思考:為什么JavaScript可以在瀏覽器中被執行
每個瀏覽器都有JS解析引擎,不同的瀏覽器使用不同的JavaScript解析引擎,待執行的js代碼會在js解析引擎下執行
為什么JavaScript可以操作DOM和BOM
每個瀏覽器都內置了DOM、BOM這樣的API函數,因此,瀏覽器中的JavaScript才可以調用他們
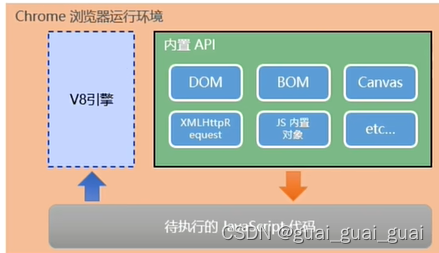
瀏覽器中的JavaScript運行環境
運行環境是指代碼正常運行所需的必要環境
總結:
- V8引擎負責解析和執行JavaScript代碼
- 內置API是由運行環境提供的特殊接口,只能在所屬的運行環境中被調用
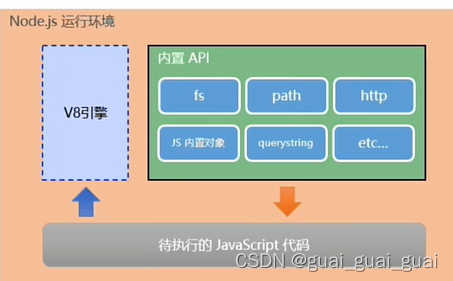
Node.js中的JavaScript運行環境
注意:
- 瀏覽器是JavaScript的前端運行環境
- Node.js是JavaScript的后端運行環境
- Node.js中無法調用DOM和BOM等瀏覽器內置API
Node.js作用:
- 基于Express(http://www.expressjs.com/cn),可以快速構建Web應用
- 基于Electron框架(http://electronjs.org/),可以構建跨平臺的桌面應用
- 基于restify框架(http://restify.com/),可以快速構建API借口項目
- 讀寫和操作數據庫,創建實用的命令行工具輔助前端開發
Node.js環境的安裝
區分LTS版本和Current版本的不同
- LTS為長期穩定版,對于追求穩定性的企業級項目來說,推薦安裝LTS版本的Node.js
- Current為新特性嘗鮮版,對熱衷于嘗試新特性的用戶來說,推薦Current版本的Node.js,但是,Current版本中可能存在隱藏的Bug或安全漏洞,因此不推薦在企業級項目中使用Current版本的Node.js
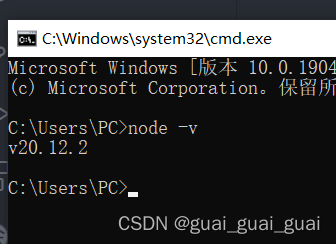
在終端中輸入命令node -v可查看node.js是否安裝成功
在Node.js環境中執行JavaScript代碼
在終端中輸入
node 要執行的js文件路徑
注意要切換到文件所處的目錄
cd 文件路徑
終端中的快捷鍵
- 上箭頭----快速定位到上一次命令
- tab鍵----補全文件路徑
- esc鍵----快速清空當前已輸入的命令
- 輸入cls清空終端
fs文件系統模塊
fs模塊是Node.js官方提供的、用來操作文件的模塊,它提供了一系列的方法和屬性,用來滿足用戶對文件的操作需求
例如:
- fs.readFile()方法,用來讀取文件中的內容
- fs.writeFile()方法,用來向指定的文件中寫入內容
如果要在JavaScript代碼中使用fs模塊來操作文件,則需先使用如下的方法導入它:
fs.readFile()的語法格式
使用fs.readFile()方法,可以讀取指定文件中的內容,語法格式如下:
fs.readFile(path[,options],callback)- 參數1:必選參數,字符串,表示文件的路徑
- 參數2:可選參數,表示以什么編碼格式來讀取文件
- 參數3:必選參數,文件讀取完成后,通過回調函數拿到讀取的結果
// 導入fs模塊 來操作文件
const fs=require('fs')
// fs.readFile(path[,options],callback)
// 調用fs.readFile()方法讀取文件
// 參數1:讀取文件的存放路徑 參數2:讀取文件時候采用的編碼格式,一般默認指定utf-8參數3:回調函數 拿到讀取失敗和成功的結果 err dataStr
// fs.readFile('../files/1.txt','utf-8',function(err,dataStr){
// // 打印失敗的結果
// // 如果讀取成功 則err的值為null
// // 如果讀取失敗 則err的值為錯誤對象,dataStr的值為undefined
// console.log(err)
// // 打印成功的結果
// console.log(dataStr)
// })fs.readFile('./files/1.txt','utf8',function(err,result){if(err){return console.log('文件讀取失敗'+err.message)}console.log('文件讀取成功,內容是:'+result)
})
向指定的文件中寫入內容 fs.writeFile()
語法格式
fs.writeFile(file,data[,option],callback)- 參數1:必選參數,需要指定一個文件路徑的字符串,表示文件的存放路徑
- 參數2:必選參數,表示要寫入的內容
- 參數3:可選參數,表示以什么格式寫入文件內容,默認值是utf8
- 參數4:必選參數,文件寫入完成后的回調函數
// 導入fs文件系統模塊
const fs=require('fs')
// 調用fs.writeFile()方法 寫入文件內容
// 參數1 表示文件的存放路徑
// 參數2:表示要寫入的內容
// 參數3:回調函數
fs.writeFile('./files/2.txt','abcd',function(err){// 如果文件寫入成功 則err的值等于null// 如果文件寫入失敗 則err的值等于一個錯誤對象console.log(err)
})
新建文件并判斷是否寫入成功?(3.txt并未初始并未創建)
// 導入fs文件系統模塊
const fs=require('fs')
// 調用fs.writeFile()方法 寫入文件內容
// 參數1 表示文件的存放路徑
// 參數2:表示要寫入的內容
// 參數3:回調函數
fs.writeFile('../files/3.txt','ok',function(err){// 如果文件寫入成功 則err的值等于null// 如果文件寫入失敗 則err的值等于一個錯誤對象// console.log(err)if(err){return console.log('文件寫入失敗'+err.message)}console.log('文件寫入成功!')
