一、引言
論文: DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
作者: IDEA
代碼: DN-DETR
注意: 該算法是在DAB-DETR基礎上的改進,在學習該算法前,建議掌握DETR、DAB-DETR等相關知識。
特點: 指出DETR收斂慢的另一個主要原因為二分圖匹配的不穩定性,提出對真實目標的錨框信息和標簽信息施加噪聲并將其喂入解碼器中,使解碼器進行去噪操作的訓練方式。去噪部分引入了真實目標信息且不需要二分圖匹配,所以有利于原始匹配部分的穩定從而加速收斂。
二、為什么降噪能加速DETR的訓練
2.1 使匈牙利匹配更加穩定
前期的優化過程通常是隨機的,導致每次的預測結果可能有比較大的波動。例如,對于同一個查詢,第一次預測該查詢與圖片中的狗🐶匹配,第二次預測該查詢可能就與圖片中的汽車🚗匹配了。匈牙利匹配結果的巨大變化,進一步導致優化目標的不一致,模型需要反反復復進行學習修正才能逐漸穩定,所以收斂速度自然就慢了。
所以作者引入施加了噪聲的真實目標信息,包括目標的中心坐標、寬高、類別。因為它們有明確的對應目標,將它們也添加到解碼器中獲得的預測是不需要進行二分圖匹配的,也就緩解了匈牙利匹配的不穩定性。
為描述訓練前期匈牙利匹配的不穩定性,作者提出了一種指標:
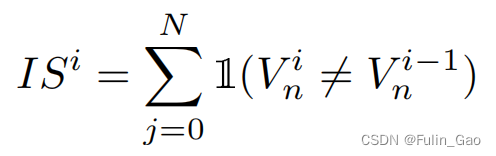
其中, I ( ? ) \mathbb{I}(\cdot) I(?)為指示函數,括號中內容成立為1,否則為0; V n i V_n^i Vni?表示第 i i i個epoch的第n個查詢經解碼器后得到的預測目標的匹配情況,定義如下:
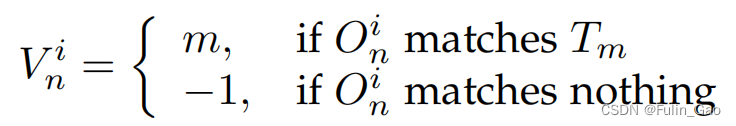
其中, O i = { O 0 i , O 1 i , ? , O N ? 1 i } \mathbf{O}^i=\{O_0^i,O_1^i,\cdots,O_{N-1}^i\} Oi={O0i?,O1i?,?,ON?1i?}表示N個預測目標, T = { T 0 , T 1 , ? , T M ? 1 } \mathbf{T}=\{T_0,T_1,\cdots,T_{M-1}\} T={T0?,T1?,?,TM?1?}表示M個真實目標。
可以看出, I S i IS^i ISi越高表明本次迭代時匈牙利匹配結果與上次的匹配結果相差越大,即不穩定性越大。

