基于擴散模型的人臉隱私保護方法——DiffPrivacy,解決了兩類人臉隱私任務:匿名化(anonymization)和視覺身份信息隱藏(visual identity information hiding)。
1. 研究背景
隨著人工智能和大數據技術的普及,個人身份圖像(尤其是人臉圖像)面臨隱私泄露風險。研究者提出兩類主要保護方法:
匿名化
目標:讓人和機器都無法識別到原來的身份,但保留面部結構,使檢測器仍能正常工作。
場景:社交媒體照片,公開發布。
視覺身份信息隱藏
目標:人類看不到真實身份,但機器可準確識別(如加密存儲、后續智能識別)。
場景:云端存儲加密,人臉認證等。
挑戰:這兩類任務的目標是矛盾的,難以通過同一模型實現。例如,匿名化需要讓模型無法識別,而視覺身份隱藏則要求機器仍能正確識別。此外,現有方法多為專用,需大量高質量人臉數據,且容易留下編輯痕跡,恢復能力有限。
DiffPrivacy設計:
多尺度圖像反演模塊(MSI)
利用擴散模型在不同時間步關注圖像的不同級別(尺度)信息,設計MSI模塊獲取原始圖像的條件嵌入(conditional embedding),支持多樣化調控。身份指導能量函數(Energy-based Identity Guidance)
在擴散生成過程的去噪階段,根據任務需求進行梯度修正。即:匿名化:最大化對原身份的混淆(讓識別模型識別錯誤)
信息隱藏:確保加密圖像能被機器準確識別
嵌入調度策略(Embedding Scheduling)
結合不同時間步分配不同的嵌入,使生成與恢復流程靈活切換。

Figure 1:DiffPrivacy方法生成的加密/匿名人臉:
既能在視覺上高度逼真地改變身份(真實感極強),
也能在需要時無損地恢復原始身份,
與對比方法相比,既不易被識破,也能靈活支持不同應用場景。
2. Related Work
2.1 Anonymization
1. 基礎低層方法
- 低級圖像處理如模糊(blurring)、馬賽克(mosaicing)、遮罩(masking)、像素化(pixelization)等,直接破壞臉部可辨識特征。這些方法有效消滅身份,但往往嚴重損害圖片可用性:檢測、識別、分析都受影響。
2. 基于生成式模型
- GANs/虛擬臉替換
- 用生成對抗網絡(GANs)生成新的、虛擬的面部區域替換原始身份,例如inpainting生成新臉(如Sun等[39])。
- 不足:生成的面部常常不自然,表情屬性單一。
- 提升:Maximov等[25]利用人臉關鍵點信息生成多樣化加密臉,但高分辨率下自然度仍有限。
3. 可恢復匿名化
