Scanpy包,用與數據整合和批次處理,包含批次效應的BBKNN算法和用于對比的ingest基礎算法比較,及其原理簡介。
1. 依賴:
(1)數據集(全部需要掛VPN):
- PBMC:pbmc3k_processed()(需要下載);pbmc68k_reduced()(scanpy自帶)
- Pancreas(需要下載)
(2)Python包:Scanpy、BBKNN
2. PBMC數據集
導入所需的包
import scanpy as sc
import pandas as pd
import seaborn as sns
# 參考數據集(已預處理、降維、聚類、注釋)
adata_ref = sc.datasets.pbmc3k_processed() # this is an earlier version of the dataset from t
# 參考數據集(已預處理、降維、聚類、注釋)
adata = sc.datasets.pbmc68k_reduced()
print(adata_ref)
生成:
上面下載數據自動放入這里
data
? pancreas.h5ad
? pbmc3k_processed.h5ad
2.1 重點數據結構分析
# 1. adata_ref
AnnData object with n_obs × n_vars = 2638 × 1838obs: 'n_genes', 'percent_mito', 'n_counts', 'louvain'var: 'n_cells'uns: 'draw_graph', 'louvain', 'louvain_colors', 'neighbors', 'pca', 'rank_genes_groups'obsm: 'X_pca', 'X_tsne', 'X_umap', 'X_draw_graph_fr'varm: 'PCs'obsp: 'distances', 'connectivities'
