文章目錄
- 關于 NebulaGraph
- 客戶端支持
- 安裝 NebulaGraph
- 關于 nGQL
- nGQL 可以做什么
- 2500 條 nGQL 示例
- 原生 nGQL 和 openCypher 的關系
- Backup&Restore
- 功能
- 導入導出
- 導入工具
- 導出工具
- NebulaGraph Importer
- NebulaGraph Exchange
- NebulaGraph Spark Connector
- NebulaGraph Flink Connectors
- NebulaGraph Studio
- NebulaGraph Dashboard
- 產品功能
- NebulaGraph Operator
- 工作原理
- 功能介紹
- NebulaGraph Algorithm 圖計算
- NebulaGraph Bench
關于 NebulaGraph
-
官網:https://www.nebula-graph.com.cn
-
官方文檔:https://docs.nebula-graph.com.cn/3.8.0/
手冊PDF : https://docs.nebula-graph.com.cn/3.8.0/pdf/NebulaGraph-CN.pdf
客戶端支持
NebulaGraph 提供多種類型客戶端,便于用戶連接、管理 NebulaGraph 圖數據庫。
- NebulaGraph Console:原生 CLI 客戶端
- NebulaGraph CPP:C++ 客戶端
- NebulaGraph Java:Java 客戶端
- NebulaGraph Python:Python 客戶端
- NebulaGraph Go:Go 客戶端
安裝 NebulaGraph
有以下安裝方式:
- 基于 Docker
- 從云開始(免費試用)
- 本地部署步驟 1:安裝 NebulaGraph
releases : https://github.com/vesoft-inc/nebula-console/releases
關于 nGQL
nGQL是 NebulaGraph 使用的的聲明式圖查詢語言,支持靈活高效的圖模式,而且 nGQL 是為開發和運維人員設計的類 SQL 查詢語言,易于學習。
nGQL 是一個進行中的項目,會持續發布新特性和優化,因此可能會出現語法和實際操作不一致的問題,如果遇到此類問題,請提交 issue 通知 NebulaGraph 團隊。 NebulaGraph 3.0 及更新版本正在支持 openCypher 9。
nGQL 可以做什么
- 支持圖遍歷
- 支持模式匹配
- 支持聚合
- 支持修改圖
