Stable Diffusion憑借其卓越的圖生圖功能,極大地提升了圖像生成的可控性與輸出品質,賦予用戶前所未有的個性化創作風格表達能力。這一革新特性使得Stable Diffusion不僅能精準地捕捉用戶的藝術愿景,更能以數字化手段孕育出新穎且極具創意的畫作。本篇教程將深入剖析圖生圖的原理,聚焦于Stable Diffusion的圖生圖AI繪畫技巧,助力您在創作獨特數字藝術作品時拓寬靈感源泉,精進技藝。
- 一、圖生圖原理
1. 擴散模型
Stable Diffusion的核心是基于擴散模型的框架。擴散模型是一種深度學習模型,它模仿物理過程中的分子擴散現象,將圖像從純噪聲逐漸演化為清晰圖像。這個過程分為兩個相反的階段:擴散(增加噪聲)和逆擴散(去除噪聲并恢復結構)。在圖生圖場景中,逆擴散階段被用來根據用戶提供的輸入圖片和提示詞,逐步生成目標圖像。
2. 條件輸入
不同于純粹的文生圖,圖生圖不僅接受文字提示,還接受一張源圖片作為額外條件。源圖片的信息被編碼為隱空間中的向量表示,與文字提示共同作為逆擴散過程的起點。模型在更新圖像狀態時,既參考了源圖片的結構特征,又受到文字提示的語義指導,從而生成與源圖相關聯且符合提示要求的新圖像。
3. 提示詞與反向提示詞
提示詞是用戶為指導生成過程提供的關鍵詞或短語,它們描述了期望的風格、氛圍、元素或主題。反向提示詞則用于指定不希望出現在生成結果中的內容。兩者結合使用,能夠更精確地約束模型的生成行為,確保輸出圖像既包含了期望的變化,又避免了不必要的元素。
二、圖生圖實戰
1. 準備工作
安裝Stable Diffusion環境和相關插件。前幾篇已講過了,還沒學習的同學,請到文章末尾查看往期教程,進行學習。SD Web UI 切換到圖生圖界面: 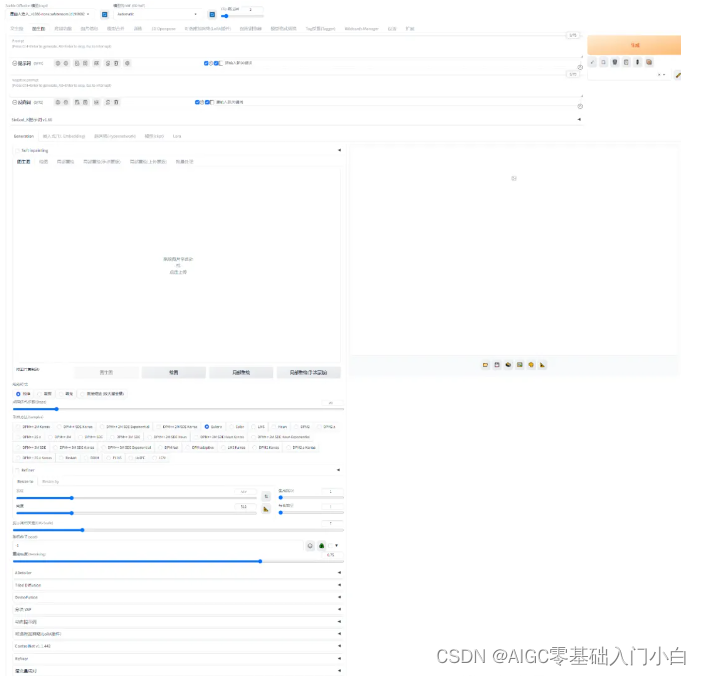圖生圖功能的主要特點:1、基于原始圖像作為參照,生成新圖像時確保關鍵的視覺樣式與布局得以忠實保留。2、運用文本指令,精準指引圖像生成的個性化路徑,涵蓋風格重塑、細節強化等多元需求。3、運用分布渲染技術遞進式提升與細化圖像品質,步步雕琢至理想狀態。4、借力于原圖固有的視覺元素,顯著提升生成圖像的契合度與可控性,確保結果貼合預期。5、輕松駕馭多種藝術流派的模擬演繹,只需借助精準的文字描述即可實現風格的無縫切換。6、具備高效批處理能力,可一次性自動化處理大量圖片,無縫完成整體優化與定制化修正。
2. 重要參數
step1 選擇一個寫實的大模型,再上傳源圖片:選擇一張清晰、主題明確的源圖片作為改造基礎。注意,圖片質量和內容直接影響生成結果。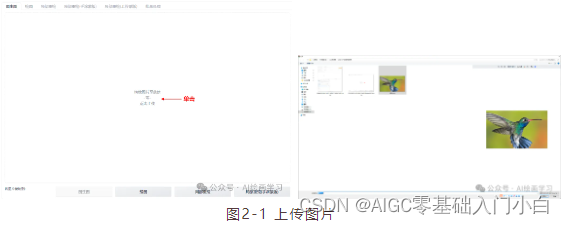
step2 縮放模式:(拉伸/剪裁/填充/直接縮放)
拉伸:自動調整大小,當寬高比例不正確時,主體被拉伸
剪裁:自動調整圖像大小,剪裁多余部分
填充:用圖像的顏色自動填充空白區域
直接縮放(放大潛變量) 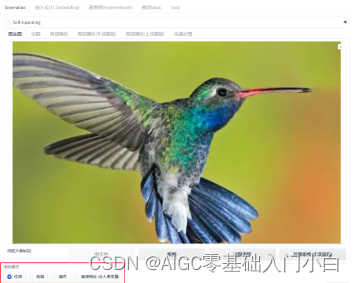
step3 圖片尺寸,點擊小三角會自動保持與原圖尺寸一致或自定義尺寸。如:512*512。
step4 編寫提示詞:構思簡潔而準確的提示詞,描述期望的生成效果。例如,“a hummingbird”。
step5 設置重繪幅度0~1 和 采樣方法,點擊“生成”按鈕。 
重繪幅度低于0.5更接近原圖,大于0.7AI創作力度變大。
3. 真人轉二次元 step1
下載一個二次元的大模型:AWPainting 下載地址:https://www.liblib.art/modelinfo/1fd281cf6bcf01b95033c03b471d8fd8
下載存放文件路徑:
step2 使用AWPainting模型,上傳圖片真人照片,設置尺寸512*768,重繪幅度0.6,采樣器DPM++ 2M
Karras,提示詞“animation style,a cute girl,”(你可隨意發揮)。

