1. 切片
1.1 介紹
切片在Go中是一個引用類型,它包含三個組成部分:指向底層數組的指針(pointer)、切片的長度(length)以及切片的容量(capacity),這些信息共同構成了切片的“頭(header)”。
切片是一個非常奇怪的集合體,它底層用的是數組,但它又能把數組值復制這個問題規避掉。
為啥底層是數組呢?因為它需要使用順序表,因為使用索引訪問,在順序表中是最快的。
1.2 特點
它的特點如下:
(1)長度可以變,容量可變,長度和容量可以不一樣,首次定義時,長度和容量相同。
長度:表示當前元素的數量
容量:表示最多可以定義多少個元素。
如切片長度3,容量5,含義為我切片中最多可以放5個元素,但當前只用了3個,還剩2個元素可以放置。
我把它理解為k8s中的request和limit。
(2)引用類型
切片之間引用(復制)的是header,并不是直接引用內存地址。
(3)底層基于數組
1.3 定義方式
1.3.1 方式一:字面量賦值定義
該方式適合小批量的定義,如果切片元素過多,就不太適合了。
package mainimport "fmt"func main() {// 錯誤的聲明方式// var s0 = []int// 這就是定義一個切片,如果在[]中加上數字或者...,那就是一個數組// 這里的int可以是go中支持的任意數據類型,但元素類型必須一致var s0 = []int{1, 2, 3} // 該切片長度為3,容量為3fmt.Printf("%v\n%[1]T", s0)
}
=========調試結果=========
[1 2 3] // 光從輸出結果來看,是無法分辨數組和切片
[]int // 打印值類型就可以,[]中為空,就表示切片
1.3.2 方式二:聲明空切片(不推薦)
package mainimport "fmt"func main() {// 定義一個長度為0,容量為0的切片var s1 []intfmt.Printf("%T %[1]v %d %d", s1, len(s1), cap(s1))
}
=========調試結果=========
[]int [] 0 0
1.3.3 方式三:make(推薦)
make可以給內建容器開辟內存空間,比較適合用于多元素定義的場景。
并且make還能指定初始容量大小,減少頻繁擴容。
但是注意,不同的數據類型使用make,參數含義是不一樣的。
package mainimport "fmt"func main() {// 0,表示長度為0,目前由于沒有元素,所以容量也為0。// 切片使用make,()中的第二個參數表示長度var s3 = make([]int, 0)fmt.Println(s3, len(s3), cap(s3))// 切片使用make,()中的第二個參數0表示長度,第三個參數5表示容量s4 := make([]string, 0, 5)fmt.Println(s4, len(s4), cap(s4))
}
=========調試結果=========
[] 0 0 // 長度為0,容量為0
[] 0 5 // 長度為0,容量為5
1.4 切片內存模型
切片的內存模型大致如下,還能稱為切片的herdedr:
(1)pointer
存放的指向底層數組的指針。
這個指針指向切片實際引用的數組元素的起始位置。通過這個指針,切片能夠訪問和操作底層數組中的元素。
(2)len
存放當前切片的長度,這個長度決定了切片可以訪問的底層數組元素的范圍。
(3)cap
存放當前切片的容量,容量反映了切片可以增長元素的最大范圍,即在不需要重新分配底層數組的情況下,可以向切片追加的元素數量。
由于切片需要使用順序表,所以它的底層其實還是依賴數組的。
但是數組一旦定死它的長度是不可變的,而切片的長度和容量都可變,那數組的長度不夠咋辦呢?
