期刊:CVPR
年份:2024
代碼:http://https: //github.com/THU-MIG/RepViT
摘要
最近,與輕量級卷積神經網絡(CNN)相比,輕量級視覺Transformer(ViTs)在資源受限的移動設備上表現出了更高的性能和更低的延遲。研究人員已經發現了輕量級ViT和輕量級CNN之間的許多結構聯系。然而,它們之間在塊結構、宏觀和微觀設計上的顯著差異并沒有得到充分的研究。在本研究中,我們從ViT的角度重新審視輕量級CNN的高效設計,并強調其在移動設備上的廣闊前景。具體來說,我們通過集成輕量級vit的高效架構設計,逐步增強了標準輕量級CNN(即MobileNetV3)的移動友好性。這就產生了一個新的純輕量級CNN家族,即RepViT。大量的實驗表明,RepViT優于現有的最先進的輕型ViT,并在各種視覺任務中表現出良好的延遲。值得注意的是,在ImageNet上,RepViT在iPhone 12上以1.0 ms的延遲實現了超過80%的top-1精度,據我們所知,這是輕量級模型的第一次。此外,當RepViT遇到SAM時,我們的RepViT-SAM的推理速度比先進的MobileSAM快近10倍。
Introduction
輕量級CNN的發展:過去十年中,研究人員主要關注輕量級CNN,并取得了顯著進展。提出了許多高效設計原則,如可分離卷積、反向殘差瓶頸、通道洗牌和結構重參數化等,這些原則促成了MobileNets、ShuffleNets和RepVGG等代表性模型的發展。
輕量級ViTs的探索:盡管直接減小ViT模型的大小以適應移動設備的約束是可能的,但這樣做往往會降低性能,使其不如輕量級CNN。因此,研究人員開始探索輕量級ViTs的設計,目標是超越輕量級CNN的性能。
輕量級ViTs和CNNs的比較:盡管輕量級ViTs和輕量級CNNs在某些結構上具有相似性,例如都采用卷積模塊來學習空間局部表示,但它們在塊結構、宏觀/微觀設計上存在顯著差異,這些差異尚未得到充分的檢查。
主要貢獻:
-
新的輕量級CNN架構RepViT:提出了一種新的輕量級CNN架構,名為RepViT,它通過整合輕量級ViTs的高效架構設計,旨在為資源受限的移動設備提供高性能的模型。
-
性能與延遲的優化:RepViT在保持低延遲的同時,實現了超越現有最先進輕量級ViTs和CNNs的性能,特別是在ImageNet數據集上達到了超過80%的top-1準確率,且在iPhone 12上的延遲僅為1.0毫秒。
-
架構設計的創新:文章詳細介紹了RepViT架構的設計過程,包括塊設計、宏觀設計和微觀設計,這些設計決策共同促進了模型性能的提升和延遲的降低。
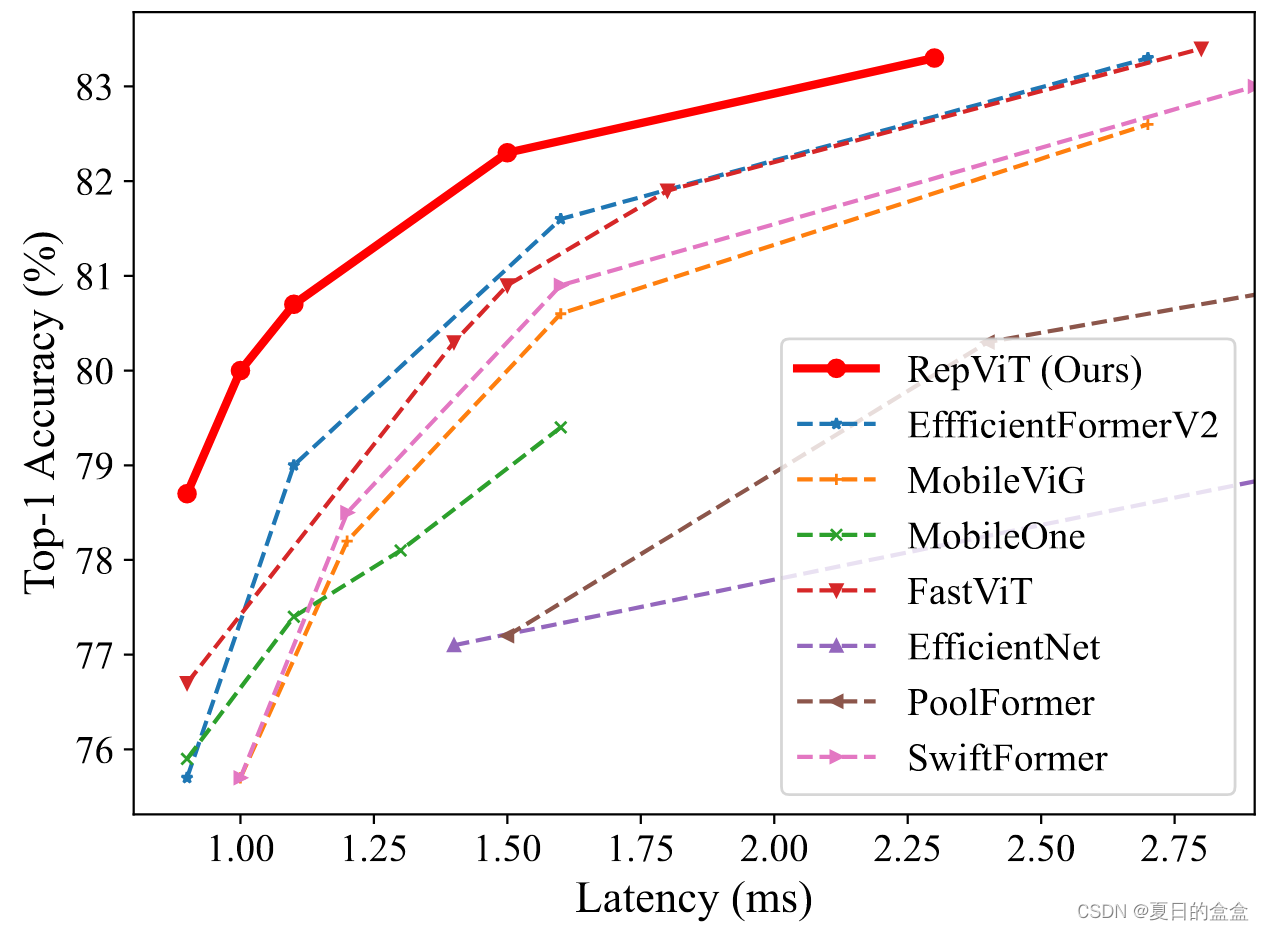
延遲 vs 準確性:
Method
2.1 預備知識
延遲度量:作者選擇在移動設備上的實際延遲作為模型性能評估的基準,而不是傳統的FLOPs或模型大小,因為這些指標與移動應用中的實際延遲相關性不高。
