前言
就一直向前走吧,沿途的花終將綻放~
題目:打折日期交叉問題
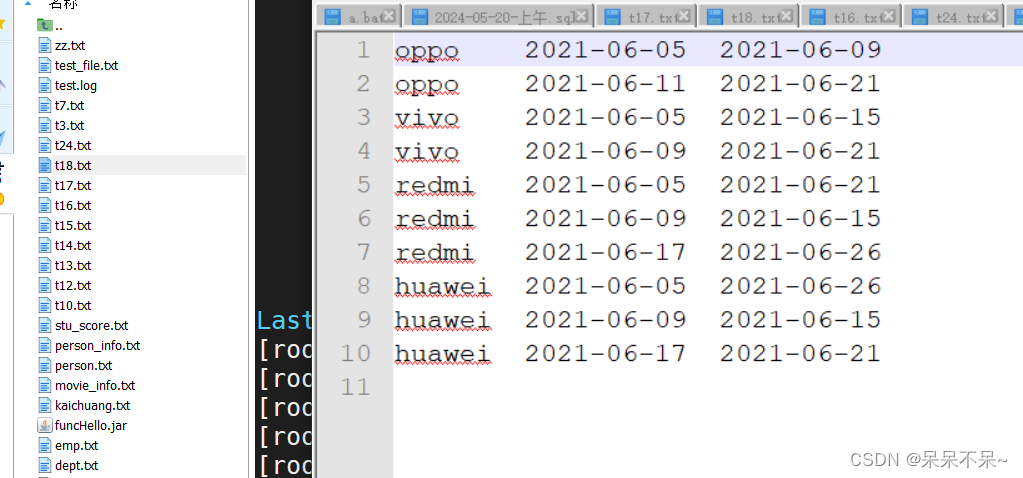
如下為平臺商品促銷數據:字段為品牌,打折開始日期,打折結束日期
brand stt edt
oppo,2021-06-05,2021-06-09
oppo,2021-06-11,2021-06-21
vivo,2021-06-05,2021-06-15
vivo,2021-06-09,2021-06-21
redmi,2021-06-05,2021-06-21
redmi,2021-06-09,2021-06-15
redmi,2021-06-17,2021-06-26
huawei,2021-06-05,2021-06-26
huawei,2021-06-09,2021-06-15
huawei,2021-06-17,2021-06-21計算每個品牌總的打折銷售天數,注意其中的交叉日期,比如 vivo 品牌,
第一次活動時間為 2021-06-05 到 2021-06-15,第二次活動時間為 2021-06-09 到 2021-06-21 其中 9 號到 15號為重復天數,
只統計一次,即 vivo 總打折天數為 2021-06-05 到 2021-06-21 共計 17 天。建表:
數據準備:
create table t18(brand string,stt string,edt string
)row format delimited fields terminated by '\t';
load data local inpath '/opt/data/t18.txt' overwrite into table t18;需求實現:
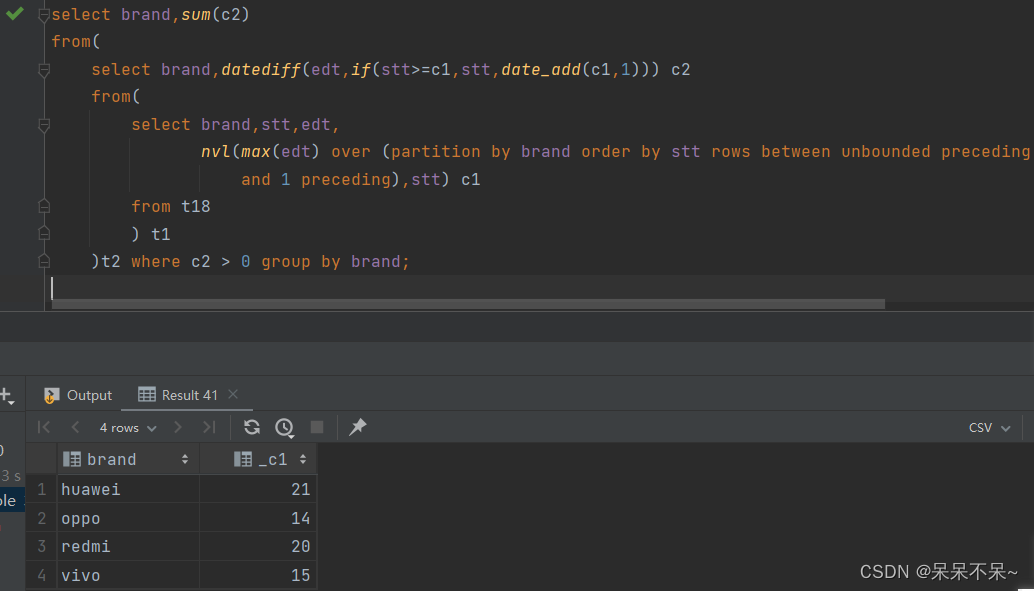
select brand,sum(c2)
from(select brand,datediff(edt,if(stt>=c1,stt,date_add(c1,1))) c2from(select brand,stt,edt,nvl(max(edt) over (partition by brand order by stt rows between unbounded precedingand 1 preceding),stt) c1from t18) t1)t2 where c2 > 0 group by brand;?hsql語句分析:
最內層查詢(子查詢t1):
- 從
t18表中選擇brand、stt和edt。- 使用窗口函數
MAX(edt) OVER (...)計算每個品牌下,按stt排序的每個行之前的最大edt值。這個窗口的范圍是從所有之前的行(unbounded preceding)到當前行之前的那一行(1 preceding)。- 如果當前行的
stt大于或等于這個計算出的最大edt(即c1),那么使用stt作為c1的值,否則使用c1的次日(date_add(c1, 1))。這是為了確保c1總是小于或等于當前行的stt,從而避免負的持續時間。- 使用
nvl函數(這通常是Oracle數據庫中的函數,用于處理NULL值,但在其他數據庫中可能是COALESCE或類似的函數)來處理可能的NULL值。如果窗口函數沒有返回任何行(即對于每個品牌的第一行),則c1將默認為stt。中間層查詢(子查詢t2):
- 基于最內層查詢的結果,計算每個事件或時間段的持續時間
c2。這是通過計算edt和c1之間的日期差來實現的(datediff(edt, c1))。- 需要注意的是,由于在最內層查詢中已經確保了
c1總是小于或等于stt,所以這里計算出的c2應該總是非負的或零。最外層查詢:
- 從中間層查詢中選擇
brand和持續時間c2的總和。- 使用
WHERE子句過濾掉持續時間為0的情況(雖然根據前面的邏輯,這種情況應該已經不存在了,但這里可能是為了額外的明確性)。- 使用
GROUP BY子句按brand分組,以便為每個品牌計算總的持續時間。
結果輸出:






和元組(Tuple)—— clickhouse 基礎篇(二))




)







