文章目錄
- 一、軟件體系結構概述
- 1.1 基本概念
- 1.1.1 背景
- 1.1.2 定義
- 1.1.3 系統
- 1.1.3.1 定義
- 1.1.3.2 特性
- 1.1.3.3 系統的體系結構
- 1.1.4 軟件設計的層次性
- 1.1.5 體系結構的類別(類型)
- 1.1.6 重要性(意義)
- 1.2 模塊及其設計
- 1.2.1 定義
- 1.2.2 模塊的內聚性
- 1.2.2.1 含義
- 1.2.2.2 內聚性的層次
- 1.2.2.3 偶然內聚性
- 1.2.2.4 邏輯內聚性
- 1.2.2.5 暫時內聚性
- 1.2.2.6 過程內聚性
- 1.2.2.7 通信內聚性
- 1.2.2.8 信息內聚性
- 1.2.2.9 功能內聚性
- 1.2.3 模塊的耦合性
- 1.2.3.1 含義
- 1.2.3.2 耦合的級別
- 1.2.3.3 內容耦合
- 1.2.3.4 共用耦合
- 1.2.3.5 控制耦合
- 1.2.3.6 特征耦合
- 1.2.3.7 數據耦合
- 1.2.4 模塊的重用
- 1.2.4.1 定義
- 1.2.4.2 重用的類型
- 1.2.4.3 構建重用
- 1.2.4.4 重用的障礙
- 1.2.5 模塊的重要性(意義)
- 1.3 軟件工程
- 1.3.1 軟件危機
- 1.3.1.1 背景
- 1.3.1.2 定義
- 1.3.1.3 人月神話
- 1.3.1.4 沒有銀子彈
- 1.3.1.5 有一個銀子彈
- 1.3.2 軟件工程的復雜性
- 1.3.2.1 建筑工程的經驗對軟件工程的啟發
- 1.3.2.2 軟件工程的復雜性
- 1.3.3 軟件工程的內容
- 1.4 軟件體系結構的意義與目標
- 1.4.1 軟件體系結構的意義
- 1.4.2 軟件體系結構的目標
- 1.5 軟件體系結構的研究現狀
- 1.5.1 軟件體系統結構的發展
- 1.5.2 軟件體系統結構的研究現狀
- 1.6 習題
- 二、軟件體系結構風格
- 2.1 什么是軟件體系結構風格
- 2.1.1 什么是結構風格
- 2.1.2 結構風格的分類
- 2.2 常用結構風格
- 2.2.1 管道/過濾器(Pipes and Filters,P/F)
- 2.2.1.1 系統組織
- 2.2.1.2 評價
- 2.2.2 數據抽象與面向對象組織(Data abstraction and Object-oriented Organization)
- 2.2.2.1 系統組織
- 2.2.2.2 評價
- 2.2.3 事件及隱含激活(Event-Based, Implicit Inovaations)
- 2.2.3.1 系統組織
- 2.2.3.2 評價
- 2.2.4 層次系統(Layers Systems)
- 2.2.4.1 系統組織
- 2.2.4.2 評價
- 2.2.5 倉庫(Repositories)
- 2.2.5.1 系統組織
- 2.2.6 解釋器(Interpreters)
- 2.2.6.1 系統組織
- 2.3 其他結構風格
- 2.4 案例分析
- 2.4.1 問題描述
- 2.4.2 解決方案
- 2.4.2.1 主程序/子過程調用(Main program/subroutine)
- 2.4.2.2 數據抽象與面向對象組織(Data abstraction and Object-oriented Organization)
- 2.4.2.3 事件及隱含激活(Event-Based, Implicit Inovaations)
- 2.4.2.4 管道/過濾器(Pipes and Filters,P/F)
- 2.5 習題
- 三、分布式體系結構分析
- 3.1 分布式處理結構風格概述
- 3.1.1 系統組織
- 3.1.2 分布式處理結構風格的優缺點
- 3.1.2.1 優點
- 3.1.2.2 缺點
- 3.1.3 構造分布式處理結構風格的主要技術
- 3.2 分布式系統
- 3.2.1 分布式系統是計算機發展的必然產物
- 3.2.2 集中式系統和分布式系統
- 3.2.2 分布式系統的優點
- 3.2.3 分布式系統的不足
- 3.3 客戶/服務器(Client/Server)結構
- 3.3.1 C/S結構
- 3.3.2 C/S模型的軟件結構的特點
- 3.3.3 C/S模型的工作過程
- 3.3.4 數據共享的方式
- 3.3.5 C/S的連接
- 3.3.6 C/S的服務器設計、實現關鍵
- 3.3.7 C/S案例
- 3.3.7.1 文件服務器的設計
- 3.3.7.2 文件服務器的C語言實現(部分)
- 四、分布式體系結構關鍵技術
- 4.1 基于消息傳遞的通信(分布式進程的通信)
- 4.1.1 發送操作(send primitive)
- 4.1.2 接發操作(receive primitive)
- 4.1.3 阻塞(Blocking)操作
- 4.1.4 非阻塞操作(Nonblocking primitive)
- 4.1.5 非緩沖操作(unbuffered primitives)
- 4.1.6 緩沖通信操作-信箱(mailbox)
- 4.1.7 不可靠(Unreliable)操作
- 4.1.8 可靠(Reliable)操作
- 4.2 遠程過程調用(RPC)
- 4.2.1 RPC概述
- 4.2.1.1 RPC的基本思想
- 4.2.1.2 RPC例子
- 4.2.2 RPC的透明性(transparent)
- 4.2.2.1 RPC透明性
- 4.2.2.1 RPC透明性的實現
- 4.2.3 參數傳遞(Parameter Passing)
- 4.2.4 動態聯編(Dynamic Binding)
- 4.2.5 RPC表示錯誤的語義(Semantics in the Presence of Failures)
- 4.2.6 RPC的實現
- 4.2.6.1 RPC協議是選擇面向連接的還是非連接的協議
- 4.2.6.2 RPC協議是選擇標準通用的還是RPC專用的協議
- 4.2.6.3 確認機制(Acknowledgement)
- 4.2.6.4 流量控制(flow control)
- 4.2.6.5 臨界路徑(critical path)
- 4.2.6.6 定時管理(timer)
- 4.2.7 RPC與消息傳遞通信的比較
- 4.3 分布式同步算法
- 4.3.1 邏輯時鐘(Logical Clocks)
- 4.3.2 Lamport 算法
- 4.4 分布式互斥算法
- 4.4.1 集中式算法
- 4.4.2 Ricart & Agrawala's算法
- 4.4.3 令牌環算法(Token Ring)
- 4.4.4 三種算法的比較
- 4.5 分布式系統的可靠性
- 4.5.1 選擇算法(Elect Algoriathms)
- 4.5.2 k-容錯技術
- 4.5.3 表決算法(voting algorithm)
- 4.6 習題
- 五、層次結構分析
- 5.1 線程技術
- 5.1.1 引入線程的目的
- 5.1.2 線程的概念
- 5.1.3 線程與進程的區別、聯系
- 5.1.4 線程的分類
- 5.1.5 線程的執行特性
- 5.1.6 線程的應用
- 5.2 服務器緩沖技術
- 5.2.1 無狀態信息(Stateless)服務器
- 5.2.2 有狀態信息(State)服務器
- 5.2.3 無狀態服務器與有狀態服務器的比較
- 5.3 N層結構的特性
- 5.3.1 層次結構設計
- 5.3.2 軟件系統的層次結構
- 5.4 N層結構的實現
- 5.5 N層結構的優缺點
- 5.6 一個用于構造分布式系統的層次結構設計
- 5.6.1 表示層——用戶界面技術
- 5.6.2 業務邏輯層——應用系統的核心
- 5.6.3 數據邏輯訪問層(DAL)
- 5.6.4 數據層
- 5.7 習題
- 六、CORBA技術及應用實例(了解即可)
- 6.1 CORBA概述
- 6.2 CORBA特性
- 6.2.1 OMG接口定義語言(IDL)
- 6.2.2 語言映射
- 6.2.3 操作調用和調度軟件
- 6.2.4 對象適配器(Object Adapter)
- 6.2.5 內部ORB協議
- 6.3 CORBA應用程序的一般開發過程
- 6.4 CORBA的基本服務
- 6.4.1 命名服務(Naming Service)
- 6.4.2 交易服務(Trading Service)
- 6.4.3 事件服務(Event Service)
- 七、結構設計空間及其量化
- 7.1 設計空間和規則(design space and rule)
- 7.1.1 設計空間(design space)
- 7.1.2 維(Deimension)
- 7.1.3 設計規則(design rule)
- 7.1.4 設計知識庫(design vocabulary)
- 7.1.5 一個設計空間的例子
- 7.2 用戶接口結構(user-interface architecture)設計
- 7.2.1 用戶接口結構的設計空間
- 7.2.1.1 基本結構模型(a basic structure model)
- 7.2.1.2 功能維例子(sample functional dimensions)
- 7.2.1.3 結構維例子(sample structure dimensions)
- 7.2.2 用戶接口結構的設計規則
- 7.3 量化設計空間(Quantified Design Space,QDS)【重點】
- 7.3.1 簡介
- 7.3.1.1 質量配置函數(QFD)
- 7.3.2 量化設計空間(QDS)
- 7.4 習題
- 八、軟件體系結構描述
- 8.1 軟件體系結構形式化的意義
- 8.2 軟件體系結構描述的方法
- 8.2.1 主程序和子過程
- 8.2.2 數據抽象和面向對象設計
- 8.2.3 Category Theory(類屬理論)
- 8.3 Z Notation簡介
- 8.3.1 什么是形式規范(formal specifications)
- 8.3.2 Z notation的思想
- 8.3.3 聲明(Declarations)
- 8.3.4 Schema texts
- 8.3.5 Predicates
- 九、J2EE體系結構分析及應用(了解即可)
- 十、區塊鏈技術(補充)
- 10.1 基本概念
- 10.2 區塊鏈在“數據追溯”方面的應用案例
- 10.3 區塊鏈在“共享經濟”方面的應用案例
一、軟件體系結構概述
1.1 基本概念
1.1.1 背景
??現在,計算機軟件工業界面臨著巨大的挑戰:對于日益復雜的需求和運行環境,如何生產一個靈活、高效的軟件系統。
??隨著軟件系統的規模和復雜性的增加,軟件結構的設計和規范變得越來越重要。對于一個小的程序,人們可以集中考慮其算法選擇和數據結構的設計,以及使用哪一種的代碼設計語言,可是,對于一個大的系統,軟件的結構就顯得更重要了,比如,系統由哪些組件(component)構成、組件間的關系如何、每個組件應完成的功能、組件運行的物理位置、如何通訊、同步/異步、數據訪問等,這些內容就體現了軟件系統結構的思想。
1.1.2 定義
- 一個軟件系統的體系結構是指構成這個系統的計算部件、部件間的相互作用關系。
- 部件可以是客戶(clients)、服務器(servers)、數據庫(databases)、過濾器(filters) 、層等。
- 部件間的相互作用關系(即連接器)可以是過程調用(procedure call)、客戶/服務器、同步/異步、管道流(piped stream)等.
1.1.3 系統
1.1.3.1 定義
??系統概念是系統理論的最基本的概念,它濃縮和概括了系統理論的最基本內容,然而,由于研究領域的不同、應用對象和理解角度的不同,對系統概念的定義也有不同,尚未有一個統一的定義。
??我國著名科學家錢學森認為“系統即由相互作用和相互依賴的若干部分(要素)結合成的具有特定功能的有機的整體,而且這個系統本身又是它所從屬的一個更大系統的組成部分”
1.1.3.2 特性
- 集合性
??系統由兩個或兩個以上的可以區別的相互區別的要素(對象)組成。 - 相關性
??系統中,各個要素之間具有相互依賴、 相互作用的關系。 - 結構性
??系統中,各個要素不是簡單的排列,而是有一定的組成形式即結構。相同的幾個要素,如果組織的結構不同,將構成不同的系統。 - 整體性
??系統中各個要素根據特定的統一要求,共同協作,對外形成個整體。 - 功能性
??各個要素完成特定的功能,它們的相互作用完成系統的功能,但系統的功能并不是它的各部分的功能的線性和,具有“整體大于各部分之和” - 環境適應性
??任何一個系統都存在于一定的環境之中,受外界的影響,具有開放性。
1.1.3.3 系統的體系結構
- 系統中各要素的組織方式和相互作用方式。
- 常用的有整體性結構、層次結構等
1.1.4 軟件設計的層次性
- 結構級
??包括與部件相關聯的系統的總體性能,部件是指模塊,模塊的相互關聯通過多種方法處理。 - 代碼級
??包括算法和數據結構的選擇,部件指程序語言中的數值、字符、指針等,相互關聯是程序中的各種操作,合成如記錄、數組、過程等。 - 執行級
??包括存儲器的映射、數據格式設置、堆棧和寄存器的分配等,部件是指硬件提供的位(bit)模式,相互關聯由代碼描述。
??以前,軟件開發人員注意力主要集中在程序語言的層次上,現在,軟件的代碼和執行層次的問題已經得到很好的解決,而對結構級的理解一直都還停留在直覺和經驗上,盡管一個軟件系統通常都有文字和圖表的說明,但所使用的句法和所表達語義的解釋從來沒有得到統一。而軟件體系結構將在軟件的較高層研究軟件系統的部件組成和部件間的關系。
1.1.5 體系結構的類別(類型)
??服務于軟件開發的不同階段,體系結構可分為
- 概略型
??是上層宏觀結構的描述,反映系統最上層的部件和連接關系。 - 需求型
??對概略型體系結構的深入表達,以滿足用戶功能和非功能的需求。 - 設計型
??從設計實現的角度對需求結構的更深層的描述,設計系統的各個部件,描述各部件的連接關系。這是軟件系統結構的主要類別。
1.1.6 重要性(意義)
??體系結構的重要性在于它決定一個系統的主體結構、基本功能和宏觀特性,是整個軟件設計成功的基礎,其重要性表現為在項目的:
- 規劃階段
??粗略的體系結構是進行項目可行性研究、工程復雜性分析、工程進度計劃、投資規模預算、風險預測等的重要依據。 - 需求階段
??在需求分析階段,需要從項目需求從發,建立更深入的體系結構,這時體系結構成為開發商與用戶之間進行需求交互的表達形式,也是交互所產生的結果,通過它,可以準確地表達用戶的需求,以及出對應需求的解決方案,并考察系統的各項性能。 - 設計階段
??需要從實現的角度,對體系結構進行更深入的分解和描述。部件的組成、各部件的功能、部件的位置、部件間的連接關系選擇等的描述。 - 實施階段
??體系結構的層次和部件是建立人員的組織、分工、協調開發人員等的依據。 - 測評階段
??體系結構是系統性能測試和評價的依據。 - 維護階段
??對軟件的任何擴充和修改都需要在體系結構的指導下進行,以維持整體設計的合理性和正確性以及性能的可分析性,并為維護升級和復雜性和代價分析提供依據。
1.2 模塊及其設計
1.2.1 定義
- 模塊(module)是由一個或多個相鄰的程序語句組成的集合。每個模塊有一個名字,系統的其他部分可以通過這個名字來調用該模塊。
- 模塊是一個獨立的代碼,能夠按過程、函數或方法調用方式調用它。
- 宏不是模塊,過程、函數是模塊,對象是模塊,對象內的方法也是模塊。
- 一個軟件產品可以分解成一些較小的模塊。
- 一個好的模塊設計應該使模塊具有高內聚性和低耦合性。
1.2.2 模塊的內聚性
1.2.2.1 含義
模塊內聚性是指一個模塊內相互作用的程度。
1.2.2.2 內聚性的層次
- 偶然內聚性(不好)
- 邏輯內聚性
- 暫時內聚性
- 過程內聚性
- 通信內聚性
- 信息內聚性
- 功能內聚性(好)
1.2.2.3 偶然內聚性
??如果一個模塊執行多個完全不相關的動作,那么這個模塊就有偶然內聚性。例如,一個模塊在一個列表中增加一個新的項或刪除一個指定的項。【許多不同類的功能都寫在一個模塊里面】
??具有偶然內聚性的模塊有兩個嚴重的缺點:一是在改正性維護和完善性維護方面,這些模塊降低了產品的可維護性;二是這些模塊不能重用。
??造成的原因:“每個模塊由35-50個可執行語句組成。”,將兩個或多個不相關的小模塊不得不組合在一起,從而產生一個具有偶然內聚性的大模塊。另外,從管理角度認為在太大的模塊內被分割出來的部分將來要組合在一起。
1.2.2.4 邏輯內聚性
??當一個模塊執行一系列相關的動作,且其中一個動作是作為其他動作選擇模塊,稱其有邏輯內聚性。例如,一個執行對主文件記錄進行插入編輯、刪除編輯和修改編輯操作的模塊;【一類功能寫在一個模塊里面】
??一個模塊有邏輯內聚性會帶來兩個問題:其一,接口部分難于理解,其二,多個動作的代碼可能會纏繞在一起,從而導致嚴重的維護問題,甚至難于在其他產品中重用這樣的模塊。
1.2.2.5 暫時內聚性
??當一個模塊執行在時間上相關的一系列動作時,稱其具有暫時內聚性。例如,在一個執行銷售管理的初始化模塊中,其動作有:打開一個輸入文件,一個輸出文件、一個處理文件,初始化銷售地區表,并讀入輸入文件的第一條記錄和處理文件的第一條記錄。這個模塊的各個動作之間的相互關系是弱的,但是卻與其他模塊中的動作有更強的聯系,就銷售地區表來說,它在這個模塊中初始化,而更新銷售地區表和打印銷售地區表這樣動作是在其他模塊中,因此,如果銷售地區表的結構改變了,則若干模塊將被改變,這樣不僅可能有回歸的錯誤(由于對產品的明顯不相關的部分的改變而引起的錯誤),而且如果被影響的模塊的數量很大時,則很可能會忽略一二個模塊。而較好的作法是將有關銷售地區表的所有操作放入一個模塊。【一段時間內的功能寫一個模塊】
??暫時內聚性的模塊的缺點:一是降低了產品的可維護性;二是這些模塊難以在其他產品中重用。
1.2.2.6 過程內聚性
??一個模塊有過程內聚性,是指其執行與產品的執行序列相關的一系列動作。比如,從數據庫中讀出部分數據,然后更新日志文件中的維護記錄。過程中的動作有一定的聯系,但這種關系也還是弱的。【一個過程寫一個模塊】
??這種模塊比暫時內聚性模塊有好些,但仍難以重用。
1.2.2.7 通信內聚性
??一個模塊有通信內聚性,是指其執行與產品的執行序列相關的一系列動作,并且所有動作在相同數據上執行。【一個類寫一個模塊】
??這種模塊比過程內聚性模塊有好些因為其動作有緊密的聯系,但仍難以重用。
1.2.2.8 信息內聚性
??如果一個模塊執行一系列動作,每一動作有自己的入口點,每一個動作有自己的代碼,所有的動作在相同的數據結構上執行,這樣的模塊稱其為信息內聚性模塊。【一個接口寫一個模塊】
??對于面向對象的范型來說,信息內聚性是最理想的。信息內聚性的模塊本質上是抽象數據類型的實現,而對象本質上就是抽象數據類型的一個實例。
擁有抽象數據結構的優點。
1.2.2.9 功能內聚性
??一個只執行一個動作或只完成單個目標的模塊有功能內聚性。【一個功能一個模塊】
??一個有功能內聚性的模塊可能經常被重用。因為它執行的那個動作經常需要在其他產品中執行。一個經過適當設計、徹底測試的并且具有良好文檔的內聚性模塊對一個軟件組織來說是一個有價值的資產,應該盡可能多地重用。
??具有功能內聚性的模塊也比較容易維護。首先,功能內聚有利于錯誤隔離;另外因為比普通的模塊更容易理解從而簡化了維護;同時還便于擴充(簡單也拋棄舊模塊用一個新模塊來代替)。
1.2.3 模塊的耦合性
1.2.3.1 含義
??模塊耦合是指模塊間的相互作用程度。
1.2.3.2 耦合的級別
- 內容耦合(不好)
- 共用耦合
- 控制耦合
- 特征耦合
- 數據耦合(好)
1.2.3.3 內容耦合
??如果一個模塊p直接引用另一個模塊q的內容,則模塊p和q是內容耦合的。比如,模塊p分支轉向模塊q的局部標號。【兩個模塊代碼雜糅】
??在產品中,內容耦合是危險的,因為它們是不可分割的,模塊q的改變,都需要對模塊p進行相應的改變,并且,在新產品中,如果不重用模塊q,則不可能重用模塊p。
1.2.3.4 共用耦合
??如果兩個模塊都能訪問同一個全局變量,則稱它們為共用耦合。比如模塊a和模塊b都需要訪問x這個全局變量。【兩個模塊訪問同一個全局變量】
缺點
- 代碼不可讀,與結構化編程的精神相矛盾;
- 維護困難。如果在一個模塊內,對某個全局變量的聲明做了維護性修改,那么訪問這個全局變量的每一個模塊都必須修改,而且,所有的修改都必須是一致的。
- 難以重用。因為重用這類模塊時,必須提供相同的全局變量名。
- 數據無法控制。作為共用模塊的后果,一個模塊也許會被它本身之外的數據改變,使得控制數據訪問的努力變得無效。
1.2.3.5 控制耦合
??如果一個模塊傳遞一個控制元素給另一個模塊,則稱這兩個模塊是控制耦合的。即一個模塊明確地控制另一個模塊的邏輯。【一個模塊的代碼運行順序由另一個模塊控制】
??控制耦合所帶來的問題是:兩個模塊不是相互獨立的——被調用模塊必須知道模塊p的內部結構和邏輯,降低了重用的可能性;另外,控制耦合一般是與邏輯內聚性的模塊的有關,邏輯內聚性的問題也在控制耦合中出現。
1.2.3.6 特征耦合
??如果把一個數據結構當作參數傳遞,而被調用的模塊只在數據結構的個別元素上操作,則稱兩個模塊是特征耦合的。【一個模塊只需要另一個模塊的部分參數】
??導致數據無法控制。
1.2.3.7 數據耦合
??如果兩個模塊的所有參數是同一類數據項,則稱它們是數據耦合的,也一就是每一個參數要么是簡單變量,要么是數據結構,而當是后者時,被調用的模塊要使用這個數據結構中的所有元素。【一個模塊需要零一個模塊完整的參數】
1.2.4 模塊的重用
1.2.4.1 定義
??重用是指利用一個產品的構件以使開發另一個具有不同性能的產品更容易。可重用的構件不一定是一個模塊或一個代碼框架,它可能是一個設計、一本手冊的一部分、一組測試數據或最后期限和費用的估計。
??而可移植的是指,為了使一個產品在另一個編譯器/硬件/操作系統上運行,如果修改這個產品比從頭編寫代碼更容易的話,那么這個產品就是可移植的。
1.2.4.2 重用的類型
- 偶然重用
??如果一個新產品的開發人員意識到以前所開發的產品中有一個構件在新產品中可重用,那么這種重用即為偶然重用。 - 計劃重用
??如果利用那些專門為在將來產品中重用而構件的軟件構件,則稱為計劃重用。
??計劃重用比偶然重用有一個潛在的優點,這就是,專門為在將來的產品中使用而構造的那個構件更容易于重用,而且重用也更加安全。因為這樣的構件一般都有健全的文檔,并做過全面的測試,另外,它們通常有統一的風格,從而易于維護。
??但另一方面在一個公司內實現計劃的代價可能是很高的。對一個軟件構件進行規格說明、設計、實現、測試和編制文檔要花很多的時間,然而,這樣一個構件是不是能重用,所投資的成本能否回收不無保證。
1.2.4.3 構建重用
??在計算機剛問世時,沒有什么東西是可以重用的。每當開發一個產品時,所有項目都是從頭開始構造的。然而不久為后,人們意識到這是相當大的工作浪費,于是人們構造了子程序庫。這樣,程序員在需要時就可直接調用這些以前編寫好的例程,這些子程序庫越來越成熟,并開始出現運行時的支持程序。
??重用可以節省時間,縮短產品的開發期限同,使軟件開發公司更有競爭力。開發人員既可以重用自己的例程,也可以重用各種類庫或API,從而節省了大量的時間。相反,如果一個軟件產品要花經費4年的時間才能進入市場,而一個競爭產品只用2年就交付使用,那么,不管它的質量有多高,它的銷路也不會太好。開發過程的時間期限在市場經濟中是至關重要的,如果產品在時間方面沒有競爭優勢,那么談論怎樣才能生產一個好的產品是不切實際的。
??軟件重用是一項誘人的技術。畢竟,如果可以重用一個現有的構件,就不必再設計、實現、測試這個構件了。
1.2.4.4 重用的障礙
??據統計,對于任意軟件產品來說,平均只有15%是完全服務于原始的產品目的的,產品的另外85%在理論上可以進行標準化,并在將來的產品中重用。在實際中,通常只能達到40%的重用率并且利用重用來縮短開發周期的組織也很少。因為重用有許多的障礙。
- 自負
??從太多的軟件專業人員寧愿從頭重寫一個程序而不愿重用一個由其他人編寫的程序。他們認為,不是他們親自編寫的程序不可能是好程序。 - 經濟利益
??一些開發人員盡力避免編寫那些太通用的例程,唯恐使自己失業。當然,從每個軟件組織實際上有大量的積壓任務的情況來看,這種擔心是毫無根據的。 - 檢索
??一個組織可能有幾十萬個潛在的可重用的構件,為了提高檢索效率,如何存儲這些構件? - 代價
??重用構件的成本:制作重用構件的成本、重用的成本、定義和實現一個可重用過程的成本。有統計表明,制作一個重用構件在理想情況下可其成本只增加11%,一般情況下增加60%,而有的重用可能會增加200%甚至480%。 - 版權
??根據客戶和軟件開發公司之間的合同,軟件產品是屬于客戶的,當軟件開發人員為另一個客戶開發一個新產品時,如果重用了另一個客戶產品中的一個構件,本質上是一個侵犯第一個客戶的版權。
1.2.5 模塊的重要性(意義)
- 解決復雜問題的一種有效方法
- Miller法則:一個人任何時候只能將注意力集中在7±2個知識塊上。
- 軟件開發時,人們的大腦需要在一段時間內集中的知識塊數往往遠遠多于7個。
- 對一個復雜的問題解決轉化為對若干個更小問題的解決來實現。
- 集體分工協作的前提
??將一個產品分解成幾個相對獨立的模塊,這些模塊分配由幾個不同的小組開發。 - 產品維護的保障
??模塊間的相對獨立性使得修改其中一個模塊的內部代碼或數據結構不影響其他模塊。不僅為運行時的維護提供了可行性,還減少維護的費用。
1.3 軟件工程
1.3.1 軟件危機
1.3.1.1 背景
??在短短的幾十年中,計算機技術成為了現代社會的高科技的核心,其中硬件的發展是其他領域不可比擬的。中央處理器功能、存儲器的容量、集成工藝的提高、新興材料的研制、網絡等變革,使得計算機很快從實驗室走向應用,進入各行各業。計算機是社會信息化的基礎。
??然而,在軟件技術方面,雖然也以巨大的速度發展,但比起計算機的硬件發展,就是微不足道的了。特別是在應用領域,許多企事業單位、機關 團體中的計算機,其性能遠遠沒有得到充分的發揮。
??隨著計算機硬件的飛速發展,對計算機軟件的功能、結構和復雜性提出了更高的需求,在軟件的設計中,軟件的局部和整體系統的結構方面,已經越來越顯出其重要性,甚至超過了軟件算法和數據結構這些常規軟件設計的概念。軟件體系結構概念的提出和應用,說明了軟件設計技術在高層次上的發展并走向成熟。
1.3.1.2 定義
??開發大型軟件過程中﹐難以匯集參與人員的設計理念然后提供給使用者一致的設計概念(conceptual integrity)﹐因而導致軟件的高度復雜性,使得大型軟件系統往往會進度落后、成本暴漲及錯誤百出,就是所謂的軟件危機(software crisis)。
1.3.1.3 人月神話
??人月神話——二十多年前(1975)﹐IBM大型電腦之父──Frederick P. Brooks 出版的一本書。
??人月(man-month)":熟悉軟件項目管理的人員都清楚,人們常常根據人月來估計工作量(并相應收費),比如一個項目五人兩月完成,那么總工作量就是10人月。
??稱之為"神話"(Mythical),其用意也并非完全否定作為計量方法的人月,而是要理清這個概念中隱含的種種錯覺。
文中論點主要包括:
- 人/月之間不能換算,換言之,兩人做五個月完成,不等于說五人做兩個月就能完成;
- 在項目后期增加人手,只能使工期進一步推遲;
- 項目越大,單位工作需要的人月越多。
著名的Brooks法則
??Adding manpower to a late software project makes it later(對于進度已落后的軟件開發計劃而言﹐若再增加人力﹐只會讓其更加落后。)
??"人月"概念可以線性化的神話:無論是開發人員的人數上,還是工作量本身上的變化,都可能導致最終完成時間的非線性變化。
1.3.1.4 沒有銀子彈
??1986年,Brooks發表了一篇著名的論文──"No Silver Bullet: Essence and Accidents of Software Engineering"。他斷言﹕在10年內無法找到解決軟件危機的根本方法(銀彈)(There will be no silver bullet within ten years)。
??Brooks認為軟體專家所找到的各種方法皆舍本逐末。解決不了軟體的根本困難──即概念性結構(conceptual structure)的復雜,無法達到概念完整性。
??軟件開發的困難來自兩個方面:本質的和偶然的。本質的困難是軟件開發本身所固有的,無法用任何方式取消的,而偶然的困難是其中的非本質因素,可以通過引入新工具、方法論或管理模式來消除。關鍵在于,只要本質的困難在軟件開發中消耗百分之十以上的工作量,則即使全部消除偶然困難也不可能使生產率提高10倍。
軟件的本質
- 復雜性(complexity)
??“復雜”是軟件的根本特性。可能來自于程序員之間的溝通不良,而產生結構錯誤或時間延誤;也可能因為人們無法完全掌握程序的各種可能狀態;也可能來自新增功能時而引發的副作用等等。 - 一致性(conformity)
??大型軟件開發中,各小系統之界面常會不一致,而且易于因時間和環境的演變而更加不一致。 - 易變性(changability)
??軟件的所處環境常是由人群、法律、硬體設備及應用領域等各因素融合而成的文化環境,這些因素皆會快速變化。 - 不可見性(invisibility)
??軟件是看不見的。既使利用圖示方法,也無法充分表現其結構,使得人們心智上的溝通面臨極大的困難。
1.3.1.5 有一個銀子彈
??1990年﹐曾首先提出"Software IC"名詞的OO大師──Brad Cox針對Brooks的觀點而發表了一篇重要文章──"There Is a Silver Bullet"。說明他找到了尚方寶劍──即有些經濟上的有利誘因會促使人類社會中的文化改變(culture change)。人們會樂于去制造類似硬體晶片(IC)般的軟件組件(software component),將組件內的復雜結構包裝得完美,使得組件簡單易用。由這些組件整合而成的大型軟件,自然簡單易用。軟件危機于是化解了。
1.3.2 軟件工程的復雜性
1.3.2.1 建筑工程的經驗對軟件工程的啟發
??橋墩有時會坍塌,但出現的次數遠遠小于操作系統崩潰的次數。
??兩種故障的主要區別:土木工程領域和軟件領域對崩潰事件的理解態度不同。當橋墩坍塌時人們幾乎總是要對橋墩進行重新設計和重新建造,因為橋墩的坍塌說明該橋的最初設計有問題,這將威脅行人的安全,所以必須對設計作大幅度的改動,此外,橋墩坍塌后,幾乎橋的所有結構被毀掉,所以唯一合理的做法是將橋墩殘留的部分拆除再重新建造。更進一步地,其他所有相同設計的橋都必須仔細考慮,在最壞的情況下,要拆除重新建造。相比之下,操作系統的一次崩潰很少被認真考慮,人們很少立即對它的設計進行考察。當出現操作系統崩潰時,人們很可能只會重新啟動系統,希望引起崩潰的環境設計不再重現。在多數情況下,沒有去分析關于崩潰原因的證據,而且操作系統的崩潰引起的破壞通常中微不足道的。
??也許當軟件工程師們以土木工程師們對待橋墩坍塌那樣認真的態度來對待操作系統故障時,這種區別就會縮小。當然,人類關于橋梁的設計畢竟經歷了幾千年的歷史,而設計操作系統的經歷只不過短短50多年。隨著經驗的積累,將一定會像理解橋一樣充分地理解操作系統,構造出無故障的操作系統。
1.3.2.2 軟件工程的復雜性
- 軟件在執行時處于離散狀態。
??主存儲器中一個比特位(bit)的改變就會引起軟件執行的狀態改變,而這種狀態總數是巨大的,在設計初期無法完全測試。 - 軟件運行環境具有不可再現性。
??在采取多道程序設計后,一道程序在同一臺機器的多次執行,其運行環境(比如,程序的代碼被裝入的主存空間的位置、程序執行過程的速度等)幾乎不可重現。 - 硬件的復雜性
??軟件的功能要由硬件來實現,硬件的結構復雜多樣性,增加了軟件測試的難度。
1.3.3 軟件工程的內容
??軟件工程是以軟件系統為對象,合理地、創造性地采用軟件系統所需的思想、理論、技術、方法對軟系統進行研究分析、設計開發和服務,使軟件最大限度地滿足需求。
軟件工程的生命周期
- 需求分析
- 規格說明
- 計劃
- 設計
- 實現
- 集成
- 維護
- 終結
1.4 軟件體系結構的意義與目標
1.4.1 軟件體系結構的意義
- 軟件體系統結構是軟件開發過程的初期產品,為以后的開發、集成、測試、維護等階段提供保證。
- 與軟件過程的其他設計活動相比,體系結構的活動成本和代價要要低得多。
- 軟件體系結構的正確有效,給軟件開發帶來極大的便利。
1.4.2 軟件體系結構的目標
- 主要目標:建立一個一致的系統及其部件的視圖,并以提供能夠滿足終端用戶和后期設計需要的結構形式。
- 外向目標:建立滿足終端用戶要求的系統需求。了解用戶需要系統應該做些什么,擴展或細化結構,澄清模糊,提高一致性。
- 內向目標:如何使系統滿足用戶需求。為些需要建立哪些軟件模塊、分析它們的結構、相互間的關系和規范。正是對這些軟件上層部件的及其關系的規劃,為以后的系統設計和實施活動提供基礎和依據
1.5 軟件體系結構的研究現狀
1.5.1 軟件體系統結構的發展
- 程序抽象
- 20世紀50年代:匯編語言對機器語言的第一層抽象;
- 20世紀60-70年代:高級語言對程序描述的抽象,算法和數據結構的概念從程序中獲得抽象,軟件設計理論獲得根本發展。
- 20世紀80年代:建立在抽象數據類型上的面向對象技術和理論。
- 20世紀90年代:面向對象技術的廣泛應用:OLE、動態鏈接、ODBC、組件、RPC、CORBA、瀏覽器等,面向網絡、跨平的分布式環境等。
- 軟件工程
- 軟件工程(1967年)是對軟件工程設計的方法、技術和管理等方面的研究,為了實現軟件的工程設計,要在獨立于程序語言之外建立軟件構成的表達,就軟件所解決的問題建立概念的關系和模型。
- 20世紀70年代開始,提出和發展了軟件的結構分析和設計方法,數據字典、數據流成為程序結構的主要描述手段,E-R圖成了主要的信息概念模型甚至延用至今。
- 80年代,軟件工程設計方法了面向對象的分析和設計。
- 90年代,面向對象方法的廣泛發展,提出了諸如UML等多種面向對象的概念模型,并在軟件工程中獲得應用。
- 從某種意義看,這些模型和表達也是軟件體系結構的描述方法,只是它們更多地從信息處理的角度建立起來的。
- 體系結構
- 人們對軟件結構的關心,在20世紀50年代就開始了,在機器語言的控制流概念方面,人們尚不知道循環和條件結構描述,而是通過測試分支指令來實現這些結構。
- 高級語言的設計者更是認識到結構的用處,建立一套完整的程序結構描述,如循環、條件、過程調用,并通過開工形式化研究獲得進一步的確認。現在幾乎沒有人認為還需要發明新的循環、條件或其他程序描述結構。
- 直到90年代,軟件體系結構才開始受到全面的關注,并形成了新的軟件技術和工程的研究熱點。
1.5.2 軟件體系統結構的研究現狀
??一個好的結構設計是決定一個軟件系統成功的主要因素。
體系統結構的研究現狀其現狀具體表現在:
- 缺乏系統統一的概念和堅實的理論基礎
??軟件體系結構已經提出,從整體上把握軟件設計的重要性,并在結構的部件、部件關系(連接)上取得一致的認識。但部件和關系的描述、體系結構的基礎、體系結構與其他軟件研究的關系、體系結構與需求分析的關系都沒有取得全面統一的認識。 - 缺乏工程知識的系統化和標準化
??現有的涉及體系結構部件和連接器標準標準化的規范,都是來自特別應用問題或領域的,沒有來處建立在軟件體系結構總體認識上。例如,許多有用的結構范例,如管道、層次、C/S等,還只能應用于特定的系統,軟件系統的設計者還沒有設計出一些公用的系統結構的原理供人們選擇。 - 缺乏形式化,沒有建立統一的體系結構的工程描述方法
??在傳統的設計中,人們很早就使用系統框圖和非形式描述來表達軟件結構,可是這些描述都太含糊了、因人、因事而異,只憑經驗、直覺或個人愛好,沒有一個標準,不便于交流。
??體系結構的形式化研究已經受到極大的關注并取得一定的成果,但它們都只是多某全側面進行的,尚缺乏全面的適用性。
??在這方面Microsoft公司推出的.NET的公共語言規范(Common Language Specification)技術可能是一個重要發展。
目前,軟件體系結構已經成為軟件工程的從業者一個重要研究領域。
軟件體系結構的研究內容
- 風格(styles)
??研究部件間的相關關系,及合成和設計規則 - 設計模式(design patterns)
??建立在結構化和面向對象的基礎上,設計人員積累大量的經驗,發現并抽象在眾多的應用中普遍存在的軟件的結構及其關系,以此為模板實現軟件重用 - 結構描述語言(ADL)
??研究各種表達軟件構成的描述形式,作為軟件設計的結構表達的一些規范。
1.6 習題
- 什么是軟件體系結構?它有哪三種類型?
??一個軟件系統的體系結構是指構成這個系統的計算部件、部件間的相互作用關系。部件可以是客戶(clients)、服務器(servers)、數據庫(databases)、過濾器(filters) 、層等。部件間的相互作用關系(即連接器)可以是過程調用(procedure call)、客戶/服務器、同步/異步、管道流(piped stream)等。
??服務于軟件開發的不同階段,體系結構可分為概略型——是上層宏觀結構的描述,反映系統最上層的部件和連接關系;需求型——對概略型體系結構的深入表達,以滿足用戶功能和非功能的需求。設計型——從設計實現的角度對需求結構的更深層的描述,設計系統的各個部件,描述各部件的連接關系。這是軟件系統結構的主要類別。 - 軟件產品在實現時通常分解成一些較小的模塊,這種做法的意義是什么?分解時應遵循的原則是什么?
??解決復雜問題的一種有效方法;集體分工協作的前提,將一個產品分解成幾個相對獨立的模塊,這些模塊分配由幾個不同的小組開發;產品維護的保障,模塊間的相對獨立性使得修改其中一個模塊的內部代碼或數據結構不影響其他模塊。不僅為運行時的維護提供了可行性,還減少維護的費用。
??一個好的模塊設計應該使模塊具有高內聚性和低耦合性。
二、軟件體系結構風格
2.1 什么是軟件體系結構風格
2.1.1 什么是結構風格
??在許多工程學科,設計模式、風格的利用是非常普遍的。事實上,衡量一個工程領域是否成熟的一個重要指標,是看該工程領域是否就建就一套共享的通用設計形式。在軟件上也是這樣。在結構上,與之聯系的有,客戶/服務器系統(client-server system,C/S)、管道/過濾器設計(pipe-filer design,P/F)、層次結構(layered architecture)、在設計方法上的面向對象(object-oriented)、數據流(dataflow)等。
??在軟件設計的實踐中,人們發現某些特殊組織結構(如C/S結構,B/S結構、P/F結構)在許多的軟件系統中頻繁出現,這些特殊結構有很高的應用價值。于是人們就設想能否將這些特殊結構進一步發展規范,使它們成為一種相對固定的設計結構,并應用于新軟件產品。
??關于一個軟件系統的結構風格定義為組織該系統可用的各種結構模式。具體地說,就是系統的組件(component)、連接器(connector),以及它們的組合的約束條件(constraint)。
??一個軟件系統的結構包括構成系統的所有計算組件(computational component)、組件間相互作用(interacton)即連接器(connector)。用數學中的圖的概念描述,一個系統結構圖就是由節點(node)和邊(edge)組成,這里節點代表組件,邊表示組件間的連接器。
2.1.2 結構風格的分類
- 數據流系統(Dataflow systems)
- 批處理序列(Batch sequential)
- 管道/過濾器(Pipes and filters)
- 調用/返回系統(Call-return systems)
- 主程序/子程序(Main program and subroutine)
- 面向對象(OO system)
- 層次結構(Hierarchical layers)
- 獨立組件(Independent components)
- 進程通訊(Communicating processes)
- 事件系統(Event systems) ;
- 虛擬機(Virtual machines)
- 解釋器(Interpreters)
- 基于規則的系統(Rule-based systems)
- 倉庫(Repositories)
- 數據庫系統(Databases)
- 超文本系統(Hypertext system)
- 黑板系統(Blackboards)
2.2 常用結構風格
2.2.1 管道/過濾器(Pipes and Filters,P/F)
2.2.1.1 系統組織
- 在一個管道/過濾器組織的系統中,每個組件有一個輸入集(input set)和一個輸出集(output set),并從輸入集中讀取數據流,處理后產生的數據流送向輸出集。
- 組件稱為過濾器(Filters),數據流稱為管道(Pipes)。過濾器間按預定的順序工作,即一個過濾器的的輸出作為下一個過濾器的輸入。從第一個過濾器的輸入開始的,數據被逐步地處理直到完成。
- 從整個系統的輸入和輸出關系看,各過濾器可以對其輸入進行局部的獨立處理并產生部分的計算結果,過濾器的活動可以按以下方法激活:
- 后續的組件從過濾器中取出數據;
- 前續的組件向過濾器推入新數據;
- 過濾器處于活躍狀態,不斷地從前續組件取出、并向后續組件推入數據。
- 前兩種情況產生的是被動式過濾器(passive filter),最后的是主動式過濾器(active filter)。被動式過濾器是通過函數或過程調用的,而主動式過濾器是作為獨立的程序或線程任務激活的。
- 管道(Pipe)是過濾器之間的連接器(Connector),如果兩個主動式過濾器連接在一起,管道將對它們實施同步控制,管道是一個先進先出(FIFO)的數據緩沖區。
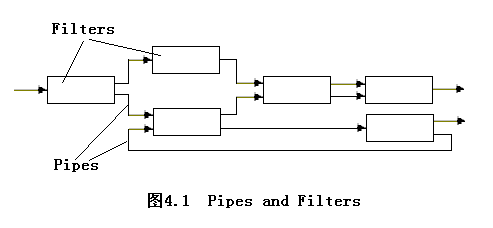
- 過濾器是獨立的運行組件。除了輸入和輸出外,其獨立性具體表現在:
- 過濾器(filters)之間不受任何其他的過濾器運行的影響,非相鄰的過濾器之間不共享任何狀態,甚至對于多次加工而言,過濾器自身也是無狀態的即每次加工后回到原始的等待狀態;
- 一個過濾器對其前繼或后續過濾器的設計和使用沒有任何的限制,惟一關心的是其輸入的到來形式、加工處理的邏輯和產生的輸出形式;
- 在整個結果的正確不依賴于各個過濾器運行的先后次序。對于原始的輸入,盡管其最終輸出形式的獲得需要經過特定的加工、并符合加工的順序要求,但在系統工作時,各過濾器只在輸入具備后獨立完成自己的計算,完整的計算過程包含在各個過濾器之間的拓撲結構(topology)中。
- 過濾器的拓撲結構(topology)
- 線性順序的管道(linear sequences filters)
- 界限管道(bounded pipes): 對管道中的駐留的數據的限制。
- 類型管道(typed pipes):對兩個過濾器間的數據有嚴格的類型定義。
2.2.1.2 評價
優點
- 使得軟構件具有良好的隱蔽性和高內聚、低耦合的特點;
- 允許設計者將整個系統的輸入/輸出行為看成是多個過濾器的行為的簡單合成;
- 支持軟件重用。重要提供適合在兩個過濾器之間傳送的數據,任何兩個過濾器都可被連接起來;
- 支持快速原型系統的實現。
- 具有自然的并發特性。過濾器可以獨立順序運行,也可以同時并發運行,從而增加了系統運行的靈活性,也使提高運行效率成為可能,尤其是網絡環境下的管道。
- 由于是通過獨立的過濾器的組合,系統具有清晰的拓撲結構,因而容易進行某些性能方面的分析,例如,數據吞吐量(throughput)、死鎖(deadlock)、計算正確性等。
缺點
- 通常導致進程成為批處理的結構。這是因為雖然過濾器可增量式地處理數據,但它們是獨立的,所以設計者必須將每個過濾器看成一個完整的從輸入到輸出的轉換。。
- 不適合于需要共享大量數據的應用設計。
- 不適合處理交互的應用。當需要增量地顯示改變時,這個問題尤為嚴重。
- 過濾器之間通過特定格式的數據進行工作,數據格式的設計和轉換是系統設計的主要方面,為了確保過濾器的正確性,必須對數據的句法和語義進行分析,這增加了過濾器設計的復雜性。
- 并行運行獲得高效率往往行不通。原因,第一,獨立運行的過濾器之間的數據傳送的效率會很低,在網絡傳送時尤其如此;第二,過濾器通常是在消耗了所有輸入后才產生輸出;第三,在單處理器的機器上進程的切換代價是很高的;第四,通過管道對過濾器的同步控制可導致頻繁啟動和停止過濾器工作。
2.2.2 數據抽象與面向對象組織(Data abstraction and Object-oriented Organization)
2.2.2.1 系統組織
??抽象數據類型概念對軟件系統有著重要作用,目前軟件界已普遍轉向使用面向對象系統。這種風格建立在數據抽象和面向對象的基礎上,數據以及施加于它們之上的操作封裝在一個抽象數據類型或對象中。這種風格的系統中組件(component)是對象(object),或者說是抽象數據類型的實例。對象是一種被稱作管理者(manager)的組件,因為它負責資源的表示(representation)。對象間的相互作用是通過函數(founction)和過程(procedure)調用(invocation)實現。連接器(connector)則是激活對象方法(method)的消息(message)。
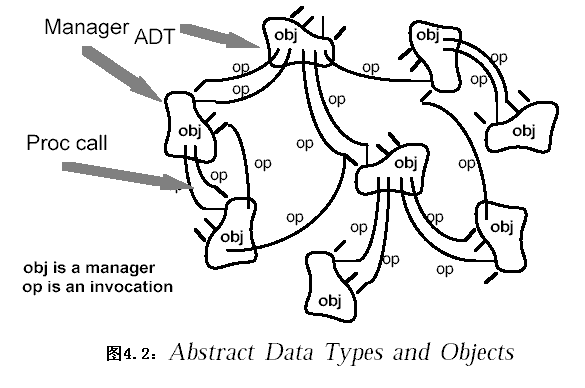
2.2.2.2 評價
優點
- 因為對象對其它對象隱藏它的表示,所以可以改變一個對象的表示,而不影響其它的對象。
- 設計者可將一些數據存取操作的問題分解成一些交互的代理程序的集合。
- 允許多個對象實現并發(concurrent)任務,對象間可有多種接口。
缺點
- 為了使一個對象和另一個對象通過過程調用等進行交互,必須知道對象的標識。只要一個對象的標識改變了,就必須修改所有其他明確調用它的對象。與此相比,管道/過濾器系統中一個過濾器就不必知道另一個過濾器而只需將處理結果按一定的形式輸出即可。因此,在面向對象(object-oriented)的系統中,一個對象(組件)的標識的改變,需要修改所有與之相互的對象(組件)。
- 必須修改所有顯式(explicitly)調用它的其它對象,并消除由此帶來的一些副作用(side-effect)。例如,如果A使用了對象B,C也使用了對象B,那么,C對B的使用所造成的對A的影響可能是料想不到的。
2.2.3 事件及隱含激活(Event-Based, Implicit Inovaations)
2.2.3.1 系統組織
??在面向對象的系統中,組件是一組對象,組件間的相互關系是通過直接的過程調用實現,這種方法的不足是組件(對象)標識必須是公開的,眾所周知(well-known)的。因此,人們考慮是否可以隱含激活(implicit invocation)或作用集成(reactive integration)。
??在一個基于事件的隱含激活系統中,組件不直接調用一個過程,而是觸發(announce)或廣播(broadcast)一個或多個事件(event)。系統中的組件事先注冊(register)它們感興趣的事件及對應的過程,將來,當一個事件被觸發(inovaation),系統自動調用在這個事件中注冊的所有過程,這樣,一個事件的觸發就導致了另一模塊中的過程的調用。
??從體系結構上說,這種隱含激活風格的組件是一些模塊,這些模塊是一些過程和一些事件的集合。過程可以用通常的方式調用,也可以在系統事件中注冊一些過程,當發生這些事件時,過程被隱含調用。
??基于事件的隱含激活風格的主要特點是事件的觸發者并不知道哪些組件會被這些事件影響。這樣不能假定組件的處理順序,甚至不知道哪些過程會被調用,因此,許多隱含調用的系統也包含顯式調用作為組件交互的補充形式。
??支持基于事件的隱含激活的應用系統很多。例如,在數據庫管理系統中確保數據的一致性(consistency)約束,在用戶界面系統中管理數據,以及在編輯器中支持語法檢查。例如在編程環境中,編輯器和變量監視器可以登記相應Debugger的斷點(breakpoint)事件。當Debugger在斷點處停下時,它聲明該事件,由系統自動調用處理程序,程序代碼自動滾動(scroll)到到斷點,變量監視器刷新變量數值。而Debugger本身只聲明事件,并不關心哪些過程會啟動,也不關心這些過程做什么處理。
2.2.3.2 評價
優點
- 為軟件重用(reuse)提供了強大的支持。當需要將一個組件加入現存系統中時,只需將它注冊到系統的事件中。
- 為擴充系統帶來了方便。當用一個組件代替另一個組件時,不會影響到其它組件的接口。
缺點
- 組件放棄了對系統計算的控制。一個組件觸發一個事件時,不能確定其它組件是否會響應它。而且即使它知道事件注冊了哪些組件的構成,它也不能確保這些過程被調用的順序。
- 數據交換的問題。有時數據可被一個事件傳遞,但另一些情況下,基于事件的系統必須依靠一個共享的倉庫進行交互,在這些情況下,全局性能和資源管理便成了問題。
- 難以保證正確性。
2.2.4 層次系統(Layers Systems)
2.2.4.1 系統組織
??層次系統組織成一個層次結構,每一層為上層提供若干服務(service),并作為下層的客戶(client)。在一些層次系統中,除了一些精心挑選的輸出函數外,內部的層只對相鄰的層可見。
??這樣的系統中組件在一些層實現了虛擬機(在另一些層次系統中層是部分不透明的)。連接器通過決定層間如何交互的協議來定義,拓撲約束限制了對相鄰層間交互。
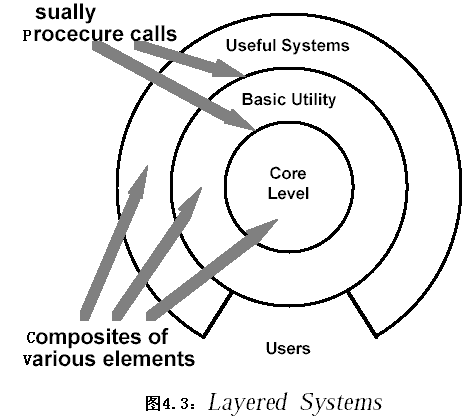
??層次系統(Layers Systems)最廣泛的應用是分層通信協議(如,OSI/RM)。在這一應用領域中,每一層提供一個抽象的功能,作為上層通信的基礎。較低的層次定義低層的交互,最低層通常只定義硬件物理連接。
2.2.4.2 評價
優點
- 支持基于層遞增的系統設計,使設計者可以把一個復雜系統按遞增的步驟進行分解。
- 支持(enhancement)功能擴充,與管道/過濾器系統一樣,因為每一層至多和相鄰的上下層交互,因此功能的改變最多影響相鄰的上下層。
- 支持重用(reuse)。只要提供的服務接口定義不變,同一層的不同實現可以交換使用。這樣,就可以定義一組標準的接口,而允許各種不同的實現方法。
缺點
- 并不是每個系統都可以很容易地劃分為分層的模式,甚至即使一個系統的邏輯結構是層次化的,出于對系統性能的考慮,系統設計時不得不把一些低級或高級的功能綜合起來。
- 很難找到一個正確層次的抽象方法。如,在通信協議中,雖然OSI/RM定義了7層協議,可是TCP/IP,IPX/SPX也都不是7層。
2.2.5 倉庫(Repositories)
2.2.5.1 系統組織
- 在倉庫(Repositories)風格的系統中,有兩種不同的組件:中央數據結構表示當前狀態,一組獨立組件執行在中央數據上,倉庫與外部組件間的相互作用在系統中會有大的變化。
- 控制原則(control discipline)的選取導致這種風格的兩個主要的子類。如果由輸入的事務類型觸發進程執行,則倉庫風格的系統是一種傳統的數據庫系統;如果由中央數據結構的當前狀態觸發進程執行,則倉庫是一個黑板系統。
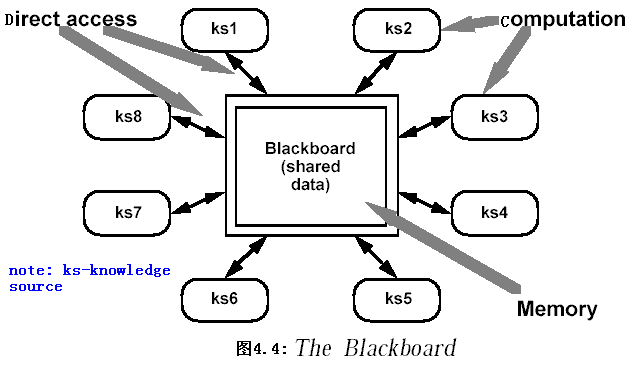
- 黑板系統實現的基本出發點是已經存在一個對公共數據結構進行協同操作的獨立程序集合。每個程序專門解決一個子問題,但需要協同工作完成整個問題的求解,這些專門的程序是相互獨立的,它們之間不存在互相調用,也不存在右事先確定的操作順序,操作次序是由問題求解的進程狀態決定的。
- 在黑板系統中,有一個中心操作組件,即黑板,它是一個數據驅動或狀態驅動的控制機制。它保存著系統的輸入、問題求解各個階段的中間結果和反映整體問題求解進程的狀態,這些是由系統的輸入和各個求解程序寫入的,因此被稱為黑板。
- 在問題求解過程中,黑板上保存了所有部分解,它們代表了問題求解的不同階段。形成了問題的可能解空間,并以不同的抽象層次表達出來,其中,最底層的表達就是系統的原始輸入,最終的問題求解在抽象的最高層次。
黑板系統主要由三部分組成
- 知識源(knowledge source)
- 知識源中包含獨立的、與應用的問題求解相關的知識(knowledge),知識源之間不直接進行通訊,它們之間的交互只通過黑板來完成。
- 知識源包含參與問題求解的條件的執行的操作,條件部分對黑板的信息和求解進程的狀態做出評估,在條件得到滿足時執行相應的操作;執行的操作可以是產生新的假設,也可以是對黑板上的數據結構的變換處理,操作的結果可能導致黑板上數據和狀態的變化,并引起進一步的處理。
- 黑板數據結構(blackboard data structure)
- 問題求解(problem-solving)的狀態數據(state data),是按照與求解進程的相關的層次來組織。通過黑板中知識源的不斷改變來體現一個問題的逐步解決。
- 控制(control)
- 控制黑板的數據和狀態的變化,并根據變化決定采取的行動。黑板狀態的改變決定使用的特定知識。
- 其中有一類特殊的知識源,它們用來確定問題求解的最終目標和終止求解的條件。
??黑板系統的傳統應用是信號處理領域,如語音和模式識別(speech and pattern recognition)。另一應用是松耦合代理(loosely coupled agent)數據共享存取。一些管道/過濾器系統(如編譯器)也可以設計為黑板系統。另個黑板系統也是人工智能廣泛使用的系統結構。
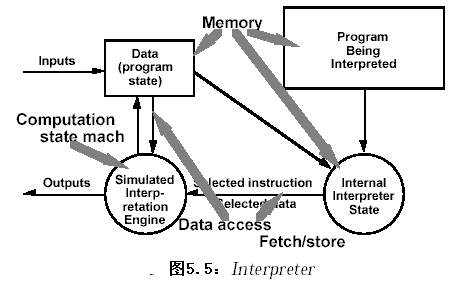
2.2.6 解釋器(Interpreters)
2.2.6.1 系統組織
??解釋器(interpreters)廣泛用于建立虛擬機(virtual machine),以減少程序的語義所期望的計算機器與硬件所提供的有效計算機器的差距。JVM-java語言虛擬機。
??一個解釋器系統由一個程序偽代碼(pseudoprogram)和解釋機(interpretation engine)。其中程序偽代碼包含程序代碼和執行的解釋中間代碼,解釋機包含解釋器的定義和執行的當前狀態的定義。
解釋器的由個部件組成
- 解釋機(interpretation engine):完成解釋工作;
- 程序源碼:待解釋的程序;
- 偽代碼(pseudocode): 用來解釋的中間代碼。
- 解釋機的當前狀態(current state of the interpretation engine)。
2.3 其他結構風格
- 分布式處理(Distributed Processes)
??分布式系統(distributed systems)多處理器系統的一個組織,客戶/服務器(client-server,C/S)結構則是組織分布式系統的主要方式。服務器(server)表現為一個進程,它向其他進程(client)提供服務或數據,通常服務器事先不知道訪問它的客戶的數量和標識(identity),客戶(client)則通過遠程過程調用(RPC)或消息傳遞(message passing)方式請求服務。 - 主程序/子過程調用(Main program/subroutine organiztions)
??系統由一個主程序(main program)和一組子過程(subroutines)組成,由主程序驅動調用所需要的子過程,通常主程序是運行一個循環順序地調用各個子過程。 - 確定域結構(Domain-specific)
??一種分布式系統的實現方式,服務程序用域(domain)管理,提供對象引用(reference)給客戶程序使用。 - 狀態變遷系統(State transition system)
??系統有一組狀態(state)集、一組狀態轉換函數,其中狀態集包括初始狀態集和終止狀態。系統接受一個輸入集,根據初始狀態依次驅動對應的狀態轉換函數。
2.4 案例分析
2.4.1 問題描述
??KWIC-Key Word Index in Contex(關鍵字索引),由Parnas在1972年提出的,問題描述如下:
??The KWIC [Key Word in Context] index system accepts an ordered set of lines; each line is an ordered set of words, and each word is an ordered set of characters. Any line may be “circularly shifted” by repeatedly removing the first word and appending it at the end of the line. The KWIC index system outputs a list of all circular shifts of all lines in alphabetical order.
??KWIC[上下文中的關鍵字]索引系統接受一組有序的行;每一行都是一組有序的單詞,每一個單詞都是一個有序的字符集。任何一行都可以通過重復刪除第一個單詞并將其附加在行的末尾來“循環移位”。KWIC索引系統按字母順序輸出所有行的所有循環移位列表。
2.4.2 解決方案
2.4.2.1 主程序/子過程調用(Main program/subroutine)
??系統由一個主程序(master control)和四個子過程:input、shift、alphabetize和output組成。
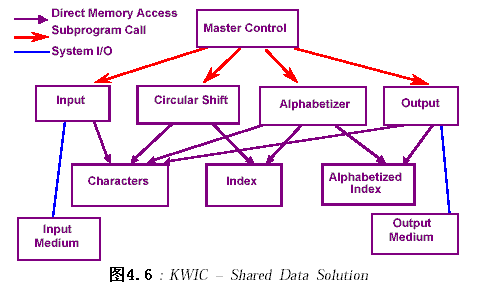
??四個子過程在主程序的控制下依次執行,子過程間的數據傳遞是通過共享的存儲區(磁盤)。
??在這種方法中,子程序間共享存儲區域,使得數據的表示效率高,節省了存儲空間;但這也帶來一些不足,數據結構的改變將影響到所有的四個子過程,不支持重用(reuse)。
2.4.2.2 數據抽象與面向對象組織(Data abstraction and Object-oriented Organization)
??系統同樣由五個模塊組成。
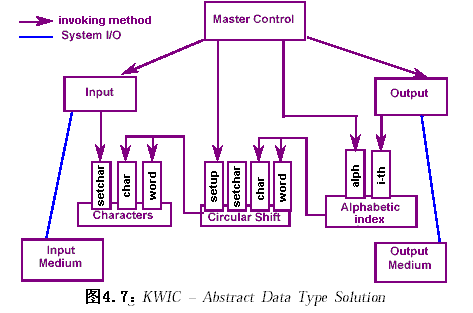
??但模塊間不再直接共享數據存儲區,每個模塊定義了一些方法,供其他模塊通過激活方法調用。
??在這種方法中,算法和數據表示封裝在模塊內,對它們的修改不影響其他模塊;支持重用。但不適合于功能的擴充,當增加一個新功能時,必須修改現有的模塊。
2.4.2.3 事件及隱含激活(Event-Based, Implicit Inovaations)
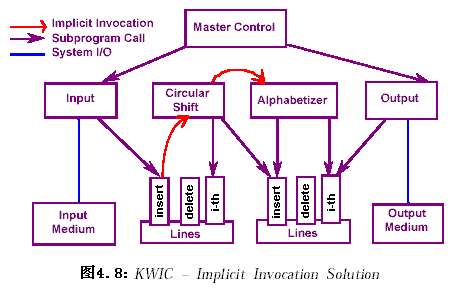
2.4.2.4 管道/過濾器(Pipes and Filters,P/F)
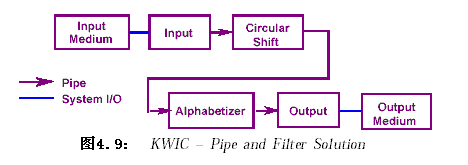
2.5 習題
- 總結P/F結構風格的缺點
(1)通常導致進程成為批處理的結構。這是因為雖然過濾器可增量式地處理數據,但它們是獨立的,所以設計者必須將每個過濾器看成一個完整的從輸入到輸出的轉換。
(2)不適合于需要共享大量數據的應用設計
(3)不適合處理交互的應用。當需要增量地顯示改變時,這個問題尤為嚴重。
(4)過濾器之間通過特定格式的數據進行工作,數據格式的設計和轉換是系統設計的主要方面,為了確保過濾器的正確性,必須對數據的句法和語義進行分析,這增加了過濾器設計的復雜性。
(5)并行運行獲得高效率往往行不通。原因,第一,獨立運行的過濾器之間的數據傳送的效率會很低,在網絡傳送時尤其如此;第二,過濾器通常是在消耗了所有輸入后才產生輸出;第三,在單處理器的機器上進程的切換代價是很高的;第四,通過管道對過濾器的同步控制可導致頻繁啟動和停止過濾器工作。
三、分布式體系結構分析
3.1 分布式處理結構風格概述
3.1.1 系統組織
組件:系統由多個可以獨立運行機制的部件組成,每個部件稱為組件;同時系統由多臺機器運行這些組件,這些機器共同協作完成系統的所有功能。
透明性:系統中的每個組件不需要關心其他組件的運行位置、實現方式及數量。
可靠性:當系統中的一個或少數幾個組件出現故障(關閉或崩潰)時,系統仍然可以工作,所出現的故障造成的影響多只是系統運行速度。
3.1.2 分布式處理結構風格的優缺點