上圖為DETR、DAB-DETR、DN-DETR前12個epoch的 I S IS IS變化情況,可以看出,DN-DETR的穩定性要好于另外兩個方法,也就說明了降噪操作能夠使匈牙利匹配更加穩定。
2.2 使搜索范圍更加局部化
因為降噪訓練所引入的錨框雖然施加了噪聲,但是其所處位置仍然在真實目標附近,所以模型在調整預測位置時不必進行全局搜索,而是只進行局部搜索就可以了。錨框和目標框之間距離的縮短使得訓練過程更加簡單,收斂也就更快。
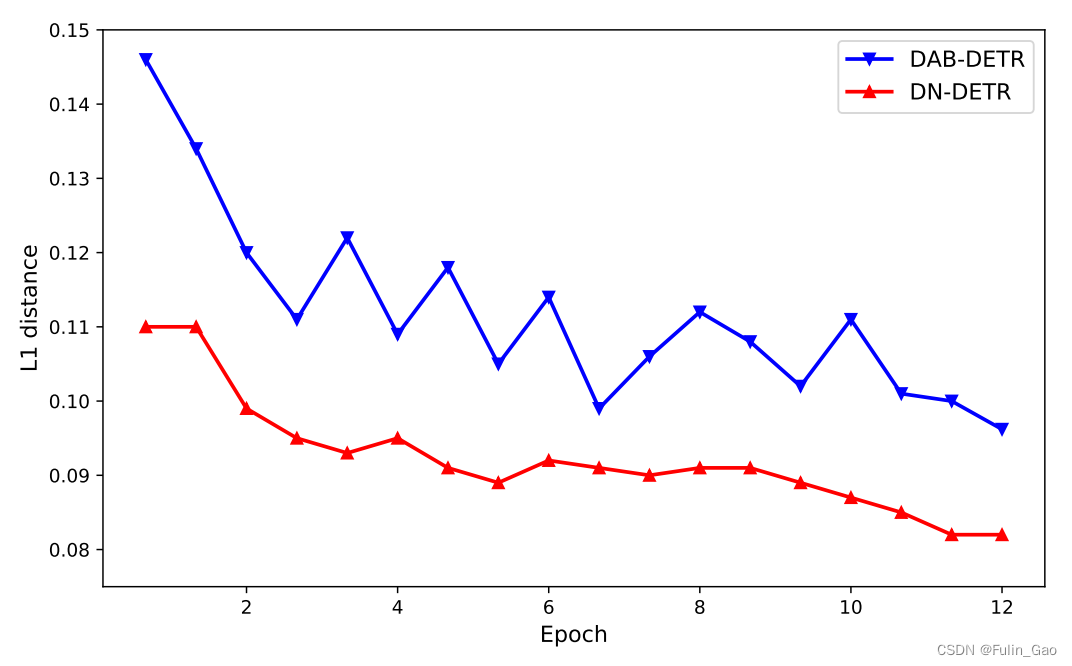
上圖為DETR和DAB-DETR訓練過程中錨框與目標框之間的距離,可以看出,DN-DETR的錨框與目標框之間的距離更小,所以訓練難度更低,收斂速度也就更快。
三、框架
3.1 施加噪聲
DN-DETR施加的噪聲是在真實目標上的,包括三個部分:中心坐標 ( x , y ) (x,y) (x,y)、寬高 ( w , h ) (w,h) (w,h)、標簽 l l l。
對于中心坐標 ( x , y ) (x,y) (x,y),會施加隨機偏移。 偏移量要滿足 ∣ Δ x ∣ < λ 1 w 2 |\Delta x|<\frac{\lambda_1 w}{2} ∣Δx∣<2λ1?w?、 ∣ Δ y ∣ < λ 1 h 2 |\Delta y|<\frac{\lambda_1 h}{2} ∣Δy∣<2λ1?h?的限制,其中 λ 1 ∈ ( 0 , 1 ) \lambda_1\in(0,1) λ1?∈(0,1)。 λ 1 \lambda_1 λ1?的取值范圍能夠保證中心坐標的偏移不會過大,無論如何偏移,新的中心坐標仍然位于舊框之中。
對于寬高 ( w , h ) (w,h) (w,h),會施加隨機縮放。 縮放后的范圍在 [ ( 1 ? λ 2 ) w , ( 1 + λ 2 ) w ] [(1-\lambda_2)w,(1+\lambda_2)w] [(1?λ2?)w,(1+λ2?)w]、 [ ( 1 ? λ 2 ) h , ( 1 + λ 2 ) h ] [(1-\lambda_2)h,(1+\lambda_2)h] [(1?λ2?)h,(1+λ2?)h]之間,其中 λ 2 ∈ ( 0 , 1 ) \lambda_2\in(0,1) λ2?∈(0,1)。并沒有固定的縮放程度,而是在上述范圍內隨機取寬、高。
對于標簽 l l l,會施加隨機翻轉。 翻轉是以 γ \gamma γ的概率將標簽改為另一個隨機標簽。
3.2 注意力掩嗎
DN-DETR引入了 P P P個版本的噪聲,這些噪聲有差別但都滿足3.1中的條件。假設一張訓練圖片中有 M M M個目標,施加 P P P個版本的噪聲后,就會得到 P P P組帶噪目標,共 M × P M\times P M×P個新的帶噪目標。假設原始一張圖片有N個查詢,新的帶噪目標會作為額外的查詢與原始查詢拼接到一起,于是形成 M × P + N M\times P+N M×P+N個查詢。原始查詢就是DAB-DETR中的300個查詢。
?? DN-DETR將與帶噪目標相關的部分稱為去噪部分,將與原始查詢相關的部分稱為匹配部分。
雖然新的查詢中被施加了噪聲,但其仍然包含真實目標的信息,如果不同組之間的查詢能夠相互訪問,那學習過程可能會異常簡單。此外,如果新的查詢與原始查詢之間能夠相互訪問,那么與噪聲相關的部分就無法與原始查詢解耦,當進入無法獲取真實目標信息的推理階段時,整個方法就癱瘓了。所以DN-DETR引入了注意力掩碼來避免這兩個問題,注意力掩碼矩陣如下:

