個人博客地址
基于源碼詳解ThreadPoolExecutor實現原理 | iwts’s blog
內容拆分
這里算是一個總集,內容太多,拆分成幾個比較重要的小的模塊:
ThreadPoolExecutor基于ctl變量的聲明周期管理 | iwts’s blog
ThreadPoolExecutor 工作線程Worker自身鎖設計 | iwts’s blog
ThreadPoolExecutor 線程回收時機詳解 | iwts’s blog
Java ThreadPoolExecutor
線程池,Thread Pool,是一種基于池化思想管理線程的工具,一般是多線程服務器中使用很多,例如MySQL。
線程過多會帶來額外的開銷,其中包括創建銷毀線程的開銷、調度線程的開銷等等,同時也降低了計算機的整體性能。
線程池維護多個線程,等待監督管理者分配可并發執行的任務。從而避免了處理任務時創建銷毀線程開銷的代價,另一方面避免了線程數量膨脹導致的過分調度問題,保證了對內核的充分利用。
- 降低資源消耗:重復利用已創建的線程,降低線程創建和銷毀造成的損耗。
- 提高響應速度:任務到達時,無需等待線程創建即可立即執行。
- 提高線程的可管理性:無限制創建,不僅會消耗系統資源,還會因為線程的不合理分布導致資源調度失衡,降低系統的穩定性。使用線程池可以進行統一的分配、調優和監控。
- 提供更多更強大的功能:線程池具備可拓展性,允許開發人員向其中增加更多的功能。比如延時定時線程池ScheduledThreadPoolExecutor,允許任務延期執行或定期執行。
ThreadPoolExecutor核心設計

線程池頂級接口Executor
頂層接口Executor提供了一種思想:將任務提交和任務執行進行解耦。用戶無需關注如何創建線程,如何調度線程來執行任務,用戶只需提供Runnable對象,將任務的運行邏輯提交到執行器(Executor)中,由Executor框架完成線程的調配和任務的執行部分。

簡單粗暴,執行就完了。
線程池擴充服務接口ExecutorService
ExecutorService接口增加了一些能力:
-
擴充執行任務的能力,例如
submit(),可以為一個或一批異步任務生成Future。 -
提供了管控線程池的方法,例如
shutdown(),停止線程池的運行。a. 包括狀態監控,例如
isShutdown()。 -
執行流程方法,例如
invokeAll()。
線程池抽象類AbstractExecutorService
將執行任務的流程串聯了起來,保證下層的實現只需關注一個執行任務的方法即可。
ThreadPoolExecutor實現
最復雜的運行部分,ThreadPoolExecutor將會一方面維護自身的生命周期,另一方面同時管理線程和任務,使兩者良好的結合從而執行并行任務。
ThreadPoolExecutor運行流程
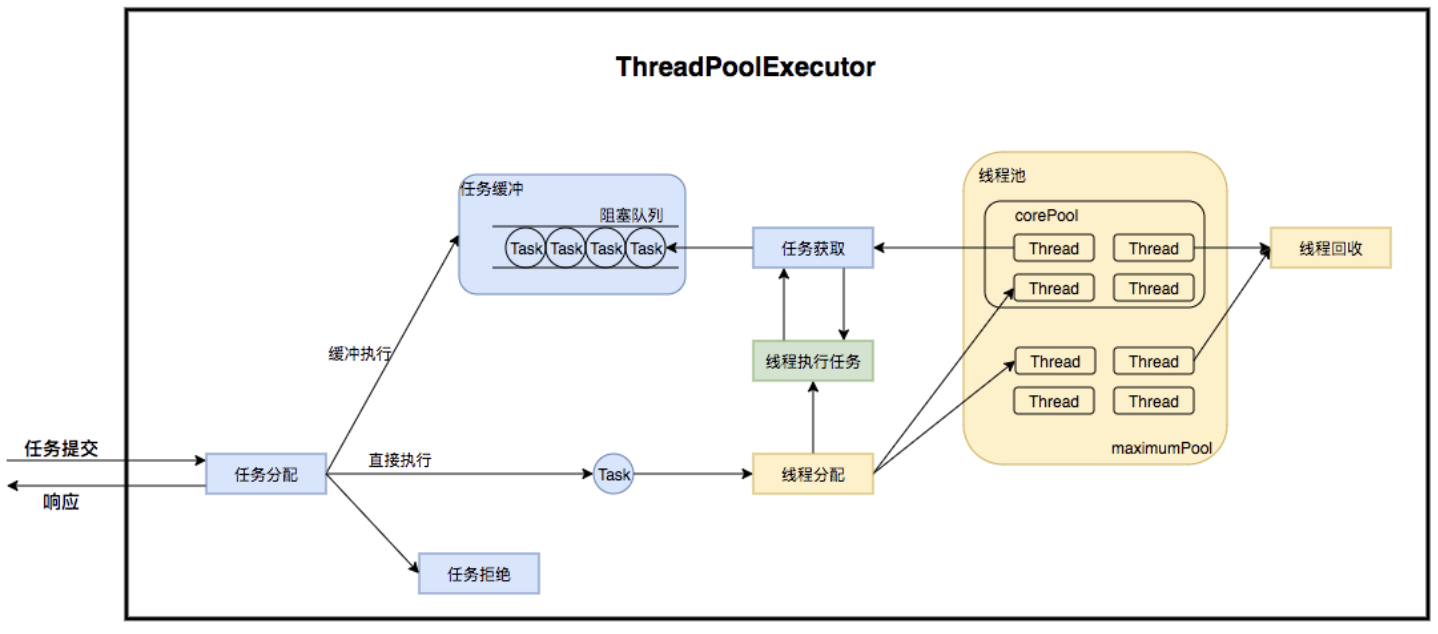
線程池在內部構建了一個生產者消費者模型,將線程和任務兩者解耦,并不直接關聯,從而良好的緩沖任務,復用線程。
線程池的運行主要分成兩部分:
- 任務管理。
- 線程管理。
任務管理部分充當生產者的角色,當任務提交后,線程池會判斷該任務后續的流轉:
- 直接申請線程執行該任務。
- 緩沖到隊列中等待線程執行。
- 拒絕該任務。
線程管理部分是消費者,它們被統一維護在線程池內,根據任務請求進行線程的分配,當線程執行完任務后則會繼續獲取新的任務去執行,最終當線程獲取不到任務的時候,線程就會被回收。
線程池生命周期管理-ctl字段的應用
線程池內部使用一個變量ctl維護兩個值:
- 運行狀態(runState)
- 線程數量 (workerCount)

在具體實現中,就是進行位運算:
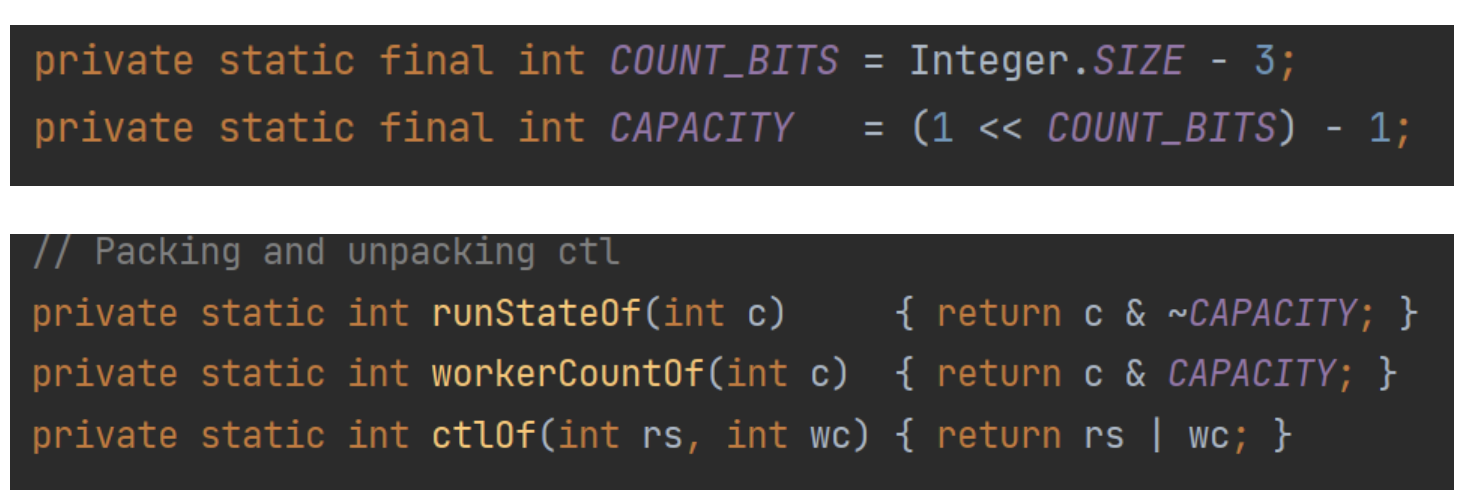
COUNT_BITS如果是32位的話,那么結合下面的一套左移、與、非的位運算,可以總結為:
- ctl的高3位保存runState,即運行狀態。
- ctl的低29位保存workerCount,即有效線程數量。
除了ctl解析方法,還提供ctl計算方法,即根據runState和workerCount,計算出ctl值。
這樣合并的好處是,操作的時候單鎖就可以處理了(CAS也非常方便),位運算速度也快。
線程池運行狀態
| 運行狀態 | 運行狀態 | desc |
|---|---|---|
| running | 運行 | 能接收新任務,能處理隊列任務 |
| shutdown | 關閉 | 不接受新任務,能處理隊列任務 |
| stop | 停止 | 不接受新任務,不處理隊列任務,中斷處理任務的線程 |
| tidying | 整理 | 所有任務已結束,workerCount=0 |
| terminated | terminated()方法執行后進入該狀態 |

