壯起膽子來談這個話題有3點原因和1點動機!
1、過去三年時間內讀了不少架構類、嵌入開發和操作系統類的書籍,或多或少已經對系統有了大致但還是有點朦朧的了解。由于曾經接觸過超級demo的CPU設計,所以對指令集的印象也相對深刻!
2、過去三年內分別體驗過Vitis AI DPU(詳情可以跳轉之前寫的Vitis AI DPU部署的博客,后續有計劃補充對架構的理解,先賒個賬)、自費1000+RMB購買的定制化加速器方案、讀了NVIDIA開源的NVDLA加速器驅動代碼和硬件代碼(詳情可以跳轉之前寫的內核態驅動、用戶態驅動和架構分析的博客),對上述三個方案的SoC架構有所了解。從系統的角度對各層都有所觀察、有所理解。
3、接觸過Xilinx sdk開發后,對怎么引入寄存器和寄存器讀寫都有些許經驗和感悟。
至于動機,手頭這個工作結束了,就開始思考如果要做下一個工作,到底是基于指令集開發還是單純使用寄存器開發?一直以來接觸最多的是在裸機上開發寄存器,偶爾也會看到程序通過編譯器得到匯編(其實就是01形式的指令集)后灌給主存來驅動硬件。一直覺得指令集開發模式很酷,就像定義了一個新的果殼宇宙,而我是建筑師。因為這樣的中二病,所以手癢癢在所難免。
技術做多了,有點冷靜下來了。我為什么需要指令集?、指令集酷的背后有什么代價?、天底下沒有免費的午餐!。
回答這個問題之前就需要回答這么幾個問題!
1、到底什么是指令集?
2、為什么現代CPU需要指令集?然而并非所有的硬件都需要指令集!簡單如自費1000+買的定制化極強的5層網絡加速器根本不涉及指令集開發,復雜如NVDLA也不存在指令集(至少到現在為止我讀完NV開源的架構方案、開源的KMD和UMD代碼,我都沒有發現指令集的存在),那么究竟是為什么現代CPU需要開發非常有條理的指令集呢?
3、開發完指令集究竟有什么樣的缺點?明明限制了邏輯寄存器的數量,明明通過多bit的比較邏輯根據操作碼來確定操作類型,明明需要額外設置取指、譯碼兩個看起來邏輯上很嚴密(好像沒覺得奇怪,5級流水線嘛,教科書上都這么寫)的環節但也會帶來功耗和面積開銷,以上種種我將會結合寄存器讀寫模式來談為什么這些在相比之下是弊端。
4、為什么我會提到另一種完全不咋流行的硬件驅動模式(此驅動為drive而非driver)?說的就是你——“寄存器讀寫”,這個方式在嵌入式開發非常流行,就是使用硬件設計好的接口直接去讀寫寄存器,這一點還得感謝內存映射機制,還得感謝虛擬地址,感謝不完了,總之感謝整個體系結構。
基于以上四個問題,我思(xia)考(xiang)了好久,覺得是時候記錄一下自己的想法了!
如果講錯了,還請各位輕錘,指出錯誤。
如果講對了,歡迎大佬在評論區拓展!我權且拋磚引玉!
一、到底什么是指令集?
列舉RISC指令集體系中的MIPS指令集來說明(先搬運點超標量這本書上的知識):
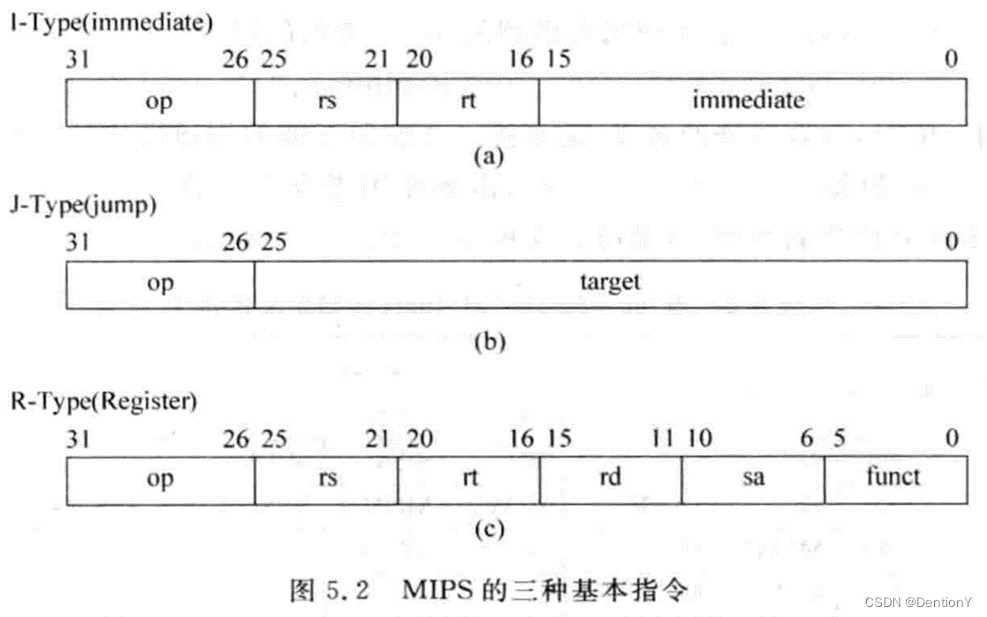
MIPS指令集類型主要分為三類。
1、和立即數相關的,rs為源寄存器,rd為目的寄存器。
2、和跳轉相關的,其中26個bit用于立即數。
3、和寄存器指令相關的,rs和rt用作源寄存器,rd用作目的寄存器。由于R-Type指令種類繁多,因此需要funct域來進一步劃分指令類別,同時sa專門用于移位指令。
給若干張表詳細解釋高op是怎么指定指令類型的!