- 最近工作([5], [13], [22]等)專注于可逆加密和匿名。典型方法:
- 條件GAN,輸入密碼條件,輸出加密臉(Gu等[13])。
- 抽取屬性/身份向量,旋轉改變身份(Cao等[5])。
- 將原圖投射到StyleGAN2潛空間,密碼與transformer一起處理生成加密代碼(Li等[22])。
- 局限性:訓練強依賴高質量人臉數據,加密和恢復的圖像質量滿意度一般。
2.2 Visual Information Hiding 視覺信息隱藏
1. 基于同態加密(Homomorphic Encryption, HE)
- 利用密碼學加密圖像,理論上安全,但不適用深度模型,對圖像推理兼容性很差。
2. 基于感知加密(Perceptual Encryption, PE)
- 專注人類感知的加密域設計,如直接用加密圖像訓練模型,準確率受較大影響。
- 例如Ito等[18]結構化變換網絡,確保分類器依然可正確識別但視覺信息隱藏,不可恢復原始圖像。
3. 對抗攻擊啟發方法
- Su等[38]應用Type-I攻擊迭代加密,可恢復和識別,但生成內容接近噪音,容易被黑客識別為加密圖片;且在線優化,速度慢。
2.3 Diffusion Models 擴散模型
演進與應用
- 經典Diffusion:基于馬爾可夫鏈反復迭代,早期[14]慢,樣本質量好。
- DDIM[35]:確定性采樣,極大提升生成速度。
- 引入類別/條件信息:如Dhariwal等[8],提升真實度但訓練成本高。
- Classifier-Free Diffusion:條件+無條件共同訓練更平衡([15])。
- Latent Diffusion:從像素空間到潛空間生成(Rombach等[30]),極大節省算力。
- 當前已廣泛用于密度估計、樣本生成及視覺任務。
3. Diff-Privacy方法原理詳細解析
總體框架
Diff-Privacy設計為三步:
- 條件嵌入學習(key-E):通過多尺度(multi-stage embedding)反演模塊(MSI)學習原圖在預訓練SDM(Stable Diffusion Model)中的條件嵌入(embedding)。
- 隱私保護圖像生成(key-I):通過能量函數身份指導+嵌入調度策略,在去噪流程中引導生成加密/匿名化臉,并通過DDIM反演得到噪音圖。
- 身份恢復:使用key-I和key-E(作為條件嵌入),利用DDIM采樣逆向還原出原始圖。
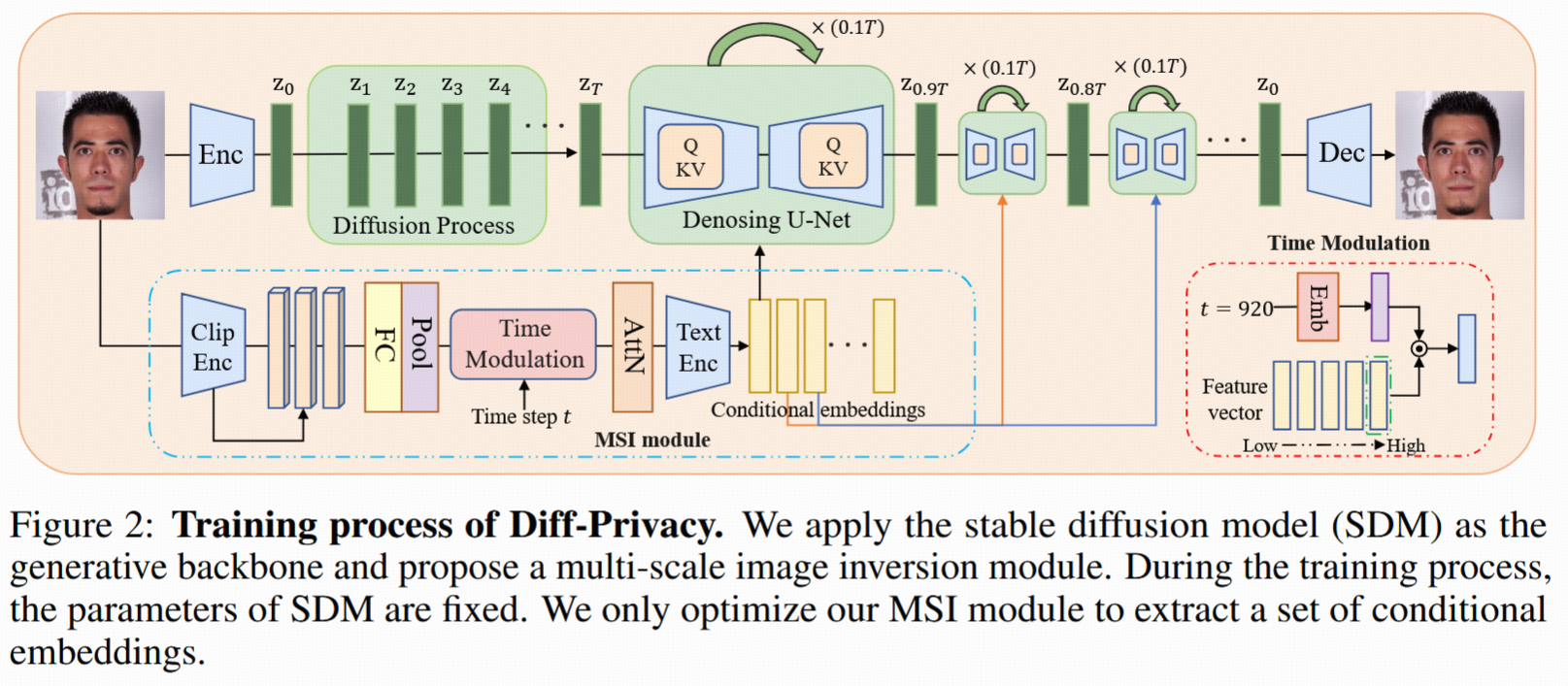
3.1 擴散模型與DDIM采樣/反演
- SDM將原圖編碼到潛空間(latent space):z? = Enc(x?)
