文章目錄
目錄
前言
一、基礎概念:什么是 MySQL 索引?
二、底層數據結構:為什么 InnoDB 偏愛 B + 樹?
B + 樹的結構特點(以短鏈接表short_link的short_code索引為例):
B + 樹的優勢:
三、索引類型:按功能和結構劃分
1. 按功能劃分(常用類型)
2. 按物理存儲劃分(InnoDB 核心區別)
四、工作原理:索引如何加速查詢?
場景 1:通過short_code查詢長鏈接(SELECT long_url FROM short_link WHERE short_code = 'abc123')
場景 2:查詢 “用戶 123 創建的所有短鏈”(SELECT * FROM short_link WHERE user_id = 123 ORDER BY create_time)
五、優缺點:索引不是 “銀彈”
優點:
缺點:
六、最佳實踐:如何正確使用索引?
1. 適合建索引的場景
2. 不適合建索引的場景
3. 避免索引失效的常見坑
總結
前言
????????MySQL 索引是數據庫性能優化的核心工具,如同書籍的目錄,能幫助數據庫快速定位數據,避免全表掃描。下面從基礎概念、底層結構、類型劃分、工作原理、優缺點及最佳實踐六個維度詳細解析,并結合實際業務場景(如短鏈接平臺、電商系統)說明其應用
一、基礎概念:什么是 MySQL 索引?
索引是 MySQL 在存儲引擎層(如 InnoDB)創建的數據結構,通過對表中特定字段的值進行排序和組織,實現 “快速定位數據位置” 的功能。
- 核心目標:減少磁盤 I/O 次數(數據庫操作中最耗時的環節),提升查詢效率。
- 類比:查詢表中
short_code = 'abc123'的短鏈接時,無索引需逐行掃描全表;有索引時,可直接通過索引定位到該記錄的物理地址,類似查字典時通過拼音目錄找漢字。
二、底層數據結構:為什么 InnoDB 偏愛 B + 樹?
MySQL 索引的底層數據結構取決于存儲引擎,InnoDB(MySQL 默認引擎)的索引基于B + 樹實現,而非哈希表、二叉樹等,原因是 B + 樹更適合數據庫的讀寫場景。
B + 樹的結構特點(以短鏈接表short_link的short_code索引為例):
- 層級化結構:由根節點、非葉子節點、葉子節點組成,層級通常為 3-4 層(百萬級數據僅需 3 次 I/O)。
- 葉子節點存完整數據(聚簇索引)或主鍵(非聚簇索引):
- 葉子節點按
short_code值有序排列,且通過雙向鏈表連接,支持范圍查詢(如short_code > 'abc' AND short_code < 'def')。 - 非葉子節點僅存 “索引值 + 子節點指針”,不存實際數據,節省內存空間。
- 葉子節點按
B + 樹的優勢:
- 平衡性:左右子樹高度差不超過 1,保證查詢效率穩定(不會出現極端情況下的長路徑)。
- 范圍查詢高效:葉子節點的雙向鏈表可快速遍歷連續數據(如查詢 “創建時間在 2023-01-01 到 2023-01-31 的短鏈接”)。