圖中, P = 2 , M = 3 , N = 5 P=2,M=3,N=5 P=2,M=3,N=5;匹配部分表示 N N N個原始查詢;灰色部分表示對應查詢不可訪問,彩色部分表示可以訪問。訪問是單向的。
從圖中可以看出,組0可以與自身、匹配部分通信。與自身不必多說,可以訪問匹配部分是因為匹配部分中不包含任何與真實目標相關的信息,所以開放給組0訪問也沒關系。組1與組0類似,但組0與組1相互均不可訪問。匹配部分要與去噪部分解耦,所以只能訪問自身。
3.3 與DAB-DETR的差別
?? DN-DETR只是提供了一個訓練策略,在推理的時候與去噪部分相關的內容和操作都會被移除,變得與DAB-DETR完全一樣。
所以,DN-DETR和DAB-DETR在結構上的差別很小。下圖為DAB-DETR和DN-DETR的解碼器中交叉注意力部分的結構圖:

如上圖所示,二者的主要差別在于查詢部分Q的解碼器嵌入(初始化全0)替換為了類別標簽嵌入+指示項。這種替換是為了同時進行標簽和錨框的去噪,否則原始輸入中只有可學習錨框與中心坐標 ( x , y ) (x,y) (x,y)、寬高 ( w , h ) (w,h) (w,h)相關,沒有與標簽 l l l相關的部分。
對于類別標簽嵌入,要先由nn.Embedding初始化一個尺寸為 ( n u m _ c l a s s e s + 1 , h i d d e n _ d i m ? 1 ) (num\_classes+1,hidden\_dim-1) (num_classes+1,hidden_dim?1)的矩陣。 n u m _ c l a s s e s + 1 num\_classes+1 num_classes+1中 n u m _ c l a s s e s num\_classes num_classes指數據集的類別總數, + 1 +1 +1表示額外增加的未知類。 