注:3.1.2 小節來自CSDN文章《分布式優缺點》
3.1.2.1 優點
- 增大系統容量。我們的業務量越來越大,而要能應對越來越大的業務量,一臺機器的性能已經無法滿足了,我們需要多臺機器才能應對大規模的應用場景。所以,我們需要垂直或是水平拆分業務系統,讓其變成一個分布式的架構。
- 加強系統可用。我們的業務越來越關鍵,需要提高整個系統架構的可用性,這就意味著架構中不能存在單點故障。這樣,整個系統不會因為一臺機器出故障而導致整體不可用。所以,需要通過分布式架構來冗余系統以消除單點故障,從而提高系統的可用性。
- 因為模塊化,所以系統模塊重用度更高
- 因為軟件服務模塊被拆分,開發和發布速度可以并行而變得更快
- 系統擴展性更高
- 團隊協作流程也會得到改善
3.1.2.2 缺點
- 架構設計變得復雜(尤其是其中的分布式事務)
- 部署單個服務會比較快,但是如果一次部署需要多個服務,部署會變得復雜
- 系統的吞吐量會變大,但是響應時間會變長
- 運維復雜度會因為服務變多而變得很復雜
- 架構復雜導致學習曲線變大
- 測試和查錯的復雜度增大
- 技術可以很多樣,這會帶來維護和運維的復雜度
- 管理分布式系統中的服務和調度變得困難和復雜
3.1.3 構造分布式處理結構風格的主要技術
層次結構:組件的一種組織方式。
技術基礎:進程通信
RPC:進程通信的發展
組件技術:RPC的發展,如CORBA、J2EE等
云計算技術:分布式處理技術的最新發展。
區塊鏈:【具體內容在第十講】
3.2 分布式系統
3.2.1 分布式系統是計算機發展的必然產物
- 不斷推出功能強大的微處理器,價格便宜
??自1945年計算機的出現至1985年,計算機系統經歷了一場代替革命。開始,計算機系統龐大價格昂貴,各單位、組織的計算機擁有量很少,并且也僅僅是彼此獨立的。到了80年代中期,計算機領域的兩項新技術改變了這種狀況。 - 強有力的微處理器的發展
??開始是8位機,很快普及到16位.32位,甚至64位的微處理器,這些處理器的價格便宜。開始,一臺機器1千萬美元,每秒1條指令,現在1臺機器1千美元,每秒1千萬條指令。 - 高帶速網絡的發展
??使得局域網可將同一單位幾百臺的計算機連接起來,它們中少量數據可在1μs內在機間傳輸,而廣域網則能夠將全球范圍內成千上萬的機器連成一體協調工作。
??網絡的發展造成異構不可避免。一個原因是網絡技術隨著是不斷地改進,不同時間最好的網絡技術可能在同一網絡中共存;另一個原因是網絡大小不是固定不變的,任何一種計算機、操作系統、網絡平臺的組合都是為了能在一個網絡內使得某一部分的性能達到最好;還有一個原因就是在一個網絡內的多樣化使得它具有可選余地,因為在某一機器類型,操作系統或應用程序所出現的問題可能在其他操作系統和應用程序上不成其為問題。 - 在計算機網絡中工作站的CPU浪費嚴重
??在計算機網絡中,工作站之間的CPU無法共享、負載不平衡,在一個網絡中,計算中心的工作站的CPU往往承擔大量的計算,而許多辦公室中的工作站其CPU又多數是空閑。 - 單個微處理器的發展有極限
??處理器芯片集成度高,比特位的傳輸又產生巨大的熱量,雖然在理論上傳輸速度可以達到光速,而實際上,在遠遠未達到這處速度之前,可能會使處理器燒毀。
3.2.2 集中式系統和分布式系統
- 集中式
??只有一個CPU以及相應的存儲器.外圍設備和幾個終端組成的計算機系統。 - 分布式
??在硬件方面,很容易將若干臺機器通過物理線路連接起來,并且也可以實現對一些資源的共享,如數據、外圍設備。這些都只是計算機網絡的概念,但是要能實現CPU的共享、分散各地的CPU能協調地完成某項任務,還需要軟件的支持,這就是分布式操作系統。
??一個分布式系統就是一個由若干獨立的計算機組成的一個系統,該系統對其用戶來說,操作起來就就像一臺計算機一樣。
一個常見的分布式系統的例子
??某學校的網絡中,每臺工作站都可以獨立工作,我們將網絡中的各個工作站的CPU組成一個CPU池,每個CPU并不指定分配某個工作站的用戶而是可以根據需要動態地將某個CPU分配給某個用戶。在這個網絡中,也只有一個文件系統,所有機器都可以用同一方式和同樣的路徑來訪問系統中的所有文件。比如一個用戶在自己的工作終端上輸入一個命令,系統將找到一個最佳的位置為其運行命令,可能是在自己的工作站上,也可能是在某一臺機器上暫時沒有工作的CPU上執行,或者是系統中某個尚未分配出去的CPU上執行。如果這個系統看上去像一個整體,而又像單處理器系統那樣工作,我們就可稱之為分布式系統。
3.2.2 分布式系統的優點
- 經濟上——分布式系統提供更高的性能/價格比
??通常價格與處理器能力的平方成正比。
??假定一個分布式系統由 n 個獨立的計算機組成,其中計算機 i 有一個CPU其計算能力為 Pi,那么這個分布式系統的計算能力 P = ∑ i = 1 n P i P=\sum_{i=1}^n P_i P=∑i=1n?Pi? - 運行速度
??分布式系統的計算能力是系統中各個獨立計算機計算能力的總和。這使得分布式系統不僅有更高的性能/價格比,并且其計算能力是集中式系統不可達到的。比如:
??由 10 000 個CPU組成的分布式系統,每個CPU的執行速度為 50MIPS,該系統總的執行能力為 50MIPS*10,000。而對單個處理器而言,要達到這個程度,一條指令必須在 0.002ηs 內完成,這在理論上都是不可能的(因為將要求電子在芯片中的運行速度要超過光速). - 應用領域的需要
??有些應用領域需要是分布式系統:比如商業分布式系統。超市連鎖店系統中,對每個分店,可獨立營銷,時刻掌握本店的庫存情況,而高層管理人員也需要時刻了解各個分店的情況。最好的作法就是建立一個分布式系統將各個分店連結起來形成一個整體。
??另外,計算機支持協調工作:有一群決策成員彼此分散各地,而共同完成一個主題。 - 可靠性
??分布式系統比集中式系統具有更高的可靠性,由于分布式系統有多個機器,單個芯片的故障,不會影響整個系統的工作,而至多只是降低系統的計算能力。 - 擴充性
??計算能力可以逐步增加。 - 適應性
??在分布式系統中,工作量以有效的方式分布于可使用的機器上
3.2.3 分布式系統的不足
- 軟件——適用于分布式系統的軟件很少
??到目前為止,還沒有一個成熟的實用的分布式操作系統、程序設計語言、以及適合的應用軟件。
??可喜的是,這方面的研究工作不斷進展,軟件問題將不再存在。OMG組織的CORBA規范就是一個很好的例子,可用于開發分布式應用系統。 - 通訊網絡——網絡飽和以及其他問題
??分布式系統的硬件基礎是計算機網絡,網絡使分布式系統的優點受到影響。
??當現有的網絡飽和時,必須重新規劃新的網絡或增加第二個網絡,從而帶來布線等方面的不便和開銷
??網絡通信信息可能會丟失,為此需要特殊的軟件來恢復,但它將使網絡負荷增加。 - 安全性——保密的數據也變得容易存取
??數據容易有利有弊:如果人們很容易地訪問系統上的所有數據,他們也可很方便地查看與他們無關的數據。為此人們不喜歡自己的機器上網。
??盡管有這些潛在的問題,人們還是覺得利大于弊,并預計分布式系統將越來重要,事實上,不久的將來,有更多的組織、單位要求連接自己的機器構成一個大的分布式系統,提供更好、更經濟、更方便的服務。一個獨立的計算機系統在中、大型企業、組織將不再存在。
3.3 客戶/服務器(Client/Server)結構
3.3.1 C/S結構
??在一個信息處理系統中,通常由若干臺計算機組成。其中用于提供數據和服務的機器,稱為服務器(Server),向服務器提出請求數據和服務的計算機稱為客戶(Client),這樣的系統工作模型稱為客戶/服務器(Client/Server)模型,簡稱C/S模型。
??在廣義上說,客戶、服務器也可以是進程。因此,C/S模型可以在單處理器的計算機系統中實現。
??在多計算機或多任務的單處理器系統中,C/S模型有多種組織方式:單客戶單服務器、單客戶多服務器、多客戶單服務器、多客戶多服務器等。
3.3.2 C/S模型的軟件結構的特點
- 簡化軟件產品的設計
??這種結構把軟件分成兩個部分,客戶部分可專門解決應用問題、界面設計、人機交互等方面,服務器則側重于服務操作的實現、數據的組織,以及系統性能等。 - 提高軟件的可靠性
??在這種結構風格的系統中,不僅客戶與服務器是獨立的,服務器與服務器之間也是獨立的,一個服務由一個服務器完成,它不影響其他服務器的工作。 - 適合分布式計算環境
??C/S模型的軟件中,Client與服務器之間的通信通常是以消息傳遞方式實現,對客戶來說,它只關心服務請求的結果能正確地獲得,而至于服務的處理是在本地還是在遠程并不重要。
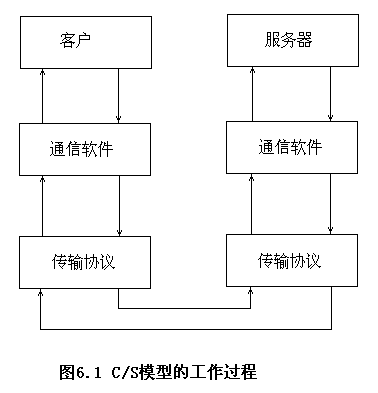
3.3.3 C/S模型的工作過程
- 客戶方處于主動,向服務器提出服務請求,而服務器處于被動,服務器進程啟動后,就處于等待接收客戶的請求,當請求到達時被喚醒;
- 客戶方以通常的方式發出服務請求,由客戶機上的通信軟件把它裝配成請求包,再經過傳輸協議軟件把請求包發送給服務器方;
- 服務器中的傳輸協議軟件接收到請求包后,對該包進行檢查,若無錯誤便將它提交給服務器方的通信軟件進行處理;
- 服務器通信軟件根據請求包中的請求,完成相應的處理或服務,并將服務結果裝配成一個響應包,由傳輸協議軟件將其發送給客戶;
- 由客戶的傳輸軟件協議把收到的響應包轉交給客戶的通信軟件,由通信軟件做適當的處理后提交給客戶。
3.3.4 數據共享的方式
- 數據移動共享
- 計算移動共享
3.3.5 C/S的連接
- 使用消息傳遞的方式
??這就是上講中的基于消息傳遞的通信方式,連接可以是同步的也可以是異步的。 - 使用過程的方式
??每個部件之間通過良好的接口定義與其他部件通信,這種方式的技術被稱為過程過程調用(Remote procedure call,即RPC),通常RPC是采用同步的連接。 - 使用對象引用方式
??這是目前普遍采用一個跨平臺分布式軟件的設計技術。
3.3.6 C/S的服務器設計、實現關鍵
- 服務器的調度任務和調度方式
??服務器的調度任務是解決多客戶和多請求同時執行的問題。作為獨立工作的服務器,無法確定什么時間會發生多少的客戶請求,所以它必須隨時準備,處理來自不同的客戶的請求,如果服務器已經無能為力處理新的請求,它必須以一定的策略建立等待隊列或通知客戶不能立即處理請求。
??現在,基于應用層的服務器都是運行于多任務的操作系統上,甚至是支持線程的操作系統,使用服務器對客戶的請求可以采用進程調度方式(process scheduling) 和線程調度(thread scheduling)方式。
??當有多個請求到達時,服務器必須按一定的方式來為每個請求服務,這種方式稱為服務器的調度方式。
??基于進程的調度方式:主服務器進程每收到一個消息,就創建一個子進程并回到循環的頂部,由子進程(從服務器(salve))負責消息的處理。 - 線程技術
【第4講進行介紹】 - 服務器緩沖技術
【第4講進行介紹】
3.3.7 C/S案例
3.3.7.1 文件服務器的設計
- 消息格式設計
??發送進程標識(source)
??接收進程標識(dest)
??請求服務類型(opcode)
??傳送的字節數(count)
??文件讀/寫指針(offset)
??備用1(reserved1)
??備用2(reserved2)
??服務結果(result)
??訪問的文件(name)
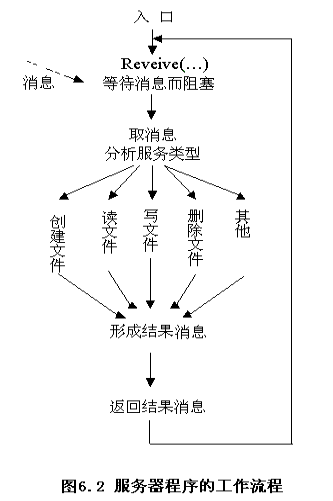
??數據緩沖區(data) - 服務器的工作流程
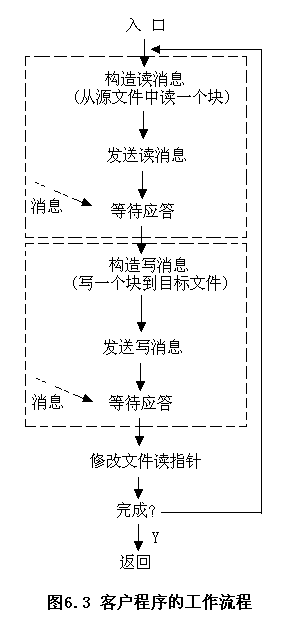
- 客戶程序工作流程
客戶程序將服務器中的一個文件的信息寫到另一個空文件(目標文件)中
3.3.7.2 文件服務器的C語言實現(部分)
- 頭文件 header.h
#define MAX_PATH 255
#define BUF_ZISE 1024
#define FILE_SERVER 243
#define CREATE 1
#define READ 2
#define WRITE 3
#define DELETE 4
#define OK 0
#define E_BAD_OPCODE -1
#define E_BAD_PARAM -2
#define E_IO -3struct message{
long source;
long dest;
long opcode;
long count;
long offset;
long result;
char name[MAX_PATH];
char data[BUF_SIZE];
};
- 服務器程序
#include <header.h>int main() {struct message m1,m2;int r;while (1) {receive (FILE_SERVER, &m1);switch (m1.opcode) {case CREATE:r=do_create(&m1,&m2);break;case READ:r=do_read(&m1,&m2);break;case WRITE:r=do_write(&m1,&m2);break;case DELETE:r=do_delete(&m1,&m2);break;default:}m2.result=r;send (m1.source, &m2);}
}
- 客戶端程序
long copy(char *src,char *dst) {struct message m1;long position;long client = 110;initialize();position=0;do {m1.opcode=READ;m1.offset=position;m1.source=client;m1.count=BUF_SIZE;strcpy(m1.name,src);send(FILE_SRVER,&m1);receice(client,&m1);if(m1.result<=0) break;m1.opcode=WRITE;m1.offset=position;m1.count=m1.result;m1.source=client;strcpy(m1.name,dst);send(FILE_SERVER,&m1);receive(client,&m1);position+=m1.result;} while(m1.result>0);return(m1.result>=0?OK:m1.result);
}
四、分布式體系結構關鍵技術
4.1 基于消息傳遞的通信(分布式進程的通信)
4.1.1 發送操作(send primitive)
格式:send(dest;&mptr)
參數:dest——把消息發送具有dest標識符的進程,mptr——表示要發送的消息的地址。
作用:將指定的消息發送到接收進程
4.1.2 接發操作(receive primitive)
格式:receive(addr;&mptr)
參數:addr——等待消息到達的接收進程的地址,mptr——指針,表標消息到后存放何處。
作用:用地址addr偵聽,所需的消息。
4.1.3 阻塞(Blocking)操作
阻塞操作也稱同步操作(synchronous primitive)
- 阻塞發送操作(Blocking send primitive)
??當一個進程調用一個send操作時,它指定一個目標進程和一個緩沖區,調用send后,發送進程便處于阻塞狀態,直到消息完全發送完畢,send操作的后繼指令才能繼續執行。 - 阻塞接收操作(Blocking receive primitive)
??當一個進程調用receive操作時,并不返回控制,而是等到把消息實際接收下來并把它放入參數mptr所指示的緩沖區后,才返回控制,并執行該操作的后繼指令。在這段時間里進程處于阻塞狀態。
特點
- 通信可靠,緩沖區可以重復使用;
- CPU空等,不具有并行性。
4.1.4 非阻塞操作(Nonblocking primitive)
非阻塞操作也稱異步操作(asynchronous primitive)
- 非阻塞send操作
??如果send操作是非阻塞的,它在消息實際發送之前,就立即把控制返回給調用進程,即發送進程在發送消息時并不進入阻塞狀態,它不等消息發送完成就繼續執行其后繼指令。 - 非阻塞receive操作
??當進程調用receive操作時,便告訴內核緩沖區的位置,內核立即返回控制,調用者不阻塞狀態。
非阻塞操作的特點
- 提高系統的并行性
??發送進程可在消息實際發送過程中進行連續的并行計算,而不是讓CPU等待。 - 緩沖區只能使用一次
??發送進程在消息發送完之前,進程不能修改緩區,在消息傳送期間進程改寫消息緩沖區可能引起可怕的后果,而何時允許使用緩沖區,卻無法得知。這樣緩沖區只能使用一次。
非阻塞操作的兩種改進方法
- 帶拷貝的非阻塞send操作(Nonblocking with copy to kernel)
??讓內核把消息拷貝到內核的內部緩沖區,然后允許進程繼續運行。
??優點:調用進程一旦得到控制,就可以使用緩沖區;消息是否發送完成,對發送進程沒有影響。
??缺點:每個被發送的消息都要從用戶空間拷貝到內核空間(額外拷貝),使系統的性能大大降低其后,網絡接口將消息拷貝到硬件傳送的緩沖區) - 帶中斷非阻塞send操作 (Noblocking with interrupt)
??當消息發送完畢后,中斷發送進程,通知發送進程此時緩沖區可用。
??優點:不需要消息的拷貝,從而節省時間;高效且提高了并行性。
??缺點:由于用戶中斷,使編程的難度增加;程序不能再現,給程序調試帶來困難;基于中斷的程序很難保證正確且出錯后幾乎不能跟蹤。
4.1.5 非緩沖操作(unbuffered primitives)
??系統提供一個消息緩沖區,用于存放到來的消息。接收進程調用receive(addr,&mptr)時,機器用地址addr在網上偵聽,當消息到來后,內核將它拷貝到緩沖區,并將喚醒接收進程。
- 非緩沖通信操作-拋棄非期望消息 (discard the unexpected message)
??receive(addr,&mptr)告訴它所在的機器上的內核,用地址addr 偵聽,并準備去接收發送給addr的一個消息,當有消息到達后,如果非該地址的消息則拋棄,否則接收進程的內核將它拷貝到mptr所指示的緩沖區,并喚醒該接收進程。
特點- 一個地址聯系一個進程;
- 若服務器調用在客戶調用send之前,非常有效。
- 如果send操作在receive之前已經完成,則服務器內核就不知道到達的消息拷貝何處。只好拋棄這個非期望的消息,并采用超時重傳機制。
- 假定有兩個或更多個客戶使用同一個服務器,當服務器從他們之中的一個客戶收到一個消息后,在它未完成處理之工作之前,不再用這個地址去偵聽發送,在它返回到循環頂部重新調用receive之前,由于要進行相應的處理工作需要花費一些時間而其他客戶可能多次嘗試發送消息給它,并且有些客戶可能放棄。在這種情況下,客戶是否繼續重發,取決于重 發計時器的值以及他們的忍耐程度。
- 消息丟失的機會大。
- 非緩沖通信操作-消息保留一段時間(keep incoming messages for a little while)
??讓接收內核對傳送來的消息保留一段時間,以便使得一個合適的receice操作能很快地接收:一個非期望的消息到來時,就啟動一個計時器,如果計時器在走完之前仍無合適的receive出現,就將該消息丟棄。
特點- 減少消息丟失的機會;
- 如何存儲和管理過早到達的消息存在問題。
4.1.6 緩沖通信操作-信箱(mailbox)
??一個希望接收消息的進程要告訴內核為其創建一個信箱,并在網絡消息包中指定一個可供查詢的地址,然后,包含這個地址的所有到達的消息都被放進信箱。現在調用receive就可以從信箱中取出一個消息,如果沒有消息就阻塞(假定用阻塞操作)。
特點
- 減少消息丟失和客戶放棄消息所引起的一系列問題;
- 信箱是有限的,有可能裝滿而造成消息的丟失。
4.1.7 不可靠(Unreliable)操作
??不可靠send操作:系統不保證消息能被對方正確接收,要想實現可靠的的通信,由用戶自己完成。
4.1.8 可靠(Reliable)操作
- REQ—ACK—REP—ACK
??客戶向服務器發送一個請求(REQ),服務器對這一請求由內核向客戶機內核返回一個確認(ACK),當客戶機內核接收到這一確認后,釋放這一用戶進程。
說明- 確認(ACK)只在內核間傳遞,客戶和服務器進程都看不到這樣的過程;
- 服務器到客戶的應答也存在REP-ACK的過程。
- REQ—REP—ACK
??客戶在發送一個消息后被阻塞,服務器內核并不返回一個確認(ACK),而是利用應答(REP)本身作為一個確認(ACK),客戶如果等待時間太長,其內核可重發一個請求,以防請求消息丟失。客戶在收到應答(REP)后,向服務器發送一個確認(ACK),服務器在發送應答后處于阻塞狀態,直到確認(ACK from client’s kernel),服務器也可以采用超時重傳機制。 - REQ—(ACK—)REP—ACK
??是一種折衷的方案:當一個請求到達服務器內核時,就啟動一個定時器,如果服務器送回應答足夠快(計時器時間未到)則應答(REP)充當一個確認(ACK);如果定時器時間到就送一個單獨的確認(ACK)。于是大多數情況下,僅需要兩條消息:請求和應答,在復雜情況下,需要另一個確認(Acknowledgement)消息。
4.2 遠程過程調用(RPC)
4.2.1 RPC概述
4.2.1.1 RPC的基本思想
??(1984年,Birrell,Nelson)允許程序調用位于其他機器上的過程,當機器A上的一個進程調用機器B上的過程時,在A上調用進程被掛起,在B上執行被調用過程,過程所需的參數以消息的形式從調用進程傳送到被調用過程,被調用過程處理的結果也以消息的形式返回給調用進程。而對程序員來說,根本沒有看出消息傳遞過程和I/O處理過程,這種方式稱為遠程過程調用(remote procedure call——RPC)。
4.2.1.2 RPC例子
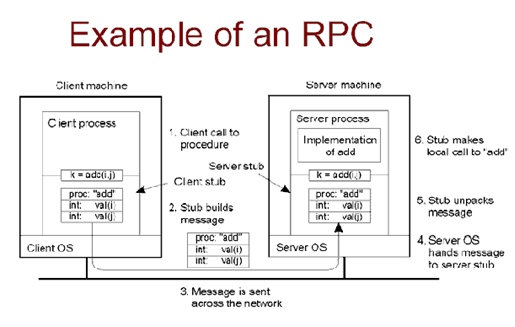
傳統的過程調用
count = read(fd, buf, nbytes)
操作系統隱藏了具體的寫數據,對程序員來說也看不到這一過程。
參數傳遞的方式:
- 按值傳送(call-by-value)
- 按地址傳送(call-by-reference)
- 拷貝/恢復(call-by-copy/restore)
4.2.2 RPC的透明性(transparent)
4.2.2.1 RPC透明性
客戶——調用進程所在的機器
服務器——被調用過程所在的機器
??RPC透明性的思想使得遠程過程調用盡可能象本地調用(內部過程調用)一樣,即調用進程不關心也不必知道被調用過程的位置(在本地或遠程另一臺計算機);反過來也是如此,被調用過程也不關心是哪臺機器上的進程調用,只要參數符合要求即可。
4.2.2.1 RPC透明性的實現
- 客戶代理(client stub)
??將參數封裝成消息,
??請求內核將消息送給服務器
??調用receive操作進入阻塞狀態
??當消息返回到客戶時,內核找到客戶進程,消息被復制到緩沖區,并且客戶進程解除阻塞
??客戶代理檢查消息,從中取出結果,并將結果復制給它的調用進程 - 服務器代理(server stub)
??調用receive操作,處于阻塞狀態,并等待消息的到來當消息到達后,代理被喚醒
??將消息分解,并取出參數
??以通常方式調用服務器的過程
??調用結束并獲得控制后,把結果封裝成消息
??調用send操作發送給客戶重新調用receive等待下一個消息
RPC的工作步驟
- 客戶進程以通常方式調用客戶代理
- 客戶代理構造一個消息,并自陷進入內核
- 客戶內核發送消息給遠程內核(服務器)服務器
- 內核把消息送給代理服務器
- 服務器代理從消息中分解出參數,并調用服務器進程
- 服務器進程完成其工作,并返回給代理
- 服務器代理封裝結果,并自陷內核
- 遠程內核發送消息給客戶內核
- 客戶內核將消息傳給客戶代理
- 代理分解消息取出結果,返回給調用進程。
4.2.3 參數傳遞(Parameter Passing)
??客戶代理的功能之一是取出參數,將它們封裝成消息,然后發送給服務器代理。表面上看,好像很簡單,但實現起來并不是如此。下面我們將討論RPC系統中參數傳遞的有關問題。
- 參數整理(Parameter Marshaling)
??將參數封裝成消息的工作 - 參數傳遞中存在的問題
- 系統中不同機器的字符集可能不同
- 分布式系統中客戶機與服務器可以是不同類型的
??例如:IBM工作站使用EBCDIC字符集,而 IBM PC機使用ASCii字符集 - 系統中不同機器的數據存儲方式可能不同
??Intel CPU 整數從右到左存儲(小端),SPARC CPU 整數從左到右存儲(大端) - 浮點數的位數可能不同
- 布爾值的表示
- 網絡傳送按字節
解決方案
- 參數按值傳遞
??設置一個基本類型的標準,正則表(canonical form),描述字符集類型,數據存儲方式及長度(位數)等。過程所需的參數,客戶代理在進行參數整理時按canonical form轉換為標準類型,然后封裝成消息發送。服務器代理收到消息后,也根據該標準映射到本地機器的字符集和數據類型。 - 參數按地址傳遞
1:copy/restore方法
2:指出是輸入參數(in parameter)還是輸出參數(out parameter) - 指針參數的傳遞
??動態傳送:指針值存入寄存器,通過寄存器間接尋址 - 用戶定義類型的數據傳遞
4.2.4 動態聯編(Dynamic Binding)
問題的提出:客戶端如何定位到服務器
方法:動態聯編
聯編(binder)——一個程序,功能:
- 登記(register)
- 查找(lookup)
- 撤銷(unregister)
服務器(export):啟動時 register,unregister
客戶:lookup
動態性:
- 服務器啟動時,export for register
- 服務器關閉時,export for unregister;
- 服務器故障時,定期輪詢(客戶代理),對無響應的過程 unregister。
聯編表(list)
| name | version | handle | unique id |
|---|---|---|---|
| read | 3.1 | 1 | 1 |
| write | 3.1 | 1 | 2 |
| close | 3.1 | 1 | 3 |
動態聯編的靈活性(flexible)
- 均衡工作量(load balancing)
??支持多服務器(support multiple servers),把客戶均衡地分布于各個服務器上; - 容錯性(fault tolerance)
??定期轉詢服務器(poll the server perodically),對無響應的過程unregister,到達一定程度的容錯性 - 支持權限
??服務器可以指定由哪些用戶使用,這樣聯編對非授權的用戶拒絕接受。
動態聯編的缺點(disadvantages)
- 花費系統時間:the extra overhead of exporting and importing interfaces costs time.(導出和導入接口的額外開銷會耗費時間。)
- 客戶進程往往執行時間短,但每次每個進程要重新 import to binder(導入動態聯編)
- 瓶頸(bottleneck):use multiple binders(使用多重綁定)
4.2.5 RPC表示錯誤的語義(Semantics in the Presence of Failures)
??RPC的設計目標是隱藏通信過程,使得遠程過程調用像本地調用一樣,但也有一些另外,如不能處理全局變量,事實上,只要客戶和服務器能正常工作,RPC就應該可以正常工作。下面的問題是當客戶或服務器出錯誤時的處理方法。
RPC可能出現的錯誤及處理方法
- 客戶不能找到服務器(client cannot locate the server)
??客戶不能找到合適的服務器,可能原因:服務器可能關閉或服務器軟件升級。
這種錯誤目前尚無好的辦法,需要指出,我們不能試圖通過返回錯誤代碼來實現,因為代碼可能剛好是一個正常的返回值。 - 從客戶到服務器的消息丟失(lost request)
??客戶發出的請求到達服務器之前丟失,服務器根本不能響應。
??解決方法:超時重傳機制 - 從服務器到客戶的應答丟失(lost reply)
??丟失應答非常難以處理,簡明的解決方法是依賴于超時重傳機制,發出的請求在一個合理的時間內沒有應答,就再發送一個請求。這種方法的問題是,客戶內核無法確定為什么沒有應答,是否請求或應答丟失?或許只是服務器速度慢?
??同一有效性(idempotent):服務器上有些操作可以安全地重復執行多次,而對數據不影響,如果某一請求的操作具有這一屬性,則稱為同一有效性(ide不mpotent)。多數請求都不具有同一有效性。
??解決方案:客戶內核給每個請求一個序列號,服務器內核則保留每個請求最近接收到的序列號。這樣,服務器就可以通過這個序列號來區別一個請求是重發的還是原來的,對重傳的請求拒絕響應。另外,也可以在消息中增加一個位來提示該請求消息是原來的還是重發的,對于原請求可以安全地進行處理,對于重發的請求,則處理要十分小心(服務器保留一個副本,是一種有效的辦法)。 - 服務器接收了請求后崩潰(server crash)
重傳機制的語義- 至少一次語義(at least once semantice):客戶等等直到服務器重啟并再次執行操作:客戶繼續重試,直到獲得一個應答為止。可保證RPC至少執行一次。
- 至多一次語義(at most once semantics):立即放棄報告失敗。保證RPC至多執行一次,但可能沒有執行。
- 精確一次語義(exactly once semantics):精確一次處理意味著一個消息只處理一次,造成一次的效果,不能多也不能少。
- 客戶發送請求后崩潰(client crash)
客戶在發送給服務器請求后而在應答收到之前崩潰的情況。
孤報(orphan)及其存在的問題- 孤報(orphan):a computation is active and no parent is waiting for result. Such unwanted computation is call Orphan.(計算是活躍的,并且沒有父級在等待結果。這種不需要的計算被稱為Orphan。)
- 孤報(orphan)存在的問題:
- 浪費CPU時間;
- Orphan可能鎖住某些文件或占用有價值的資源;
- 當客戶機重啟時,來自Orphan的應答造成應答混亂.
- 孤報(orphan)的解決方法【1981年Nelson提出了四種的解決方法】
- 消滅(extermination)
??思想:客戶代理在發送RPC消息后,代理進行事務登錄(log),記錄發送的請求,重啟時,檢查事務登錄,Orphan被撤消。
??缺點:磁盤空間浪費;orphan可能引起新的RPC導致更多的orphan,客戶重啟后,無法找到它們;網絡分區:網絡被分成兩個獨立的部分,客戶所在的另一個部分中的orphan仍能活動(不是一種可靠的方法)。 - “再生”(reincarnation)
??思想:將時間按順序分成時間段,每一段的一個序號,當客戶重啟時,廣播一個消息告訴所有的主機新的時間段的開始。機器收到這樣的廣播消息后, 所有的過程計算被撤消。對于已發出的應答,由于消息中含有時間段序號而客戶可以很容易地區別它們。
??缺點:那些有效的計算也被刪除 - 合理再生(Reasonable regeneration)
??思想:當機器收到新的時間段的廣播廣消息后,每臺機器檢查是否有遠程計算,如果有則試著找出它們的客戶,若能找到客戶(主人),則繼續它的計算,否則將遠程計算撤消。
??缺點:系統開銷大。 - 期滿(expiration)
??思想:每個RPC都給對方一個標準的時間量T,來作為它的工作期限,如果它在T時間內不能完成工作,客戶必須重新請求,以保證每個RPC就可以在T時間內完成。當有客戶崩潰后,在客戶機重起之前等待一個時間量T,這樣可保證所有的Orphan已發送。
??缺點:時間量T的取值比較復雜。
- 消滅(extermination)
4.2.6 RPC的實現
4.2.6.1 RPC協議是選擇面向連接的還是非連接的協議
- 面向連接的協議
優點:通信實現容易:內核發送消息后,它不必關心它是否會丟失,也無須處理確認,而這些方面都由支持連接的軟件來實現。
缺點:性能較差(需要額外的軟件)。 - 面向非連接的協議
優點:性能較好
缺點:信息可能丟失
在單一建筑物和校園內使用的分布式系統可以采用面向連接的協議。
4.2.6.2 RPC協議是選擇標準通用的還是RPC專用的協議
??要使用自定義的RPC協議就得完全自己設計一些分布式系統使用IP(or UDP)作為基本協議,原因是:IP/UFP協議已經設計,可節約相當可觀的工作消息包可在幾乎所有的Unix系統中傳送和接收IP/UDP消息支持許多現存的網絡總之,IP/UDP很容易使用,并且適合現存的Unix系統和網絡關于性能,IP是無連接的協議,在它之上可建立起可靠的TCP協議(面向連接的),IP協議支持網關的報文分組,使報文從一介網絡進入另一個網絡(物理網絡)。
4.2.6.3 確認機制(Acknowledgement)
- stop-and-wait protocol
思想:逐包確認。
特點:一個包丟失了,可獨立重傳;容易實現。 - blast protocol
思想:一個消息的所有包都發送完成后等待一個確認,而不是一個一個確認。
特點:報文丟失時,有兩種選擇:- 全部放棄:等待重傳整個消息的所有包,容易實現;
- 選擇重傳:請求丟失包重傳,占用網絡的帶寬少。(對局域網這種方法較少使用,廣域網絡普遍采用)。
4.2.6.4 流量控制(flow control)
??通常網絡接口芯片可以接收連續不斷到來的包,但是由于芯片中緩沖區的限制,總是對連續到來的包的個數有個數量限制"超載"(overrun):一個消息到來而接收它的機器無法接收,以至于到來的消息丟失。超載是一個很嚴重的問題,它比因噪聲等其他破壞引來的包丟失普遍得多。
上面兩種確認機制對超載問題有所不同
- stop-and-wait protocol(超載的可能性小)
??因為第二個包在沒有收到明確的確認之前不能被收送。(在擁有多個發送用戶的情況下可能存在) - blast protocol(接收方超載是很可能的)
- 由于網絡接口芯片引起的超載(因接收方處理一個進程而來不及處理到來的消息包)。
解決方法:- 忙等待:CPU空操作,應用短延時的網絡環境;
- 中斷:發送進程掛起,CPU重新調度,應用在長延時網絡環境;
- 由于網絡接口芯片緩沖區容量引起的超載
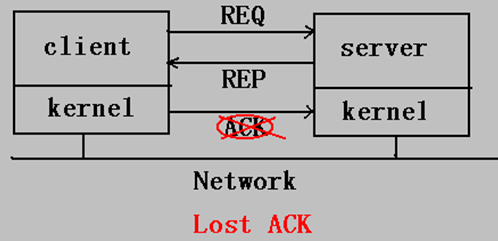
解決方法:設有n個緩沖容量,發送進程每連接發送n個消息包時,便等待一個確認(由協議完成)確認丟失問題(lost ACK)
- 由于網絡接口芯片引起的超載(因接收方處理一個進程而來不及處理到來的消息包)。
圖中"ACK"包丟失,造成的問題。
解決:對確認(ACK)進行確認(ACK),“超時確認”。
4.2.6.5 臨界路徑(critical path)
??分布式系統是否成功依賴于它的性能的好壞,而系統性能的好壞又依賴于它的通信速度,通信速度與系統的具體實現有關,下面我們進一步討論從客戶到服務器執行一個RPC的過程。
??臨界路徑(critical path):每個RPC的指令執行的順序是從客戶調用客戶代理,自陷進入內核,消息傳送,服務器中斷,服務器代理,最后到達進行請求處理并返回應答的服務器。RPC的這一系列步驟稱為(從客戶到服務器的)臨界路徑。臨界路徑(critical path)圖示
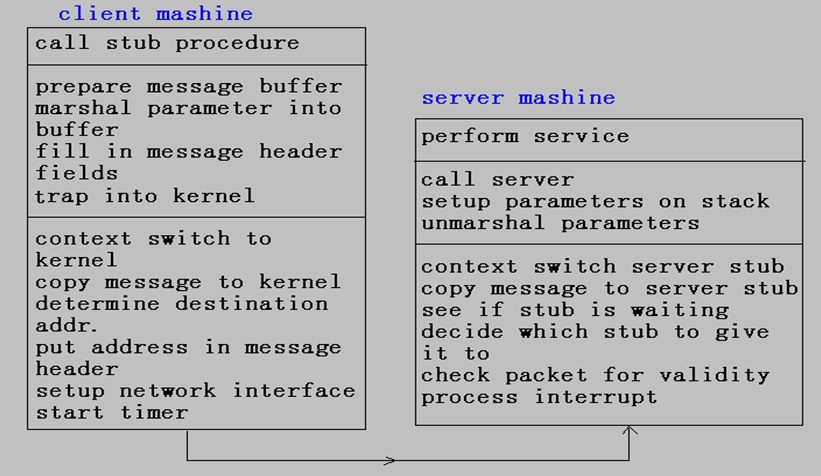
- 客戶調用 stub procedure
??申請一個緩沖區用來整理外出的消息,有些系統有一定數量的緩沖區,也有一些是一個緩沖區池,從中選擇一個合適的供服務器使用。 - 參數整理
??參數整理成適合的格式,并與消息一起插入消息緩沖區中。以備傳送,自陷進入內核。 - 切換進入內核
??內核獲得控制,保存CPU寄存器及內存映像,建立新的內存映像。 - 拷貝消息到內核
??因為用戶和內核是不連接的,內核必須明確地把拷貝到內核緩沖區。 - 填入目標地址
??將其拷貝到網絡接口,到此客戶臨界結束。
??原則上,啟動計時器不屬于計算RPC時間的部分,啟動計時機后,系統有兩種方式:忙等待和重新調度。
??在服務器端,當字節到達后,被存入板上緩沖區或主存,當消息包的所有字節都到達后,服務器將形成一個中斷。
??檢查消息包的有效性,并決定將其送給一個代理,若沒有等待的代理則放棄或保存至緩沖區。
??假定有一個等待的代理,那么,消息被拷貝到代理并切換到服務器代理,恢復寄存器及主存映像,代理調用receive原語,分解參數,建立服務器的調用環境,進行請求處理。
臨界路徑(critical path)的開銷-拷貝
??在考慮臨界路徑的時間開銷問題時,其中最重大的部分是拷貝
- copy1:客戶代理->內核
- copy2:內核->網絡接口板
- copy3:網絡接口板->目標機器
- copy4:網絡接口板->內核
- copy5:內核->服務器代理。
4.2.6.6 定時管理(timer)
??所有的協議都是以通過通信介質交換消息為目的的,而事實上,所有的系統中,消息都有可能丟失,或許是因為噪聲或是超載。所以,多數協議都設置定時器,當消息發送出去后,期待應答(確認)的到來,若沒有消息到來而定時器期滿(expiration),則重發。這個過程可以重復幾直到發送方放棄。
設置定時器:建立一個數據結構來指定定時器何時期滿,以及期滿時如何處理。
多個進程的定時器組織成列表方式:
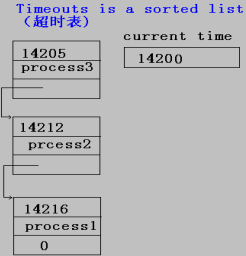
??當一個確認或應答在超時之前到來,列表中查出對應進程所在的項,將它刪除,實際上,只有少數的進程可能超時,但每一個進程都要進入超時表后再刪除,這些大量的工作多數是多余的。另外,定時器也不需要精確的時間,但定時太短引起過多的超時,定時太長則對包丟失的情況又過多的等待。
實現方法:
??在PCB中增加一個字段,稱為定時器,當發出一個RPC時,將允許延遲的時間加上當前的時鐘的值并存于PCB中定時器字段,如果不需要超時重傳的,其值規定為0,這樣,內核定期掃描PCB鏈表,如果定時器值非0且小于當前時間,則該進程超時。
4.2.7 RPC與消息傳遞通信的比較
??RPC結構性好,使用方便,消息傳遞通信更靈活,但結構性差。RPC只有一個返回,而消息傳遞通信可以向多個客戶返回。RPC返回的結果或參數的值最好是少量的,消息傳遞通信可適合于大批量數據的傳遞。
4.3 分布式同步算法
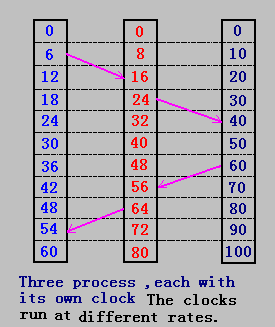
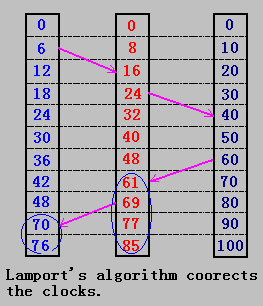
4.3.1 邏輯時鐘(Logical Clocks)
??時間在同步中起重要的作用,首先,我們來看分布式系統中時間的度量(measured)。
幾乎所有的計算機是使用電路來記錄時間,盡管普遍使用時鐘這個概念來表示這些設備,但它們并不是真正意義是的時鐘(clock),更確切地說,計算機中使用的只是計時器(timer),由有規律振蕩的晶體來產生。因為加工工藝等原因,不可能有兩個晶體時鐘是一致,從而不同的計算機其時鐘不可能完全一樣。
??假使兩臺或幾臺機器時鐘可以非常精確,但大型分布式系統允許兩臺機器僅次于地球的兩個時區上,這樣它們的時鐘仍是不一致的。
??因此,在分布式系統中,需要考慮另一種時間的度量,即邏輯時鐘。在這方面有重大貢獻的是Lamport,他在1978年提出時鐘同步是可能的,并給出一些算法,這些觀點為分布式系統奠定了重要的理論基礎。
4.3.2 Lamport 算法
Lamport指出:時鐘同步不需要絕對的(精確時間),如果進程間沒有相互作用,就不需要時鐘同步。并且進程所關心的不是什么時間做什么工作(由于進程的運行過程由多種因素決定,有不確定性),它們所關心的是事件發生的順序。
思想:
- happen before
??如果事件a是在事件b之前發生,則記a->b,即a happen before b。特別地,在一次通信中,如果發送進程發送消息的事件是a,接收進程接收消息的事件為b,則a->b。
??happen before 是可傳遞的,即如果a->b、b->c,則a->c。 - timestamp
??在分布式系統中,每一臺機器都設置一個整型變量作為“時鐘”(它并不是真實的時鐘),當一個事件a發生時,用這個時鐘的值作為事件a的timestamp(時間戳),記作C(a)。這樣,如果a->b,則C(a)<C(b);在同一機器上的任兩個事件a和b,都有C(a) != C(b);
??在進程通信中,消息中含有發送時的時間戳,消息到達目標機器時,它的內核檢查其時間戳,如果它的當前時鐘小于所收到消息的時間戳,則修改它的時鐘,使其時鐘值大于接收消息的時間戳。
Lamport算法-邏輯時鐘修改
個人理解:
- 如果接收的時間戳大于自身的的時間戳,則修改自身時間戳為接收的時間戳+1;
- 如果增加了自身的時間戳則后續的時間戳也需要增加相同的增量(增量可以由自身時間戳間隔確定)
4.4 分布式互斥算法
4.4.1 集中式算法
【在分布式系統中最直接的方法是模仿單處理器系統中的作法實現互斥】
基本思想
??指定一個進程為協調者(Coordinator),當一個進程要進入臨界區時,它發送一個請求消息給協調者進程表示它的要進入臨界區并要求給一個許可(permission),如果當前沒有進程在臨界區執行,協調者進程返回一介許可的應答,當許可的應答收到時,要求進程則可以進入執行,當它的臨界區執行完成時,再發送一個要求釋放臨界區的消息。【向協調者申請許可,誰有許可誰進入臨界區,退出臨界區,歸還許可】
優點
- 可以保證臨界區的互斥
- 具有公平性(fare)
- 容易實現
- 可以用于其他的資源分配
缺點
- 協調者進程的錯誤將使用整個系統無法工作
- 死鎖不容易檢測
- 協調者進程可能出現瓶頸
4.4.2 Ricart & Agrawala’s算法
基本思想
??當一個進程要進入臨界區時,它建立一個包含它要進入的臨界區名、進程號、和當前時間戳(timestamp),并把消息發送給所有的進程,理論上也包括它自己,消息傳送是可靠的,每個消息要求有確認,如果網絡支持可靠的組通信,則可用于代替單個的通信。
??當一個進程收到另一個進程的一個請求時,它采取的工作依賴于消息中臨界區名,這有三種情況:
- 如果它不在相關臨界區內,并且也不想進入,它返回一個許可(OK)的應答;
- 如果它已經在臨界區內,它不返回任何應答,而是將消息加入場專門的請求隊列中;
- 如果它想進入臨界區執行(但前還沒有進入),它把消息中的時間戳,與它發送給其他進程的請求消息的時間戳進行比較,時間戳小的則獲得進入臨界區的許可。如果當前收到的消息的時間戳小,就發送一個OK消息,否則,如果進程自己發送的消息中的時間戳小,就不做發送任何消息而是將收到的請求加入請求隊列中。【先來先進,自身時間戳小于收到的時間戳,則執行情況2;否則,執行情況1;】
??進程在發送了請求進入臨界區的請求消息后,就等待其他進程的許可(OK)消息,一旦它得到所有進程的許可(OK),就可以進入臨界區執行。
??進程退出臨界區時,向在該進程的請求隊列中的所有進程發送OK消息,并從隊列中刪除這些進程的請求消息。【告訴請求隊列的進程我退出臨界區】
優點:
- 可以實現互斥,并保證不出現死鎖(deadlock)或餓死(starvation)【本質是先來先服務,不會發生死鎖和餓死】
缺點:
- 每次請求進入臨界區要2(n-1)次通信(假定系統中的n個進程)【向n-1個進程發送請求,接收n-1個進程的ok消息,一共2(n-1)】
- 任何一個進程的崩潰,將使用算法無法完成
4.4.3 令牌環算法(Token Ring)
基本思想
【所有進程圍成一個圓,令牌在圓中依次傳遞,在誰手上誰可以訪問臨界區,不需要訪問臨界區或者退出臨界區,則把令牌給下一個進程】
??將系統中所有進程建立一個邏輯環(logical ring),環中進程的順序可以按進程地址排序或其他方法排序,只要環中一進程能知道它的下一個進程是誰即可。
??環被初始化后,進程0得到一個令牌(Token),令牌沿環逐個下傳,從k到中k+1(當k+1為環中進程時取0)。
??當一個進程從它的上一個得到令牌時, 如果它要進入臨界區,則就可以進入執行,臨界區執行完成后,再把令牌傳給下一個。
??每獲得一個令牌,至多只能執行一個臨界區。
優點
- 可以實現互斥,不會出現餓死
缺點
- 令牌丟失時要建立一個新的令牌,但很難確認是否已經丟失
- 任何一個進程的崩潰,將使用算法無法完成
4.4.4 三種算法的比較
| 進/出臨界區花費的代價 | 進入臨界區等待時間 | 問題 | |
|---|---|---|---|
| 集中式算法 | 3 | 2 | 協調者奔潰 |
| RA算法(分布式算法) | 2 (n-1) | 2 (n-1) | 任一進程奔潰 |
| 令牌環算法 | 1 — ∞ \infin ∞ | 0 — (n-1) | 令牌丟失、任一進程奔潰 |
次數說明:
【3次 —— 申請許可、給予許可、返回確認】【2次 —— 申請許可、收到許可】
【2(n-1) —— 向n-1個進程發送請求,接收n-1個進程的ok消息,一共2(n-1)】
【1 — ∞ \infin ∞ —— 1 表示令牌傳遞需要一次,無窮 表示 即使當前所有進程都沒有申請進入臨界區運行,令牌也要沿環不斷地傳遞;因此,當一個進程要進入臨界區執行是,令牌消息傳遞的個數是不確定的,可以有任意多次,即 無窮。】【0 — (n-1) —— 0表示令牌剛好在手上,n-1 表示令牌剛好傳遞給下一個進程】
4.5 分布式系統的可靠性
4.5.1 選擇算法(Elect Algoriathms)
??在分布式系統的許多算法中都要有一個進程充當協調者、發起者、序列生成器、或其他特殊的角色,如集中式(互斥)算法中的協調者進程。通常,由哪個進程充當這個角色均可,但總得有一個進程來承擔。這一節介紹選擇這種協調者的算法即選擇算法。
幾個假定
- 系統中每一個進程都有一個唯一的標識,如進程號;
- 系統中每個進程都知道其他進程的標識,但為些進程可能是活動的,也可能是關閉或崩潰;
- 選擇算法的目標:保證在選擇算法執行后,所有進程都認可某個進程成為了新的協調者。
Bull算法
??當某個進程發現協調者(Coordinator)無法響應它的請求時,該進程就啟動一個選擇過程。進程P,執行的選擇過程如下:
- P向所有的進程號(優先級)比它高的進程發送Election消息;
- 如果得不到其他進程的響應,進程P獲勝,成為協調者;
- 如果有一個進程號(優先級)更高的進程響應,該進程就接管選擇過程。進程P的任務完成;
??任何時刻進程都可能收到進程號(優先級)比它小的進程發送來的Election消息,該消息到達時,消息的接收者就向發送者發送一個OK消息,說明它仍是活動進程,而且它將接管選擇過程。接收者接管選擇過程,除非它已經接管一個選擇;最后,其他進程都放棄只剩一個進程時,該進程成為新的協調者,然后它向所有的進程發送消息,通知這些進程從此刻起,它是新的協調者。
環算法(Ring Algorithm)
??對所有進程進行物理或邏輯的排序,這樣每個進程都知道它的下一個進程是誰。
??任何一個進程發現協調者不起作用時,就創建一個包含該進程號(優先級)的Election消息,并將該消息發送給它的下一個(即后繼)進程;
??如果后繼進程已經中止,就跳過它發送給下一個,依此類推,直到找到一個活動進程為止;
??每個進程收到Election消息時,就將自己的進程號(和優先級)加入到Election消息的進程表中;
??最后Election消息會回到創建它的進程(通過判斷進程表中是否含的自己的進程號),它從進程表中選擇最大進程號(或優先級)的進程作為新的協調者,并構造一個Coordinator消息通知所有其他進程。
4.5.2 k-容錯技術
??如果系統允許有k個組件出錯,而仍能正常工作,這種容錯技術稱為k-容錯技術。那么,Fail-silent faults【非拜占庭失敗】須提供k+1個備份。Byzantine Faults則須提供2k+1個備份。
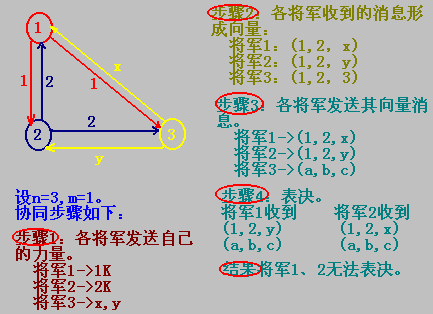
“兩支軍隊”問題(two-army problem)
【說明即使兩個處理器是正常的,但它們要達成一致的意見是困難的。】
??一支紅色軍隊,5000人,駐在山谷。兩支藍色的軍隊,每支3000人,駐扎在山角監視著山谷。兩支藍色的軍隊只有同時向紅色軍隊發動進攻,才能獲勝,任何一支單獨出擊都將失敗。現在,兩支藍色軍隊的目標就是對進攻的時間達成一致的意見,然而他們的協同只能通過互派信使來交換意見,但信使隨時可能被俘虜。
??假設一支藍色軍隊的將軍Alxander,決定在第二天凌晨2:00進攻,并派出一個信使將這個決定通知另一支藍色軍隊的將軍Bonaparte,之后就下達自己的軍隊,準備第二天凌晨2:00進攻;
??然而,到了第二于凌晨,Alexander擔心,Bonaparte不知道信使已經安全返回,可能不會輕易進攻,結果,Alexander又派一個信使把確認的消息傳給Bonaparte;假如信使也安全到達Bonaparte,這時,輪到Bonparte擔心,Alexander不知道確認是否安全到達,可能不會按時進攻。這樣Bonaparte只好也派一個信使將確認通知Alexander。
??這樣,兩個將軍將來回確認,永遠無法到成協議。因為最后一個發送消息的人不知道消息為對方接收,如果最后一個消息丟失,則所有協議都無效,無法進攻,并進入死循環。
問題是:通信是不可靠的,下列我們假設通信是完善可靠的,僅僅是處理器可能出錯。
Byzantine generals problem 【拜占庭失敗問題】
??一支紅色軍隊安營在山谷中,有n個將軍率領n支藍色軍隊扎營在山下周圍,他們可以點對點完善地通信。假設其中有m(m<n)個將軍可能是是背叛者(出錯),并且阻礙軍隊達成一致的意見(修改消息),現在問題是正規軍(非背叛的)能否達成協同?
??不失一般性,我們把這里的協同的含義稍作修改,即假設每個將軍都掌握自己的軍隊的力量,問題的目標是各個將軍能交換他們的部隊力量,這樣,算法結束時,每個將軍就有一個向量表示盟軍的力量, 如果將軍是正規軍,用i表示他的軍隊的力量,否則沒有定義。
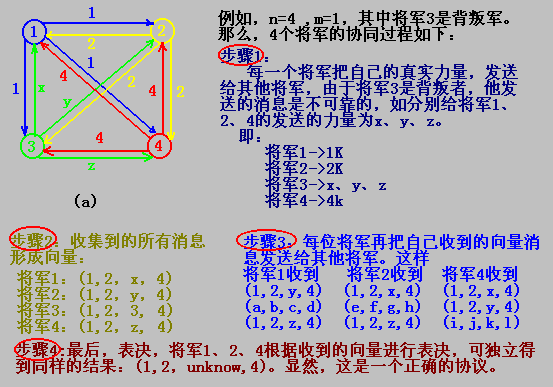
現在來看另一個例子
??1982年,Lamport證明在一個系統中,有m個出錯的處理器時,協同形成需要2m+1個正常工作的處理器,即總數是3m+1。協同形成需要約三分之二的人通過。
4.5.3 表決算法(voting algorithm)
表決技術(votings)
??客戶讀或寫一個備份文件的操作前,先向所有的服務器發送請求,并得到多數服務器的許可后才能進行。
??設備份服務器有N個,并規定客戶對備份文件的更新要經多數服務器的許可,即至少(N+1)/2個服務器的許可后,存取工作才可以進行,復制文件并形成新的版本(具有一版本號,對新修改的備份文件其版本號應該是相同的。)
??“許可”,可以是一個含有版本號的應答消息。
??這樣,讀一個備份文件的步驟是:
- 向至少半數以上的服務器([N+1]/2)發送讀操作請求消息,要求返回文件的版本號
- 如果所有的返回版本號是一致的,則說明該版本號是最近的,文件是最新的。因為其余的服務器個數不足半數,如果他們的版本號高,則說明其更新操作是無效的。如果更低,則說明上一次訪問操作已經確認,只是這些服務器尚未更新。
??例如,有5個服務器,某客戶得到3個服務器的版本號是8,則其余的兩個服務器的版本號不可能是9,因為版本號從8到9要得到半數以上的服務器的許多,而不是2個。
表決算法(voting algorithm)
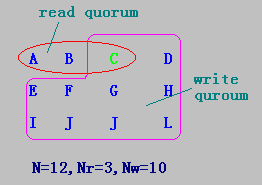
??某文件系統有N個備份服務器,定義Nr和Nw分別表示讀法定人數(read quorum)和寫法定人數(write quorum):
- 當客戶的一個讀操作得到Nr個服務器的相同版本號的許可時,可執行該讀操作;
- 當客戶的一個寫操作從Nw個服務器中得到相同的版本號的許可時,則可執行該寫操作。
- 其中Nr+Nw>N。
例子
-
N=12,Nr=3,Nw=10
-
N=12,Nr=7,Nw=6
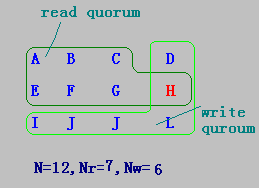
-
N=12,Nr=1,Nw=12
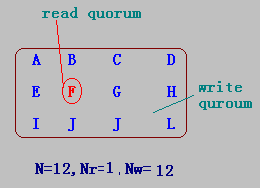
??特別地,Nr=1,Nw=12,意味著寫操作要求所有的服務器表決,則讀操作可以從中任選一個。
說明
- 由于讀操作比寫操作更經常發生,為提高算法效率,可規定Nr<Nw。
- 當Nw接近N時,只要少數服務器的關閉,寫操作就不能允許。
4.6 習題
- 在分布式令牌環互斥算法中,一個進程進入臨界區執行需要令牌消息傳遞的個數是 1 ? ∞ 1-\infin 1?∞ ,解釋這里 ∞ \infin ∞ 的含義。
??在分布式令牌環互斥算法中,算法保持一個令牌在環中傳遞,一個進程只有在得到令牌時才能進入臨界區執行,以便實現互斥;即使當前所有進程都沒有申請進入臨界區運行,令牌也要沿環不斷地傳遞;因此,當一個進程要進入臨界區執行是,令牌消息傳遞的個數是不確定的,可以有任意多次,即 ∞ \infin ∞ 。 - 解釋RPC透明性的含義。
??使得遠程過程調用盡可能象本地調用(內部過程調用)一樣,即調用進程不關心也不必知道被調用過程的位置(在本地或遠程另一臺計算機);反過來也是如此,被調用過程也不關心是哪臺機器上的進程調用,只要參數符合要求即可。 - PRC中客戶代理(client stub)實現什么主要功能?
??將參數封裝成消息;請求內核將消息送給服務器;調用receive操作進入阻塞狀態;當消息返回到客戶時,內核找到客戶進程,消息被復制到緩沖區,并且客戶進程解除阻塞;客戶代理檢查消息,從中取出結果,并將結果復制給它的調用進程
五、層次結構分析
5.1 線程技術
5.1.1 引入線程的目的
- 系統工作單位的粒度減小,提高并行程度
- 減少處理器切換的開銷
5.1.2 線程的概念
??進程的有效細化,是進程內可獨立執行(調度)的實體。
5.1.3 線程與進程的區別、聯系
- 一個進程可分為多個線程,這些線程共享同一個進程的地址空間
- 進程的活動由它的線程的活動來體現
- 只有一個線程的進程與進程沒有區別
- 同一個進程的幾個線程之間需要同步控制
- 線程可以并發執行,也可以并行執行(多CPU時)
- 進程是資源分配的基本單位,線程是處理器分配、調度的基本單位
- 進程的地址空間是私有的,進程間的處理器切換時現場的保護/恢復的開銷大;而同一進程的線程之間進程處理器切換時現場的保護/恢復的開銷小
5.1.4 線程的分類
- 用戶級線程
- 線程的管理是在用戶空間實現
- 可以在不支持線程的OS中實現
- 線程間切換不要進程內核,減小系統的開銷
- 未能實現并行程序的提高
- 系統級線程
- 線程的管理由OS實現
- 并行程度得到提高
- 但在內核的切換影響到系統開銷
5.1.5 線程的執行特性
- 線程的生命期-動態性
??派生、阻塞、激活、調度、結束 - 線程的同步
??同一進程的線程共享該進程的地址空間,需要同步或互斥
5.1.6 線程的應用
- 服務器:文件系統或通信
- 分派/處理結構(dispath/worker)
- 隊列結構(Team)
- 管道結構(Pipe)
- 客戶:前后臺處理
- 異步處理:進程中若有兩個或多個任務,它們之間的處理順序沒有規定,則每個任務可以由一個線程處理
5.2 服務器緩沖技術
5.2.1 無狀態信息(Stateless)服務器
??當一個客戶發送的一個請求給服務器時,服務器執行請求,返回結果,然后刪除該請求的有關所有信息,這樣的一個服務器稱為無狀態信息的。
5.2.2 有狀態信息(State)服務器
??有狀態信息服務器(Stateful information server):文件服務器擁有打開、關閉、讀、寫等操作,當一個文件被打開后,服務器將保存是哪一個客戶打開的,打開的是哪一個文件,并生成一個文件描述符(file discroptor)。
??一個客戶如果已經打開了一個文件,那么它的后續操作,只要給出文件描述符及有關的參數即可,服務器收到請求后,根據文件描述符就知道哪一個文件。
??狀態信息(Stateful information)是一個映射表,文件描述符映射到它的文件。
5.2.3 無狀態服務器與有狀態服務器的比較
對于無狀態服務器
- 每一個請求都要求是完備的、獨立的,包含完整的文件名、偏移量,以便服務器的工作,請求消息長度增加。
- 無狀態信息服務器具有更高的容錯性。
- Open/Close調用沒有必要,從而減少傳送消息的次數。
- 服務器不會因為保留狀態信息而浪費空間,因為某一時刻當有大量客戶要打開大量文件時,表將填滿而新文件不能打開,客戶的請求得不到服務,正確的程序將不能正確地工作,無狀態信息服務器將消除這個問題。
- 客戶機崩潰也不會產生問題。
- 文件加鎖是不可能的,因為無狀態可登記,這種情況下,無狀態信息服務器不得不使用加鎖服務器。
對于有狀態信息服務器
- Read/Write消息中不必包含文件名,它們的長度將縮短,從而占用更少的網絡帶寬;
- 由于打開的文件在內存中,讀、寫操作速度更快,性能得到提高;
- 因為更經常的是讀操作,所以可以事先成塊讀到內存而減少延時;
- 同一有效性容易實現,如果客戶因超時重傳同樣的請求,服務器有兩個接收的情況下,由于內存中保存了狀態信息,很容易通過比較每個消息的序號而發現;
- 文件加鎖是可能的。
5.3 N層結構的特性
【層次結構是解決復雜問題時最常用的軟件結構】
5.3.1 層次結構設計
- 層次
- 完成若干功能或服務的模塊,這些功能具有獨立性;
- 一個層次是一個服務的提供者;
- 一個層次還可以進一步分層;
- 層次間的單向依賴關系
??同一系統的層次之間構成單向的依賴關系,一個層次依賴于較低的層次。這種依賴關系是通過接口實現的。 - 層次的隱藏性
??層次間的單向依賴關系使得每個層次具有隱藏性。一個層次可以隱藏其內部的實現細節,向上提供一個一致的服務。使高層次可以不必了解低層次的細節,如物理特性、存儲方式、位置等。 - 分層的原則
??第n層存在的必要性:它對n-1進一步完善和擴充,并提供n+1的服務接口更簡單可靠。從這個意義上說,層次的隱藏性是不完全的,如果第n層中的一項服務已經足夠完善,則該服務就不必在n+1層中繼續存在,這樣,第n+2層在需要該服務時可直接使用第n層中的服務。
5.3.2 軟件系統的層次結構
【研究表明,任何軟件的完整結構都具有層次關系】
- 硬件基礎層
??這是軟件得以運行的物質基礎,它包括:處理器、存儲器、時鐘、中斷及其控制、I/O端口、I/O通道、快速緩存、DMA等。軟件是針對特定硬件的構成而設計的,反映對硬件的支持的需要,即硬件發生變化后,原則上軟件也需要做出相應的為變更。 - 軟化的硬件層
??在對硬件結構和性能進行描述的基礎上,實現硬件的操作和控制描述,這就是軟化的硬件層。在該層次上,處理器被軟化為狀態和指令的集合,中斷被描述為狀態和中斷服務的集合等。該層是軟件構成的基礎,其程序設計工具主要是匯編語言(assemble language)。 - 基礎控制描述層
??主要包括高級語言的所支持的程序控制和數據描述。程序控制的概念有:順序、條件、選擇、循環、變量、參數、生存期、程序、過程/函數等,數據描述的概念有:數組、結構/記錄、隊列、樹、圖、指針等,以及面向對象中的類、對象、繼承、多態、重載等。該層次的工具是程序設計語言、結構化或面向對象的分析設計。 - 資源和管理層
??在基礎控制要描述層建立的一切對象和數據都需要在操作系統的協調和控制下才能實際地實現其設計的作用和功能。該層提供了基于操作系統結構的任務管理、消息處理、系統輸入/輸出控制,其他系統級別的資源和功能服務。該層的某些服務的定義在基礎控制描述層中,但功能的實現是建立在操作系統管理層的。 - 系統結構模型層
??我們知道,軟件體系結構是軟件的“高層(high level)結構”,該層包括的概念如:解釋器、管道/過濾器,C/S、黑板等 - 應用層
??這是純粹從應用領域出發所建立的系統結構概念,該層包括的概念如:企業管理、公文處理、控制系統、CAD系統等。

