寫在前面:
transformer模型已經是老生常談的一個東西,以transformer為基礎出現了很多變體和文章,Informer、autoformer、itransformer等等都是頂刊頂會。一提到transformer自然就是注意力機制,變體更是數不勝數,一提到注意力自然就是“放大優點,忽視缺點”、“模仿人的思考,只關注有用的信息”之類的解釋,但我認為這樣的解釋就是沒有解釋。只是在實驗過程中,通過這種操作使得實驗結果變得很好,為了方便稱呼這種操作,聯想到了“注意力”這個詞,于是才有了“注意力機制”這個說法。
transformer到底是在干什么,了解它的設計思想,存在哪些缺陷,才是對水文章有幫助的地方。
講解細節和代碼的博客已經有很多了,我們重點整理一下模型設計思路,為什么時至今日還能出這么多成果,就算肉被吃完了,我們是否還能喝到一口湯。
目錄
- 1. Transformer
- 2. Informer
- 3. Autoformer
- 4. FEDformer
- 4. Scaleformer
- 5. iTransformer
- 總結
1. Transformer
第一個問題:為什么對模型命名為transformer(變形金剛)
帶著問題和答案來閱讀,能更好理解其設計思想。
汽車人在變形的過程中,會先把身體分解成一系列基本的元素,然后重構成人形,整個過程簡單來說就是“分解->重組”。Transformer本質還是“編碼->解碼”模型,那顯然“編碼”就是對應“分解”,“解碼”就是對應“重組”。
以這種視角切入,就能很快明白模型想干什么。
現在就可以正式切入我們的論文了,發表在31st Conference on Neural Information Processing Systems (NIPS 2017),Long Beach,CA,USA. 也是老頂會了。

第二個問題:為什么論文名字要突出“Attention”
最前面我寫到,實驗中的某個操作效果很好,為了方便稱呼,所以取名Attention。
transformer本質是在做編解碼,但是論文的重點卻在Attention,那就只有一種可能了:編解碼中都用了某一種操作(技術),能夠使得效果變好。
也就是說Attention是分解和重組的關鍵步驟,是整篇論文最創新的地方。(分解重組、編解碼大部分人都能想到,如果是你,你會怎么創新)
第三個問題:為什么叫"Attention"
這個問題等讀完整篇文章就很顯然了。但我想說,既然實驗中的這個操作能聯想到“注意力”,那同樣也能從“注意力”推出這個操作在干什么。
人在進行某個活動時,通過會把注意力放在這個活動上,會忽略掉其他東西。在代碼中,處理的東西是一個張量,也就是一堆數值,怎么把注意力放在某個重要地方?很顯然,乘以一個系數就行,重要的部分乘以放大因子,不重要的乘以縮小因子。
關鍵是哪些地方放大,哪些地方縮小,放大和縮小的程度是多少?
那么模型設計的思路基本就呼之欲出了。作者在實驗過程中,設計了一種操作,能夠在編碼器和解碼器中設計了一種操作,能夠使得矩陣中自適應的放大和縮小某些地方的數值;區別在于編碼器更側重分解,解碼器更注重重組。
這個時候來看整個模型,很快就能get到作者的意圖
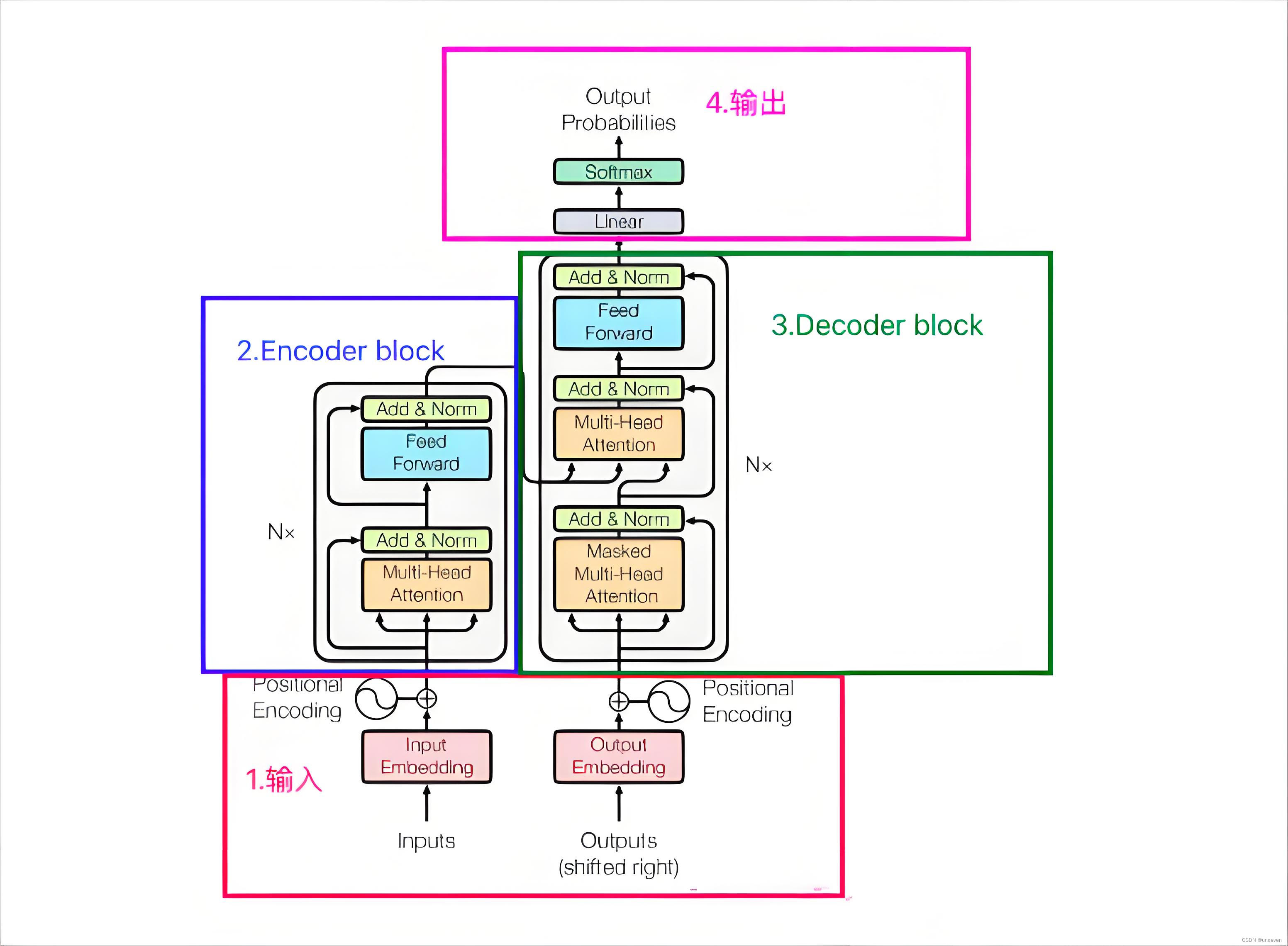
講解模型的博客有很多,但是為了理順整個流程,我們還是繼續把各個模塊過一遍
1 輸入
在前人的研究基礎上,我們已經知道,在處理文本的過程中,每個單詞的長度并不一致,輸入格式的不一致將使模型運行不了,將單詞映射到一個統一的維度就是一個很好的方法。
怎么映射也是一門學問,也出了很多成果,說的最多的就是“詞向量”,把單詞變成一個詞向量,并且在這個映射的空間中,就算長的不像但是語義上很像的單詞在這個空間中距離很近,這就很有意義。
Embedding就是在做這樣的一件事,但position Encoding又在干什么呢?
