目錄
十、視圖
1、簡單視圖:
2、復雜視圖:
3、視圖更新:
十一、函數
1、函數創建:
十二、數據庫優化
1、索引優化:
2、查詢優化:
3、設計優化:
十、視圖
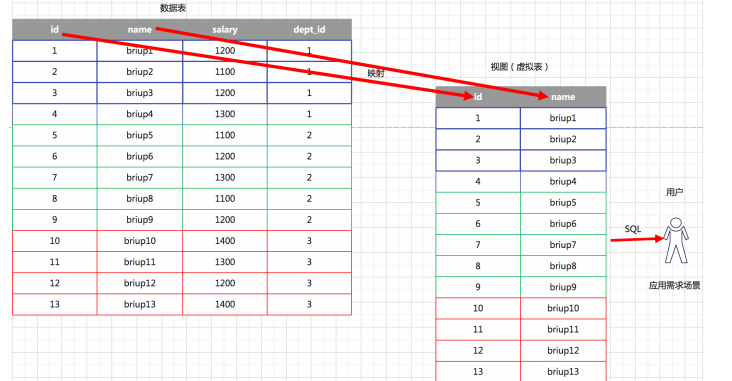
????????在 MySQL 中,視圖(View)是一種虛擬的表,它是基于一個或多個表的查詢結果構建而成的。視圖提供了一種方便和靈活的方式來處理復雜查詢、控制數據訪問和重用查詢邏輯。
????????通過使用視圖,可以提高查詢的效率和可維護性,并增強數據庫的安全性。
????????視圖一方面可以幫我們使用表的一部分而不是所有的表,另一方面也可以針對不同的用戶制定不同的查詢視圖。比如,針對一個公司的銷售人員,我們只想給他看部分數據,而某些特殊的數 據,比如采購的價格,則不會提供給他。再比如,人員薪酬是個敏感的字段,那么只給某個級別以上的人員開放,其他人的查詢視圖中則不提供這個字段。
理解視圖:
- 視圖(view)是一個虛擬表,非真實存在,其本質是根據SQL語句獲取動態的數據集,并為其命名,用戶使用時只需使用視圖名稱即可獲取結果集,并可以將其當作表來使用
- 數據庫中只存放了視圖的定義,而并沒有存放視圖中的數據(數據存放在原來的表中)
- 使用視圖查詢數據時,數據庫會從原來的表中取出對應的數據。因此,視圖中的數據是依賴于原來的表中的數據的。一旦表中的數據發生改變,顯示在視圖中的數據也會發生改變
視圖優點:
- 操作簡單
- 減少數據冗余
- 數據安全
- 適應多變的需求
- 能夠分解復雜的查詢邏輯
視圖分類: 簡單視圖 和 復雜視圖
語法:
CREATE [OR REPLACE] VIEW view_name [(字段列表)]
AS
select語句 [WITH [CASCADED |LOCAL] CHECK OPTION]
select語句 :表示一個完整的查詢語句,將查詢記錄映射到視圖中
[with [cascaded | local] check option]? :可選項,表示更新視圖時要保證在該視圖的權限范圍之內,cascaded表示級聯,local表示只考慮當前視圖。
1、簡單視圖:
????????簡單視圖是基于單個表的查詢結果構建的視圖。它們通常包含簡單的SELECT語句,可以直接從單個表中選擇列或進行簡單的列計算。簡單視圖的查詢邏輯相對較簡單,不涉及復雜的多表連接操作或子查詢。
案例1:基于bemp構建視圖,數據列只有id、name。
drop table emp;drop table dept;create table dept(id int primary key,name varchar(20));insert into dept values(1,'java'),(2,'bigdata'),(3,'web');create table emp(id int primary key,name varchar(20),salary double,dept_id int,foreign