前篇博文將OceanBase的存儲架構巧妙地與自然界中的“水生態”進行了類比,今日我們轉變視角,聚焦在與擁有相同LSM-Tree架構的其他產品的比較,深入探討OceanBase相較于它們所展現出的獨特性能。
?眾所周知,OceanBase數據庫的存儲引擎是以LSM-Tree架構為基礎的。相較之下,傳統的LSM-Tree結構在層次化存儲方面往往表現得更為明顯,而OceanBase的LSM-Tree實現則在此基礎上有其獨特之處。
我們以業界經典的LSM-Tree實現案例為例--單機存儲引擎LevelDB:其數據流向和OceanBase數據庫是類似的,數據會從可寫的Activate Memtable->只讀的Immutable Memtable->L0?->L1?->...->Ln?。磁盤數據被從上到下分成了多個層次,越下層的數據越舊。同時,在寫入內存前,數據會先追加寫入寫前日志(WAL)中。
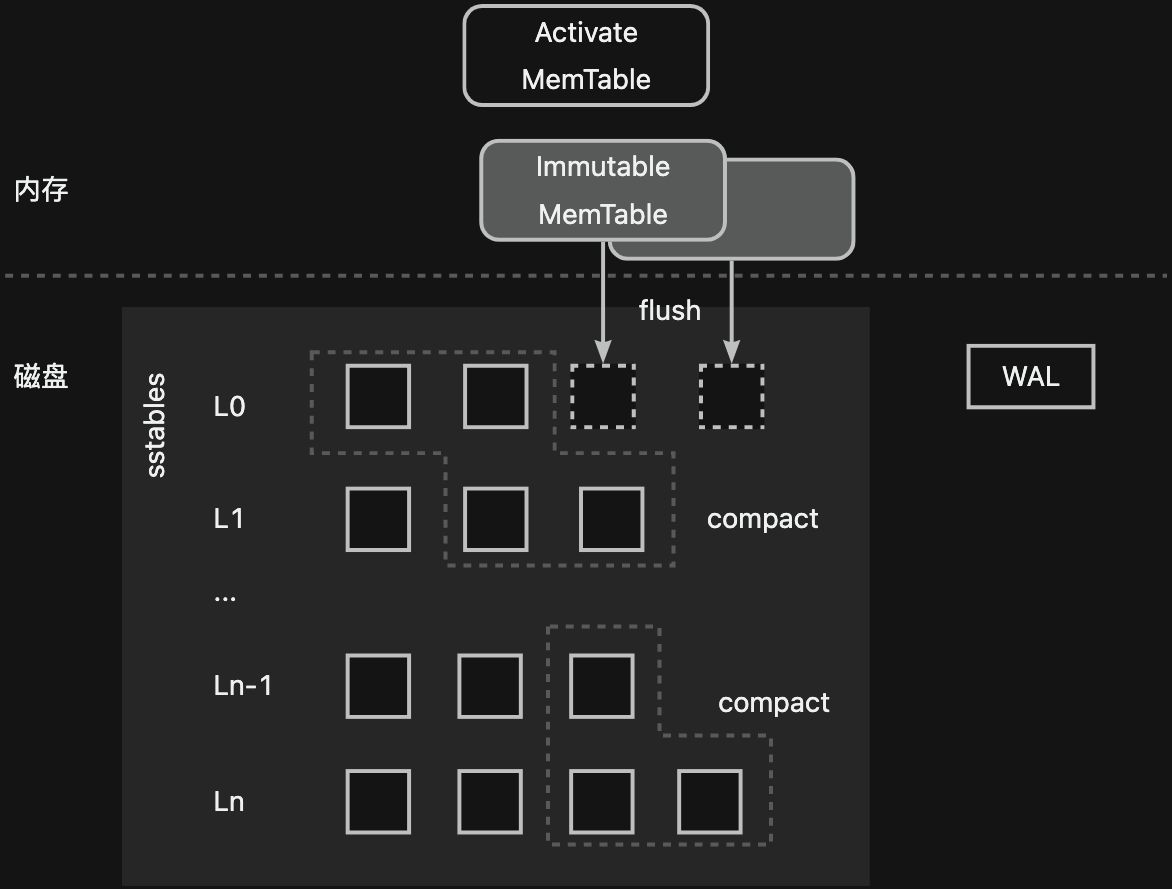
?LevelDB中只讀的內存數據通過Flush過程被下刷到磁盤,并按照鍵的順序以SSTable文件的形式存儲。L0層的SSTable文件間存在數據范圍的重疊,每個SSTable文件可以被認為是一個sorted run(一個有序的集合,集合內每個元素唯一)。而L0層以下的每一層SSTable文件是有序不重疊的,也就是說,每一層的多個SSTable文件共同構成了一個sorted run。每層的SSTable文件會通過compact過程向下一層移動,每一次compact過程會涉及到相鄰兩層多個數據范圍重疊的SSTable文件。這些SSTable文件的數據會重新進行排序與合并,形成一個新的SSTable文件。隨著從上到下層數的增加,每層的可容納SSTable文件總數據量會成倍數增長。
?對于這樣的分層結構,我們很容易注意到其中存在的幾個問題:
- 讀放大
- LSM-Tree的讀操作需要從新到舊層層查找,這個過程可能需要多次I/O,放大了讀盤次數。
- 空間放大
- 磁盤數據都是只讀的,大量冗余和無效數據會占用額外的存儲,放大了磁盤空間。
- 寫放大
- 磁盤數據的有序整理不可避免的帶來了額外的寫入。
所謂的compact過程通過將層級之間的數據進行合并、清理無效的數據、減少上下層級有范圍重疊的SSTable文件數量,改善了讀放大與空間放大的問題,但由于增加了額外的磁盤寫操作,引入了額外的寫放大問題。