- 支持訪問控制
- 支持聚合查詢
- 支持索引
- 支持大部分 openCypher 9 圖查詢語法(不支持修改和控制語法)
2500 條 nGQL 示例
https://github.com/vesoft-inc/nebula/tree/master/tests/tck/features
features 目錄內包含很多.features格式的文件,每個文件都記錄了使用 nGQL 的場景和示例。例如:
原生 nGQL 和 openCypher 的關系
原生 nGQL 是由 NebulaGraph 自行創造和實現的圖查詢語言。openCypher 是由 openCypher Implementers Group 組織所開源和維護的圖查詢語言,最新版本為 openCypher 9。
由于 nGQL 語言部分兼容了 openCypher,這個部分在本文中稱為 openCypher 兼容語句。
Backup&Restore
Backup&Restore(簡稱 BR)是一款命令行界面(CLI)工具,可以幫助備份 NebulaGraph 的圖空間數據,或者通過備份文件恢復數據。
功能
- 一鍵操作備份和恢復數據。
- 支持基于以下備份文件恢復數據:
- 本地磁盤(SSD 或 HDD),建議僅在測試環境使用。
- 兼容亞馬遜對象存儲(Amazon S3)云存儲服務接口,例如:阿里云對象存儲(Alibaba Cloud OSS)、MinIO、Ceph RGW 等。
- 支持備份并恢復整個 NebulaGraph 集群。
- (實驗性功能)支持備份指定圖空間數據。
導入導出
導入工具
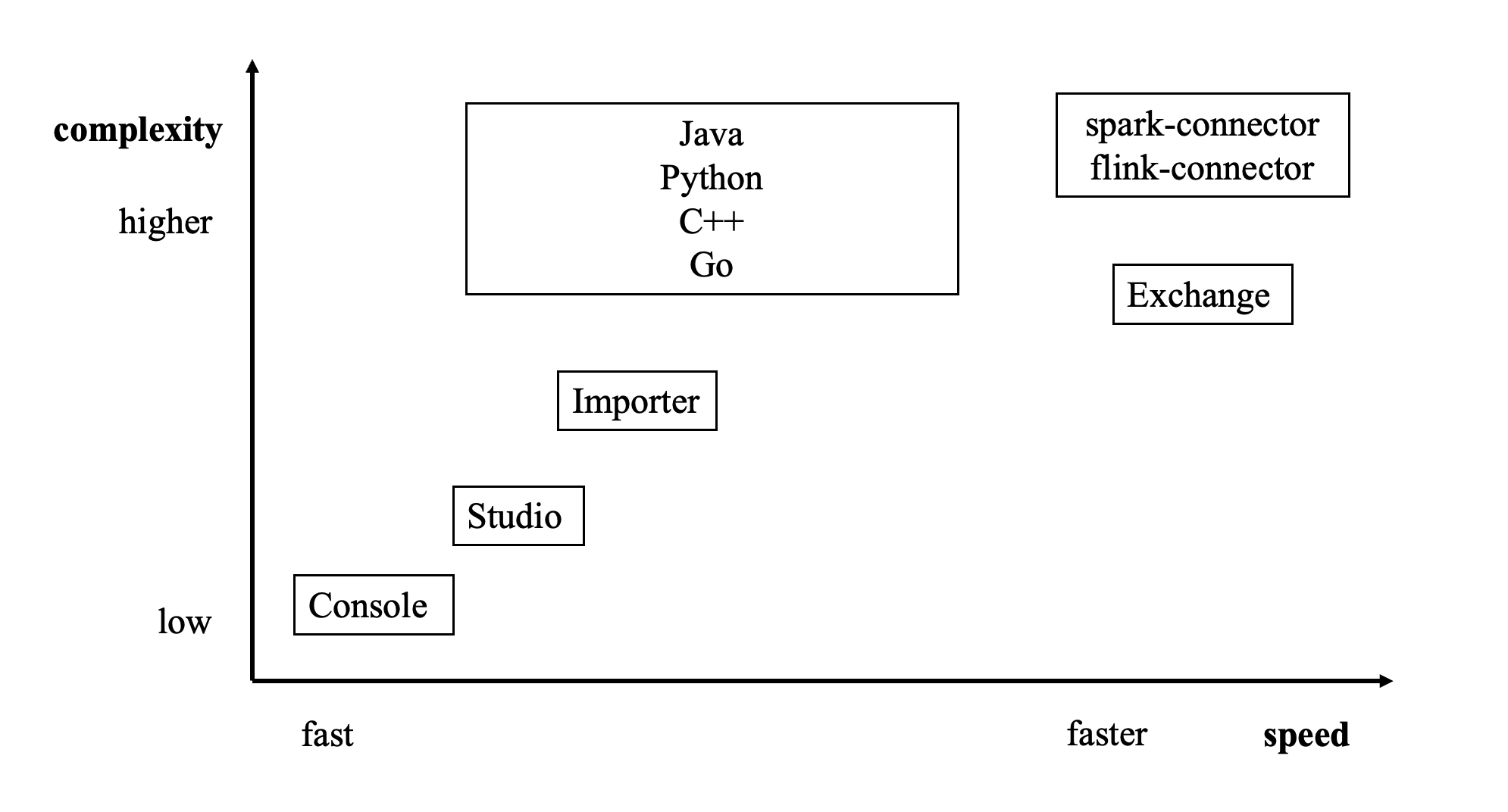
有多種方式可以將數據寫入NebulaGraph 3.8.0:
- 使用命令行 -f 的方式導入:可以導入少量準備好的 nGQL 文件,適合少量手工測試數據準備。
- 使用 Studio 導入:可以用過瀏覽器導入本機多個 CSV 文件,格式有限制。
- 使用 Importer 導入:導入單機多個 CSV 文件,大小沒有限制,格式靈活。適合十億條數據以內的場景。
- 使用 Exchange 導入:從 Neo4j、Hive、MySQL 等多種源分布式導入,需要有 Spark 集群。適合十億條數據以上的場景。
- 使用 Spark-connector/Flink-connector 讀寫 API:這種方式需要編寫少量代碼來使用 Spark/Flink 連接器提供的 API。
- 使用 C++/GO/Java/Python SDK:編寫程序的方式導入,需要有一定編程和調優能力。
下圖給出了幾種方式的定位:
導出工具