key(dept_id) references dept(id));insert into emp values(1,'lisi',3000,1),(2,'wangwu',3200,1);insert into emp(id,name,salary) values(5,'zhuqi',3500);insert into emp values(3,'zhansan',2800,1),(4,'zhaoliu',900,2);-- 新建或更新視圖create or replace view v_emp(id,username)asselect id,namefrom emp;desc emp;select * from emp;-- 查看視圖結構desc v_emp;select * from v_emp;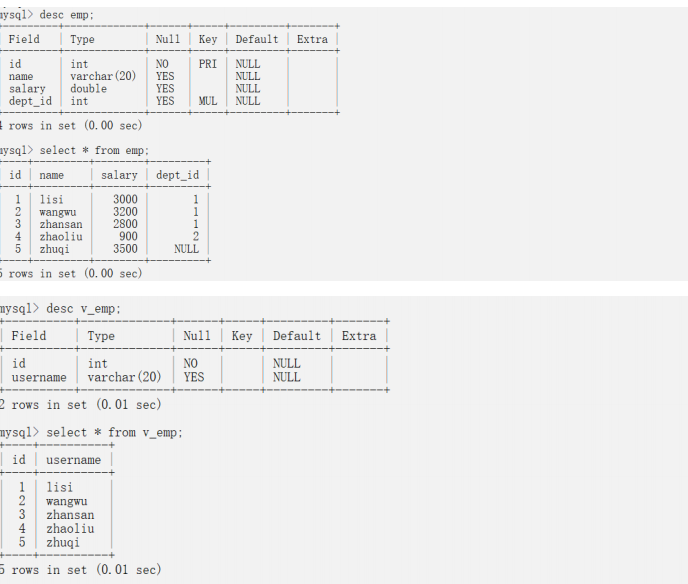
案例2:基于bemp員工表構建視圖,要求有編號、名字、薪水和年薪
create view v_emp1asselect id,name,salary,salary*30from emp;案例3:基于v_emp1構建視圖,只需要名字和薪水
create view v_emp_newasselect name,salary*30 as yearSalfrom v_emp1;select * from v_emp_new;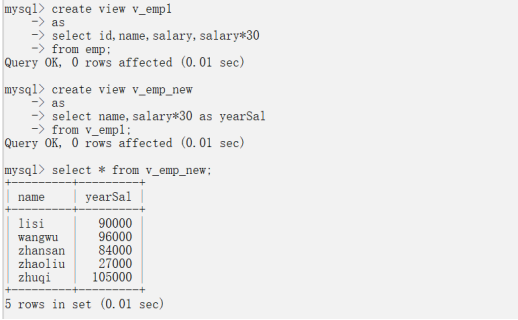
2、復雜視圖:
????????復雜視圖是基于多個表的連接操作、子查詢或其他復雜查詢邏輯構建的視圖。它們可以涉及多個表之間的關聯、聚合函數、子查詢、條件邏輯等復雜的查詢操作。
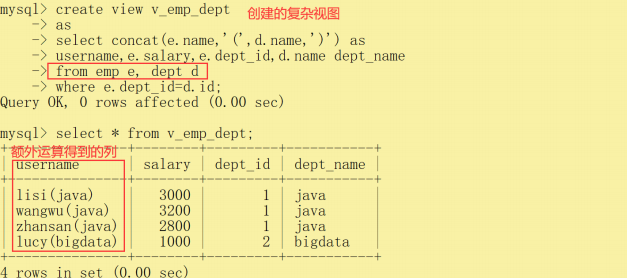
案例1:構建視圖v_emp_dept,能查詢員工信息及所屬部門
create view v_emp_deptasselect concat(e.name,'(',d.name,')') as username,e.salary,e.dept_id,d.name dept_namefrom emp e, dept dwhere e.dept_id=d.id;select * from v_emp_dept;
查看當前數據庫下的視圖語法
show tables;
重命名視圖
rename table old_view_name to new_view_name;
修改視圖
alter view view_name
as
select查詢語句
注意事項:可以使用創建視圖替換
刪除視圖
drop view if exists view_name;
3、視圖更新:
????????對于簡單視圖,即只涉及單個表的視圖,可以通過直接對底層表進行更新來間接地更新視圖。例如,如果有一個視圖 my_view ,它是從表 my_table 中選擇的某些列,可以通過更新 my_table 來更新視圖中的數據。
注意事項:對基表(數據表)進行更新改會影響視圖!
