小阿軒yx-案例:MySQL主從復制與讀寫分離
案例分析
概述
實際生產環境中
- 如果對數據庫讀和寫都在同一個數據庫服務器中操作,無論在安全性、高可用性還是高并發等各個方面都完全不能滿足實際需求
- 一般都是通過主從復制(Master-Slave)同步數據
- 再通過讀寫分離來提升數據庫并發負載能力進行部署與實施
案例前置知識點
MySQL 主從復制原理
- MySQL 主從復制和 MySQL 讀寫分離兩者有緊密聯系
- 首先部署主從復制,才能在此基礎上進行數據的讀寫分離
MySQL 支持的復制類型
基于語句復制
- 在主服務器上執行的 SQL 語句,在從服務器上執行同樣的語句
MySQL 默認采用基于語句的復制,效率比較高
基于行的復制
- 把改變的內容復制過去,而不是把命令在從服務器上執行一遍
混合類型的復制
- 默認采用基于語句的復制,一旦發現基于語句無法精準復制時,就會采用基于行的復制
復制的工作過程

- 每個事物更新數據完成之前,Master 將這些改變記錄進二進制日志。寫入二進制日志完成后,Master 通知存儲引擎提交事務
- Slave 將 Master 的 Binary log 復制到其中繼日志(Relay log)
- SQL slave thread(SQL 從線程)處理該過程的最后一步
復制過程有一個很重要的限制,即復制在Slave上時串行化的,也就是說Master上的并行更新操作不能在 Slave 上并行操作
MySQL 讀寫分離原理
- 簡單說,讀寫分離就是只在主服務器上寫,只在從服務器上讀。
- 讓主數據庫處理事務性查詢,而數據庫處理 select 查詢。
- 數據庫復制被用來把主數據庫上事務性查詢導致的變更同步到集群中的從數據庫。
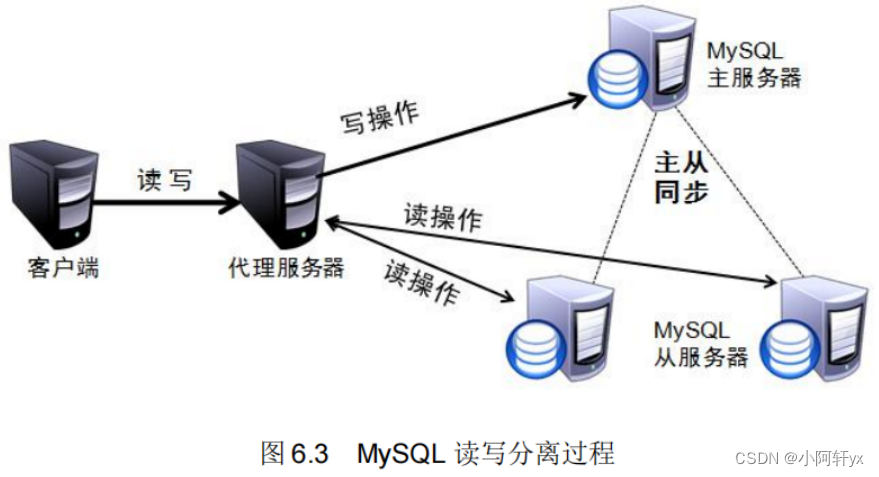
目前較為常見的 MySQL 讀寫分離分為兩種
基于程序代碼內部實現
在代碼中根據 select、insert 進行路由分類,這類方法也是目前生產環境應用最廣泛的
優點
- 性能較好
- 在程序代碼中實現
- 不需要增加額外的設備作為硬件開支
缺點
- 需要開發人員來實現
- 運維人員無從下手
基于中間代理層實現
- 一般位于客戶端和服務器之間,代理服務器接到后端請求后通過判斷轉發到后端數據庫
兩個代表性程序
MySQL-Proxy
- 為 MySQL 開源項目
- 通過自帶的 lua 腳本進行 SQL 判斷
(注:MySQL 官方不建議將 MySQL-Proxy用到生產環境)
Amoeba
- 由陳思儒用java語言進行開發
- 作者曾就職于阿里巴巴擔任首席工程師(現已離職)
- 阿里巴巴將其用于生產環境
缺點
- 不支持事務
- 不支持存儲過程
案例
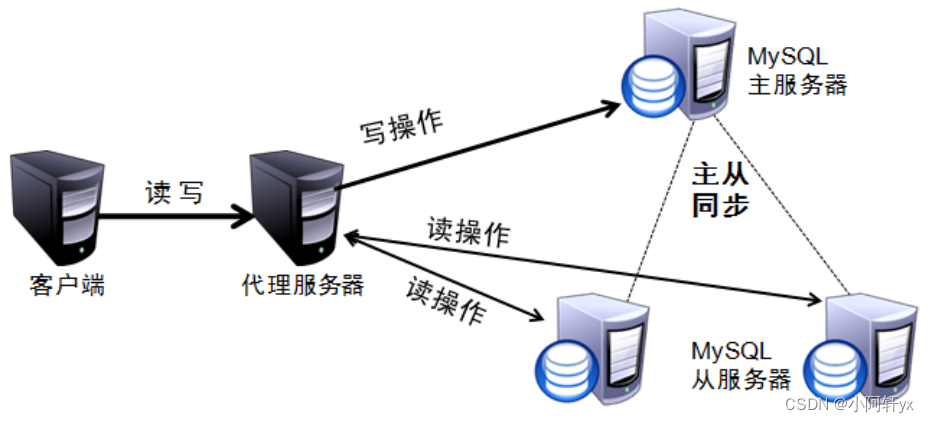

搭建 MySQL 主從復制
需求
通過 Amoeba 實現 MySQL 數據庫請求的讀寫分離
關閉所有服務器的 ffirewalld
[root@localhost ~]# setenforce 0
[root@localhost ~]# systemctl stop firewalld建立時間同步環境
主節點搭建時間同步服務器