N層結構——C/S或B/S結構稱為2層結構,我們把層次結構中3層或3層以上統稱為N層結構。
5.4 N層結構的實現
??一個產品的軟件體系結構風格如果采用N層結構。則可能按下面的步驟實施:
- 定義為合適的分層而采取的抽象標準:在軟件開發中,根據距硬件接近或距應用接近的程度建立分層,比如某個應用可能建立如下的分層:用戶界面、特定功能模塊、公共服務、操作系統接口、操作系統、硬件層。
- 抽象標準決定模型層次的數目:分層的原則是對于第n+1層來說,如果第n層提供的功能不會比第n-1層簡單,則第n層就不必存在。
- 給每個層次命名和分配任務:在層次結構中最高層的任務就是整個系統從用戶出發的任務。如果采用自底向上的設計方法,較高層次是建立在較低層次之上的,這要求對系統具有豐富的經驗和敏銳的洞察力,以便在確定高層前找到低層次的合適抽象。
- 規范服務:層次之間要嚴格分開,確保沒有部件會跨越兩層以上,層J函數的參數、返回值和錯誤類型者應限定在程序語言的類型、層J定義的類型或從共享數據模塊中引用的類型。
- 為每個層次定義接口:在層J中定義一套良好的供層J+1層使用的服務接口(interface),使用層J+1看不到層J對接口對應的服務的實現細節,
- 設計錯誤處理策略:盡可能把錯誤處理在更低層次上,避免高陷入更多的錯誤。
例如:
Window NT的層次結構
- 系統服務層
- 資源管理層
- 內核
- 硬件抽象層
- 硬件層
5.5 N層結構的優缺點
優點
- 層次的利用性:如果層次中很好地體現了抽象、并且具有定義良好、文檔化的接口,那么該層能在多個環境中使用。
- 對標準化的支持:清晰定義并廣泛接受的抽象層次能夠促進實現標準化的任務和接口開發,相同接口的不同實現能夠互換使用,這樣就允許在不同的層使用來自不同組織的產品。
- 依賴性本地化:層次的標準接口通常把代碼的變化的影響限制在其所在的層次上,支持了系統的可移植性和可測試性。
- 可替換性:獨立層次的實現能夠輕易地被功能相同的模塊替換。如果層次之間的聯系在代碼中是固定的,那么聯系能夠根據新層次實現的名稱來更新。比如,硬件的可替換性,新的硬件I/O設備通過安裝正確的驅動程序就能夠使用,互操作性不影響高層次,高層次的接口不要改變,可以像以前一樣繼續向低層請求服務。
- 位置透明性:通常低層次把服務所在的網絡物理位置隱藏起來,使高層次的請求可以不關心其服務是在本地或是在遠程。
缺點
- 改變行為的連鎖效應:當某個層次的構成和行為發生變化時會生產生嚴重的連鎖效應,在維護升級時,如果必須在許多層次上做大量的工作,那么層次結構將變成一種缺點。
- 低效率:分層結構通常要比單層結構的效率低。如果高層服務嚴重地依賴于底層服務,那么必須穿越許多中間層進行數據的拷貝。
- 分層是有限制的:并不是所有的產品都可以分層,同一產品需要分成幾個層次沒有統一的標準。
5.6 一個用于構造分布式系統的層次結構設計