訓練對齊:為了公平比較,作者將MobileNetV3-L的訓練與現有的輕量級ViTs對齊,包括使用AdamW優化器、余弦學習率調度器、數據增強技術如Mixup、自動增強和隨機擦除,以及標簽平滑作為正則化方案。
2.2 塊設計
2.2.1 Separate token mixer and channel mixer
動機:輕量級ViTs的一個關鍵設計特征是將Token Mixer和Channel Mixer分開。這種分離基于MetaFormer架構,已被證明對ViTs的有效性至關重要。

如圖2(a)所示:
- 在MobileNetV3-L中,原始的塊結構采用1×1擴展卷積和1×1投影層來實現通道間的交互(即Channel Mixer),并在1×1擴展卷積之后使用3×3深度卷積(DW)來融合空間信息(即Token Mixer)。這種設計將Token Mixer和Channel Mixer耦合在一起。
- 為了分離它們,作者首先將DW卷積上移,并在DW之后放置可選的Squeeze-and-Excitation(SE)層,因為SE層依賴于空間信息的交互。(通過將DW卷積移動到1×1擴展卷積之前,我們可以首先對每個通道進行空間混合,然后再通過1×1卷積進行通道混合。這樣,空間信息的混合和通道信息的混合就不再是順序依賴的,而是可以獨立進行。)
- 采用結構重參數化技術來增強模型在訓練期間的學習能力。這種技術允許在推理過程中消除跳躍連接帶來的計算和內存成本,這對移動設備尤其有利。
擴展閱讀:
擴展卷積(Expansion Convolution):處理通道信息
- 擴展卷積通常用于CNN中的“擴展層”或“瓶頸層”,其目的是在不顯著增加參數數量的情況下增加特征圖的維度。
- 在MobileNetV2和MobileNetV3等架構中,擴展卷積通過1×1的卷積操作來實現通道數的增加,這有助于在后續的深度卷積層中捕獲更豐富的特征。
深度卷積(Depthwise Convolution):處理空間信息
- 深度卷積是一種對輸入特征圖的每個通道分別應用的卷積操作,每個通道的卷積核獨立于其他通道。
- 這種卷積方式可以增加特征圖的空間維度,同時保持較低的計算成本,因為它允許每個輸入通道獨立地學習空間特征。
- 在MobileNet系列架構中,深度卷積通常與擴展卷積結合使用,以實現有效的特征提取和降維。
投影(Projection Layer):
- 投影層通常指的是1×1的卷積層,它用于調整特征圖的通道數,而不會改變其空間維度。
- 在某些CNN架構中,如MobileNetV1,投影層用于在深度卷積后減少特征圖的通道數,以降低后續層的計算負擔。
- 在Transformer架構中,投影層也可以用于將多頭自注意力(Multi-Head Self-Attention, MHSA)模塊的輸出投影回原始維度,以準備進行下一輪的自注意力計算。
拓展閱讀2:
Token Mixer:
- 在ViT中,Token Mixer通常指的是多頭自注意力機制(MHSA),它允許模型在不同位置的輸入特征(tokens)之間建立聯系,通過注意力權重來強調某些特征。這種機制有助于模型捕獲全局上下文信息。
