公司內部做的一次技術分享
文章目錄
- 12306的成就
- 12306系統特點
- 12306系統難點
- 解決思路
- 產品角度
- 技術角度
- 余票庫存的表如何設計?
- 搶票軟件推薦
- 巨人的肩膀
對于未公開的技術部分,只能結合已公開的信息,去做大膽的猜想。
本文提到的一些解決方案,并不一定是標準的實現,一些觀點旨在引發大家的思考。
12306的成就
- 創下全球最大實時票務交易系統世界記錄,春運一個月抵歐洲一年。
- 最高可達百萬并發,承受了這個世界上能秒殺任何系統的QPS。
- 網站瀏覽量一天最高超1500億次,峰值是雙11的三倍。
12306系統特點
- 跟淘寶天貓等相比,業務簡單(賣票)。
- 流量極大。
- 動態庫存。
12306系統難點
目前 12306 最大的難點,在于庫存扣減。
它跟傳統的電商網站,可能最大的不同在于它的庫存, 它的庫存是動態變化的,庫存之間會互相影響。
比如現在有一個組合品的需求,A品是由B品和C品通過不同的比例混合而成,用戶下單的時候傳過來的是A品這個 SKU,但是庫存扣減的時候是把它的組合品的單品(B和C),都去扣一遍的。
我們平時各種商品 sku 庫存的話,它是表里面的一行行記錄。

某個行程是:杭州 -> 武漢 -> 成都。
杭州 -> 成都 ,武漢 -> 成都。這兩個是一個車次。那么每賣出一張 武漢 -> 成都 的票,杭州 -> 成都 的票也會少一張。

舉個極端的例子,火車上就一個座位,車次是從 A -> B -> C。
如果賣出 B -> C 的車票,不去扣減 A-> C 庫存的話,那么假設有兩個用戶分別買了 A-> C 和 B -> C 。那么當車行至站點B的時候,車上會有兩個人,但是座位就一個。
所以不同車次之間的庫存是會互相影響的。
A -> B -> C -> D 共 4 個車站,假如乘客買了 B -> C 的車票,那么同時會影響到 A->C,A->D,B->C,B->D。
這里不會影響 A -> B 的行程,因為乘客買的是 B -> C 的車票,站點 B 才上車,不占用 A -> B 行程的座位,我下車你上車,不沖突。
計算耗費性能
一些長途,中間會經過十幾個站點,而且有些城市是沒有直達的車次的,中間只能換乘。涉及了多個車站的排列組合,這里計算是比較耗費性能的。
行鎖競爭會非常激烈

購買一個行程會涉及多個站點的扣減庫存,有可能這些多個站點的庫存扣減是放在一個事務中的,如果是在一個事務中,那么一次下單行為,可能要涉及到幾十次庫存扣減。
鎖范圍膨脹,事務就會被拉大,線程數可能迅速被占滿,導致數據庫可能成為性能瓶頸,并且接口性能也會有所下降。