})
練習 - 考試成績整理
核心實現步驟:
- 導入需要的fs文件系統模塊
- 使用fs.readFile()方法,讀取素材目錄下的成績.txt文件
- 判斷文件是否讀取失敗
- 文件讀取成功后,處理成績數據
- 將處理完成的成績數據,調用fs.writeFile()方法,寫入到新文件成績- ok.txt中
// 1. 導入 fs 模塊
const fs = require('fs')// 2. 調用 fs.readFile() 讀取文件的內容
fs.readFile('../素材/成績.txt', 'utf8', function(err, dataStr) {// 3. 判斷是否讀取成功if (err) {return console.log('讀取文件失敗!' + err.message)}// console.log('讀取文件成功!' + dataStr)// 4.1 先把成績的數據,按照空格進行分割const arrOld = dataStr.split(' ')console.log(arrOld)// 4.2 循環分割后的數組,對每一項數據,進行字符串的替換操作const arrNew = []arrOld.forEach(item => {arrNew.push(item.replace('=', ':'))})console.log(arrNew)// 4.3 把新數組中的每一項,進行合并,得到一個新的字符串const newStr = arrNew.join('\r\n')//\r\n表示換行console.log(newStr)// 5. 調用 fs.writeFile() 方法,把處理完畢的成績,寫入到新文件中fs.writeFile('./files/成績-ok.txt', newStr, function(err) {if (err) {return console.log('寫入文件失敗!' + err.message)}console.log('成績寫入成功!')})
})
fs模塊 - 路徑動態拼接問題
在使用fs模塊操作文件時,如果提供的操作路徑是以./或../開頭的相對路徑時,很容易出現路徑動態拼接錯誤的問題
原因:代碼在運行的時候,會以執行node命令時所處的目錄,動態拼接出被操作文件的完整路徑
解決方案:在使用fs模塊操作文件時,直接提供完整的路徑,不要提供./或../開頭的相對路徑,從而防止路徑動態拼接的問題
const fs = require('fs')// 出現路徑拼接錯誤的問題,是因為提供了 ./ 或 ../ 開頭的相對路徑
// 如果要解決這個問題,可以直接提供一個完整的文件存放路徑就行
/* fs.readFile('./files/1.txt', 'utf8', function(err, dataStr) {if (err) {return console.log('讀取文件失敗!' + err.message)}console.log('讀取文件成功!' + dataStr)
}) */// 移植性非常差、不利于維護 注意將\寫成\\ 轉義字符
/* fs.readFile('C:\\Users\\escook\\Desktop\\Node.js基礎\\day1\\code\\files\\1.txt', 'utf8', function(err, dataStr) {if (err) {return console.log('讀取文件失敗!' + err.message)}console.log('讀取文件成功!' + dataStr)
}) */// __dirname 表示當前文件所處的目錄
// console.log(__dirname)fs.readFile(__dirname + '/files/1.txt', 'utf8', function(err, dataStr) {if (err) {return console.log('讀取文件失敗!' + err.message)}console.log('讀取文件成功!' + dataStr)
})
Path路徑模塊
path模塊是Node.js官方提供的,用來處理路徑的模塊,它提供了一系列的方法和屬性,用來滿足用戶對路徑的處理需求。
例如:
- path.join()方法,用來將多個路徑片段拼接成一個完整的路徑字符串
- path.basename()方法,用來從路徑字符串中將文件名解析出來
如果要在JavaScript代碼中,使用path模塊來處理路徑,則需要先使用如下方式導入path
const path = require('path')path.join()代碼示例
使用path.join()方法,可以把多個路徑片段拼接為完整的路徑字符串:
const path = require('path')
const fs = require('fs')// 注意: ../ 會抵消前面的路徑
// const pathStr = path.join('/a', '/b/c', '../../', './d', 'e')
// console.log(pathStr) // \a\d\e// fs.readFile(__dirname + '/files/1.txt')fs.readFile(path.join(__dirname, './files/1.txt'), 'utf8', function(err, dataStr) {if (err) {return console.log(err.message)}console.log(dataStr)
})
注意:今后凡是涉及到路徑拼接的操作,都要使用path.join()方法進行處理,不要直接使用+字符串拼接
獲取路徑中的文件名path.basename()格式
使用path.basename()方法,可以獲取路徑中的最后一部分,經常通過這個方法獲取路徑中的文件名,語法格式如下:
path.basename(path[,ext])參數解讀:
- path<string>必選參數,表示一個路徑的字符串
- ext<string>可選參數,表示文件擴展名
- 返回:<string>表示路徑中的最后一部分
const path = require('path')// 定義文件的存放路徑
const fpath = '/a/b/c/index.html'const fullName = path.basename(fpath)
console.log(fullName)const nameWithoutExt = path.basename(fpath, '.html')
console.log(nameWithoutExt)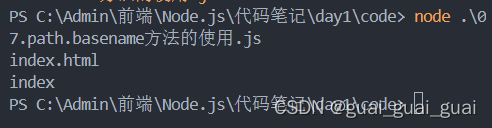
獲取路徑中的文件擴展名path.extname()
使用path.extname()方法,可以獲取路徑中的擴展名部分,語法格式如下:
path.extname(fpath)參數解讀:
- path<string>必選參數,表示一個路徑的字符串
- 返回:<string>返回得到的擴展名字符串
const path = require('path')// 這是文件的存放路徑
const fpath = '/a/b/c/index.html'const fext = path.extname(fpath)
console.log(fext)

綜合案例 - 時鐘案例
案例的實現步驟
-
創建兩個正則表達式,分別用來匹配<style>和<script>標簽
// 1.1 導入 fs 模塊
const fs = require('fs')
// 1.2 導入 path 模塊
const path = require('path')// 1.3 定義正則表達式,分別匹配 <style></style> 和 <script></script> 標簽
const regStyle = /<style>[\s\S]*<\/style>/ // /s/S表示匹配任意字符
const regScript = /<script>[\s\S]*<\/script>/-
使用fs模塊,讀取需要被處理的HTML文件
// 2.1 調用 fs.readFile() 方法讀取文件