安裝NTP
[root@localhost ~]# yum -y install ntp從服務器選擇時間與主機同步
配置 NTP
[root@localhost ~]# vim /etc/ntp.conf
//添加如下兩行
server 127.127.1.0
fudge 127.127.1.0 stratum 8重啟服務
[root@localhost ~]# systemctl restart mysqld
[root@localhost ~]# systemctl enable ntpd登錄 MySQL 程序,給從服務器授權?
[root@localhost ~]# mysql -uroot -ppwd123
mysql> grant replication slave on *.* to 'myslave'@'192.168.10.%' identified by '123456' ;
mysql> flush privileges;
mysql> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 337 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.01 sec)配置從服務器
[root@localhost ~]# vim /etc/my.cnf在[mysqld]模塊中修改或添加:
##修改,值不能和其他mysql服務器重復
server-id = 22
##添加(可不指定)
relay-log=relay-log-bin
##添加(可不指定)
relay-log-index=slave-relay-bin.index--relay-log=name????中繼日志的文件的名字
?--relay-log-index=name??????MySQL slave 在啟動時需要檢查relay log index 文件中的relay log信息,此處定義該索引文件的名字
重啟服務
[root@localhost ~]# systemctl restart mysqld登錄MySQL,配置同步
[root@localhost ~]# mysql -uroot -ppwd123
mysql> change master to master_host='192.168.10.101',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=337;
Query OK,0 rows affected,2 warnings (0.05 sec)啟動同步
mysql> start slave;注:如果后面加了分號,顯示的最后一行會提示ERROR: No query specified,當然,這沒有任何影響
查看 Slave 狀態,確保以下兩個值為 YES
##注意后面不要加分號
mysql> show slave status\G
*********1.row*********
//省略部分內容
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
//省略部分內容
...