線程池工作流程
任務提交-submit()
就是一個入口方法,但是分為阻塞和非阻塞:
- submit:返回Future對象,底層仍然是execute,Future操作時可能會阻塞。
- execute:常規非阻塞方法,提交后正常執行。
submit是異步編程時可能會用到:
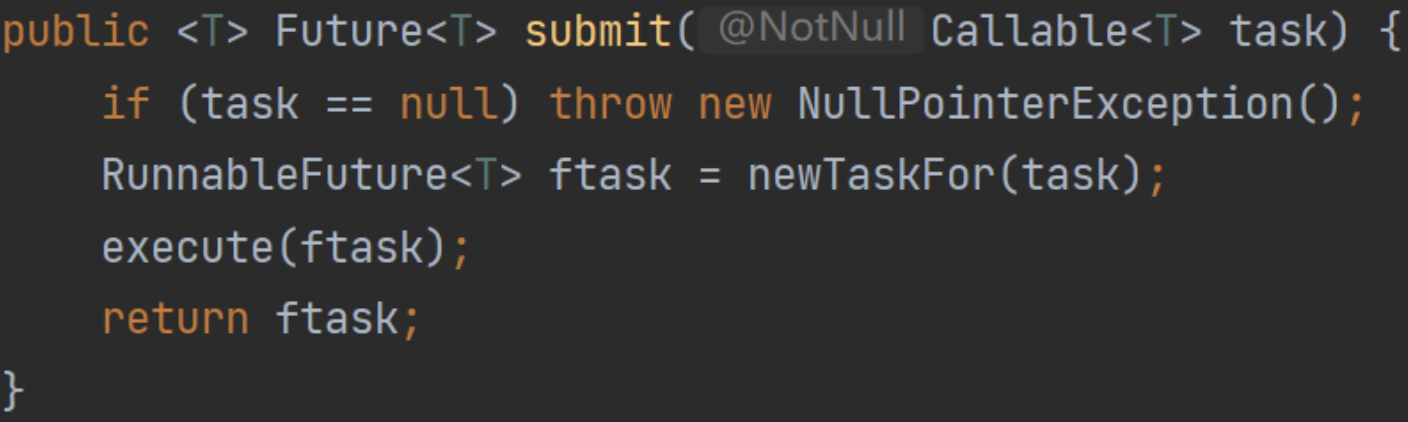
本質上是利用Future,還是普通的調用execute執行,對外透出Future對象。
任務調度-execute()
任務調度是線程池的核心,當用戶提交了一個任務,接下來這個任務將如何執行都是由任務調度來決定。核心入口方法:java.util.concurrent.ThreadPoolExecutor#execute
代碼也并不難:
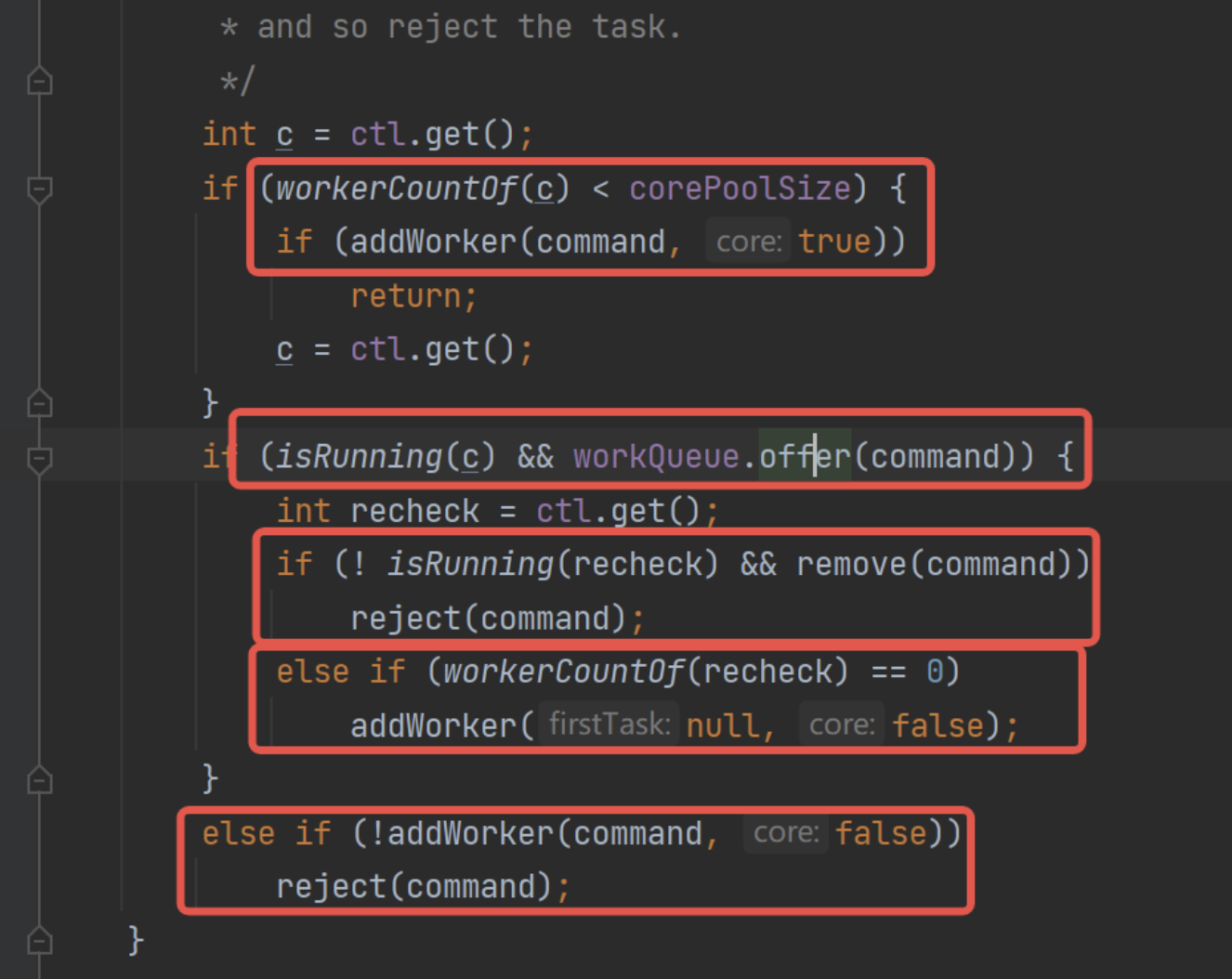
其中reject()方法是拒絕策略,具體參考下面的內容,addWorker()下面工作線程部分詳講,目前需要知道是創建了一個工作線程,入參有Runable對象則說明創建后就用這個線程來執行該對象的任務方法,沒有就說明只是創建線程。
總的流程可以參考:
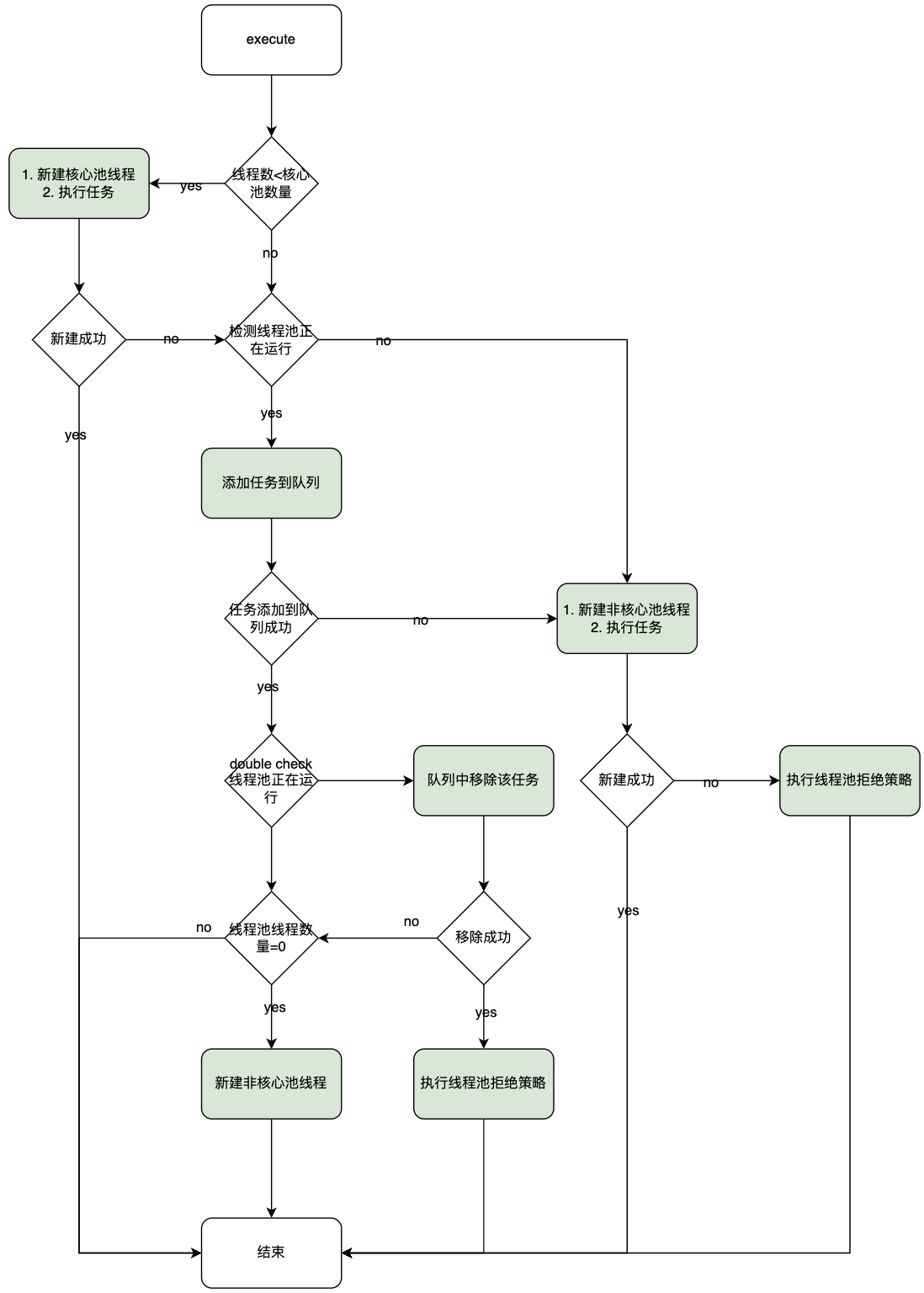
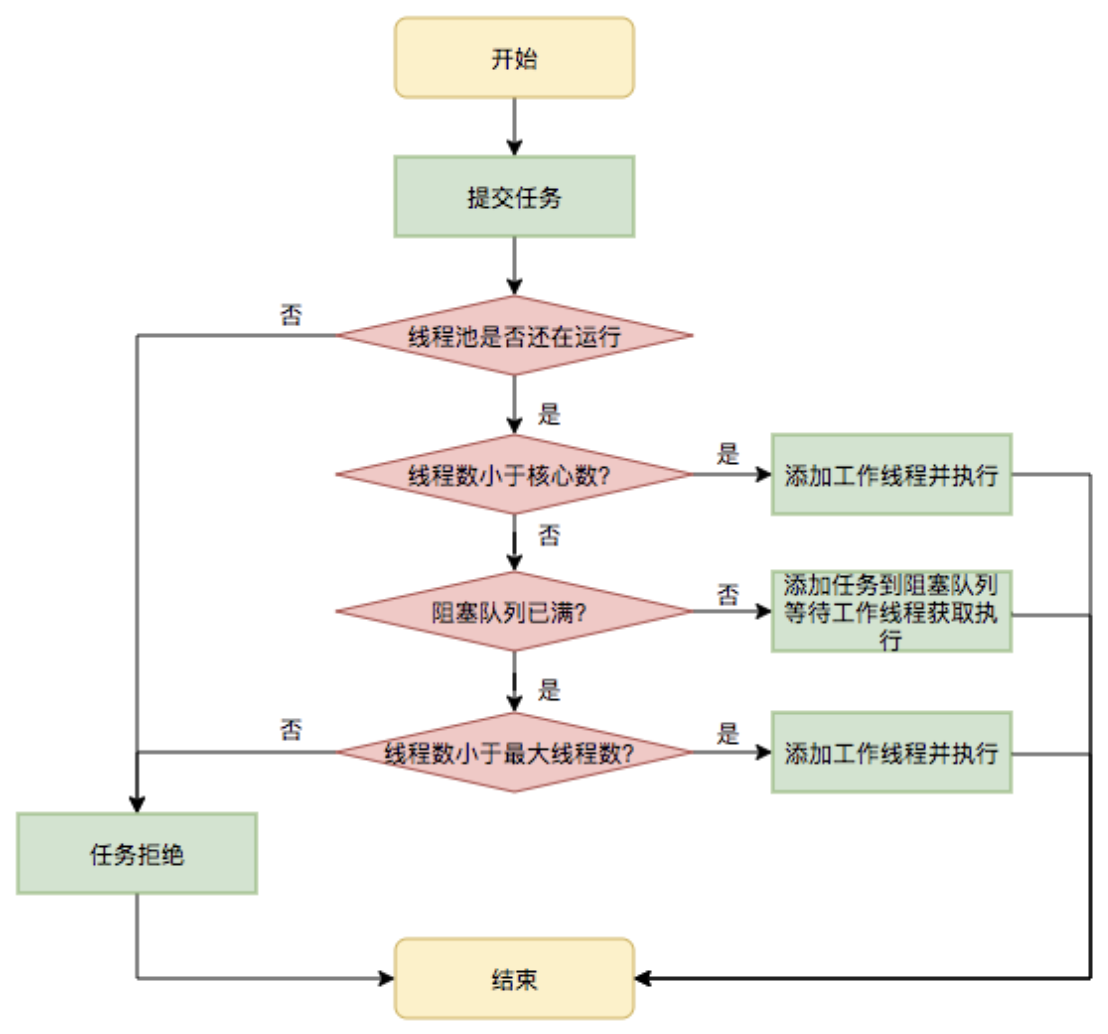
如果從大的方向看,整個execute的調度工作為:
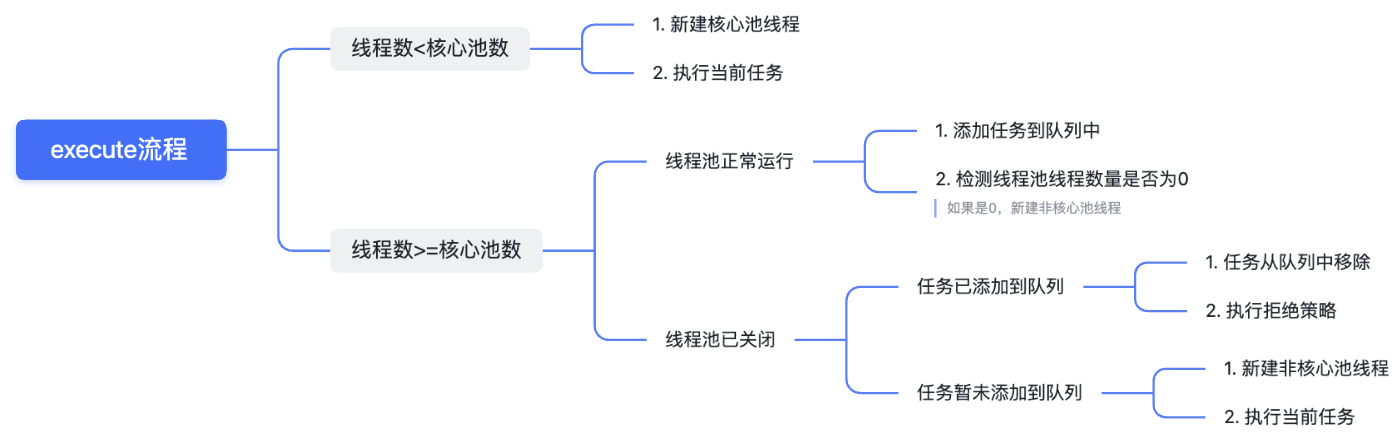
簡而言之:
- 當前線程數量小于核心池數量,創建線程并執行。
- 當前線程數量大于核心池數量,且任務隊列不滿,加入任務隊列。
- 如果任務隊列已經滿了,但是線程池數量小于線程池設定的最大數量,創建一個線程來執行任務。
- 如果比最大數量都大,只能拒絕服務。
任務緩沖模塊設計
任務緩沖模塊是線程池能夠管理任務的核心。
線程池的本質是對任務和線程的管理,而做到這一點最關鍵的思想就是將任務和線程兩者解耦,不讓兩者直接關聯,才可以做后續的分配工作。
線程池中是以生產者消費者模式,通過一個阻塞隊列來實現的。
阻塞隊列緩存任務,工作線程從阻塞隊列中獲取任務。
任務阻塞隊列
緩沖模塊的核心設計了,JUC提供了阻塞隊列框架:BlockingQueue,設計思想如下:

而具體的實現則交給使用者自行選擇,比較簡單的,直接從JUC包的實現中選擇阻塞隊列實現類就可以了。
JUC原生阻塞隊列類型對比
不同阻塞隊列的具體實現類有不同的特性,簡單總結如下:
| 名稱 | 描述 |
|---|---|
| ArrayBlockingQueue | 底層數據結構為數組,隊列大小要主動設置,FIFO。 |
| LinkedBlockingQueue | 底層數據結構為單向鏈表,隊列大小為int最大位,FIFO。 |
| PriorityBlockingQueue | 底層數據結構為數組,無界,按存放對象compareTo指定優先級進出。 |
| DelayQueue | 基于PriorityBlockingQueue,指定延期時間,延期時間到后從隊列中獲取數據。 |
| SynchronousQueue | 不存儲數據,只有在執行take的時候,才會執行put。 |
| LinkedTransferQueue | 跟LinkedBlockingQueue類似,多了transfer相關方法。 |
| LinkedBlockingDeque | 跟LinkedBlockingQueue類似,底層改成雙向鏈表,組成雙向阻塞隊列,高并發時,鎖競爭最多減少一半。 |
任務申請-getTask()
注意不是任務提交。
根據上面任務調度的內容,正常情況下,任務提交后的執行有兩種方式:
- 直接創建新的線程,并去執行任務。
- 線程從任務隊列中獲取任務然后執行,執行完任務的空閑線程會再次去從隊列中申請任務。
一般來說,對于業務請求量較大的系統,大部分情況下都是2,不會額外創建線程。都是丟入隊列就完事。
1的執行時機其實是業務請求的時候,調用submit()或者execute()。那2的執行時機是由線程池保證的。這一塊下面工作線程部分會講到。
那么從任務隊列中挑選一個任務并執行。
這個申請的核心代碼為:getTask()
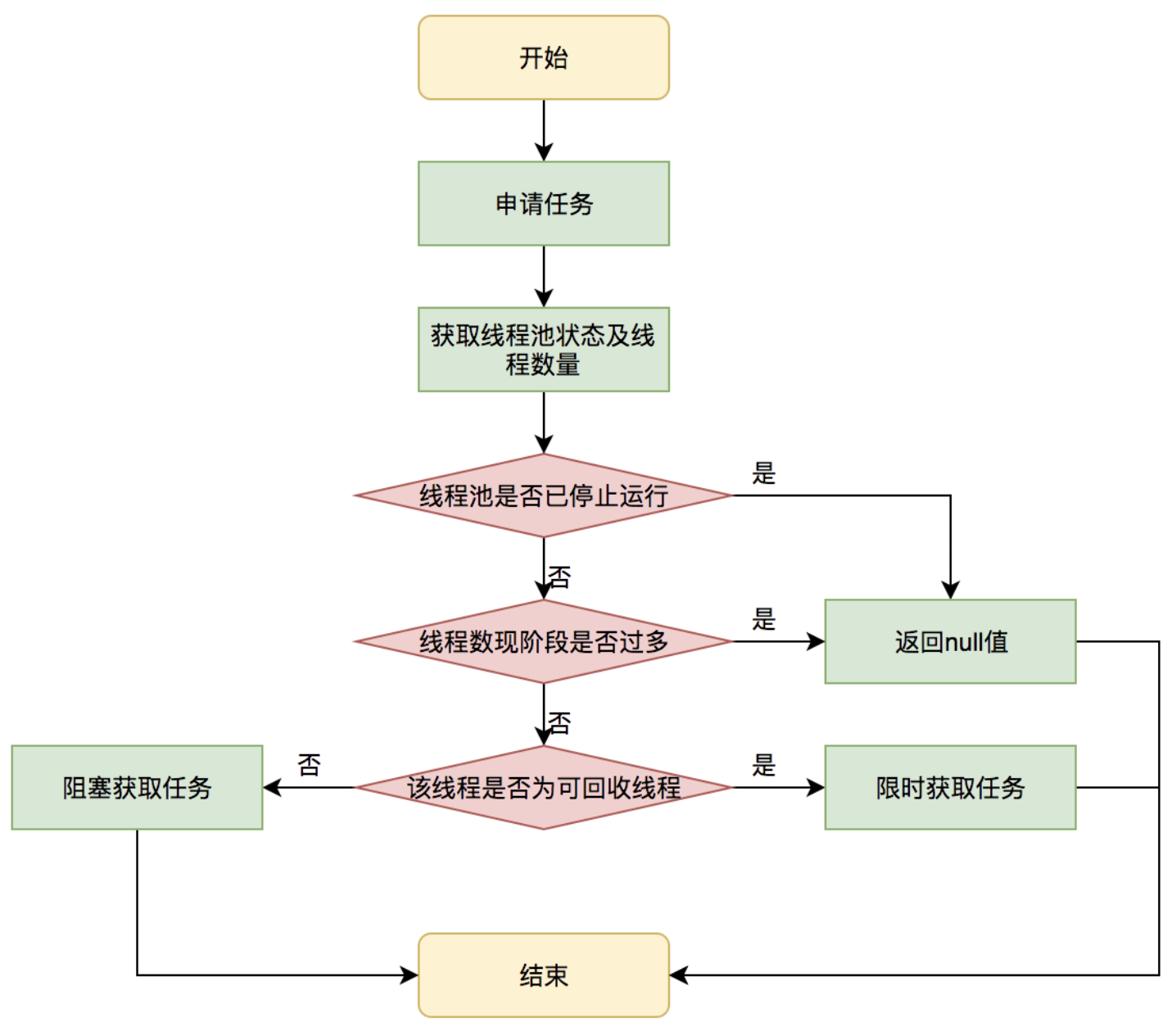
代碼稍微有點長,分成兩批解析:

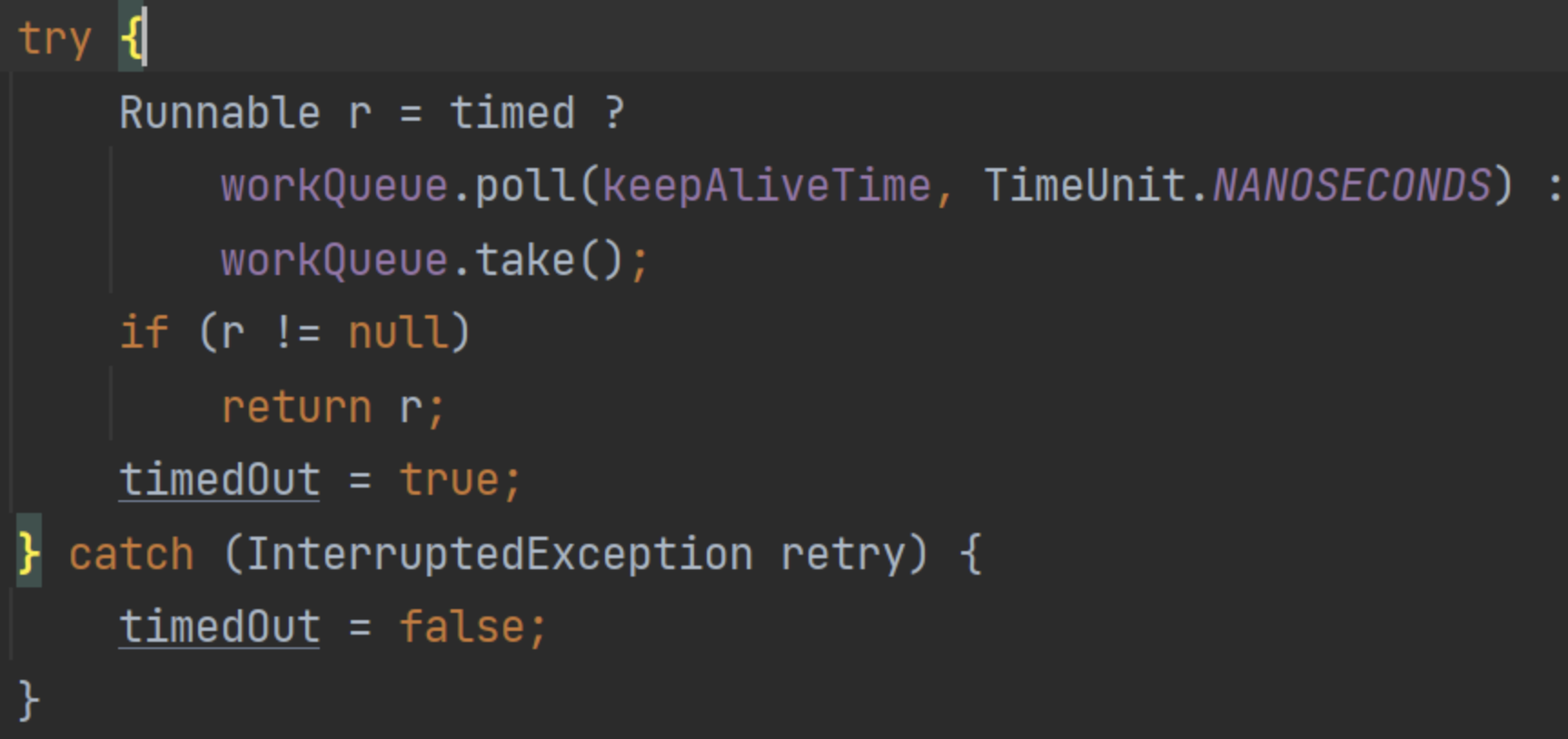
常規隊列維護,通過take()/poll()方法,阻塞/限時阻塞來獲取任務。
任務拒絕-reject()
任務拒絕模塊是線程池的保護部分,參考上面的代碼,當線程池的任務緩存隊列已滿,并且線程池中的線程數目達到maximumPoolSize時,就需要拒絕掉該任務,可以采取任務拒絕策略,以保護線程池。
核心執行方法為:reject()

所以拒絕策略需要實現一個接口RejectedExecutionHandler,其設計如下:

