前面提到過進程是由很多線程組成的,那么今天廖老師就詳細解釋了線程是如何運行的。
首先,,Python的標準庫提供了兩個模塊:_thread和threading,_thread是低級模塊,threading是高級模塊,對_thread進行了封裝。絕大多數情況下,我們只需要使用threading這個高級模塊。
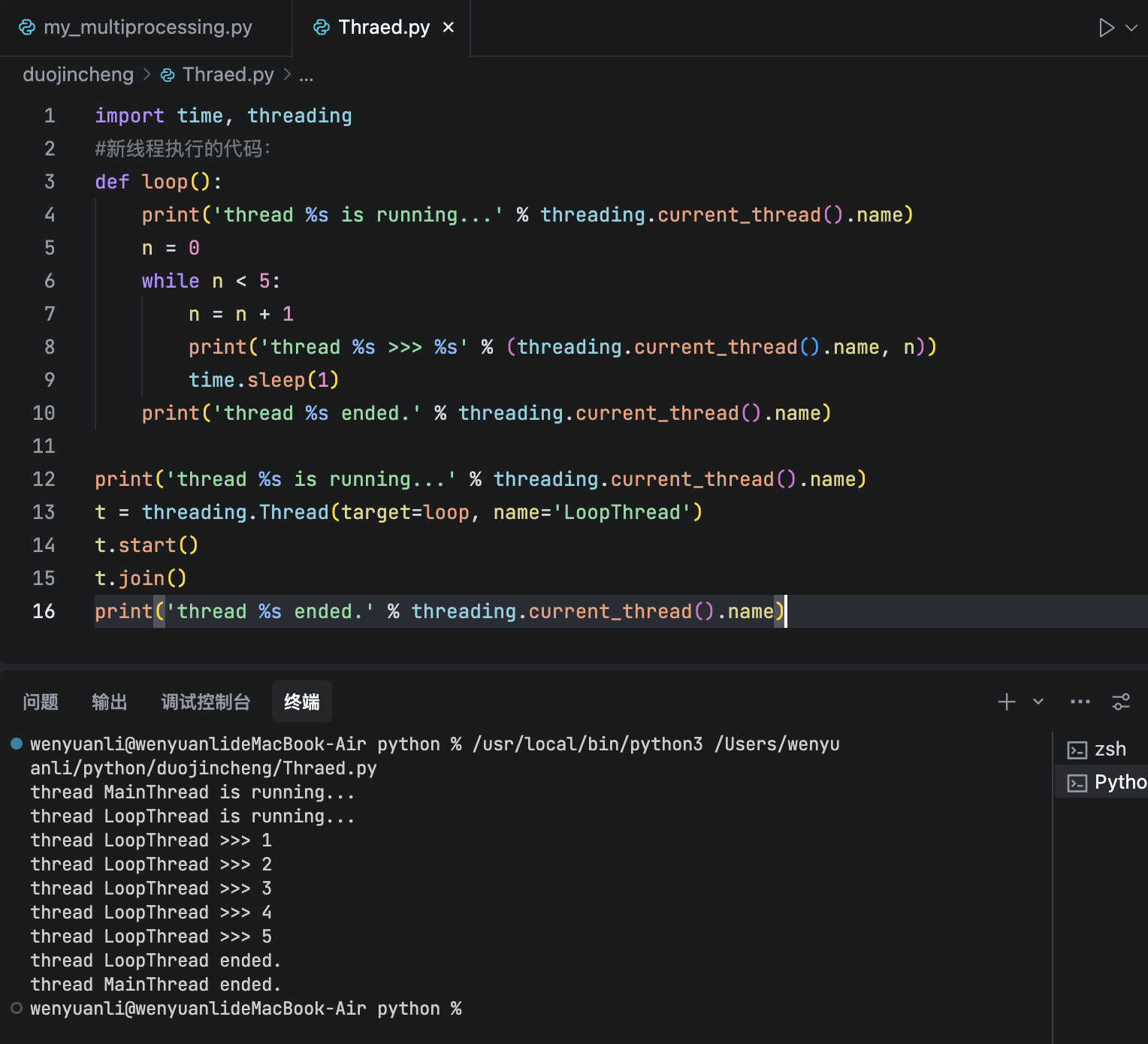
根據廖老師的例子,運行出來如此的結果。
任何 Python 程序默認都在一個主線程中運行,該線程通常名為?MainThread
threading.current_thread().name用于獲取當前正在執行的線程的名稱。
t = threading.Thread(target=loop, name='LoopThread') ? 這里使用?threading.Thread類來創建一個線程對象 ,也就是我們所需要的支線線程
start()方法會??啟動新線程??。這意味著 Python 會創建新的執行上下文,并??幾乎同時??開始在新線程中執行?loop函數
重要的是,調用?start()后,主線程不會阻塞,它會繼續向下執行(t.join()),而新線程?LoopThread也開始并發地執行自己的任務。
不過由于多進程中,同一個變量,各自有一份拷貝存在于每個進程中,互不影響,而多線程中,所有變量都由所有線程共享,所以,任何一個變量都可以被任何一個線程修改,因此,線程之間共享數據最大的危險在于多個線程同時改一個變量,把內容給改亂了。所以我們這里會引入一個lock語句
balance = 0
lock = threading.Lock()def run_thread(n):for i in range(100000):# 先要獲取鎖:lock.acquire()try:# 放心地改吧:change_it(n)finally:# 改完了一定要釋放鎖:lock.release()創建一個鎖就是通過threading.Lock()來實現。
不過這里的鎖雖然可以讓我們的內容不那么紊亂,但是包含鎖的某段代碼實際上只能以單線程模式執行,效率就大大地下降了甚至他會讓多個鎖在一起執行可能形成一個死鎖。


:Kubernetes架構-原理-組件)

類型和Option類型)




)









:讓大模型能夠回答私域知識問題)