禁止商業或二改轉載,僅供自學使用,侵權必究,如需截取部分內容請后臺聯系作者!
文章目錄
-
- 介紹
- 加載R包
- 數據下載
- 函數
- 導入數據
- 數據預處理
- 畫圖
- 總結
- 系統信息
介紹
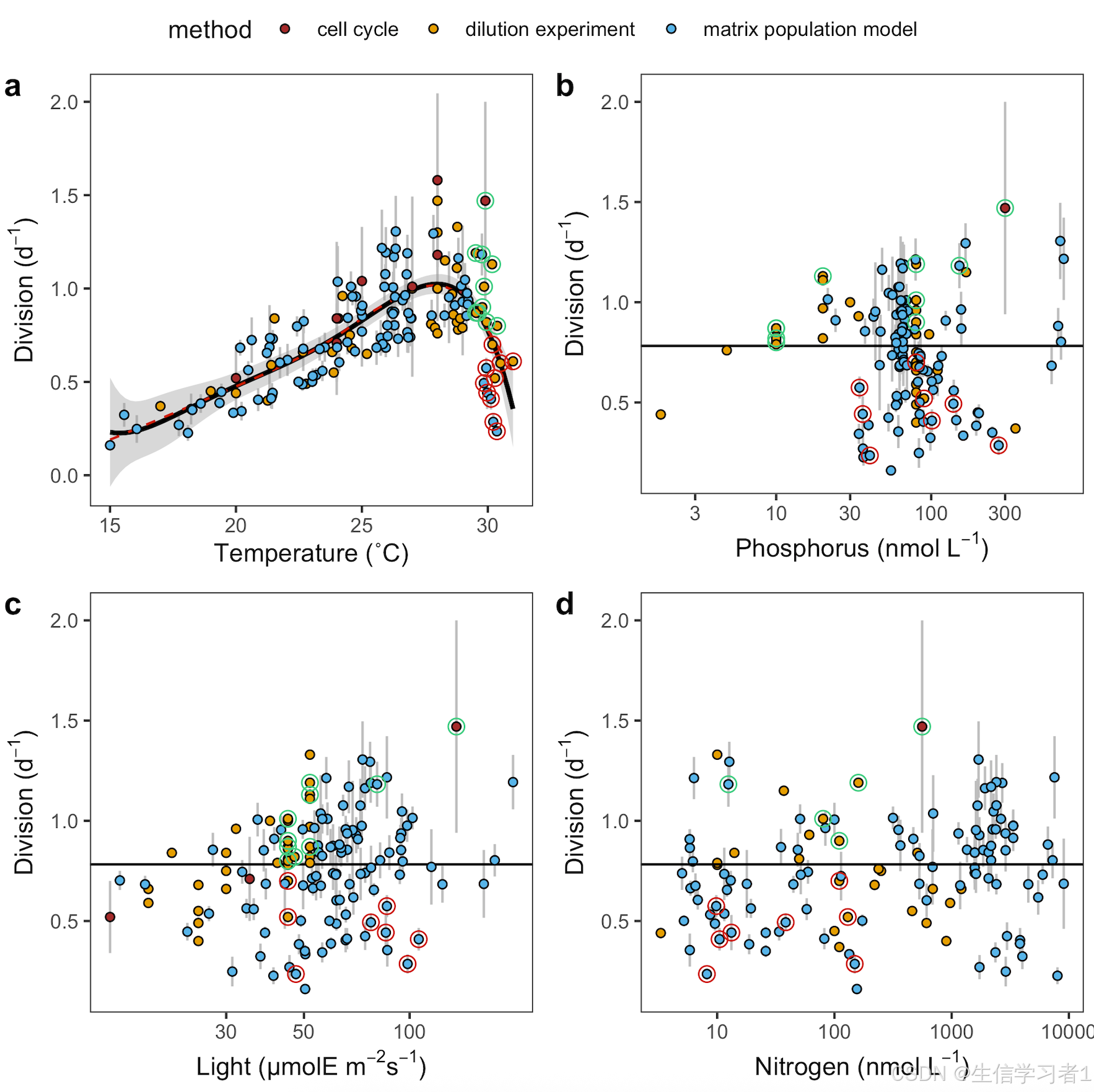
數據導入
代碼的開始部分涉及多個數據集的導入,這些數據集涵蓋了不同類型的生態學數據,包括實驗室培養實驗(culture.csv)、稀釋實驗(dilution.csv)、細胞豐度數據(abundance.csv)、校準數據(calibration.csv)以及基于矩陣種群模型的原位分裂率數據(mpm.csv)。此外,還包括了一個基于達爾文模型的模擬結果數據集(model_results.parquet)。這些數據集為后續的數據處理和可視化提供了基礎。
數據預處理
在數據預處理階段,代碼首先對model_all數據集進行了篩選和轉換,去除了某些不需要的列(如SST和NO3),并對生物量(biomass)進行了閾值處理,將小于0.01的值替換為0。接著,代碼通過pivot_wider和mutate函數計算了不同排放情景下相對于歷史數據的生物量變化百分比,并將數據重新轉換為長格式,以便于后續分析。







![daily notes[44]](http://pic.xiahunao.cn/daily notes[44])

)





介紹及使用)