?為了權衡這三者,不同的實現者通常會采用不同的compact策略:
- size-tiered compaction
- 每層有多個大小相近的sorted runs,當某一層的數據總量達到限制后將整層合并,刷寫到下一層成為一個更大的sorted run,直到最大的一層維護一個sorted run。這種方式對全局有序的要求最小,可以最大程度的減少寫放大。但由于數據冗余度可能較大,讀放大和空間放大問題較為嚴重。
- leveled compaction
- 每層一個sorted run,層級之間維持相同的數據倍數比,層級越高數據量越多。每層的數據量達到限制后與下一層進行合并。通常每個sorted run被劃分為多個SSTable文件,以提供了更精細化的合并任務的拆分與控制。這種compact方式將相鄰層級的多個SSTable降為一個,減小了讀放大和空間放大。但由于compact時最差情況可能涉及下一層級的所有SSTable文件,寫放大相對更大。
- tiered+leveled compaction
- 結合了size-tiered和leveled的compact方式,某些層包含多個sorted runs,某些層只有一個sorted run。
不難看出,LevelDB采用的是tiered+leveled的compact方式,其中L0層包含了多個sorted runs,其余層只有一個sorted run,但從compact的流程來說,L0層的多個sorted runs在合并到下一層的過程里會選擇L1層有數據范圍重疊的SSTable文件,更接近于leveled compaction的形式。
?在了解完傳統LSM-Tree架構的實現與相關知識后,我們通過下圖簡單回憶一下上篇博客講到的OceanBase的存儲架構。可以看到,OceanBase和LevelDB單機存儲引擎的數據流轉方向是近乎一致的,這也是同為LSM-Tree架構的顯著相同點:數據都是先追加寫到日志,再寫入內存;內存都分為可寫的與只讀的兩部分,通過凍結可寫部分來生成只讀部分,通過將只讀部分下刷到磁盤形成持久化只讀數據。
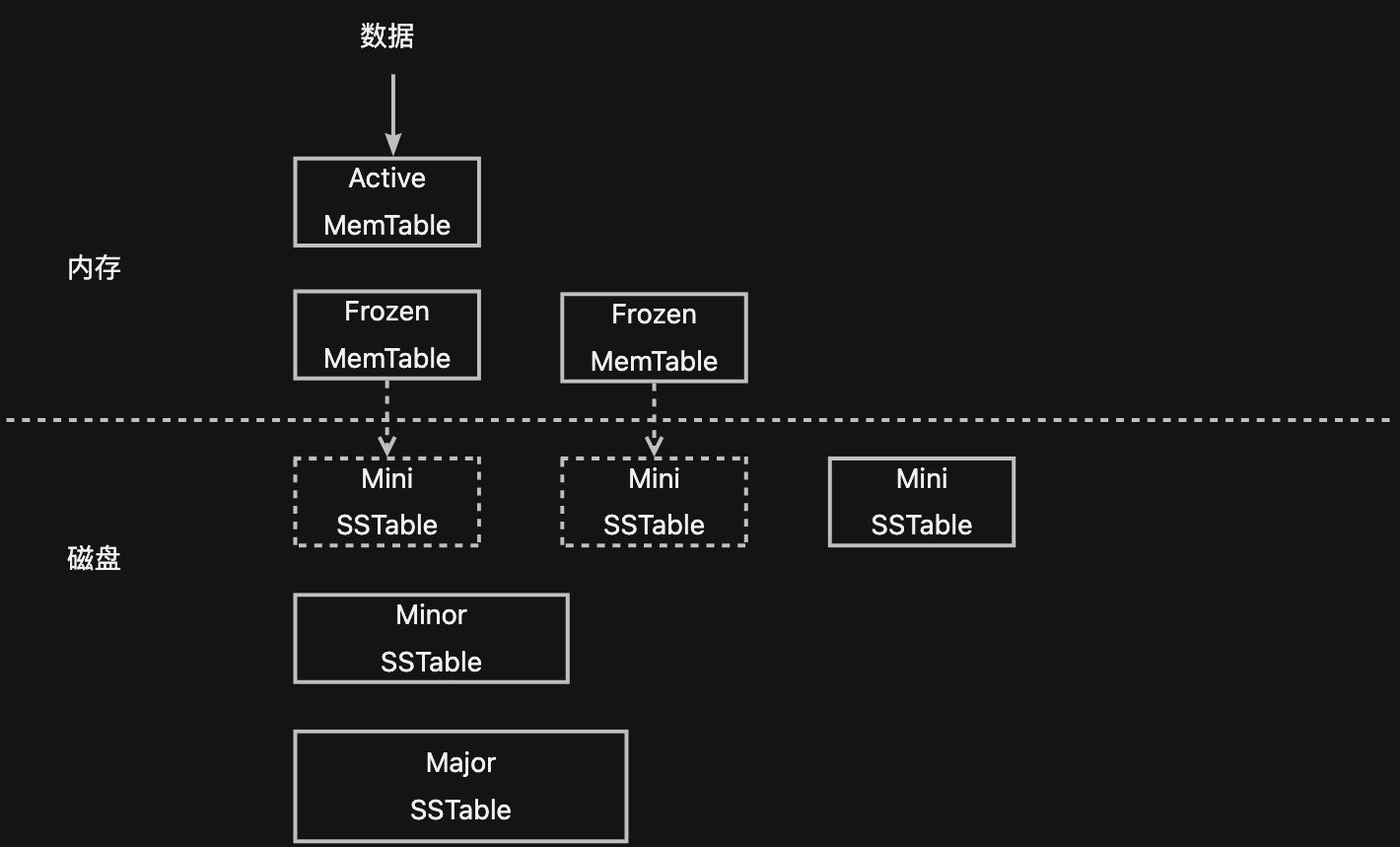
?而兩者的不同點主要集中在為了權衡讀放大、寫放大和空間放大所做的磁盤只讀數據的組織和管理上。