切換底層數組,當切片需要擴容,但底層數組長度又不夠的時候,go會廢棄這個老的底層數組,再創建一個新的滿足切片擴容長度的底層數組。

1.4.1 切片元素內存地址理解
package mainimport "fmt"func main() {var s0 = []int{1, 2, 3}fmt.Printf("%p %p\n", &s0, &s0[0])// &s0,表示的是當前這個結構體(切片)的內存地址(header地址)。// &s0[0],表示的是當前這個切片底層數組的第一個元素的內存地址,也是底層數組的首地址。
}
=========調試結果=========
0xc000008078 0xc000010168
1.4.2 追加內容到切片(append)
append內置函數,用于在切片的尾部追加元素,并且不會修改當前切片的header,因為它總是會返回一個新的header(至于header內容是否改變,取決于操作的切片是新還是舊)。
如果是基于老切片新增元素給新切片,則header可能會發生變化,也就是說pointer、len、cap都有可能會發生變化。
增加元素后,有可能超過當前切片容量,導致切片擴容(切片擴容容量為擴容前已存在元素的倍數)。
注意append只能用于切片。
package mainimport "fmt"func main() {var s0 = []int{1, 2, 3}fmt.Printf("%p %p\n", &s0, &s0[0])// append(s0, 11),表示對s0進行尾部元素追加,追加完畢后又寫入到s0s0 = append(s0, 11)fmt.Println(s0, &s0[0])
}
=========調試結果=========
0xc000008078 0xc000010168
// 11就是追加的內容,并且追加后,底層數組的首地址也發生了改變
// 這是符合上面的推斷的
[1 2 3 11] 0xc00000e3c0
1.4.2.1 切片長度與容量
package mainimport "fmt"func main() {// 切片長度為3,容量為5var s0 = make([]int, 3, 5)fmt.Printf("切片內存地址:%p\n底層數組首地址:%p\n切片元素數量:%d\n切片容量:%v\n切片元素:%v", &s0, &s0[0], len(s0), cap(s0), s0)
}
=========調試結果=========
切片內存地址:0xc000116060
底層數組首地址:0xc000142030
切片元素數量:3
切片容量:5
切片元素:[0 0 0]
基于老切片追加元素到新切片,觀察新老切片的變化。
// 上面s0切片還是3個0值,下面我給他調整一下
package mainimport "fmt"func main() {var s0 = make([]int, 3, 5)fmt.Printf("切片內存地址:%p\n底層數組首地址:%p\n切片元素數量:%d\n切片容量:%v\n切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)fmt.Println("----------------------------------")// 向s0追加兩個元素,得到新的切片s1s1 := append(s0, 1, 2)fmt.Println(s0, len(s0), cap(s0))fmt.Println(s1, len(s1), cap(s1))
}
=========調試結果=========
切片內存地址:0xc0000aa060
底層數組首地址:0xc0000d8030
切片元素數量:3
切片容量:5
切片元素:[0 0 0]
----------------------------------
// 看這部分
[0 0 0] 3 5 // 這是s0
[0 0 0 1 2] 5 5 // 這是s1
為什么s0的長度和容量與s1不一樣?
這就不得不再說下切片的herdedr了,首先最開始用make定義切片的時候,var s0 = make([]int, 3, 5),這個切片中只存儲了3個0元素,但由于容量為5,實際上還能增加2個元素。
所以追加兩個元素后(??s0??原本長度為3,追加后長度為5),總長度并沒有超過原切片的容量(5),所以??append??操作是在原切片??s0??的底層數組上進行的,并且??s1??和??s0??共享同一個底層數組。但是,??s1??和??s0??是兩個不同的切片頭(header),因為它們有不同的長度。
那這里思考一個問題,s0和s1的底層數組是否相同?
看下面的代碼:
package mainimport "fmt"func main() {// 定義一個長度為3,容量為5的切片var s0 = make([]int, 3, 5)fmt.Printf("切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)fmt.Println("----------------------------------")// 向s0追加兩個元素,得到新的切片s1s1 := append(s0, 1, 2)// fmt.Println(s0, len(s0), cap(s0))// fmt.Println(s1, len(s1), cap(s1))fmt.Printf("切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)
}
=========調試結果=========
切片內存地址:0xc000080048 底層數組首地址:0xc0000aa030 切片元素數量:3 切片容量:5 切片元素:[0 0 0]
----------------------------------
切片內存地址:0xc000080078 底層數組首地址:0xc0000aa030 切片元素數量:5 切片容量:5 切片元素:[0 0 0 1 2]
通過上面的返回可以看到,s0切片和s1切片的header(內存地址)不同,但底層數組地址完全一樣,究其原因就是因為底層數組的長度是滿足元素新增的,所以實際上兩個切片都是引用的同一個數組(數據是存在同一個內存空間中的)。
既然底層是同一個數組,為什么s0和s1顯示的內容不同?