- 使用 Spark-connector/Flink-connector 讀寫 API:這種方式需要編寫少量代碼來使用 Spark/Flink 連接器提供的 API。
- 使用 Exchange 導出功能將數據導出至 CSV 文件或另一個圖空間(支持不同 NebulaGraph 集群)中。
NebulaGraph Importer
NebulaGraph Importer(簡稱 Importer)是一款 NebulaGraph 的 CSV 文件單機導入工具,可以讀取并批量導入多種數據源的 CSV 文件數據,還支持批量更新和刪除操作。
功能
- 支持多種數據源,包括本地、S3、OSS、HDFS、FTP、SFTP、GCS。
- 支持導入 CSV 格式文件的數據。單個文件內可以包含多種 Tag、多種 Edge type 或者二者混合的數據。
- 支持過濾數據源數據。
- 支持批量操作,包括導入、更新、刪除。
- 支持同時連接多個 Graph 服務進行導入并且動態負載均衡。
- 支持失敗后重連、重試。
- 支持多維度顯示統計信息,包括導入時間、導入百分比等。統計信息支持打印在 Console 或日志中。
- 支持 SSL 加密。
NebulaGraph Exchange
NebulaGraph Exchange(簡稱 Exchange)是一款 Apache Spark? 應用,用于在分布式環境中將集群中的數據批量遷移到 NebulaGraph 中,能支持多種不同格式的批式數據和流式數據的遷移。
Exchange 由 Reader、Processor 和 Writer 三部分組成。Reader 讀取不同來源的數據返回 DataFrame 后,Processor 遍歷 DataFrame 的每一行,根據配置文件中fields的映射關系,按列名獲取對應的值。在遍歷指定批處理的行數后,Writer 會將獲取的數據一次性寫入到 NebulaGraph 中。下圖描述了 Exchange 完成數據轉換和遷移的過程。
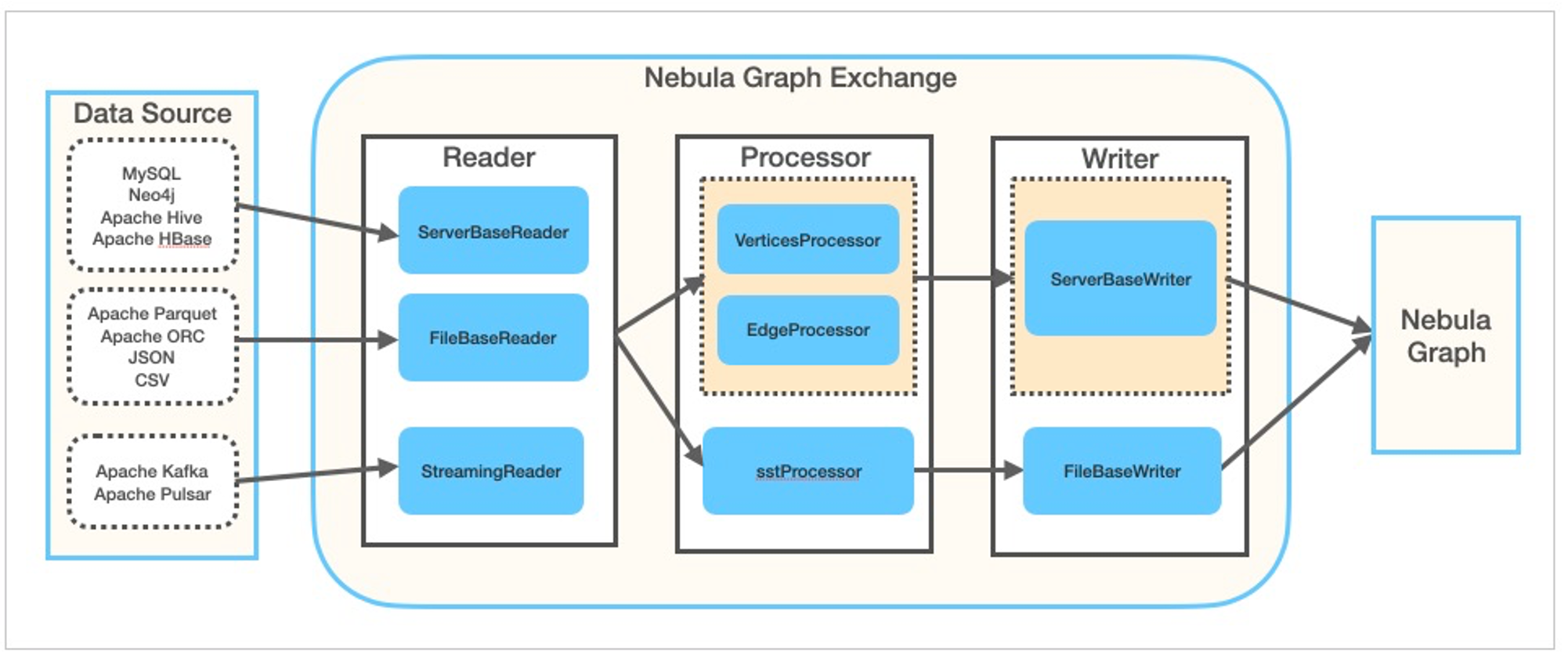
Exchange 有社區版和企業版兩個系列,二者功能不同。社區版在 GitHub 開源開發,企業版屬于 NebulaGraph 企業套餐。
NebulaGraph Spark Connector
詳情:https://github.com/vesoft-inc/nebula-spark-connector/blob/release-3.8/README_CN.md
NebulaGraph Spark Connector 是一個 Spark 連接器,提供通過 Spark 標準形式讀寫 NebulaGraph 數據的能力。NebulaGraph Spark Connector 由 Reader 和 Writer 兩部分組成。