在Transformer出來之前,LSTM一直是序列數據處理的老大(man~),最大的優勢和劣勢就在于LSTM是順序處理的模型,一個一個記憶單元順序處理使LSTM對位置極其敏感,“從北京到上海”和“從上海到北京”兩句話的意思天差地別,LSTM就能明白這種區別,transformer很難。解決這個問題就用到了position Encoding,把序列中元素的位置進行編碼作為協變量加入進去,就能彌補位置信息的缺失。
(“有機會的話,也可以聊聊xLSTM如何改進的”)
output這個地方也是同樣的操作。output也是有說法的,一開始可能會疑惑,為了這個圖里的輸出和輸入為什么都有output?因為transformer會把所有的輸出都送到解碼器,才會輸出下一個單詞,不斷重復這個操作。但這會帶來一些問題,一句話越變越長,這句話還得完整送到解碼器,導致最后越來越慢,這就是所謂的transformer推理慢的原因。大部分的變體都是基于這點做的改進。
還有個問題,最開頭這個詞沒有輸出啊,output不就是空嗎,以及什么時候結尾啊,因此在模型初始的時候輸入< start >標記符標志開始,當模型輸出< end >表示結束了。
2 編碼器
注意力這個東西講的博客很多,就不再贅述,下面這個圖就是注意力的過程
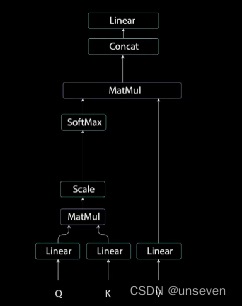
從transformer的原圖可以看出來,編碼器的Q,K,V都是同一個東西,序列編碼之后送到了三個不同的Linear(線性層)因此對Q,K,V產生了變化,但是這樣做的數學原理是什么?
其結果就是放大了部分數值和縮小了部分數值,整個過程一看就懂,不過注意力、計算相似度這類的說法聽起來很難。
通過Q,K,V三個分支把輸入分解了。
多頭注意力和自注意力的區別在于,自注意力把真個輸入都一次性算完了。事情交給一個人做,要是他出錯了就完蛋了,不如把輸入分成多個head,每個head交給不同的人做,然后把結果匯總,就算一個人出錯了也不至于全部完蛋。
之后就是前饋網絡、殘差連接、歸一化,這個操作基本都要用到,沒什么好說的,作用就在于對信息進一步的過濾。
3 解碼器
解碼器的重點在重組。
首先對之前的輸入先做了一個多頭注意力(Q,K,V是同一個),但在第二個多頭注意力的Q,K是編碼器的結果,V是上一個多頭注意力的結果,通過這種方式對輸入信息和之前的輸出信息進行了整合、重組。
值得注意的是,編解碼器都一個“N x ” ,意思是疊加N層,這也提示了注意力不會改變原始輸入的大小。疊加N層也體現了深度學習和淺層學習的區別,transformer是典型的深度學習技術。
4 輸出
輸出是一個Linear和softmax,Linear就是一個全連接層,把解碼信息變為單詞庫的大小,有多少個單詞那么維度就該設為多大,通過softmax轉為每個單詞的概率,把概率最大的單詞作為輸出。
總結
如果會全連接神經網絡,那么學會transformer并不難,因為核心的操作還是Linear,但是讀懂transformer還是很難,我當初也是死摳模型細節,搞不懂它在干什么。從模型設計的角度來理解transformer,就會發現transformer干的事情很明確很簡單——把輸入和輸出通過注意力機制在編解碼中實現分解和重組,這樣的模型就叫transformer。在其他地方改動,但只要遵循了這樣的設計規則,就是transformer的變體。
2. Informer

Informer :超越高效Transformer的長時間序列預測
發表在The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21),也是老頂會了。
transformer很吊,這我們都知道,但是也存在致命的問題,推理的時候會越來越慢,內存開銷越來越大,有沒有什么方法解決?