可以把切片的長度當成一個窗簾,底層數組實際上就是存儲著00012,但由于s0受到長度3的限制,所以我們是看不到超過長度3的內容的。
為啥兩個切片的header不同呢?
因為兩個切片的元素數量不同,所以s1 := append(s0, 1, 2)插入元素后返回值給s1時,header中的len被更新了,所以header看著不一樣,其實簡單理解,s0和s1都是一個獨立的切片,所以header肯定不一樣,雖然它們底層引用的都是相同的數組。
1.4.2.2 切片容量溢出
這里主要講一下,切片容量溢出后,底層到底是怎么做的。
主要看下面新增的s3切片:
package mainimport "fmt"func main() {// 定義一個長度為3,容量為5的切片var s0 = make([]int, 3, 5)fmt.Printf("s0 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)fmt.Println("----------------------------------")// 向s0追加兩個元素,得到新的切片s1。s1 := append(s0, 1, 2)fmt.Printf("s1 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)fmt.Println("----------------------------------")s2 := append(s0, -1)fmt.Printf("s2 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s2, &s2[0], len(s2), cap(s2), s2)fmt.Println("----------------------------------")// 向s2追加三個元素,得到新的切片s3s3 := append(s2, 3, 4, 5)fmt.Printf("s3 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
=========調試結果=========
s0 切片內存地址:0xc000008078 底層數組首地址:0xc00000e3c0 切片元素數量:3 切片容量:5 切片元素:[0 0 0]
----------------------------------
s1 切片內存地址:0xc0000080a8 底層數組首地址:0xc00000e3c0 切片元素數量:5 切片容量:5 切片元素:[0 0 0 1 2]
----------------------------------
s2 切片內存地址:0xc0000080d8 底層數組首地址:0xc00000e3c0 切片元素數量:4 切片容量:5 切片元素:[0 0 0 -1]
----------------------------------
s3 切片內存地址:0xc000008108 底層數組首地址:0xc000012230 切片元素數量:7 切片容量:10 切片元素:[0 0 0 -1 3 4 5]
上述代碼中,通過向s2追加三個元素,得到新的切片s3。
具體的實現邏輯大概是這樣:
s2底層數組容量為5,長度為4,append要新增3個,超了2個,觸發擴容,于是向系統申請一塊新的連續(順序表)的內存空間,然后將s2底層數組中已有的數據復制過來,再把要追加的元素寫入,最終得到一個新的底層數組,并且append還會返回一個全新的header給到s3,其中pointer指向新的底層數組、切片長度為7、切片容量為10(系統會自動冗余一些空間,后續講擴容策略)。
1.5 切片的擴容機制
官方文檔:??https://go.dev/src/runtime/slice.go??
(老版本)實際上,當擴容后的cap<1024時,擴容翻倍,容量變成之前的2倍;當cap>=1024時,變成之前的1.25倍(擴容前已存在元素的倍數)。
(新版本1.18+)閾值變成了256,當擴容后的cap<256時,擴容翻倍,容量變成之前的2倍(擴容前已存在元素的倍數);當cap>=256時, newcap += (newcap + 3*threshold) / 4 計算后就是 newcap = newcap +
newcap/4 + 192 ,即1.25倍后再加192。
擴容是創建新的底層數組,把原內存數據拷貝到新內存空間,然后在新內存空間上執行元素追加操作。
切片頻繁擴容成本非常高(元素越多,復制時間越長),所以盡量早估算出使用的大小,一次性給夠,建議使用make。常用make([]int, 0, 100) 。
header復制也會消耗資源,但是很少。
如:var s1 = s0,這種就是header結構體復制
思考一下:如果 s1 := make([]int, 3, 100) ,然后對s1進行append元素,會怎么樣?