在 `scanpy` 中,`AnnData`(Annotated Data)是一個用于存儲和操作單細胞RNA-seq等生物學數據的數據結構。以下是對`adata_ref`對象中各個字段的解釋:- `obs`:觀測(observations)信息,即每個細胞或樣本的元信息。在這個例子中包括:- `'n_genes'`:每個細胞中表達的基因數量。- `'percent_mito'`:每個細胞中線粒體基因的百分比。- `'n_counts'`:每個細胞的總計數。- `'louvain'`:【聚類結果,表示每個細胞屬于哪個聚類。】- `var`:變量信息,即基因的元信息。在這個例子中包括:- `'n_cells'`:每個基因在多少個細胞中被檢測到。- `uns`:未結構化的數據,可以存儲各種附加信息。在這個例子中包括:- `'draw_graph'`:用于存儲繪圖圖形的信息。- `'louvain'`:用于存儲Louvain聚類的信息。- `'louvain_colors'`:Louvain聚類結果的顏色映射。- `'neighbors'`:用于存儲鄰域信息的數據。- `'pca'`:用于存儲主成分分析(PCA)的信息。- `'rank_genes_groups'`:用于存儲基因組中基因排序的信息。- `obsm`:觀測矩陣,包含與觀測相關的矩陣數據。在這個例子中包括:- `'X_pca'`:PCA降維后的坐標。- `'X_tsne'`:t-SNE降維后的坐標。- `'X_umap'`:UMAP降維后的坐標。- `'X_draw_graph_fr'`:繪圖圖形的坐標。- `varm`:變量矩陣,包含與變量相關的矩陣數據。在這個例子中包括:- `'PCs'`:主成分分析的主成分。- `obsp`:觀測矩陣中的矩陣,包含與觀測相關的矩陣數據。在這個例子中包括:- `'distances'`:細胞之間的距離矩陣。- `'connectivities'`:細胞之間的連接性矩陣。這些字段提供了關于單細胞RNA-seq數據集的豐富信息,包括細胞的特征、基因的特征、降維后的坐標、聚類結果等。# 2. adata