- 適配磁盤讀寫:節點大小通常為 16KB(InnoDB 頁大小),單次 I/O 可加載整個節點,減少 I/O 次數。
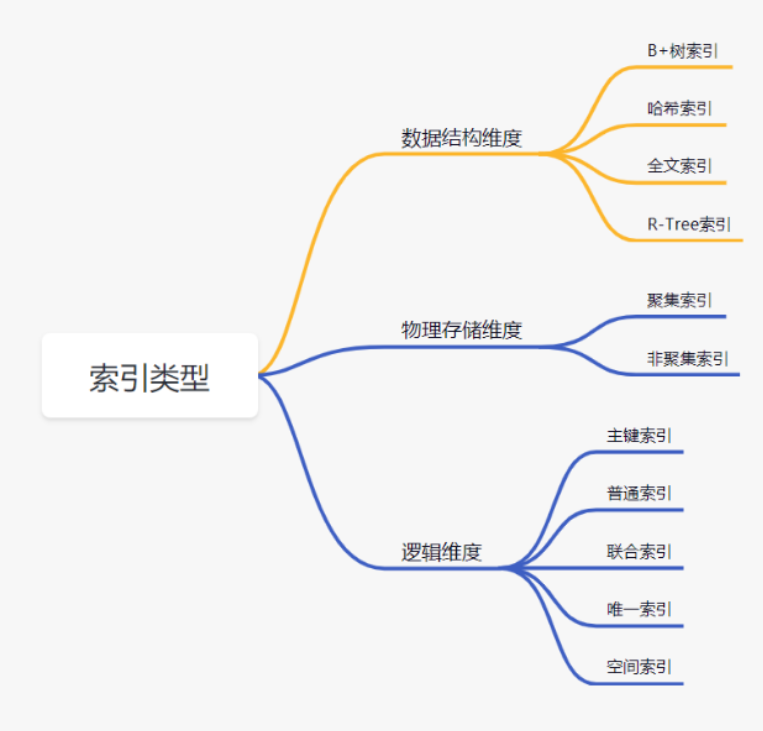
三、索引類型:按功能和結構劃分
1. 按功能劃分(常用類型)
| 索引類型 | 定義與特點 | 適用場景(結合業務) |
|---|---|---|
| 主鍵索引(PRIMARY KEY) | 表中唯一標識記錄的索引,默認自動創建,字段值非空且唯一,InnoDB 中為主鍵聚簇索引。 | 短鏈接表short_link的id字段(自增主鍵),或short_code(唯一短鏈碼),用于唯一定位單條記錄。 |
| 唯一索引(UNIQUE) | 字段值唯一(允許 NULL,但最多一個 NULL),可避免重復數據。 | 短鏈接表的short_code字段(若不為主鍵),防止生成重復短鏈;用戶表user的phone字段,確保手機號唯一。 |
| 普通索引(INDEX) | 無唯一性約束,最常用的索引類型,僅用于加速查詢。 | 短鏈接表的user_id(查詢 “某用戶創建的所有短鏈”)、create_time(按時間篩選短鏈)。 |
| 聯合索引(復合索引) | 對多個字段組合創建的索引,需遵循 “最左前綴原則”(查詢條件需包含最左字段)。 | 電商訂單表order的(user_id, create_time)聯合索引,優化 “查詢用戶 A 在 2023 年的所有訂單”。 |
| 全文索引(FULLTEXT) | 用于長文本字段(如varchar、text)的關鍵詞檢索,支持自然語言查詢。 | 商品表product的description字段,實現 “搜索含‘紅酒’關鍵詞的商品”。 |
2. 按物理存儲劃分(InnoDB 核心區別)
-
聚簇索引(Clustered Index):
索引與數據存儲在一起,葉子節點直接存儲完整的行數據(僅 InnoDB 有)。- 默認以主鍵為聚簇索引;若表無主鍵,InnoDB 會用唯一索引代替;若均無,則生成隱藏的
row_id作為聚簇索引。 - 例:短鏈接表
short_link的主鍵id為聚簇索引,葉子節點存id, short_code, long_url, user_id等完整字段。
- 默認以主鍵為聚簇索引;若表無主鍵,InnoDB 會用唯一索引代替;若均無,則生成隱藏的
-
非聚簇索引(Secondary Index):
索引與數據分離,葉子節點僅存儲 “索引值 + 聚簇索引值(主鍵)”,查詢時需先查非聚簇索引得到主鍵,再通過聚簇索引查完整數據(稱為 “回表”)。- 例:短鏈接表的
user_id普通索引,葉子節點存user_id + id,查詢user_id=123的短鏈詳情時,需先通過user_id索引找到id,再用id查聚簇索引獲取完整數據。
- 例:短鏈接表的
四、工作原理:索引如何加速查詢?