當追加的元素不超過切片容量時,只有切片長度會變,其他不變。
如果超過了容量,那么就會觸發擴容。

1.6 引用類型
在Go語言中,引用類型(Reference Types)是指那些在賦值、作為函數參數傳遞或作為函數返回值時,傳遞的是指針(即內存地址)的類型,而不是值本身。
這意味著,當操作引用類型的變量時,實際上是在操作其指向的內存位置上的數據。
但嚴格意義上來說,復制的是header。
Go語言中的引用類型包括切片(slices)、映射(maps)、通道(channels)、接口(interfaces)、函數類型以及指向它們的指針。
1.6.1 思考以下代碼切片之間是否發生了復制
package mainimport "fmt"func main() {var s0 = []int{1, 3, 5}fmt.Printf("s0 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)s1 := s0fmt.Printf("s1 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)
}
=========調試結果=========
s0 切片內存地址:0xc000008078 底層數組首地址:0xc000010168 切片元素數量:3 切片容量:3 切片元素:[1 3 5]
s1 切片內存地址:0xc0000080a8 底層數組首地址:0xc000010168 切片元素數量:3 切片容量:3 切片元素:[1 3 5]
通過返回結果可以得出,只是把切片賦值給另一個新切片,只有header地址會改變,header中的pointer、len、cap都不會變。
這說明什么?說明s0和s1之間,只復制了header結構體,但header中的pointer、len、cap都沒變。
如果把s1切片的元素修改,s0切片會改變嗎?
package mainimport "fmt"func main() {var s0 = []int{1, 3, 5}// fmt.Printf("s0 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)s1 := s0// fmt.Printf("s1 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s1[0] = 100fmt.Println(s0, s1)
}
=========調試結果=========
[100 3 5] [100 3 5]
表面上看,操作s1就好像在操作s0,有點類似復制了切片的內存地址,通過地址操作兩個切片一起變,但實際上還是因為兩個切片共用同一個底層數組。
1.6.2 使用函數傳參是否會發生復制
package mainimport "fmt"func showAddr(s2 []int) { // 新增函數fmt.Printf("s2 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s2, &s2[0], len(s2), cap(s2), s2)
}func main() {var s0 = []int{1, 3, 5}fmt.Printf("s0 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s0, &s0[0], len(s0), cap(s0), s0)s1 := s0fmt.Printf("s1 切片內存地址:%p 底層數組首地址:%p 切片元素數量:%d 切片容量:%v 切片元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)s1[0] = 100// fmt.Println(s0, s1)showAddr(s0) // 函數傳參
}
=========調試結果=========
s0 切片內存地址:0xc000008078 底層數組首地址:0xc000010168 切片元素數量:3 切片容量:3 切片元素:[1 3 5]
s1 切片內存地址:0xc0000080a8 底層數組首地址:0xc000010168 切片元素數量:3 切片容量:3 切片元素:[1 3 5]
s2 切片內存地址:0xc0000080d8 底層數組首地址:0xc000010168 切片元素數量:3 切片容量:3 切片元素:[100 3 5]
通過結果得出,只有header結構體發生了復制,但header中存儲的pointer、len、cap不變。
1.7 總結
Go語言中全都是值拷貝(復制),如整型、數組這樣的類型的值是完全復制,slice、map、channel、interface、function這樣的引用類型也是值拷貝,不過復制的是標頭值。
2 . 子切片
2.1 介紹
切片可以通過指定索引區間獲得一個子切片,格式為slice[start:end],規則就是前包后不包,對應元素的索引。
2.2 子切片特點
子切片(slice)是基于底層數組的一個視圖或者窗口。
當從一個已有的切片中創建子切片時,實際上是在共享同一個底層數組,而不是創建一個新的、獨立的數組。因此,子切片的創建本身不會導致底層數組的擴容。
但是,如果使用append追加,則是有可能觸發擴容的。
2.3 子切片語法
slice[start:end]
start:不寫默認為0。
end:不寫話,默認為切片長度。
注意:指定start和end時,不能超過切片的容量。
2.4 子切片示例
2.4.1 示例一:完全復制header
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的內存地址:%p|s1的底層數組首地址:%p|s1的長度:%d|s1的容量:%d|s1的元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)// 把s1切片賦值給s2s2 := s1 // 本質上就是在復制headerfmt.Printf("s2的內存地址:%p|s2的底層數組首地址:%p|s2的長度:%d|s2的容量:%d|s2的元素:%v\n", &s2, &s2[0], len(s2), cap(s2), s2)// 開始子切片s3 := s1[:] //構建一個新的header,但不會新建數組fmt.Printf("s3的內存地址:%p|s3的底層數組首地址:%p|s3的長度:%d|s3的容量:%d|s3的元素:%v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
===========調試結果===========
s1的內存地址:0xc0000aa060|s1的底層數組首地址:0xc0000d8030|s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s2的內存地址:0xc0000aa090|s2的底層數組首地址:0xc0000d8030|s2的長度:5|s2的容量:5|s2的元素:[10 30 50 70 90]
s3的內存地址:0xc0000aa0c0|s3的底層數組首地址:0xc0000d8030|s3的長度:5|s3的容量:5|s3的元素:[10 30 50 70 90]
通過上面的代碼,可以看到s3子切片后,結果和之前的相同,說明了什么?
