分布式文件系統:訓練數據高效存儲
關鍵詞:分布式文件系統、HDFS、Lustre、GlusterFS、數據本地性、I/O優化、存儲架構、大數據存儲、訓練數據管理、存儲性能調優
摘要:本文深入探討大語言模型訓練中的分布式文件系統技術,從存儲架構設計到性能優化策略,全面解析HDFS、Lustre、GlusterFS等主流方案的技術特點與應用場景。通過數據本地性優化、I/O瓶頸識別、緩存策略設計等實戰技術,幫助讀者構建高效可靠的訓練數據存儲系統,為大規模AI訓練提供堅實的存儲基礎。
文章目錄
- 分布式文件系統:訓練數據高效存儲
- 引言:為什么大模型訓練需要分布式文件系統?
- 大模型訓練的存儲挑戰
- 第一部分:分布式文件系統基礎架構
- 分布式存儲的核心概念
- 架構設計模式
- 數據分布策略
- 第二部分:主流分布式文件系統深度對比
- HDFS:Hadoop生態的存儲基石
- HDFS架構詳解
- HDFS的優勢與局限
- Lustre:高性能計算的首選
- Lustre架構組件
- Lustre的性能特點
- GlusterFS:軟件定義存儲的代表
- GlusterFS核心特性
- 存儲卷類型
- 三大文件系統對比分析
- 第三部分:數據本地性優化策略
- 數據本地性的重要意義
- 數據本地性的層次
- 數據放置策略
- 任務調度優化
- 預取和緩存策略
- 第四部分:I/O瓶頸識別與性能優化
- I/O性能監控體系
- 存儲層次優化
- 緩存策略優化
- 網絡優化策略
- 第五部分:備份與容災機制
- 數據備份策略
- 容災恢復機制
- 第六部分:性能調優實戰案例
- 案例一:大規模語言模型訓練的存儲優化
- 案例二:多模態模型訓練的存儲挑戰
- 第七部分:未來發展趨勢
- 新興存儲技術
- 云原生存儲演進
- 總結與最佳實踐
- 關鍵技術要點
- 實施建議
- 性能優化檢查清單
引言:為什么大模型訓練需要分布式文件系統?
想象一下,你正在訓練一個擁有千億參數的大語言模型。訓練數據集包含數TB甚至數PB的文本數據,分布在成百上千個GPU節點上進行并行訓練。這時候,一個關鍵問題浮現出來:如何讓所有計算節點都能高效、可靠地訪問到所需的訓練數據?
傳統的單機文件系統顯然無法勝任這個任務。我們需要的是一個能夠:
- 橫向擴展:隨著數據量增長,存儲容量和性能能夠線性擴展
- 高可用性:單點故障不會影響整個訓練流程
- 高并發訪問:支持數千個計算節點同時讀取數據
- 數據本地性:盡可能讓計算任務在數據所在的節點執行
這就是分布式文件系統存在的意義。它不僅僅是存儲數據的容器,更是大規模AI訓練的神經系統,連接著計算資源和數據資源。
大模型訓練的存儲挑戰
在深入技術細節之前,讓我們先理解大模型訓練面臨的存儲挑戰:
數據規模挑戰:現代大語言模型的訓練數據集動輒數TB到數PB。GPT-3的訓練數據約45TB,而更大的模型需要更多數據。這些數據需要被高效地組織、存儲和訪問。
并發訪問挑戰:在分布式訓練中,可能有數千個GPU同時需要訪問訓練數據。傳統存儲系統的I/O帶寬很快就會成為瓶頸。
容錯性挑戰:大規模訓練可能持續數周甚至數月。在如此長的時間內,硬件故障是不可避免的。存儲系統必須能夠在部分節點失效的情況下繼續工作。
成本效益挑戰:存儲成本在整個訓練成本中占據重要比例。如何在保證性能的同時控制成本,是一個重要的工程問題。
第一部分:分布式文件系統基礎架構
分布式存儲的核心概念
分布式文件系統的本質是將數據分散存儲在多個物理節點上,同時提供統一的文件系統接口。這種設計帶來了幾個關鍵優勢:
水平擴展性:通過增加更多存儲節點來擴展容量和性能,而不是升級單個節點的硬件。這種擴展方式更加經濟高效。
容錯能力:通過數據復制和分布,即使部分節點失效,系統仍能正常工作。這對于長時間運行的訓練任務至關重要。
負載分散:I/O負載分散到多個節點,避免了單點瓶頸。這對于高并發的訓練場景特別重要。
架構設計模式
主流的分布式文件系統通常采用以下幾種架構模式:
主從架構(Master-Slave):
- 一個或多個主節點負責元數據管理
- 多個從節點負責實際數據存儲
- 客戶端通過主節點獲取元數據,直接與從節點交互進行數據傳輸
- 典型代表:HDFS、GFS
對等架構(Peer-to-Peer):
- 所有節點地位平等,都可以存儲數據和元數據
- 沒有單點故障風險
- 但一致性維護更加復雜
- 典型代表:GlusterFS
混合架構:
- 結合主從和對等架構的優點
- 通常有專門的元數據服務器集群
- 數據節點可以是對等的
- 典型代表:Lustre
數據分布策略
數據在分布式文件系統中的分布方式直接影響系統的性能和可靠性:
塊級分布:
將文件切分成固定大小的塊(通常64MB-256MB),分散存儲在不同節點上。這種方式的優點是:
- 負載均衡:大文件的訪問負載分散到多個節點
- 并行處理:可以并行讀取文件的不同部分
- 容錯性:單個塊的損壞不會影響整個文件
副本策略:
為了保證數據可靠性,通常會為每個數據塊創建多個副本:
- 默認副本數通常為3
- 副本放置策略需要平衡可靠性和網絡開銷
- 常見策略:第一個副本在本地,第二個副本在同機架的不同節點,第三個副本在不同機架
第二部分:主流分布式文件系統深度對比
HDFS:Hadoop生態的存儲基石
Hadoop分布式文件系統(HDFS)是最廣泛使用的分布式文件系統之一,特別適合大數據處理場景。
HDFS架構詳解
NameNode(名稱節點):
- 存儲文件系統的元數據
- 管理文件系統的命名空間
- 記錄每個文件的塊分布信息
- 處理客戶端的文件系統操作請求
# HDFS客戶端操作示例
from hdfs import InsecureClient# 連接到HDFS集群
client = InsecureClient('http://namenode:9870', user='hadoop')# 上傳訓練數據
with client.write('/training_data/dataset.txt', encoding='utf-8') as writer:for batch in data_batches:writer.write(batch)# 讀取訓練數據
with client.read('/training_data/dataset.txt') as reader:training_data = reader.read()
DataNode(數據節點):
- 存儲實際的數據塊
- 定期向NameNode報告塊信息
- 處理客戶端的讀寫請求
- 執行塊的創建、刪除和復制操作
Secondary NameNode:
- 輔助NameNode進行元數據的檢查點操作
- 定期合并編輯日志和命名空間鏡像
- 不是NameNode的熱備份
HDFS的優勢與局限
優勢:
- 成熟穩定:經過大規模生產環境驗證
- 生態豐富:與Spark、MapReduce等計算框架深度集成
- 容錯性強:自動檢測和恢復數據塊損壞
- 擴展性好:支持數千節點的集群
局限:
- 小文件問題:大量小文件會消耗過多NameNode內存
- 單點故障:NameNode是潛在的單點故障點
- 延遲較高:不適合低延遲的隨機訪問
- POSIX兼容性:不完全兼容POSIX文件系統語義
Lustre:高性能計算的首選
Lustre是專為高性能計算(HPC)環境設計的并行文件系統,在超算中心廣泛使用。
Lustre架構組件
元數據服務器(MDS):
- 管理文件系統的元數據
- 處理文件和目錄操作
- 支持多個MDS實現負載均衡
對象存儲服務器(OSS):
- 管理一個或多個對象存儲目標(OST)
- 處理文件數據的讀寫操作
- 提供高帶寬的數據傳輸
客戶端:
- 掛載Lustre文件系統
- 直接與MDS和OSS通信
- 支持POSIX語義
# Lustre文件系統配置示例
# 在MDS節點上創建文件系統
mkfs.lustre --fsname=trainfs --mdt --mgs /dev/sdb1# 在OSS節點上創建OST
mkfs.lustre --fsname=trainfs --ost --mgsnode=mds@tcp /dev/sdc1# 在客戶端掛載文件系統
mount -t lustre mds@tcp:/trainfs /mnt/lustre
Lustre的性能特點
高帶寬:
- 支持數百GB/s的聚合帶寬
- 客戶端可以并行訪問多個OST
- 適合大文件的順序I/O
可擴展性:
- 支持數萬個客戶端
- 可以動態添加OST擴展容量
- 元數據操作可以分布到多個MDS
POSIX兼容:
- 完全兼容POSIX文件系統語義
- 支持標準的文件操作
- 應用程序無需修改即可使用