1 row in set (0.00 sec)驗證主從復制
在主從服務器上分別查詢數據庫
[root@localhost ~]# mysql -uroot -ppwd123
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec)在主服務器上創建數據庫
mysql> create database test;
Query OK, 1 row affected (0.00 sec)mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| db_test |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)在從服務器上再次查詢數據庫,顯示數據庫相同,則主從復制成功
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| db_test |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)擴展
主主復制
- 將一個 slave1服務器作為另一臺 slave2的master
在slave1 上修改my.cnf
## 在[mysqld]模塊添加
server-id=11
log-bin=master-bin
log-slave-updates=true重啟mysql
[root@localhost ~]# systemctl restart mysqld在slave1上執行以下命令創建一個授權用戶,用于在slave2上鏈接slave1
mysql> grant replication slave on *.* to 'myslave'@'192.168.10.%' identified by '123456' ;
mysql> flush privileges;
mysql> show master status;搭建 Mysql 讀寫分離
Amoeba(變形蟲)
- 開源框架項目
- 于 2008 年發布一款 Amoeba for MySQL 軟件。
- 這個軟件致力于 MySQL的分布式數據庫前端代理層
- 主要為應用層訪問 MySQL 的時候充當SQL路由功能
優勢
- 具有負載均衡
- 高可用性
- SQL過濾
- 讀寫分離
- 可路由到相關的目標數據庫
- 可并發請求多臺數據庫
通過 Amoeba 能夠完成多數據源以下功能
- 高可用
- 負載均衡
- 數據切片
目前 Amoeba 已在很多企業的生產線上使用
在主機amoeba上安裝java環境
[root@localhost ~]# chmod +x jdk-6u14-linux-x64.bin
## 根據提示按 Enter 鍵完成即可
[root@localhost ~]# ./jdk-6u14-linux-x64.bin
[root@localhost ~]# mv jdk1.6.0_14/ /usr/local/jdk1.6## 增加一下配置
[root@localhost ~]# vim /etc/profile
## 添加到最末尾
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH:$JAVA_HOME/bin
export AMOEBA_HOME=/usr/local/amoeba/
export PATH=$PATH:$AMOEBA_HOME/bin[root@localhost local]# source /etc/profile## 查詢版本,確定java安裝成功
[root@localhost local]# java -version
java version "1.6.0 14"
Java(TM) SE Runtime Environment (build 1.6.0 14-b08)
Java HotSpot(TM) 64-Bit Server VM (build 14.0-b16, mixed mode)(Java 環境已配置成功)
安裝并配置 amoeba
[root@localhost local]# mkdir /usr/local/amoeba
[root@localhost ~]# tar zxf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
[root@localhost ~]# chmod -R 755 /usr/local/amoeba/
[root@localhost ~]# /usr/local/amoeba/bin/amoeba
## 有此提示表示成功
amoeba start|stop配置 amoeba 讀寫分離,兩個 Slave 讀負載均衡
Master、Slave1、Slave2三個mysql服務器中開放權限給amoeba訪問(只在master中即可,會復制到slave中)
mysql> grant all on *.* to test@'192.168.10.%' identified by '123.com';在amoeba上配置amoeba.xml文件
[root@localhost ~]# cd /usr/local/amoeba/conf
[root@localhost conf]# vim amoeba.xml## 修改帶有注釋的行部分,此處設置的是mysql客戶端連接amoeba時用的賬號和密碼
<property name="authenticator"><bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">##30行<property name="user">amoeba</property>##32行<property name="password">123456</property></property>.......略......<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter"><property name="LRUMapSize">1500</property>##115行<property name="defaultPool">master</property>##118行<property name="writePool">master</property>##119行此處的注釋去掉<property name="readPool">slaves</property><property name="needParse">true</property></queryRouter>編輯 Server.xml 文件
[root@localhost conf]# vim dbServers.xml
