上一次寫AI學習筆記已經好久之前了,溫習溫習,這一章講講關于Spring? AI 調用大模型、對話記憶、Adv?isor、結構化輸出、自定義對話記憶?、Prompt 模板的相關知識點。
快速跳轉到你感興趣的地方
- 一、提示詞工程(Prompt)
- 1. 基本概念 (提示詞、提示詞工程)
- 2. 分類 (基于角色、功能)
- 3. Prompt 優化技巧
- 二、對話記憶(多輪對話實現)
- 1. 使用 Chat Client 實現基礎對話功能
- 2. Advisor 顧問的使用
- 三、SpringAI會話記憶、Advisor實戰
- 1. 使用 InMemoryChatMemory:內存存儲 實現對話記憶
- 2. 自定義Advisor的使用
- 3. 使用自定義 Advisor 實現自定義日志 Advisor
- 四、結語(會不斷補充,可以收藏一下)
一、提示詞工程(Prompt)
1. 基本概念 (提示詞、提示詞工程)
提示詞就是用戶輸入給AI的指令,但是寫好提示詞,是一件十分不容易的事情。準確的提示詞能夠讓AI清楚的明白你所要達到的目的,從而生成滿意的內容。
而提示詞工程就是通過優化輸入給AI模型的指令或問題(即“提示詞”),以提升模型輸出的準確性和相關性。其核心在于理解模型的行為模式,并通過結構化語言引導模型生成更符合預期的結果。
2. 分類 (基于角色、功能)
按照角色來分類可以分為如下三類:
- 用戶 Prompt
是用戶直接向 AI 提出的具體需求或問題,例如請求寫詩、解答問題或生成代碼。其核心是傳遞用戶的具體意圖,要求 AI 執行明確的任務。 - 系統 Prompt
是開發者或平臺設定的隱藏指令,用于定義 AI 的角色、行為邊界和回答風格。它不直接面向用戶,但決定了 AI 如何響應用戶 Prompt。例如,設定 AI 為“專業詩人”或“情感顧問”會直接影響生成內容的專業性、語氣和結構。 - 助手 Prompt
在多輪對話中,助手 Prompt(即 AI 的歷史回復)會成為后續交互的上下文。預設的助手消息能引導對話方向,例如在客服場景中提前聲明服務范圍。這種機制增強了對話連貫性,但也需注意避免因歷史信息導致回答偏差。
按照功能來分可以分為:
- 指令型提?示詞: 明確告訴 AI? 模型需要執行的任務,?通常以命令式語句開頭。
將上述中文文本翻譯為英文
- 對話型?提示詞: 模擬?自然對話,以問答形式?與 AI 模型交互。
你認為AI會在取代人類嗎?
- 創意型?提示詞 引導 AI 模型?進行創意內容生成,如?故事、詩歌、廣告文案等。
寫一首描寫愛情的詩歌,贊美矢志不渝偉大的愛情
- 角色扮?演提示詞 ?讓 AI 扮演特定?角色或人物進行回答。
你是一位使用Java的程序員,使用java編寫一個貪吃蛇游戲
- 少樣本?學習提示詞 提供一些示例?,引導 AI 理解所?需的輸出格式和風格。
將以下句子改寫為正式商務語言:
示例1:
原句:這個想法不錯。
改寫:該提案展現了相當的潛力和創新性。示例2:
原句:我們明天見。
改寫:期待明日與您會面,繼續我們的商務討論。現在請改寫:這個價格太高了。
3. Prompt 優化技巧
網上和 Pro?mpt 優化相關的資源非常豐富,幾乎各大主流 AI ?大模型和 AI 開發框架官?方文檔都有相關的介紹。Spring AI 提示工程指南,智譜 AI Prompt 設計指南等等
這里講講我學習整理后的一些心得
這是springAI的提示詞編寫教程中的重點,其實重點在三個方面:
在開發提示時,重要的是要集成幾個關鍵組件,以確保清晰度和有效性:
- 指令:向AI提供清晰而直接的指令,類似于你與人溝通的方式。這種清晰度對于幫助AI“理解”預期內容至關重要。
- 外部環境:在必要時,為人工智能的反應提供相關的背景信息或具體指導。這種“外部環境”構成了提示,并幫助AI掌握整個場景。
- 用戶輸入:這是最直接的部分——用戶的直接請求或問題
只要說明白這三點,就算是一個合適的提示詞,但是是遠遠不夠的,這里我用AI整理出了優化的重點,感興趣的可以看一下。
清晰具體地定義需求,避免模糊指令,確保模型準確理解任務目標明確指定輸出格式,如JSON或特定結構,便于后續處理或解析將復雜任務拆解為多個簡單子任務,逐步遞進完成,提高準確率使用分隔符區分不同輸入部分,避免混淆,如"""文本內容"""在需要推理的問題中要求展示思維鏈,分步驟呈現推導過程通過少樣本示例引導模型模仿特定風格或行為模式控制輸出長度,設定字數限制或篇幅要求,確保簡潔性對長文本采用分段歸納再整合的方法,突破上下文限制在技術性任務中先讓模型自主生成答案,再進行評估驗證必要時隱藏詳細推理過程,直接輸出最終結果或結構化數據利用外部工具增強能力,如API查詢實時數據或訪問知識庫在長對話中定期總結關鍵信息,保持上下文連貫性角色扮演方式可提升專業領域回答的準確性為系統提示設定明確的行為模式和任務規范### 優化Prompt的技巧清晰具體地定義需求,避免模糊指令,確保模型準確理解任務目標明確指定輸出格式,如JSON或特定結構,便于后續處理或解析將復雜任務拆解為多個簡單子任務,逐步遞進完成,提高準確率使用分隔符區分不同輸入部分,避免混淆,如"""文本內容"""在需要推理的問題中要求展示思維鏈,分步驟呈現推導過程通過少樣本示例引導模型模仿特定風格或行為模式控制輸出長度,設定字數限制或篇幅要求,確保簡潔性對長文本采用分段歸納再整合的方法,突破上下文限制在技術性任務中先讓模型自主生成答案,再進行評估驗證必要時隱藏詳細推理過程,直接輸出最終結果或結構化數據利用外部工具增強能力,如API查詢實時數據或訪問知識庫在長對話中定期總結關鍵信息,保持上下文連貫性角色扮演方式可提升專業領域回答的準確性為系統提示設定明確的行為模式和任務規范### 優化Prompt的技巧清晰具體地定義需求,避免模糊指令,確保模型準確理解任務目標明確指定輸出格式,如JSON或特定結構,便于后續處理或解析將復雜任務拆解為多個簡單子任務,逐步遞進完成,提高準確率使用分隔符區分不同輸入部分,避免混淆,如"""文本內容"""在需要推理的問題中要求展示思維鏈,分步驟呈現推導過程通過少樣本示例引導模型模仿特定風格或行為模式控制輸出長度,設定字數限制或篇幅要求,確保簡潔性對長文本采用分段歸納再整合的方法,突破上下文限制在技術性任務中先讓模型自主生成答案,再進行評估驗證必要時隱藏詳細推理過程,直接輸出最終結果或結構化數據利用外部工具增強能力,如API查詢實時數據或訪問知識庫在長對話中定期總結關鍵信息,保持上下文連貫性角色扮演方式可提升專業領域回答的準確性為系統提示設定明確的行為模式和任務規范二、對話記憶(多輪對話實現)
1. 使用 Chat Client 實現基礎對話功能
參考 Spring AI 的官方文檔,了解到 Spring AI 提供了 ChatClient API 來和 AI 大模型交互。
ChatClient 是使用 ChatClient.Builder 對象創建的。您可以為任何 ChatModel Spring Boot 自動配置獲取一個自動配置的 ChatClient.Builder 實例,也可以通過編程方式創建一個
這是官方提供的通過構造器注入的事例:
// 方式1:使用構造器注入
@RestController
class MyController {private final ChatClient chatClient;public MyController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}@GetMapping("/ai")String generation(String userInput) {return this.chatClient.prompt().user(userInput).call().content();}
}
使用建造者模式
// 方式2:使用建造者模式
ChatClient chatClient = ChatClient.builder(chatModel).defaultSystem("you are a helpful AI").build();
ChatC?lient 支持多種響應格式,比如返?回 ChatRes?ponse 對象、?返回實體對象、流式返回:
// ChatClient支持多種響應格式
// 1. 返回 ChatResponse 對象(包含元數據如 token 使用量)
ChatResponse chatResponse = chatClient.prompt().user("Tell me a joke").call().chatResponse();// 2. 返回實體對象(自動將 AI 輸出映射為 Java 對象)
// 2.1 返回單個實體
record ActorFilms(String actor, List<String> movies) {}
ActorFilms actorFilms = chatClient.prompt().user("Generate the filmography for a random actor.").call().entity(ActorFilms.class);// 2.2 返回泛型集合
List<ActorFilms> multipleActors = chatClient.prompt().user("Generate filmography for Tom Hanks and Bill Murray.").call().entity(new ParameterizedTypeReference<List<ActorFilms>>() {});// 3. 流式返回(適用于打字機效果)
Flux<String> streamResponse = chatClient.prompt().user("Tell me a story").stream().content();// 也可以流式返回ChatResponse
Flux<ChatResponse> streamWithMetadata = chatClient.prompt().user("Tell me a story").stream().chatResponse();可以給 C?hatClient 設置默認參數,比如系?統提示詞,還可以在對?話時動態更改系統提示?詞的變量,類似模板的概念:
// 定義默認系統提示詞
ChatClient chatClient = ChatClient.builder(chatModel).defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}").build();// 對話時動態更改系統提示詞的變量