Channel Mixer:
- Channel Mixer通常指的是在特征的通道維度上進行混合的操作,如1×1的卷積,它允許模型在保持空間位置不變的同時,重新分配和組合不同通道的特征信息。
分開的原因:
- 在一些傳統的ViT架構中,Token Mixer和Channel Mixer可能是結合在一起的,這意味著它們在同一個操作中同時發生。然而,這種耦合可能不利于模型的效率和靈活性,尤其是在需要處理不同分辨率或在資源受限的設備上運行時。
效果:將 MobileNetV3-L 的延遲降低到 0.81 ms,以及臨時性能下降到 68.3%。?
2.2.2?Reducing expansion ratio and increasing width
擴展比(Expansion Ratio):擴展比是指在網絡中的某些層,特別是卷積層或前饋網絡(Feed Forward Network, FFN)中,輸出通道數與輸入通道數的比例。例如,如果一個層的擴展比是4,那么它的輸出通道數是輸入通道數的4倍。
擴展比的調整:
在傳統的ViT中,FFN模塊的擴展比通常設置為4,這意味著FFN的隱藏維度是輸入維度的4倍。這種設計雖然有助于捕獲復雜的特征,但也導致了計算資源的大量消耗。
網絡寬度(Width):網絡寬度指的是網絡中通道的數量。增加網絡寬度可以提供更多的特征表示能力,有助于提高模型的性能。
寬度的調整:
為了補償降低擴展比帶來的參數減少,作者提出增加網絡的寬度。例如,在每個階段之后加倍通道數,從而在保持或提高性能的同時,減少模型的延遲。
方案:
RepViT在通道混合器中為所有階段設置擴展比為 2,隨著擴展比較小,我們可以增加網絡寬度來彌補較大的參數減少。我們在每個階段之后對通道進行雙重處理,每個階段最終得到48,96,192和384個通道。
效果:在 0.91 ms 的類似延遲下獲得了 73.0% 的 top-1 準確率的較差性能。
2.3?宏觀設計
2.3.1?Early convolutions for stem
動機:
Stem是CNN中的第一個卷積層,它負責從原始圖像中提取初步的特征表示。在ViT和一些輕量級CNN中,Stem通常使用patchify操作,將輸入圖像分割成小塊。Patchify操作雖然簡單,但可能導致優化問題和對訓練配置的敏感性。這是因為它將圖像分割成固定大小的非重疊塊,這可能不利于模型學習有效的特征表示。
為了解決上述問題,引入了早期卷積的概念。這種方法使用幾個stride為2的3×3卷積層作為Stem,以替代傳統的patchify操作。
早期卷積的優勢:使用早期卷積可以提高優化穩定性和性能。這是因為較小的卷積核可以更好地捕捉局部特征,并且多層堆疊可以逐漸增加感受野,從而有助于模型學習更豐富的特征表示。
實現細節:在RepViT架構中,作者采用了兩個3×3卷積層,步長為2,作為Stem。第一個卷積層的過濾器數量設置為24,第二個卷積層設置為48。

效果:整體延遲降低到 0.86 ms。top-1 準確率提高到 73.9%。?