熱點問題
火車站不同的站之間都是一個具體庫存,中間的庫存扣了之后,那么遠的這個站的庫存也要扣減。
極端情況下,一些熱門城市,中間一些站點可能比較火爆,那兩端的人是不是永遠買不到票。
所以說像 12306 這種庫存,其實涉及到非常多的一個行鎖競爭,而且事務是非常大的。一列火車之間的庫存其實是互相影響的,動態變化的。
另外還會涉及到其他維度,比如 硬座、硬臥、軟臥、無座 這種業務邏輯在里面。
業務邏輯加上庫存之間相互影響,就導致庫存扣減邏輯異常復雜。
解決思路
產品角度
- 早期的 12306 是通過整點去搶票,整點就會產生非常高的流量峰值,對系統造成非常大的壓力,后面采取了分時段售票,比如今天開搶 15 天之后的車票,將搶票的壓力按照時間區間分散開,大大減低了峰值。
- 候補車票。
在2019年5月份,12306 新增了“候補購票”功能,在“候補購票”功能沒出來之前,放票時間一到,千萬人同時刷新搶票,這便是春運火車票秒光的原因。
候補車票堪稱搶了一票第三方軟件的“飯碗”。
“黃牛”的秘密武器是外掛,用最快的服務器不斷地刷新和監控12306,刷票速度往往是正常購票的幾十倍。
實際上,市面上通行的“搶票軟件”,原理與“黃牛”并無本質區別。
以前,合肥到上海的車票賣光了,有人退票或改簽,車票會回到票池可供購買。搶票軟件實時刷新監控,第一時間購買,這便是搶票軟件比人快的原因。
現在,有了候補車票,合肥到上海的車票賣光了,乘客可以候補登記,有人退票或改簽,車票按順序優先賣給候補登記的人,而不是回到票池公開出售。這便是搶票軟件無效的原因。
現在很多搶票軟件反而沒有“候補購票”功能搶票來得快。
候補車票在整個系統上相當于是一個異步過程。先排隊,后面搶沒搶到票再通知你。只要異步了,就可以通過消息,或者定時任務慢慢去消費,大大降低系統的壓力。

12306 是有非常多的灰色流量的,像是一些搶票軟件或者腳本。因為這里面涉及到的利益非常巨大,滋生了很多灰色流量,給12306本身帶來了很多額外的壓力。
“候補購票”功能可以降低黃牛刷票行為,攔截部分灰色流量。
- 驗證碼機制。BT的驗證碼機制,可以過濾非常大的灰色流量。
12306 的驗證碼,是所有驗證碼中的一股絕對的“清流”。

2013 年起,鐵道部為了應對黃牛搶票,以及各類搶票軟件和插件,升級了購票驗證碼系統。
在12306官方網站上,從購票到付款,都需要輸入驗證碼。從最開始的字母數字驗證碼,再到后來升級后的圖形驗證碼,成為了一道“難過”的關卡。


各類奇葩驗證碼出現在了 12306 上。
到了2015年底,根據有關網站統計,12306上的圖形驗證碼多達接近600種。再經過排列組合,總共有多達300000種。一次性輸入準確的比例僅僅是8%,兩次輸入準確比例27%,三次以上輸入準確的比例才勉強超過60%,如果一次性輸入成功的平均用時為5秒的話,按照熱門車票“秒光”的情況計算,每輸錯一次驗證碼,就意味著當次購票成功率下降80%左右。
直到 2018 年,各類奇葩驗證碼才陸續開始“下崗”。
上面的候補搶票和驗證碼機制,主要是為了對抗黃牛。
道高一尺,魔高一丈。黃牛也在不斷進步。
推薦閱讀: 為什么車票剛出就沒了?揭秘AI神器搶票內幕 進化的12306與殺不死的“黃牛”