子切片和原來的切片使用的底層數組也是同一個。
2.4.2 示例二:偏移切片
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的內存地址:%p|s1的底層數組首地址:%p|s1的長度:%d|s1的容量:%d|s1的元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)// 首地址發生變化,切偏移一個元素,最終的長度和容量都-1s4 := s1[1:]fmt.Printf("s4的內存地址:%p|s4的底層數組首地址:%p|s4的長度:%d|s4的容量:%d|s4的元素:%v\n", &s4, &s4[0], len(s4), cap(s4), s4)}
===========調試結果===========
s1的內存地址:0xc000008078|s1的底層數組首地址:0xc00000e3c0|s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s4的內存地址:0xc0000080a8|s4的底層數組首地址:0xc00000e3c8|s4的長度:4|s4的容量:4|s4的元素:[30 50 70 90]
看結果:
s1的底層數組首地址:0xc00000e3c0
s4的底層數組首地址:0xc00000e3c8
是不是以為底層數組變了?錯,子切片過程中,只要沒有append操作,底層數組依然還是同一個。
之所以一個首地址是3c0,一個是3c8,是因為int類型就占用8個字節。
并且s4 := s1[1:],意思是偏移了一個元素(把第一個元素擋住了,看不到了),所以此時的首地址就變成了第二個元素的內存地址。
并且由于偏移了一個元素,所以子切片的容量就為4,長度呢?長度沒有指定,所以就從偏移處直到末尾,為4。
2.4.3 示例三:指定start和end
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的內存地址:%p|s1的底層數組首地址:%p|s1的長度:%d|s1的容量:%d|s1的元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)// s1[1:4],展示元素索引1,2,3的元素。s5 := s1[1:4]fmt.Printf("s5的內存地址:%p|s5的底層數組首地址:%p|s5的長度:%d|s5的容量:%d|s5的元素:%v\n", &s5, &s5[0], len(s5), cap(s5), s5)}