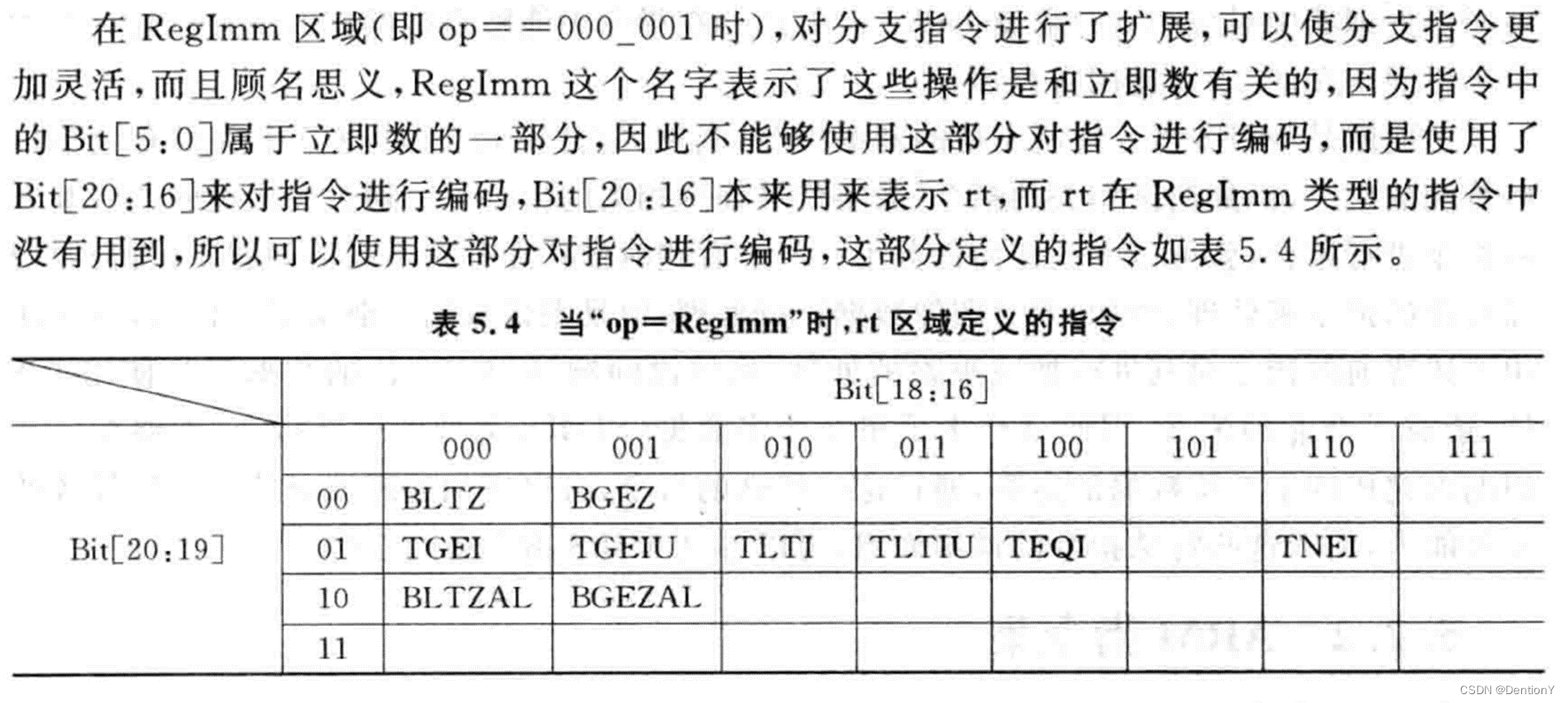
到這里為止,MIPS指令集的基本輪廓已經顯現了。
那我們還是借助超標量這本書來解釋“指令集架構ISA”的概念:
ISA是規定處理器的外在行為的一系列內容的統稱,它包括基本數據類型、指令、寄存器、尋址模式、存儲體系、中斷、異常與外部IO等內容。
換句話說,指令集其實在用有限的32bit指定好了這么幾件事:
1、讓處理器做什么操作?(做什么的物理實現(也就是基于cmos的電路實現)已經搭建好了),這一條由op以及其他必要信息來指定
2、給了處理器做該操作的該有的信息,比如去讀哪個寄存器,比如有什么樣的立即數?
第一條信息其實指明了指令集的op與其他必要的field來指定,粗糙地說是“做什么操作”,更加精確地說則是在已有的電路實現中選擇哪條數據路徑和控制路徑來實現某條指令規定的功能,所以說白了是多選一的選擇器信號或者某功能的使能信號,只不過在CPU設計中該信號會在不同流水級中挨個用上。
第二條信息指明了實現該操作必要的數據信息,這些信息的來源從指令的表現形式上來看要么是寄存器,要么是主存。但注意,不管是寄存器,還是主存,抑或是被掩蓋掉看不到的3級Cache或者是磁盤和外存,得益于虛擬存儲映射機制(意味著存儲被統一)、頁面替換、cacheline內的block替換等替換策略(意味著CPU執行程序不會礙于有限的物理內存)和中斷異常(意味著能允許內核態、用戶態線程的切換,同時允許中斷現場的保存,保存所需要的資源都要從寄存器或者主存回到主存的臨時空間)等的存在,物理存儲在實際CPU運行(意味著這是個動態行為)中會被模糊。數據信息雖然來源紛繁復雜,但是總之一句話,就是數據信息的來源在沒有操作系統的情況下是可以支持硬件工程師使用寄存器讀/寫的方式來獲取或者賦予。
那么再回答一個問題?第二條信息我指明了是寄存器讀/寫,那么第一條信息的是不是也可以指明寄存器行為呢?我給一個RTL的verilog代碼的模板(以一個簡單的加法器為例)
module add #(parameter WIDTH = 4
)
(input clk,input rst_n,input [WIDTH-1:0] datain1,input [WIDTH-1:0] datain2,input enable_add,output [WIDTH :0] dataout
);reg [WIDTH :0] dataout_reg;
assign dataout = dataout_reg;always @(posedge clk or negedge rst_n)
beginif (!rst_n) dataout_reg <= 0;else beginif (enable_add) dataout_reg <= datain1 + datain2;else dataout_reg <= dataout_reg;end
endendmodule
上述代碼中,enable_add就是一個加法功能的使能信號,那我為什么又說這是多選一的選擇信號呢?這基于CPU設計了多功能的考量,給一個粗糙的例子:
......
case (op_signal)
6'b001_001: begin ......operator_sel = <add_selection_signal>; // 賦予加法指令的控制信號......