案例:基于bemp構建視圖,顯示編號和名字,并對數據修改
create view v_bempasselect id,namefrom emp;insert into v_bemp values(6,'briup');update v_bemp set name='zhaosi' where id=4;select * from v_bemp;select * from emp;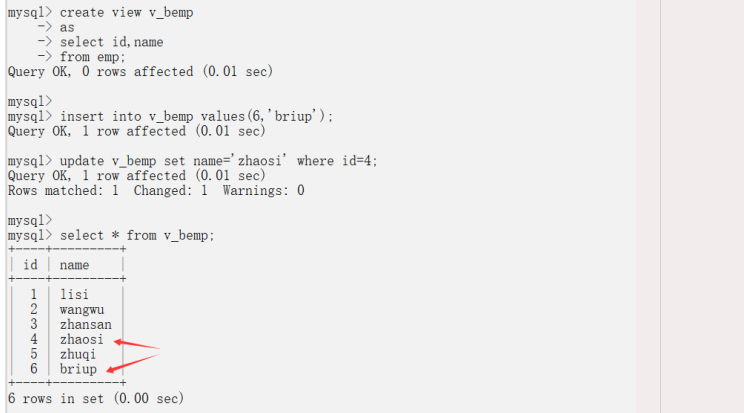
如果是復雜視圖,包含下述結構中的任何一種,那么就不能通過它去更新原來
表中數據:
- 聚合函數(SUM(), MIN(), MAX(), COUNT()等)
- select查詢列表有數學表達式
- DISTINCT
- UNION或UNION ALL
- 位于選擇列表中的子查詢
- GROUP BY
- HAVING
- JOIN
- 常量視圖
案例展示:
執行更新操作:

十一、函數
????????函數是事先經過編譯并存儲在數據庫中的一段sql語句集合,調用函數可以簡化應用開發工作,提高數據處理的效率。
1、函數創建:
mysql8 增加了一個安全選項,需要執行一下代碼才能創建函數
set global log_bin_trust_function_creators=TRUE;
基本格式:
delimiter 自定義符號
create function 函數名(形參列表) returns 返回類型 -- 注意是retruns
begin
????????函數體 -- 若干sql語句,但是不要直接寫查詢
????????return val;
????????end 自定義符號
delimiter ;
-- 格式說明:
delimiter 自定義符號 是為了在函數內寫語句方便,制定除了;之外的符號作為函數書寫結束標志,一般用$$或者//
形參列表:形參名 類型 類型為mysql支持類型
返回類型: 函數返回的數據類型,mysql支持類型即可
函數體:若干sql語句組成
return: 返回指定類型返回值
?案例1:創建無參數的函數
-- 開啟函數創建set global log_bin_trust_function_creators=TRUE;-- 創建無參數的函數delimiter $$create function func01() returns intbeginreturn (select salary from s_emp order by salary desc limit 1);end $$delimiter ;-- delimiter后面必須跟空白字符, 再跟;-- 函數調用select func01();select * from s_emp where salary=func01();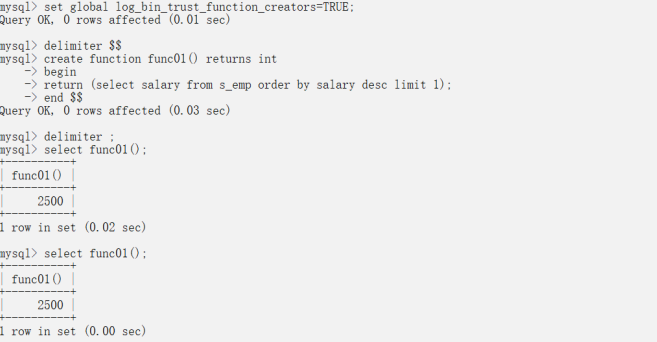
案例2:創建有參數的函數
-- 創建包含參數的函數delimiter $$create function func02(eid int)returns varchar(25)beginreturn (select last_name from s_emp where id=eid);end $$delimiter ;-- 函數調用select func02(1);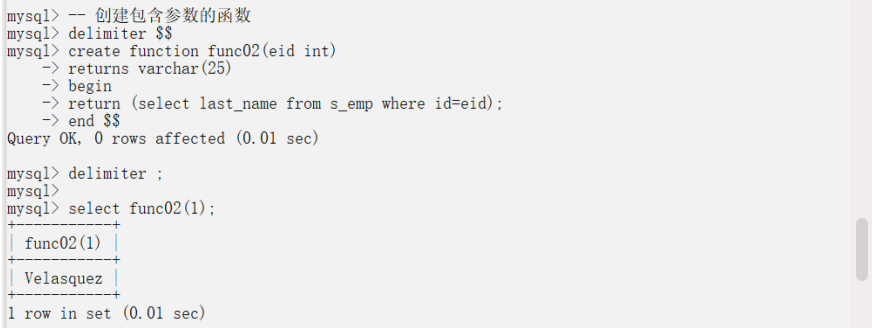