Informer就提出了一系列創新點
- 提出了ProbSparse self-attention機制,時間復雜度為O(L?logL),降低了常規 Self-Attention 計算復雜度和空間復雜度。
- 提出了self-attention蒸餾機制來縮短每一層的輸入序列長度降低了 J 個堆疊層的內存使用量。
- 提出了生成式的decoder機制,在預測序列(也包括inference階段)時一步得到結果,而不是step-by-step,直接將預測時間復雜度由O(N)降到了O(1)。
模型結構圖,我們一點一點理解為什么要這樣設計
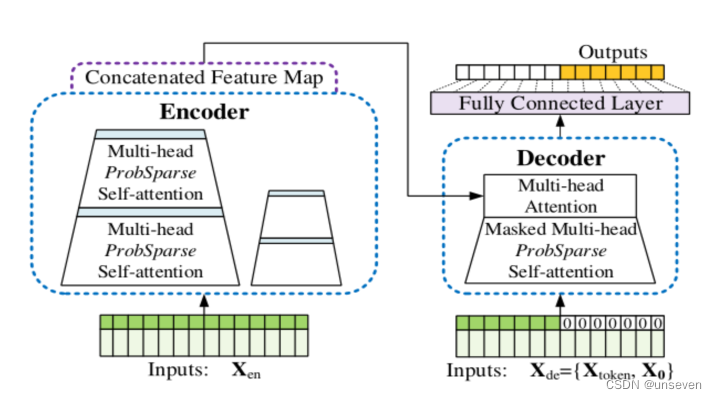
我們已經知道遵循什么樣的設計原則可以稱為transformer變體,Informer的結構圖基本就是把transformer抄了一篇,是典型的transformer結構。
先來看輸出
transformer:我推理慢都是因為需要一個一個輸出結果,因為我需要上一個結果作為下一個數據輸出的依據 (??_??)
Informer:那我就是想搞快點,不想管這么多怎么辦 (︶︹︺) ,那我就把所有結果當成0先填進去,你先給我預測出來,準不準先不說,你就說快不快吧 (╯ ̄Д ̄)╯╘═╛
transformer:填0沒有依據啊,這不是瞎搞嗎?( ′? ??`)
Informer:要依據是吧!我tm先把前幾個時刻抄一遍,后面再填0行吧 (*  ̄︿ ̄)
transformer:… … …行,行吧( ???)
這種一步生成結果的方式把復雜度由O(N)降到了O(1),
雖然有點抽象,但是后續所有變體基本都是這么做的,
準不準先不說,你就說快不快吧。
Informer:需要預測多少個時刻的數值,我就填多少個0 (。→?←。)
transformer:但有個問題啊,輸出是定長的,但是我不知道一句話最后有多長啊?ヽ(.??ˇд ˇ??;)ノ
Informer:誰跟你說我要預測本文啊,我做時序預測不行嗎 (;?_?)
transformer:… … … (┙>∧<)┙へ┻┻
是的,后續的變體都是時序預測任務,
而不是自然語言處理,巧妙地避開了這個問題,
換應用場景也是典型的科研小妙招
ProbAttention
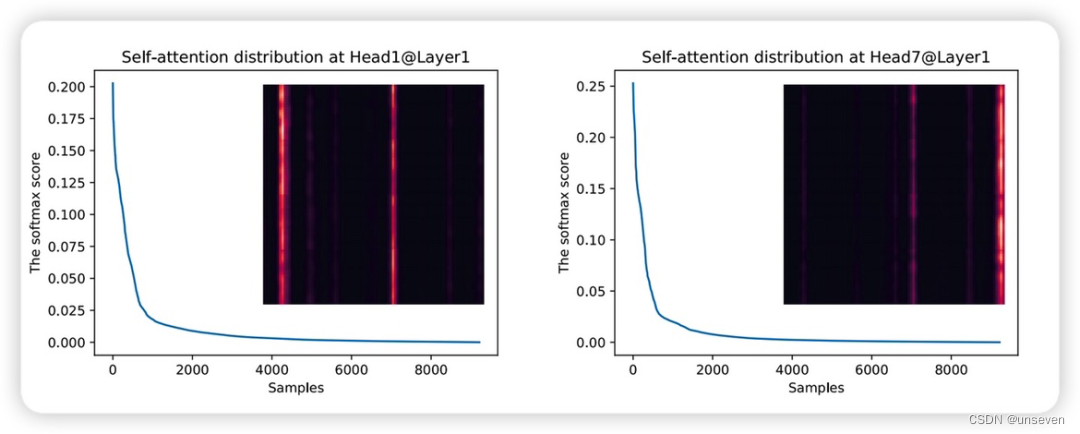