6'b001_???: begin......operator_sel = <mul_selection_signal>; // 賦予乘法指令的控制信號
end
end
......
以上給了加法和乘法的例子,加法就是被選出來的指令。
我們再來觀察加法器的代碼,接口中有這么幾個信號:
module add #(parameter WIDTH = 4
)
(input clk,input rst_n,input [WIDTH-1:0] datain1,input [WIDTH-1:0] datain2,input enable_add,output [WIDTH :0] dataout
);
clk時鐘信號和rst_n復位信號是系統信號,datain1和datain2就是加法的2個加數,dataout就是加法的結果,enable_add就是選中了加法的行為。在verilog中如果需要把這個加法器接入到CPU中,會考慮給這datain1、datain2、dataout和enable_add分配地址,對于地址的讀寫如果從ZYNQ的角度來考慮,其實就是sdk中的reg_read和reg_write操作。
另外有沒有覺得datain1和datain2就是加法的2個加數,dataout就是加法的結果,enable_add就是選中了加法的行為眼熟?這不就是指令嘛!該有的都有了
op = &enable_add // 嚴格表述,&和C中一樣,表示取指
rs1 = &datain1
rs2 = &datain2
rd = &dataout
那么回到問題本身,什么是指令集?
我給出的答案是攜帶了操作類型的信息以及執行該操作必要的數據信息,而這些信息中操作類型被明確指定,數據信息除了立即數以外都是寄存器偏移,它的行為本質上和寄存器讀寫一致,不過是被高度抽象的!至于為什么需要高度抽象,看下一節。
二、為什么現代CPU需要指令集?
如果對硬件開發不熟悉的軟件工程師或者算法工程師而言,直接對基于RTL的verilog硬件操控寄存器來實現遙望著還有十萬八千里距離的程序無疑是十分痛苦的,因為這個工作得把熟悉的基于python或者c的代碼實現轉換為基于寄存器的代碼。
時代進步了,指令集把對控制信號和數據信號的信息做了個極大化的抽象,在RISC中被編碼為32bit的寬度。好處在于,一次性給出2個或者3個或者4個寄存器信息,把基于python或者c的代碼實現轉為基于指令集的代碼的工程量砍了至少一半以上,這個工程我們稱之為基于指令集的匯編開發。這個量說大也不大,畢竟計科和微電子系的同行們試過直接手擼匯編,大名鼎鼎的雷軍先生在金山開發時用的也是匯編,說小還真不小,畢竟用過c或者更高級的python的同志們想再回到匯編時代肯定是不樂意的。