核心是要實現rejectedExecution()方法。
除了我們自定義,JUC也提供了一些常用拒絕策略實現類,對比參考為:
| 對象 | 名稱 | 描述 |
|---|---|---|
| AbortPolicy | 丟棄策略 | 丟棄任務 & 拋出異常。線程池默認拒絕策略。 |
| DiscardPolicy | 丟棄策略 | 丟棄任務,但是不拋出異常。 |
| DiscardOldestPolicy | 丟棄最老任務策略 | 丟棄隊列最前面的任務(最老),然后重新提交被拒絕的任務。 |
| CallerRunsPolicy | 由調用線程來執行任務 | 直接阻塞,由提交任務的線程自己來執行該任務。 |
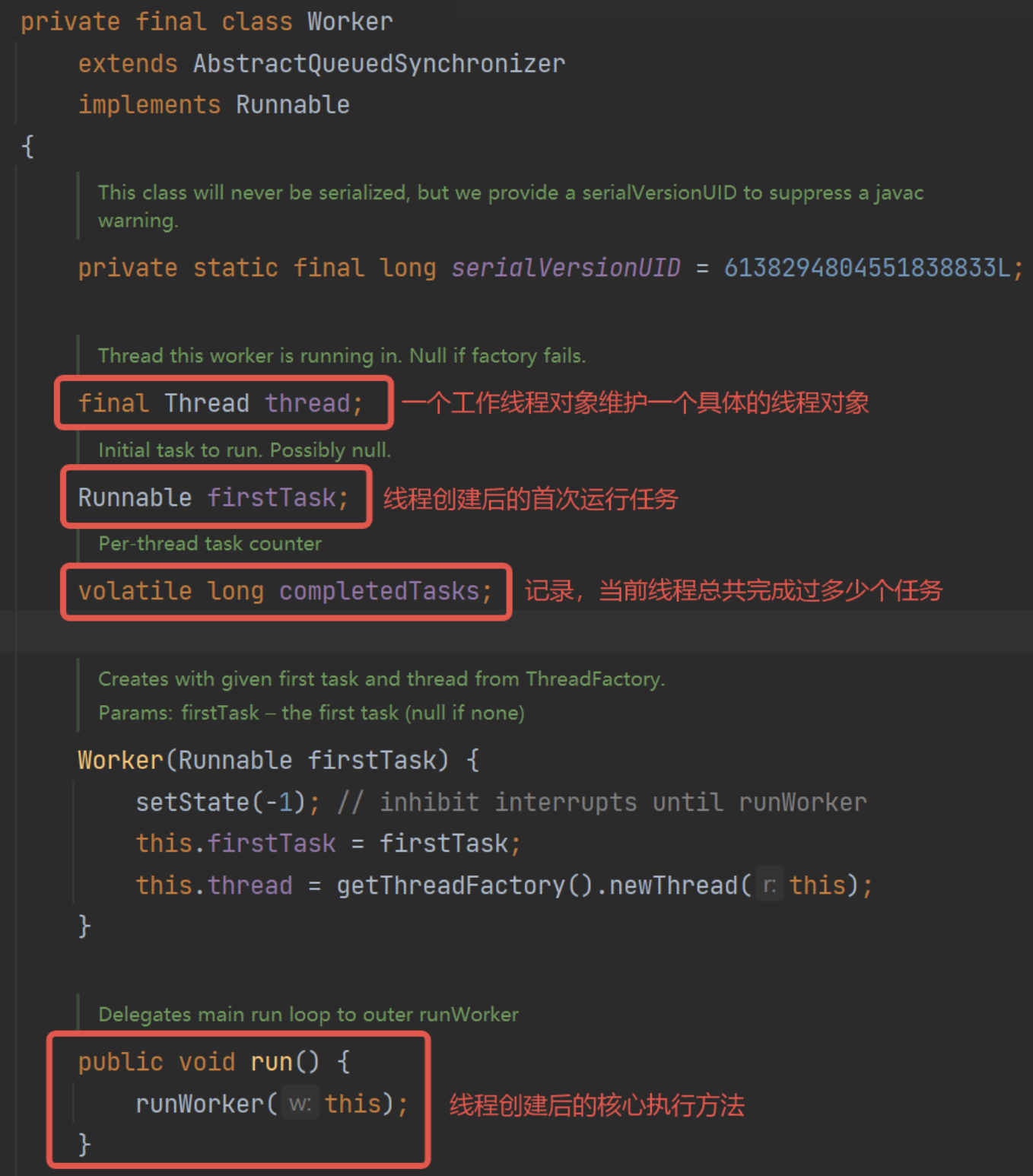
Worker-工作線程管理
線程池設計了內部類Worker,主要是用來管理新建的線程,除了監控,核心的方法是:
- 執行。
- 申請任務。
此外還包括回收等線程監控類型方法。
由于一個工作線程對象,其中有一個具體的線程,那么本質上是不需要加鎖的。競爭資源是任務隊列,而任務隊列由阻塞隊列來實現。
可以看Worker的設計:
線程的創建-addWorker()
結合上面內容,任務在提交的時候,就是線程創建的時機,即核心方法:addWorker()
代碼就不放了,主要是工作隊列的維護。
需要注意的一點:addWorker()本身是不處理任何任務的。上面的流程圖也可以看到,只截了一半,因為addWorker()本身只是新建一個工作線程,并不執行任何任務。
但是,其中的線程被創建后,會在addWorker()方法中start,開啟Worker的真正的執行方法:run方法。
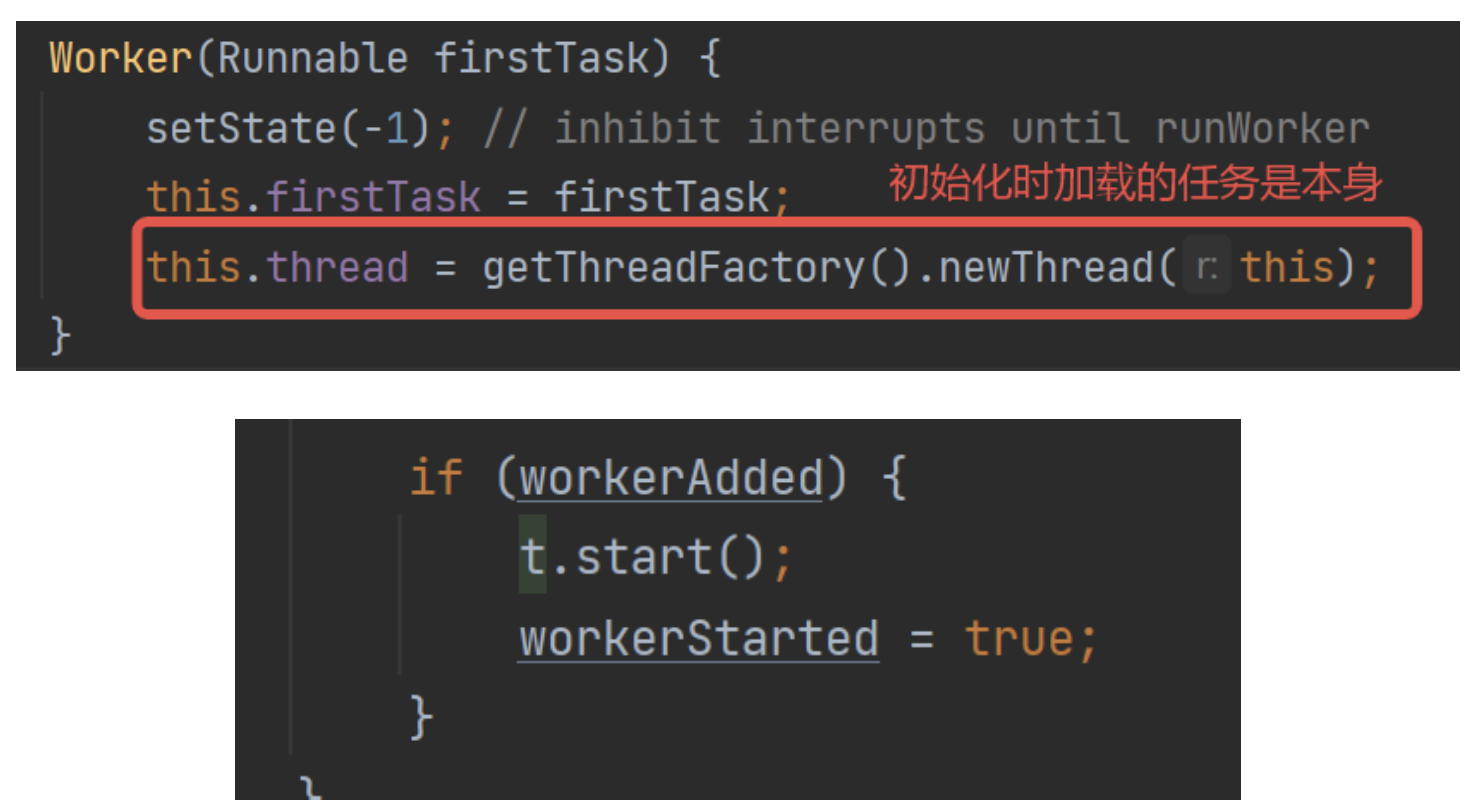
在工作隊列全部維護結束后,start()方法開啟任務,workerStarted=true,宣告工作線程真正執行起來。
線程工廠ThreadFactory
這里也是ThreadPoolExecutor的構造方法了,也可以看到上面的代碼,一個線程的創建都是要走線程工廠的。
可以設定線程大量的數據。
一般是默認,可以看默認配置:

自定義的話,一般是設置一下daemon、線程name,或者有一些特殊操作。
目前個人用的不多。
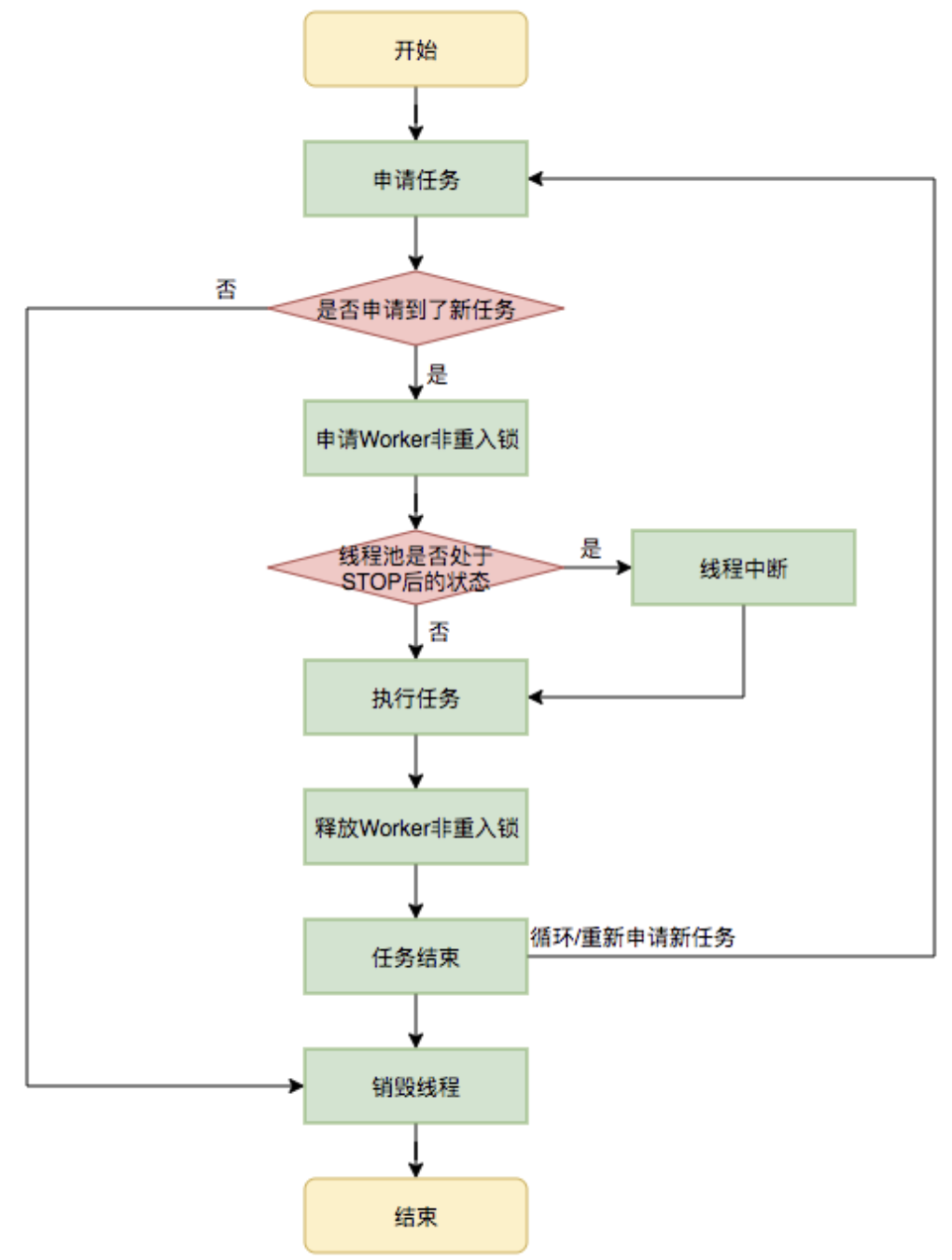
工作線程的執行-runWorker()
上面可以知道,工作線程在創建之后,就直接開啟任務開始執行了,那么Worker的run()方法就是工作線程核心執行方法,實際上就是:runWorker():
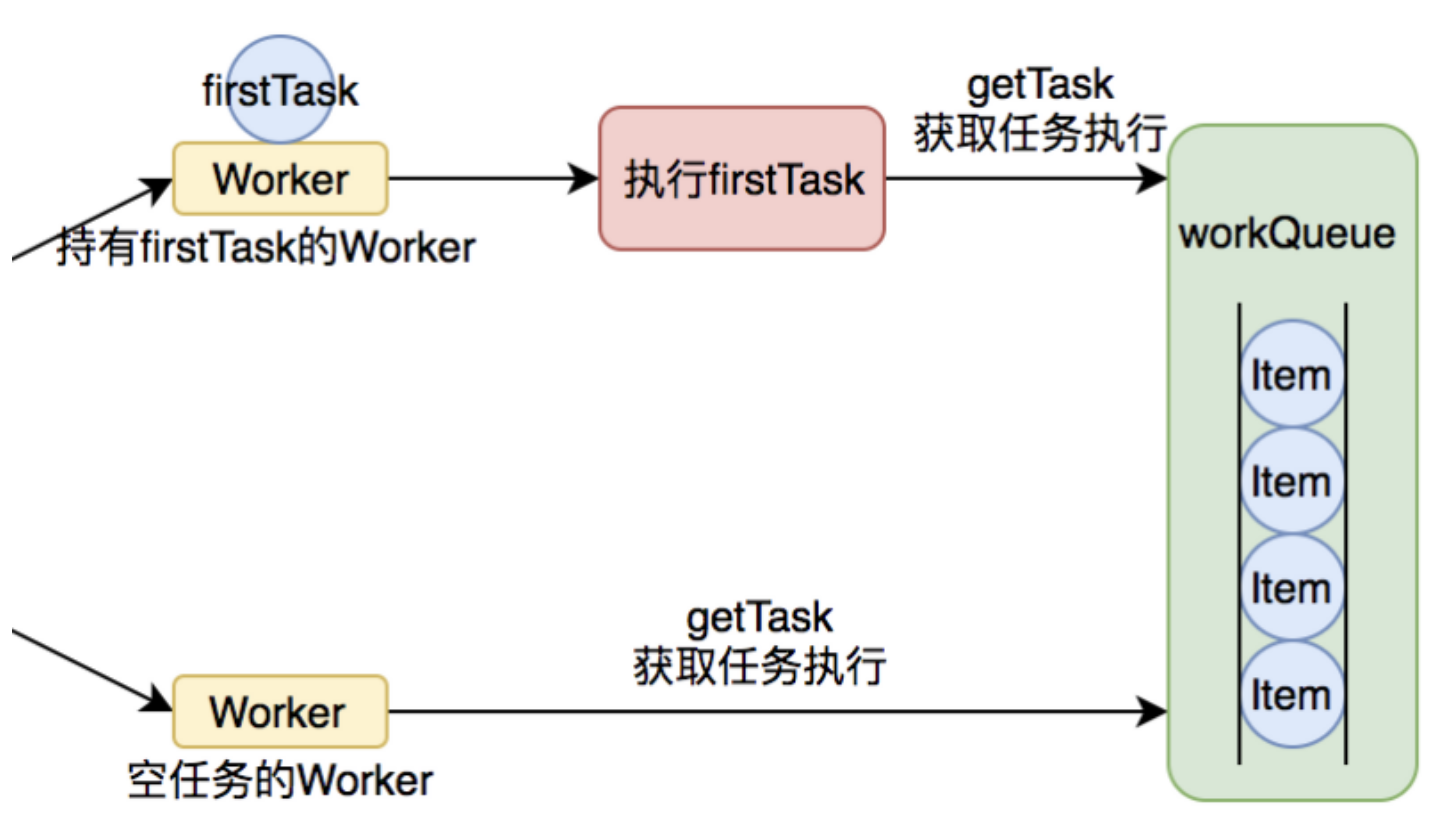
截圖的后半部分,真正的執行。
核心方法是利用getTask()方法從工作隊列中獲取任務并執行。
那么這里看代碼可以了解到firstTask的真正的意義:
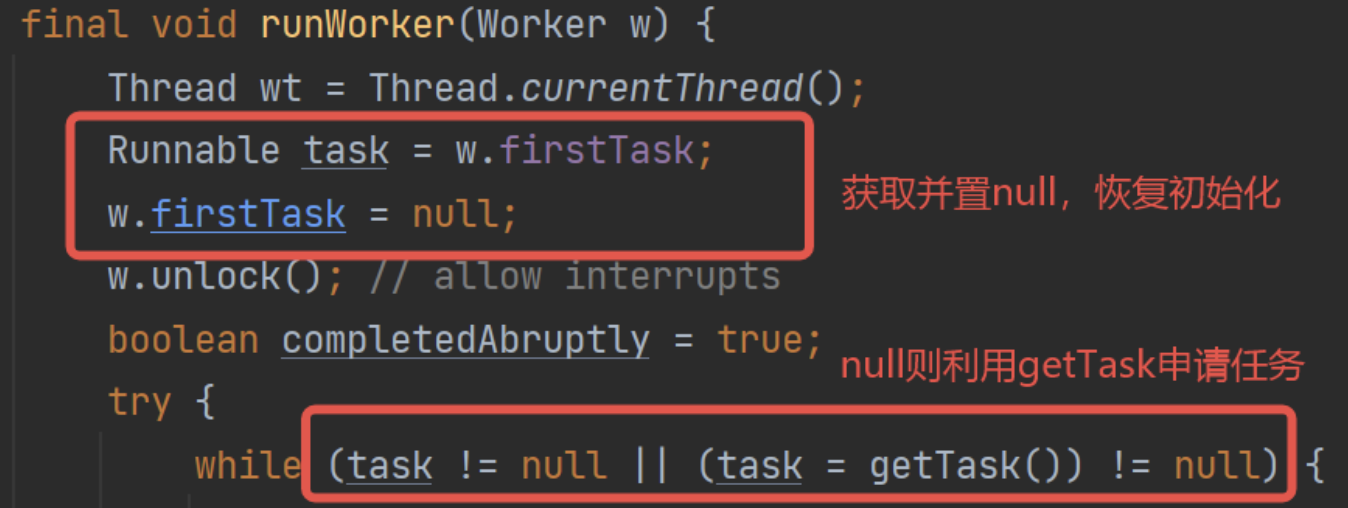
等于說firstTask,就是當前工作線程的待執行任務。如果待執行任務為null,就執行任務申請方法獲取任務,反之則正常執行。
支持提前設置,從而實現:先執行這個任務,再從任務隊列中獲取。
這個設計猜測是例如定時任務線程池,會獲取任務后設置到firstTask,但是不執行,等待時間到了才執行。
后面的執行沒啥好說的。細節一點的圖:
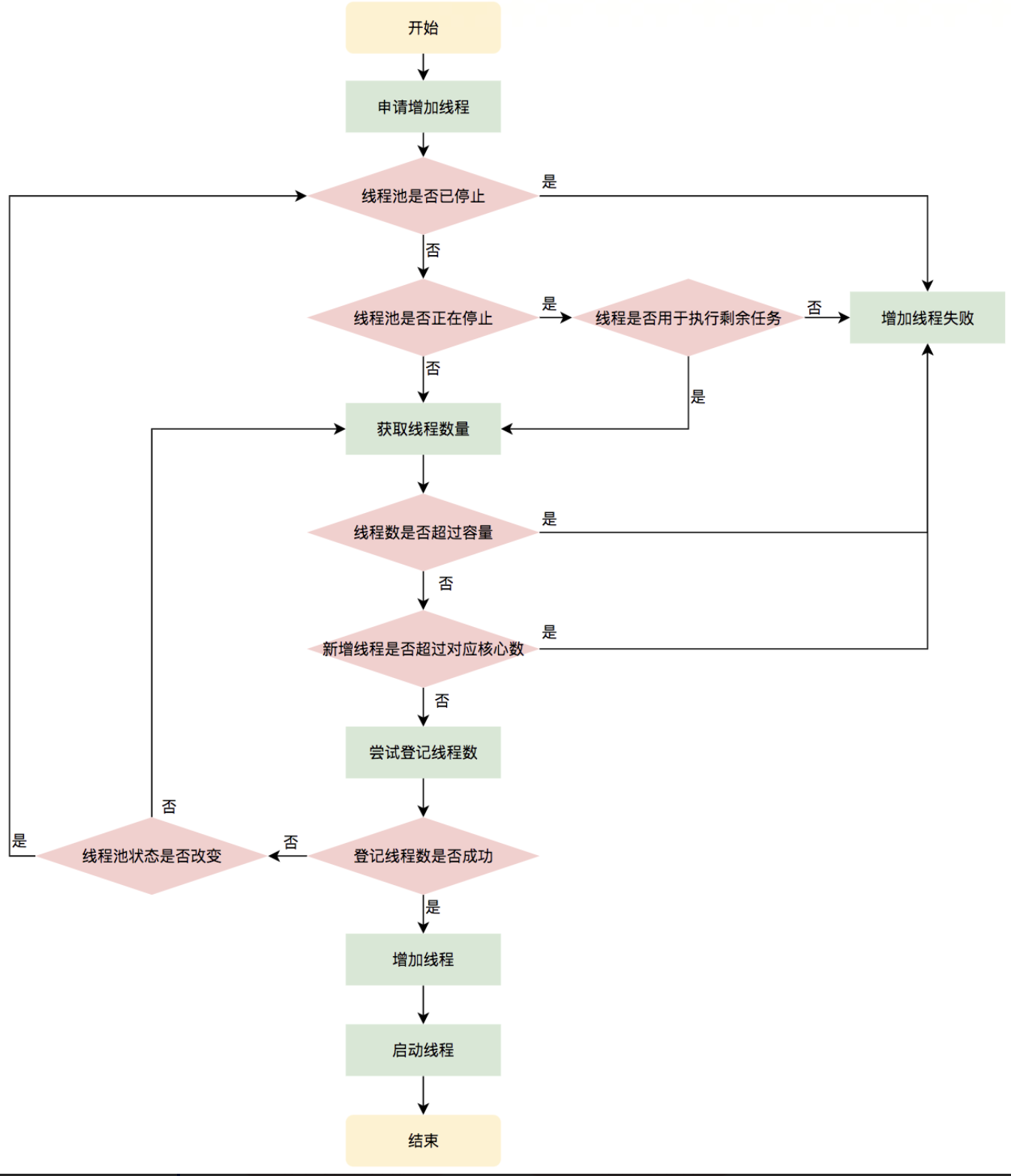
線程生命周期管理
線程池需要管理線程的生命周期,需要在線程長時間不運行的時候進行回收。
線程池使用一張Hash表去持有線程的引用,這樣可以通過添加引用、移除引用這樣的操作來控制線程的生命周期。