?2.3.2?Deeper downsampling layers
動機:在CNN中,下采樣層負責減少特征圖的空間維度,同時增加特征的深度,這有助于模型捕獲不同尺度的特征并減少計算量。在標準的ViT和一些輕量級CNN中,下采樣通常由單獨的層完成,例如通過步長大于1的卷積或池化操作。然而,這種簡單的下采樣可能會導致信息丟失,影響模型性能。
深化下采樣層的策略:
通過增加下采樣層的深度來提高網絡的性能。這包括使用多個連續的卷積層來逐步降低特征圖的分辨率,同時增加特征的深度。
具體實現:
- 在RepViT中,作者首先使用一個步長為2的深度卷積(DW convolution)進行空間下采樣,然后使用一個1×1的逐點卷積(pointwise convolution)來調整通道維度。
- 為了進一步加深下采樣層并捕獲更多的信息,作者在逐點卷積后添加了一個前饋網絡(FFN)模塊,以記憶更多的潛在信息。

MobileNetV3-L僅通過步長為 = 2 的 DW 卷積,可能缺乏足夠的網絡深度,導致信息丟失和對模型性能的負面影響。因此,為了實現單獨和更深的下采樣層,我們首先使用stride = 2和pointwise 1 × 1卷積的DW卷積分別進行空間下采樣和調制通道維度。
效果:將 top-1 準確率提高到 75.4%,延遲為 0.96 ms。
2.3.3?Simple classifier
動機:
分類器是CNN架構中的最后部分,負責將特征轉換為最終的類別預測。在傳統的CNN中,分類器通常包括全連接層、全局平均池化層或類似的結構。在一些現有的輕量級CNN中,分類器可能包含額外的卷積層和全連接層,這些設計雖然可以提高特征的表達能力,但也增加了計算復雜度和延遲。
簡化分類器的設計:
使用更簡單的分類器設計,以減少計算量并降低延遲。這種設計通常包括全局平均池化層(Global Average Pooling, GAP)后接一個線性層。
- 全局平均池化層可以有效地將特征圖轉換為一維特征向量,同時顯著減少參數數量和計算量。這種操作對于減少模型大小和提高推理速度非常有益。
- 在全局平均池化之后,一個線性層(通常是一個全連接層)用于將池化后的特征映射到最終的類別上。這種設計簡單且有效。
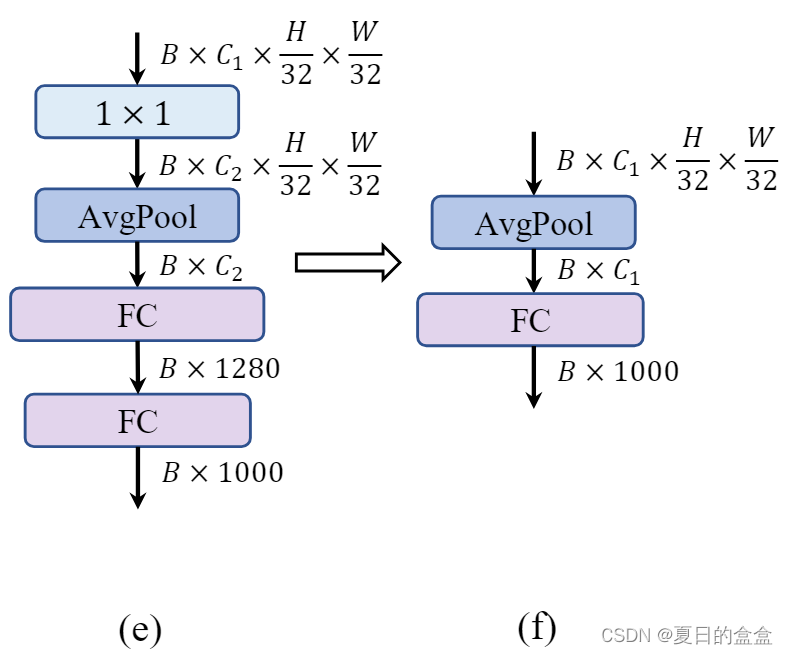
效果:精度下降 0.6%,但延遲降低到 0.77 ms。?