作者發現在原始的Transformer中的自注意力機制中,注意力分數呈現長尾分布,也就是只有少部分的點是和別的點直接有強相關性的,所以在Transformer中如果可以在計算Attention過程中刪除那些沒有用的query,就可以降低計算量
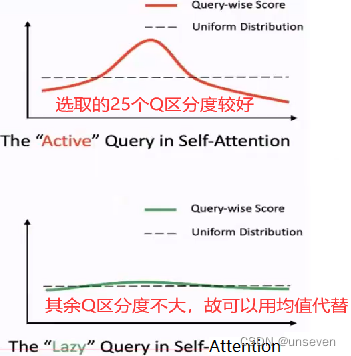
- 簡化K:
對每個Q不再與所有K計算,而是隨機選取25個K,這樣減少計算量 - 簡化Q:
每個Q與各自隨機選取的25個K計算結果有25個值,選取最大值作為Q結果
對所有Q,選取最大的前25個Q ,因為這25個Q具有較好的區分度
25個Q之外的其余Q使用96個特征V的均值作為Q結果,因為這些Q區分度不大,可以看做均勻分布
self-attention Distilling 蒸餾
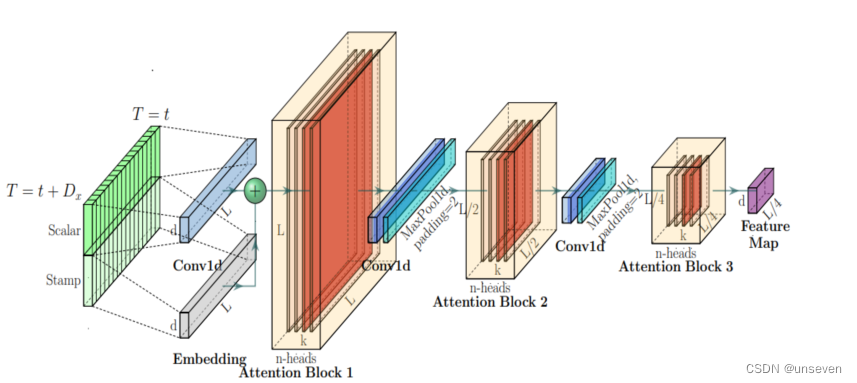
在每個attention block后加入Cov1d + Maxpooling操作來減少特征維度;Informer在encoder模塊用到Self-attention Distilling抽取最重要的Attention信息并減少算法所需的內存和時間。
前面我們提到encoder有N層,每加一層開銷就加大一步,這樣不斷去蒸餾的話,相比原先的模型,每加一層,參數反而進一步減少。
總結
一步式生成的做法減去了對上一個數據的依賴,理論上精度是更糟糕,但是在時序預測任務中,也防止了上一個時刻預測錯誤導致的誤差累加。
Q,K直接通過類似抽樣的方式只計算有用的部分,極大的簡化了計算
蒸餾則直接通過下采樣的方式,把信息減少一大半。
在我看來,這些改進都很容易想到,而且顯然是犧牲精度換取時間,但最早吃到transformer蛋糕發了頂會。
3. Autoformer
Autoformer:用于長時序預測的分解Transformer模型,
發表在35th Conference on Neural Information Processing Systems (NeurIPS 2021),也是老頂會了。

Autoformer才是在時序預測上下了功夫的,在天氣預報上一戰成名,Informer像是縫合的。
Autoformer結構如下圖所示。
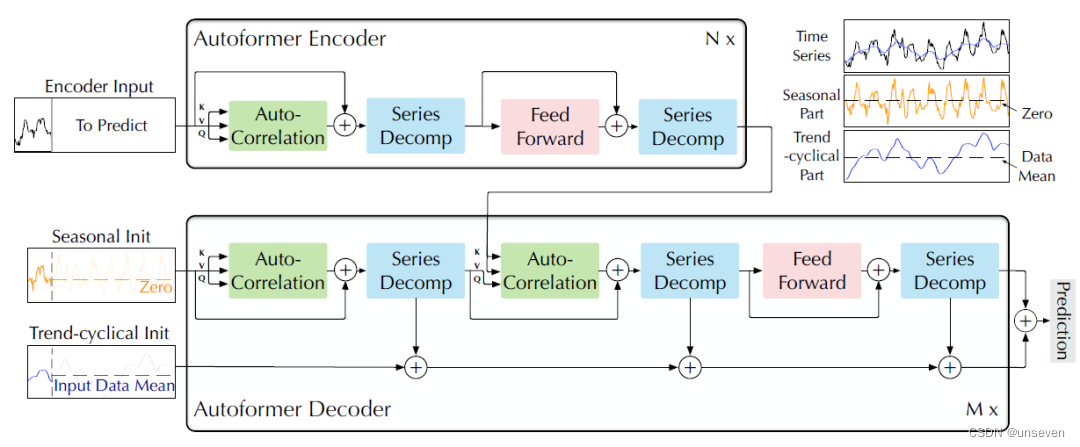
很明顯Autoformer是典型的transformer結構,但它把時序預測任務和transformer做了結合(縫合)。