時代接著進步,編譯器和Runtime的出現極大化地促進高級編程語言的發展。編譯器前端對接高級程序,后端對接指令集。用過c或者更高級的python的同志們可以無所畏懼地開發軟件或者算法是因為有了編譯器和runtime這一層隔膜,事實上也得感謝操作系統將必要的硬件抽象為內核態驅動(KMD,Kernel Mode Driver),而驅動是底層將寄存器行為進一步封裝的高級方案。runtime和編譯器在我熟悉的NVDLA的方案里面被統一歸到用戶態驅動(UMD,User Mode Driver)中,而在另一套我熟悉的Vitis AI DPU的方案中分別列舉。因此關于UMD的歸類各家有各家看法。
我們以上提到的所有,其實本質上是出于用戶的考量,使用者怎么方便,計算機系統工作者就怎么考慮。畢竟使用者越多,整個框架賣得越多,當然得到的反饋也越多,同時促進了生產力的發展。所以,理所應當地,越是底層的,越不容易開源,嗐。
三、開發完指令集究竟有什么缺點?
第二節我們討論到基于指令集的工作,提到一個詞用戶。但事實上,硬件設計的指標并非遠在天邊的用戶,而是PPA (Performance, Power, Area),和針對具體場景而提出的成本、抗輻射、可用性等等。
我們還是以前述的加法操作為例。在CPU中五級流水線——取指、譯碼、執行、訪存、寫回中,取指和譯碼負責從ICache中取回指令和將指令破譯。而在我提到的加法操作的verilog設計中其實只需要考慮將數據信息從寄存器中獲取到就行,所以就只局限于當前這個操作,寄存器操作可以省略取指、譯碼的很大一部分工作。執行一條指令所需要的周期數減少、功能部件數量減少,接著功耗減少,在芯片上的占用面積也減少。
對于硬件加速器如是,我舉一個Vitis AI DPU的架構:
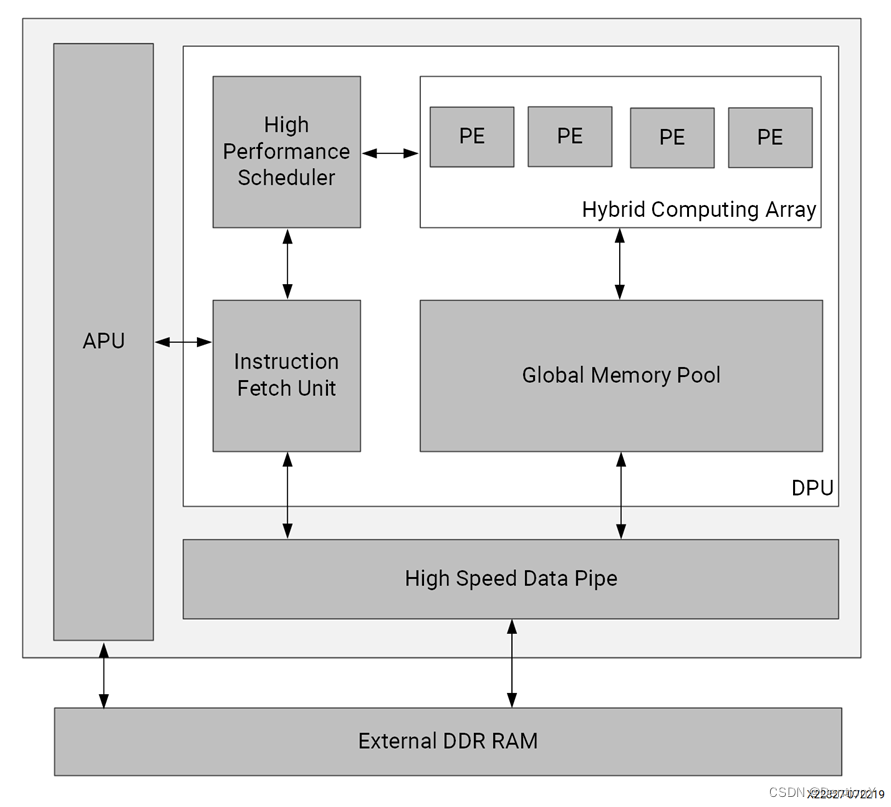
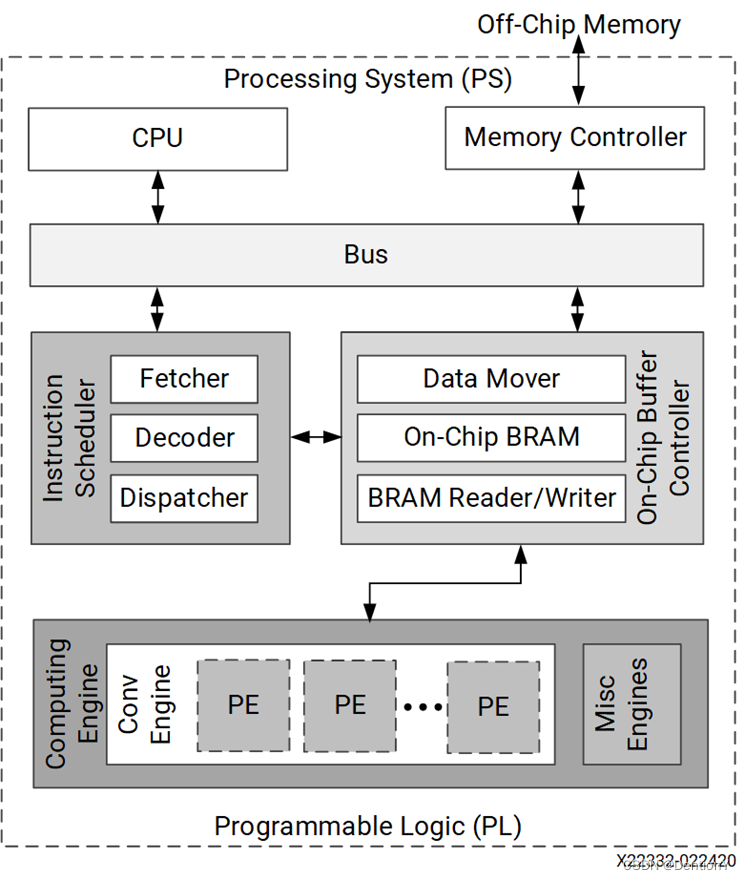
在這個硬件加速器中還是照著CPU的流水線來開發,從APU中以100MHz的頻率給指令,指令通過Bus進入由時鐘生成器生成325MHz高頻時鐘和100MHz低頻時鐘的PL,指令進入指令分配器中依次經過取指、譯碼和分發,同時從片上Memory中獲取必要的數據信息,或者在data miss時從片外Memory中獲取數據信息。隨后將數據和指令的控制信息傳送到矩陣乘加的計算陣列中,將得到的中間結果通過BRAM讀寫控制器放到片上Memory或者Data Mover(這個應該是FIFO)中,一旦存儲不下了,就把數據從片上調到片外(當然這個過程是隱藏在計算流程后面的,減少串行執行帶來的延遲以提升計算性能)。