5.6.1 表示層——用戶界面技術
【劃分UIC和UIPC,進一步抽象,提高代碼的重用性和降低模塊的耦合度】
【UI與UI之間的調用的代碼不要寫在UIC中,由UIP處理,提高重用性】
- UI——用戶和應用進行交互的接口
提供的功能- 輸入方面
- 輔助用戶輸入,提供各種提示和幫助,在輸入的同時會有一些校驗,如日期等
- 響應用戶操作所觸發的各種事件(可能會展現出其他的UI)。
- 限制用戶的輸入,在數據改變的時候,可能會有一些相關聯的操作(如,單價的改變,影響到總價)。
- 處理一些特殊的操作(如drap-drop,剪貼板等)
- 輸出方面
- 格式化數據(如金額、日期等)
- 特殊顯示(壞帳號用特殊顏色標識出來)
- 將一些編碼轉換成有意義的名稱
- 個性化(Web頁面,Winfrom(dialog,MDI,SDI))
- 其他(狀態、分頁顯示查詢結果等)
- 輸入方面
- UIPC——處理用戶UI的流程控制
- MVC模型

- View——用戶操作界面
- Model——內部數據結構,狀態數據
- Controller——控制流程,UIPC的核心
- 什么是UIPC
??根據狀態改變決定使用哪一個UI。
應用場景:- 有些UI之間的相互作用,存在明確的處理順序(向導界面的上一、下一等,購物網站的瀏覽、選擇并加入購物車到收銀臺結帳)。處理這種流程的控制器稱為UIP
- 這些類型的界面操作的特點:
- 用戶操作流程可以用一張流程(導航)圖來描述)
- 導航圖上每一個節點是一個用戶界面(窗口、頁面)
- 界面之間的跳轉由用戶操作觸發的
- UIPC的好處
- 隔離UI與業務邏輯層
- 對流程中的UI進行管理
- 提供狀態保存和傳遞機制
- 狀態保存
??Server狀態和Client狀態,狀態有效期? - Smart Client
- 智能安裝和版本更新
- Connected。選擇一個合適的有效的Service
- 能夠利用本地資源(CPU、HD等)
- 離線能力。在不連接網絡上工作,連線時提交數據
- MVC模型
5.6.2 業務邏輯層——應用系統的核心
- Business Component
- 含義
??實現業務規則及執行業務工作的組件,負責發起事務,實現業務功能。 - 特點
- 由用戶處理層的UIPC、服務接口、以及其他業務組件調用,包含一些業務數據和操作,以及復雜的數據結構
- 是事務的發起者,參與事務的提交
- 必須驗證輸入和輸出
- 通過調用數據層組件獲取數據或修改應用數據
- 設計
- PIPELine Parttern,順序規定
- Event Parttern,順序不固定
- 含義
- Business Workflow
- 含義
- 具有各種不同功能的活動相連的一組有相互繞道而行關系的任務。
- 業務流程有起點和終點,而且它們都是可重復的
- 由多個Business Components組成,有一定的順序。
- 特點
- 迅速實現商業規則和商業目標的改變的能力
- 將每一步業務操作、資源管理以及流程獨立分離
- 以前后一致的方式定義、改變和實現業務流程
- 種類
- 基本于人的業務流程:他要完成、批準、執行的文檔
- 基于規則的自動化流程:應用程度彼此連接,在無人干預的情況下進行合作
- 實現
- 流程引擎--Business Workflow的核心
??實現業務流程,同時管理活動的啟動和終止,或業務功能 - 資源管理
??使實現商業功能或活動所必須的資源具有可用性 - 調度程序
??資源可用性的限制,商業功能經常受時間約束,需要調度程序以使時間約束和資源可用性相匹配 - 審計管理
??關鍵組件,跟蹤誰操作什么 - 安全管理
??資格授權
- 流程引擎--Business Workflow的核心
- 含義
- Business interface
- 含義
??服務接口是一組軟件實體,為實現處理映射和轉換服務的外觀組件(facade),把業務邏輯表現為服務,為服務提供進入點。 - 作用
- 提供業務處理的調用點
- 實現緩沖、映射、以及簡單的格式和結構轉換
- 不實現業務邏輯
- 進行信息安全控制,有的需要安全身份驗證
- 分隔內部系統的實現
- 對內部實現進行更新時,不需要變更服務接口
- 需要驗證傳入的消息
- 特點
- 將服務接口視為應用程序的信任界限
- 同一功能的服務發布多種服務接口,不同接口執行不同的服務等級義協議(SLA)
- 盡可能提高與其它平臺和服務的互操作性
- 實現
- 服務接口使得使用者和提供者之間能夠交換信息,負責實現通信時的所有細節
- 網絡協議
??應該封閉使用者和通信所使用的網絡協議(如,服務由TCP/IP上的http向使用者提供,則服務接口可以實現為ASP.NET組件,發布URL,http請求、響應和返回等) - 數據格式
??負責對使用者的數據格式和服務所期望的數據格式的轉換 - 安全性
??信任邊界,敏感操作授權使用 - 服務等級協議(SLA)
??Service Level Agreement,服務接口緩沖、縮短響應時間、節省網絡傳輸等,負載平衡功能、容錯技術等
- 方法
- XML Web 服務
- 消息隊列方式(MQ)
- 優點
- 接口與應用邏輯分離(重用、維護)
- 部署靈活(代碼與服務分離)
- 缺點
- 接口粒度設計
- 增加在更改服務所需的工作量
- 增加復雜性和性能開銷
- 含義
- Business Entities (BE)
- 含義
??應用程序的邏輯可能在設計中需要考慮多種數據格式,UI層的數據與數據庫中的數據格式、外部服務提供的數據格式等可以不同。BE提供了一個中間層。 - 作用
- 將顯示數據與實際存儲隔離,保證業務實體的獨立性,提高重用性
- 業務實體一般是在應用程序中內部使用
- 不同業務其數據格式不同
??XML、dataset、datareader
- 含義
5.6.3 數據邏輯訪問層(DAL)

