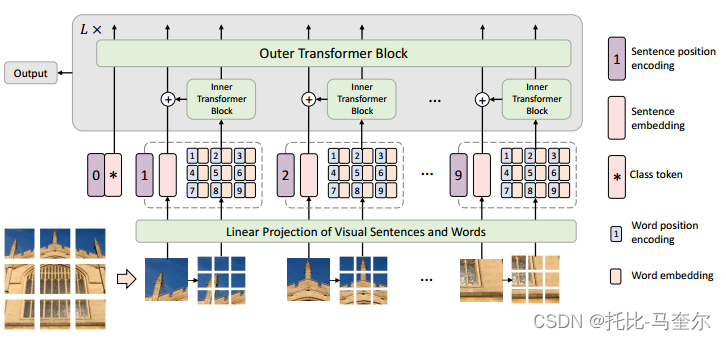
Transformer iN Transformer (TNT)。具體來說,我們將局部補丁(例如,16×16)視為“視覺句子”,并將它們進一步劃分為更小的補丁(例如,4×4)作為“視覺單詞”。每個單詞的注意力將與給定視覺句子中的其他單詞一起計算,計算成本可以忽略不計。單詞和句子的特征將被聚合以增強表示能力。
1. 介紹
Transformer是一種主要基于自注意力機制的神經網絡,它可以提供不同特征之間的關系。
CV 任務中的輸入圖像和真實標簽之間存在語義差距。ViT 將給定??圖像劃分為多個局部塊作為視覺序列。然后,可以自然地計算任意兩個圖像塊之間的注意力,以便為識別任務生成有效的特征表示。
文章貢獻
一種用于視覺識別的新型 Transformer-in-Transformer (TNT) 架構。為了增強視覺 Transformer 的特征表示能力,首先將輸入圖像劃分為多個塊作為“視覺句子”,然后進一步將它們分成子補丁作為“視覺單詞”。
除了用于提取視覺句子的特征和注意力的傳統Transformer Block之外,我們進一步將子變壓器嵌入到架構中以挖掘較小視覺單詞的特征和細節。
具體來說,每個視覺句子中視覺單詞之間的特征和注意力是使用共享網絡獨立計算的,因此增加的參數量和 FLOP(浮點運算)可以忽略不計。然后,單詞的特征將被聚合成相應的視覺句子。該類令牌還通過全連接頭用于后續視覺識別任務。通過所提出的TNT模型,我們可以提取細粒度的視覺信息并提供更多細節的特征。
2. 方法
2.1 預先工作
多頭自注意力
在自注意力模塊中,輸入 被線性變換為三個部分,查詢
,鍵
和值
。其中 n 是序列長度,
、
、
分別是輸入、查詢(鍵)和值的維度。縮放點積注意力:
最后,使用線性層來產生輸出。多頭自注意力將查詢、鍵和值拆分為
個部分并并行執行注意力函數,然后將每個頭的輸出值連接并線性投影以形成最終輸出。
多層感知器(MLP)
MLP 應用于自注意力層之間,用于特征變換和非線性:
其中W和b分別是全連接層的權重和偏置項,σ(·)是激活函數。
層歸一化(LN)
層歸一化 是 Transformer 中穩定訓練和更快收斂的關鍵部分。LN 應用于每個樣本,
,其中
分別是特征的平均值和標準差,
是逐元素點積,
是可學習的變換參數。
2.2 Transformer in Transformer
給定一個 2D 圖像,我們將其均勻分割為 n 個補丁,其中
是每個圖像塊的分辨率。ViT 僅利用標準轉換器來處理補丁序列,這會破壞補丁的局部結構,Transformer-in-Transformer (TNT) 架構來學習圖像中的全局和局部信息。
在 TNT 中,我們將補丁視為代表圖像的視覺句子。每個補丁又分為m個子補丁,即一個視覺句子由一系列視覺單詞組成:,其中
是第 i 個視覺句子的第 j 個視覺詞;
是子塊的大小,
。
通過線性投影,我們將視覺單詞轉換為一系列單詞嵌入:
其中是第 j 個詞嵌入,c 是詞嵌入的維度,Vec(·) 是向量化操作。
在 TNT 中,我們有兩個數據流,其中一個數據流跨視覺句子進行操作,另一個數據流處理每個句子內的視覺單詞。對于詞嵌入,我們利用Transformer Block來探索視覺單詞之間的關系:
其中是第?
?個塊的索引,L是堆疊塊的總數。第一個塊
的輸出就是
。變換后圖像中的所有詞嵌入均為
,可以看作內部Transformer Block,表示為
。該過程通過計算任意兩個視覺單詞之間的交互來構建視覺單詞之間的關系。
對于句子級別,創建句子嵌入記憶來存儲句子級別表示的序列:
?其中
是類似于ViT的類標記,并且它們都被初始化為零。在每一層中,詞嵌入的序列通過線性投影變換到句子嵌入的域中,并添加到句子嵌入中:
,其中
。使用標準Transformer Block來轉換句子嵌入:
