原文鏈接:https://arxiv.org/pdf/2502.05370v1
在混合專家(MoE)架構中,初始階段涉及輸入樣本通過GateNet進行多分類的鑒別過程,目的是確定最適合處理輸入的專家模型。這個步驟被稱為“experts selection”,也是整個MoE模型的核心理念,學術界通常將其描述為稀疏性激活。隨后,被選中(激活)的專家模型負責處理輸入樣本,進而生成最終的預測結果。
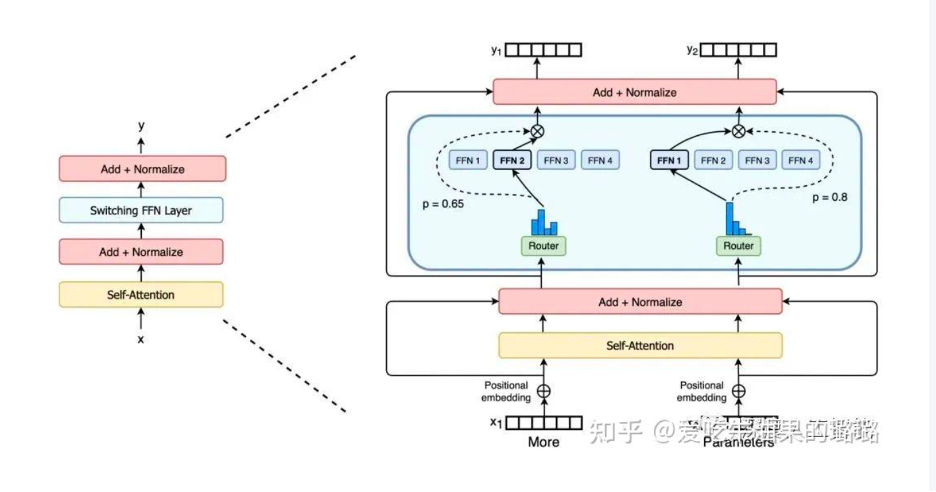
所以MOE有高效性的特點:由于只有少數專家模型被激活,大部分模型處于未激活狀態,混合專家模型具有很高的稀疏性。這種稀疏性帶來了計算效率的提升,因為只有特定的專家模型對當前輸入進行處理,減少了計算的開銷。
但是MOE也同樣有問題:那些不參與推理的模型仍然在GPU中待命,這樣就導致GPU的memory不堪重負。所以就提出了experts offload。
由于是MOE所以一些模型其實是不激活的,那么,就可以把這些模型offload到CPU上,這樣就是可以節約GPU的儲存和帶寬。這個就叫做experts offload.
但是現有的很多experts offload方法都沒有很好的提升模型時延,或者仍然有大量內存占用的問題。主要原因是他們做的不夠細,模型沒有很好的被分門別類,導致真正需要使用的expert被錯誤的放到了CPU上,在使用expert的時候需要重新加載的時間。
粗顆粒度的offloading solution是基于request level的,這樣的話就是由多個iteration組成的。而細顆粒度則是iteration level的。但是實驗表明,粗顆粒度的expert heatmap被激活的更加均勻(熵更大)而且隨著iteration的增加,expert被激活的就是更加均勻。
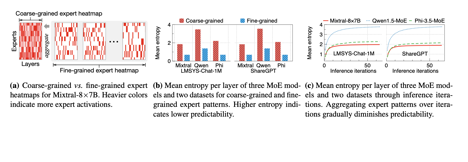
fMoE提出了expert-map,記錄iteration級別輸入的內容以及調取模型的情況,然后根據這張expert-map來決定experts offload。
fMoE的整體架構:
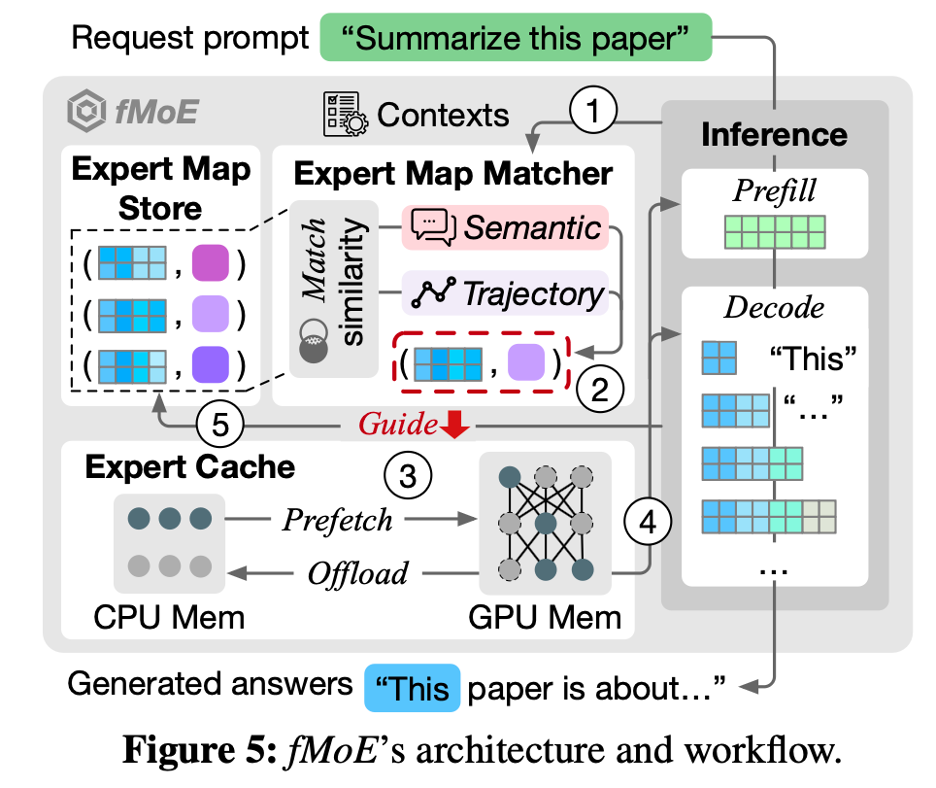
問題
- 這個fMoE是在訓練階段用呢,還是推理階段用呢?
推理階段用,因為模型不能有變化 - Expert map macher 和expert cache怎么保證比推理更快的呢?
要提前幾層預測出來expert的使用情況
整片文章使用了啟發解的方式去semantic和trajectory與歷史記錄的相似性(用cosine similarity),然后選擇和歷史semantic、trajectory相近的expert去prefetch
LLM中的trajectory是指啥?In this paper, “trajectory” is defined as the collection of probability distributions over experts observed through layers.
大概的意思是,由歷史的iteration的內容來推斷當前iteration的內容。但是,每個iteration有很多layers, 所以存在semantic和trajectory兩種方式。但這兩個score咋整合呢???

)





)

)