設置變量
1)定義用戶變量
固定格式:
-- 定義格式
set @[變量名] = 值;
-- 使用格式
@[變量名]
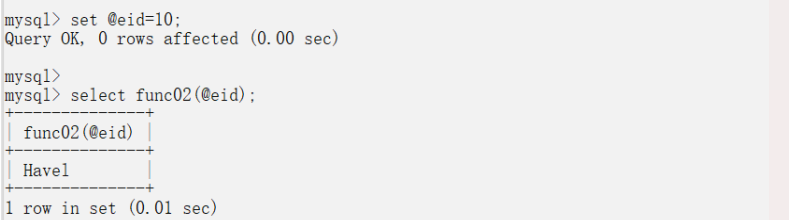
具體案例:
set @eid=10;
select func02(@eid);
2)定義局部變量
????????可以在函數內部定義局部變量。局部變量只在函數內部可見,其作用域僅限于函數內部。
????????局部變量可以使用set賦值。
DECLARE variable_name datatype [DEFAULT initial_value];
-- variable_name 是變量的名稱
-- datatype 是變量的數據類型
-- initial_value 是可選的初始值
具體案例:定義函數獲取商品總價,傳遞數量和單價。
DELIMITER //CREATE FUNCTION get_total_price(num INT, price DECIMAL(10, 2))RETURNS DECIMAL(10, 2)BEGINDECLARE total DECIMAL(10, 2);SET total = num * price;RETURN total;END //DELIMITER ;select get_total_price(5,2.5);-- 刪除函數drop function get_total_price;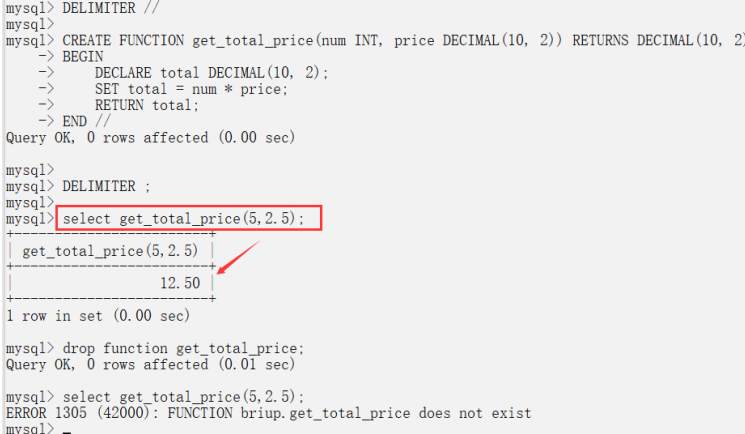
十二、數據庫優化
????????數據庫優化是針對關系型數據庫系統的性能和效率進行改進的過程。通過優化數據庫,可以提高查詢速度、減少資源占用,提升系統的響應性和可擴展性。
以下是一些常見的數據庫優化技術和策略:
1、索引優化:
(1)在合適的字段上創建索引
????????如果不加索引的話,那么查找任何哪怕只是一條特定的數據都會進行一次全表掃描,如果一張表的數據量很大而符合條件的結果又很少,那么不加索引會引起致命的性能下降。但是也不是什么情況都非得建索引不可,比如性別可能就只有兩個值,建索引不僅沒什么優勢,還會影響到更新速度,這被稱為過度索引。
????????所以要建在合適的地方,合適的對象上。經常 操作 、 比較 、 判斷 的字段應該建索引。索引根據實際需要來設置,不是越多越好,索引本身也是占用內存空間的。
(2)復合索引代替單索引
????????比如有一條語句是這樣的: select * from users where area=’beijing’ and age=22; 如果我們是在area和age上分別創建單個索引的話,由于mysql查詢每次只能使用一個索引,所以雖然這樣已經相對不做索引時全表掃描提高了很多效率,但是如果在area、age兩列上創建復合索引的話將帶來更高的效率。如果我們創建了(area, age,salary)的復合索引,那么其實相當于創建了(area,age,salary)、(area,age)、(area)三個索引,這被稱為最佳左前綴特性。