以短鏈接平臺的兩個核心查詢為例,解析索引的工作流程:
場景 1:通過short_code查詢長鏈接(SELECT long_url FROM short_link WHERE short_code = 'abc123')
-
若
short_code有唯一索引(非聚簇索引):- 數據庫通過 B + 樹查找
short_code = 'abc123'的葉子節點,獲取對應的主鍵id = 1001。 - 再通過聚簇索引(主鍵
id)查找id = 1001的葉子節點,獲取long_url(回表操作)。
- 數據庫通過 B + 樹查找
-
若查詢字段僅為
short_code和id(SELECT id, short_code FROM ...):- 非聚簇索引的葉子節點已包含
short_code + id,無需回表,直接返回結果(稱為 “覆蓋索引”,性能更優)。
- 非聚簇索引的葉子節點已包含
場景 2:查詢 “用戶 123 創建的所有短鏈”(SELECT * FROM short_link WHERE user_id = 123 ORDER BY create_time)
-
若
user_id有普通索引,create_time有普通索引:- 先通過
user_id索引篩選出所有user_id=123的記錄,得到對應的id列表。 - 再通過聚簇索引獲取每條記錄的完整數據,最后按
create_time排序(需額外排序操作)。
- 先通過
-
若建立
(user_id, create_time)聯合索引:- 索引葉子節點按
user_id排序,同user_id內按create_time排序,篩選后可直接按順序返回,無需額外排序(利用索引的有序性)。
- 索引葉子節點按
五、優缺點:索引不是 “銀彈”
優點:
- 加速查詢:大幅減少掃描行數,百萬級表中查詢耗時可從秒級降至毫秒級。
- 優化排序 / 分組:利用索引的有序性,避免
ORDER BY/GROUP BY時的文件排序(最耗時的操作之一)。
缺點:
- 占用存儲空間:索引需單獨存儲,一張表若有 5 個索引,存儲空間可能比表數據本身還大。
- 降低寫入效率:新增 / 修改 / 刪除數據時,需同步更新索引(B + 樹的插入 / 平衡操作耗時),寫入性能可能下降 50% 以上。
六、最佳實踐:如何正確使用索引?
1. 適合建索引的場景
- 頻繁查詢的字段:如短鏈接表的
short_code(每次跳轉都查詢)、用戶表的username(登錄查詢)。 - 排序 / 分組字段:如訂單表的
create_time(按時間統計訂單)、商品表的price(按價格排序)。 - 聯合查詢條件:如
WHERE a = ? AND b = ?,建立(a, b)聯合索引比單字段索引更高效。
2. 不適合建索引的場景
- 低頻查詢的字段:如 “用戶最后登錄 IP”(半年查一次),建索引浪費空間。
- 字段值重復率高:如 “性別”(僅男 / 女),索引篩選效率低(幾乎掃描全表)。
- 大字段:如
text類型的 “商品詳情”,索引維護成本極高(字段越長,B + 樹節點存儲的索引值越少,層級越深)。
3. 避免索引失效的常見坑
- 函數 / 表達式操作索引字段:
WHERE SUBSTR(short_code, 1, 3) = 'abc'會導致short_code索引失效(索引存原始值,函數處理后無法匹配)。 - 類型轉換:
WHERE short_code = 123(short_code是字符串)會觸發隱式轉換,索引失效(需寫成WHERE short_code = '123')。 - 模糊查詢左匹配:
WHERE short_code LIKE '%abc'(左模糊)索引失效,LIKE 'abc%'(右模糊)可命中索引。 - 違反最左前綴原則:
(a, b, c)聯合索引,僅WHERE b = ? AND c = ?無法命中索引(需包含最左字段a)。
總結
????????MySQL 索引是 “以空間換時間” 的典型設計,核心價值是通過 B + 樹等數據結構加速查詢,但需根據業務場景合理設計(如短鏈接的short_code唯一索引、訂單表的聯合索引),避免濫用導致寫入性能下降。理解索引的底層原理和失效場景,是數據庫性能優化的關鍵。
詳解(環境搭建+項目開發示例))


基礎概念)


)
:基于IMX6ULL的點燈操作》)






![洛谷P9468 [EGOI 2023] Candy / 糖果題解](http://pic.xiahunao.cn/洛谷P9468 [EGOI 2023] Candy / 糖果題解)
大模型入門【3】--基于Chailit客服端實現頁面AI對話)