優點
- 增加代碼重用性,可以被業務邏輯層在多個地方反復引用
- 盡可能消除業務邏輯層對數據源的依賴(由于數據源改變造成的影響極小化),DAL可以通過配置文件進行改變(如Oracle改變為MS SQL Server),隱藏了數據操作的細節
- 需要一個Helper來幫助完成數據操作,管理連接、緩沖等
Helper的作用
- 為DAL提供通用的數據訪問接口
- 減少數據訪問操作代碼(簡化執行SQL語句和調用存儲過程的代碼)
- 進行數據連接管理
- 在不同的數據源之間,可以提供統一的接口
5.6.4 數據層
數據源:關系數據庫、文件系統、Exchange Server、Web Storage等
5.7 習題
- 在C/S結構中,有狀態信息服務器和無狀態信息服務器相比,哪一種服務器對同時使用的用戶數有限制?為什么?
??有狀態信息服務器對同時使用的用戶數有限制。因為有狀態信息服務器需要設計一個狀態信息表,用于登記當前的用戶操作請求,當狀態信息表填滿時,新用戶的操作被推遲,意味著同時使用的用戶數受限制。
六、CORBA技術及應用實例(了解即可)
6.1 CORBA概述
解決分布式系統的應用程序開發問題的兩條規則
- 尋求獨立于平臺的模型和抽象
- 在不犧牲太多性能的前提下,盡可能隱藏低層的復雜細節
??這兩條規則不僅用于分布式系統,對于開發任何一個可移植的應用程序都是是適用的。使用合適的抽象和模型建立一個能提供異構的應用程序開發層(分布計算環境),系統異構的復雜性集中在這個層次,在這一層次上,低層的細節被隱藏起來,并且允許應用程序的開發人員只解決他們自己的開發問題,而不必面對需求所涉及到的、由于不同計算機平臺所帶來的低層的網絡細節。
對象管理組(OMG)
??對象管理組(Object Management Group),是一個非贏利的組織,建立于1989年4月,總部在美國,起由11個公司參與組建,現在擁有800多個成員,目前它是世界上最大的軟件團體,其目標就是解決異構系統的可移植、分布式應用程序的開發問題、制定的技術對一些具體的問題作了合理高層抽象,并隱藏低層細節。
??OMG使用兩個相關的模型來描述如何與平臺無關的分布式體系結構
- 對象模型(Object Model)
??用來定義在一個異構環境中,如何描述分布式對象接口,它將對象定義為永恒不變的、始終是唯一的、被封裝過的實體,這些實體只能被嚴格定義的接口(interface)訪問,即客戶機通過向對象發請求,才能使用對象的服務,對象的實現細節和它的位置對客戶中隱藏的。 - 引用模型(Reference Model)
??用來說明對象間如何交互。它提供一組服務接口。- 對象服務接口(Object Services,OS),這是一組與領域無關的接口,這些對象服務允許應用和諧查找和發現對象引用( Object Reference),被認為是構造分布式計算環境的核心部分,常見的有命名服務(Name Service)、交易服務(Trading Service)、事件服務(Event Service)等。
- 領域接口(Domain Interface),起著與對象服務種類相似的作用,對象服務接口是與領域無關的水平定向接口,只是領域接口針對領域而已,它與領域有關垂直定向接口,允許對象引用跨越不同的網絡。
- 應用程序接口(Application Interface),是專門為特定的應用程序而開發的,它們并不是OMG所制定的標準,但是如果某些應用程序的接口出現在許多的應用程序中,