如果從寄存器讀寫的角度來說,取指、譯碼和分發的功能部件可以做極大的簡化。但是缺點也是明顯的!就是debug Verilog的時候沒有那么容易,在sdk開發的時候也沒那么容易!
這個方案還用到了中斷,主要起2方面作用:1、通知CPU,矩陣乘加計算完了,以便于系統發送新的矩陣乘加指令;2、通知CPU,所有有關矩陣乘加的操作都計算完了,為了保證基于CNN的圖像分類可以接著執行,該把執行softmax的指令發送一下了,所以作者設計了2個softmax的固化IP。
類似基于五級流水的加速方案還有很多,比如Vortex GPGPU(基于RISC-V指令集擴展)(具體不做解讀,大概能看得明白,學了超標量處理器設計的思路,4路x發射亂序的GPGPU):
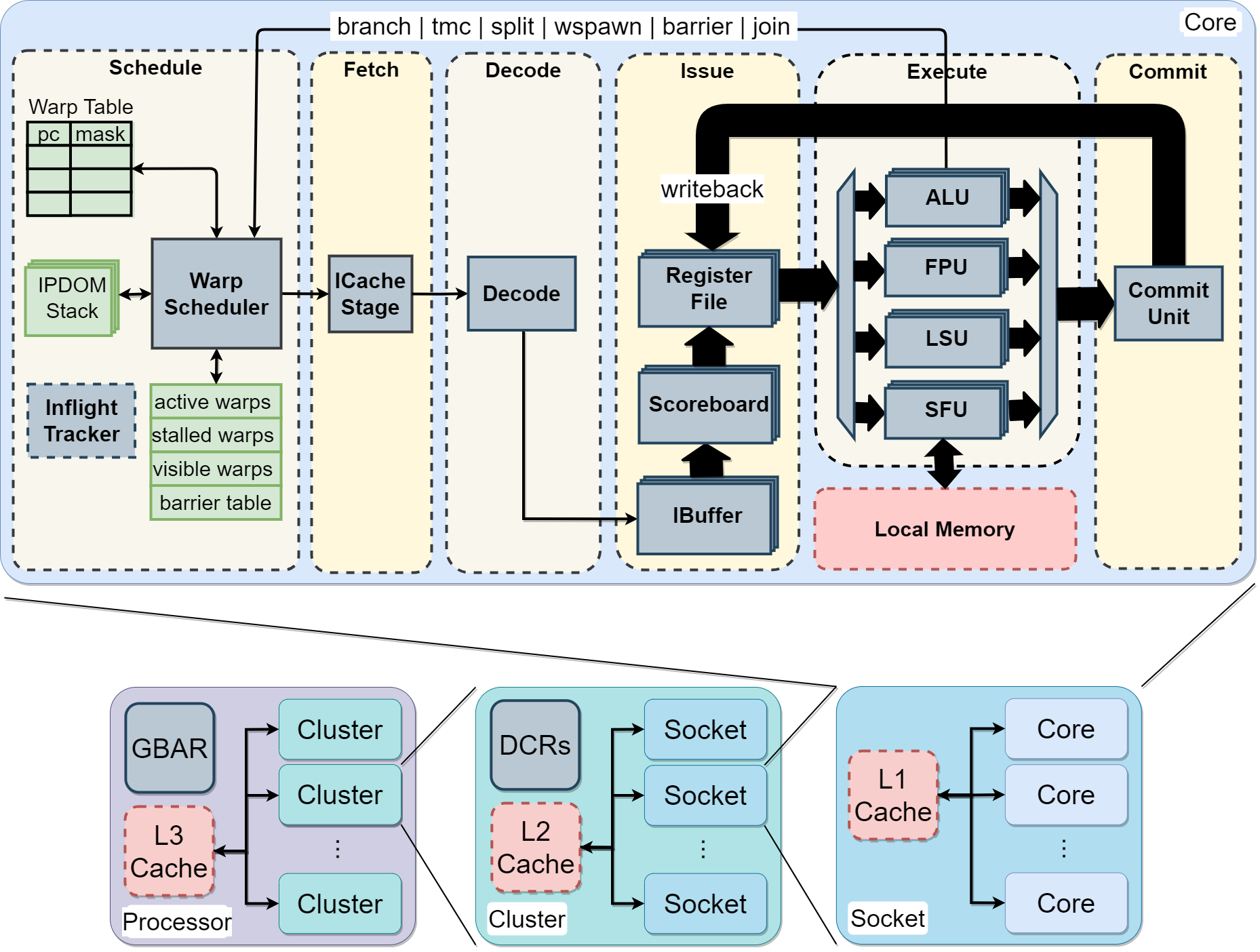
所以其實從硬件開發的角度來說,全部功能模塊都用指令集實現無疑是對PPA的損害,所以要考慮到并非所有功能模塊都使用指令集開發。
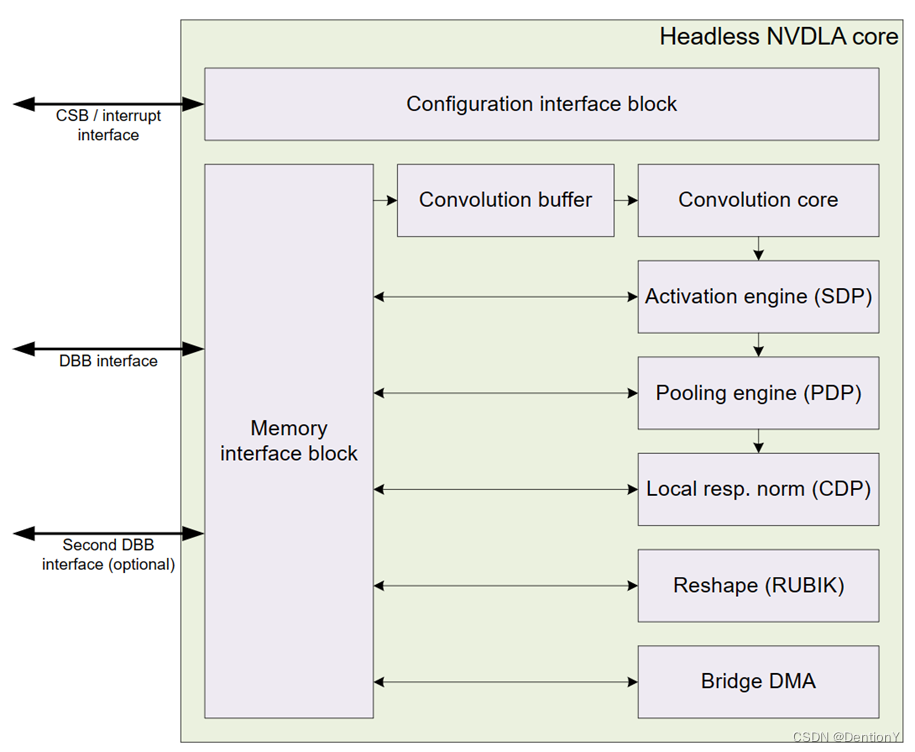
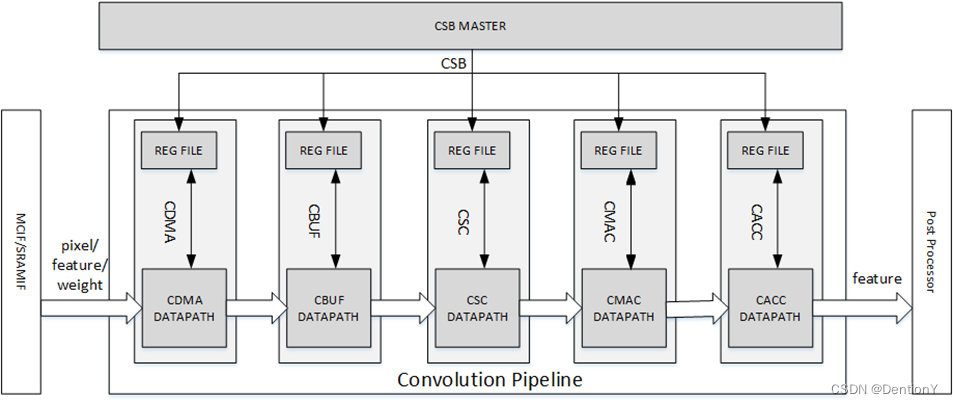
我個人認為基于寄存器開發的方案是PPA的大哥!但是如果從基于寄存器開發的例子NVDLA來說,想接著做二次開發的難度還是比較大,代碼邏輯混亂,不容易理清楚。以下是NVDLA IP架構,從架構內容可以看出不具備指令開發的特點,其中Configuration interface block用于以硬件方式配置寄存器,隨后該模塊接著被拉出寄存器在KMD層面抽象。
看完以上幾個方案,我們如果從基于ZYNQ+FPGA的模式來考慮,很多人可能覺得如果要開發基于自定義指令集的方案應該怎么做?畢竟前面提到和RISC-V指令集相關的GPGPU,這個可以讓CPU來識別是不是host (CPU)或者device (GPU)負責,類似NVIDIA的方案。那是不是就沒法兒搞自定義指令集這一工程了呢?不然!給個方案實現:
1、RTL層面依然使用自定義指令集來完成取指、譯碼、執行、訪存、寫回等五個步驟的加速器;
2、RTL層面有了這么幾個要素:1)取指令的起始地址;2)加速器開始運行的使能信號;
3、在2中提到的2個寄存器可以明顯被拉出來(在完成axi類型的IP封裝、和ZYNQ搭建SoC以后、經歷綜合、實現、bitstream導出后會給出寄存器在memory中的偏移地址),使用寄存器的偏移地址可以在Xilinx Vitis sdk中對起始地址處賦予指令的內容,也就是需要手寫匯編。
4、至于手寫匯編能不能被編譯器代替,這得需要專門的編譯器工具了。不過對CNN或者Transformer這類矩陣乘占據大多數的,往往開發數據級并行DLP,因此指令數量在模型規模不大的情況下其實并不會很多。
四、寄存器讀寫怎么驗證?