fs.readFile(path.join(__dirname, '../素材/index.html'), 'utf8', function(err, dataStr) {// 2.2 讀取 HTML 文件失敗if (err) return console.log('讀取HTML文件失敗!' + err.message)// 2.3 讀取文件成功后,調用對應的三個方法,分別拆解出 css, js, html 文件resolveCSS(dataStr)resolveJS(dataStr)resolveHTML(dataStr)
})-
自定義resolveCSS方法,來寫入index.css樣式文件
// 3.1 定義處理 css 樣式的方法
function resolveCSS(htmlStr) {// 3.2 使用正則提取需要的內容const r1 = regStyle.exec(htmlStr)//選出匹配正則表達式內的字符串// 3.3 將提取出來的樣式字符串,進行字符串的 replace 替換操作const newCSS = r1[0].replace('<style>', '').replace('</style>', '')// 3.4 調用 fs.writeFile() 方法,將提取的樣式,寫入到 clock 目錄中 index.css 的文件里面fs.writeFile(path.join(__dirname, './clock/index.css'), newCSS, function(err) {if (err) return console.log('寫入 CSS 樣式失敗!' + err.message)console.log('寫入樣式文件成功!')})
}-
自定義resolveJS方法,來寫入index.js文件
// 4.1 定義處理 js 腳本的方法
function resolveJS(htmlStr) {// 4.2 通過正則,提取對應的 <script></script> 標簽內容const r2 = regScript.exec(htmlStr)// 4.3 將提取出來的內容,做進一步的處理const newJS = r2[0].replace('<script>', '').replace('</script>', '')// 4.4 將處理的結果,寫入到 clock 目錄中的 index.js 文件里面fs.writeFile(path.join(__dirname, './clock/index.js'), newJS, function(err) {if (err) return console.log('寫入 JavaScript 腳本失敗!' + err.message)console.log('寫入 JS 腳本成功!')})
}-
自定義resolveHTML方法,來寫入index.html文件
// 5.1 定義處理 HTML 結構的方法
function resolveHTML(htmlStr) {// 5.2 將字符串調用 replace 方法,把內嵌的 style 和 script 標簽,替換為外聯的 link 和 script 標簽const newHTML = htmlStr.replace(regStyle, '<link rel="stylesheet" href="./index.css" />').replace(regScript, '<script src="./index.js"></script>')// 5.3 寫入 index.html 這個文件fs.writeFile(path.join(__dirname, './clock/index.html'), newHTML, function(err) {if (err) return console.log('寫入 HTML 文件失敗!' + err.message)console.log('寫入 HTML 頁面成功!')})
}案例兩個注意點:
- fs.writeFile()方法只能用來創建文件,不能用來創建路徑
- 重復調用fs.write()寫入同一個文件,新寫入的內容會覆蓋之前的內容
http模塊
- 在網絡節點中,負責免費消費資源的電腦,叫做客戶端,負責對外提供網絡資源的電腦,叫做服務器
- http模塊是Node.js官方提供的、用來創建web服務器的模塊,通過http模塊提供的http.createServer()方法,就能方便的把一臺普通的電腦,變成一臺Web服務器,從而對外提供Web資源服務
如果希望使用http模塊創建Web服務器,則需要先導入它:
const http=require('http')進一步理解http模塊的作用
服務器和普通電腦的區別在于,服務器上安裝了web服務器軟件,例如:IIS,Apache等。通過安裝這些服務器軟件,就能把一臺普通的電腦變成一web服務器。
在Node.js中,我們不需要使用IIS,Apache等這些第三方服務器軟件,因為我們可以基于Node.js提供的http模塊,通過幾行簡單的代碼,就能輕松的手寫一個服務器軟件,從而對外提供web服務
服務器相關的概念
IP地址
IP地址就是互聯網上每臺計算機的唯一地址,因此IP地址具有唯一性,如果把“個人電腦”比作“一臺電話”,那么“IP地址“就相當于”電話號碼“,只有知道對方IP地址的前提下,才能與對應的電腦之間進行數據通信。
IP地址的格式:通常用”點分十進制“表示成(a,b,c,d)的形式,其中,abcd都是0~255之間的十進制整數,例如:用點分十進表示的IP地址(192.168.1.1)
注意:
- 互聯網中每臺Web服務器,都有自己的IP地址,在window中運行ping www.baidu.com命令,即可查看到百度服務器的IP地址
- 在開發期間,自己的電腦既是一臺服務器,也是一個客戶端,為了方便測試,可以在自己的瀏覽器中輸入127.0.0.1這個IP地址,就可以把自己的電腦當成一臺服務器進行訪問了
?域名和域名服務器
盡管IP地址能夠唯一地標記網絡上的計算機,但IP地址是一長串數字,不直觀,而且不便于記憶,于是人們又發明了另一套字符型地地址方案,即所謂的域名(Domain Name)地址
IP地址和域名是一一對應關系,這份對應關系存放在一種叫做域名服務器(DNS,Domain name server)的電腦中。使用時只需通過好記的域名訪問對應的服務器即可,對應的轉換工作由域名服務器實現,因此,域名服務器就是提供IP地址和域名之間的轉換服務的服務器
注意:
- 單純使用IP地址,互聯網中的電腦也能夠正常工作。但是有了域名的加持,能讓互聯網的世界變得更加方便
- 在開發測試期間,127.0.0.1對應的域名是localhost,它們都代表我們自己的電腦,在使用效果上沒有任何區別
端口號
計算機中的端口號,就好像是現實生活中的門牌號一樣,通過門牌號,外賣小哥可以在整棟大樓眾多的房間中,準確的把外賣送到你的手中
同樣的道理,在一臺電腦中,可以運行成百上千web服務,每個web服務都對應唯一的端口號,客戶端發送過來的網絡請求,通過端口號可以被準確地交給對應的web服務進行處理
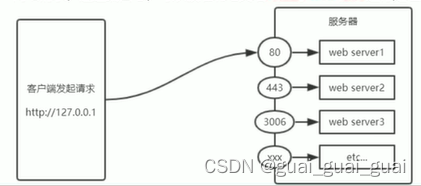
注意:
- 每個端口號不能同時被多個服務器所占用
- 在實際應用中,URL中的80端口可以被省略
創建基本的web服務器
創建web服務器的基本步驟
-
導入http模塊
如果希望在自己的電腦上創建一個web服務器,從而對外提供web服務,則需要導入http模塊:
const http=require('http')-
創建web服務器實例
調用http.creatServer()方法,即可快速創建一個web服務器實例:
const server=http.creatServer()-
為服務器實例綁定request事件,監聽客戶端的請求
為服務器實例綁定request事件,即可監聽客戶端發送過來的網絡請求
server.on('request', function (req, res) {console.log('Someone visit our web server.')