最突出的特征是:把以往時序任務成果的序列分解概念引入了transformer、和Informer一樣的一步式生成結果、新的注意力機制。
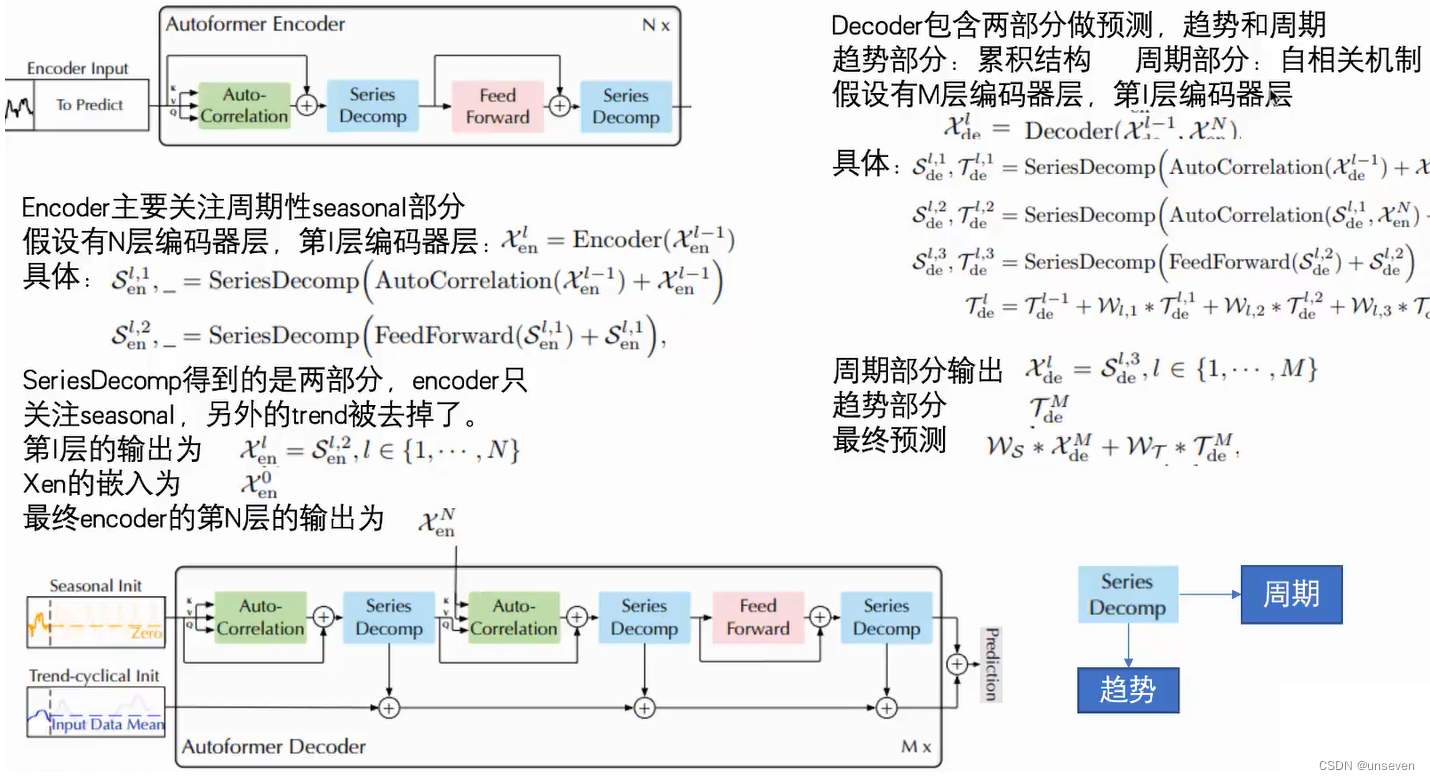
Decomposition Architecture(分解結構)
作者使用了平均池化以滑動窗口的方式提取了時間序列的整體趨勢特征(記作趨勢項),其中為保證提取特征前后維度大小不變而使用了首尾填充操作(padding)。接著將原先序列同趨勢項做差得到兩者差值(記作季節項)。至此原始時間序列便被分解為兩個特征序列。
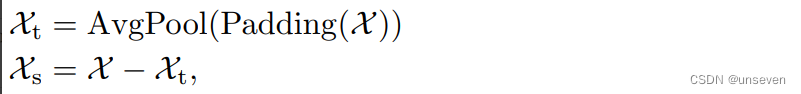
Auto-Correlation Mechanism(自相關機制)
通過計算序列的自相關來發現基于周期的依賴關系,并通過時延聚合來聚合相似的子序列。基于周期的依賴關系,作者發現周期之間相同的相位位置的子序列具有相關性。
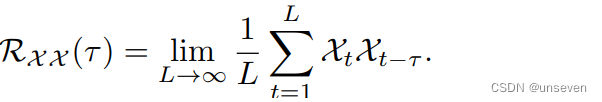
根據隨機過程理論,兩個序列的相關性可以通過上述公式獲得。τ為原始序列平移長度,該公式旨在對多次序列平移前后的相關性進行計算并求其均值。

這個Roll操作可以講一講,中間分成的兩段其實就是前后對調了一下,換回來就是原序列L,把掉到后面的序列再和前面相同大小的序列做自相關。
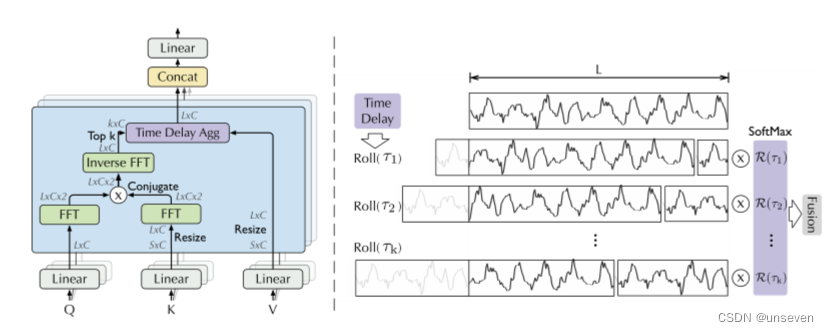
好處就是不再局限于參考之前哪幾個時刻的點,而是參考一段時間的序列。
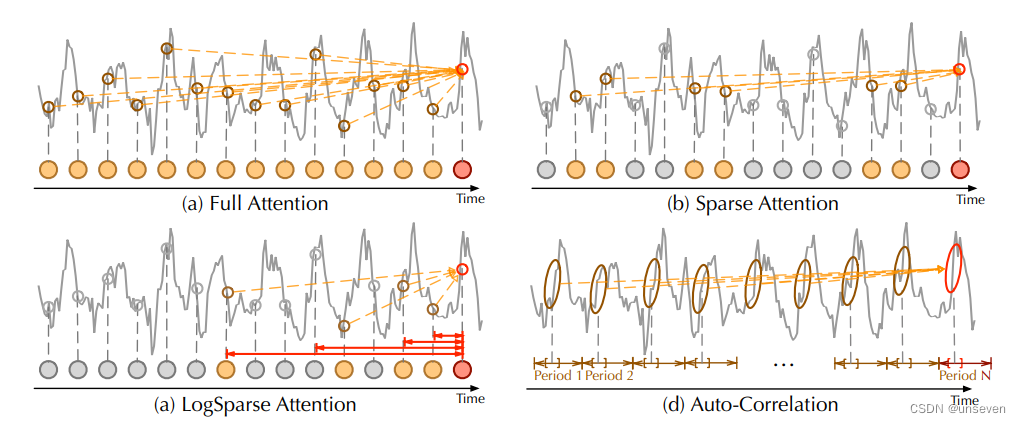
總結
Autoformer算是把transformer把時序任務做了適配,采用了一步式生成(和Informer同一年發表),提出了參考一段序列的注意力機制。
總的來說,并不是很難,這些創新也不是很難想到。適配太過簡單,滑動平均池化就算作了趨勢序列,原序列一減就得到了季節序列,怎么看都扯淡,因此后面基于這點有新的變體出現,但或許是作者故意留了口湯給后面的研究者。
4. FEDformer
FEDformer:用于長期序列預測的頻率增強分解Transformer, Proceedings of the 39th International Conference on Machine Learning,Baltimore,Maryland,USA,PMLR 162,2022.Copy-right 2022 by the author(s).