我以NVDLA為例,這個問題在回答如何在裸機層面和驅動層面去驗證,驅動層面的細節太多,請移步我之前寫過關于NVDLA的驅動代碼解讀。以下回答裸機層面:

最后封裝的時候是這樣的:

NVDLA IP的寄存器被拉到AMBA總線中,注意,給寄存器分配偏移地址是在SoC搭完以后,所以換句話說,沒有AMBA總線來做中介是不可能在系統層面進行驗證的。
我拿一段代碼來說明(下面是axi-lite slave內的一段代碼):
`timescale 1 ns / 1 psmodule ppv3_preprocess_accelerator_v1_0_S00_AXI #(// Users to add parameters hereparameter DATA_WIDTH_AXI = 32,parameter PRIOR_DATA_WIDTH = 1024 , // 64prior * int8 * 2 (xc,yc)parameter GT_DATA_WIDTH = 256 , // 8gt * int8 * 4 (xleft,xright,yupper,ybottom)parameter NUMBER_OF_GT = 8 ,parameter NUMBER_OF_PRIOR = 64 ,parameter DATA_WIDTH_INT8 = 8 ,parameter HPIC = 160 , // 160 or 120parameter WPIC = 160 ,parameter NUMBER_OF_CLS = 32 , // cls numberparameter DATA_WIDTH_INT4 = 4 ,parameter CLS_DATA_WIDTH = 8192 , // 64prior * int4 * 32(cls)parameter CONF_DATA_WIDTH = 512 , // 64prior confidence * int8parameter CONF_INT8 = 8 , // int8 confidenceparameter CONF_THRESHOLD = 8 , // int-itize confidence threshold // alignmentparameter DATA_WIDTH_INT12 = 12 ,// uppersumparameter DATA_WIDTH_INT16 = 16 ,// User parameters ends// Do not modify the parameters beyond this line// Width of S_AXI data busparameter integer C_S_AXI_DATA_WIDTH = 32,// Width of S_AXI address busparameter integer C_S_AXI_ADDR_WIDTH = 6)(// Users to add ports hereoutput o_run,output [DATA_WIDTH_AXI-2:0] o_num_cnt, input i_idle,input i_read,input i_write,input i_done,output train_or_test,output nms_enable,output faster_enable,output dsla_enable,output yolo_enable,input end_signal,// User ports ends// Do not modify the ports beyond this line// Global Clock Signalinput wire S_AXI_ACLK,// Global Reset Signal. This Signal is Active LOWinput wire S_AXI_ARESETN,// Write address (issued by master, acceped by Slave)input wire [C_S_AXI_ADDR_WIDTH-1 : 0] S_AXI_AWADDR,// Write channel Protection type. This signal indicates the// privilege and security level of the transaction, and whether// the transaction is a data access or an instruction access.input wire [2 : 0] S_AXI_AWPROT,// Write address valid. This signal indicates that the master signaling// valid write address and control information.input wire S_AXI_AWVALID,// Write address ready. This signal indicates that the slave is ready// to accept an address and associated control signals.output wire S_AXI_AWREADY,// Write data (issued by master, acceped by Slave) input wire [C_S_AXI_DATA_WIDTH-1 : 0] S_AXI_WDATA,// Write strobes. This signal indicates which byte lanes hold// valid data. There is one write strobe bit for each eight// bits of the write data bus. input wire [(C_S_AXI_DATA_WIDTH/8)-1 : 0] S_AXI_WSTRB,// Write valid. This signal indicates that valid write// data and strobes are available.input wire S_AXI_WVALID,// Write ready. This signal indicates that the slave// can accept the write data.output wire S_AXI_WREADY,// Write response. This signal indicates the status// of the write transaction.output wire [1 : 0] S_AXI_BRESP,// Write response valid. This signal indicates that the channel// is signaling a valid write response.output wire S_AXI_BVALID,// Response ready. This signal indicates that the master// can accept a write response.input wire S_AXI_BREADY,// Read address (issued by master, acceped by Slave)input wire [C_S_AXI_ADDR_WIDTH-1 : 0] S_AXI_ARADDR,// Protection type. This signal indicates the privilege// and security level of the transaction, and whether the// transaction is a data access or an instruction access.input wire [2 : 0] S_AXI_ARPROT,// Read address valid. This signal indicates that the channel// is signaling valid read address and control information.input wire S_AXI_ARVALID,// Read address ready. This signal indicates that the slave is// ready to accept an address and associated control signals.output wire S_AXI_ARREADY,// Read data (issued by slave)output wire [C_S_AXI_DATA_WIDTH-1 : 0] S_AXI_RDATA,// Read response. This signal indicates the status of the// read transfer.output wire [1 : 0] S_AXI_RRESP,// Read valid. This signal indicates that the channel is// signaling the required read data.output wire S_AXI_RVALID,// Read ready. This signal indicates that the master can// accept the read data and response information.input wire S_AXI_RREADY);// AXI4LITE signalsreg [C_S_AXI_ADDR_WIDTH-1 : 0] axi_awaddr;reg axi_awready;reg axi_wready;reg [1 : 0] axi_bresp;reg axi_bvalid;reg [C_S_AXI_ADDR_WIDTH-1 : 0] axi_araddr;reg axi_arready;reg [C_S_AXI_DATA_WIDTH-1 : 0] axi_rdata;reg [1 : 0] axi_rresp;reg axi_rvalid;// Example-specific design signals// local parameter for addressing 32 bit / 64 bit C_S_AXI_DATA_WIDTH// ADDR_LSB is used for addressing 32/64 bit registers/memories// ADDR_LSB = 2 for 32 bits (n downto 2)// ADDR_LSB = 3 for 64 bits (n downto 3)localparam integer ADDR_LSB = (C_S_AXI_DATA_WIDTH/32) + 1;localparam integer OPT_MEM_ADDR_BITS = 