- 加噪過程:zt = sqrt(α?)z? + sqrt(1-α?)ε(ε為高斯噪聲)
- 去噪(采樣):使用UNet網絡生成epsilon估計
- DDIM逆過程:采樣和反演公式(見Eq. 2,4),使噪音圖能夠還原原圖。
3.2 條件嵌入(Conditional Embedding)學習
1. 多階段條件嵌入空間(C*)
- 觀察:擴散模型去噪初期決定布局、結構;中期決定內容;末期生成紋理。
- 10階段嵌入方案:1000步去噪分10段,每段一個嵌入(每個token配768維向量)——更細粒度調控。
- 如何獲取嵌入:不是直接優化而是用MSI模塊,結合CLIP圖像編碼器多層特征(五層768向量),分別與時間步embedding相乘,通過注意力模塊聚合,最終對齊并得到embedding組。
2. 訓練目標
- 優化MSI,使SDM去噪誤差最小(Eq. 7)
- cross-attention做dropout防過擬合。
3.3 隱私保護機制設計
3.3.1 嵌入調度策略
- 利用多階段嵌入,不同privacy目標采用分階段切換:如去噪初/中期用無條件embedding,后期用learned embedding。
- 匿名化:前40%用無條件embedding,后60%用learned embedding。
3.3.2 能量函數身份指導模塊
- 目標:通過能量函數對去噪方向做梯度修正,實現身份相似/不同可控。
- 主要步驟:
- 利用預訓練人臉識別模型,得到embedding空間表示;
- 構建identity loss:
- 匿名化用identity dissimilarity loss(LIdis):多種噪音下生成新臉,最大化與原臉embedding夾角,保證身份差異;
