什么是注意力機制
注意力機制的核心重點就是讓網絡關注到它更需要關注的地方。
當我們使用卷積神經網絡去處理圖片的時候,我們會更希望卷積神經網絡去注意應該注意的地方,而不是什么都關注,我們不可能手動去調節需要注意的地方,這個時候,如何讓卷積神經網絡去自適應的注意重要的物體變得極為重要。
注意力機制就是實現網絡自適應注意的一個方式。
注意力機制可以分為通道注意力機制,空間注意力機制,以及二者的結合。
通道注意力機制關注的是某些重要的通道,空間注意力機制關注的是圖片中某些重要的區域。
注意力機制的實現方式
在深度學習中,常見的注意力機制的實現方式有SENet,CBAM,ECA等等。
1.SENet的實現
SENet是通道注意力機制的典型實現。
對于輸入進來的特征層,我們關注其每一個通道的權重,對于SENet而言,其重點是獲得輸入進來的特征層,每一個通道的權值。利用SENet,我們可以讓網絡關注它最需要關注的通道。
其具體實現方式就是:
1、對輸入進來的特征層進行全局平均池化。
2、然后進行兩次全連接,第一次全連接神經元個數較少,第二次全連接神經元個數和輸入特征層相同。
3、在完成兩次全連接后,我們再取一次Sigmoid將值固定到0-1之間,此時我們獲得了輸入特征層每一個通道的權值(0-1之間)。
4、在獲得這個權值后,我們將這個權值乘上原輸入特征層即可。
實現代碼:
def se_block(input_feature, ratio=16, name=""):channel = input_feature._keras_shape[-1]se_feature = GlobalAveragePooling2D()(input_feature)se_feature = Reshape((1, 1, channel))(se_feature)se_feature = Dense(channel // ratio,activation='relu',kernel_initializer='he_normal',use_bias=False,bias_initializer='zeros',name = "se_block_one_"+str(name))(se_feature)se_feature = Dense(channel,kernel_initializer='he_normal',use_bias=False,bias_initializer='zeros',name = "se_block_two_"+str(name))(se_feature)se_feature = Activation('sigmoid')(se_feature)se_feature = multiply([input_feature, se_feature])return se_feature2.CBAM的實現
CBAM將通道注意力機制和空間注意力機制進行一個結合,相比于SENet只關注通道的注意力機制可以取得更好的效果。CBAM會對輸入進來的特征層,分別進行通道注意力機制的處理和空間注意力機制的處理。
通道注意力機制的實現可以分為兩個部分,我們會對輸入進來的單個特征層,分別進行全局平均池化和全局最大池化。之后對平均池化和最大池化的結果,利用共享的全連接層進行處理,我們會對處理后的兩個結果進行相加,然后取一個sigmoid,此時我們獲得了輸入特征層每一個通道的權值(0-1之間)。在獲得這個權值后,我們將這個權值乘上原輸入特征層即可。