chatClient.prompt().system(sp -> sp.param("voice", voice)).user(message).call().content());2. Advisor 顧問的使用
Advisor在Spring AI中扮演著類似AOP(面向切面編程)中顧問的角色,用于在 AI 模型調用前后添加邏輯以增強 AI 的能力。它允許開發者在不修改核心代碼的情況下,對AI請求進行預處理或后處理,例如日志記錄、對話記憶、RAG等。
- 前置增強:調用 AI 前改寫一下 Prompt 提示詞、檢查一下提示詞是否安全
- 后置增強:調用 AI 后記錄一下日志、處理一下返回的結果
比如對話記憶顧問 Me?ssageChatMemoryAdv?isor 可以幫助我們實現多輪對話能?力,省去了自己維護對話列表的麻煩。
var chatClient = ChatClient.builder(chatModel).defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory), // 對話記憶 advisornew QuestionAnswerAdvisor(vectorStore) // RAG 檢索增強 advisor).build();String response = this.chatClient.prompt()// 對話時動態設定攔截器參數,比如指定對話記憶的 id 和長度.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678").param("chat_memory_response_size", 100)).user(userText).call().content();
Advisors 的原理圖如下:
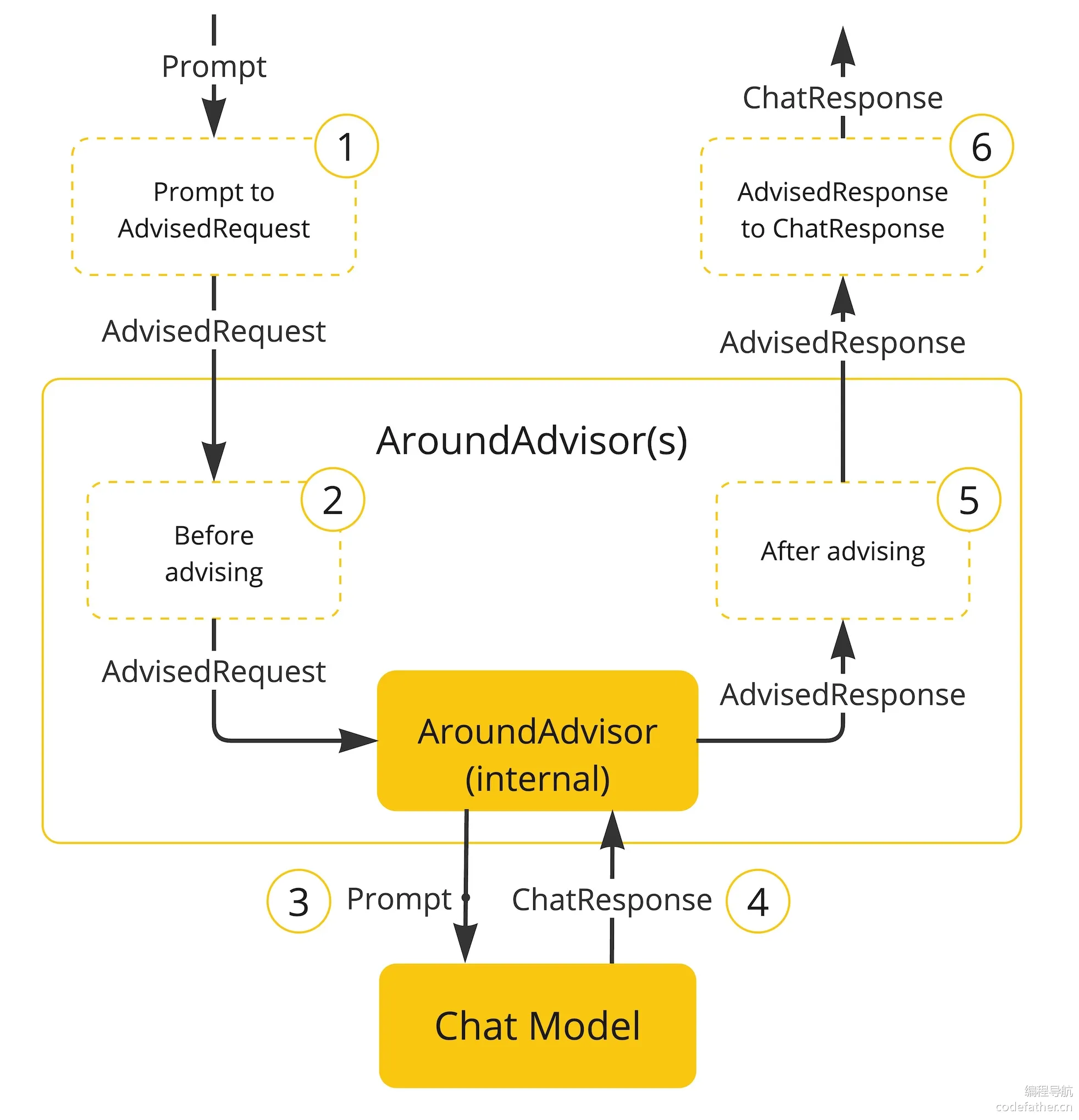

實際開發中,往往我們會用到多個攔截器,組合在一起相當于一條攔截器鏈條(責任鏈模式的設計思想)。每個攔截器是有順序的,通過 getOrder() 方法獲取到順序,得到的值越低,越優先執行。
想要實現對話記憶功能,可以使用 Spring? AI 的 ChatMe?moryAdvisor,?它主要有幾種內置的實現方式:
- MessageChatMemoryAdvisor:從記憶中檢索歷史對話,并將其作為消息集合添加到提示詞中
- PromptChatMemoryAdvisor:從記憶中檢索歷史對話,并將其添加到提示詞的系統文本中
- VectorStoreChatMemoryAdvisor:可以用向量數據庫來存儲檢索歷史對話
Messag?eChatMemoryAdvisor 和 Pro?mptChatMemor?yAdvisor 用法類?似,但是略有一些區別:
Messag?eChatMemoryAdvisor將對話歷史作為一系列獨?立的消息添加到提示中,保留原始?對話的完整結構,包括每條消息的?角色標識(用戶、助手、系統)
[{"role": "user", "content": "你好"},{"role": "assistant", "content": "你好!有什么我能幫助你的嗎?"},{"role": "user", "content": "講個笑話"}
]
PromptC?hatMemoryAdvisor將對話歷史添加到提示詞的系統文本部?分,因此可能會失去原始的消息邊界。???????????????????
以下是之前的對話歷史:
用戶: 你好
助手: 你好!有什么我能幫助你的嗎?