- 信息隱藏用identity similarity loss(Lis):最大化加密臉和原臉embedding夾角接近(0.95),保證機器可識別。
- 構建diversity loss(Ldiv):同一原圖噪不同,加密后身份embedding也應分散,增強加密樣本多樣性。
- 在去噪流程中加能量函數引導采樣方向,Eq. 14為帶能量修正的采樣。
3.3.3 匿名化細節
- 初始加0.6強度噪音(保持布局、破壞面部)
- 結合identity dissimilarity loss和diversity loss引導生成新臉
- 先用無條件embedding,后改為learned embedding(見Eq. 18)
- 保存對應步驟DDIM逆反得到的噪音地圖,作為恢復密鑰
3.3.4 信息隱藏細節
- 初始噪音強度調高至0.8(連背景/姿態也可變)
- 用identity similarity loss增強加密臉和原臉embedding接近,機器仍能識別
- embedding調度比匿名化更偏向無條件(60%)
- 同樣保存DDIM噪音地圖,配對密鑰恢復
3.4 身份恢復機制
- 用加密/匿名后的噪音圖(key-I)+相應embedding(key-E),進入逆DDIM采樣,逐步去噪最終還原原臉。
總結
DiffPrivacy通過:
- 多尺度嵌入學習(MSI)解決少樣本高質量控制;
- 能量函數身份引導模塊實現不同身份相似/差異需求的梯度修正;
- 分階段嵌入調度,將擴散模型去噪的各階段與屬性控制靈活結合;
- 恢復過程依賴于密鑰(noise map+embedding),確保安全性。