????????因此我們在創建復合索引時應該將最常用作限制條件的列放在最左邊,依次遞減。
(3)使用短索引
????????對串列進行索引,如果可能應該指定一個前綴長度。例如,如果有一個CHAR(255)的列,如果在前10 個或20個字符內,多數值是唯一的,那么就不要對整個列進行索引。短索引不僅可以提高查詢速度而且可以節省磁盤空間和I/O操作。
2、查詢優化:
(1)盡量不使用NULL
????????通常,索引字段是不存在 NULL 的,所以指定 IS NULL 和 IS NOT NULL 的話會使得索引無法使用,進而導致查詢性能低下。
(2)減少子查詢
????????執行子查詢時,會創建臨時表,查詢完畢后再刪除它,所以子查詢的速度會收到影響。
(3)減少模糊查詢
????????一般情況下不鼓勵使用like操作,如果非使用不可,如何使用也是一個問題。like "%aaa%" 不會使用索引而 like "aaa%" 可以使用索引。
(4)使用 EXISTS 代替 IN
????????在大多時候,[NOT] IN 和 [NOT] EXISTS 返回的結果是相同的。但是兩者用于子查詢時,EXISTS 的速度會更快一些。
-- exists使用案例-- 參考博文https://blog.csdn.net/zhangzehai2234/article/details/124652056-- exists:外表先進行循環查詢,將查詢結果放入exists的子查詢中進行條件驗證,確定外層查詢數據是否保留-- 查詢存在員工的部門的信息select id,namefrom s_dept as sdwhere exists (select id,last_name,dept_idfrom s_empwhere dept_id = sd.id);-- 查詢已分配好部門員工的信息select id,last_name,dept_idfrom s_emp as sewhere exists(select id,namefrom s_deptwhere id = se.dept_id);(5)避免排序
????????我們在查詢的時候,雖然我們沒有想要進行排序,但是在數據庫內部頻繁地進行著暗中的排序。因此對于我們來說,了解都有哪些運算會進行排序很有必要,會進行排序的代表性的運算有下面這些
- group by 子句
- order by 子句
- 聚合函數(sum、count、avg、max、min)
????????在極值函數(MAX/MIN)中使用索引,使用這兩個函數時都會進行排序。但是如果參數字段上建有索引,則只需要掃描索引,不需要掃描整張表。
????????能寫在 WHERE 子句里的條件不要寫在 HAVING 子句里。
- distinct
????????為了排除重復數據,distinct 也會進行排序。如果需要對兩張表的連接結果進行去重,可以考慮使用exists代替distinct,以避免排序。
- 集合運算符(union、intersect、except)
- 窗口函數(rank、row_number等)
(6)limit 分頁機制