用戶: 講個笑話
現在請繼續回答用戶的問題。
一般情況下,更建議使用 MessageChatMemoryAdvisor 更符合大多數現代 LLM 的對話模型設計,能更好地保持上下文連貫性。
使用 Chat Memory構造ChatMemoryAdvisor
上述 ChatMemoryAdvisor 都依賴 Chat Memory 進行構造,Chat Memory 負責歷史對話的存儲,定義了保存消息、查詢消息、清空消息歷史的方法。
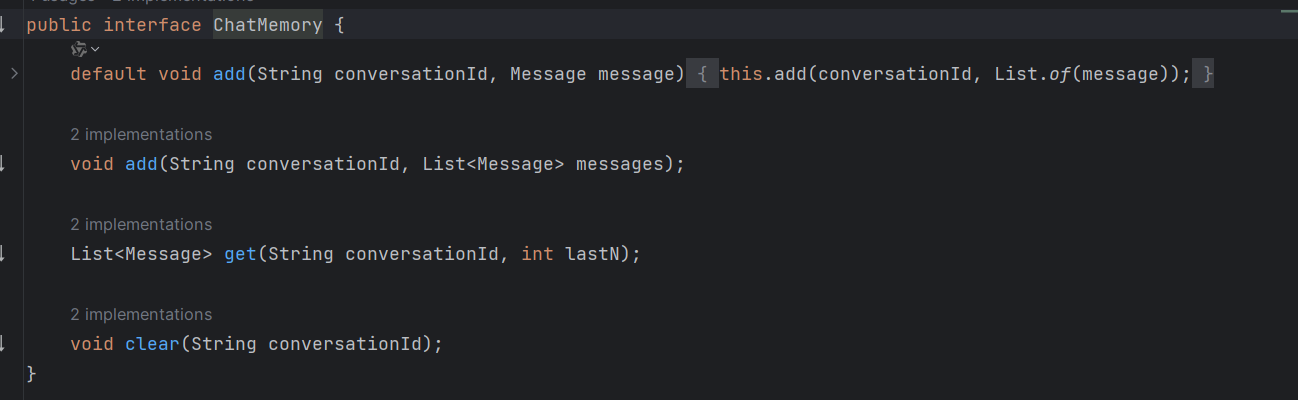
Sprin?g AI 內置了幾種 Chat Me?mory,可以將對?話保存到不同的數據?源中,比如:
- InMemoryChatMemory:內存存儲
- CassandraChatMemory:在 Cassandra 中帶有過期時間的持久化存儲
- Neo4jChatMemory:在 Neo4j 中沒有過期時間限制的持久化存儲
- JdbcChatMemory:在 JDBC 中沒有過期時間限制的持久化存儲
- 自定義數據源存儲
三、SpringAI會話記憶、Advisor實戰
1. 使用 InMemoryChatMemory:內存存儲 實現對話記憶
- 首先初始化 ChatC?lient 對象。使用 Spring 的構造器注入方式來注入阿里大模型dashscopeChatMod?el 對象,并使用該對象來初始化 ChatCli?ent。初始化時指定默認的系統 Prompt 和基于內存?的對話記憶 Advisor。代碼如下:
@Component
@Slf4j
public class App {private final ChatClient chatClient;private static final String SYSTEM_PROMPT = "your system prompt";public LoveApp(ChatModel dashscopeChatModel) {// 初始化基于內存的對話記憶ChatMemory chatMemory = new InMemoryChatMemory();chatClient = ChatClient.builder(dashscopeChatModel).defaultSystem(SYSTEM_PROMPT).defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory)).build();}
}
- 編寫對話方法,調用 chatClient 對象,傳入用戶 Pr?ompt,并且給 advi?sor 指定對話 id 和對話?記憶大小。代碼如下:
public String doChat(String message, String chatId) {ChatResponse response = chatClient.prompt().user(message).advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)).call().chatResponse();String content = response.getResult().getOutput().getText();log.info("content: {}", content);return content;
}
- 編寫單元測試,測試多輪對話:
@SpringBootTest
class AppTest {@Resourceprivate App app;@Testvoid testChat() {String chatId = UUID.randomUUID().toString();// 第一輪String message = "你好,我是wangdong.";String answer = app.doChat(message, chatId);Assertions.assertNotNull(answer);// 第二輪message = "我想學習springAI!!!";answer = app.doChat(message, chatId);Assertions.assertNotNull(answer);// 第三輪message = "你記得我叫啥嗎?";answer = app.doChat(message, chatId);Assertions.assertNotNull(answer);}
}
第一輪:

第二輪:
第三輪:

這樣我們就完成了基于內存的會話記憶,但是這樣還是有弊端,一旦程序重啟,我們的會話還是會丟失,還需要別的方法來優化會話記憶
2. 自定義Advisor的使用
自定義Adcisor 和 Spring AOP 比較相似,我們可以通過編寫攔截?器或切面對請求和響應進行處理?,比如記錄請求響應日志、鑒權等。
Spring ?AI 的 Advisor 就可以理解為攔截器,可以對?調用 AI 的請求進行增強?,比如調用 AI 前鑒權、?調用 AI 后記錄日志。
官方已經提供了一些 Advisor,但可能無法滿足我們實際的業務需求,這時我們可以使用官方提供的 自定義 Advisor 功能。按照下列步驟操作即可。
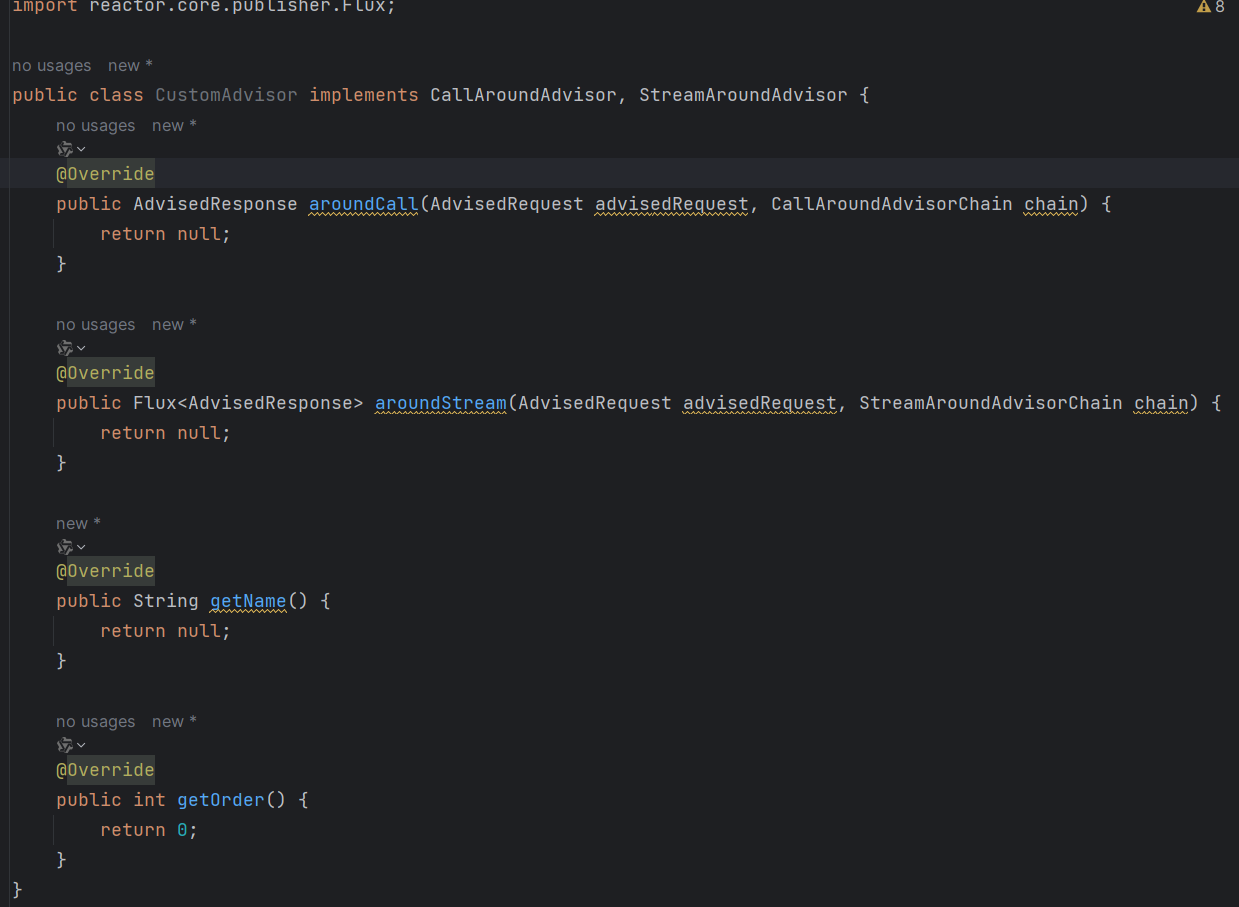
- 自定義的Advisor要實現這兩個接口
CallAroundAdvisorStreamAroundAdvisor
public class CustomAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {//實現方法...