外部變壓器塊 用于對句子嵌入之間的關系進行建模。
TNT塊的輸入和輸出包括視覺詞嵌入和句子嵌入。
在TNT 塊中,內部 Transformer 塊用于對視覺單詞之間的關系進行建模以進行局部特征提取,外部 Transformer 塊從句子序列中捕獲內在信息。最后,分類標記用作圖像表示,并應用全連接層進行分類。
位置編碼
空間信息是圖像識別的重要因素。對于句子嵌入和詞嵌入,我們都添加相應的位置編碼來保留空間信息,使用標準的可學習一維位置編碼。具體來說,每個句子都分配有一個位置編碼:
,其中
是句子位置編碼。對于句子中的視覺單詞,每個單詞嵌入都添加一個單詞位置編碼:
其中是跨句子共享的單詞位置編碼。這樣,句子位置編碼可以保持全局空間信息,而詞位置編碼用于保持局部相對位置。
2.3 復雜性分析
標準變壓器塊包括兩部分,即多頭自注意力和多層感知器。MSA的FLOPs為
,MLP的FLOPs為
。其中 r 是MLP中隱藏層的維度擴展比。總體而言,標準變壓器塊的 FLOPs 為
。由于 r 通常設置為4,并且輸入、鍵(查詢)和值的維度通常設置為相同,因此FLOPs計算可以簡化為
FLOPs值越高,說明模型或算法的計算復雜度越高,可能需要更強大的計算資源來支持其運行
?參數個數為。
TNT 塊由三部分組成:內部變壓器塊 Tin、外部變壓器塊 Tout 和線性層。 Tin和Tout的計算復雜度分別為2nmc(6c + m)和2nd(6d + n)。線性層的 FLOPs 為 nmcd。總共,TNT 塊的 FLOP 為
。TNT塊的參數復雜度計算為
。
TNT 塊與標準 Transformer 塊的 FLOPs 比率約為 1.14×。同樣,參數比例約為1.08×。隨著計算和內存成本的小幅增加,我們的 TNT 模塊可以有效地對局部結構信息進行建模,并在準確性和復雜性之間實現更好的權衡。
2.4 網絡架構
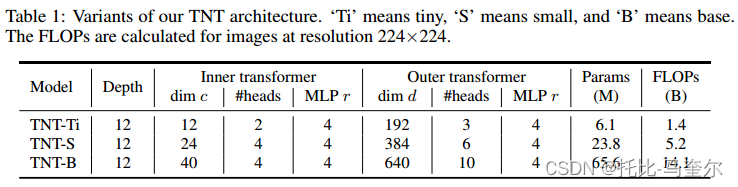
3. 實驗
3.1 數據集和實驗設置
ImageNet ILSVRC 2012 [26] 是一個圖像分類基準,由屬于 1000 個類的 120 萬張訓練圖像和 50K 個驗證圖像(每類 50 張圖像)組成。數據集下載鏈接
3.2?ImageNet 上的 TNT
在TNT結構中,句子位置編碼用于維護全局空間信息,單詞位置編碼用于保留局部相對位置。
3.3 消融實驗
視覺詞的數量:
在TNT中,輸入圖像被分割成許多16×16的塊,并且每個塊進一步被分割成 m 個大小為(s, s)的子塊(視覺詞)以提高計算效率。
本文中 m 默認取值為16.
3.4 可視化
特征圖的可視化
將 DeiT 和 TNT 的學習特征可視化,以進一步了解所提出方法的效果。為了更好的可視化,輸入圖像的大小調整為 1024×1024。特征圖是通過根據塊的空間位置重塑塊嵌入來形成的。
第 1 個、第 6 個和第 12 個塊中的特征圖如圖(a)所示,其中每個塊隨機采樣 12 個特征圖。與 DeiT 相比,TNT 中本地信息得到了更好的保存。我們還使用 t-SNE 對第 12 個塊中的所有 384 個特征圖進行可視化。
t-SNE算法的核心思想是將高維空間中的數據點映射到低維空間中,使得相似的數據點在低維空間中靠近彼此,而不相似的數據點則被遠離。

可視化了 TNT 的像素級嵌入。對于每個補丁,我們根據詞嵌入的空間位置重塑詞嵌入以形成特征圖,然后按通道維度對這些特征圖進行平均。對應于14×14塊的平均特征圖

注意力圖的可視化。我們的 TNT 塊中有兩個自注意力層,即內部自注意力層和外部自注意力層,分別用于建模視覺單詞和句子之間的關系。內部變壓器中不同查詢的注意力圖。對于給定的查詢視覺詞,具有相似外觀的視覺詞的注意力值較高,表明它們的特征將與查詢交互更相關。

?






)

)
)





)


)