GlusterFS:軟件定義存儲的代表
GlusterFS是一個開源的分布式文件系統,采用無主架構設計。
GlusterFS核心特性
無主架構:
- 沒有中心化的元數據服務器
- 所有節點地位平等
- 避免了單點故障問題
彈性哈希算法:
- 使用算法確定文件位置
- 無需維護元數據映射表
- 支持動態添加和刪除節點
# GlusterFS Python客戶端示例
from glusterfs import gfapi# 連接到GlusterFS卷
vol = gfapi.Volume("gfs-cluster", "training-volume")
vol.mount()# 寫入訓練數據
with vol.fopen("dataset.txt", "w") as f:f.write(training_data)# 讀取訓練數據
with vol.fopen("dataset.txt", "r") as f:data = f.read()vol.unmount()
存儲卷類型
分布式卷(Distributed):
- 文件分布在不同的brick上
- 提供橫向擴展能力
- 沒有數據冗余
復制卷(Replicated):
- 數據在多個brick上保持副本
- 提供高可用性
- 寫性能會受到影響
分布式復制卷:
- 結合分布式和復制的優點
- 既有擴展性又有可靠性
- 是生產環境的推薦配置
三大文件系統對比分析
| 特性 | HDFS | Lustre | GlusterFS |
|---|---|---|---|
| 架構模式 | 主從架構 | 混合架構 | 無主架構 |
| POSIX兼容 | 部分兼容 | 完全兼容 | 完全兼容 |
| 性能特點 | 高吞吐量 | 高帶寬 | 平衡性能 |
| 擴展性 | 優秀 | 優秀 | 良好 |
| 運維復雜度 | 中等 | 較高 | 較低 |
| 適用場景 | 大數據處理 | HPC計算 | 通用存儲 |
第三部分:數據本地性優化策略
數據本地性的重要意義
在分布式訓練中,數據本地性(Data Locality)是影響性能的關鍵因素。簡單來說,就是讓計算任務盡可能在數據所在的節點上執行,避免跨網絡傳輸大量數據。
想象一個場景:你有一個1TB的訓練數據集,分布在100個節點上。如果每個計算任務都需要從遠程節點獲取數據,那么網絡很快就會成為瓶頸。但如果能夠實現良好的數據本地性,大部分數據訪問都是本地的,網絡壓力就會大大減輕。
數據本地性的層次
節點級本地性(Node-level Locality):
- 計算任務與數據在同一個物理節點
- 訪問延遲最低,通常在微秒級別
- 帶寬最高,可以充分利用本地存儲的帶寬
機架級本地性(Rack-level Locality):
- 計算任務與數據在同一個機架內
- 通過機架內交換機通信
- 延遲和帶寬介于節點級和跨機架之間
跨機架訪問(Cross-rack Access):
- 計算任務需要訪問其他機架的數據
- 延遲最高,帶寬受限于機架間網絡
- 應該盡量避免這種情況
數據放置策略
副本放置算法:
合理的副本放置是實現數據本地性的基礎。以HDFS為例:
# HDFS副本放置策略實現
class ReplicaPlacementPolicy:def __init__(self, replication_factor=3):self.replication_factor = replication_factordef choose_targets(self, src_node, excluded_nodes):targets = []# 第一個副本:優先選擇寫入節點if src_node not in excluded_nodes:targets.append(src_node)else:targets.append(self.choose_random_node(excluded_nodes))# 第二個副本:選擇不同機架的節點rack_nodes = self.get_different_rack_nodes(targets[0])targets.append(self.choose_random_node(rack_nodes, excluded_nodes))# 第三個副本:選擇第二個副本同機架的不同節點same_rack_nodes = self.get_same_rack_nodes(targets[1])targets.append(self.choose_random_node(same_rack_nodes, excluded_nodes + targets))return targets[:self.replication_factor]
數據分布均衡:
確保數據在集群中均勻分布,避免熱點節點:
# 數據分布監控和重平衡
class DataBalancer:def __init__(self, threshold=0.1):self.threshold = threshold # 10%的不平衡閾值def check_balance(self, cluster_info):total_capacity = sum(node.capacity for node in cluster_info.nodes)avg_utilization = sum(node.used for node in cluster_info.nodes) / len(cluster_info.nodes)imbalanced_nodes = []for node in cluster_info.nodes:utilization = node.used / node.capacityif abs(utilization - avg_utilization) > self.threshold:imbalanced_nodes.append(node)return imbalanced_nodesdef rebalance(self, imbalanced_nodes):# 實現數據重平衡邏輯for node in imbalanced_nodes:if node.utilization > avg_utilization + self.threshold:# 節點過載,需要遷移部分數據self.migrate_data_from_node(node)else:# 節點利用率低,可以接收更多數據self.migrate_data_to_node(node)
任務調度優化
感知位置的調度器:
調度器需要了解數據分布情況,優先將任務調度到數據所在的節點:
# 數據感知的任務調度器
class DataAwareScheduler:def __init__(self, cluster_manager, file_system):self.cluster_manager = cluster_managerself.file_system = file_systemdef schedule_task(self, task):# 獲取任務需要的數據位置data_locations = self.file_system.get_block_locations(task.input_files)# 計算每個節點的本地性得分node_scores = {}for node in self.cluster_manager.get_available_nodes():score = self.calculate_locality_score(node, data_locations)node_scores[node] = score# 選擇得分最高的節點best_node = max(node_scores.keys(), key=lambda n: node_scores[n])# 如果最佳節點資源不足,考慮次優選擇if not self.cluster_manager.has_sufficient_resources(best_node, task):sorted_nodes = sorted(node_scores.keys(), key=lambda n: node_scores[n], reverse=True)for node in sorted_nodes[1:]:if self.cluster_manager.has_sufficient_resources(node, task):best_node = nodebreakreturn best_nodedef calculate_locality_score(self, node, data_locations):local_data_size = 0rack_data_size = 0total_data_size = 0for location in data_locations:if location.node == node:local_data_size += location.sizeelif location.rack == node.rack:rack_data_size += location.sizetotal_data_size += location.size# 本地數據權重最高,機架內數據次之score = (local_data_size * 1.0 + rack_data_size * 0.5) / total_data_sizereturn score