===========調試結果===========
s1的內存地址:0xc00009a060|s1的底層數組首地址:0xc0000c8030|s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s5的內存地址:0xc00009a090|s5的底層數組首地址:0xc0000c8038|s5的長度:3|s5的容量:4|s5的元素:[30 50 70]
s5此處的切片長度為:3
s5此處的切片容量為:4
那這個長度和容量是怎么計算出來的?
子切片長度計算方式:end減去start
子切片容量計算方式:從偏移量(start索引)開始到切片底層數組的最后一個元素。
2.4.4 示例四:start和end相同
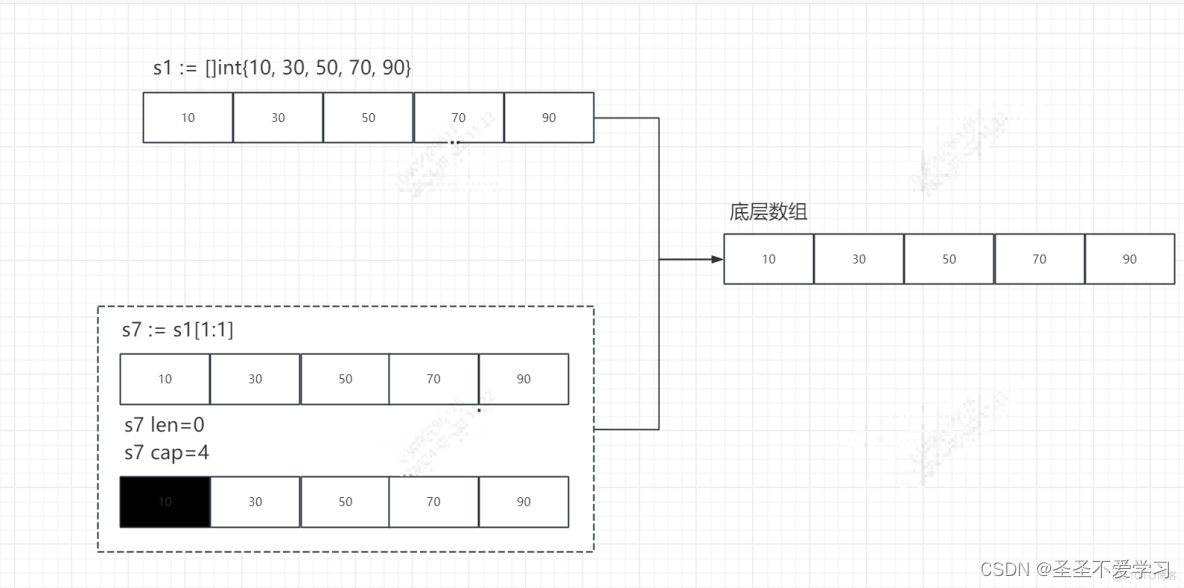
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的內存地址:%p|s1的底層數組首地址:%p|s1的長度:%d|s1的容量:%d|s1的元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)// 該子切片會復制一個新的header,偏移一個元素,子切片長度為0,容量為4s7 := s1[1:1] // 子切片元素超界了,這里是不能顯示的fmt.Printf("s7的內存地址:%p|s7的底層數組首地址:%p|s7的長度:%d|s7的容量:%d|s7的元素:%v\n", &s7, &s7[0], len(s7), cap(s7), s7)}
注意看s1[1:1],這里實際上已經超界了,長度為0,容量為4,如下圖,并且執行的時候會報錯。
然后基于現在的代碼,對s7進行append操作,看看會發生什么。
