摘要
本文提出了一種新的針對圖像語義分割的知識蒸餾方法,稱為類內和類間知識蒸餾(I2CKD)。該方法的重點是在教師(繁瑣模型)和學生(緊湊模型)的中間層之間捕獲和傳遞知識。對于知識提取,我們利用從特征圖派生的類原型。為了促進知識轉移,我們**采用了三重損失來最小化類內的差異,最大化教師和學生原型之間的類間差異。**因此,I2CKD使學生能夠更好地模仿每個類的教師的特征表示,從而提高緊湊網絡的分割性能。
介紹
一般來說,教師和學生之間的知識質量是使用均方誤差(MSE)等幾個指標以密集的兩兩方式計算的,而不考慮類內和類間的特征關系。
在本文中,我們提出了一種針對語義分割的新型知識蒸餾方法,稱為類內和類間知識蒸餾(I2CKD)。首先,我們使用特征映射和ground truth(mask)計算每個類的教師原型(質心)。我們工作背后的假設是,教師的良好表現得益于他們合適的制作原型。因此,我們建議將這些知識傳授給學生。為此,正如方法的名稱所暗示的那樣,我們通過最小化/最大化他們之間的類內和類間距離來強迫每個類的學生原型模仿老師原型(見圖1)。作為這種約束的一種復雜損失,我們利用了三重損失。