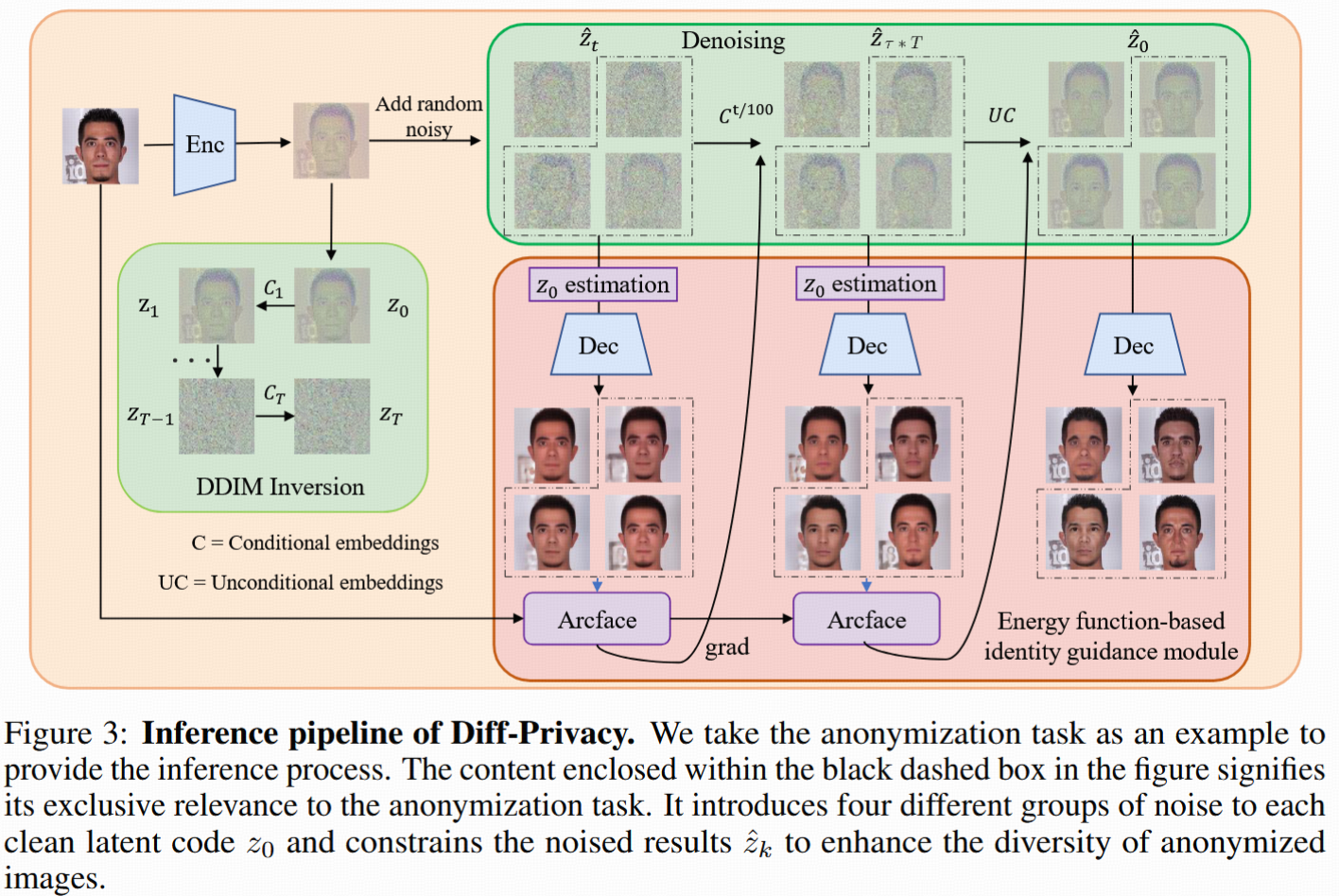
4. Experiments
4.1 實現細節
- 模型參數:僅訓練提出的MSI模塊,其余全部采用預訓練SDM默認參數。
- 訓練設備與耗時:NVIDIA RTX3090,每張圖訓練約20分鐘,batch size=1,學習率0.001。
- 評測數據集:CelebA-HQ [19] + LFW [16],涵蓋高質量與真實場景多樣性。
4.2 Anonymization
4.2.1 De-identification
對比方法:
- RiDDLE [22](可恢復)
- FIT [13](可恢復)
- CIAGAN [25]
- DeepPrivacy [17]
定性分析(Figure 4):

- CIAGAN去匿名后圖像扭曲嚴重。
- FIT改變身份但視覺質量差,屬性錯亂(如女性圖生成男性臉)。
- RiDDLE生成多樣臉,但細節不自然(如眼部畸形)。
- DeepPrivacy雖逼真,但表情等非身份屬性無法保留。
- Diff-Privacy優勢:自然逼真的面部特征,保留表情、姿態等非身份屬性,整體視覺效果優勝。
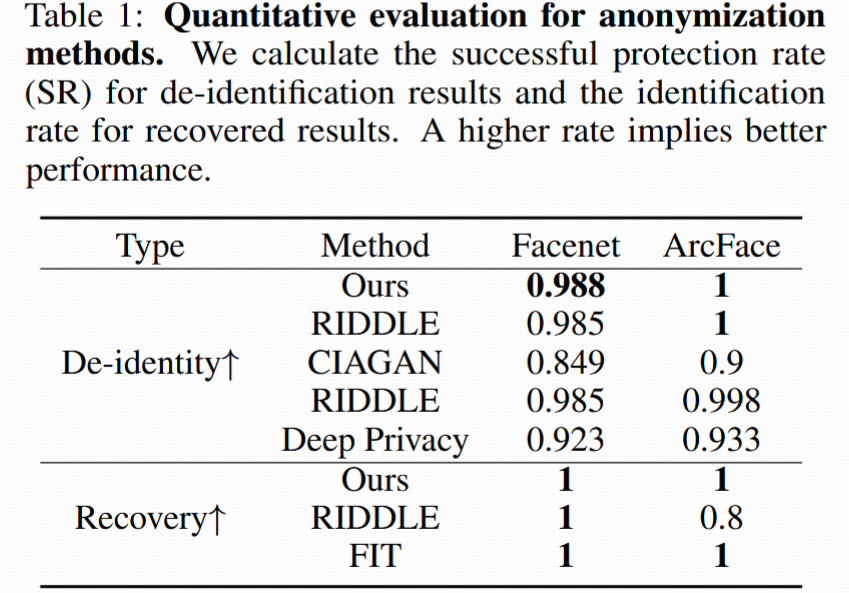
定量分析:
- 成功保護率SR(Table 1):利用人臉識別網絡(FaceNet、ArcFace),當加密臉與原臉embedding距離超過閾值,認為保護成功。
- Diff-Privacy在SR指標高于其它方法,安全性強。
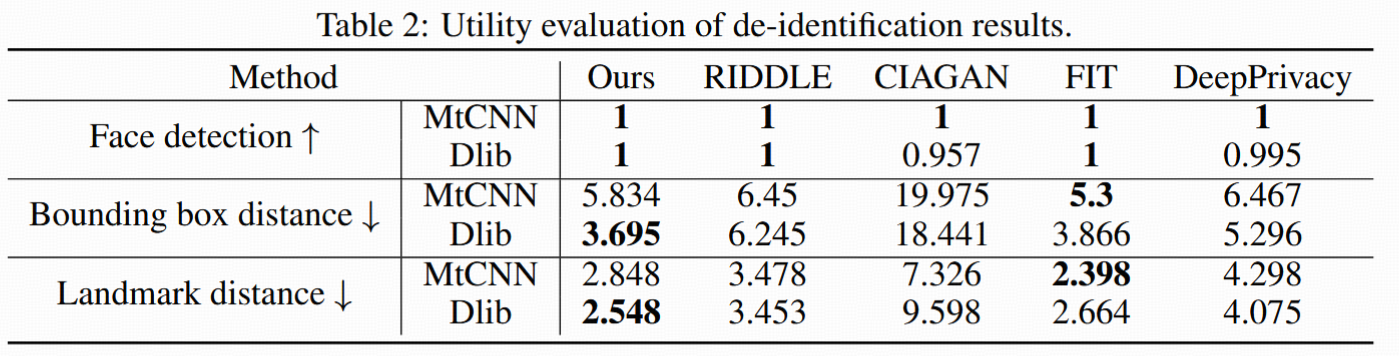
人臉檢測可用性(Table 2):