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的長度:%d|s1的容量:%d|s1的元素:%v\n", len(s1), cap(s1), s1)s7 := s1[1:1]fmt.Printf("s7的長度:%d|s7的容量:%d|s7的元素:%v\n", len(s7), cap(s7), s7)s7 = append(s7, 300, 400)fmt.Printf("s1的長度:%d|s1的容量:%d|s1的元素:%v\n", len(s1), cap(s1), s1)fmt.Printf("s7的長度:%d|s7的容量:%d|s7的元素:%v\n", len(s7), cap(s7), s7)}
===========調試結果===========
s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s7的長度:0|s7的容量:4|s7的元素:[]
s1的長度:5|s1的容量:5|s1的元素:[10 300 400 70 90]
s7的長度:2|s7的容量:4|s7的元素:[300 400]
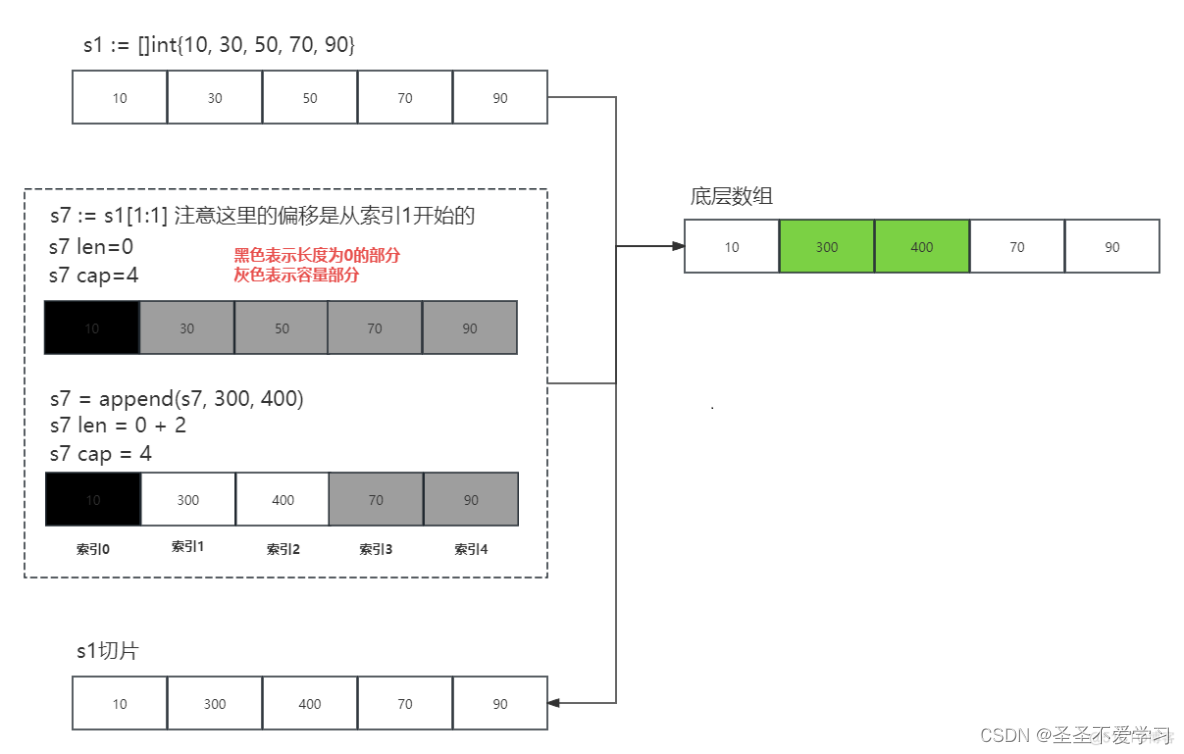
可以看到,最開始s7長度為0(啥也看不到了),容量為4,append后長度變成了2,容量不變。
并且由于s7和s1共享同一個底層數組,所以對應s1切片中索引1和2的元素也被改變了。
為什么是索引1和2?
因為最開始s7 := s1[1:1],這里start是從1開始的,對應的就是s1切片元素中的索引1。
再來看一個特殊示例
package mainimport "fmt"func main() {// 聲明并初始化一個長度和容量都為5的切片s1 := []int{10, 30, 50, 70, 90} // 索引范圍[0,4] 0到4fmt.Printf("s1的長度:%d|s1的容量:%d|s1的元素:%v\n", len(s1), cap(s1), s1)s9 := s1[5:5] //長度為0,容量為0,類似[]int{}定義方式fmt.Printf("s9的長度:%d|s9的容量:%d|s9的元素:%v\n", len(s9), cap(s9), s9)
}
===========調試結果===========
s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s9的長度:0|s9的容量:0|s9的元素:[]
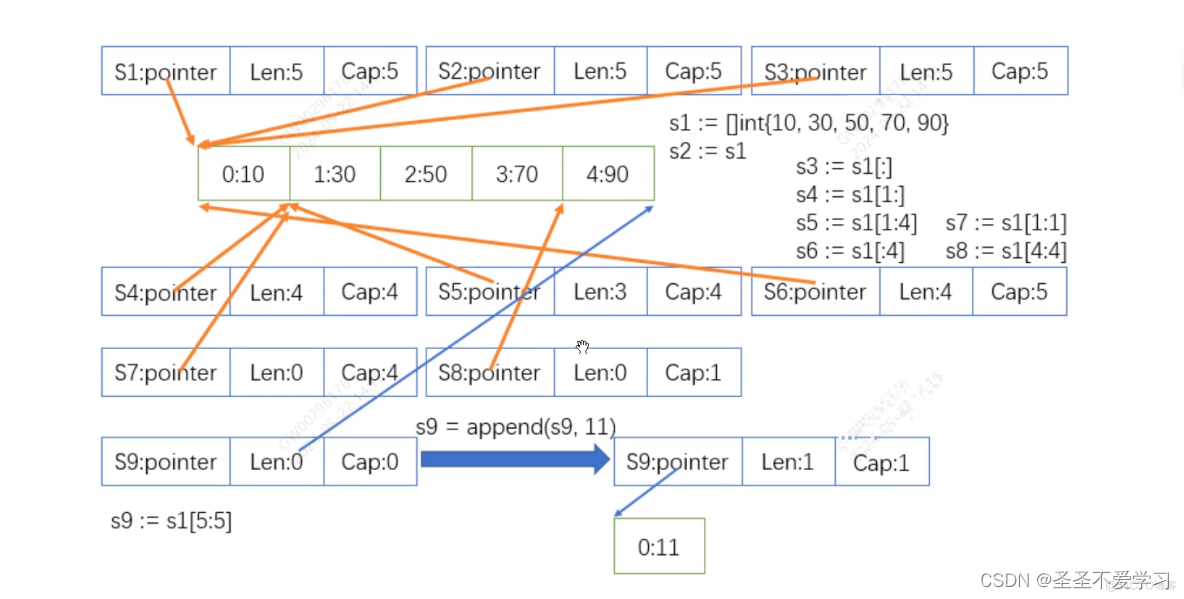
為什么還能寫成s9 := s1[5:5]?按索引來算不是超界了嗎?