FEDformer結構圖如下,Autoformer留的這口湯顯然就被FEDformer喝到了,不能說有點像,只能說一模一樣
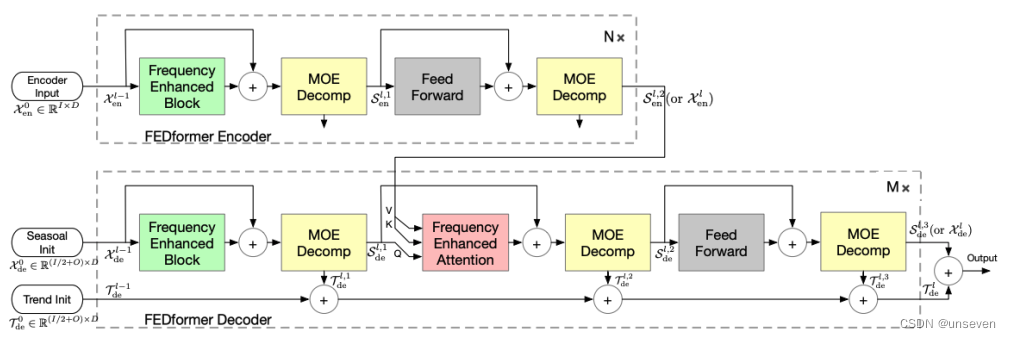
FEDformer 的主體架構采用編碼-解碼器架構。周期-趨勢分解模塊(MOE Decomp)將序列分解為周期項S和趨勢項T。而且這種分解不只進行一次,而是采用反復分解的模式。
在編碼器中,輸入經過兩個 MOE Decomp 層,每層會將信號分解為 seasonal 和 trend 兩個分量。其中,trend 分量被舍棄,seasonal分量交給接下來的層進行學習,并最終傳給解碼器。
在解碼器中,編碼器的輸入同樣經過三個 MOE Decomp 層并分解為 seasonal 和 trend 分量。其中,seasonal 分量傳遞給接下來的層進行學習,其中通過 頻域Attention(Frequency Enhanced Attention)層對編碼器和解碼器的 seasonal 項進行頻域關聯性學習,trend 分量則進行累加最終加回給 seasonal 項以還原原始序列。
FEB
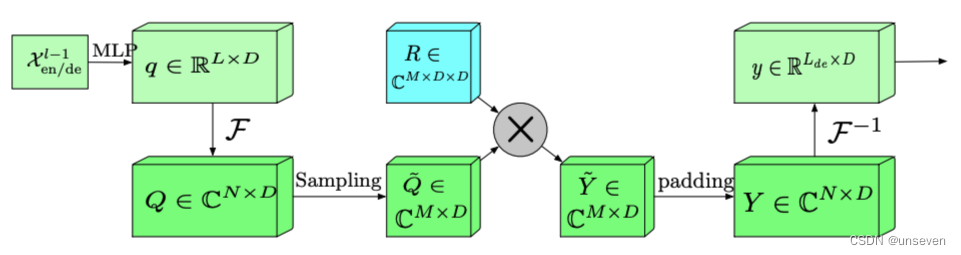
FEDformer 中兩個最主要的結構單元的設計靈感正是來源于此。Frequency Enchanced Block(FEB)和 Frequency Enhanced Attention(FEA)具有相同的流程:頻域投影 -> 采樣 -> 學習 -> 頻域補全 -> 投影回時域:
首先將原始時域上的輸入序列投影到頻域。
再在頻域上進行隨機采樣。這樣做的好處在于極大地降低了輸入向量的長度進而降低了計算復雜度,然而這種采樣對輸入的信息一定是有損的。但實驗證明,這種損失對最終的精度影響不大。因為一般信號在頻域上相對時域更加「稀疏」。且在高頻部分的大量信息是所謂「噪音」,這些「噪音」在時間序列預測問題上往往是可以舍棄的,因為「噪音」往往代表隨機產生的部分因而無法預測。相比之下,在圖像領域,高頻部分的“噪音”可能代表的是圖片細節反而不能忽略。
在學習階段,FEB 采用一個全聯接層 R 作為可學習的參數。