- 在MtCNN和Dlib檢測下評估檢測率以及人臉框/關鍵點距離(像素偏差)。
- Diff-Privacy檢測率最高,且結構保持度、關鍵點一致性均優。
- 支持去身份后用于一般CV任務,實用性強。
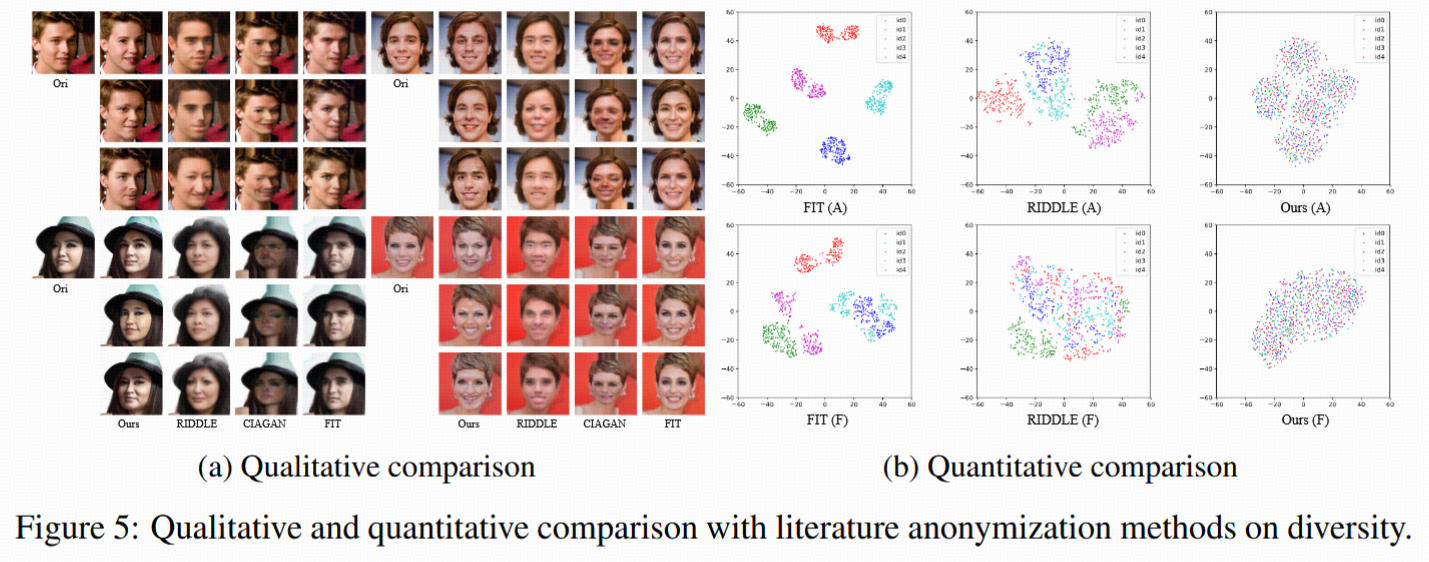
身份多樣性(Figure 5, t-SNE可視化):
- Diff-Privacy能生成多樣去身份臉,且分布更分散。
- 200組加密臉embedding分布覆蓋超大區域——隱私防護性、多樣性強于FIT等方法(后者聚類緊湊,泛化差)。
4.2.2 身份恢復
對比方法:FIT, RiDDLE(可恢復)
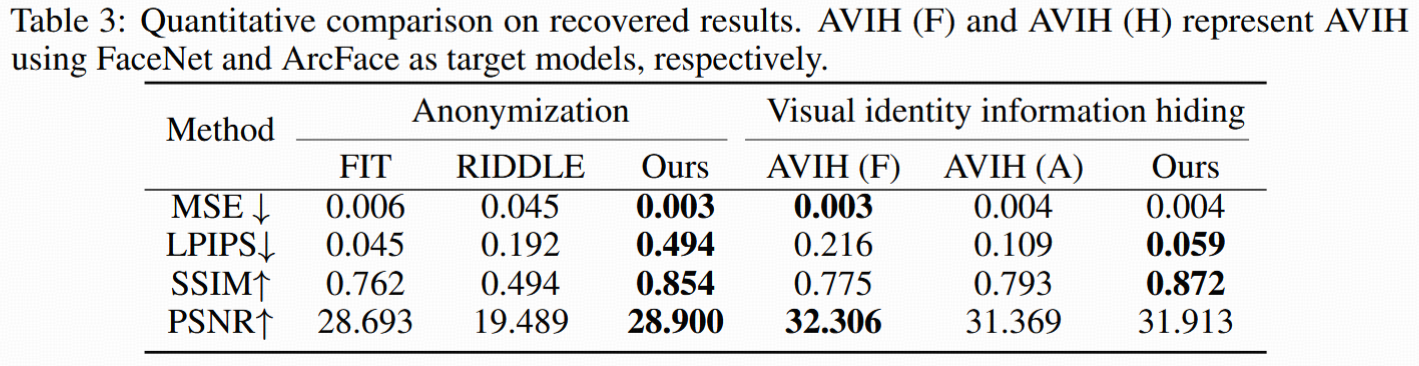
- 用識別率(Table 1底部)、原-恢復圖像相似度(MSE,PSNR,SSIM,LPIPS)(Table 3)。
- Diff-Privacy恢復后圖像清晰度、結構一致性都高于競品,視覺效果、像素級和感知級分數均優(Figure 7)。
4.3 Visual identity information hiding 視覺身份信息隱藏
4.3.1 加密評測(對比AVIH [38])
- 按AVIH流程選定12身份/10圖,other身份樣本共12878張。
- 用FaceNet和ArcFace識別,加密后判斷同身份/異身份匹配難度。
- Diff-Privacy在FaceNet識別率高于AVIH 3個百分點,ArcFace下則基本相當,接近未加密原圖識別率。
- 隱私安全性:加密臉保留真實感,黑客難判定是否被加密,提升安全性。
4.3.2 身份恢復