??CORBA(Common Object Request Broker Architecture):公共對象請求代理的體系結構,第一版于1991年問世,當時只規范了如何在C語言中使用它,1994年推出CORBA2.0規范,目前普遍使用的是CORBA2.X,現在CORBA3規范已經建立,它主要新增了Java和internet、服務質量控制以及CORBA組件包等方面。
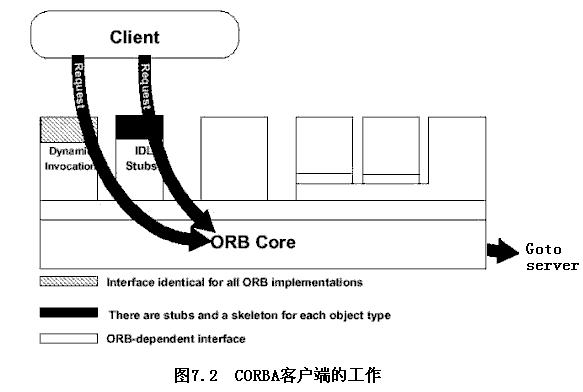
CORBA簡化了C/S模式
??在傳統的client/server應用中,開發者使用自己設計的標準或通用標準來的協議(如Socket)。協議定義與實現的語言、網絡傳輸及其w他網絡因素有關。而CORBA簡化了這一過程,它使用IDL來定義客戶與服務器之間的接口協議。
- CORBA客戶端的工作
- CORBA服務器端的工作
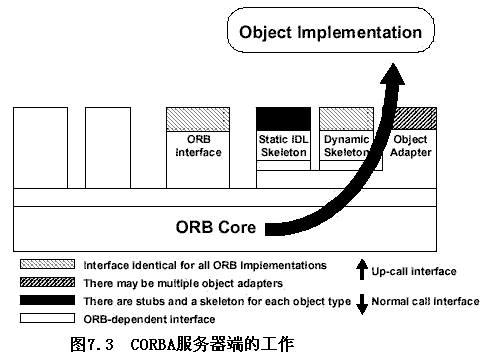
6.2 CORBA特性
6.2.1 OMG接口定義語言(IDL)
??為了調用一個分布式對象的操作,客戶程序必須了解由這個對象所提供的接口,一個對象的接口是由它所支持的操作和能夠來回傳輸這些操作的數據類型所組成的。
??在CORBA中,對象接口是按OMG接口定義語言(Interface Define Language,IDL)來定義的,與C++、JAVA等高級語言不同,IDL不是編程語言,所以對象和應用程序不能用IDL實現,IDL在客戶和服務器程序之間建立一個契約,用它來描述在應用程序中需要用到的類型和對象接口,這些描述與實現的語言無關,可以不用考慮客戶程序的編程語言是否與服務器程序的編程語言一致。正是IDL的語言獨立性,使CORBA成為異構系統的集成技術。
??IDL是一個純說明性的語言,它使用程序員把焦點集中在對象接口、接口所支持的操作和操作時可能引發的異常上。它有一整套詞法規則,供程序員定義接口。有關這些詞法的使用,將在下一講中作簡要介紹。
??IDL的一個重要特性是,一個接口可以繼承一個或多個其他的接口。
6.2.2 語言映射
??因為IDL只是一種說明性語言,它不能用于編寫實際的應用程序,它不是提供控制結構或變量,所以它不能被編譯或多用解釋成一個可執行的程序,它只適用于說明我對象的接口,定義用于對象通信的數據類型。
??語言映射指定如何把IDL翻譯成不同的編程語言,目前OMG IDL語言映射可適用于C、C++、Java、COBOL、Smalltalk、Ada等。
??IDL語言映射是開發應用程序的關鍵,它們提供CORBA所支持的抽象概念和模型的具體實施。IDL經過語言映射后,被翻譯成特定語言的存根和框架,用于客戶端和服務器端的程序的組成部分。
6.2.3 操作調用和調度軟件
??CORBA應用程序是以接收CORBA對象的請求或調用CORBA對象的請求這種形式工作的。
調用請求的兩種方法
- 靜態調用和調度
??采用這種方法,IDL被被翻譯成特定語言的存根(stub)和框架(Skeleton),這些存根和框架被編譯成應用程序,一個存根(Stub)是一個客戶端函數,它允許請求調用作為平常的本地函數調用,框架(Skeleton)是服務器端的一個函數,它允許由服務器接收到的請求調用被調度給合適的伺服程序(Servant procedure)。
??這種方法很受歡迎,它提供了一個更自然的編程模式。 - 動態調用和調度
??這種方法涉及到CORBA請求的結構和調度是在運行時進行的,而不是在編譯時產生的,因為疫有編譯狀態信息,所以在運行時請求創建和解釋需要訪問服務程序,由它們來提供有關的接口和類型信息。
調用請求的過程
- 定位目標對象;
- 調用服務器應用程序;
- 傳遞調用這個對象所需的參數;
- 必要時,激活這個對象的伺服程序;
- 等待請求結束;
- 如果調用成功,返回結果值和參數值;如果失敗,返回一個異常。
對象引用(Object Reference)
??客戶程序通過發送消息來控制對象,每當客戶調用一個操作時,ORB發送一個消息給服務器對象。為了能發送一個消息給一個對象,客戶必須擁有該對象的對象引用(Object Reference),對象引用起著一個句柄的作用,句柄標識唯一的一個對象,并且封裝了要將所有消息發送給正確的目標ORB所需要的信息。
??對象引用與C++中的類的實例指針有相同有語義,Java中沒有指針的概念而用引用。每個對象引用必須準確地標識一個對象;一個對象可以有多個引用;引用可以是空的;
引用的獲取
??對象引用是客戶程序獲得目標對象唯一的途徑,引用由服務器以某種方式發布的,常見的有:
- 返回一個引用作為一個操作;
- 以某些已知的服務程序公告一個引用(Naming Service 或Trading Service)
- 通過將一個對象引用轉換成一個字符串和將它寫在一個文件上,來公布一個對象的引用;
- 通過其他可以外傳的方式來傳送一個對象引用(電子郵件等)
請求調用的特征
- 定位透明性
??客戶不知道也不必關心目標對象是否在本地的,是否在同一機器上不同的進程中實現,或者是在不同的機器上同一個進程中實現的。服務器進程也不必始終保留在同一臺機器上。 - 服務器透明性
??客戶不必知道哪個服務器實現了哪些對象; - 語言獨立性
??客戶機無須關心服務器使用何種語言。 - 實現獨立性
??客戶并不知道實現是如何工作的。 - 體系結構獨立性
??客戶不必顧及服務器使用的CPU結構體系,并且屏蔽了字節的順序等細節問題。 - 操作系統獨立性
??客戶不必考慮服務器使用何種的操作系統,甚至服務器程序可以在不需要操作系統支持下實現(比如一些嵌入式系統)。 - 協議獨立性
??客戶不知道發送消息是采用什么通信協議,如果服務器可以采用多個通信協議,那么ORB可以在運行時任意選擇一個。 - 傳輸獨立性
客戶機忽略消息傳送過程中網絡的傳輸層和數據層,ORB可以透明地使用各種網絡技術。
6.2.4 對象適配器(Object Adapter)
- 伺服程序(Servant)
??它是一個編程語言的實體,用來實現一個或多個CORBA對象。伺服程序也稱具體化的CORBA對象,它存在于服務器應用程序的上下文(Context)中,比如,在C++或Java中伺服程序一個特定類的一個對象實例。 - 一個對象適配器是一個對象,它將一個對象接口配置給調用程序所需要的不同接口,CORBA對象適配器滿足下面三個要求:
- 創建允許客戶程序對對象尋址的對象引用;
- 確保每個目標對象都應由一個伺服程序來具體化;
- 獲取由服務器端的ORB所調度的請求,并進一步將請求產直傳送給已具體化的目標對象的伺服程序。
- 基本對象適配器(BOA,Baisc Object Adapter)
??CORBA早期版本(2.1之前)的規范中只有基本對象適配器,只能支持C語言的伺服程序,伺服程序沒有注冊。 - 可移植對象適配器(POA,Portable Object Adapter)
??CORBA2.2引入了可移植對象適配器(POA,Portable Object Adapter)來取代BOA,它提供了編程語言的伺服程序在由不同的廠家提供的ORB之間的可移植性,POA提供的基本服務有:對象創建、伺服程序的注冊、請求調度(Dispatch)。
6.2.5 內部ORB協議
??CORBA 2.0引入一個通用的ORB互操作性結構體系,稱為GIOP(General Inter-ORB Protocol,通用ORB協議)。
??GIOP是一類抽象的協議,它指定了轉換語法和一個消息格式的標準集,以便允許獨立開發的ORB可以在任何一個面向連接的傳遞中進行通信。IIOP是internet網上的ORB協議(Interent Inter-ORB Protocol, IIOP),它是GIOP在TCP/IP上的實現。
服務器應用程序的事件處理模型
??下圖表明了ORB、POA管理器、POA和伺服程序之間的關系。