?LevelDB的每個SSTable是一個獨立的文件,通過以多個SSTable文件組成一個sorted run的形式來細分每次compact操作;而為了能夠有效減小寫放大和空間放大,OceanBase希望沒有修改過的數據不要進行重寫,因此OceanBase將所有數據統一存儲在一個文件(data_file)上,以定長塊(宏塊)的形式來分配和使用data_file的空間,每個SSTable由多個不連續的宏塊組成,沒有修改過的宏塊能夠在compact時直接重用。這種組織方式上的差異性進一步讓OceanBase和LevelDB有了一些區別:
- Level的磁盤數據通常具有比較明顯的層級劃分,每層數據量的上限從上到下逐級增大,L0層由多個SSTable文件組成,每個SSTable文件是一個sorted run,L0層以下的每層都是一個sorted run,由一個或多個SSTable文件組成;如果以層級來劃分OceanBase的磁盤數據的話,可以被認為有三層,由于有宏塊這一細粒度有序集的存在,OceanBase中的L1層與L2層并不需要細分為多個SSTable,而是直接通過一個SSTable來組成sorted run。
?從compact的角度來說,OceanBase也和LevelDB不一樣。為了更好的控制寫放大,OceanBase既可以通過tiered類型的compact過程將若干個Mini SSTable合成一個Mini SSTable,也可以通過leveled類型的compact過程將若干個Mini SSTable和一個Minor SSTable合成一個新的Minor SSTable。同時,為了最大程度的減小讀放大與空間放大,OceanBase會定期進行full compact過程,將所有SSTable合成一個新的Major SSTable。由于該過程通常被放在業務低峰期,資源的大量占用被認為是可接受的。
?另一方面,從具體的一些實現上來說,LevelDB的MemTable通常采用跳表的結構,而OceanBase的MemTable則采用了BTree+HashTable的混合結構。
?從下一章開始,我們將展開講講OceanBase是如何整理SSTable的。當然,感興趣的同學不妨先預習一下,在OceanBase的Github倉庫里查看ob_compaction_util.h文件,我們將逐一揭秘其中“M系列”的compact過程。
)




)








概述)



![buu[HCTF 2018]WarmUp(代碼審計)](http://pic.xiahunao.cn/buu[HCTF 2018]WarmUp(代碼審計))