- 對比恢復后圖像質量(Figure 6, Table 3):AVIH像素級與Diff-Privacy相近,但感知級指標(LPIPS, SSIM)Diff-Privacy明顯優,且恢復區域更完整,無明顯偽影。
4.4 Ablation Study 消融實驗
① 條件嵌入組的作用
- 只用單一嵌入(Ours-OE)vs. 用組嵌入(完整MSI)。
- 圖像編輯性、屬性解耦、加密/恢復質量,組嵌入全面優于單嵌入(Figure 8, Table 5)。
② Embedding調度策略
- 實驗不同τ值(分階段使用無條件/學習嵌入)對于匿名化/信息隱藏后圖像identity距離的影響(Figure 8,9)。
- 匿名化推薦τ=0.4(最大化脫敏且屬性不變);信息隱藏τ=0.6(人眼變化最大但機器可識別)。
③ 噪音強度(Sns)
- 噪音變弱,生成圖像更靠近原圖;Sns=0.6適合匿名化(屬性保留),Sns=0.8最大身份差異(用于信息隱藏)(Figure 10)。
④ Diversity loss多樣性損失
- 移除多樣性損失功能后,去身份臉embedding聚集,分布減小,多樣性明顯降級(Figure 11)。
5. Conclusion 結論
論文貢獻總結:
- 統一兩大隱私需求:提出Diff-Privacy方案,兼顧可恢復匿名化和信息隱藏。
- 三階段架構:多尺度條件嵌入(key-E)、能量函數+調度引導加密(key-I)、可逆恢復。
- 實驗表現:量化與定性結果均超過主流競品,圖片質量、恢復效果、身份多樣性更優。







 React的狀態管理工具--Redux,案例--移動端外賣平臺)
(上))