})-
啟動服務器
調用服務器實例的.listen()方法,即可啟動當前的web服務器實例
server.listen(8080, function () { console.log('server running at http://127.0.0.1:8080')
})// 1. 導入 http 模塊
const http = require('http')
// 2. 創建 web 服務器實例
const server = http.createServer()
// 3. 為服務器實例綁定 request 事件,監聽客戶端的請求
server.on('request', function (req, res) {console.log('Someone visit our web server.')
})
// 4. 啟動服務器
server.listen(80, function () { console.log('server running at http://127.0.0.1:8080')
})req請求對象
只要服務器接收到了客戶端的請求,就會調用通過server.on()為服務器綁定的request事件處理函數
如果想在事件處理函數中,訪問與客戶端相關的數據或屬性,可以使用如下方式:
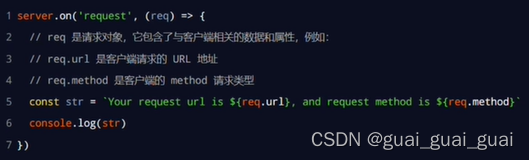
res響應對象
在服務器的request事件處理函數中,如果想訪問與服務器相關的數據或屬性,可以使用如下的方式

const http = require('http')
const server = http.createServer()
// req 是請求對象,包含了與客戶端相關的數據和屬性
server.on('request', (req, res) => {// req.url 是客戶端請求的 URL 地址const url = req.url// req.method 是客戶端請求的 method 類型const method = req.methodconst str = `Your request url is ${url}, and request method is ${method}`console.log(str)// 調用 res.end() 方法,向客戶端響應一些內容res.end(str)
})
server.listen(80, () => {console.log('server running at http://127.0.0.1')
})解決中文亂碼問題
當調用res.end()方法,向客戶端發送中文內容的時候,會出現亂碼問題,此時,需要手動設置內容的編碼格式
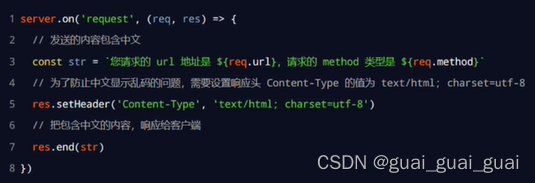
const http = require('http')
const server = http.createServer()server.on('request', (req, res) => {// 定義一個字符串,包含中文的內容const str = `您請求的 URL 地址是 ${req.url},請求的 method 類型為 ${req.method}`// 調用 res.setHeader() 方法,設置 Content-Type 響應頭,解決中文亂碼的問題res.setHeader('Content-Type', 'text/html; charset=utf-8')// res.end() 將內容響應給客戶端res.end(str)
})server.listen(80, () => {console.log('server running at http://127.0.0.1')
})
根據不同的url響應不同的html內容
核心實現步驟
- 獲取請求的url地址
- 設置默認的響應內容為404 Not found
- 判斷用戶請求的是否為/或/index.html首頁
- 判斷用戶請求的是否為/about.html關于頁面
- 設置Content-Type響應頭,防止中文亂碼
- 使用res.end()把內容響應給客戶端
動態響應內容
const http = require('http')
const server = http.createServer()server.on('request', (req, res) => {// 1. 獲取請求的 url 地址const url = req.url// 2. 設置默認的響應內容為 404 Not foundlet content = '<h1>404 Not found!</h1>'// 3. 判斷用戶請求的是否為 / 或 /index.html 首頁// 4. 判斷用戶請求的是否為 /about.html 關于頁面if (url === '/' || url === '/index.html') {content = '<h1>首頁</h1>'} else if (url === '/about.html') {content = '<h1>關于頁面</h1>'}// 5. 設置 Content-Type 響應頭,防止中文亂碼res.setHeader('Content-Type', 'text/html; charset=utf-8')// 6. 使用 res.end() 把內容響應給客戶端res.end(content)