}
- 實現核心方法
對于非流式處理 (CallAroundAdvisor),實現 aroundCall 方法:
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {// 1. 處理請求(前置處理)AdvisedRequest modifiedRequest = processRequest(advisedRequest);// 2. 調用鏈中的下一個AdvisorAdvisedResponse response = chain.nextAroundCall(modifiedRequest);// 3. 處理響應(后置處理)return processResponse(response);
}
對于流式處理 (StreamAroundAdvisor),實現 aroundStream 方法:
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {// 1. 處理請求AdvisedRequest modifiedRequest = processRequest(advisedRequest);// 2. 調用鏈中的下一個Advisor并處理流式響應return chain.nextAroundStream(modifiedRequest).map(response -> processResponse(response));
}
- 設置執行順序
通過實現getOrder()方法指定 Advisor 在鏈中的執行順序。值越小優先級越高,越先執行:
@Override
public int getOrder() {// 值越小優先級越高,越先執行return 100;
}
- 提供唯一名稱
為每個 Advisor 提供一個唯一標識符:
@Override
public String getName() {return "魚皮自定義的 Advisor";
}
3. 使用自定義 Advisor 實現自定義日志 Advisor
雖然 Spring ?AI 已經內置了 SimpleLoggerAdvisor 日志攔截器,但是以 D?ebug 級別輸出日志,而默認 Spri?ng Boot 項目的日志級別是 Inf?o,所以看不到打印的日志信息。
雖然上述方?式可行,但如果為了更靈活地打印指定的?日志,建議自己實現?一個日志 Adv?isor。
我們可以同時參考 官方文檔 和內置的 SimpleLoggerAdvisor 源碼,結合 2 者并略做修改,開發一個更精簡的、可自定義級別的日志記錄器。默認打印 info 級別日志、并且只輸出單次用戶提示詞和 AI 回復的文本。
/*** 自定義日志 Advisor* 打印 info 級別日志、只輸出單次用戶提示詞和 AI 回復的文本*/
@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {@Overridepublic String getName() {return this.getClass().getSimpleName();}@Overridepublic int getOrder() {return 0;}private AdvisedRequest before(AdvisedRequest request) {log.info("AI Request: {}", request.userText());return request;}private void observeAfter(AdvisedResponse advisedResponse) {log.info("AI Response: {}", advisedResponse.response().getResult().getOutput().getText());}public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {advisedRequest = this.before(advisedRequest);AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);this.observeAfter(advisedResponse);return advisedResponse;}public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {advisedRequest = this.before(advisedRequest);Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);}
}
上述代碼中值得關注的是 arou?ndStream 方法的返回,通過 MessageAggregator 工具類將 Flux 響應聚合成單個 AdvisedR?esponse。這對于日志記錄或其他需要觀察整個響應而非流中各?個獨立項的處理非常有用。注意,不能在 MessageAggre?gator 中修改響應,因為它是一個只讀操作。
在 App 中應用自定義的日志 Advisor:
chatClient = ChatClient.builder(dashscopeChatModel).defaultSystem(SYSTEM_PROMPT).defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory),// 自定義日志 Advisor,可按需開啟new MyLoggerAdvisor(),).build();
四、結語(會不斷補充,可以收藏一下)
本章介紹了 Spring? AI 調用大模型、提示詞工程、對話記憶、Adv?isor 的基本使用,對于對話記憶的自定義和jdbc存儲,也會在這段時間加入,我會在學習中不斷整理筆記,鞏固自己學到的東西。


深入理解【實戰】)
結構型:代理模式詳解)
)




)




+利于SEO優化(下載))