頻域補全過程與第2步頻域采樣相對,為了使得信號能夠還原回原始的長度,需要對第2步采樣未被采到的頻率點補零。
投影回時域,因為第4步的補全操作,投影回頻域的信號和之前的輸入信號維度完全一致。
FEA
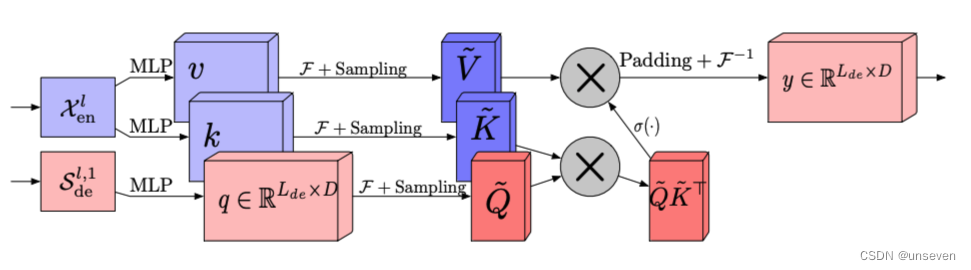
傳統Transformer中采用的Attention機制是平方復雜度,而 Frequency Enhanced Attention(FEA)中采用的Attention是線性復雜度,這極大提高了計算效率。
因為 FEA 在頻域上進行了采樣操作,也就是說:「無論多長的信號輸入,模型只需要在頻域保留極少的點,就可以恢復大部分的信息」。采樣后得到的小矩陣,是對原矩陣的低秩近似。
總結
FEDformer顯然是認為Autoformer的序列分解太過簡單,因此引入了傅里葉變換或者小波變換。但是頻域信息冗余的問題也一并引入,采用了隨機采樣減少復雜度。
FEDformer鉆了Autoformer空子,傅里葉變換本身就是序列分解用爛了手段,但是Autoformer沒用,單憑這一點肯定發不出文章,但是傅里葉變換本身就有缺陷,因此還能根據這一點改進注意力機制,這種認為信息冗余需要抽樣的做法顯然是致敬了Informer。給我感覺是本來Autoformer能做,但我自己給自己制造點麻煩,然后自己解決,形成閉環。
4. Scaleformer
Scaleformer:用于時序預測的多尺度細化迭代Transformer,Published as a conference paper at ICLR 2023,也是老頂會了。

Scaleformer也是標準的transformer結構,結構如下
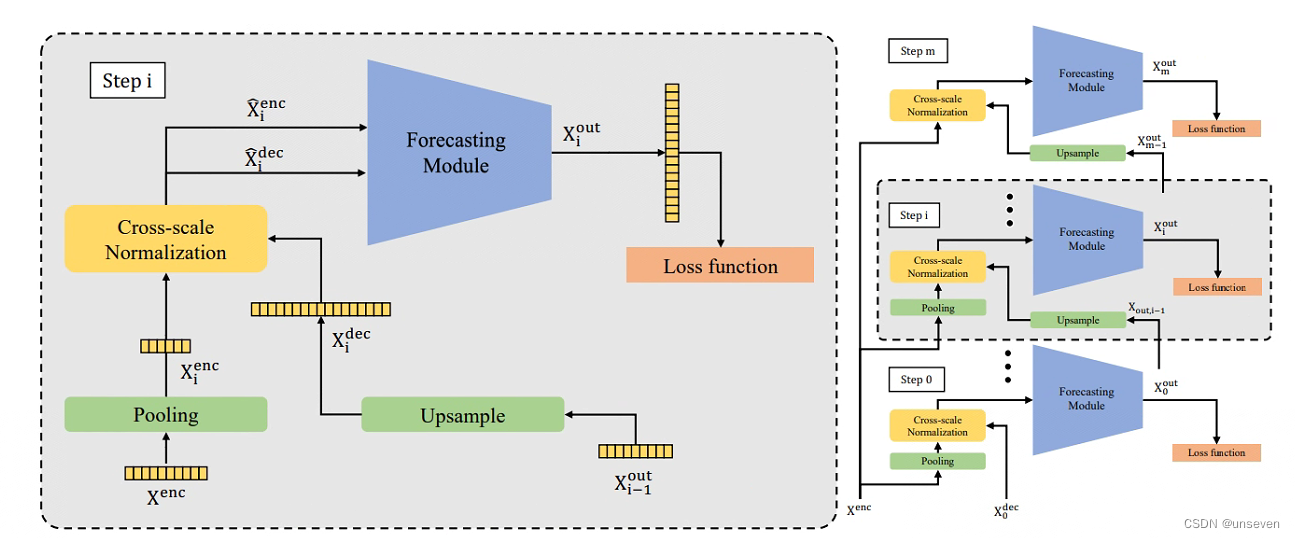
結構圖給人最明顯的特點就是,不再單獨對編碼器和解碼器堆疊N層,而是對整個編解碼對進行堆疊
這種堆疊方式其實很容易想到,想發頂刊還是差點東西,因此引入多尺度的概念,每一層的輸入還得加點東西,層與層的pooling和Upsample大小不一致,提出的信息在尺度上自然就不同,將其稱為多尺度信息
多尺度框架與跨尺度標準化如下:

當然我們不知道當初作者是如何想到這樣的模型,但如果是我的話,我會先從堆疊方式入手,自然而然的想到多尺度作為不同的輸入。Scaleformer在其他方面與transformer并無區別。
5. iTransformer