- Reader
提供一個 Spark SQL 接口,用戶可以使用該接口編程讀取 NebulaGraph 圖數據,單次讀取一個點或 Edge type 的數據,并將讀取的結果組裝成 Spark 的 DataFrame。 - Writer
提供一個 Spark SQL 接口,用戶可以使用該接口編程將 DataFrame 格式的數據逐條或批量寫入 NebulaGraph 。
NebulaGraph Flink Connectors
NebulaGraph Flink Connector 是一款幫助 Flink 用戶快速訪問NebulaGraph的連接器,支持從NebulaGraph圖數據庫中讀取數據,或者將其他外部數據源讀取的數據寫入NebulaGraph圖數據庫。
NebulaGraph Studio
NebulaGraph Studio(簡稱 Studio)是一款可以通過 Web 訪問的開源圖數據庫可視化工具,搭配 NebulaGraph 內核使用,提供構圖、數據導入、編寫 nGQL 查詢等一站式服務。
用戶可以在 NebulaGraph GitHub 倉庫中查看最新源碼,詳情參見 nebula-studio https://github.com/vesoft-inc/nebula-studio。
Studio 可以方便管理 NebulaGraph 數據,具備以下功能:
- 使用 Schema 管理功能,用戶可以使用圖形界面完成圖空間、Tag(標簽)、Edge Type(邊類型)、索引的創建,查看圖空間的統計數據,快速上手 NebulaGraph 。
- 使用導入功能,通過簡單的配置,用戶即能批量導入點和邊數據,并能實時查看數據導入日志。
- 使用控制臺功能,用戶可以使用 nGQL 語句創建 Schema,并對數據執行增刪改查操作。
NebulaGraph Dashboard
NebulaGraph Dashboard(簡稱 Dashboard)是一款用于監控 NebulaGraph 集群中機器和服務狀態的可視化工具。
產品功能
- 監控集群中所有機器的狀態,包括 CPU、內存、負載、磁盤和流量。
- 監控集群中所有服務的信息,包括服務 IP 地址、版本和監控指標(例如查詢數量、查詢延遲、心跳延遲等)。
- 監控集群本身的信息,包括集群的服務信息、分區信息、配置和長時任務。
- 支持全局調整監控數據的頁面更新頻率。
NebulaGraph Operator
NebulaGraph Operator 是用于在 Kubernetes 系統上自動化部署和運維 NebulaGraph 集群的工具。