比如我是一個搞黑灰產的人,我可以雇傭一批大學生,去做圖形驗證碼識別。簡單驗證碼還是機器去執行。
那這樣的話其實還是沒辦法防止,但是這樣增加了灰產的成本,畢竟人工比機器成本高,從一定程度上還是能夠降低灰產的流量占比。
12306 之所以能夠使用如此變態的驗證碼機制的大前提是:沒有把用戶體驗放在首位。
12306 比較特殊,市面上幾乎不存在競爭對手,而且火車票對于逢年過節,旅行返鄉的人來說,幾乎可以等同于必需品。
在這種情況下,12306 不必將用戶體驗放在首位,對于 12306 來說是可以犧牲部分用戶體驗來換取系統穩定性。
- 12306 是讀多寫少的情況,查詢流量占大頭。
天量的火車票查詢是影響 12306 性能的重要原因之一,大概占了90%以上的訪問流量。更棘手的是:峰谷的查詢有天壤之別,平時工作日跟這種節假日,春運。流量相差是巨大的,時間區間是非常明顯的。
如果說完全用機器去堆,可能就會造成一個資源浪費。
還有至關重要一點是,假如完全用機器去堆,在實際業務峰值超出了初始評估量時,服務將面臨無法完全承載而癱瘓,因為大規模服務器的采購、交付、部署到應用上線所耗費時間以月計,根本無法在業務量激增時"即插即用"。
幾乎沒有辦法在成本和并發能力之間做一個好的平衡。以往的一個做法是從幾個關鍵入口流量控制,保障系統可用性,但是會影響用戶體驗。
淘寶/天貓大促的時候,也會增加服務器,但阿里的業務盤子大,這些新增的機器很快會被其他業務(包括阿里云)消化掉,可能還不夠。但是對于 12306來說,就比較難做到這一點。
在 2015 年的時候,12306 跟阿里云達成合作,通過云的彈性和“按量付費”的計量方式,來支持巨量的查詢業務,把架構中比較“重”(高消耗、低周轉)的部分放在云上,將75%的余票查詢業務切換到了阿里云上。
將余票查詢模塊和12306現有系統做分離,在云上獨立部署一套余票查詢系統。
通過動態的云計算,在高峰時段動態去擴容,可以達到分鐘級的擴容,這樣就避免在平時浪費大量的機器。
合作后,提高了網站的負載能力。2019年的春運,12306挺過了流量的高峰 297 億次的日訪問量。
推薦閱讀: 秘密合作半年 阿里同12306關系被曝光
技術角度
歷史背景:12306 是在 2010 年左右上線的,11年到12年之間,基本上一到節假日系統就崩潰。當時也是被噴的不行。12年之后在 7、8月份進行了大規模的重構,到了13年的春節,整個系統就比較穩定了,基本沒有 down 機的情況發生。
面對 12306 這種讀多寫少的場景,可能我們平時會采用 Redis 這種緩存機制,12306 具體選擇的解決方案,可能跟我們常見的解決方案有一些不一樣。
12306 通過充分調研,并沒有選擇 Redis,而是選擇了名叫 Pivotal GemFire 的產品。
沒聽過 Pivotal ,學 Java 的肯定都聽過 Spring。
Spring 框架它歸屬于 Spring 團隊。沒錯框架名和團隊名是一樣的,這個團隊歸屬于 Pivotal 公司。
很多銀行、投行,實時交易方面的系統都采用 Pivotal GemFire 作為解決方案。

