本文來自《老餅講解-BP神經網絡》https://www.bbbdata.com/
目錄
- 一、什么是隨機森林模型
- 1.1.隨機森林模型介紹
- 1.2.為什么隨機森林要用多棵決策樹
- 二、怎么訓練一個隨機森林模型
- 2.1.訓練一個隨機森林模型
隨機森林模型是機器學習中常用的模型之一,它是決策樹模型的一個延伸。
本文簡單快速直接地介紹什么是隨機森林模型以及如何實現一個隨機森林模型。
一、什么是隨機森林模型
1.1.隨機森林模型介紹
隨機森林模型顧名思義,就是有很多棵樹的模式,這里的樹,指的是決策樹。
它訓練了許多棵決策樹,然后集合在一起,作為一個集成模型進行決策。
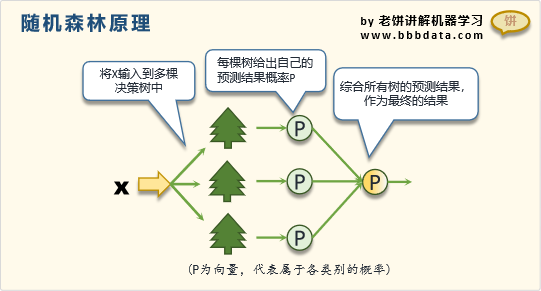
如圖所示,隨機森林的模型表達式如下:
y = 1 k [ t 1 . prob ( x ) + t 2 . prob ( x ) + . . . + t k . prob ( x ) ] \text{y}= \dfrac{1}{k} \left [ \text{t}_1.\text{prob}(x)+\text{t}_2.\text{prob}(x)+...+\text{t}_k.\text{prob}(x) \right ] y=k1?[t1?.prob(x)+t2?.prob(x)+...+tk?.prob(x)]
其中,y:隨機森林給出的各類別的預測概率
ti : 決策樹
ti*prob(x): 第i棵樹對x的預測,輸出為各個類別的預測概率(行向量)
k : 森林規模數
1.2.為什么隨機森林要用多棵決策樹
隨機森林模型采用了多棵決策樹進行集成,這主要是因為決策樹是一個極易過擬合的模型,因此集成多棵決策樹,讓它們一起進行綜合評估,使得預測結果更加穩定。
二、怎么訓練一個隨機森林模型
2.1.訓練一個隨機森林模型
在python中通過sklearn如下實現一個隨機森林模型,代碼示例如下:
# -*- coding: utf-8 -*-
"""
sklearn的隨機森林Demo
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import numpy as npnp.random.seed(888)
# ==================== 加載數據 =====================================================
iris = load_iris()
X = iris.data
y = iris.target# ========================= 模型訓練 ====================================================
clf = RandomForestClassifier(n_jobs=1,oob_score=True,max_features=2,n_estimators=100)
clf.fit(X, y)# =============================== 模型預測 ===================================================
pred_prob = clf.predict_proba(X)
pred_c = clf.predict(X)
preds = iris.target_names[pred_c]#=================打印結果==========================
print("\n----前5條預測結果:----")
print(pred_prob[0:5])
print("\n----袋外準確率oob_score:----")
print(clf.oob_score_)
print("\n----特征得分:----")
print(clf.feature_importances_)
代碼運行結果如下:
----前5條預測結果:----
[[1. 0. 0. ][0.99 0.01 0. ][1. 0. 0. ][1. 0. 0. ][1. 0. 0. ]]----袋外準確率oob_score:----
0.9533333333333334----特征得分:----
[0.08186032 0.02758341 0.44209899 0.44845728]
其中,特征得分是指每個特征對隨機森林貢獻度的占比,它是決策樹特征得分的拓展。
相關鏈接:
《老餅講解-機器學習》:老餅講解-機器學習教程-通俗易懂
《老餅講解-神經網絡》:老餅講解-matlab神經網絡-通俗易懂
《老餅講解-神經網絡》:老餅講解-深度學習-通俗易懂



)




![代碼隨想錄算法訓練營第一天 [300.最長遞增子序列 674. 最長連續遞增序列 718. 最長重復子數組]](http://pic.xiahunao.cn/代碼隨想錄算法訓練營第一天 [300.最長遞增子序列 674. 最長連續遞增序列 718. 最長重復子數組])










)