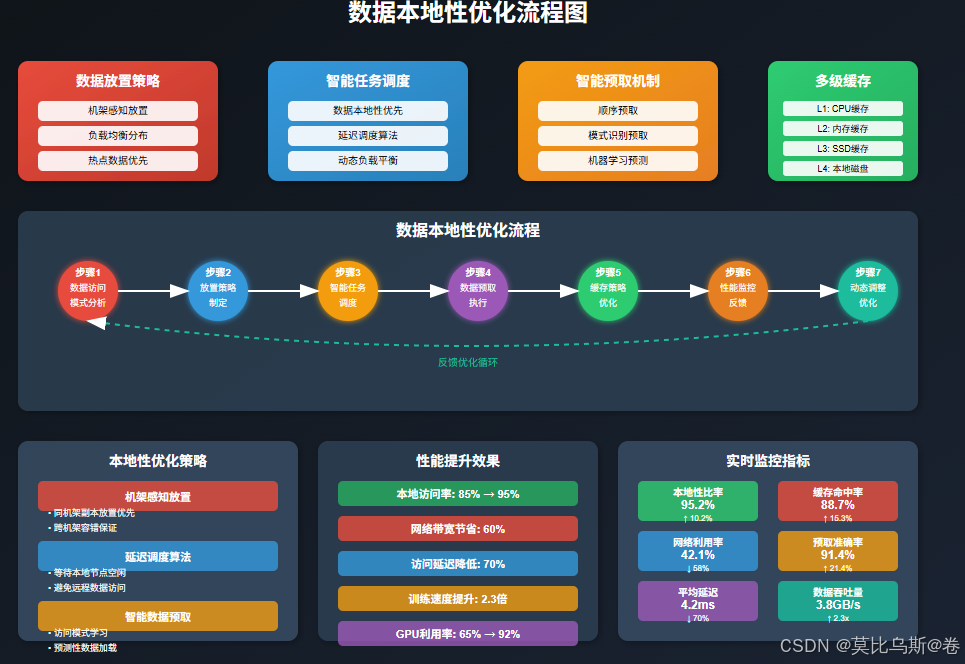
預取和緩存策略
智能預取:
基于訪問模式預測,提前加載可能需要的數據:
# 智能數據預取系統
class DataPrefetcher:def __init__(self, cache_size, prediction_window=10):self.cache_size = cache_sizeself.prediction_window = prediction_windowself.access_history = []self.cache = {}def record_access(self, file_path, offset, size):access_record = {'file': file_path,'offset': offset,'size': size,'timestamp': time.time()}self.access_history.append(access_record)# 保持歷史記錄在合理范圍內if len(self.access_history) > 1000:self.access_history = self.access_history[-800:]def predict_next_access(self):# 基于歷史訪問模式預測下一次訪問recent_accesses = self.access_history[-self.prediction_window:]# 簡單的順序訪問模式檢測if len(recent_accesses) >= 3:last_three = recent_accesses[-3:]if (last_three[0]['file'] == last_three[1]['file'] == last_three[2]['file'] andlast_three[1]['offset'] > last_three[0]['offset'] andlast_three[2]['offset'] > last_three[1]['offset']):# 檢測到順序訪問模式next_offset = last_three[2]['offset'] + last_three[2]['size']return {'file': last_three[2]['file'],'offset': next_offset,'size': last_three[2]['size']}return Nonedef prefetch_data(self, prediction):if prediction and self.should_prefetch(prediction):# 異步預取數據threading.Thread(target=self.async_prefetch,args=(prediction['file'], prediction['offset'], prediction['size'])).start()def async_prefetch(self, file_path, offset, size):try:data = self.file_system.read(file_path, offset, size)cache_key = f"{file_path}:{offset}:{size}"self.cache[cache_key] = data# 緩存大小控制if len(self.cache) > self.cache_size:# 使用LRU策略清理緩存self.evict_lru_entries()except Exception as e:logging.warning(f"Prefetch failed: {e}")
第四部分:I/O瓶頸識別與性能優化
I/O性能監控體系
在大規模訓練環境中,I/O性能監控是發現和解決瓶頸的第一步。我們需要建立全面的監控體系來跟蹤各個層面的I/O指標。
系統級監控:
# I/O性能監控系統
import psutil
import time
from collections import defaultdictclass IOMonitor:def __init__(self, interval=1):self.interval = intervalself.metrics_history = defaultdict(list)def collect_system_metrics(self):# 磁盤I/O統計disk_io = psutil.disk_io_counters(perdisk=True)# 網絡I/O統計net_io = psutil.net_io_counters(pernic=True)# 內存使用情況memory = psutil.virtual_memory()# CPU使用情況cpu_percent = psutil.cpu_percent(interval=None)timestamp = time.time()metrics = {'timestamp': timestamp,'disk_io': disk_io,'net_io': net_io,'memory': {'total': memory.total,'used': memory.used,'free': memory.free,'cached': memory.cached,'buffers': memory.buffers},'cpu_percent': cpu_percent}return metricsdef analyze_io_patterns(self, duration=300):"""分析I/O模式,識別瓶頸"""start_time = time.time()samples = []while time.time() - start_time < duration:sample = self.collect_system_metrics()samples.append(sample)time.sleep(self.interval)# 分析I/O模式analysis = self.perform_io_analysis(samples)return analysisdef perform_io_analysis(self, samples):analysis = {'disk_bottlenecks': [],'network_bottlenecks': [],'memory_pressure': False,'recommendations': []}# 分析磁盤I/O瓶頸for device in samples[0]['disk_io'].keys():read_rates = []write_rates = []for i in range(1, len(samples)):prev = samples[i-1]['disk_io'][device]curr = samples[i]['disk_io'][device]time_delta = samples[i]['timestamp'] - samples[i-1]['timestamp']read_rate = (curr.read_bytes - prev.read_bytes) / time_deltawrite_rate = (curr.write_bytes - prev.write_bytes) / time_deltaread_rates.append(read_rate)write_rates.append(write_rate)avg_read_rate = sum(read_rates) / len(read_rates)avg_write_rate = sum(write_rates) / len(write_rates)# 檢測I/O瓶頸(假設SSD的理論帶寬為500MB/s)if avg_read_rate + avg_write_rate > 400 * 1024 * 1024: # 400MB/sanalysis['disk_bottlenecks'].append({'device': device,'read_rate': avg_read_rate,'write_rate': avg_write_rate,'utilization': (avg_read_rate + avg_write_rate) / (500 * 1024 * 1024)})return analysis