h i d d e n _ d i m hidden\_dim hidden_dim是原始查詢的維度, ? 1 -1 ?1表示減去一個維度留給指示項。對于去噪部分的 M × P M\times P M×P個查詢,它們有明確的類別(施加噪聲后的),所以可以直接從矩陣中索引對應的特征。對于匹配部分的 N N N個查詢,它們不知道與什么類別匹配,均被假設為未知類,用矩陣的最后一個特征表達。剩下的那個維度用指示項填補,指示項用于表示當前查詢屬于原始的匹配部分(0)還是新增的去噪部分(1)。
對于可學習錨框,匹配部分按照DAB-DETR進行均勻分布的初始化,去噪部分直接使用施加噪聲后的中心坐標和寬高。
下圖為DN-DETR的結構圖:
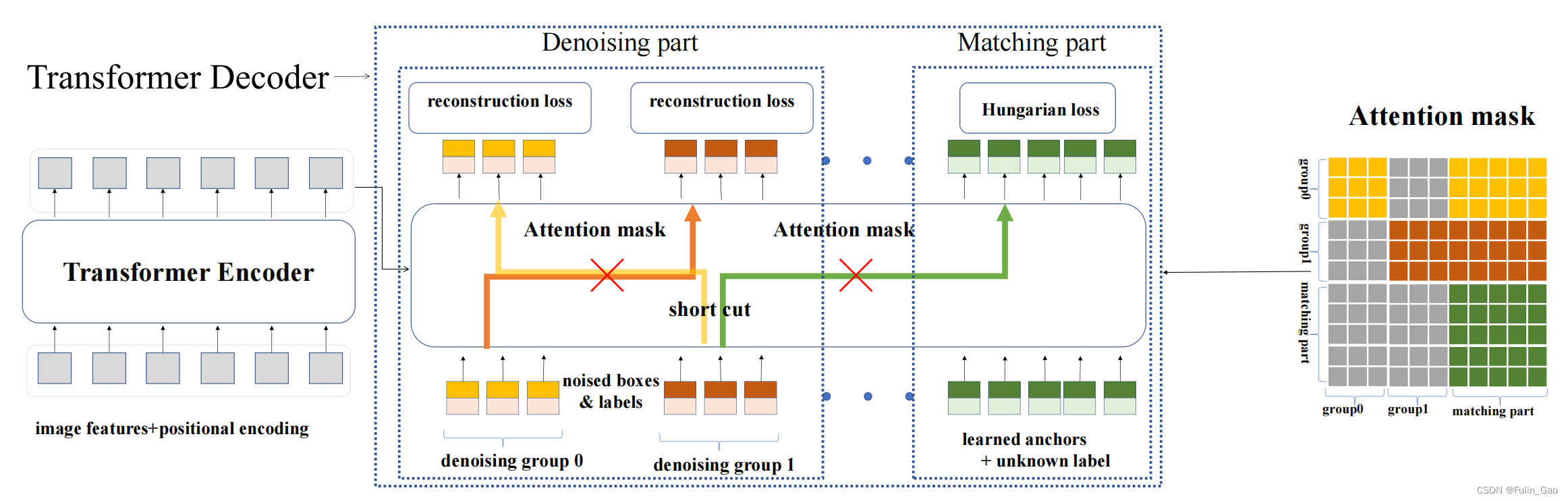
總結下來,DAB-DETR和DN-DETR僅訓練時有差別,差別是:
(1) 解碼器嵌入被換成了類別標簽嵌入+指示項。嵌入部分由nn.Embedding初始化,匹配部分按未知類取最后一個特征,去噪部分按噪聲類別取對應索引的特征。指示項為0表示匹配部分,為1表示去噪部分。
(2) 輸入查詢的數量從 N N N變成了 M × P + N M\times P+N M×P+N。 M × P M\times P M×P是該圖片中 M M M個真實目標被施加了 P P P個版本的噪聲后得到的錨框和標簽。
(3) 為了避免通信帶來的問題,引入了注意力掩碼。
(4) 與原始查詢拼接在一起的去噪查詢也會經解碼器輸出框和標簽預測。為實現去噪,對于框使用l1 loss和GIOU loss,對于標簽使用Focal loss,三個loss合并稱為重構損失(reconstruction loss)。
致謝:
本博客僅做記錄使用,無任何商業用途,參考內容如下:
DN-DETR 論文簡介
DN-DETR 源碼解析





)



)




)




)