????????300W數據,select * from tableA limit 1000000,10; 會導致mysql將1000000之前的所有數據全部掃描一次,大量浪費了時間。解決辦法:
- 查詢字段加索引,可以建立與主鍵的復合索引
- limit最大的問題在于要掃描前面不必要的數據,所以可以先對主鍵的條件做設定,然后記錄住主鍵的位置再取行。 select * from tableA where id > 1000000 order by id limit 10;
(7)增加中間表
????????對于需要經常聯合查詢的表,可以建立中間表以提高查詢效率。通過建立中間表,把需要經常聯合查詢的數據插入到中間表中,然后將原來的聯合查詢改為對中間表的查詢,以此來提高查詢效率。
3、設計優化:
(1)默認值設置不為空
????????只要列中包含有NULL值都將不會被包含在索引中,復合索引中只要有一列含有NULL值,那么這一列對于此復合索引就是無效的。所以我們在數據庫設計時不要讓字段的默認值為NULL。
(2)選取最適用的字段屬性
????????MySQL可以很好的支持大數據量的存取,但是一般說來,數據庫中的表越小,在它上面執行的查詢也就會越快。因此,在創建表的時候,為了獲得更好的性能,我們可以將表中字段的寬度設得盡可能小。
????????例如,在定義郵政編碼這個字段時,如果將其設置為CHAR(255),顯然給數據庫增加了不必要的空間,甚至使用VARCHAR這種類型也是多余的,因為CHAR(6)就可以很好的完成任務了。同樣的,如果可以的話,我們應該使用MEDIUMINT而不是BIGIN來定義整型字段。
(3)讀寫分離
????????海量數據的存儲及訪問,通過對數據庫進行讀寫分離,來提升數據的處理能力,數據庫的寫操作都集中到一個數據庫上,而一些讀的操作呢,可以分解到其它數據庫上。
優點:得數據庫的處理壓力分解到多個數據庫上,從而大大提升數據處理能力
缺點:付出數據復制的成本。
(4)數據庫范式化和規范化
????????通過合理的范式設計,減少數據冗余和不一致性;使用適當的關系模型和數據結構,以提高查詢和更新的效率。
(5)分表
????????分表技術比較麻煩,要修改程序代碼里的SQL語句,還要手動去創建其他表,也可以用merge存儲引擎實現分表,相對簡單許多。分表后,程序是對一個總表進行操作,這個總表不存放數據,只有一些分表的關系,以及更新數據的方式,總表會根據不同的查詢,將壓力分到不同的小表上,因此提高并發能力和磁盤I/O性能。
????????分表分為垂直拆分和水平拆分:
????????垂直拆分:把原來的一個很多字段的表拆分多個表,解決表的寬度問題。 你可以把不常用的字段單獨放到一個表中,也可以把大字段獨立放一個表中,或者把關聯密切的字段放一個表中。
????????水平拆分:把原來一個表拆分成多個表,每個表的結構都一樣,解決單表數據量大的問題。
數據庫優化是一個持續的過程,需要結合具體的應用場景和需求進行調整和改進。通過綜合考慮索引、查詢、范式化、緩存、分區、硬件配置等方面的優化策略,可以提升數據庫系統的性能和效率。

:Kubernetes架構-原理-組件)

類型和Option類型)




)









:讓大模型能夠回答私域知識問題)