AnnData object with n_obs × n_vars = 700 × 765obs: 'bulk_labels', 'n_genes', 'percent_mito', 'n_counts', 'S_score', 'G2M_score', 'phase', 'louvain'var: 'n_counts', 'means', 'dispersions', 'dispersions_norm', 'highly_variable'uns: 'bulk_labels_colors', 'louvain', 'louvain_colors', 'neighbors', 'pca', 'rank_genes_groups'obsm: 'X_pca', 'X_umap'varm: 'PCs'obsp: 'distances', 'connectivities'
2.2 原始數據可視化
sc.pl.umap(adata_ref, color='louvain')
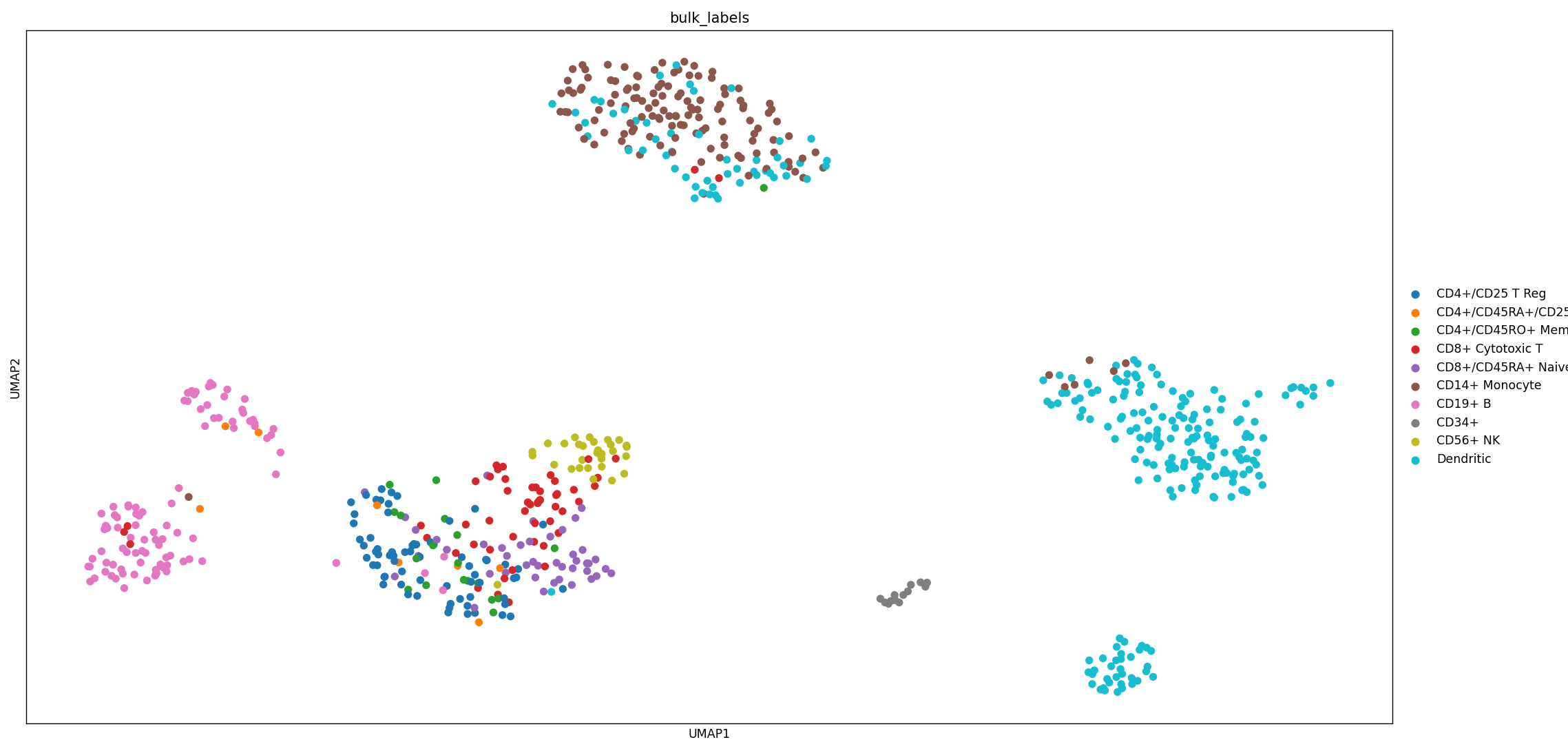
sc.pl.umap(adata, color='bulk_labels') # obs: 'bulk_labels',
adata_ref 數據可視化
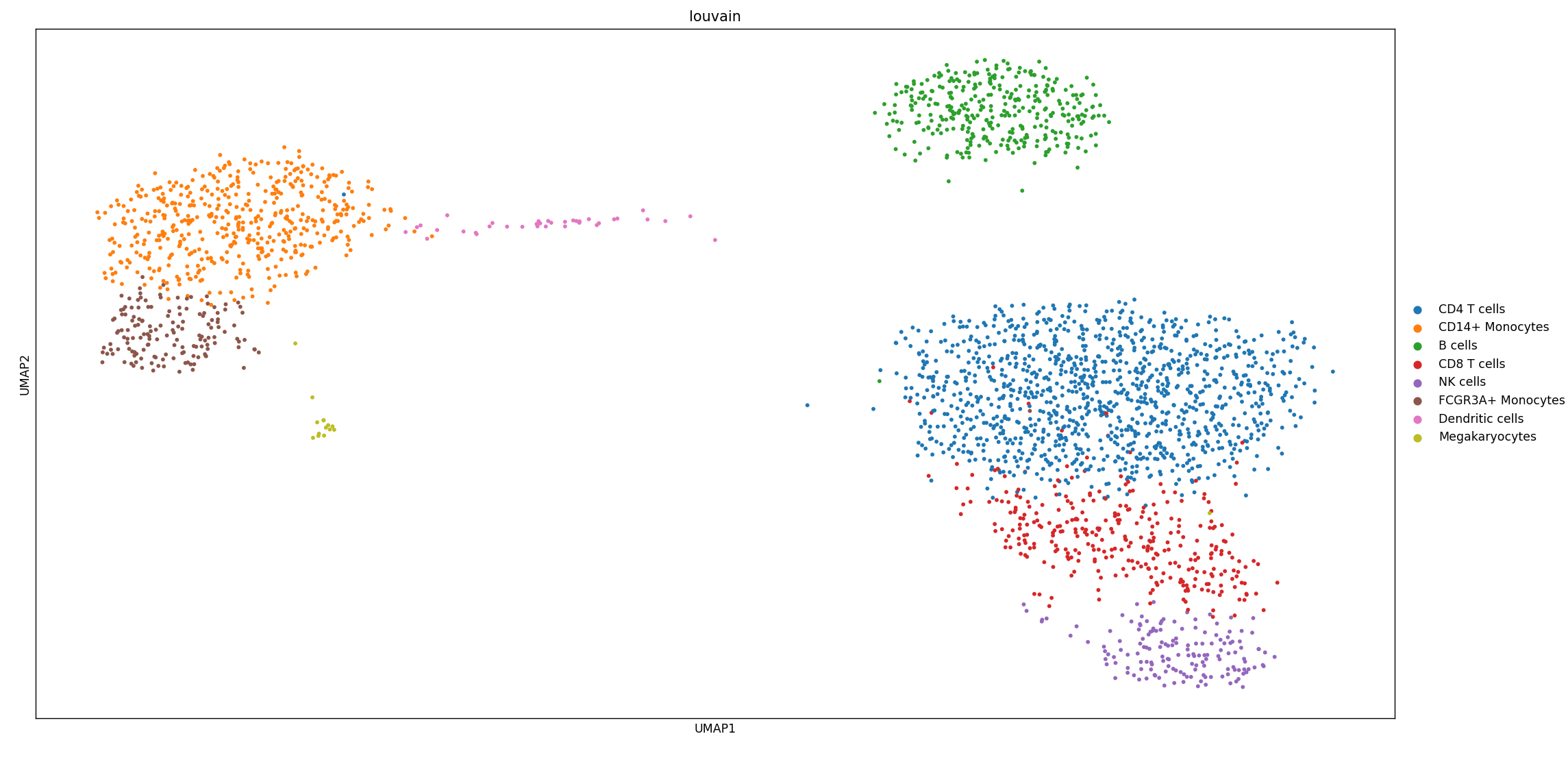
adata 數據可視化
adata_ref.obs和adata.obs
# adata_ref.obsn_genes percent_mito n_counts louvain
index
AAACATACAACCAC-1 781 0.030178 2419.0 CD4 T cells
AAACATTGAGCTAC-1 1352 0.037936 4903.0 B cells
AAACATTGATCAGC-1 1131 0.008897 3147.0 CD4 T cells
AAACCGTGCTTCCG-1 960 0.017431 2639.0 CD14+ Monocytes
AAACCGTGTATGCG-1 522 0.012245 980.0 NK cells
... ... ... ... ...