})server.listen(80, () => {console.log('server running at http://127.0.0.1')
})
案例 - 實現clock時鐘的web服務器
核心思路:
把文件的實際存放路徑,作為每個資源請求的url地址
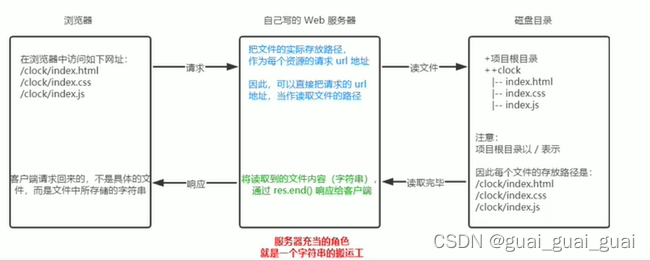
實現步驟:
-
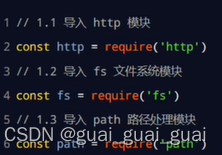
導入需要的模塊
-
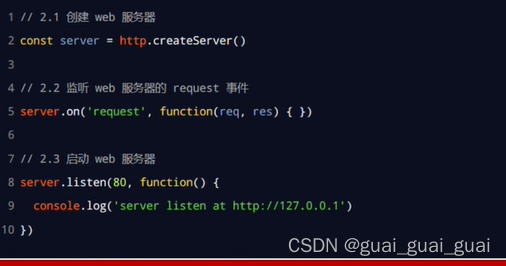
創建基本的web服務器
-
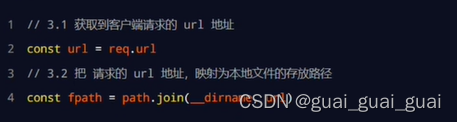
將資源的請求url地址映射為文件的存放路徑
-
讀取文件內容并響應給客戶端

-
優化資源的請求路徑

// 1.1 導入 http 模塊
const http = require('http')
// 1.2 導入 fs 模塊
const fs = require('fs')
// 1.3 導入 path 模塊
const path = require('path')// 2.1 創建 web 服務器
const server = http.createServer()
// 2.2 監聽 web 服務器的 request 事件
server.on('request', (req, res) => {// 3.1 獲取到客戶端請求的 URL 地址// /clock/index.html// /clock/index.css// /clock/index.jsconst url = req.url// 3.2 把請求的 URL 地址映射為具體文件的存放路徑// const fpath = path.join(__dirname, url)// 5.1 預定義一個空白的文件存放路徑let fpath = ''if (url === '/') {fpath = path.join(__dirname, './clock/index.html')} else {// /index.html// /index.css// /index.jsfpath = path.join(__dirname, '/clock', url)}// 4.1 根據“映射”過來的文件路徑讀取文件的內容fs.readFile(fpath, 'utf8', (err, dataStr) => {// 4.2 讀取失敗,向客戶端響應固定的“錯誤消息”if (err) return res.end('404 Not found.')// 4.3 讀取成功,將讀取成功的內容,響應給客戶端res.end(dataStr)})
})
// 2.3 啟動服務器
server.listen(80, () => {console.log('server running at http://127.0.0.1')
})
模塊化
模塊化是指解決一個復雜問題時,自頂向下逐層把系統劃分成若干模塊的過程,對于整個系統來說,模塊是可組合,分解和更換的單元
編程領域中的模塊化
編程領域中的模塊化就是遵守固定的規則,把一個大文件拆成獨立并且相互依賴的多個小模塊
把代碼進行模塊化拆分的好處:
- 提高了代碼的復用性
- 提高了代碼的可維護性
- 可以實現按需加載
模塊化規范
模塊化規范就是對代碼進行模塊化的拆分與組合時,需要遵守的那些規則
例如:
- 使用什么樣的語法格式來引用模塊
- 在模塊中使用什么樣的語法格式向外暴露成員
模塊化規范的好處:大家都遵守同樣的模塊化規范寫代碼,降低了溝通的成本,極大的方便了各個模塊之間的相互調用,利人利己
Node.js中模塊的分類
Node.js中根據2模塊來源的不同,將模塊分為3大類,分別是:
- 內置模塊(內置模塊是由Node.js官方提供的,例如fs,path,http等)
- 自定義模塊(用戶創建的每個js文件,都是自定義模塊)
- 第三方模塊(由第三方開發出來的模塊,并非官方提供的內置模塊,也不是用戶創建的自定義模塊,使用前需要先下載)
加載模塊
使用強大的require()方法,可以加載需要的內置模塊,用戶自定義模塊,第三方模塊進行使用。例如

注意:使用require()方法加載其他模塊時,會執行被加載模塊中的代碼

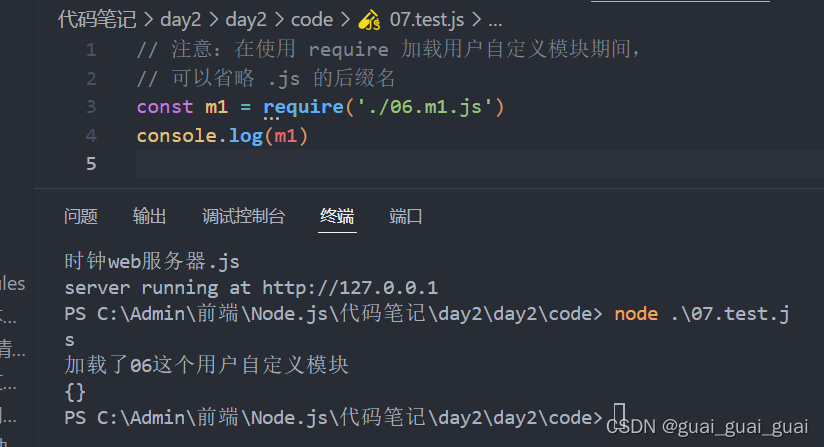
Node.js中的模塊作用域
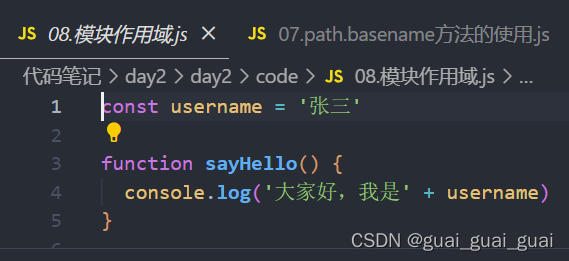
模塊作用域和函數作用域類似,在自定義模塊中定義的變量、方法等成員,只能在當前模塊內被訪問,這種模塊級別的訪問限制,叫做模塊作用域
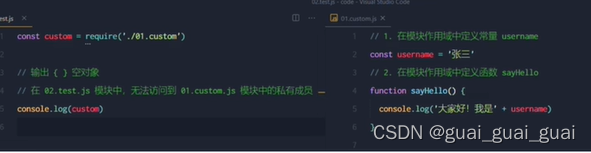
模塊作用域的好處
防止了全局變量污染的問題
