類常量池、運行時常量池和字符串常量池這三種常量池,在Java中扮演著不同但又相互關聯的角色。理解它們之間的關系,有助于深入理解Java虛擬機(JVM)的內部工作機制,尤其是在類加載、內存分配和字符串處理方面。
類常量池(Class Constant Pool)
每個Java類文件(.class文件)都具有自己的類常量池,它用于存儲編譯期生成的常量,包括各種字面量(字面量就是指由字母、數字等構成的字符串或者數值)和符號引用(比如類和接口的全名、字段的名稱和描述符、方法的名稱和描述符)。類常量池在編譯期間就已經被確定,并被保存在.class文件中。
Class常量池是用來保存常量的一個中間場所。在JVM真的運行時,需要把類常量池中的常量加載到內存中的運行時常量池中。
運行時常量池(Runtime Constant Pool)
運行時常量池是類被加載到JVM時類常量池的內存版本:當Java類被加載到JVM時,各個類文件中的類常量池內容被讀取并存入到運行時常量池中,其中字符串的部分直接進到字符串池,其他常量進入到運行時常量池。
根據Java虛擬機規范約定:每一個運行時常量池都在Java虛擬機的方法區中分配,在加載類和接口到虛擬機后,就創建對應的運行時常量池。
規范中規定了運行時常量池屬于方法區,但是沒規定方法區屬于哪。于是虛擬機在各自實現的時候就各顯神通了。在不同版本的JDK中,運行時常量池所處的位置也不一樣。以HotSpot虛擬機為例:
在JDK 1.7之前,方法區位于永久代,運行時常量池作為方法區的一部分,處于永久代中,字符串常量池位于運行時常量池的一部分也處于永久代中。
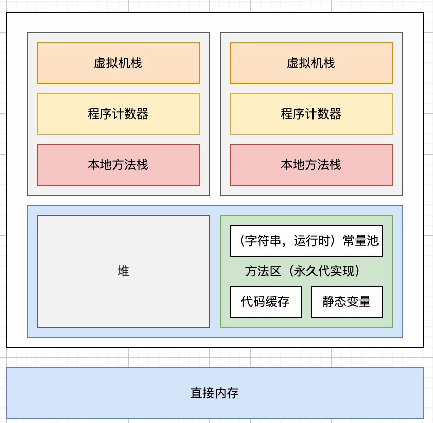
因為使用永久代實現方法區可能導致內存泄露問題,所以,從JDK1.7開始,JVM嘗試解決這一問題。
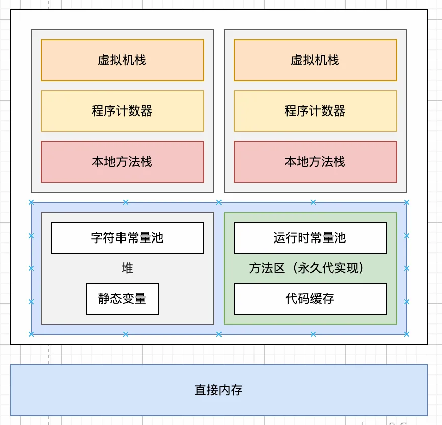
在JDK 1.7中,靜態變量和運行時常量池中的字符串常量池轉移到了堆內存中,其他類型的常量還保留在方法區中。
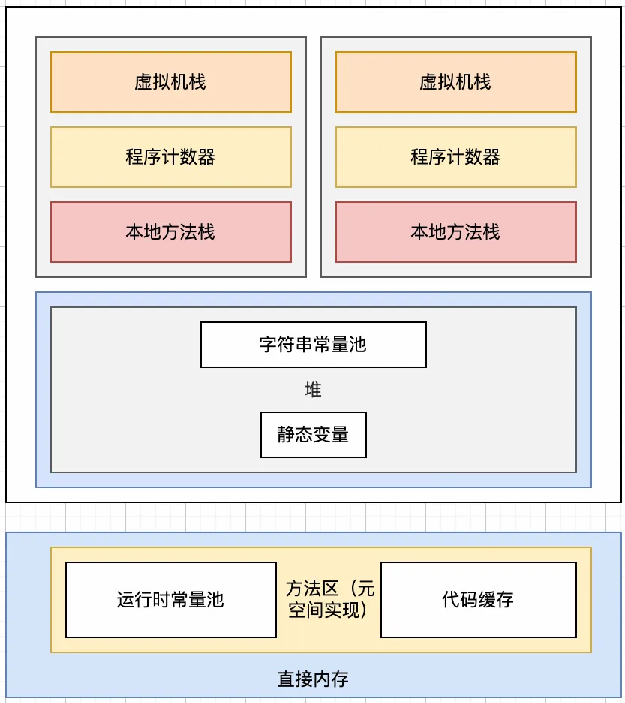
在JDK 1.8中,徹底移除了永久代,方法區通過元空間的方式實現,元空間是使用本地內存(Native Memory)來存儲類的元數據信息的。隨之,運行時常量池也在元空間中實現。
運行時常量池中包含了若干種不同的常量,他的來源主要有兩種:
-
編譯期可知的字面量和符號引用(來自Class常量池)
-
運行期解析后可獲得的常量(如String的intern方法)
字符串常量池(String Constant Pool)
字符串常量池專門用于存儲字符串常量。對于 Hotspot 虛擬機來說,類加載時,字符串字面量作為類常量池的一部分信息被載入運行時常量池中,它們以特殊的形式存儲在運行時常量池中,此時它們并未被實例化為Java堆中的String對象。只有當這個字符串字面量被調用時,才會對其進行解析,即檢查字符串常量池中是否已經存在相同內容的字符串對象。如果存在,就直接返回指向該對象的引用,如果不存在,虛擬機會在字符串常量池中創建一個對應的String實例,并返回這個新實例的引用。
這種處理方式的優勢在于,可以減少在類加載階段對內存的需求和降低開銷,因為不是所有的字符串字面量在類的使用周期內都會被用到。同時,此方法延遲了String對象的實例化,直到它們真正被需要,這有助于提高性能并減少內存的無謂占用。
為什么從JDK 1.7開始,字符串常量池從永久代中挪到堆(Heap)中?
主要原因是因為永久代的 GC 回收效率太低,只有在FulIGC的時候才會被執行回收。但是Java中往往會有很多字符串的生命周期都很短暫,將字符串常量池放到堆中,能夠更高效及時地回收字符串內存。
字符串常量池中的常量有以下幾個來源:
1、字面量常量。
在代碼中直接使用雙引號括起來的字符串字面值(如 strings="hello”)會被認為是常量,并且會在編譯后進入class文件的常量池,并且在運行階段,進入字符串常量池。這是最常見的字符串常量來源。
2、intern()方法
String類提供了一個intern方法,用于將字符串對象手動添加到字符串常量池中。調用intern()方法時,如果字符串常量池中已經存在相同內容的字符串,將會返回常量池中的引用;如果不存在,則會在常量池中添加該字符串在堆中的引用。
要注意的是,字符串常量池是一個固定大小的Hashtable,默認值大小長度是1009,如果放進字符串常量池的String非常多,就會造成Hash沖突嚴重,從而導致鏈表會很長,而鏈表長了后直接會造成的影響就是當調用String.intern時性能會大幅下降(因為要一個一個找,以此判斷字符串常量在不在字符串常量池中)。在jdk6中StringTable是固定的,就是1009的長度,所以如果常量池中的字符串過多就會導致效率下降很快。在jdk7中,StringTable的長度可以通過一個參數指定:
-XX:StringTableSize=99991














)

)
)