相關工作
面向語義分割的知識蒸餾
[9]中,提取率0階和1階兩類知識。0階計算像素類概率之間的差。1階考慮中心像素與其8個領域之間的差異。[12]專注于匹配教師和學生的特征圖大小,并提出應用自編碼器。然后,計算兩兩關聯圖來量化教師和學生知識之間的關系。[10]提出了一個結構化蒸餾(SKD)方案,該方案考慮了使用圖的特征圖之間的中間蒸餾。分數圖之間的像素蒸餾以及通過對抗學習的整體蒸餾。Wang等開發了一種名為Intra-class Feature Variation Distillation(IFVD)的新方法,學習學生模仿教師的Intra-class關系。為了傳遞IFV知識,使用了余弦距離。Shu等人開發了一種稱為通道知識蒸餾(CWD)的方法,該方法的通道維度計算教師和學生激活通道映射的softmax之間的KLD。在我們之前的工作中,我們利用教師特征圖之間的相互依賴性作為知識蒸餾。這些知識使用自注意機制捕獲,并使用MSE轉移。
在獲得滿意的性能的同時,這些方法忽略了特征圖(原型)中每個類的有意義的知識。這些知識可以有效地用于測量教師和學生網絡之間的類內和類間相似性。這就是我們方法I2CKD的目的。
方法
總體
如圖2所示,我們的方法I2CKD將知識從訓練有素的教師網絡中提煉出來,傳遞給學生。對于學生網絡的每個訓練階段。我們都凍結了教師網絡。學生網絡通過三個損失來更新其權重,分別捕獲得分圖和特征圖級別的學生/ground truth差異和教師/學生差異。貢獻的核心在于特征映射級別,我們建議利用教師和學生之間的類內和類間關系。為此,我們計算了教師和學生類原型之間的三元組損失。
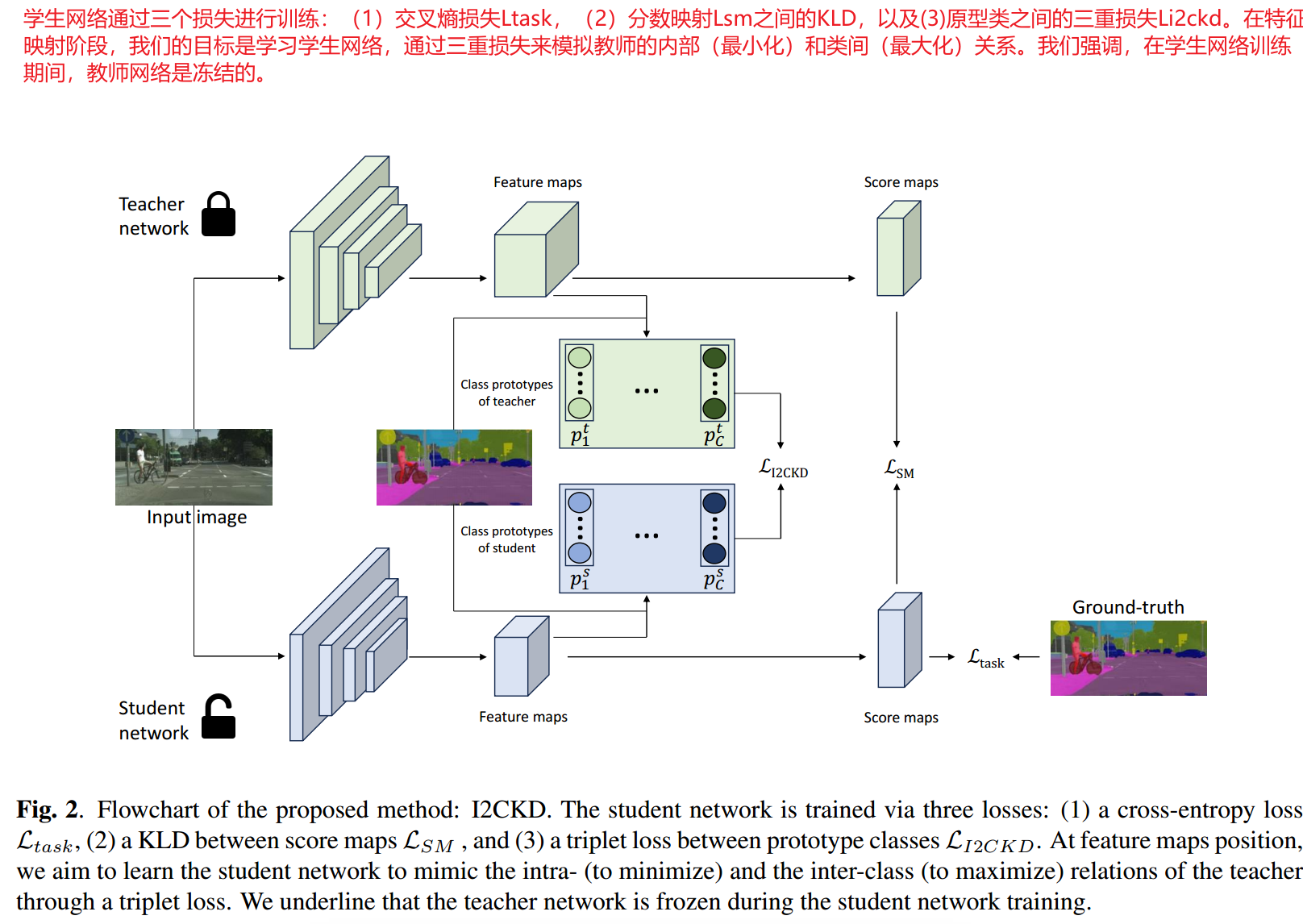
類內和類間的知識蒸餾
類原型計算
對于給定通道的特征映射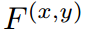 ,類c的原型表示為:
,類c的原型表示為:
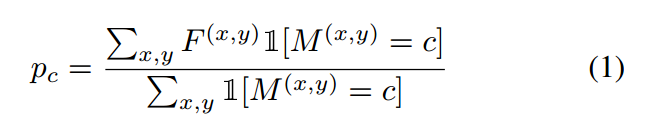
其中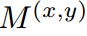 表示ground truth(掩碼)。
表示ground truth(掩碼)。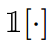 是一個指示函數,如果參數為真,則等于1,否則等于0。對于教師和學生網絡,我們在特征映射上計算所有類的原型。得到矩陣大小為
是一個指示函數,如果參數為真,則等于1,否則等于0。對于教師和學生網絡,我們在特征映射上計算所有類的原型。得到矩陣大小為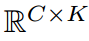 ,其中C和K分別表示類和通道的數量。
,其中C和K分別表示類和通道的數量。
三重損失
我們蒸餾方案的最終目標是最小化類內的差異,最大化教師和學生網絡之間的類間差異。具體來說,我們的目標是執行以下約束:
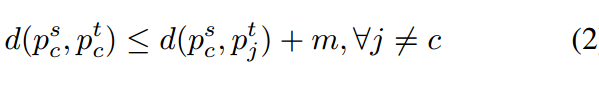
這里d(*)是一個距離函數,m代表一個恒定的邊界。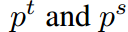 是從教師和學生網絡中提取出的類原型。
是從教師和學生網絡中提取出的類原型。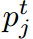 表示與C不同的類的原型,m是給定的余量。
表示與C不同的類的原型,m是給定的余量。
這一約束的執行允許將學生和教師類原型之間的損失表述如下:
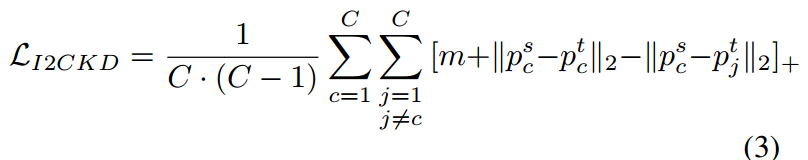
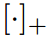 表示函數
表示函數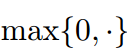 ,
,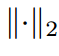 為
為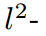 范數,
范數,
學生訓練的總損失
語義切分的總體學生訓練損失如下:
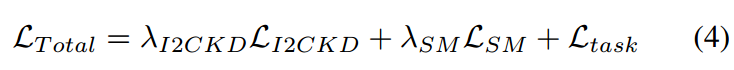
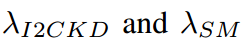 是平衡所考慮的損失的超參數。
是平衡所考慮的損失的超參數。
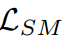 是教師分數圖
是教師分數圖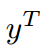 與學生分數圖
與學生分數圖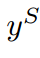 之間的KLD。
之間的KLD。
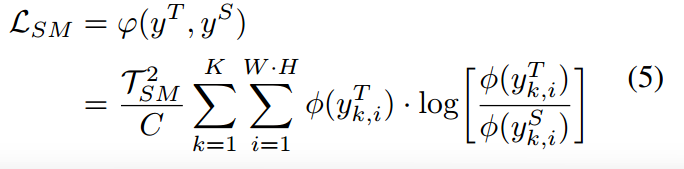
 是softmax函數
是softmax函數
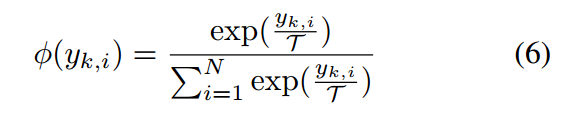
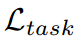 是ground truth與分割后的圖像之間的損失,在我們的工作中,我們使用交叉熵損失。
是ground truth與分割后的圖像之間的損失,在我們的工作中,我們使用交叉熵損失。



)

)
)





)


)



:表單)