1;//----------------------------------------------//-- Signals for user logic register space example//------------------------------------------------//-- Number of Slave Registers 4reg [C_S_AXI_DATA_WIDTH-1:0] slv_reg0;reg [C_S_AXI_DATA_WIDTH-1:0] slv_reg1;reg [C_S_AXI_DATA_WIDTH-1:0] slv_reg2;reg [C_S_AXI_DATA_WIDTH-1:0] slv_reg3;wire slv_reg_rden;wire slv_reg_wren;reg [C_S_AXI_DATA_WIDTH-1:0] reg_data_out;integer byte_index;reg aw_en;// I/O Connections assignmentsassign S_AXI_AWREADY = axi_awready;assign S_AXI_WREADY = axi_wready;assign S_AXI_BRESP = axi_bresp;assign S_AXI_BVALID = axi_bvalid;assign S_AXI_ARREADY = axi_arready;assign S_AXI_RDATA = axi_rdata;assign S_AXI_RRESP = axi_rresp;assign S_AXI_RVALID = axi_rvalid;// Implement axi_awready generation// axi_awready is asserted for one S_AXI_ACLK clock cycle when both// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_awready is// de-asserted when reset is low.always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_awready <= 1'b0;aw_en <= 1'b1;end elsebegin if (~axi_awready && S_AXI_AWVALID && S_AXI_WVALID && aw_en)begin// slave is ready to accept write address when // there is a valid write address and write data// on the write address and data bus. This design // expects no outstanding transactions. axi_awready <= 1'b1;aw_en <= 1'b0;endelse if (S_AXI_BREADY && axi_bvalid)beginaw_en <= 1'b1;axi_awready <= 1'b0;endelse beginaxi_awready <= 1'b0;endend end // Implement axi_awaddr latching// This process is used to latch the address when both // S_AXI_AWVALID and S_AXI_WVALID are valid. always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_awaddr <= 0;end elsebegin if (~axi_awready && S_AXI_AWVALID && S_AXI_WVALID && aw_en)begin// Write Address latching axi_awaddr <= S_AXI_AWADDR;endend end // Implement axi_wready generation// axi_wready is asserted for one S_AXI_ACLK clock cycle when both// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_wready is // de-asserted when reset is low. always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_wready <= 1'b0;end elsebegin if (~axi_wready && S_AXI_WVALID && S_AXI_AWVALID && aw_en )begin// slave is ready to accept write data when // there is a valid write address and write data// on the write address and data bus. This design // expects no outstanding transactions. axi_wready <= 1'b1;endelsebeginaxi_wready <= 1'b0;endend end // Implement memory mapped register select and write logic generation// The write data is accepted and written to memory mapped registers when// axi_awready, S_AXI_WVALID, axi_wready and S_AXI_WVALID are asserted. Write strobes are used to// select byte enables of slave registers while writing.// These registers are cleared when reset (active low) is applied.// Slave register write enable is asserted when valid address and data are available// and the slave is ready to accept the write address and write data.assign slv_reg_wren = axi_wready && S_AXI_WVALID && axi_awready && S_AXI_AWVALID;always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginslv_reg0 <= 0;slv_reg1 <= 0;slv_reg2 <= 0;slv_reg3 <= 0;end else beginif (slv_reg_wren)begincase ( axi_awaddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB] )2'h0:for ( byte_index = 0; byte_index <= (C_S_AXI_DATA_WIDTH/8)-1; byte_index = byte_index+1 )if ( S_AXI_WSTRB[byte_index] == 1 ) begin// Respective byte enables are asserted as per write strobes // Slave register 0slv_reg0[(byte_index*8) +: 8] <= S_AXI_WDATA[(byte_index*8) +: 8];end 2'h1:for ( byte_index = 0; byte_index <= (C_S_AXI_DATA_WIDTH/8)-1; byte_index = byte_index+1 )if ( S_AXI_WSTRB[byte_index] == 1 ) begin// Respective byte enables are asserted as per write strobes // Slave register 1slv_reg1[(byte_index*8) +: 8] <= S_AXI_WDATA[(byte_index*8) +: 8];end 2'h2:for ( byte_index = 0; byte_index <= (C_S_AXI_DATA_WIDTH/8)-1; byte_index = byte_index+1 )if ( S_AXI_WSTRB[byte_index] == 1 ) begin// Respective byte enables are asserted as per write strobes // Slave register 2slv_reg2[(byte_index*8) +: 8] <= S_AXI_WDATA[(byte_index*8) +: 8];end 2'h3:for ( byte_index = 0; byte_index <= (C_S_AXI_DATA_WIDTH/8)-1; byte_index = byte_index+1 )if ( S_AXI_WSTRB[byte_index] == 1 ) begin// Respective byte enables are asserted as per write strobes // Slave register 3slv_reg3[(byte_index*8) +: 8] <= S_AXI_WDATA[(byte_index*8) +: 8];end default : beginslv_reg0 <= slv_reg0;slv_reg1 <= slv_reg1;slv_reg2 <= slv_reg2;slv_reg3 <= slv_reg3;endendcaseendendend // Implement write response logic generation// The write response and response valid signals are asserted by the slave // when axi_wready, S_AXI_WVALID, axi_wready and S_AXI_WVALID are asserted. // This marks the acceptance of address and indicates the status of // write transaction.always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_bvalid <= 0;axi_bresp <= 2'b0;end