依托于 Kubernetes 擴展機制,NebulaGraph 將其運維領域的知識全面注入至 Kubernetes 系統中,讓 NebulaGraph 成為真正的云原生圖數據庫。
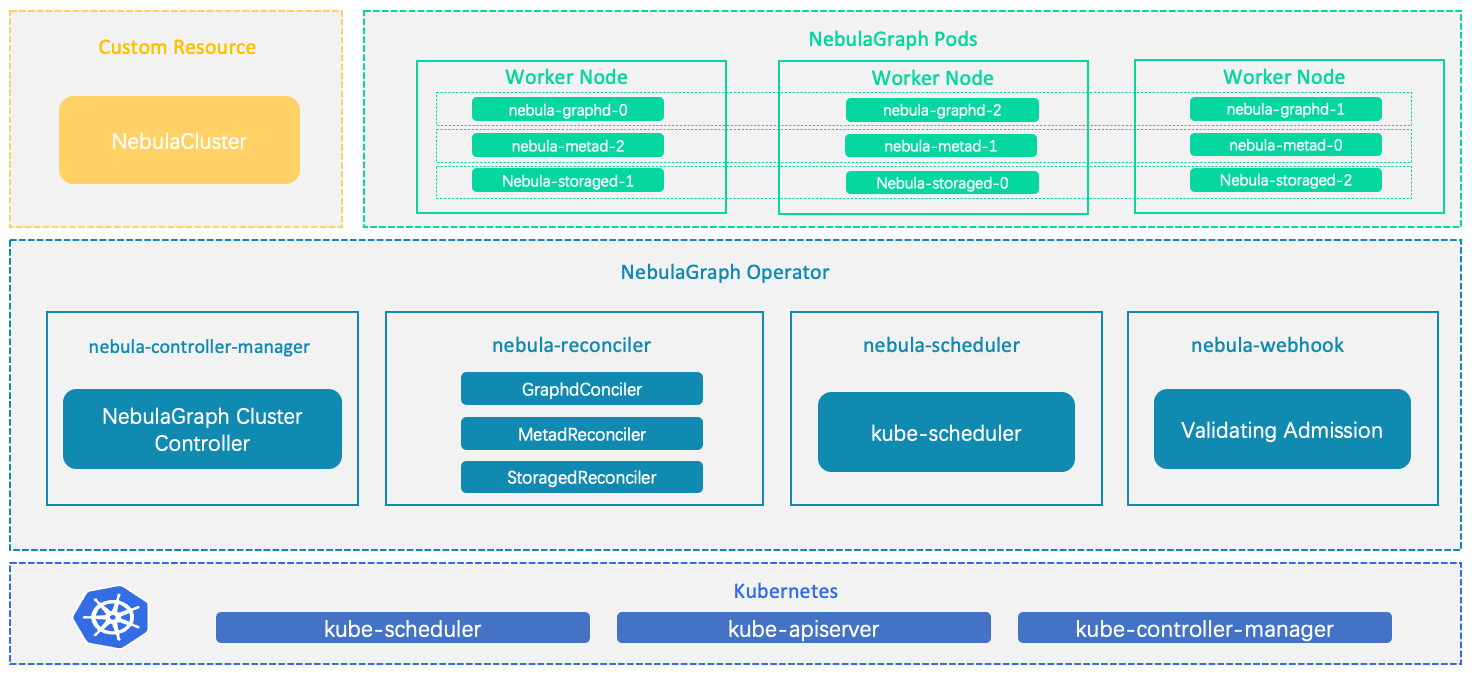
工作原理
對于 Kubernetes 系統內不存在的資源類型,用戶可以通過添加自定義 API 對象的方式注冊,常見的方法是使用 CustomResourceDefinition(CRD)。
NebulaGraph Operator 將 NebulaGraph 集群的部署管理抽象為 CRD。通過結合多個內置的 API 對象,包括 StatefulSet、Service 和 ConfigMap,NebulaGraph 集群的日常管理和維護被編碼為一個控制循環。在 Kubernetes 系統內,每一種內置資源對象,都運行著一個特定的控制循環,將它的實際狀態通過事先規定好的編排動作,逐步調整為最終的期望狀態。當一個 CR 實例被提交時,NebulaGraph Operator 會根據控制流程驅動數據庫集群進入最終狀態。
功能介紹
NebulaGraph Operator 已具備的功能如下:
- 集群創建和卸載:NebulaGraph Operator 簡化了用戶部署和卸載集群的過程。用戶只需提供對應的 CR 文件,NebulaGraph Operator 即可快速創建或者刪除一個對應的 NebulaGraph 集群。更多信息參見創建 NebulaGraph 集群。
- 集群升級:支持升級 3.5.0 版的 NebulaGraph 集群至 3.6.0 版。
- 故障自愈:NebulaGraph Operator 調用 NebulaGraph 集群提供的接口,動態地感知服務狀態。一旦發現異常,NebulaGraph Operator 自動進行容錯處理。更多信息參考故障自愈。
- 均衡調度:基于調度器擴展接口,NebulaGraph Operator 提供的調度器可以將應用 Pods 均勻地分布在 NebulaGraph 集群中。
NebulaGraph Algorithm 圖計算
NebulaGraph Algorithm (簡稱 Algorithm)是一款基于 GraphX 的 Spark 應用程序,通過提交 Spark 任務的形式使用完整的算法工具對 NebulaGraph 數據庫中的數據執行圖計算,也可以通過編程形式調用 lib 庫下的算法針對 DataFrame 執行圖計算。
NebulaGraph Bench
NebulaGraph Bench 是一款利用 LDBC 數據集對 NebulaGraph 進行性能測試的工具。
2024-05-21(二)






)
)




)