注意:指定start和end時,除了能使用元素對應的索引,還能夠使用的最大值是切片的容量,s1切片的容量是5。
2.4.5 子切片總結
可以看出,上面所有示例操作都是從同一個底層數組上取的段,所以子切片和原始切片共用同一個底層數組。
- start默認為0,end默認為len(slice)即切片長度,明確定義時可以使用的最大值為切片的容量。
- 通過指針(切片內存地址)確定底層數組從哪里開始共享。
- 切片長度計算方法是end - start。
- 切片容量計算方式是底層數組從偏移的元素(start)到結尾還有幾個元素。
2.5 切片總結
- 使用slice[start:end]表示切片,切片長度為end-start,前包后不包。
- start缺省(不寫),表示從索引0開始。
- end缺省(不寫),表示直接取到末尾,包含最后一個元素,特別注意這個值是len(slice)即切片長度,不是容量,如a1[5:]相當于a1[5:len(a1)]
- start和end都缺省,表示從頭到尾。
- start和end同時給出,要求end >= start。
- start、end最大都不可以超過容量值。
- 假設當前容量是8,長度為5,有以下情況:
a1[:8],可以,end最多寫成8(因為后不包),a1[:9]不可以。
a1[8:],不可以,end缺省為5,等價于a1[8:5]。
a1[8:8],可以,但這個切片容量和長度都為0了。
a1[7:7],可以,但這個切片長度為0,容量為1。
a1[0:0],可以,但這個切片長度為0,容量為8。
a1[:8],可以,這個切片長度為8,容量為8,這8個元素都是原序列的。
a1[1:5],可以,這個切片長度為4,容量為7,相當于跳過了原序列第一個元素。- 切片剛產生時,和原序列(數組、切片)開始共用同一個底層數組,但是每一個切片都自己獨立保存著指針、cap和len。
- 一旦一個切片擴容,就和原來共用一個底層數組的序列分道揚鑣,從此陌路。
3. 對數組進行切片
數組也可以切片,但是會生成新的切片
package mainimport "fmt"func main() {// 在[]中加個5,就變成了長度和容量都為5的數組s1 := [5]int{10, 30, 50, 70, 90}fmt.Printf("s1的內存地址:%p|s1的底層數組地址:%p|s1的長度:%d|s1的容量:%d|s1的元素:%v\n", &s1, &s1[0], len(s1), cap(s1), s1)// 數組拷貝,多一個副本出來,元素完全相同s2 := s1fmt.Printf("s2的內存地址:%p|s2的底層數組地址:%p|s2的長度:%d|s2的容量:%d|s2的元素:%v\n", &s2, &s2[0], len(s2), cap(s2), s2)s3 := s1[:]//這個切片操作,會產生一個新的底層數組嗎?fmt.Printf("s3的內存地址:%p|s3的底層數組地址:%p|s3的長度:%d|s3的容量:%d|s3的元素:%v\n", &s3, &s3[0], len(s3), cap(s3), s3)
}
===========調試結果===========
s1的內存地址:0xc0000d8030|s1的底層數組地址:0xc0000d8030|s1的長度:5|s1的容量:5|s1的元素:[10 30 50 70 90]
s2的內存地址:0xc0000d80c0|s2的底層數組地址:0xc0000d80c0|s2的長度:5|s2的容量:5|s2的元素:[10 30 50 70 90]
s3的內存地址:0xc0000aa060|s3的底層數組地址:0xc0000d8030|s3的長度:5|s3的容量:5|s3的元素:[10 30 50 70 90]
可與看到,對數組進行切片后,切片的底層數組其實就是s1數組,說明對數組切片,不會誕生一個新的底層數組。


)


)








,簡介)