6.3 CORBA應用程序的一般開發過程
??基于CORBA的系統包括客房客戶程序和服務器程序兩部分。通常需要執行以下幾個步驟:
- 確定應用程序對象,定義它們在IDL中的接口
- 將定義的IDL文件進行語言映射
- 聲明和實現服務器程序中的伺服類
- 編寫應用服務器程序。
- 編寫客戶程序
6.4 CORBA的基本服務
6.4.1 命名服務(Naming Service)
??命名服務是CORBA最基本的服務,它提供從名稱到對象引用的映射:給定一個名稱,該服務返回一個存儲在此名稱下的一個對象引用。很像internet上的DNS。
命名服務給客戶程序帶來的好處
- 客戶程序可以給對象起個有意義的名稱而不必處理字符串化的對象引用;
- 通過改變在某個名稱下的公告的引用值,客戶程序可以在不改變源代碼的情況下使用不同接口的實現,即客戶程序使用同一個名稱卻獲得不同的引用;
- 命名服務可以使應用程序的組元訪問一個應用程序的初始引用。在命名服務中公告這些引用,可以避免將引用變為字符串化的引用并存儲在文件中的必要性。
命名圖(naming graph)
- 名稱綁定(name binding)
??將名稱映射為對象引用,稱為名稱綁定(name binding)。同一個對象引用可以使用不同的名稱而多次被存儲,但是每個名稱只能準確也確定一個引用。 - 命名上下文(naming context)
??一個存儲名稱綁定(name binding)的對象,稱為命名上下文(naming context)。每一個上下文對象實現一個從名稱到對象引用的映射表,這個表中的命名可以表示某個應用程序的對象引用,也可以表示命名服務中的另一個上下文對象。
??一個上下文和名稱綁定(name binding)的層次結構稱為命名圖(naming graph)。 - 一個簡單的命名圖
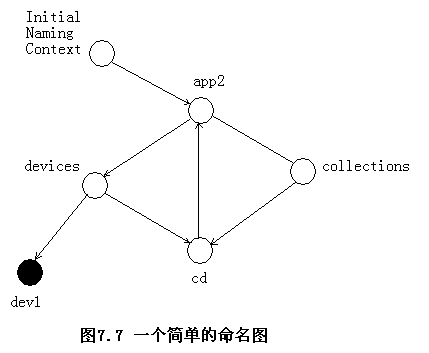
名稱解析(name resolve)
??命名服務提供(resolve)操作,由命名服務器將客戶程序中一個指定的名稱轉換為對應的對象引用并返回。
6.4.2 交易服務(Trading Service)
??命名服務允許一個客戶程序通過一個符號名來定位對象的引用,這種機制對于客戶程序定位一個對象很有用,但這要求客戶程序必須確切知道要使用什么對象。
??往往客戶程序需要多種機制來定位一個對象,例如,一個客戶程序可能只知道所需要的對象類型,對要做出精確選擇的其他必要信息并不清楚。這時CORBA的交易服務(Trading Service)提供了這種功能。允許客戶程序借助交易來定位對象。
??與命名服務類似,一個交易用來存儲對象引用及其服務描述,客戶程序執行動態查找服務,此服務是基于查詢服務描述的。
基本的交易概念
- 公告
??也稱服務提供源(service offer),用于存儲交易服務,一個service offer包含此服務的描述(一組屬性)和一個提供此服務的對象引用和服務類型。 - 導出
??放置一個公告的行為稱為導出(export)操作,放置一個公告的程序稱為導出者或服務提供者(service provider)。 - 導入
??為一個符合一定標準的服務提供者搜索交易的行為稱為導入(import)
交易服務的基本輪廓
??一個交易就是一個用于存儲屬性描述對象引用的數據庫,我們可以導出(增加)新對象引用和它的描述,或者收回它們。
6.4.3 事件服務(Event Service)
??前面我們介紹的CORBA請求調用是基于同步的請求調用,在同步請求上,一個主動的客戶程序向被動的服務器調用請求,在發送一個請求后,客戶程序阻塞并等待返回結果。
??CORBA事件服務允許服務器向客戶發送消息,即將C/S方式轉化為對待方式(peer-peer)。
CORBA的事件服務模型
??提供者(suppliers)生成事件而使用者(consumers)接收事件,提供者和使用者都連接一個事件通道(event channel)上,事件通道將事件從提供者傳送到使用者,而且不需要提供者事先了解使用者的情況,反之亦然。事件通道在事件服務中起著關鍵作用,它同時負責提供者和使用者的注冊,可靠地將事件發送給所有注冊的使用者,并且負責處理那些與沒有響應的使用者有關的錯誤。
事件服務發送事件的模型
-
推模型(push model)
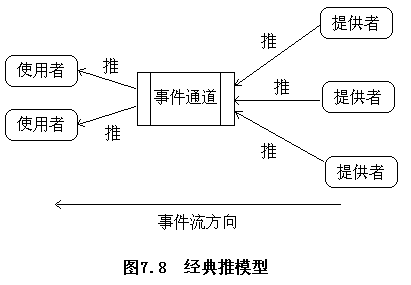
-
拉模型(pull model)
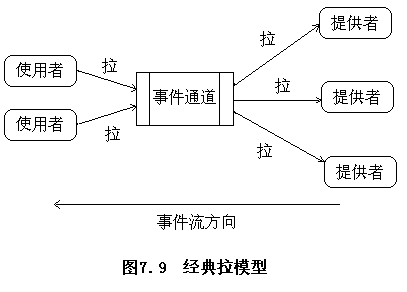
七、結構設計空間及其量化
7.1 設計空間和規則(design space and rule)
7.1.1 設計空間(design space)
??把能用來描述、分類,并可供系統設計員選擇的有效的結構集合稱為設計空間。
??一個指定的應用系統的設計空間(desigm space)是指在建立該系統設計時所有可供選擇的功能維(functional dimensions)和結構維(structure dimensions)的集合。
7.1.2 維(Deimension)
- 設計空間是多維的,每個維描述系統的一個特征(characteristic)或需求(requirement)的變化(variation),維的值表示維所對應的特征或需求所有可選擇范圍。
- 功能維(functional dimensions)表示問題空間(ploblem space),即功能設計或性能設計的可選擇的各個方面。
- 結構維(structure dimensions)表示方法空間(solution space),即實現一個特征的所有可選擇的方法。
- 設計空間的維通常是不連續的,并且沒有度量單位。表示也可能是。表示結構的維通常是一組離散的(discrete)值的集合,它們可能是沒有任何意義的序列,如狀態轉換圖(state transition diagram)、菜單(menu)、表單(form)等。有一些維在理論上是連續的(如表示性能的維),我們通常把它分成幾個不連續的部分,如low、medium、high等。
7.1.3 設計規則(design rule)
??設計空間中的維數,可能是相關的,也可能是獨立的,設計規則(design rule,簡稱規則)是指維之間的所有關系,主要兩種類型:有功能維與結構維的關系規則、結構維內部之間的關系規則。
??規則(rule)可用正(positive)、負(negative)權值(weight)表示,這樣規則體現了維之間關系的緊密程度或選定一種組合的好、壞。
??一旦從設計空間中選定一個設計,那么就可以通過權值來計算這個設計的得分(score),如果能將一個應用的設計空間的所有設計的得分計算出來,就可以比較各種設計的得分,以找出一個最合適的設計。
??對于一個經驗豐富的高級設計員,可以建立一個足夠完備(complete)和可靠(reliable)的規則,作為自動系統設計(automated system design)的基礎。但是并不是說有了規則,就可以設計出一個完善的或一個最有可能的系統。規則可以幫助一個初級設計員(journeyman designer)像高級設計員(master designer)一樣去選擇一個合適的、沒有大錯誤的設計。一個自動系統設計(automated system design)的實現將是一個漫長的過程。
7.1.4 設計知識庫(design vocabulary)
設計知識庫(design vocabulary)
??表示軟件設計的知識(knowledge),一種好的方法就是建立一個設計知識庫(design vocabulary),一組容易理解(well-understood)、可重用(reusable)的設計概念(concept)和模式(pattern)。
使用設計知識庫的好處(major benefit)
- 便于建立新系統(mental building blocks);
- 幫助理解和預見(predicting)一個設計的屬性(property);
- 減少了學習新的概念的數量,因而減少用于理解他人的設計的努力(effort)。
??比如,程序結構由控制流程的少數幾個標準概念【條件(conditional)、循環(iteration)、子過程調用(subroutine call)等】來描述,程序避免了早期所使用的復雜的底層測試和分枝等操作,而直接使用這些大家普遍理解和接受的控制流程模型,并把精力集中于這些模型的屬性(如循環語句中的條件變量、結束條件等),這樣不僅容易編寫、容易閱讀而且更加可靠。
??隨著軟件工程的成熟和研究關注轉向大的系統,我們期待類似于程序結構的標準也會在大型軟件系統中出現,現存中型(medium-size)軟件的結構模型的正在不斷走向成熟,人們已經注意到(anticipate)對于一個大型系統更高層的抽象是必要的。
7.1.5 一個設計空間的例子
??上面,我們主要介紹由不同的系統結構構成的多維設計空間(multidimensional design space)的概念,設計空間中的每個維描述了系統的一個特征及其可選擇的范圍,維上的值(即規則)則表示了需求與選定設計(design choices)的關系程度。比如,在一個并發進程的同步機制(interprocess synchronization mechanism)中,響應時間(response time)作為一個維,需求為Fast,Med和Slow,同步機制作為另一個維,結構有Message,Semaphore,Monitor,Rendezvous,Other,None等。
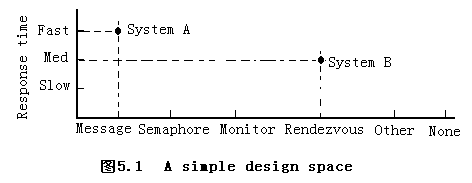
??一個設計空間中不同維之間不一定是獨立的(independent),事實上,為了建立設計規則,發現維之間的關系是非常重要的。
??構造設計空間的關鍵是選擇維,一些維反映需求或評估標準(evaluation criteria),如功能、性能等,另一些維則反映結構及其可用的設計。在維之間找出關系可以提供直接的設計指導,因為這些關系表明了設計選擇是否最符合新系統的功能需求。在圖5.1的例子,假設message機制能提供Fast的響應時間,而Rendezvous機制只能提供Med的響應時間。
設計空間的組成
- 功能設計空間(functional design space):描述設計空間中功能(function)和性能(performence)方面的需求。
- 結構設計空間(structure design space):表示設計空間可用的結構。
??比如,在瀑布模型(watefall model)中功能設計空間表示需求分析的結果,而結構設計空間則是指設計階段初始系統的分解(decomposition)
7.2 用戶接口結構(user-interface architecture)設計
7.2.1 用戶接口結構的設計空間
??下面,我們介紹一個設計用戶交互接口的軟件的設計空間的建立。
7.2.1.1 基本結構模型(a basic structure model)
??為了描述可用的結構,我們需要定義幾個術語(terminology)用于表示系統的組件,這些術語要求是通用的,主要有:
- 特定應用組件(aplication-specific component):組件應用于一個特定的應用程序,不期望在其他程序中重用,這些組件主要是應用程序的功能核心(functional core)。
- 可共享用戶接口(shared user interface)組件:這些組件是供多個應用程序使用的用戶接口。如果一個軟件要求能適應(accommodate)各種不同的I/O設計,那么只有能應用于所有這些設備類型的組件才作為可共享用戶接口組件。
- 依賴設備(device-dependent)組件:這些組件依賴于特定的設備類型且不是特定應用組件。
??在一些簡單的系統中,可以沒有后兩種組件,比如,系統可能沒有設備驅動程序的代碼,或者系統不要求提供支持多類型設備的應用。
??在一些中等規模的設計空間中,接口分成兩種設備接口(device interface)和應用接口(application interface),圖5.2表示了用戶接口的一種基本結構模型。
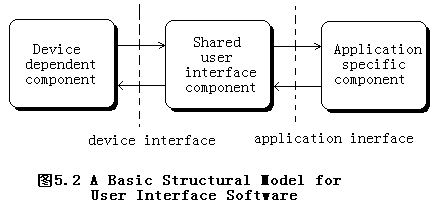
7.2.1.2 功能維例子(sample functional dimensions)
??有研究表明一個完整的用戶接口系統的設計空間包括25個功能維和19個結構維,這里我們只能選擇一些有代表性的6個功能維和5個結構維。
用戶接口系統的功能維
- 1.外部事件處理
- 無外部事件
- 在等待輸入時處理事件
- 外部事件剝奪用戶命令
- 2.用戶定制
- 高級
- 中級
- 低級
- 3.適應跨設備的用戶接口
- 無
- 局部行為改變
- 全局行為改變
- 應用語義改變
- 4.計算機系統組織
- 單一處理
- 多重處理
- 分布式處理
- 5.基本接口類型
- 菜單選擇
- 表單填寫
- 命令語言
- 自然語言
- 直接操作
- 6.應用程序對用戶接口風格的適應
- 高級
- 中級
- 低級
??以上6個功能維可分為3組
- External requirements(外部需求):這組維數主要包括特定應用、用戶、I/O設備的支持需求,以及周圍計算機系統的約束。
- Basic interactive behavior(基本交互行為):這組維數主要包括影響內部結構的用戶接口行為。
- Practical considerations(考慮實際應用):主要指系統的適應性。
1.External requirements(外部需求)
- External event handling(外部事件處理)
??這是一個反映賦于應用程序影響(impose)外部需求的維,指出應用程序是否需要響應外部事件、何時響應等這方面的選擇。維的取值如下:- No external events(沒有外部事件)
??應用程序不受外部事件(external events)的影響,或者只是在執行到指定的用戶命令時自動檢查外部事件。例如,一個電子郵件程序可能檢查是否有新的郵件,這種檢查僅僅是在執行指定的命令時才進行。用戶接口(user-interface)如果選擇這種類型將為支持外部事件。 - Process events while waiting for input(等待輸入時處理事件)
??應用程序必需處理外部事件(external events),但響應時間的要求不是很嚴格(stringent),只是在執行用戶輸入命令時響應中斷。 - External events preempt user commands(外部事件剝奪用戶命令)
??要求外部事件具有較高的優先級, 隨時中斷用戶命令的執行,這種需求在實時控制系統(real-time control )中是很普遍的。
- No external events(沒有外部事件)
- User customizability(用戶定制)
??這是一個反映賦于用戶影響外部需求的維,設計空間可取三種值:- High(高級)
??用戶可以添加新的命令或重定義原命令的執行,同時也修改用戶接口的細節。 - Medium(中級)
??用戶可以修改不影響命令語義(semantics)的用戶接口細節,如,菜單項中的命令名、窗口的大小、顏色等允許用戶自己定制。 - Low(低級)
??很少或沒有用戶自定義的接口需求。
- High(高級)
- User Interface adaptability across devives(適應跨設備的用戶接口)
??該維依賴于應用程序中用戶接口支持的I/O設備。它反映當改變不同的I/O設備類型時用戶接口行為的改變程度(extent),設計空間取值有:- None(無)
??對于系統所支持的所有設備,所有的接口行為都是一樣的,即無需任何改變。 - Local behavior change(局部行為改變)
??當設備改變時,只允許改變個別的接口細節,如修改菜單的外觀(appearance)。 - Global behavior change(全局行為改變)
??跨越不同設備時,用戶接口行為在表面上有較大的改變,比如需要改變用戶接口類型。 - Application semantics change(應用語義改變)
??需要根本上修改命令的語義。
- None(無)
- Computer system organization(計算機系統組織)
??該維反映應用程序執行的周圍環境。主要有- Uniprocessing(單一處理)
??一個時間內只有一個應用程序 - Multiprocessing(多重處理)
??多個應用程序并發執行(concurrent) - Distributed processing(分布式處理)
??計算環境是網絡的、多CPU的和不可忽略的(non-negligible) 通信開銷等。
- Uniprocessing(單一處理)
2.Basic interactive behavior(基本交互行為)
- Basic interface class(基本接口類型)
??該維表示用戶接口所支持的人-機交互能力- Menu selection(菜單選擇)
??可以從事先定義的菜單中選擇執行,每次選擇后對應命令的執行也顯示出來,允許多次選擇。 - Form filling(表單填寫)
??通過填寫表單中指定的參數,決定程序的運行。 - Command language(命令語言)
??提供一種人工的符號語言,擴充過程定義,類似于一種程序語言。 - Natural language(自然語言)
??接口操作基于一種自然語言(如英語)的子集,關鍵問題是解釋那些不明確的(ambiguous)輸入。 - Direct manipulation(直接操作)
??接口操作直接基于圖形表示
- Menu selection(菜單選擇)
??需要提出,上述中只有菜單選擇和表單填寫可以支持同一種系統結構,其他類型的需求是單一的。
3.Practical considerations(考慮實際應用)
- Application portability across user interface styles(應用程序對用戶接口風格的適應)
??該維定義了用戶接口系統的適應性級別,表明用戶接口對特定應用(aplication-specific)組件的隔離程度。- High(高級)
??應用程序可以交叉使用不同的用戶接口風格, 比如命令語言和菜單。 - Medium(中級)
??應用程序獨立于用戶接口的少量風格變化,如菜單的外觀。 - Low(低級)
??沒有考慮用戶接口的改變,或者當用戶接口以改變時應用程序的改變是可以接受的。
- High(高級)
7.2.1.3 結構維例子(sample structure dimensions)
用戶接口的結構維
- 1.應用接口抽象層
- 單一程序
- 抽象設備
- 工具包
- 固定數據類型的交互管理
- 可擴展數據類型的交互管理
- 可擴展交互管理
- 2.抽象設備可變性
- 觀念設備
- 參數化設備
- 可變操作的設備
- 專用設備
- 3.用戶接口定義符號
- 隱含在可共享用戶接口代碼
- 隱含在應用代碼
- 外部說明符號
- 外部過程符號
- 內部說明符號
- 內部過程符號
- 4.基本通信
- 事件
- 純狀態
- 狀態提示
- 狀態+事件
- 5.控制線程機制
- 不支持
- 標準線程
- 輕量級線程
- 非搶占式線程
- 事件處理
- 中斷服務程序
??以上5種結構維可分為3組:
- Division of functions and knowledge among modules(模塊中功能和信息的劃分):這組維主要說明模塊中功能的確定、模塊間的連接、以及每個模塊所包含的信息。
- Representation issues(表示問題):這組主要考慮系統中使用的數據表示方法,也就是說要既要考慮在用戶接口中使用的實際數據,又要考慮用于指定用戶接口行為和外觀的元數據(metadata),系統中元數據可以是顯式的(explicitly),比如,用于描述對話框外觀的數據結構,也可以是隱含的(implicitly)。
- Control flow、communication、synchronization issues(控制流程、通信、同步問題):這組主要考慮用戶接口的動態行為(dynamic behavior)。
1.Division of functions and knowledge among modules(模塊中功能和信息的劃分)
- Application interface abstraction level (應用接口抽象層)
??在一定程度上,該維是一個關鍵的結構維,將其設計空間分為6個應用接口通過類型,它們由通信的抽象層來區分。- Monolithic program (單一程序)
??將所有接口功能集中在一個單一的程序中,沒有區分特定應用程序和共享程序,只有一個模塊也就不存在模塊間的接口。主要適合于小的系統或是一些對用戶接口的細節考慮全面的特殊系統。 - Abstract device(抽象設備)
??共享組件是一些簡單的設備驅動程序,為應用程序提供抽象設備的操作,接口行為的多數是由應用程序控制,少數也可由共享組件完成。在這類中應用程序接口就設備接口。 - Toolkit (工具包)
??共享組件提供一個交互技術庫(工具箱),如菜單、滾動條,應用程序則負責選擇工具箱元素,并將它們組合成一個完整的接口。這樣共享組件只能控制局部的用戶接口風格部分,接口的全局行為由應用程序控制。共享組件和應用程序組件之間的交互是按照指定的交互技術(如得到菜單的選擇)。對于工具箱中沒有提供的交互技術,應用程序可以直接訪問抽象設備層, 此時應用程序負責實現特定應用的數據類型和面向設備的表示間的轉換(conversion)。 - Interaction manager with fixed data types (固定數據類型的交互管理)
??共享組件控制局部和全局的交互順序(sequence)t 和格式(stylistic)的決定,它與應用程序的交互被表示為抽象信息的傳遞,這些抽象傳遞使用一組標準的數據(如整數、字符串),應用程序必須以標準的類型解釋它的輸入和輸出。 - Interaction manager with extensible data types(可擴展數據類型的交互管理)
??在上一種功能的基礎上,可能擴展數據類型,包括輸入和輸出的數據轉換也要求是新的數據類型,要完整地使用這種方式,一般要求接口的外部表示與應用主程序分開。 - Extensible interaction manager(可擴展交互管理)
??應用程序與共享組件間的通信也是通過抽象信息傳遞,應用程序可以定制擴展交互管理,這要求有而面向對象語言和繼承機制。
- Monolithic program (單一程序)
- Abstract device variability (抽象設備可變性)
??這是描述設備接口(device interface)的關健維,為了設備獨立性的操作我們把設備接口視為抽象設備(abstract device)。- Ideal device(觀念設備)
??在觀念設備中,操作及其結果經過詳細說明(specify),比如,廣泛使用的postScript的圖像模型,可以不考慮實際的打印機或顯示器的分辨率。在這種方法中,設備可變性都由設備驅動層隱藏,因此應用程序的可移植性很強,當觀念設備與實際設備偏離很小時,這種方法非常有用。 - Parameterized device(參數化設備)
??設備按一些指定的參數分類,如參數可以是屏幕大小、顏色數、鼠標的鍵數等。設備獨立性組件能根據參數值調整其行為,操作和結果也是經過詳細說明的,但要依賴于對應的參數,這種方式的好處是可以設備以最適合的參數操作,但它使得設備獨立性代碼要分析設備的參數所有范圍,在應用程序中實現開銷很大。 - Device with variable operations(可變操作的設備)
??擁有一組良定義的設備操作,但設備獨立性代碼在選擇操作實現時可能有很大地偏離(leeway),操作的結果也就可能不明確。這種方法在設備操作的選擇在在抽象層而驅動程序可以在很大范圍內選擇時可以發揮作用。 - Ad-hoc device(專用設備)
??在很多實際系統中,抽象設備定義局限于一種特別的方式,設備的不同其操作行為也改變,這樣應用程序可使用的設備種類的范圍很小,也就是說應用只能使用專門的設備。
- Ideal device(觀念設備)
2.Representation issues(表示問題)
- Notation for user interface definition (用戶接口定義符號)
??這是一個表示維,它說明用于定義用戶接口外觀和行為的技術。- Implicit in shared user interface code(隱含在可共享用戶接口代碼)
??這是一種完全可接受的方式,比如,菜單的可視外觀是隱含中工具箱提供的菜單過程中。 - Implicit in application code(隱含在應用代碼)
??用戶接口外觀和行為隱含在應用中,可用于當應用程序中緊含著用戶接口的情況。 - External declarative notation(外部說明符號)
??用戶接口外觀和行為在非過程部分定義,與應用程序分開。這種方式支持用戶自定義。 - External procedural notation (外部過程符號)
??用戶接口外觀和行為在一個過程中定義并與應用程序分開,這種方式較靈活但使用困難。 - Internal declarative notation (內部說明符號)
- Internal procedural notation(內部過程符號)
- Implicit in shared user interface code(隱含在可共享用戶接口代碼)
3.Control flow、communication、synchronization issues(控制流程、通信、同步問題)
- Basic of communication (基本通信)
??這是一個通信維,該維按模塊間的可共享狀態(shared state)、事件(event)通信方法區分。事件(event)是指發生在一個離散時間的信息傳遞。- Event(事件)
- Pure state (純狀態)
- State with hints (狀態提示)
- State plus events(狀態+事件)
- Control thread mechanism (控制線程機制)
??描述是否支持邏輯多線程,在用戶接口系統中支持多線程是很重要的。- None(不支持)
??只使用一個單獨的線程(只有一個線程的進程) - Standard processes (標準線程)
- Lightweight processes (輕量級線程)
- Non-preemptive processes (非搶占式線程)
- Event handlers (事件處理)
- Interrupt service routines(中斷服務程序)
- None(不支持)
7.2.2 用戶接口結構的設計規則
??規則指示了維之間的關系程度,主要有兩種類型
- 功能維與結構維的關系規則
??允許系統需求驅動結構設計 - 結構維內部之間的關系規則
??描述系統內部的一致性(consistency),這種規則使要發現一個具有更高得分的設計變得復雜。
規則例子(sample rules)
??如果外部事件處理需要搶占用戶命令,那么搶占控制線程機制(標準進程、輕量級進程或中斷服務例程)是非常受歡迎的。如果沒有這樣的機制,必須對所有用戶界面和應用程序處理施加非常嚴格的約束,以保證足夠的響應時間。
??高用戶可定制性要求有利于用戶界面行為的外部表示法。隱式和內部符號通常比外部符號更難訪問,并且更緊密地耦合到應用程序邏輯。
??分布式系統組織支持基于事件的通信。基于狀態的通信需要共享存儲器或一些等效的存儲器,在這樣的環境中訪問這些存儲器通常是昂貴的。
7.3 量化設計空間(Quantified Design Space,QDS)【重點】
7.3.1 簡介
??人們對軟件產品(artifact)的分析已經有多年的研究和實踐。在理論和經驗上,系統的性能(performance)、復雜性(complexity)、可靠性(reliable)、可測試性(testability)以及其他所期望的質量的度量已經成為軟件工程的主要組成(integral part)。然而軟件產品作為軟件開發過程的最后一個階段,對其分析的是重要的。現在已經達到共識:軟件產品可以與開發過程所依賴的設計一樣好。
??在過去,軟件分析工具的開發并沒伴隨(accompany)人們對軟件設計的逐慚關注而發展。原型技術( prototyping techniques)能證明(demonstrate)設計階段的可行性(feasibility)或研究(investigate)設計中的特殊問題。形式軟件檢查(inspection)可以在后期開發階段展開之前盡早地發現設計上的錯誤。形式描述語言(formal specification language)可以用于描述一個設計。但現在不沒有一個能從理論和質量上對設計進行分析的工具。這樣的工具應能提供一些度量設計符合產品所擁有的需求的程度,而無需構造一個原型,并且能使一個設計者將自己的知識應用于一個應用領域或致力于軟件設計和構造。
??量化設計空間(Quantified Design Space,QDS)是美國卡內基.梅隆(Carnegic Mellon)大學(CMU)提出的。QDS的目標是分析和比較一個指定應用的各種軟件設計,QDS的思想是基于設計空間(design space)和質量配置函數(quality function deployment,QFD),是一種將系統需求轉換為可選擇的功能和結構設計,量化(quantified)分析各種的可能選擇及其組合。QDS作用是可以為一個期望系統(desired system)制作(produce)一個設計模型,也可以用來分析和對比已有的設計,或對現有的設計提出改進建議。
7.3.1.1 質量配置函數(QFD)
??QFD是一個質量保證(assurance)技術,其作用是將客戶的需求轉換為產品從需求分析到設計開發各個階段的技術需求,或轉換為制造(manufacturing)和維護(support)。1997年QFD應用于日本的汽車制造并獲得顯著的效果,現在已經在日本和美國得到普遍應用。QFD的基本目標(fundamental)是“客戶的聲音”(voice of customer)出現在(manifested)產品開發過程的各個階段。QFD的觀點(philosophy)是讓所有的投資者對產品開發達成一個共識(common understanding)。
QFD技術帶來的好處
- 問題(issues)發現在開發階段,并且是問題形成之前。
- 決定(decision)記錄在一個有結構的框架中,必要時可以跟蹤(trace)。
- 在開發過程中過程的各個階段需求(requrement)不容易被誤解(misinterpreted)。
- 重復工作(rework)減少,需求改變最小化,減少產品進入市場所花的時間。
- 由定義的框架表示產品知識(knowledge),不僅可供現有產品開發使用,還可用于將來的工作。
- 最終產品更接近的客戶需求。
QFD過程
??QFD的基本原理(philosophy)是通過一組詳細說明的圖形符號和用于開發過程各個階段的良好定義的轉換機制(將需求轉換為實現)。QFD實現協作工程的多用戶設計系統的產品分析(同時有多用戶從從的單個設計側面協同工作)。
QFD過程的步驟如下:
-
步驟1:建立產品或服務開發的范圍,招集投資者代表參與QFD工作,收集各階段的用戶需求(這些需求用戶可按它們自己的語言表示),由交叉功能小組分析這些需求并達成共識,將這些需求加入到QFD表(如圖5.4)的左邊列中。