GemFire 基于開源項目 Geode 進行研發的。Redis 是在 2010 年左右才發行的第一個版本,Geode 是更早的一個開源項目。

GemFire 本身是 Geode 的商用版本,可以理解為收費的 Redis(Redis的作者現在就在 GemFire 打工)。就像 Oracle 和 MySQL。
為什么選擇 Pivotal GemFire 而不是 Redis?
https://redis.io/comparisons/redis-vs-gemfire/
Redis 是開源的緩存解決方案,而 GemFire 是商用的,我們在互聯網項目中為什么使用 Redis 比較多呢,很大原因就是因為 Redis 是開源的,不要錢。
開源對應的也就是穩定性不是那么的強,并且開源社區也不會給你提供解決方案,畢竟你是白嫖的。
而在銀行以及 12306 這些系統中,它們對可靠性要求非常的高,因此會選擇商用的 GemFire,不僅性能強、高可用,而且 GemFire 還會提供一系列的解決方案。
12306 本身不缺錢,在資金預算充足的情況下,追求系統的穩定性和交易的絕對可靠,追求的是最好的解決方案。
而 GemFire 類似 Oracle 是一套完整的解決方案,不只是給你一套工具,讓你私有化部署就不管了,而是需要后面持續去維護的。
據說 GemFire 同時做到了分布式系統里的CAP,違背了架構的一個常識。
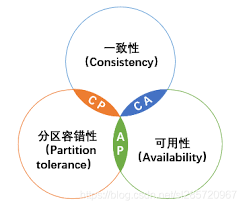
當時 12306 也嘗試了許多其他的解決方案,都扛不住查詢的流量,而使用 GemFire 之后扛住了流量,因此就使用了 GemFire。
Redis 主要用作緩存存儲,而當時 (12年左右) 12306 最大的瓶頸主要是在 IO 上面。
為什么 12306 最大的瓶頸會在 IO 上面呢?這跟 12306 使用讀擴散有關。
讀擴散和寫擴散常見于 訂閱/聊天/群聊 系統。
推薦閱讀:讀擴散與寫擴散分析
讀擴散,一般指犧牲了讀的性能,去提升寫的性能。
寫擴散,一般指犧牲了寫的性能,去提升讀的性能。
對應 12306 來說:
- 讀擴散:扣減只需要關注列車站點之間的扣減,關注車次,查詢的時候再去動態計算。
優點:扣減簡單;缺點:計算余票復雜。
- 寫擴散:扣減直接把各個站點之間票都扣減,關注站點。
優點:扣減復雜;缺點:查詢余票簡單。
個人猜測 12306 使用讀擴散的原因是對數據實時性有要求,當擴散隊列很長的時候,寫入時間存在延時,可能導致不同行程的余票對不齊。
而且涉及排列組合過多,使用寫擴散,數據冗余會比較嚴重,浪費存儲成本。
計算余票是一個數據密集型的運算,要關聯很多的數據進行計算。一方面需要數據,一方面又要頻繁的計算。計算跟數據本身是分開的(計算在CPU,數據存儲在內存)。
GemFire 的定位是實時存儲網格。
一般分布式緩存,比如Redis,查詢數據就算再快,還是要從緩存里取出數據,再CPU進行計算。
GemFire 最大的特點是將存儲和計算放在了一起,它的存儲和實時計算的性能目前還沒有其他中間件可以取代。

扣減庫存數據庫選用的是 Sybase(收費,關系型數據庫),相比查詢的流量,扣減庫存的流量是完全可以承載的。
db-engines.com 這個網站可以對比主流數據庫之間的差異
扣減庫存之后再同步至 GemFire,然后在 GemFire 里進行動態計算,整個 GemFire 承載的是查詢的流量。引入 GemFire 之后,整個系統的查詢擴散瓶頸基本上就解決了。
GemFire 將很多機器內存匯總成一個大的節點,作為整體去管理,盡量保證業務運算和業務數據是在同一個節點,盡量避免多節點的網絡通信。