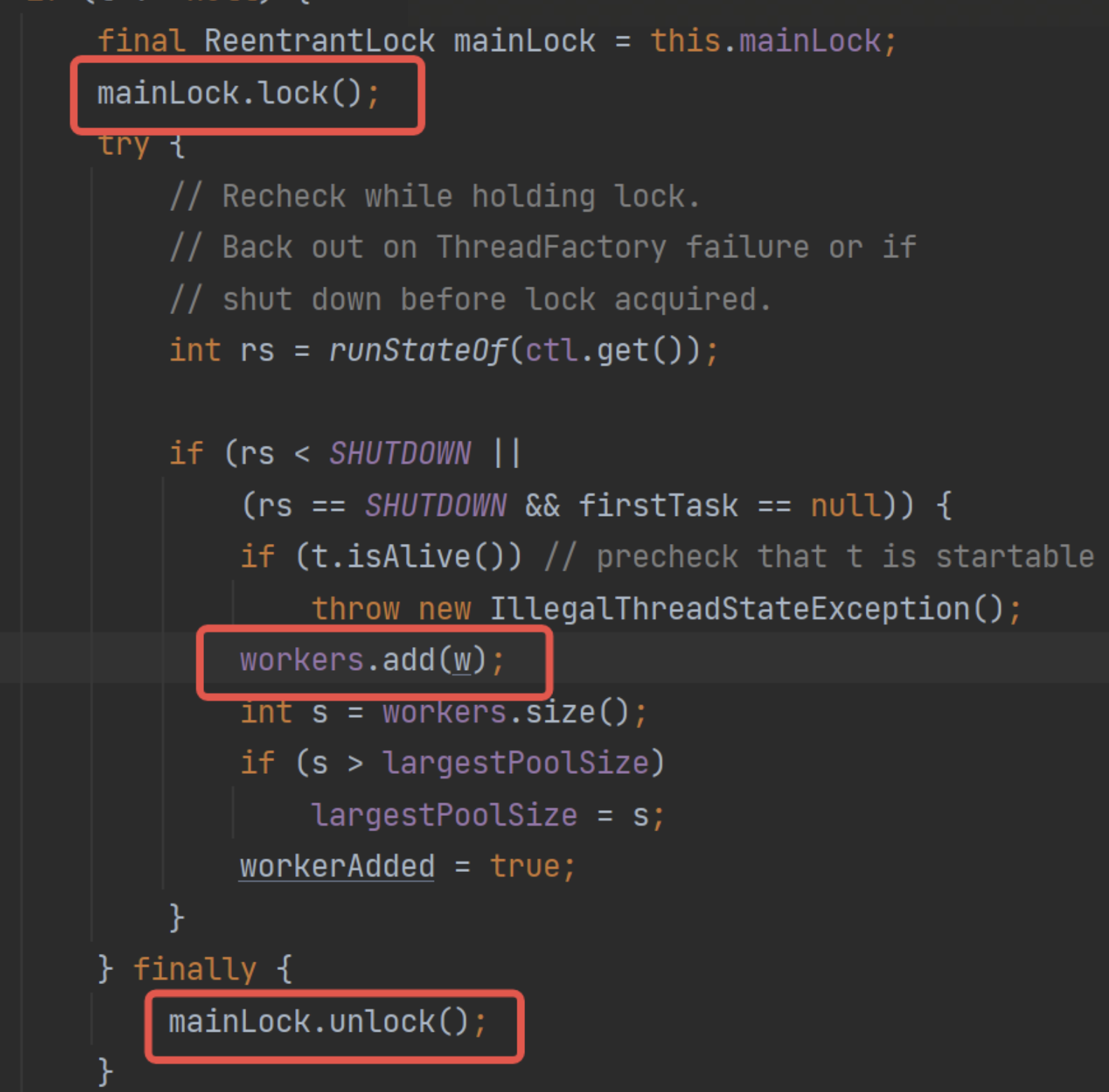
可以看到,workers是HashSet,那么問題來了,線程池有大量的工作線程,頻繁創建/清除線程的時候,用線程不安全的HashSet必然是有并發安全問題的。
所以線程池要求在操作workers的時候,都需要獲鎖,根據該鎖對workers進行操作:

也就是說,在工作線程的創建/銷毀,都要加上這個鎖,例如工作線程的創建:
工作線程的回收
這里比較復雜,慢慢聊。
工作線程自身鎖
Worker對象其實本身就是一把鎖。這是個細節,Worker本身是實現了AQS的:
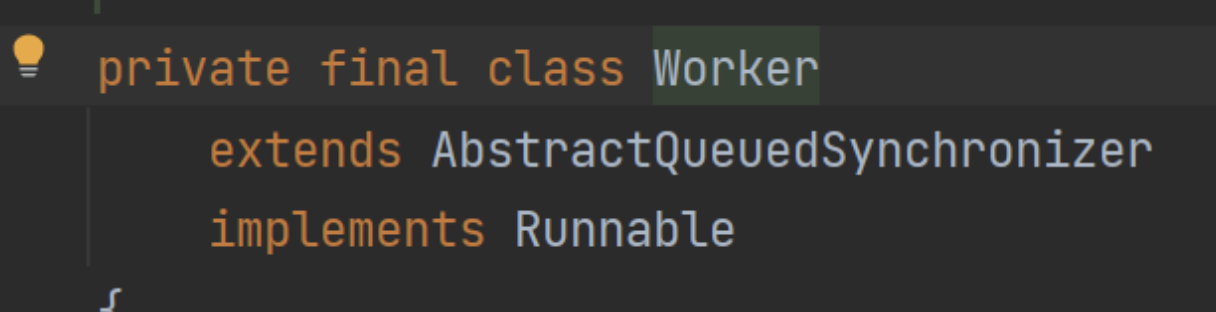
這里其實最主要的作用是工作線程的回收。雖然可以通過維護workers來完成對工作線程生命周期的管理,新建線程比較好理解,但是刪除線程的時候,工作線程本身就是一種競爭資源了。回收的時候是可能恰好碰到調用的。
這里選擇AQS的原因,其實可以看注釋,這邊簡單翻譯一部分:
Worker類存在的主要意義就是為了維護線程的中斷狀態。因為正在執行任務的線程是不應該被中斷的。在線程真正開始運行任務之前,為了抑制中斷。所以把 Worker 的狀態初始化為負數-1。
完全看不懂,這里從其他角度慢慢繞過來解釋一下。
線程的中斷與回收
解釋這個問題,首先看下Worker自身是從哪里調用鎖的:
- 工作線程處理前后加鎖。
- 工作線程嘗試中斷時嘗試獲鎖。
第一個看代碼runWorker():
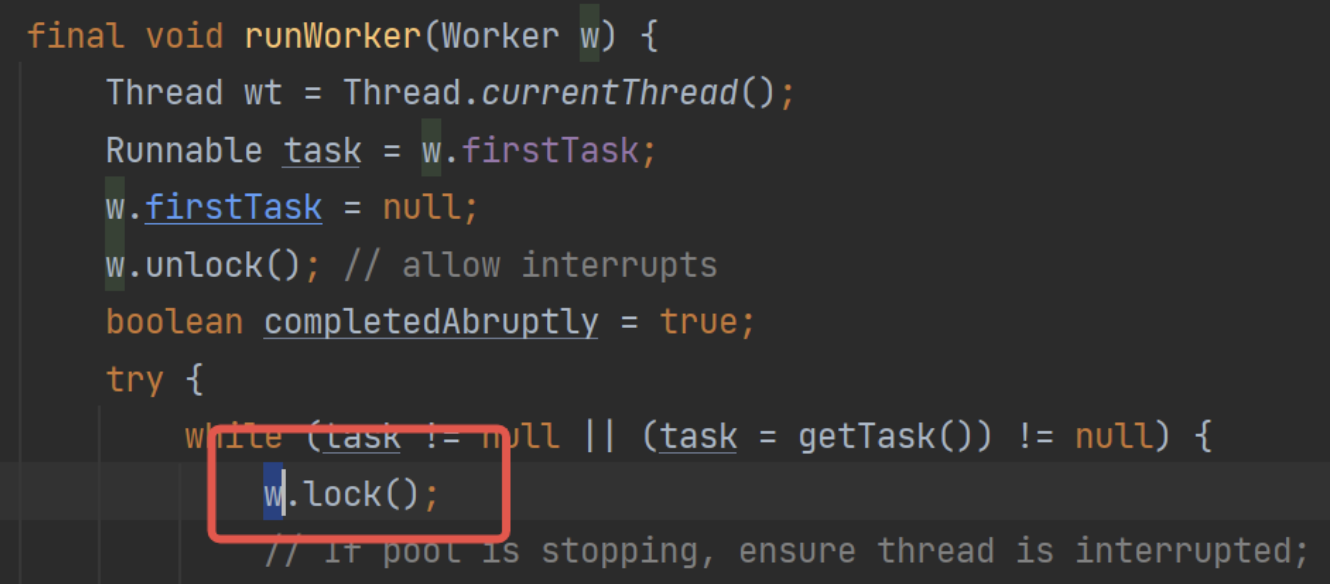
也就是說,當前線程如果在處理,那么本身是給自己加鎖的。
第二個看代碼interruptIdleWorkers():

這里是不是就有點恍然大悟的意思了。
工作線程本身實現AQS,將自身當作競爭對象。
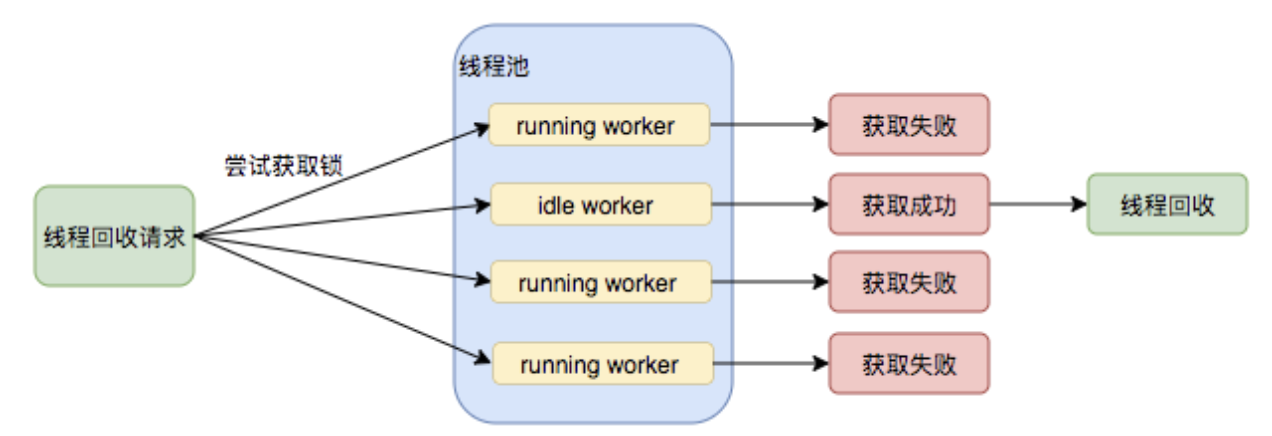
那么工作線程工作的時候,加鎖,鎖住自己,那么interruptIdleWorkers()方法在執行的時候,如果能獲取鎖,就說明一個問題:此時當前線程是沒有在工作的。那么就會被中斷掉。
為了實現這個功能,就只能選擇不可重入鎖,所以自己實現了AQS來實現這個特性。具體可以看代碼實現。
基本可以推測到,interruptIdleWorkers()這個方法就是回收方法,那么其調用時機是什么?
線程回收時機
一個重要的回收時機-keepAliveTime
這里單獨拉出來聊了,比較經典。
八股文一般說:keepAliveTime是線程存活時間,如果當前線程池線程數量大于核心池的時候,如果一個線程超過keepAliveTime沒有獲取到任務,則會觸發線程回收。
這里聊聊相關源碼。首先看基礎的任務申請:
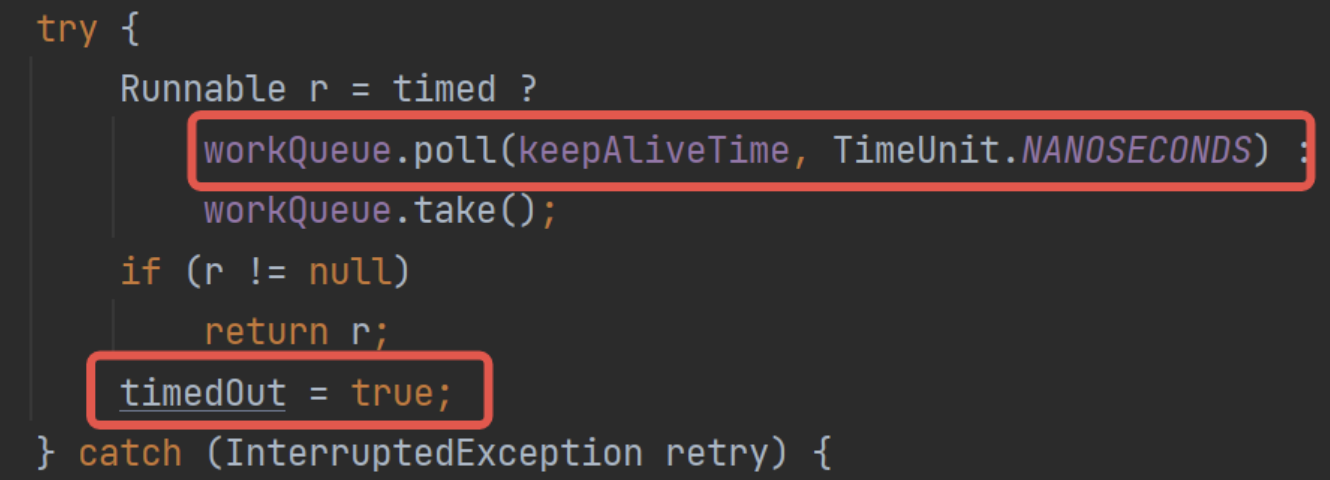
這里如果設置了超時時間的情況下,請求任務隊列是調用的poll()方法,并指定了keepAliveTime。那么這個方法的意思就是,阻塞這么長時間,超過時間后直接返回null。
所以這里就對應到八股文了,如果此時poll()返回空,那么就是說當前隊列里什么數據都沒有,那么這里其實就是說明:該線程等待了keepAliveTime都沒有獲取到數據,也就是說這段時間全部是空閑。可以回收了。
而這里只是設置了timedOut標記,留給上層來處理:

這里判定之后返回個null。

直接跳出線程執行run()方法,在finally塊中觸發線程回收。processWorderExit()方法的底層就是下面的tryTerminate()了,會直接進行回收。
tryTerminate()

核心回收方法,根據其調用可以梳理出正常運行中的回收時機:
-
工作線程創建失敗時:
addWorkerFailed()。 -
runWorker()方法退出時。正常來說runWorker()方法是一個自旋,只有在任務申請失敗時才會退出自旋。那么這個時機就是指任務隊列已經清空了:
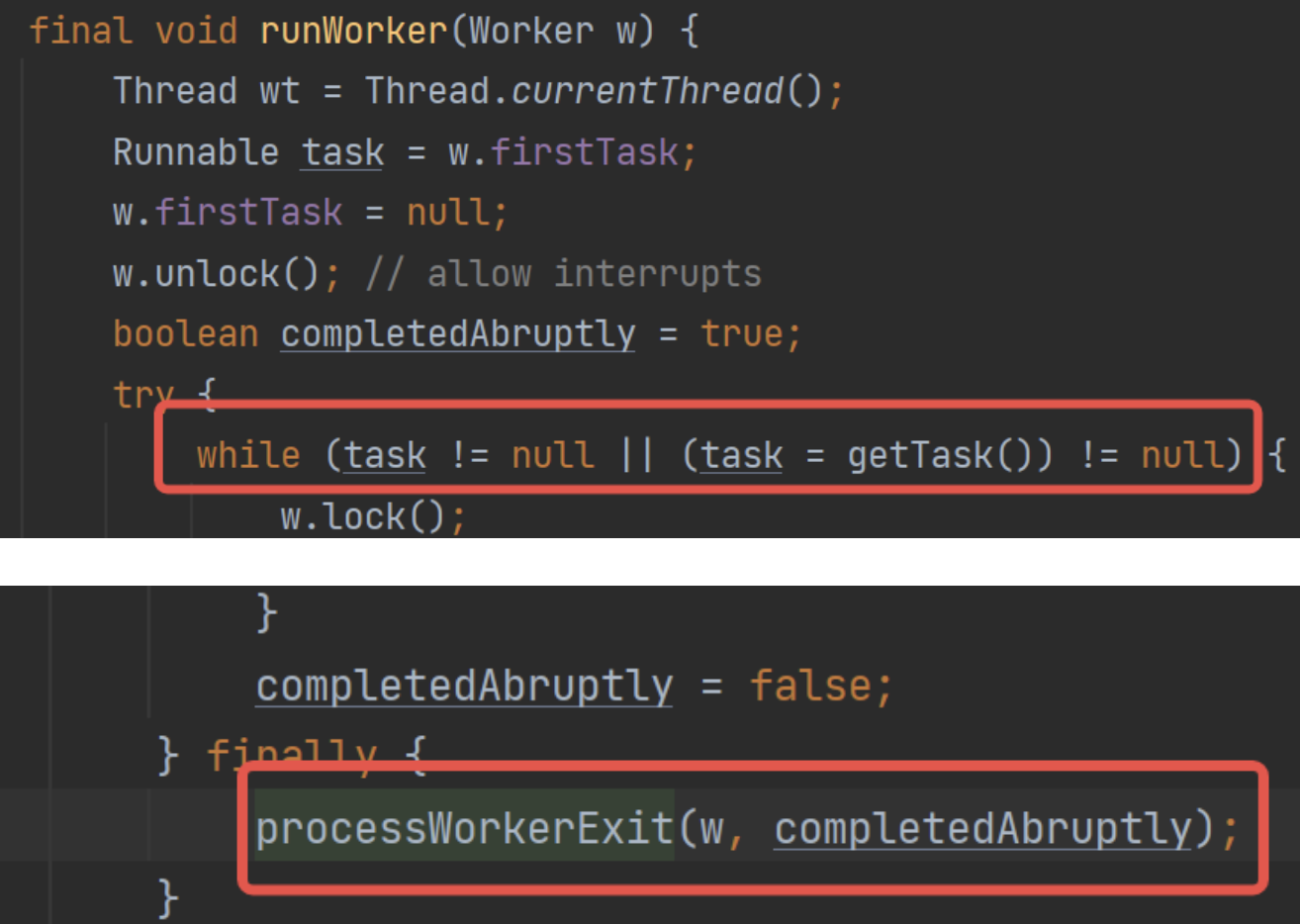
總體流程為:

-
shutdown()。可以看到執行了兩次。
-
shutdownNow()。
-
remove(),移除任務時順便執行一次。
-
purge(),todo。
interruptIdleWorkers
一般是針對線程池本身參數進行操作的時候,會觸發回收,看其調用方式,可以梳理出來全部的線程回收時機:
- shutdown()。
- 設置核心池大小的時候,如果當前線程池線程數量大于核心池數量大小,執行一次回收:
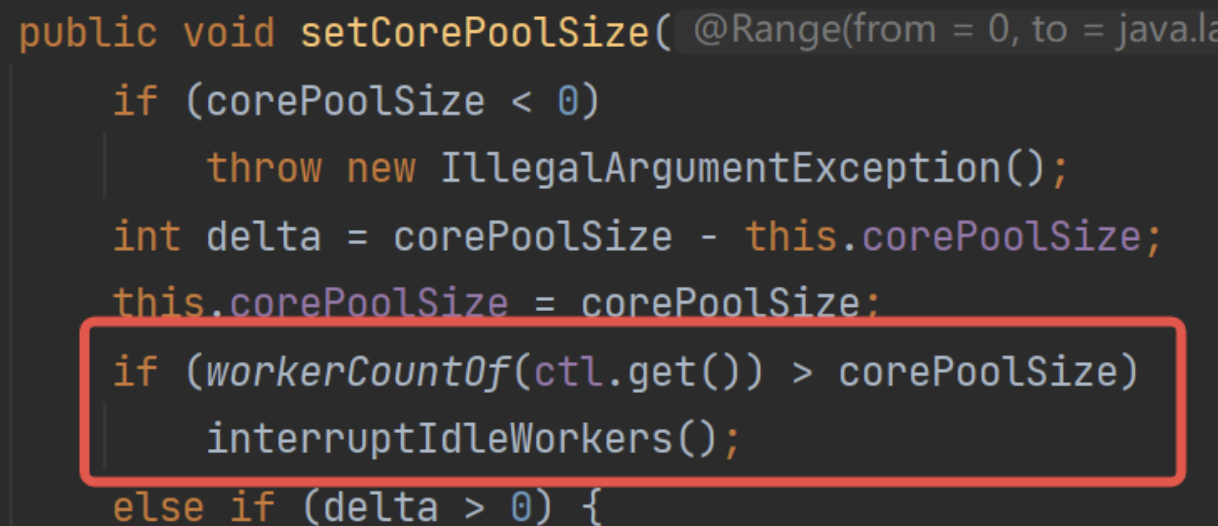
- 設置允許核心池超時時,執行一次回收:
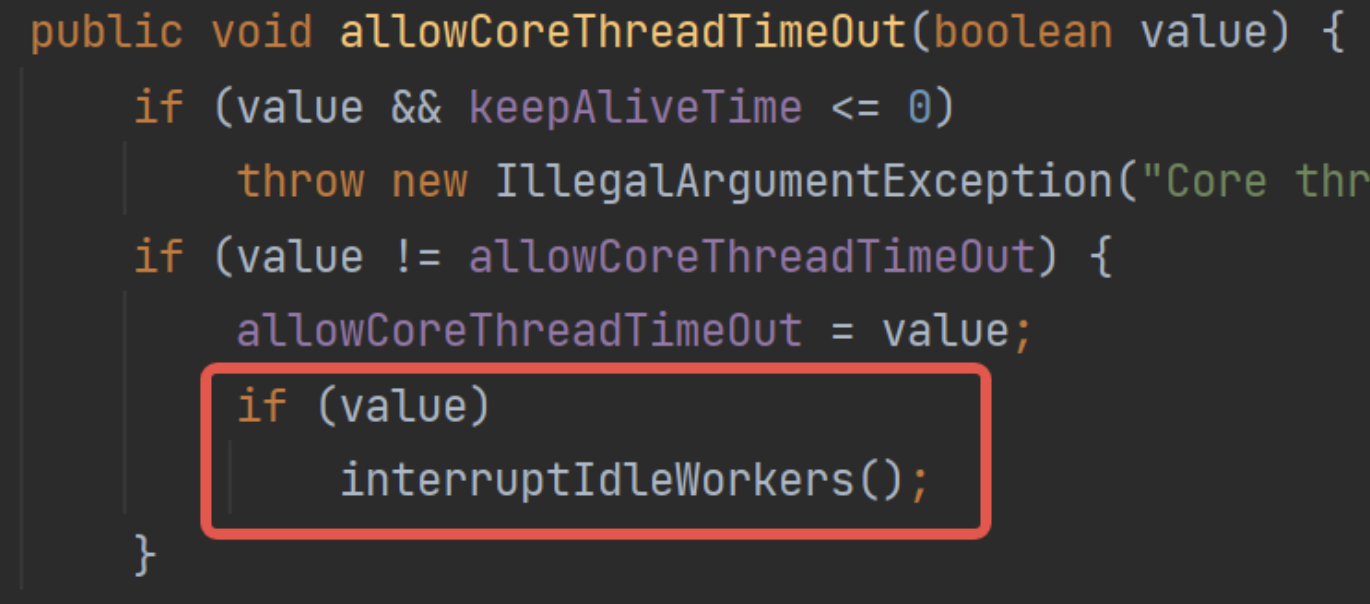
- 設置最大池數量時,如果當前線程池線程數量大于最大池數量,執行一次回收:
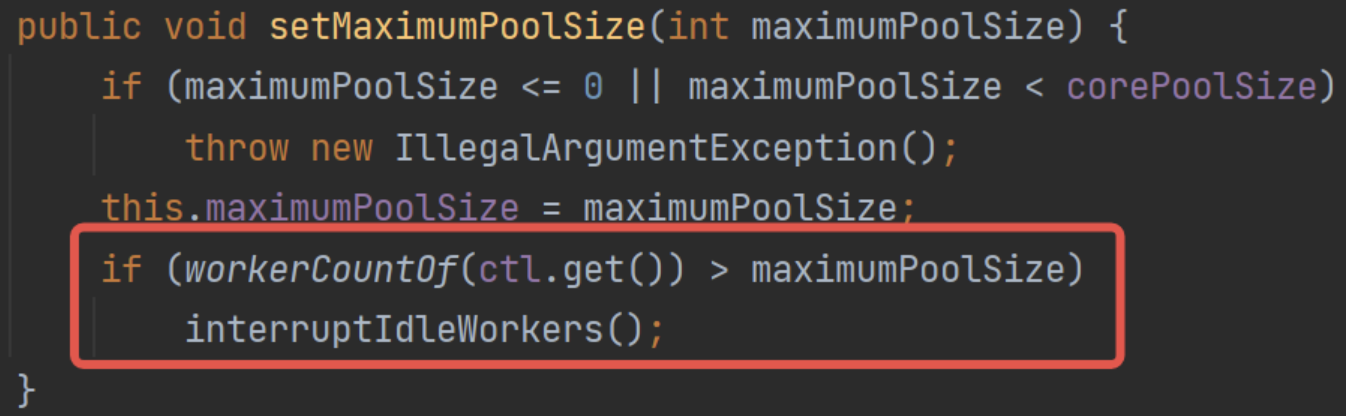
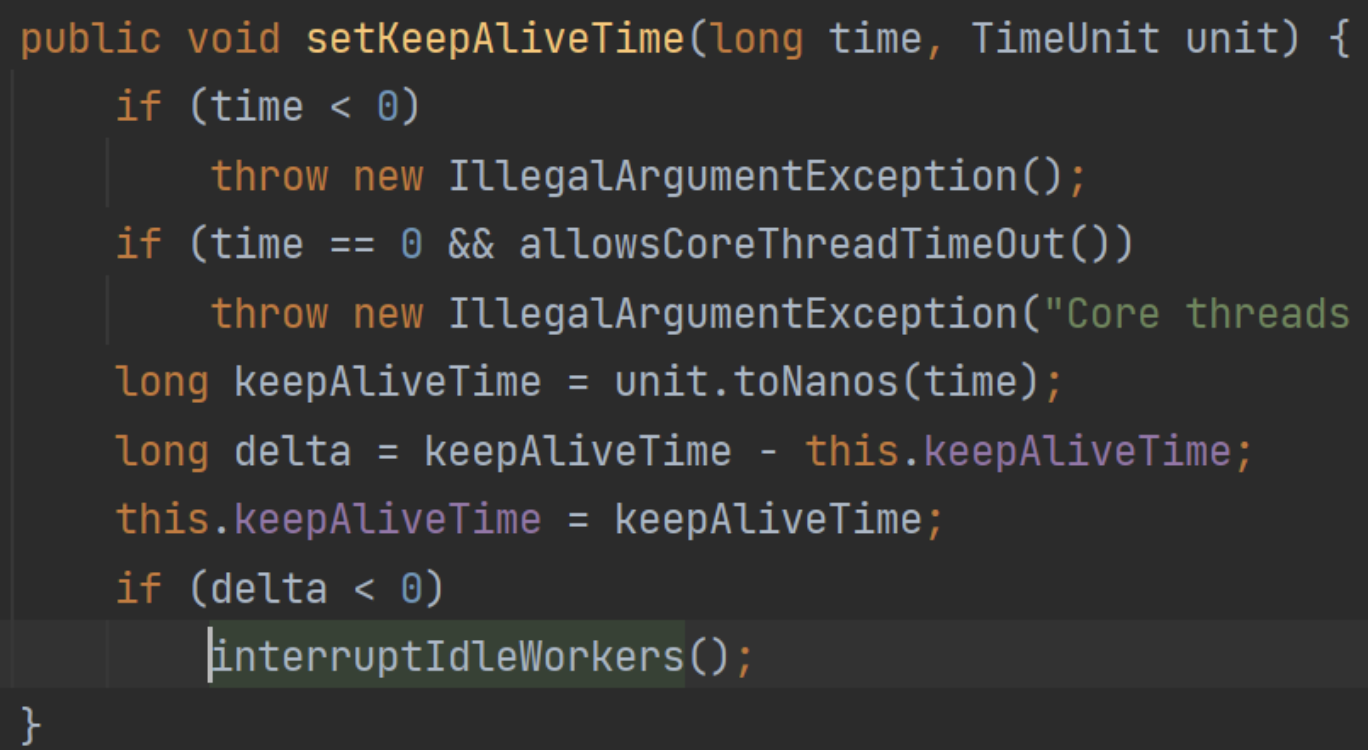
- 設置線程池線程存活時間時,如果設置變小了,那么執行一次回收:
不使用ReentrantLock和synchronized的原因
跟上面的邏輯一樣,為啥要加鎖,就是為了區分線程是否中斷,而ReentrantLock和synchronized都有一個重要特性:可重入。因為可重入,那么這個鎖就沒有意義了,因為線程都是一個,既然可重入那么就是必然能獲鎖了。
所以選用AQS,手動刪掉可重入的特性,實現互斥。
tryAcquire實現不可重入
也可以看看重寫AQS的獲鎖代碼:
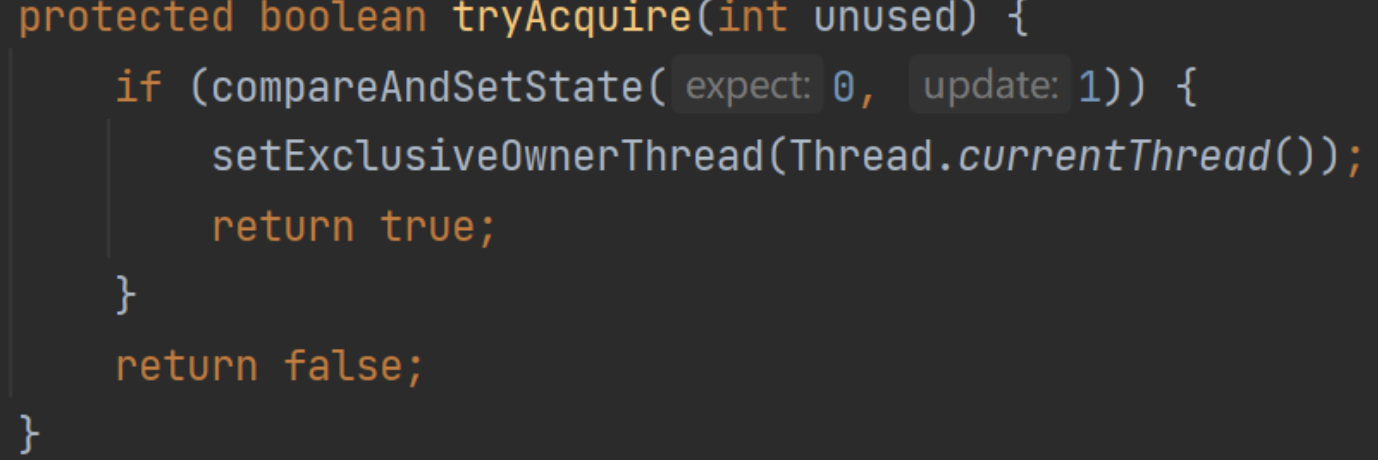
雖然設置的excluiveOwnerThread,但是完全不用,就是直接CAS獲鎖,沒有重入的特性。
總結
綜上,可以簡單給出一個大致的回收流程:
而回收請求執行時機:
- 任務隊列空。
- shutdown()等線程池關閉任務。
- 線程池變量更改的時候,例如核心池大小變更等。
- 任務移除。
- purge(),todo。
runWorker()方法的總結
也算是工作隊列核心的總結吧:
線程池設置核心池和最大池的原因
個人理解了。
假設核心池數量為15,最大池數量為20。
線程的創建和銷毀是很重的操作,所以線程池本意是想在核心池中的線程都能正常使用,偶爾使用最大池。
- 房子裝修,一般來說聘15個工人,3天完成工作。
- 那么每天的工作量不一定,也有可能運水泥瓷磚的人不給力,導致今天工期延緩
- 但是不管怎樣,3天左右或快或慢基本都能干完
- 運材料的人或多或少,每天都是15人份左右的裝修材料。
那么就認為這15個工人是核心池,即完成任務基本就是需要這么些人,可以少點但不能多。
- 房子裝修,這次設計的比較簡單,13個人,3天完成工作。
- 那么多出來的兩個人,要么找點別的活先干著。實在沒活,就直接跑路了,也沒啥好待的。
等于說核心池的線程釋放。
- 房子裝修,這次設計的比較復雜,15個人,干了一天后覺得不行,干不完了
- 老板為了不延期,說好的3天就3天,那么就臨時加人手
- 花錢雇新工程師,讓17個人,勉強3天干完。
等于說核心池線程不夠用,則依舊可以創建線程。
- 老板也要掙錢,再讓我快,我都不掙錢了,自然不會給你再增加工人,就這樣湊合吧。
等于說達到了最大線程池。
那么keepAliveTime也是衍生出來的配置,控制線程空閑后多長時間后自動回收。
線程池數量設置方法論
這個跟業務相關,一般是跟著業務一起調整,包括實際上線之后的調整。剛開始可能也只是設計一個大概值。
本質上,一個任務可以區分成CPU密集型任務和I/O密集型任務。
-
CPU密集型任務。
- 需要大量CPU計算。
- 所以大量的切換上下文非常影響性能,最好一個時間片內執行完畢。
- 那么這種情況下,如果線程數量給的太大,會導致CPU大量輪詢,每個時間片給的也少。
- 所以CPU密集型任務盡量保證CPU核心數量和線程數量一致,減少上下文切換的損耗。
- 所以線程數量比CPU核心數量稍高或者相等相對會好一點。
- 需要大量CPU計算。
-
IO密集型任務(操作數據庫也算IO)。
- 可能會阻塞。
- CPU可能會長時間空轉,等待IO操作。
- 所以恰恰相反,這種任務需要設置很多線程,IO等待的時候不要讓CPU閑著,去處理其他線程,提高吞吐量。
- 可以考慮線程數量是核心數量的兩倍。
-
混合型任務。
- 這種就是取個中間值。
- 建議做好區分,分開處理。
美團遇到的問題
Java線程池實現原理及其在美團業務中的實踐 - 美團技術團隊 (meituan.com)
這篇文章有一些詳細案例,可以看看。
線程池大小預估錯誤
比較常見,核心池最大池數量較小,從而導致觸發拒絕策略。
但是不能太大,并發量太高可能會打掛下游。
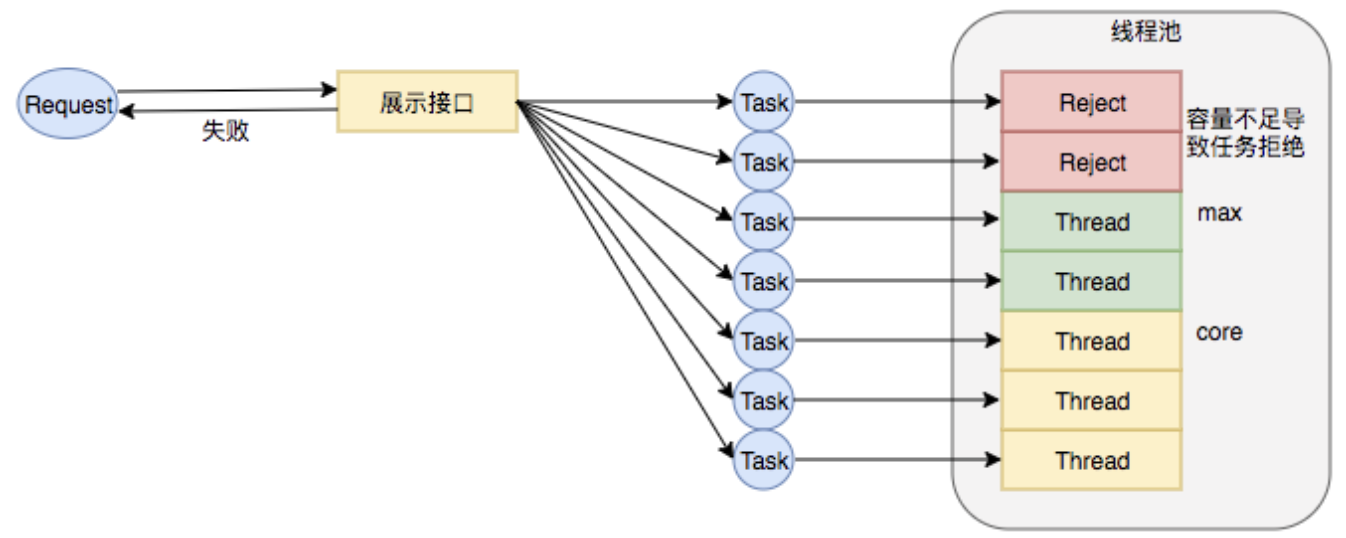
線程池任務堆積
一方面是沒有設置好量,容量太大,導致大量任務堆積,或者沒有預估到任務RT可能會很高,瞬間就大量堆積。
而此時如果業務本身要求RT較低,那么整個方法接口就會因為堆積,持續發生大量超時。


)

)

)

))





:循環群的兩道例題)