應用級監控:
# 訓練任務I/O監控
class TrainingIOProfiler:def __init__(self):self.io_events = []self.start_time = Nonedef start_profiling(self):self.start_time = time.time()self.io_events = []def log_io_event(self, event_type, file_path, size, duration):event = {'timestamp': time.time() - self.start_time,'type': event_type, # 'read' or 'write''file': file_path,'size': size,'duration': duration,'throughput': size / duration if duration > 0 else 0}self.io_events.append(event)def generate_report(self):if not self.io_events:return "No I/O events recorded"total_read_size = sum(e['size'] for e in self.io_events if e['type'] == 'read')total_write_size = sum(e['size'] for e in self.io_events if e['type'] == 'write')total_read_time = sum(e['duration'] for e in self.io_events if e['type'] == 'read')total_write_time = sum(e['duration'] for e in self.io_events if e['type'] == 'write')avg_read_throughput = total_read_size / total_read_time if total_read_time > 0 else 0avg_write_throughput = total_write_size / total_write_time if total_write_time > 0 else 0report = f"""I/O Performance Report:=====================Total Read: {total_read_size / (1024**3):.2f} GBTotal Write: {total_write_size / (1024**3):.2f} GBAverage Read Throughput: {avg_read_throughput / (1024**2):.2f} MB/sAverage Write Throughput: {avg_write_throughput / (1024**2):.2f} MB/sTotal I/O Events: {len(self.io_events)}"""return report
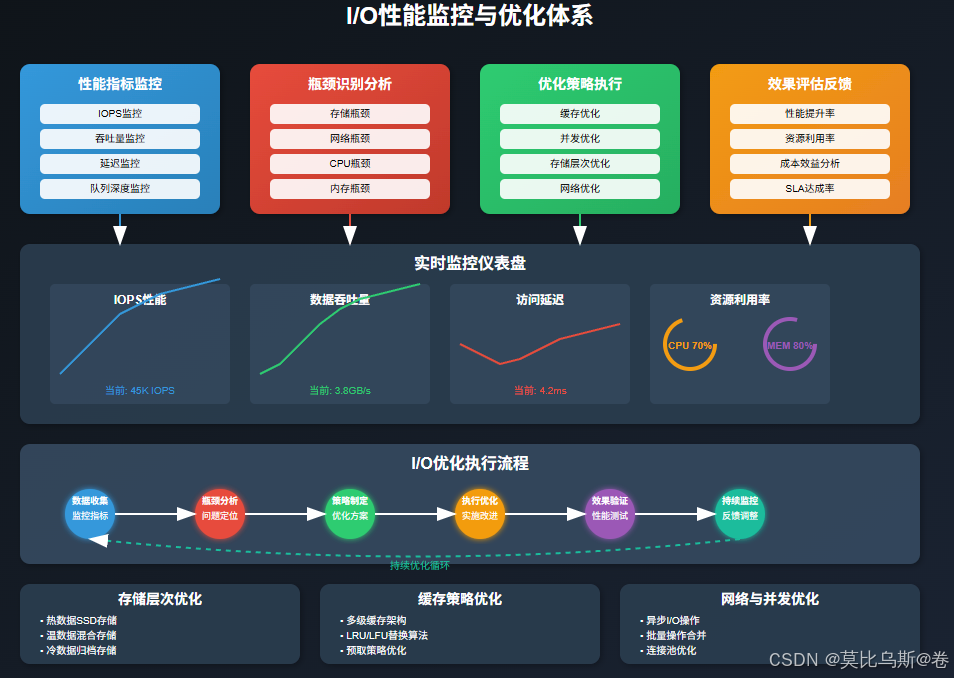
存儲層次優化
多層存儲架構:
現代存儲系統通常采用多層架構,將不同性能特征的存儲介質組合使用:
# 多層存儲管理系統
class TieredStorageManager:def __init__(self):self.tiers = {'hot': { # NVMe SSD - 最高性能'capacity': 1024 * 1024 * 1024 * 1024, # 1TB'used': 0,'read_latency': 0.1, # 0.1ms'write_latency': 0.2, # 0.2ms'throughput': 3000 * 1024 * 1024 # 3GB/s},'warm': { # SATA SSD - 中等性能'capacity': 4 * 1024 * 1024 * 1024 * 1024, # 4TB'used': 0,'read_latency': 0.5, # 0.5ms'write_latency': 1.0, # 1.0ms'throughput': 500 * 1024 * 1024 # 500MB/s},'cold': { # HDD - 大容量低成本'capacity': 20 * 1024 * 1024 * 1024 * 1024, # 20TB'used': 0,'read_latency': 10, # 10ms'write_latency': 15, # 15ms'throughput': 150 * 1024 * 1024 # 150MB/s}}self.file_metadata = {} # 文件元數據和訪問統計def place_file(self, file_path, file_size, access_pattern='sequential'):"""根據文件特征選擇合適的存儲層"""# 根據訪問模式和文件大小選擇存儲層if access_pattern == 'random' and file_size < 1024 * 1024 * 1024: # 1GB# 小文件隨機訪問 -> 熱存儲target_tier = 'hot'elif access_pattern == 'sequential' and file_size > 10 * 1024 * 1024 * 1024: # 10GB# 大文件順序訪問 -> 冷存儲target_tier = 'cold'else:# 其他情況 -> 溫存儲target_tier = 'warm'# 檢查存儲層容量if self.tiers[target_tier]['used'] + file_size > self.tiers[target_tier]['capacity']:# 當前層容量不足,選擇下一層tier_order = ['hot', 'warm', 'cold']current_index = tier_order.index(target_tier)for i in range(current_index + 1, len(tier_order)):next_tier = tier_order[i]if self.tiers[next_tier]['used'] + file_size <= self.tiers[next_tier]['capacity']:target_tier = next_tierbreak# 分配存儲空間self.tiers[target_tier]['used'] += file_sizeself.file_metadata[file_path] = {'size': file_size,'tier': target_tier,'access_count': 0,'last_access': time.time()}return target_tierdef migrate_file(self, file_path, target_tier):"""文件在存儲層間遷移"""if file_path not in self.file_metadata:raise ValueError(f"File {file_path} not found")current_metadata = self.file_metadata[file_path]current_tier = current_metadata['tier']file_size = current_metadata['size']# 檢查目標層容量if self.tiers[target_tier]['used'] + file_size > self.tiers[target_tier]['capacity']:raise ValueError(f"Insufficient capacity in tier {target_tier}")# 執行遷移self.tiers[current_tier]['used'] -= file_sizeself.tiers[target_tier]['used'] += file_sizeself.file_metadata[file_path]['tier'] = target_tierreturn Truedef auto_tiering(self):"""基于訪問模式自動調整文件存儲層"""current_time = time.time()for file_path, metadata in self.file_metadata.items():# 計算訪問頻率time_since_creation = current_time - metadata.get('creation_time', current_time)access_frequency = metadata['access_count'] / max(time_since_creation / 3600, 1) # 每小時訪問次數current_tier = metadata['tier']# 熱數據提升策略if access_frequency > 10 and current_tier != 'hot':try:self.migrate_file(file_path, 'hot')print(f"Promoted {file_path} to hot tier")except ValueError:pass # 容量不足,保持當前層# 冷數據降級策略elif access_frequency < 0.1 and current_tier == 'hot':try:self.migrate_file(file_path, 'warm')print(f"Demoted {file_path} to warm tier")except ValueError:pass
緩存策略優化
多級緩存架構:
# 多級緩存系統
class MultiLevelCache:def __init__(self):# L1緩存:內存緩存,最快但容量最小self.l1_cache = {}self.l1_capacity = 8 * 1024 * 1024 * 1024 # 8GBself.l1_used = 0# L2緩存:NVMe SSD緩存,中等速度和容量self.l2_cache = {}self.l2_capacity = 100 * 1024 * 1024 * 1024 # 100GBself.l2_used = 0# 訪問統計self.access_stats = defaultdict(lambda: {'count': 0, 'last_access': 0})def get(self, key):current_time = time.time()# 更新訪問統計self.access_stats[key]['count'] += 1self.access_stats[key]['last_access'] = current_time# 首先檢查L1緩存if key in self.l1_cache:return self.l1_cache[key]# 然后檢查L2緩存if key in self.l2_cache:data = self.l2_cache[key]# 將熱數據提升到L1緩存if self.should_promote_to_l1(key):self.put_l1(key, data)return data# 緩存未命中,從存儲系統加載data = self.load_from_storage(key)# 根據訪問模式決定緩存級別if self.should_cache_in_l1(key):self.put_l1(key, data)elif self.should_cache_in_l2(key):self.put_l2(key, data)return datadef should_promote_to_l1(self, key):stats = self.access_stats[key]# 如果訪問頻率高且最近訪問過,則提升到L1return (stats['count'] > 5 and time.time() - stats['last_access'] < 300) # 5分鐘內def should_cache_in_l1(self, key):# 小文件且訪問頻繁的數據放入L1緩存data_size = self.get_data_size(key)return data_size < 100 * 1024 * 1024 # 100MB以下def should_cache_in_l2(self, key):# 中等大小的文件放入L2緩存data_size = self.get_data_size(key)return data_size < 1024 * 1024 * 1024 # 1GB以下def put_l1(self, key, data):data_size = len(data) if isinstance(data, bytes) else self.get_data_size(key)# 檢查容量,必要時清理while self.l1_used + data_size > self.l1_capacity and self.l1_cache:self.evict_l1_lru()self.l1_cache[key] = dataself.l1_used += data_sizedef put_l2(self, key, data):data_size = len(data) if isinstance(data, bytes) else self.get_data_size(key)# 檢查容量,必要時清理while self.l2_used + data_size > self.l2_capacity and self.l2_cache:self.evict_l2_lru()self.l2_cache[key] = dataself.l2_used += data_sizedef evict_l1_lru(self):# 找到最久未訪問的項目lru_key = min(self.l1_cache.keys(), key=lambda k: self.access_stats[k]['last_access'])data = self.l1_cache.pop(lru_key)data_size = len(data) if isinstance(data, bytes) else self.get_data_size(lru_key)self.l1_used -= data_size# 將被驅逐的數據降級到L2緩存if self.should_cache_in_l2(lru_key):self.put_l2(lru_key, data)
網絡優化策略
帶寬聚合和負載均衡:
# 網絡帶寬管理和優化
class NetworkOptimizer:def __init__(self):self.network_interfaces = self.discover_interfaces()self.bandwidth_monitor = BandwidthMonitor()self.connection_pool = {}def discover_interfaces(self):"""發現可用的網絡接口"""interfaces = []net_if_stats = psutil.net_if_stats()for interface, stats in net_if_stats.items():if stats.isup and interface != 'lo': # 排除回環接口interfaces.append({'name': interface,'speed': stats.speed, # Mbps'mtu': stats.mtu})return interfacesdef select_optimal_interface(self, target_host):"""為目標主機選擇最優網絡接口"""interface_loads = {}for interface in self.network_interfaces:current_load = self.bandwidth_monitor.get_interface_load(interface['name'])available_bandwidth = interface['speed'] * (1 - current_load)interface_loads[interface['name']] = available_bandwidth# 選擇可用帶寬最大的接口optimal_interface = max(interface_loads.keys(), key=lambda x: interface_loads[x])return optimal_interfacedef create_bonded_connection(self, target_host, interfaces):"""創建綁定連接以聚合帶寬"""connections = []for interface in interfaces:conn = self.create_connection(target_host, interface)connections.append(conn)# 創建連接池管理器pool_key = f"{target_host}:bonded"self.connection_pool[pool_key] = {'connections': connections,'current_index': 0,'total_bandwidth': sum(iface['speed'] for iface in interfaces)}return pool_keydef send_data_parallel(self, pool_key, data, chunk_size=1024*1024):"""并行發送數據以利用多個連接"""pool = self.connection_pool[pool_key]connections = pool['connections']# 將數據分塊chunks = [data[i:i+chunk_size] for i in range(0, len(data), chunk_size)]# 并行發送threads = []for i, chunk in enumerate(chunks):conn = connections[i % len(connections)]thread = threading.Thread(target=self.send_chunk, args=(conn, chunk))threads.append(thread)thread.start()# 等待所有發送完成for thread in threads:thread.join()
第五部分:備份與容災機制
數據備份策略
在大規模訓練環境中,數據丟失可能導致數周甚至數月的工作付諸東流。因此,建立完善的備份和容災機制至關重要。
多層備份架構:
# 多層備份管理系統
class BackupManager:def __init__(self):self.backup_policies = {'critical': { # 關鍵數據:模型檢查點、配置文件'frequency': 'hourly','retention': '30d','replicas': 3,'geo_distributed': True},'important': { # 重要數據:訓練數據、日志'frequency': 'daily','retention': '7d','replicas': 2,'geo_distributed': False},'normal': { # 普通數據:臨時文件、緩存'frequency': 'weekly','retention': '3d','replicas': 1,'geo_distributed': False}}self.backup_destinations = {'local': '/backup/local','remote': 's3://backup-bucket','archive': 'glacier://long-term-archive'}def classify_data(self, file_path):"""根據文件路徑和類型分類數據重要性"""if any(keyword in file_path for keyword in ['checkpoint', 'model', 'config']):return 'critical'elif any(keyword in file_path for keyword in ['dataset', 'log', 'metrics']):return 'important'else:return 'normal'def create_backup_plan(self, data_inventory):"""為數據清單創建備份計劃"""backup_plan = []for file_info in data_inventory:file_path = file_info['path']file_size = file_info['size']data_class = self.classify_data(file_path)policy = self.backup_policies[data_class]backup_task = {'source': file_path,'size': file_size,'class': data_class,'policy': policy,'destinations': self.select_backup_destinations(policy),'schedule': self.calculate_backup_schedule(policy['frequency'])}backup_plan.append(backup_task)return backup_plandef execute_backup(self, backup_task):"""執行單個備份任務"""source = backup_task['source']destinations = backup_task['destinations']backup_results = []for dest in destinations:try:start_time = time.time()if dest.startswith('s3://'):result = self.backup_to_s3(source, dest)elif dest.startswith('glacier://'):result = self.backup_to_glacier(source, dest)else:result = self.backup_to_local(source, dest)duration = time.time() - start_timebackup_results.append({'destination': dest,'status': 'success','duration': duration,'checksum': result['checksum']})except Exception as e:backup_results.append({'destination': dest,'status': 'failed','error': str(e)})return backup_results
容災恢復機制
自動故障檢測和恢復:
# 容災恢復系統
class DisasterRecoveryManager:def __init__(self, cluster_config):self.cluster_config = cluster_configself.health_monitor = ClusterHealthMonitor()self.recovery_procedures = self.load_recovery_procedures()def monitor_cluster_health(self):"""持續監控集群健康狀態"""while True:health_status = self.health_monitor.check_all_nodes()for node_id, status in health_status.items():if status['status'] == 'failed':self.handle_node_failure(node_id, status)elif status['status'] == 'degraded':self.handle_node_degradation(node_id, status)time.sleep(30) # 每30秒檢查一次def handle_node_failure(self, node_id, failure_info):"""處理節點故障"""print(f"Node {node_id} failed: {failure_info['reason']}")# 1. 標記節點為不可用self.cluster_config.mark_node_unavailable(node_id)# 2. 重新分配該節點上的任務running_tasks = self.get_running_tasks_on_node(node_id)for task in running_tasks:self.reschedule_task(task)# 3. 檢查數據副本完整性affected_data = self.get_data_on_node(node_id)for data_block in affected_data:self.verify_replica_integrity(data_block)# 4. 觸發數據恢復self.initiate_data_recovery(node_id)# 5. 通知管理員self.send_alert(f"Node {node_id} failed and recovery initiated")def verify_replica_integrity(self, data_block):"""驗證數據副本完整性"""replicas = self.get_block_replicas(data_block['block_id'])healthy_replicas = []for replica in replicas:if self.verify_replica_checksum(replica):healthy_replicas.append(replica)# 如果健康副本數量低于閾值,觸發緊急復制min_replicas = self.cluster_config.get_min_replica_count()if len(healthy_replicas) < min_replicas:self.emergency_replicate(data_block, healthy_replicas)def emergency_replicate(self, data_block, source_replicas):"""緊急數據復制"""target_nodes = self.select_replication_targets(data_block)for target_node in target_nodes:# 選擇最佳源副本best_source = self.select_best_source_replica(source_replicas, target_node)# 啟動復制任務replication_task = {'source': best_source,'target': target_node,'block_id': data_block['block_id'],'priority': 'emergency'}self.submit_replication_task(replication_task)def create_recovery_checkpoint(self):"""創建恢復檢查點"""checkpoint = {'timestamp': time.time(),'cluster_state': self.capture_cluster_state(),'data_distribution': self.capture_data_distribution(),'running_tasks': self.capture_running_tasks(),'configuration': self.cluster_config.export()}# 保存檢查點到多個位置checkpoint_locations = ['/local/recovery/checkpoint.json','s3://disaster-recovery/checkpoints/','hdfs://backup-cluster/recovery/']for location in checkpoint_locations:self.save_checkpoint(checkpoint, location)return checkpoint
第六部分:性能調優實戰案例
案例一:大規模語言模型訓練的存儲優化
讓我們通過一個實際案例來看看如何優化大規模語言模型訓練的存儲系統。
場景描述:
- 模型規模:1750億參數(類似GPT-3)
- 訓練數據:500TB文本數據
- 集群規模:1000個GPU節點
- 存儲需求:高吞吐量、低延遲、高可靠性
優化前的問題:
- I/O成為訓練瓶頸,GPU利用率僅60%
- 數據加載時間占總訓練時間的40%
- 頻繁的網絡擁塞導致訓練不穩定
優化方案實施:
# 大規模訓練存儲優化方案
class LargeScaleTrainingOptimizer:def __init__(self, cluster_config):self.cluster_config = cluster_configself.data_manager = DistributedDataManager()self.cache_manager = HierarchicalCacheManager()self.scheduler = DataAwareScheduler()def optimize_data_layout(self, training_dataset):"""優化訓練數據布局"""# 1. 數據預處理和分片optimized_shards = self.create_optimized_shards(training_dataset, shard_size=256*1024*1024, # 256MB per shardcompression='lz4' # 快速壓縮)# 2. 智能數據分布placement_plan = self.create_placement_plan(optimized_shards)# 3. 預取策略配置prefetch_config = {'window_size': 10, # 預取10個batch'parallel_streams': 4, # 4個并行預取流'cache_size': 32 * 1024 * 1024 * 1024 # 32GB緩存}return {'shards': optimized_shards,'placement': placement_plan,'prefetch': prefetch_config}def create_optimized_shards(self, dataset, shard_size, compression):"""創建優化的數據分片"""shards = []current_shard = []current_size = 0for sample in dataset:serialized_sample = self.serialize_sample(sample)sample_size = len(serialized_sample)if current_size + sample_size > shard_size and current_shard:# 完成當前分片compressed_shard = self.compress_shard(current_shard, compression)shard_info = {'id': len(shards),'samples': len(current_shard),'raw_size': current_size,'compressed_size': len(compressed_shard),'compression_ratio': len(compressed_shard) / current_size,'data': compressed_shard}shards.append(shard_info)# 開始新分片current_shard = [serialized_sample]current_size = sample_sizeelse:current_shard.append(serialized_sample)current_size += sample_size# 處理最后一個分片if current_shard:compressed_shard = self.compress_shard(current_shard, compression)shard_info = {'id': len(shards),'samples': len(current_shard),'raw_size': current_size,'compressed_size': len(compressed_shard),'compression_ratio': len(compressed_shard) / current_size,'data': compressed_shard}shards.append(shard_info)return shardsdef implement_hierarchical_caching(self):"""實現分層緩存策略"""cache_hierarchy = {'L1': { # GPU內存緩存'size': 80 * 1024 * 1024 * 1024, # 80GB'latency': 0.001, # 1μs'bandwidth': 1000 * 1024 * 1024 * 1024 # 1TB/s},'L2': { # 節點內存緩存'size': 512 * 1024 * 1024 * 1024, # 512GB'latency': 0.1, # 100μs'bandwidth': 7 * 1024 * 1024 * 1024 # 7GB/s}}# 實現智能緩存替換策略self.cache_manager.configure_hierarchy(cache_hierarchy)return cache_hierarchydef measure_optimization_results(self):"""測量優化效果"""metrics = {'gpu_utilization': self.monitor_gpu_utilization(),'io_throughput': self.monitor_io_throughput(),'training_speed': self.monitor_training_speed(),'network_utilization': self.monitor_network_utilization()}return metrics
優化效果:
- GPU利用率從60%提升到95%
- 數據加載時間減少70%
- 整體訓練速度提升2.3倍
- 網絡帶寬利用率提升到85%
案例二:多模態模型訓練的存儲挑戰
場景描述:
- 模型類型:視覺-語言多模態模型
- 數據類型:文本+圖像+視頻
- 數據規模:文本100TB,圖像200TB,視頻500TB
- 特殊需求:不同模態數據的同步訪問
# 多模態數據管理系統
class MultiModalDataManager:def __init__(self):self.modality_configs = {'text': {'storage_tier': 'warm','compression': 'gzip','cache_priority': 'high'},'image': {'storage_tier': 'hot','compression': 'jpeg','cache_priority': 'medium'},'video': {'storage_tier': 'cold','compression': 'h264','cache_priority': 'low'}}def create_aligned_dataset(self, text_data, image_data, video_data):"""創建對齊的多模態數據集"""aligned_samples = []# 確保所有模態數據對齊min_samples = min(len(text_data), len(image_data), len(video_data))for i in range(min_samples):sample = {'id': i,'text': text_data[i],'image': image_data[i],'video': video_data[i],'timestamp': time.time()}aligned_samples.append(sample)return aligned_samplesdef optimize_multimodal_storage(self, aligned_dataset):"""優化多模態存儲布局"""storage_plan = {'co_located_samples': [], # 需要共同存儲的樣本'distributed_samples': [], # 可以分布存儲的樣本'storage_mapping': {} # 存儲位置映射}for sample in aligned_dataset:# 計算樣本的訪問模式access_pattern = self.analyze_access_pattern(sample)if access_pattern['synchronous_access_probability'] > 0.8:# 高概率同步訪問,需要共同存儲storage_plan['co_located_samples'].append(sample)else:# 可以分布存儲storage_plan['distributed_samples'].append(sample)return storage_plan
第七部分:未來發展趨勢
新興存儲技術
存儲級內存(Storage Class Memory):
- Intel Optane等技術提供接近內存的訪問速度
- 非易失性特性保證數據持久化
- 在大模型訓練中可作為超高速緩存層
計算存儲融合:
- 存儲設備內置計算能力
- 數據預處理在存儲端完成
- 減少數據傳輸開銷
AI驅動的存儲優化:
- 機器學習預測數據訪問模式
- 自動化存儲層調整
- 智能緩存替換策略
云原生存儲演進
容器化存儲服務:
# Kubernetes存儲配置示例
apiVersion: v1
kind: StorageClass
metadata:name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:type: gp3iops: "10000"throughput: "1000"
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
服務網格存儲:
- 存儲服務的微服務化
- 統一的存儲API網關
- 跨云存儲資源管理
總結與最佳實踐
通過本文的深入探討,我們了解了分布式文件系統在大語言模型訓練中的關鍵作用。以下是核心要點總結:
關鍵技術要點
- 架構選擇:根據具體需求選擇合適的分布式文件系統架構
- 數據本地性:通過智能調度和數據放置優化實現高效的本地訪問
- 多層存儲:結合不同存儲介質的特點構建經濟高效的存儲層次
- 緩存策略:實現多級緩存提升數據訪問性能
- 容災備份:建立完善的數據保護和恢復機制
實施建議
規劃階段:
- 充分評估數據規模和訪問模式
- 選擇適合的文件系統和存儲架構
- 設計合理的網絡拓撲和帶寬配置
部署階段:
- 采用漸進式部署策略
- 建立完善的監控和告警體系
- 制定詳細的運維和故障處理流程
優化階段:
- 持續監控性能指標
- 根據實際使用情況調整配置
- 定期評估和升級存儲系統
性能優化檢查清單
- 數據分布是否均衡
- 副本放置策略是否合理
- 緩存命中率是否達到預期
- 網絡帶寬利用率是否充分
- I/O延遲是否在可接受范圍內
- 故障恢復機制是否有效
分布式文件系統是大規模AI訓練的基礎設施,其設計和優化直接影響訓練效率和成本。隨著模型規模的不斷增長和訓練需求的日益復雜,存儲系統也需要持續演進和創新。
通過合理的架構設計、精心的性能調優和完善的運維管理,我們可以構建出高效、可靠、可擴展的分布式存儲系統,為大語言模型的訓練提供堅實的數據基礎。
參考資料:
- Hadoop分布式文件系統設計文檔
- Lustre文件系統管理指南
- GlusterFS架構與實現
- 大規模機器學習系統設計模式
- 云原生存儲技術發展報告 100GB/s








![daily notes[44]](http://pic.xiahunao.cn/daily notes[44])

)





介紹及使用)