-
步驟2:QFD小組選擇滿足用戶需求的實現機制(realization mechanism),這些機制組織在QFD圖表的上端,建立用戶需求對實現機制的關系矩陣。
-
步驟3:為每個實現機制建立目標值(target value),并填入QFD圖表的關系矩陣的下方,這些目標可以是量化數值或量化目標,但這些目標都是可以主觀驗證的(verifiable)。
-
步驟4:建立機制與需求的關系(relationship),以確定不實現用戶需求哪一種機制是最重要的每一種關系可用圖形符號表示其程度(high、medium、Weak),如果某個機制不滿足一個需求,則對應的關系矩陣的值為空。例如,圖中,database manager機制與需求Work with large designs有強(strong)的系統性能關系,但與需求Apply expert knogledge系統能力上關系較弱(Weak)。這些關系賦于一個權值(weight)以便計算每個實現機制的重要性。分析這些關系是QFD的主要能力(strength)之一,比如,圖5.4中,起始可能認為database manager機制主要滿足Support cooperative design,但更進一步分析表明,有效的數據庫database manager機制對需求work with large designs也有很好的性能,這種“副效益”(side-benefit)在QFD框架中可以很清楚地表示出來。
-
步驟5:計算機制間的相關性(correlations)即各種實現機制間的正、負關系,正數關系表示兩種機制彼此都很好,負數關系表示一種機制的實現會干擾(interfere)另一個機制的實現。這些關系在QFD圖表的上方,用圖形符號表示關系程度,空格表示兩個機制沒有聯系。比如,圖5.4中表明ASCII文件的使用與數據庫管理有很嚴重的負關系。
-
步驟6:估計(assess)每一種機制的實現難度也根據組織的強弱,困難等級(rating)記錄在QFD圖表中target value的上方。
-
步驟7:計算每種機制的重要等級:一種機制的各關系值乘以QFD表右邊列(customer importance)對應客戶值的并相加得到這種機制的技術絕對值。為了明確起見,可以再將這些絕對值轉換為相對值,它們分別記錄在QFD圖表的底部。
-
步驟8::建立了關系(relationship)和相關性(correlation)后,FQD小組就可以分析該框架,選擇在產品中使用的機制。
- a.確定每種機制的目標值;
- b.檢查(inspect)每種相關性,找出可能沖突的機制,這突出某種機制允許為其相關性賦于一個權值,組織困難等級用數據表示出來。
- c.排除具有負相關性、高困難等級、風險性和低技術重要性的機制
- d.對于尚未充足表達的需求,可以再次檢查。
??過程的結果可以作為下一階段的產品開發。
QFD總結:
??為完成這個QFD例子,每個實現機制 (realization mechanism)要指出其目標值(target value),實現機制的各列要按相對技術重要性重排。這個框架還可以作為下一個QFD的輸入,比如選定database manager機制,另個指定通信使用(client-server),作為下一階段QFD的輸入。
7.3.2 量化設計空間(QDS)
QDS原理
- QDS的內容是設計空間的概念和QFD技術。
- QDS從設計空間中提取概念、一個設計分解成維及其可選擇的設計、設計維間的正負相關性,分析需求與實現機制間的關系,應用QFD過程。
- 這種基于QFD框架的設計空間的實現稱為量化設計空間(QDS)
應用QFD框架實現一個設計空間
??QFD過程的共同目標是獲取設計知識,即關于實現機制與客戶需求間的關系和機制間相關性的知識。設計空間的規則(rule)能從QFD框架中的關系和相關性獲得。比如,一個規則表明一個“distributed system”不能在一個“monolithic program”可實現。
通用功能設計空間(Generalized Functional Design Space)
??客戶需求列在表的左邊,賦于這些客戶需求的權置于表中另一個列,功能維及其可選擇的設計空間位于表的上方,并與需求構成的關系矩陣,關系值越大表明功能越能滿足需求,計算每個功能的“calculated weight”,及各需求的權,表的“design decision”中1表示可選用的功能。“effective weight”為“calculated weight”與“design decision”的積。

通用結構設計空間(Generalized Structure Design Space)

結構設計可選擇相關性(Corrlation of Structural Deisgn Alternative)

量化設計空間值(score)

??設E1、E2、…、En 是每個選定結構設計備選方案的有效重量;設Cmn為備選方案m和n的相關系數。
??對于每個選定的結構設計方案,將設計方案的有效權重與其他選定方案的有效權相加,并將總和的每個項乘以矩陣中的相關因子。然后將乘積總和相加,得出設計的最終得分: S r o c e = ∑ C i j ( E i + E j ) Sroce=\sum C_{ij}(E_i+E_j) Sroce=∑Cij?(Ei?+Ej?)
7.4 習題
- 簡述QDS的思想、作用及目標。
??QDS的思想是基于設計空間和質量配置函數,是一種將系統需求轉換為可選擇的功能和結構設計,量化分析各種的可能選擇及其組合。
??QDS作用是可以為一個期望系統制作一個設計模型,也可以用來分析和對比已有的設計,或對現有的設計提出改進建議。
??QDS的目標是分析和比較一個指定應用的各種軟件設計;
八、軟件體系結構描述
8.1 軟件體系結構形式化的意義
??通常,好的結構設計是決定軟件系統成功的主要因素,然而,目前許多有應用價值的結構,如管道/過濾器、層次結構、C/S結構等,他們都被認為是一種自然的習慣方法,并應用在特定的形式。因此,軟件系統的設計師還沒有完全開發出系統結構的共性,制定出設計間的選擇原則,從特定領域中研究出一般化的范例,或將自己的設計技能傳授他人。
??要使軟件體系結構的設計更具有科學性,一個重要的步驟是就是要有一個合適的形式化基礎。這一章我們將介紹軟件體系結構的形式化描述(formal specification)。
??人們已經認識到,對于一個成熟的工程學科,形式模型(formal model)和形式化分析技術(techniques for formal analysis)是基礎(cornerstone),只是不同工程學科他們使用的形式不同。形式化方法可以提供精確、抽象的模型,提供基于這些模型的分析技術,作為描述指定工程設計的表示法,也有助于模擬系統行為。因此在軟件體系結構領域,它的形式化描述也有很多的用處:
- The architecture of a specific system(指定系統的體系結構)
??這種類型的形式化,可以提供從軟件結構來設計一個特定的系統,這些形式化方法可以作為功能規格說明書的一個部分,擴充系統結構的非形式的特征,還可以詳細分析一個系統。 - An architecture style(軟件結構風格)
??這種類型的形式化,可以闡明一般結構化概念的含義,如,結構化連接、層次結構化的表示、結構化風格,在理想的情況下,這種形式化方法可以提供在結構一級基于推理方法分析系統。 - Formal semantics for architectural description language(結構描述語言的形式語義)
??這種類型的形式化,是用語言的方法描述結構,并應用傳統語言的技術表示描述語言的語義。
8.2 軟件體系結構描述的方法
軟件體系結構描述的方法分為
- 一般描述方法(或非形式的方法)
- 形式化描述方法。
常用的一般描述方法
- 主程序和子過程
- 數據抽象和面向對象設計
- 層次結構
常用的形式化描述方法
- Category Theory(類屬理論)
- Z Notation(Z標記語言)。
8.2.1 主程序和子過程
??在結構化范型中,將系統結構映射為主程序和一系列具有調用關系的子過程(或子函數)的集合。主程序充當子過程的調用者,子過程之間又存在著復雜的過程調用關系。過程之間通過參數傳入和傳出數據。這是軟件設計最直接、最基本的結構關系。更復雜的系統設計包含了模塊、包、庫、程序覆蓋等概念。
- 庫
??提供了系統設計支持的公用的二進制代碼,它是設計和調試好的子過程的集合。 - 包
??通常是是針對特定應用的類別所提供的公用子過程集合,它可以是源代碼或二進制代碼形式的。為了支持上運行時組裝,通常需要為包提供初始化操作,以維持包的初始狀態。 - 模塊
??具有與包類似的結構,但支持上層功能的轉換操作,可以看成是具有獨立主程序和子過程結構的功能塊。 - 程序覆蓋
??是在有限的存儲空間條件下,支持功能模塊和包對換的機制。
優點
- 是一切軟件結構的最本質、最基礎的形式,一切軟件的結構問題都可以通過在此層次上的代碼得追溯;
- 只要設計得當,代碼的效率可以得到最大限度的發揮和提高。
缺點
- 部件的連接關系不明顯。直觀的部件關系只是過程的調用,但實際支持的連接可以復雜,為把握部件之間的連接關系造成困難。
- 代碼的維護性差。簡單的過程調用關系為代碼的維護帶來困難,特別是數據據結構的變化會引起復雜的關聯變化。
- 代碼的重用性差。單純的過程概念不能反應復雜的軟件結構關系,難以成為軟件重用的基本單元,不能構成大規模的重用基礎。
8.2.2 數據抽象和面向對象設計
??數據抽象和面向對象設計是在主程序和子過程設計方法的基礎上建立和發展起來的重要的軟件描述方法。數據抽象是面向對象設計的理論基礎,類和對象是該描述方法的基礎粒度。
??類是數據抽象的載體,由數據成員和操作方法構成,成員的類型和取值范圍定義了數據運算的域,方法定義了對數據的運算及其遵循的公理,這樣,數據以及對它們的操作就被安然完整地封裝在一起而形成了抽象數據類型。
??對象是類的實例,是軟件系統的可運行實體,它全面復制了類的數據組成和操作方法,對象的數據反映了對象的生存狀態。對象之間是通過操作方法的調用建立相互作用關系,方法調用采用<對象名>.<方法名>(<參數>)的形式。這就是對象的信息隱藏性和封裝性,它保證了行為正確的對象在外界環境不出現意外時永遠是正確的。
??類的繼承性是一種重用機制。通過繼承類的數據和操作,并加以擴充,可以快速建立(或導出)起新的類。另外,封裝性保證了類或對象作為獨立體的完整性。
??多態性是同一行為名,作用在不同類的對象上時,對應的性質相同但操作細節不同的特性,保證了系統中部件要可替換兼容性。
??動態鏈接是在可環境中實現多態性的機制,也是運行代碼重用的機制,為運行代碼的擴充、升級提供了可能。
8.2.3 Category Theory(類屬理論)
??類屬理論是一種表達對象關系的數學語言,最初的研究是Samuel Eilenberg 和 Sanders Maclane提出的。廣泛用于描述軟件體系結構中的部件和連接器。
8.3 Z Notation簡介
??Z Notation是由牛津大學(University of Oxford )的Programming Research Group研究的一種數學語言,基于一階謂詞邏輯(firs-order logic)和集合論(set theory)。使用標準的邏輯操作符(∧、∨、→等)和集合操作符(∩、∪、∈等)以及它們的標準常規定義。
??使用Z Notation可以描述數學對象的模型,這些對象與程序計算對象相似,這是Z可作為體系結構和軟件工程描述的原因。
8.3.1 什么是形式規范(formal specifications)
??形式規范(formal specifications)是用數學表示法(notation)精確地描述信息系統的屬性,而不過分注重實現這些屬性的方法,也就是說,這些規范描述系統應該做什么而不關心系統如何實現。這種抽象使用得形式規范對開發計算機系統的過程很有意義,因為它們使得系統的問題能夠可信賴地回答,沒有必要解決大量的程序代碼細節。
??形式規范為客戶需求分析、程序實現、系統測試或編寫系統用戶手冊等人員提供一個單一、可靠的資料,因為一個系統的形式規范獨立于程序代碼,可以在系統開發之前完成。雖然在這些規范在系統設計階段或客戶需求變化時需要改變,但它們是促進對系統達成共識的一個有效方法。
8.3.2 Z notation的思想
??Z notation的思想是把描述一個系統的規范分解成若干圖表(schema,也稱架構或模式), 圖表(schema)可以再分解更小的圖表。在Z中,圖表(schema)用于描述系統的靜態和動態方面:
- 靜態方面(static aspects)包括:
- 系統的狀態;
- 維持系統從一個狀態向另一個狀態轉換的不變關系(invariant relationships);
- 動態方面(dynamic aspects)包括:
- 系統的可能操作;
- 輸入與輸出關系;
- 狀態的變化的產生。
例子:

8.3.3 聲明(Declarations)
??聲明滿足屬性的各種變量或變量的取值,在Z中有兩種基本的聲明方法。

- 聲明的變量是某集合的一組元素,顯式地列出。
??X1,X2,…,Xn : E - 聲明的變量是schema的引用(reference),以schema作為組件。
??聲明變量時,還可以指定是輸入或輸出,在變量后加上“?”表示該變量從用戶輸入;在變量后加上“!”表示輸出。
??聲明的變量的適用范圍由它出現的上下文(context)決定,可以是適合整個規范的全局變量,作為schema的組件,也可以是適合于某個謂詞或表達式的局部變量。
8.3.4 Schema texts
??一個schema文本是由聲明和或選擇的謂詞列表。
Schema-Text ::= Declaration [Predicate; : : : ; Predicate]
8.3.5 Predicates


? d e c l ∣ p r e d 1 ? p r e d 2 \forall decl\; |\; pred1 * pred2 ?decl∣pred1?pred2:它被讀作“對在 decl 中滿足謂詞 pred1 的所有變量,都使得謂詞 pred2 為真”;
? d e c l ∣ p r e d 1 ? p r e d 2 \exists decl\; |\; pred1 * pred2 ?decl∣pred1?pred2:它被讀作“存在 decl 中滿足謂詞 pred1 的一個或多個變量,使得謂詞 pred2 為真”;
九、J2EE體系結構分析及應用(了解即可)
詳情可以訪問下面博客
JavaEE
十、區塊鏈技術(補充)
【10.2和10.3任選一題即可,回答要寫明題目,技術名稱和意義】
10.1 基本概念
- 賬本
??按區塊存儲交易記錄,下一個區塊存儲上一個區塊的哈希值,形成鏈接的關系。 - 交易
??節點之間發生的支付。 - 挖礦
??在最新區塊鏈的數據上,生成一個符合條件的區塊,鏈入區塊鏈的過程,即區塊鏈上通過其特定計算公式,最快得到正確答案的機器就獲得相應虛擬貨幣獎勵的過程。這一過程就是挖礦,即通過PoW工作量證明算法,解決數學問題,來爭取記賬權。 - 共識
??就是所有分布式節之間怎么達成共識,通過算法來生成和更新數據,去認定一個記錄的有效性,這既是認定的手段,也是防止篡改的手段。以比特幣為例,采用的是“工作量證明”(Proof Of Work,簡稱POW)。工作量是需要算力的,通過工作量證明,有效的防止了篡改和偽造,因為如果要達到偽造和篡改的工作量,大概需要上億元成本跟的算力。
【共識機制是通過特殊節點的投票,在很短的時間內完成對交易的驗證和確認;對一筆交易,如果利益不相干的若干個節點能夠達成共識,我們就可以認為全網對此也能夠達成共識。】 - 智能合約
??是一種旨在以信息化方式傳播、驗證或執行合同的計算機協議。智能合約允許在沒有第三方的情況下進行可信交易,這些交易可追蹤且不可逆轉。智能合約概念于1995年由Nick Szabo首次提出。智能合約的目的是提供優于傳統合約的安全方法,并減少與合約相關的其他交易成本。一般解釋:智能合約實際上就是運行在以太坊網絡中的一段開放源代碼的程序,滿足觸發條件自動執行
【以信息化方式傳播、驗證或執行合同的計算機協議,允許在沒有第三方情況下進行可信交易,這些交易可追蹤且不可逆轉,也就是運行在以太網網絡中的一段開源程序,滿足觸發條件自動執行。】
10.2 區塊鏈在“數據追溯”方面的應用案例
- 食品溯源
??將牛肉生產的所有信息寫入文件,將文件的哈希值保存在區塊中;在食用每塊牛肉前,可以清楚知道這塊牛肉的來源,包括大到牛肉是來自哪一頭牛身上的哪一部位,牛的健康狀況,小到每一片牛肉是由誰切的,所有信息都可以追溯。;區塊鏈的信息無法篡改,保證每一條信息都是真實可靠的。任何人都不可能更改區塊鏈中的信息,所以所有信息都是可信任的 - 物流溯源
??區塊鏈技術可以記錄物流的全流程信息,包括貨物的來源、運輸、存儲、配送等,確保物流過程的真實性和可追溯性,從而提高物流效率和安全性。 - 交易溯源
??使用區塊鏈,交易的執行、清算和結算可以同時進行,交易完成后,自動寫入分布式賬本里,同時更新其他節點的賬本,大幅縮短結算周期;結合智能合約,當交易發生時,可以準確、迅速的自動進行處理。 - 數字版權
??通過hash算法等區塊鏈加密技術,將作品的權屬信息變成唯一的、真實的且不可篡改的區塊,保存在區塊鏈中。由作品的產生開始,版權的每一次授權、轉讓,都能夠被恒久的記錄和追蹤。通過秘鑰檢驗使用者是否被授權,沒有權限則拒絕任何訪問。這樣可以很好的保護數字版權,版權泄露時可以容易查出源頭。
10.3 區塊鏈在“共享經濟”方面的應用案例
德國Innogy共享充電樁
??德國能源巨頭Innogy和物聯網平臺企業Slock.it合作推出基于區塊鏈的電動汽車點對點充電項目。用戶無需與電力公司簽訂任何供電合同,只需在智能手機上安裝Share&Charge APP,并完成用戶驗證,即可在Innogy廣布歐洲的充電樁上進行充電,電價由后臺程序自動根據當時與當地的電網負荷情況實時確定。由于采用了區塊鏈技術,整個充電和電價優化過程是完全可追溯和可查詢的,因此極大地降低了信任成本。需要充電時,從APP中找到附近可用的充電站,按照智能合約中的價格付款給充電站主人。

![[單機]完美國際_V155_GM工具_VM虛擬機](http://pic.xiahunao.cn/[單機]完美國際_V155_GM工具_VM虛擬機)








 A. Ice Skating (并查集))

--HTML5語義化標簽)
)