2.3.4?Overall stage ratio
階段比率(Stage Ratio):階段比率是指網絡中不同階段的層數或塊數的比例。這個比例對網絡的性能和計算效率有重要影響。
動機:在第三階段使用更多的層數可以帶來準確性和速度之間的良好平衡。現有的輕量級ViTs通常在第三階段應用更多的塊,以實現更好的性能。
對網絡采用 1:1:7:1 的階段比率。然后,我們將網絡深度增加到 2:14:2,實現更深的布局。
效果:將 top-1 準確率提高到 76.9%,延遲為 0.91 ms。
2.4 微觀設計
2.4.1?Kernel size selection
動機:
- 卷積核的大小直接影響CNN的性能和計算效率。較大的卷積核可以捕獲更廣泛的上下文信息,但會增加計算復雜度和延遲,特別是在移動設備上。
- 一些研究工作,如ConvNeXt和RepLKNet,展示了使用大卷積核可以提高性能,但這些研究通常不針對移動設備優化。
在移動設備上,由于計算資源和內存訪問成本的限制,大卷積核可能不是最優選擇。此外,編譯器和計算庫通常對3×3卷積核有更高度的優化。
效果:保持76.9%的最高精度,同時延遲降低到0.89 ms。
2.4.2?Squeeze-and-excitation layer placement
動機:
- SE層作為一種通道注意力模塊,可以彌補卷積在缺乏數據驅動屬性方面的局限性,帶來更好的性能。
- 盡管SE層能夠提升性能,但它也會引入額外的計算成本。因此,在設計輕量級模型時,需要仔細考慮SE層的放置,以平衡性能增益和計算效率。
先前研究的啟示:引用了先前的研究,指出在低分辨率特征圖的階段使用SE層可能不會帶來顯著的準確率提升,而在高分辨率特征圖的階段使用SE層則可以更有效地提升性能。
具體方案:
在RepViT中,采用了一種跨塊的SE層放置策略。具體來說,每個階段中的第1、3、5...個塊使用SE層,這種交錯放置方式旨在最大化準確率的提升,同時控制延遲的增加。
效果:準確率達到77.4%,延遲為0.87 ms。
拓展閱讀:
SE模塊:
Squeeze:
- 這一步驟通過全局平均池化(Global Average Pooling, GAP)將特征圖壓縮成一個單一的通道。這意味著無論特征圖的空間維度有多大,都會被壓縮成一個包含所有空間信息的單一數值。
- 這種壓縮操作生成了一個長度為1的全局特征向量,它捕獲了輸入特征圖的全局空間信息。
Excitation:
- 接下來,這個全局特征向量通過幾個全連接(FC)層進行非線性變換,通常包括一個ReLU激活函數和一個sigmoid激活函數。
- ReLU層引入非線性,而sigmoid層則將輸出值壓縮到0和1之間,生成一個與輸入通道數相同長度的權重向量。

Result
如表所示,RepViT在各種模型大小上始終實現最先進的性能。在類似的延遲情況下,RepViTM0.9可以顯著優于EfficientFormerV2-S0和fastvitt - t8,準確率分別提高3.0%和2.0%。與EfficientFormerV2-S1相比,repviti - m1.1還可以獲得1.7%的性能提升。值得注意的是,repviti - m1.0在iPhone 12上以1.0 ms的延遲實現了超過80%的top-1精度,據我們所知,這是輕量級機型的第一次。我們最大的模型,repviti - m2.3,獲得83.7%的準確率,只有2.3毫秒的延遲。以上結果很好地表明,通過結合高效的架構設計,純輕量級cnn可以在移動設備上優于現有的最先進的輕量級vit。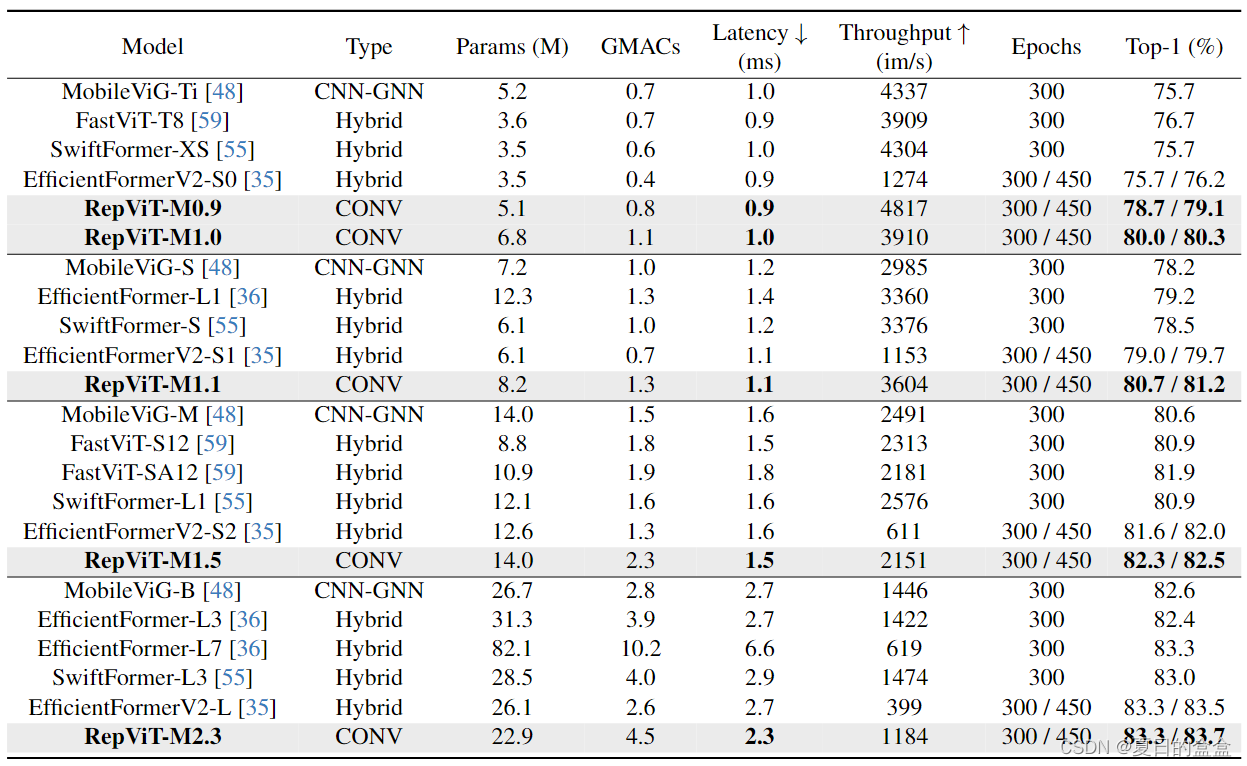 ?Conclusion
?Conclusion
在本文中,我們通過結合輕量級vit的架構設計來重新審視輕量級cnn的高效設計。這就產生了RepViT,這是一個針對資源有限的移動設備的新型輕量級cnn系列。在各種視覺任務上,RepViT優于現有的最先進的輕量級vit和cnn,表現出良好的性能和延遲。這凸顯了面向移動設備的純輕量級cnn的前景。我們希望RepViT可以作為一個強大的基線,并激發對輕量級模型的進一步研究。
的目錄,請檢查網絡設置)
gawk進階)





)


)


—網絡加固—防DNS污染和ARP欺騙)


)