但是 GemFire 也存在不足的地方,對于擴容的支持不太友好。在 12306 中,也有過測試,需要幾十個T的內存就可以將業務數據全部放到內存中來,因此直接將內存給加夠,也就不需要很頻繁的擴容。
余票庫存的表如何設計?
這里的設計思路都是猜測的,并不一定是 12306 真實的設計方案。
12306 余票庫存的表的設計是非常特色并且重要的
首先說一下需要哪幾個表來表示余票的庫存信息:
1、基礎的車次表:表示車次的編號以及發車時間等具體的車次信息,屬于比較穩定的數據。
2、車的座位表:表示每個座位的具體信息,包括在幾車廂、幾行、幾列,以及 該座位的售賣情況。
3、車的余票表:通過座位表可以計算出每個車位在各個車站區間還有多少余票,但是動態計算比較浪費性能,因此再添加余票表,通過定時計算余票信息放入到余票表中,提高查詢的性能。
(其實還應該有站點表和車廂表,不過不太重要,這里直接就省略了)
這里說一下這 3 個表的對應關系:
比如車次為 K123,該車上有很多的座位,每個座位對應座位表中的一條數據。
而余票表指的是 K123 車次上,硬座、硬臥、軟臥、無座各有多少張余票,余票表的信息可以由座位表來計算得到。
接下來說一下如何通過座位表來表示用戶購買的車票:
12306 中的車票信息其實是比較復雜的,因為各個車站之間是有依賴關系的,比如 4 個車站 A->B->C->D
如果乘客購買 B->C 的車票的話,不僅 B->C 的庫存要減一,B->D 的庫存也要減一,這是排列組合的情況,可以考慮通過二進制去簡化車票的表示。
在座位表中,我們設置一個字段 sell varchar(50) 表示該座位的售賣情況,如果該車次有 4 個站 A->B->C->D,那么 sell 字段的長度就為 3,sell 字段的第一位表示該座位 A->B 的票是否已經被買了,第二位表示 B->C 的票是否已經被買了…
如果乘客購買 B->C 的車票,則 sell 字段的值為:010。
如果乘客購買 B->D 的車票,此時發現該座位在 B->C 已經被賣出去了,因此不能將該座位出售給這位乘客。
如果乘客購買 C->D 的車票,則 sell 字段的值為:011 ,表示 B->C,C->D 都已經有人了。
通過座位表來計算出余票,得到余票表。
通過余票表提升查詢性能
這里余票表就相當于是數據庫中的視圖。
如果要去查詢一個車次中某一個類型的余票還有多少,還需要去對座位表進行計算,這個消耗是比較大的 ,因此通過余票表來加快對于余票的查詢。
可以定時去計算座位表中的數據,將每種類型的座位的余票給統計出來,比如:
硬臥:xx張
硬座:xx張
軟臥:xx張
…
再將余票表的信息給放入到緩存中,大大提高查詢的性能。
我們在使用 12306 的時候,也會發現,有時候顯示的有票,但是真正去買的時候發現已經沒有余票了,這就說明 12306 沒有保證實時的一致性,只要保證了最終一致性即可,也就是用戶真正去買的時候,保證對于余票數量的查詢是準確的就可以了。
個人推測 12306 使用的是緩存+動態計算結合的方式,查詢的時候使用的是緩存(最終一致性),等到真正下單的時候會再去動態計算一遍(實時一致性)。這樣利用緩存就能隔絕掉很大的查詢的流量,并且也能保證最終下單的準確性。
對于電商,如果商品銷售小份額的超出庫存,部分場景下可以通過補充庫存進行彌補,僅要求弱一致性。而 12306 屬于實時的交易型系統,庫存資源的數量固定,對分布式事務要求強一致性。
中間的站點如果太過火爆,導致兩邊的站點買不到票怎么辦?
比如 A->B->C->D,對于一個車次中的座位來說,如果 B->C 的乘客非常多,那么是不是就會導致 A->D 買不到票了?
這個是通過運營部來進行設計,首先考慮的肯定是要盈利,遠途票價比較貴,因此比較傾向于遠途的旅客,營業部根據具體的實際情況以及盈利情況來定一下各個區間預留多少票,給每個車站區間都留有一些余票,那么就不會因為某一個區間非常火爆,而導致其他乘客買不到長途的票了。
搶票軟件推薦
https://www.bypass.cn/(親測好用)
巨人的肩膀
- 【高級進階】12306未公開技術細節!技術專家必須理解的設計思想!
- 【12306完結】鐵道部技術內幕!為什么是Gemfire?如何強一致?預留票機制?
- 讀擴散與寫擴散分析
- 數據存儲結構設計,是讀擴散,還是寫擴散?
- 由12306.CN談談網站性能技術
- 12306 架構設計難點
- 12306的十年往事
- 為什么車票剛出就沒了?揭秘AI神器搶票內幕
- 進化的12306與殺不死的“黃牛”
- 12306訂票系統技術內幕 源碼
- 架構必看:12306搶票億級流量架構演進(圖解+秒懂+史上最全)
- 秘密合作半年 阿里同12306關系被曝光
- 搶了個票,還以為發現了12306的系統BUG
- 12306 技術分析
- 從嗤之以鼻到“奇跡” 前淘寶工程師詳解12306技術
- Gemfire:分布式緩存利器
- REDIS VS GEMFIRE







)
)




)