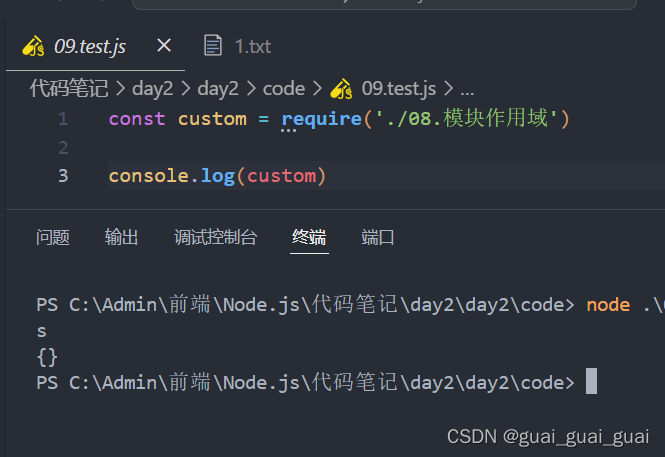
在09中引入08,發下輸出custom為空對象,說明不同模塊之間變量不可相互訪問
?向外共享模塊作用域中的成員
module對象
每個.js自定義模塊中都有一個module對象,他里面存儲了和當前模塊有關的信息。打印如下:
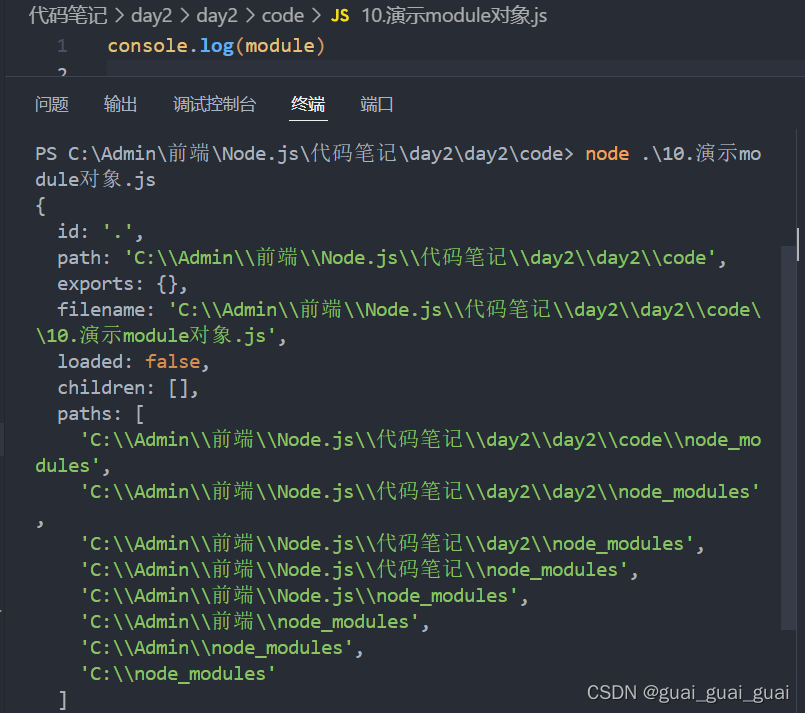
?module.exports對象
在自定義模塊中,可以使用module.exports對象,將模塊內的成員共享出去,供外界使用
外界用require()方法導入自定義模塊時,得到的就是mojule.exports所指向的對象
共享require()方法導入模塊時,導入的 結果,永遠以module.exports指向的對象為準
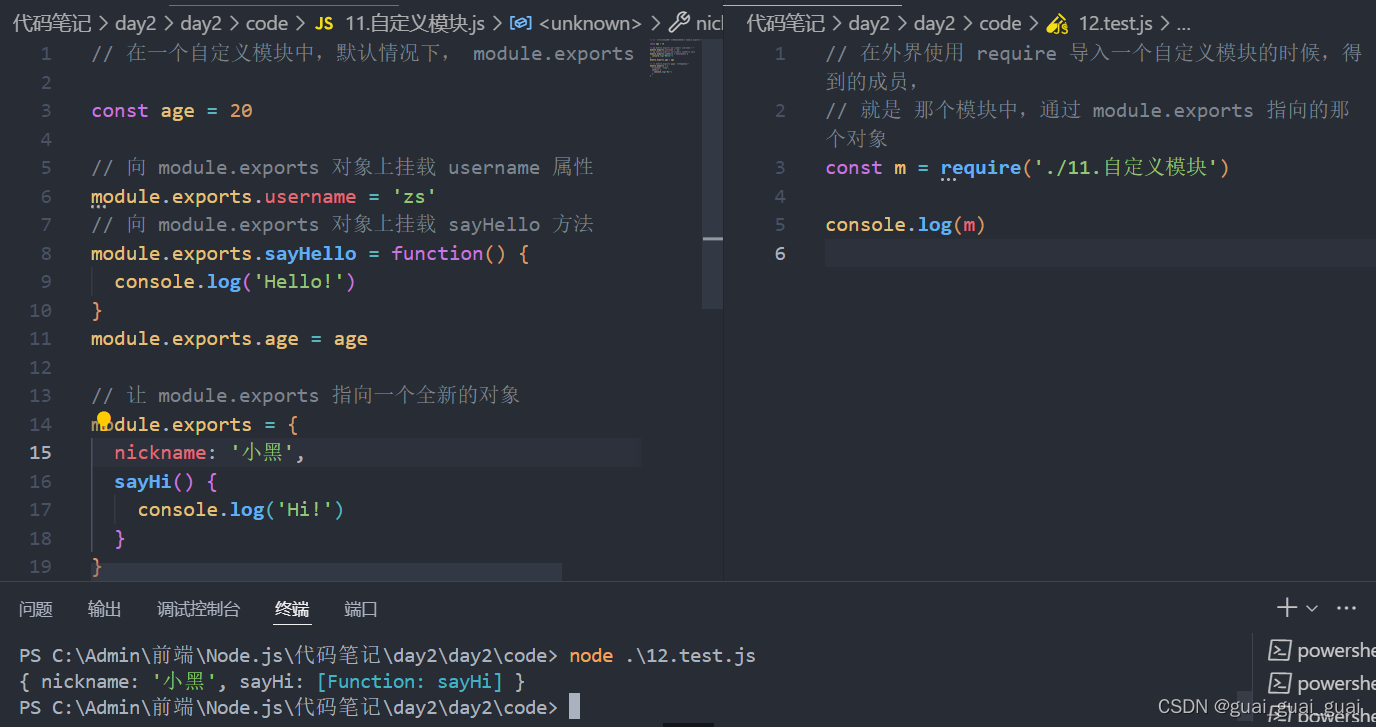 ?exports對象
?exports對象
由于module.exports單詞寫起來比較復雜,為了簡化向外共享成員的代碼,Node提供了exports對象,默認情況下,exports和module.exports指向同一個對象,最終共享的結果,還是以module.exportos指向的對象為準。

exports和module.exports的使用誤區
時刻謹記,require()模塊時,得到的永遠是module.exports指向的對象,exports原本是和module.exports指向的地址相同,但若給exports重新賦值,則exports會指向一個新的對象,但是module.exports指向的地址不變,內容也不變,require引入的時候,可以將module.exports中的內容引入,而exports指向的新對象則不hi引入,凡是給exports重新賦值,都會指向一個新的對象
注意:為了防止混亂,建議不要在同一個模塊中同時使用exports和module.exports
Node.js中的模塊化規范
Node.js遵循了CommonJS模塊化規范,CommonJS規定了模塊的特性和各模塊之間如何相互依賴
CommonJS規定:
- 每個模塊內部,module變量代表當前模塊
- module變量是一個對象,它的exports屬性(即module.exports)是對外的接口
- 加載某個模塊,其實是加載該模塊的module.exports屬性,require()方法用于加載模塊
包
Node.js中的第三方模塊又叫做包
就像電腦和計算機指的是相同的東西,第三方模塊和包指的是同一個概念,只不過叫法不同
?包的來源
不同于Node.js中的內置模塊與自定義模塊,包是由第三方個人或團隊開發出來的,免費供所有人使用
注意:Node.js中的包都是免費且開源的,不需要付費就可免費下載使用
為什么需要包
由于Node.js的內置模塊僅提供了一些底層的API,導致在基于內置模塊進行項目開發時,效率很低
包是基于內置模塊封裝出來的,提供了更高級、更方便的API,極大的提高了開發效率
包和內置模塊之間的關系,類似于jQuery和瀏覽器內置API之間的關系
從哪里下載包
國外有一家IT公司,叫做npm,lnc.這家公司旗下有一個非常著名的網站:http://www.npmjs.com/,它是全球最大的包共享平臺,你可以從這個網站上搜索到任何你需要的包,只要你有足夠的耐心
npm,lnc.公司提供了一個地址為https://registry.npmjs.org/的服務器,來對外共享所有的包,我們可以從這個服務器上下載自己所需的包.
注意:
從http://www.npmjs.com/網站上搜索自己需要的包
從https://registry.npmjs.org/服務器上下載自己需要的包
包的分類
項目包
那些被安裝到項目的node_modules目錄中的包,都是項目包
項目包又分為兩類,分別是:
開發依賴包(被記錄到devDependencies節點中的包,只在開發期間會用到)
核心依賴包(被記錄到dependencies節點中的包,在開發期間和項目上線之后都會用到)

全局包
在執行npm install命令時,如果提供了-g參數 則會把包安裝為全局包
全局包會被安裝到C:\Users\用戶日錄AppData\Roaming\npm\node modules目錄下

注意:
- 只有工具性質的包,才有全局安裝的必要性,因為它們提供了好用的終端命令
- 判斷某個包是否需要全局安裝后才能使用,可以參考官方提供的使用說明即可
i5ting_toc
i5ting_toc是一個可以把md文檔轉為html頁面的小工具,使用步驟如下:
規范包的結構
一個規范的包,它的組成結構,必須符合以下三點要求:
- 包必須以單獨的目錄存在
- 包的頂級目錄下要必須包含package.json這個包管理配置文件
- package.json中必須包含name,version,main這三個屬性,分別代表包的名字,版本號,包的入口
?初始化package.json

name:包的名字,名字唯一,不可重復
version:包的版本號
main:指定包的入口文件,外界resquire導入包導入的就是main屬性所指向的文件