修改(注意去掉注釋),slave2的復制一個slave1<!-- mysql user -->##26行<property name="user">test</property>##29行,去掉注釋符<property name="password">123.com</property></factoryConfig>......略......##45行<dbServer name="master" parent="abstractServer"><factoryConfig><!-- mysql ip -->##48行<property name="ipAddress">192.168.1.101</property> </factoryConfig></dbServer>##52行<dbServer name="slave1" parent="abstractServer"><factoryConfig><!-- mysql ip -->##55行<property name="ipAddress">192.168.1.102</property></factoryConfig></dbServer><dbServer name="slave2" parent="abstractServer"><factoryConfig><!-- mysql ip --><property name="ipAddress">192.168.1.103</property></factoryConfig></dbServer>##59行<dbServer name="slaves" virtual="true"><poolConfig class="com.meidusa.amoeba.server.MultipleServerPool"><!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA--><property name="loadbalance">1</property><!-- Separated by commas,such as: server1,server2,server1 -->##65行<property name="poolNames">slave1,slave2</property> </poolConfig></dbServer>啟動 amoeba 軟件
[root@localhost ~]# cd /usr/local/amoeba/
[root@localhost amoeba]# bin/amoeba start&注:當在前臺運行某個作業時,終端被該作業占據;而在后臺運行作業時,它不會占據終端。可以使用&命令把作業放到后臺執行
如果能看到 8066 和 3306端口,證明 amoeba 是正常開啟
[root@localhost amoeba]# netstat -anpt | grep java
tcp6 0 0 127.0.0.1:51388 ...* LISTEN 31083/java
tcp6 0 0 :::8066 ...* LISTEN 31083/java
tcp6 0 0 192.168.8.100:58748 192.168.8.139:3306 ESTABLISHED 31083/java
tcp6 0 0 192.168.8.100:37810 192.168.8.134:3306 ESTABLISHED 31083/java
tcp6 0 0 192.168.8.100:56066 192.168.8.136:3306 ESTABLISHED 31083/iava
測試
在 client 主機上
[root@localhost ~]# yum -y install mysql通過代理訪問 MySQL?
[root@localhost ~]# mysql -u amoeba -p 123456 -h 192.168.10.104 -P 8066
## 密碼:123456
Enter password:
MySQL [(none)]>若在連接“192.168.1.110”時報如下錯誤
MySQL [(none)]>show databases;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
1437053119Connection id:
Current database:*** NONE ***
ERROR 2013 (HY000): Lost connection to MySQL server during query
MySQL [(none)]>同時,在 Amoeba 的服務器上面有如下報錯日志
amoeba Could not create a validated object, cause: ValidateObject failed是因為 dbServers.xm 中的用戶,需要在主從機上分配權限。
同時注意該文件中
<!-- mysql schema --><property name="schema">test</property>test數據庫肯定是要存在的。
在 Master、Slave1 和 Slave2 上面創建 test 數據庫,就可以解決此問題。?
在 master 服務器上創建表
mysql> stop slave;
MySQL [test]> use auth
MySQL [auth]> create table users (id int(10),name char(20));
Query Ok, 0 rows affected (0.16 sec)分別在兩臺服務器上執行操作
mysql> stop slave;在主服務器上
mysql> insert into users values ('2','zhangsan');
Query OK,1 rows affected (0.06 sec)從服務器同步了表,手動插入其它內容
slave1:
mysql> use auth;
mysql>insert into users values ('2','zhangsan');slave2:
mysql> use auth;
mysql> insert into users values ('3','zhangsan);在客戶機上查詢3次
mysql> use auth;
mysql> select * from users;對比三次的輸出,驗證讀操作,發現沒有在master寫入的數據,而slave上寫的能查到
在客戶機上
mysql> use auth;
mysql>insert into users values ('4','zhangsan');
##發現在client上查詢不到自己寫的數據
mysql> select * from users;在主服務器上
##能查到在client上寫入的數據,說明寫操作在master上
mysql> select * from users;在從服務器上
##發現沒有數據,說明寫入的操作是在master上
mysql> select * from users;由此驗證,已經實現了 MySQL讀寫分離
目前所有的寫操作都全部在 Master 主服務器上,用來避免數據的不同步;所有的讀操作都分攤給了 Slave 從服務器,用來分擔數據庫壓力。
小阿軒yx-案例:MySQL主從復制與讀寫分離




)


-->深度剖析(二))

)
)
)


的目錄,請檢查網絡設置)
gawk進階)