空間注意力機制的實現:我們會對輸入進來的特征層,在每一個特征點的通道上取最大值和平均值。之后將這兩個結果進行一個堆疊,利用一次通道數為1的卷積調整通道數,然后取一個sigmoid,此時我們獲得了輸入特征層每一個特征點的權值(0-1之間)。在獲得這個權值后,我們將這個權值乘上原輸入特征層即可。
實現代碼如下:
def channel_attention(input_feature, ratio=8, name=""):channel = input_feature._keras_shape[-1]shared_layer_one = Dense(channel//ratio,activation='relu',kernel_initializer='he_normal',use_bias=False,bias_initializer='zeros',name = "channel_attention_shared_one_"+str(name))shared_layer_two = Dense(channel,kernel_initializer='he_normal',use_bias=False,bias_initializer='zeros',name = "channel_attention_shared_two_"+str(name))avg_pool = GlobalAveragePooling2D()(input_feature) max_pool = GlobalMaxPooling2D()(input_feature)avg_pool = Reshape((1,1,channel))(avg_pool)max_pool = Reshape((1,1,channel))(max_pool)avg_pool = shared_layer_one(avg_pool)max_pool = shared_layer_one(max_pool)avg_pool = shared_layer_two(avg_pool)max_pool = shared_layer_two(max_pool)cbam_feature = Add()([avg_pool,max_pool])cbam_feature = Activation('sigmoid')(cbam_feature)return multiply([input_feature, cbam_feature])def spatial_attention(input_feature, name=""):kernel_size = 7cbam_feature = input_featureavg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)concat = Concatenate(axis=3)([avg_pool, max_pool])cbam_feature = Conv2D(filters = 1,kernel_size=kernel_size,strides=1,padding='same',kernel_initializer='he_normal',use_bias=False,name = "spatial_attention_"+str(name))(concat) cbam_feature = Activation('sigmoid')(cbam_feature)return multiply([input_feature, cbam_feature])def cbam_block(cbam_feature, ratio=8, name=""):cbam_feature = channel_attention(cbam_feature, ratio, name=name)cbam_feature = spatial_attention(cbam_feature, name=name)return cbam_feature3、ECA的實現
ECANet是也是通道注意力機制的一種實現形式。ECANet可以看作是SENet的改進版。
ECANet的作者認為SENet對通道注意力機制的預測帶來了副作用,捕獲所有通道的依賴關系是低效并且是不必要的。
ECA模塊的思想是非常簡單的,它去除了原來SE模塊中的全連接層,直接在全局平均池化之后的特征上通過一個1D卷積進行學習。
既然使用到了1D卷積,那么1D卷積的卷積核大小的選擇就變得非常重要了,了解過卷積原理的同學很快就可以明白,1D卷積的卷積核大小會影響注意力機制每個權重的計算要考慮的通道數量。
實現代碼如下:
def eca_block(input_feature, b=1, gamma=2, name=""):channel = input_feature._keras_shape[-1]kernel_size = int(abs((math.log(channel, 2) + b) / gamma))kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1avg_pool = GlobalAveragePooling2D()(input_feature)x = Reshape((-1,1))(avg_pool)x = Conv1D(1, kernel_size=kernel_size, padding="same", name = "eca_layer_"+str(name), use_bias=False,)(x)x = Activation('sigmoid')(x)x = Reshape((1, 1, -1))(x)output = multiply([input_feature,x])return output開始應用:將注意力機制加入到YOLOv8中
1.找到conv.py文件
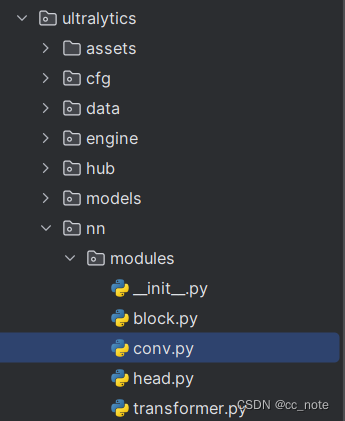
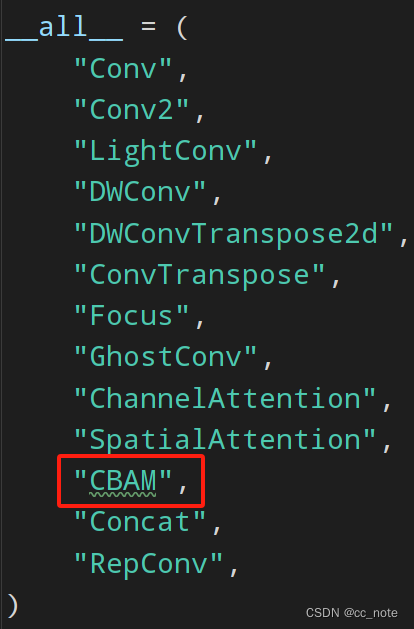
2.在conv.py中添加名字
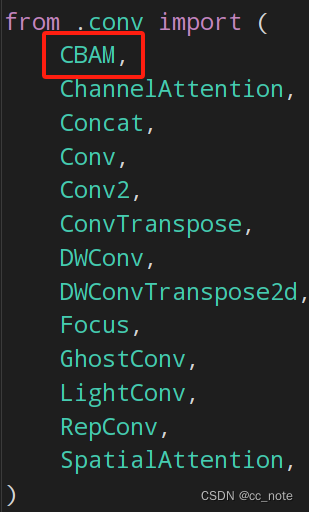
3.在__init__.py中添加名字

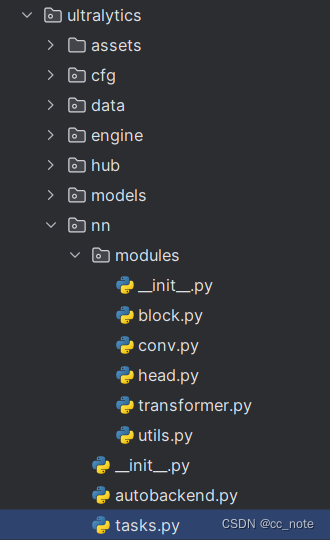
4.在tasks.py文件中添加名字

5.在tasks.py中添加配置
在該函數中添加代碼

添加的代碼為:
elif m in {CBAM}:c1, c2 = ch[f], args[0]if c2 != nc:c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, *args[1:]]添加后的為:
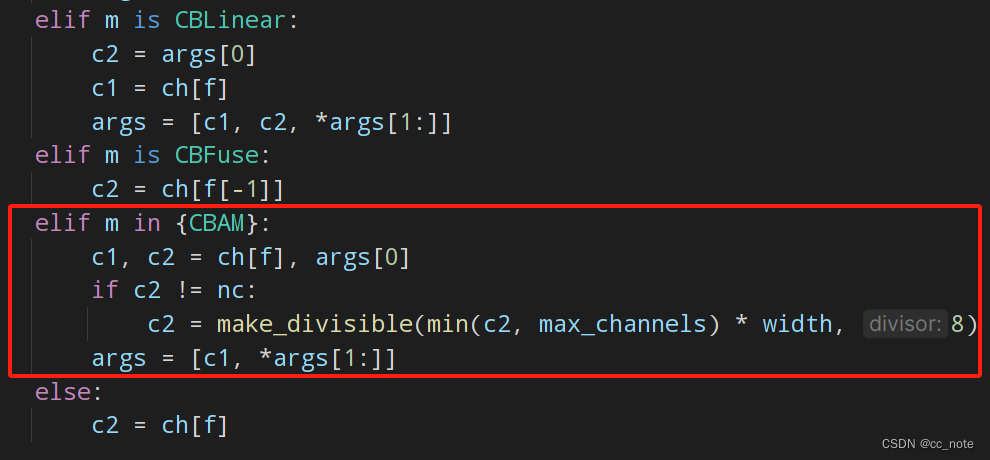
6.打開yaml文件
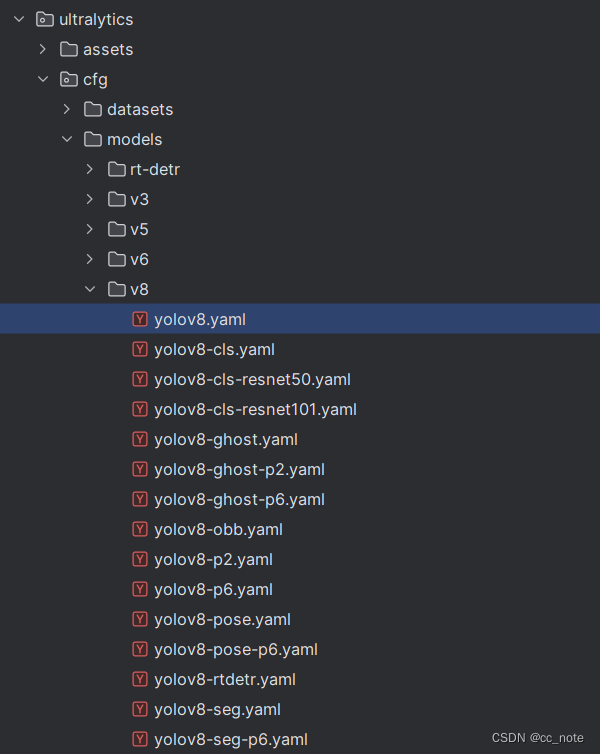
7.盡量不要在這個文件中更改內容,我們可以自己創建一個yaml文件(my_yolov8_CBAM.yaml),然后將yolov8.yaml中的內容復制過來
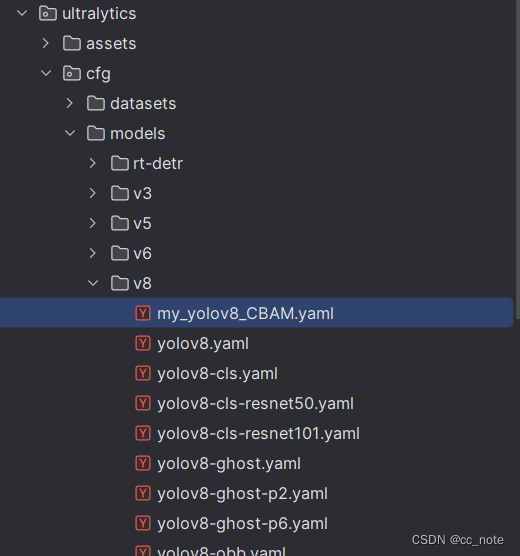
8.在backbone中進行修改
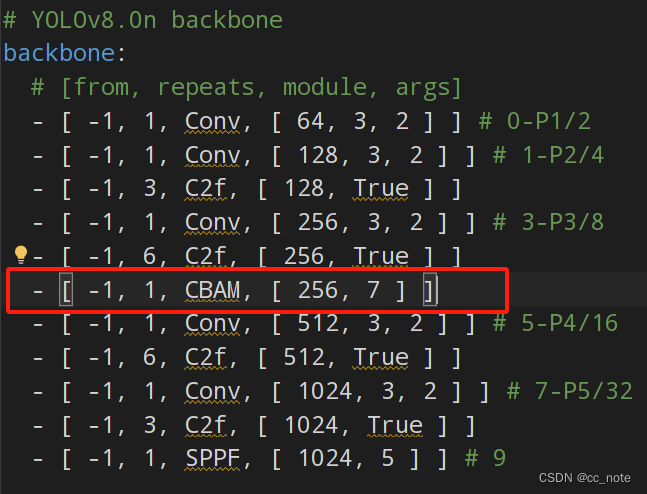
from列中的-1表示應用上一層的參數、repeats列表示重復多少次、module列表示模型的名字、args列表示參數,
9.第八點操作添加完后層數會改變,head部分需要進行相應的修改
修改前:
# YOLOv8.0n head
head:- [ -1, 1, nn.Upsample, [ None, 2, "nearest" ] ]- [ [ -1, 6 ], 1, Concat, [ 1 ] ] # cat backbone P4- [ -1, 3, C2f, [ 512 ] ] # 12- [ -1, 1, nn.Upsample, [ None, 2, "nearest" ] ]- [ [ -1, 4 ], 1, Concat, [ 1 ] ] # cat backbone P3- [ -1, 3, C2f, [ 256 ] ] # 15 (P3/8-small)- [ -1, 1, Conv, [ 256, 3, 2 ] ]- [ [ -1, 12 ], 1, Concat, [ 1 ] ] # cat head P4- [ -1, 3, C2f, [ 512 ] ] # 18 (P4/16-medium)- [ -1, 1, Conv, [ 512, 3, 2 ] ]- [ [ -1, 9 ], 1, Concat, [ 1 ] ] # cat head P5- [ -1, 3, C2f, [ 1024 ] ] # 21 (P5/32-large)- [ [ 15, 18, 21 ], 1, Detect, [ nc ] ] # Detect(P3, P4, P5)修改后:
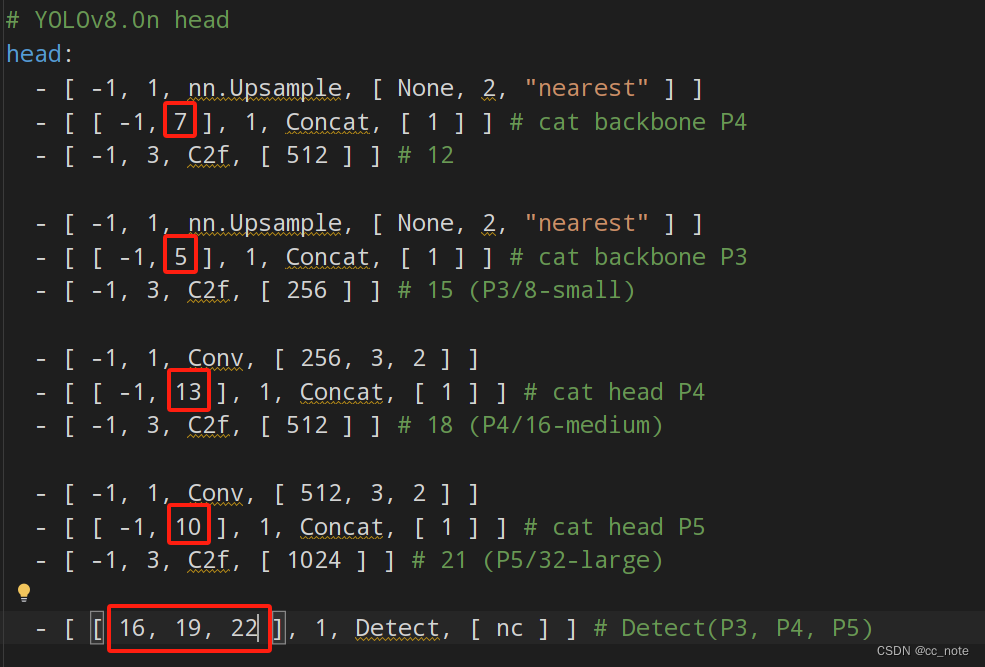
為什么都+1了?
舉個例子,原來要連接第六層,加了注意力層后,原來的第六層就變成第七層,所以在Concat連接時需要修改相應的層數
至此,注意力機制已經插入,可以開始使用了
10.在根目錄下新建一個main.py文件,代碼如下:
from ultralytics import YOLOmodel = (YOLO("ultralytics/cfg/models/v8/my_yolov8_CBAM.yaml"))
model.train(**{'cfg': 'ultralytics/cfg/default.yaml'})運行即可開始訓練

















)

)