description:包的簡短的描述信息,指出包的功能
keywords:數組,里面包含了檢索的字符串
license:開源許可協議
{"name": "itheima-tools","version": "1.1.0","main": "index.js","description": "提供了格式化時間、HTMLEscape相關的功能","keywords": ["itheima","dateFormat","escape"],"license": "ISC"
}定義格式化時間的方法
function dateFormat(dateStr) {const dt = new Date(dateStr)const y = dt.getFullYear()const m = padZero(dt.getMonth() + 1)const d = padZero(dt.getDate())const hh = padZero(dt.getHours())const mm = padZero(dt.getMinutes())const ss = padZero(dt.getSeconds())return `${y}-${m}-${d} ${hh}:${mm}:${ss}`
}
/ 定義一個補零的函數
function padZero(n) {return n > 9 ? n : '0' + n
}module.exports = {dateFormat
}當require只引入一個文件夾時,會先檢查文件夾里面是不是有package.json,會尋找其屬性main,自動導入main里包含的文件
在index.js中定義轉義HTML的方法
// 定義轉義 HTML 字符的函數
function htmlEscape(htmlstr) {return htmlstr.replace(/<|>|"|&/g, match => {//正則表達式< > " &均符合條件 match即為匹配成功的字符switch (match) {case '<':return '<'case '>':return '>'case '"':return '"'case '&':return '&'}})
}// 定義還原 HTML 字符串的函數
function htmlUnEscape(str) {return str.replace(/<|>|"|&/g, match => {switch (match) {case '<':return '<'case '>':return '>'case '"':return '"'case '&':return '&'}})
}module.exports = {htmlEscape,htmlUnEscape
}
將不同的功能進行模塊劃分
- 將格式化時間的功能,拆分到src->dateFormat.js中
- 將處理HTML字符串的功能,拆分到src->htmlEcape.js中
- 在index.js中,導入兩個模塊,得到所需要向外共享的方法
- 在index.js中,使用module.exports把對應的方法共享出去
htmlEscape.js
// 定義轉義 HTML 字符的函數
function htmlEscape(htmlstr) {return htmlstr.replace(/<|>|"|&/g, match => {//正則表達式< > " &均符合條件 match即為匹配成功的字符switch (match) {case '<':return '<'case '>':return '>'case '"':return '"'case '&':return '&'}})
}// 定義還原 HTML 字符串的函數
function htmlUnEscape(str) {return str.replace(/<|>|"|&/g, match => {switch (match) {case '<':return '<'case '>':return '>'case '"':return '"'case '&':return '&'}})
}module.exports = {htmlEscape,htmlUnEscape
}
dateFormat.js
// 定義格式化時間的函數
function dateFormat(dateStr) {const dt = new Date(dateStr)const y = dt.getFullYear()const m = padZero(dt.getMonth() + 1)const d = padZero(dt.getDate())const hh = padZero(dt.getHours())const mm = padZero(dt.getMinutes())const ss = padZero(dt.getSeconds())return `${y}-${m}-${d} ${hh}:${mm}:${ss}`
}// 定義一個補零的函數
function padZero(n) {return n > 9 ? n : '0' + n
}module.exports = {dateFormat