小技巧:你可以把重繪幅度設置0.2,循環生成圖片,逐步轉換二次元效果,最后通視頻編輯軟件把圖片制作轉場動畫。
4、制作頭像 step1
上傳大頭照512*512,使用AWPainting模型,設置同尺寸1024*1024,重繪幅度0.6,采樣器DPM++ 2M
Karras。
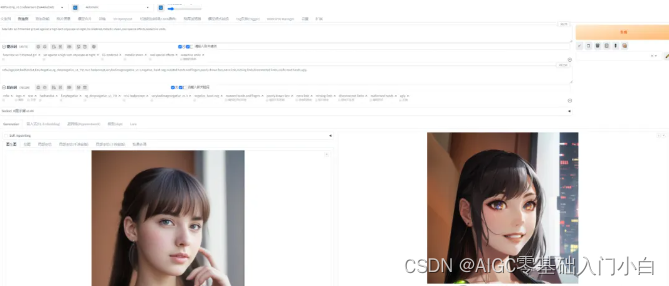
step2 提示詞"futuristic sci-fi themed girl,set against a high-tech
cityscape at night,CG rendered,metallic sheen,cool special
effects,seductive smile,",生成圖像。

總結:
篇幅有限,這里就不一一展示了,有需要的朋友可以點擊下方的卡片進行領取!







 A. Ice Skating (并查集))

--HTML5語義化標簽)
)






)


![[C++][數據結構]哈希3:unordered_map和unordered_set的模擬實現](http://pic.xiahunao.cn/[C++][數據結構]哈希3:unordered_map和unordered_set的模擬實現)