elsebegin if (axi_awready && S_AXI_AWVALID && ~axi_bvalid && axi_wready && S_AXI_WVALID)begin// indicates a valid write response is availableaxi_bvalid <= 1'b1;axi_bresp <= 2'b0; // 'OKAY' response end // work error responses in futureelsebeginif (S_AXI_BREADY && axi_bvalid) //check if bready is asserted while bvalid is high) //(there is a possibility that bready is always asserted high) beginaxi_bvalid <= 1'b0; end endendend // Implement axi_arready generation// axi_arready is asserted for one S_AXI_ACLK clock cycle when// S_AXI_ARVALID is asserted. axi_awready is // de-asserted when reset (active low) is asserted. // The read address is also latched when S_AXI_ARVALID is // asserted. axi_araddr is reset to zero on reset assertion.always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_arready <= 1'b0;axi_araddr <= 32'b0;end elsebegin if (~axi_arready && S_AXI_ARVALID)begin// indicates that the slave has acceped the valid read addressaxi_arready <= 1'b1;// Read address latchingaxi_araddr <= S_AXI_ARADDR;endelsebeginaxi_arready <= 1'b0;endend end // Implement axi_arvalid generation// axi_rvalid is asserted for one S_AXI_ACLK clock cycle when both // S_AXI_ARVALID and axi_arready are asserted. The slave registers // data are available on the axi_rdata bus at this instance. The // assertion of axi_rvalid marks the validity of read data on the // bus and axi_rresp indicates the status of read transaction.axi_rvalid // is deasserted on reset (active low). axi_rresp and axi_rdata are // cleared to zero on reset (active low). always @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_rvalid <= 0;axi_rresp <= 0;end elsebegin if (axi_arready && S_AXI_ARVALID && ~axi_rvalid)begin// Valid read data is available at the read data busaxi_rvalid <= 1'b1;axi_rresp <= 2'b0; // 'OKAY' responseend else if (axi_rvalid && S_AXI_RREADY)begin// Read data is accepted by the masteraxi_rvalid <= 1'b0;end endend // Implement memory mapped register select and read logic generation// Slave register read enable is asserted when valid address is available// and the slave is ready to accept the read address.assign slv_reg_rden = axi_arready & S_AXI_ARVALID & ~axi_rvalid;always @(*)begin// Address decoding for reading registerscase ( axi_araddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB] )2'h0 : reg_data_out <= slv_reg0;2'h1 : reg_data_out <= {{27{1'b0}}, end_signal, i_done, i_idle, i_read, i_write};2'h2 : reg_data_out <= slv_reg2;2'h3 : reg_data_out <= slv_reg3;default : reg_data_out <= 777; // To debugendcaseend// Output register or memory read dataalways @( posedge S_AXI_ACLK )beginif ( S_AXI_ARESETN == 1'b0 )beginaxi_rdata <= 0;end elsebegin // When there is a valid read address (S_AXI_ARVALID) with // acceptance of read address by the slave (axi_arready), // output the read dada if (slv_reg_rden)beginaxi_rdata <= reg_data_out; // register read dataend endend // Add user logic here// tick gen o_runreg r_run;always @(posedge S_AXI_ACLK) begin if(!S_AXI_ARESETN) begin // sync reset_nr_run <= 1'b0; end else beginr_run <= slv_reg0[31];end endassign o_run = (r_run == 1'b0) && (slv_reg0[DATA_WIDTH_AXI-1] == 1'b1) ; // Posedge 1 tickassign o_num_cnt = slv_reg0[DATA_WIDTH_AXI-2:0];assign {dsla_enable, yolo_enable, faster_enable, nms_enable, train_or_test} = slv_reg3[4:0]; // wire reset_n = S_AXI_ARESETN;
// wire clk = S_AXI_ACLK;reg r_done; // to keep done status, i_done is a 1 tick.always @(posedge S_AXI_ACLK) beginif(!S_AXI_ARESETN) begin // sync reset_nr_done <= 1'b0; end else if (i_done) beginr_done <= 1'b1;end else if (o_run) beginr_done <= 1'b0;end // else. keep statusend
/*always @(posedge S_AXI_ACLK) begin if(!S_AXI_ARESETN) begin // sync reset_nslv_reg1 <= 32'b0; end else beginslv_reg1[0] <= i_idle;slv_reg1[1] <= i_read;slv_reg1[2] <= i_write;slv_reg1[3] <= r_done;end end
*/// User logic endsendmodule其中
......assign slv_reg_rden = axi_arready & S_AXI_ARVALID & ~axi_rvalid;always @(*)begin// Address decoding for reading registerscase ( axi_araddr[ADDR_LSB+OPT_MEM_ADDR_BITS:ADDR_LSB] )2'h0 : reg_data_out <= slv_reg0;2'h1 : reg_data_out <= {{27{1'b0}}, end_signal, i_done, i_idle, i_read, i_write};2'h2 : reg_data_out <= slv_reg2;2'h3 : reg_data_out <= slv_reg3;default : reg_data_out <= 777; // To debugendcaseend
......
和這段代碼
assign o_run = (r_run == 1'b0) && (slv_reg0[DATA_WIDTH_AXI-1] == 1'b1) ; // Posedge 1 tickassign o_num_cnt = slv_reg0[DATA_WIDTH_AXI-2:0];assign {dsla_enable, yolo_enable, faster_enable, nms_enable, train_or_test} = slv_reg3[4:0];
把一個已經定義好的IP的接口信號怎么關聯到axi-lite bus內做了一個樣板操作,通過封裝為axi-lite類型的IP后和ZYNQ接在一起以后就有了寄存器的偏移地址。
隨后的驗證在sdk層面可以移步我之前寫的sdk代碼解讀。
總結
簡單談了談指令集和寄存器讀寫怎么驅動硬件,以及指令集開發的優缺點。詳細談了寄存器讀寫和指令集開發的流程與驗證流程。其實本來還有一堆細節要講,比如下一個工作應該怎么考慮,but考慮到目前某些部件的硬件代碼還不熟悉暫時先擱置,最近在趕進度,后期會分析這個問題。



)



之插入排序----直接插入排序和希爾排序)




;用法和常見問題)


)
)