ITransformer:使用Transformer模型進行長期預測,發表在Published as a conference paper at ICLR 2023,也是老頂刊了

iTransformer更是典型的不能再典型的Transformer模型了,因為山模型上和Transformer沒有一點區別。
Transformer的變體出了太多了,東抄一點,西抄一點,于是清華大學出手了,直接就是用的原原本本的Transformer,把這些變體全超過了。直接就是認為你們都不會玩Transformer,Transformer的效果比不過類似DLinear這樣線性模型,是因為你們沒用對
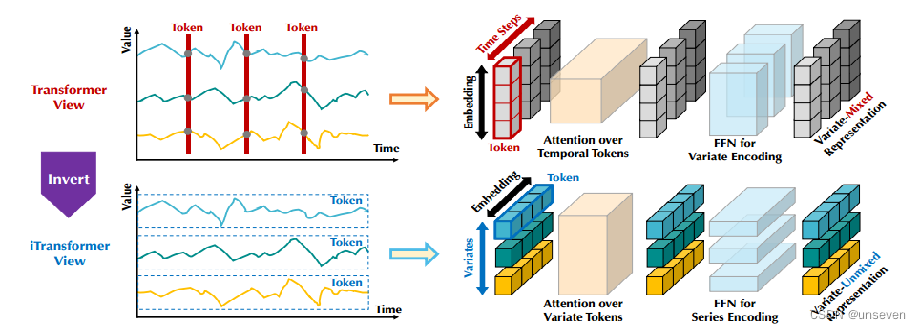
我們數據集的每條樣本都是,在某個時刻的樣本,由單個或多個特征組成,樣本按行編碼為token

實際上應該把每個特征的所有數據進行編碼,樣本按列編碼為token

時刻也作為特征,按列編碼進去
iTransformer應該這么玩:
其余部分就是一個標準的Transformer
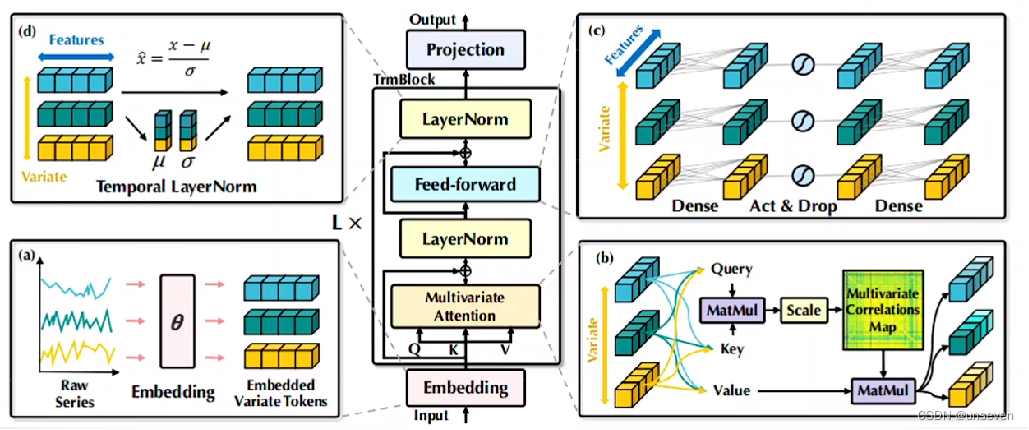
總結
這樣的改進怎么說呢,也是萬萬沒想到,我也不會玩Transformer。實驗結果也證明這樣的編碼方式用在其他變體上都能使效果提升。
之后新的時序預測模型,S/D-mamba,SOFTS這些都是統一按照iTransformer的格式編碼,模型改進進入下一個階段。
總結
Transformer算是開啟了一篇新的領域,在實驗上沒有過多介紹,從模型設計和創新點上來看Transformer,很快就能理解Transformer和這些變體想干什么。
Transformer從分解和重組出發,設計了一種機制并加將其加入了編解碼器,得到了很好的效果。
Informer為了解決Transformer推理慢的問題,對Q、K進行了抽樣,引入了蒸餾機制、一步式生成Decoder,應用在時序任務。
Autoformer為了解決Informer精度問題,引入了時序分解、序列到序列的注意力。
FEDformer完善了Autoformer序列分解機制,引入了傅里葉變換,并對頻域信息進行抽樣。
Scaleformer引入了多尺度信息,采用了新的模塊堆疊方法。
iTransformer采用轉置的編碼方式,超越了先前的變體。






)



)




)