}
index.js
// 這是包的入口文件const date = require('./src/dateFormat')
const escape = require('./src/htmlEscape')// 向外暴露需要的成員
module.exports = {...date,//將date中所有的屬性均掛載到這個對象上...escape
}
編寫包的說明文檔
- 包根目錄中的README.md文件,是包的說明文檔,通過它,我們可以事先把包的使用說明,以markdown的格式寫出來,方便用戶參考
- README文件中具體寫什么內容,沒有強制性的要求,只要能夠清晰的把包的作用,用法,注意事項等描述清楚即可
- 我們所創建的這個包的README.md文檔中,會包含以下6項內容:
- 安裝方式,導入方式,格式化時間,轉義HTML中的特殊字符,還原HTML中的特殊字符、開源協議
## 安裝
```
npm install itheima-tools
```## 導入
```js
const itheima = require('itheima-tools')
```## 格式化時間
```js
// 調用 dateFormat 對時間進行格式化
const dtStr = itheima.dateFormat(new Date())
// 結果 2020-04-03 17:20:58
console.log(dtStr)
```## 轉義 HTML 中的特殊字符
```js
// 帶轉換的 HTML 字符串
const htmlStr = '<h1 title="abc">這是h1標簽<span>123 </span></h1>'
// 調用 htmlEscape 方法進行轉換
const str = itheima.htmlEscape(htmlStr)
// 轉換的結果 <h1 title="abc">這是h1標簽<span>123&nbsp;</span></h1>
console.log(str)
```## 還原 HTML 中的特殊字符
```js
// 待還原的 HTML 字符串
const str2 = itheima.htmlUnEscape(str)
// 輸出的結果 <h1 title="abc">這是h1標簽<span>123 </span></h1>
console.log(str2)
```## 開源協議
ISC發布包
具體詳見08.發布包-把包發布到npm_嗶哩嗶哩_bilibili
模塊的加載機制
優先從緩存中加載
模塊在第一次加載后會被緩存,這也意味著多次調用require()不會導致模塊的代碼被執行多次
注意:不論是內置模塊,用戶自定義模塊,還是第三方模塊,他們都會優先從緩存中加載,從而提高模塊的加載效率
內置模塊的加載機制
內置模塊是由Node.js官方提供的模塊,內置模塊的加載優先級最高
例如,require('fs')始終返回內置的fs模塊,即使在node_modules目錄名下有名字相同的包(第三方模塊)也叫做fs
自定義模塊的加載機制
使用require()加載自定義模塊時,必須指定以./或../開頭的路徑標識符,在加載自定義模塊時,如果沒有指定./或../這樣的路徑標識符,則node會把它當作內置模塊或第三方模塊進行加載
同時,在使用require()導入自定義模塊時,如果省略了文件的擴展名,則Node.js會按照順序分別嘗試以下的文件:
- 按照確切的文件名進行加載
- 補全.js擴展名進行加載
- 補全.json擴展名進行加載
- 補全.node擴展名進行加載
- 加載失敗,終端報錯
第三方模塊的加載機制
如果傳遞給 require0 的模塊標識符不是一個內置模塊,也沒有以./或../開頭則Node.js 會從當前模塊的父級目錄開始,嘗試從/node_modules 文件夾中加載第三方模塊
如果沒有找到對應的第三方模塊,則移動到再上一層父目錄中,進行加載,直到文件系統的根目錄
例如,假設在C:\Users\itheimaproject foo,js' 文件里調用了 require(tools),則 Nodejs 會按以下順序查找:
C:\Users\itheima\project\node modules\tools
C: \Users\itheima\node\modules\tools
C: \Users\node\modules\tools
C: \node\modules\tools
目錄作為模塊
當把目錄作為模塊標識符,傳遞給require()進行加載的時候,有三種加載方式:
- 在被加載的目錄下查找一個叫做package.json的文件,并尋找main屬性,作為require()加載的入口
- 如果目錄里沒有package.json文件,或者main入口不存在或無法解析,則Node.js將會試圖加載目錄下的index.js文件
- 如果以上兩步都失敗了,則Node.js會在終端打印錯誤信息,報告模塊的缺失:Error:Cannot find module 'xxx'

)


)

)












和元組(Tuple)—— clickhouse 基礎篇(二))