TTTCGAACTCTCAT-1 1155 0.021104 3459.0 CD14+ Monocytes
TTTCTACTGAGGCA-1 1227 0.009294 3443.0 B cells
TTTCTACTTCCTCG-1 622 0.021971 1684.0 B cells
TTTGCATGAGAGGC-1 454 0.020548 1022.0 B cells
TTTGCATGCCTCAC-1 724 0.008065 1984.0 CD4 T cells# adata.obsbulk_labels n_genes percent_mito n_counts S_score G2M_score phase louvain
index
AAAGCCTGGCTAAC-1 CD14+ Monocyte 1003 0.023856 2557.0 -0.119160 -0.816889 G1 1
AAATTCGATGCACA-1 Dendritic 1080 0.027458 2695.0 0.067026 -0.889498 S 1
AACACGTGGTCTTT-1 CD56+ NK 1228 0.016819 3389.0 -0.147977 -0.941749 G1 3
AAGTGCACGTGCTA-1 CD4+/CD25 T Reg 1007 0.011797 2204.0 0.065216 1.469291 G2M 9
ACACGAACGGAGTG-1 Dendritic 1178 0.017277 3878.0 -0.122974 -0.868185 G1 2
... ... ... ... ... ... ... ... ...
TGGCACCTCCAACA-8 Dendritic 1166 0.008840 3733.0 -0.124456 -0.867484 G1 2
TGTGAGTGCTTTAC-8 Dendritic 1014 0.022068 2311.0 -0.298056 -0.649070 G1 1
TGTTACTGGCGATT-8 CD4+/CD25 T Reg 1079 0.012821 3354.0 0.216895 -0.527338 S 0
TTCAGTACCGGGAA-8 CD19+ B 1030 0.014169 2823.0 0.139054 -0.981590 S 4
TTGAGGTGGAGAGC-8 Dendritic 1552 0.010886 4685.0 -0.148449 -0.674752 G1 2
# adata_ref.obs_names
Index(['AAACATACAACCAC-1', 'AAACATTGAGCTAC-1', 'AAACATTGATCAGC-1','AAACCGTGCTTCCG-1', 'AAACCGTGTATGCG-1', 'AAACGCACTGGTAC-1','AAACGCTGACCAGT-1', 'AAACGCTGGTTCTT-1', 'AAACGCTGTAGCCA-1','AAACGCTGTTTCTG-1',...'TTTCAGTGTCACGA-1', 'TTTCAGTGTCTATC-1', 'TTTCAGTGTGCAGT-1','TTTCCAGAGGTGAG-1', 'TTTCGAACACCTGA-1', 'TTTCGAACTCTCAT-1','TTTCTACTGAGGCA-1', 'TTTCTACTTCCTCG-1', 'TTTGCATGAGAGGC-1','TTTGCATGCCTCAC-1'],dtype='object', name='index', length=2638)# var_names
Index(['TNFRSF4', 'SRM', 'TNFRSF1B', 'EFHD2', 'C1QA', 'C1QB', 'STMN1','MARCKSL1', 'SMAP2', 'PRDX1',...'EIF3D', 'LGALS2', 'ADSL', 'TTC38', 'TYMP', 'ATP5O', 'TTC3', 'SUMO3','S100B', 'PRMT2'],dtype='object', name='index', length=208)
也可以看到數據本身還有其他的:

以下信息放置到文章上方,本實例并沒有采用。
sc.settings.verbosity = 1 # verbosity: errors (0), warnings (1), info (2), hints (3)
sc.logging.print_versions()
sc.settings.set_figure_params(dpi=80, frameon=False, figsize=(8</




)


)








,簡介)

